前言
IPAdapter能够通过图像给Stable Diffusion模型以内容提示,让其生成参考该图像画风,可以免去Lora的训练,达到参考画风人物的生成效果。
摘要
通过文本提示词生成的图像,往往需要设置复杂的提示词,通常设计提示词变得很复杂。文本提示可以由图像来替代。直接微调预训练模型也是一种行之有效的方法,但是需要消耗大量计算资源。并且存在模型兼容性问题。在本文中,我们介绍了 IP-Adapter,这是一种有效且轻量级的适配器,用于实现预训练文本到图像扩散模型的图像提示功能。我们的 IP 适配器的关键设计是解耦的交叉注意力机制,将文本特征和图像特征的交叉注意力层分开。尽管我们的方法很简单,但只有 22M 参数的 IP 适配器可以实现与完全微调的图像提示模型相当甚至更好的性能。当我们冻结预训练的扩散模型时,所提出的 IP-Adapter 不仅可以推广到从同一基础模型微调的其他自定义模型,还可以推广到使用现有可控工具的可控生成。借助解耦交叉注意力策略的优势,图像提示也可以很好地与文本提示配合使用,实现多模态图像生成。项目页面位于 https://ip-adapter.github.io。
介绍
- GLIDE [1]、DALL-E 2 [2 ]、Imagen [ 3]、Stable Diffusion (SD) [4]、eDiff-I [5]和RAPHAEL [ 6]等大型文本到图像扩散模型的成功,图像生成取得了显著的进步。编写文本提示通常会比较复杂,并且生成内容无法表达复杂的场景或概念。
- DALL-E 2[ 2 ] 首次尝试支持图像提示,扩散模型以图像嵌入而不是文本嵌入为条件,需要先验模型才能实现文本到图像的能力。然而,现有的大多数文本到图像扩散模型都是以文本为条件来生成图像的,例如,流行的SD模型以从冻结的CLIP[8]文本编码器中提取的文本特征为条件。这些文本到图像扩散模型是否也支持图像提示。我们的工作试图以一种简单的方式为这些文本到图像扩散模型启用图像提示的生成能力。
- SD Image Variations和Stable unCLIP,已经证明了直接在图像嵌入上微调文本条件扩散模型以实现图像提示功能的有效性。然而,这种方法的缺点是显而易见的。首先,它消除了使用文本生成图像的原始能力,并且这种微调通常需要大量的计算资源。其次,微调的模型通常不可重用,因为图像提示功能不能直接转移到从相同的文本到图像基础模型派生的其他自定义模型。此外,新模型通常与现有的结构控制工具(如ControlNet[9])不兼容,这给下游应用带来了重大挑战。
ControlNet [9]和T2I-adapter [11],已经证明,在现有的文本到图像扩散模型中可以有效地插入一个额外的网络来指导图像生成。
大多数研究侧重于图像生成,并带有额外的结构控制,如用户绘制的草图、深度图、语义分割图等。此外,通过简单的适配器,如T2I适配器的样式适配器[11]和Uni-ControlNet的全局控制器[12],也可以通过简单的适配器实现由参考图像提供的样式或内容的图像生成。为了实现这一点,从CLIP图像编码器中提取的图像特征通过可训练网络映射到新特征,然后与文本特征连接起来。通过替换原始文本特征,将合并后的特征输入到扩散模型的UNet中,以指导图像生成。这些适配器可以看作是具有使用图像提示能力的一种方式,但生成的图像仅部分忠实于提示的图像。结果往往比微调的图像提示模型差,更不用说从头开始训练的模型了。
我们认为,上述方法的主要问题在于文本到图像扩散模型的交叉注意力模块。对预训练扩散模型中交叉注意力层的键和值投影权重进行训练,以适应文本特征。因此,将图像特征和文本特征合并到交叉注意力层中只能完成图像特征与文本特征的对齐,但这可能会遗漏一些特定于图像的信息,并最终导致仅使用参考图像进行粗粒度可控生成(例如,图像样式)。
为此,我们提出了一种更有效的图像提示适配器,命名为IP-Adapter,以避免了前人方法的缺点。具体而言,IP-Adapter对文本特征和图像特征采用解耦的交叉注意力机制。对于扩散模型的UNet中的每个交叉注意力层,我们仅为图像特征添加一个额外的交叉注意力层。在训练阶段,只训练新的交叉注意力层的参数,而原来的UNet模型保持冻结状态。我们提出的适配器是轻量级的,但非常高效:只有22M参数的IP适配器的生成性能可与文本到图像扩散模型中完全微调的图像提示模型相媲美。更重要的是,我们的 IP 适配器具有出色的泛化能力,并且与文本提示兼容。使用我们提出的 IP 适配器,可以轻松完成各种图像生成任务,如下图所示。
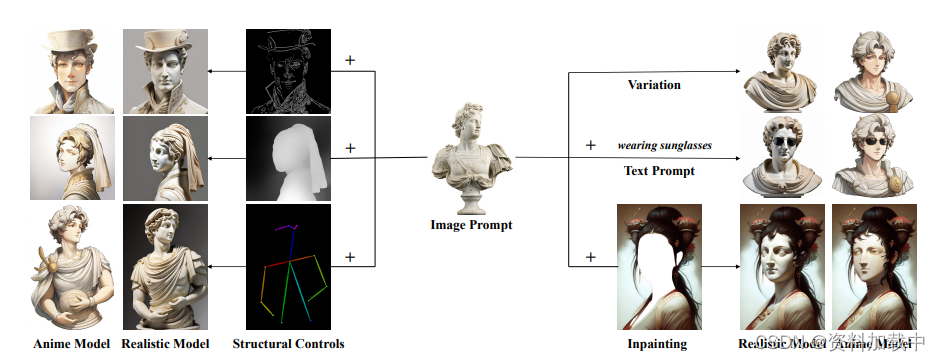
我们提出了IP-Adapter,这是一种轻量级的图像提示适应方法,具有解耦的交叉注意力策略,适用于现有的文本到图像扩散模型。定量和定性实验结果表明,在基于图像提示生成方面,具有约22M参数的小型IP适配器与完全微调的模型相当,甚至更好。
相关工作
文生图扩散模型
大型文本转图像模型主要分为两类:自回归模型和扩散模型。早期的作品,如DALLE [ 13 ]、CogView [ 14, 15 ]和Make-A-Scene [ 16],都是自回归模型。对于自回归模型,使用像VQ-VAE [ 17 ]将图像转换为token,然后训练一个以文本标记为条件的自回归转换器[18]来预测图像标记。然而,自回归模型通常需要较大的参数和计算资源来生成高质量的图像,如Parti [19]所示。
最近,扩散模型(DMs)[20,21,22,23]已成为文本到图像生成的新模型。作为先驱,GLIDE采用级联扩散架构,分辨率为64×64,分辨率为3.5B文本条件扩散模型,分辨率为256×256,分辨率为1.5B文本条件上采样扩散模型。DALL-E 2 采用扩散模型条件图像嵌入,并训练先前的模型通过给出文本提示来生成图像嵌入。DALL-E 2 不仅支持图像生成的文本提示,还支持图像提示。为了增强对文本的理解,Imagen 采用了 T5 [ 24],一个在纯文本数据上预训练的大型 transformer 语言模型,作为扩散模型的文本编码器。Re-Imagen [ 25 ] 使用检索到的信息来提高稀有或看不见实体的生成图像的保真度。SD 建立在潜在扩散模型 [ 4 ] 之上,该模型在潜在空间而不是像素空间上运行,使 SD 能够仅使用扩散模型生成高分辨率图像。为了改善文本对齐,eDiff-I 设计了一组文本到图像扩散模型,利用了多种条件,包括 T5 文本、CLIP 文本和 CLIP 图像嵌入。Versatile Diffusion [ 26 ] 提出了一个统一的多流扩散框架,以支持单个模型中的文本到图像、图像到文本和变体。为了实现可控的图像合成,Composer [ 27] 提出了一种在以图像嵌入为条件的预训练扩散模型上具有各种条件的联合微调策略。RAPHAEL在文本条件图像扩散模型中引入了混合专家(MoE)策略[28,29],以提高图像质量和审美吸引力。
DALL-E 2 的一个吸引人的特点是它还可以使用图像提示来生成图像变化。因此,还有一些工作需要探索,以支持仅以文本为条件的文本到图像扩散模型的图像提示。SD 图像变化模型是从修改后的 SD 模型微调而来的,其中文本特征被替换为 CLIP 图像编码器的图像嵌入。稳定的unCLIP也是SD上的微调模型,其中图像嵌入被添加到时间嵌入中。虽然微调模型可以成功地使用图像提示生成图像,但往往需要比较大的训练成本,并且无法与现有工具兼容,例如ControlNet[9]。
适用于大型模型的适配器
由于微调大型预训练模型效率低下,另一种方法是使用适配器,它添加了一些可训练的参数,但会冻结原始模型。适配器在NLP领域已经应用了很长时间[30]。最近,适配器已被用于实现大型语言模型的视觉语言理解[31,32,33,34,35]。
随着最近文本到图像模型的普及,适配器也被用于为文本到图像模型的生成提供额外的控制。ControlNet [9] 首先证明了可以使用预训练的文本到图像扩散模型来训练适配器,以学习特定于任务的输入条件,例如 canny edge。几乎同时,T2I适配器[11]采用简单轻量级的适配器来实现对生成图像的颜色和结构的细粒度控制。为了降低微调成本,Uni-ControlNet [ 12 ] 提出了一种多尺度条件注入策略来学习各种局部控制的适配器。
除了用于结构控制的适配器外,还有根据所提供图像的内容和风格进行可控生成的工作。ControlNet Shuffle 经过训练,可以重新组合图像,可用于指导由用户提供的图像生成。此外,还提出了ControlNet Reference-only,通过简单的特征注入在SD模型上实现图像变体,无需训练。在 T2I 适配器的更新版本中,样式适配器旨在通过将从 CLIP 图像编码器中提取的图像特征附加到文本特征来使用参考图像来控制生成图像的样式。Uni-ControlNet的全局控制适配器还将CLIP图像编码器的图像嵌入投射到小网络的条件嵌入中,并与原始文本嵌入连接起来,用于指导参考图像的样式和内容的生成。SeeCoder [10] 提出了一个语义上下文编码器来替换原始文本编码器以生成图像变体。
尽管上述适配器是轻量级的,但它们的性能几乎无法与微调的图像提示模型相提并论,更不用说从头开始训练的模型了。在这项研究中,我们引入了一种解耦的交叉注意力机制,以实现更有效的图像提示适配器。所提出的适配器仍然简单小巧,但优于以前的适配器方法,甚至可以与微调模型相媲美。
方法
预备知识
扩散模型是一类生成模型,由两个过程组成:扩散过程(也称为正向过程),它使用固定的马尔可夫 T 步链逐渐将高斯噪声添加到数据中,以及去噪过程,该过程使用可学习模型从高斯噪声生成样本。扩散模型还可以基于其他输入进行调节,例如文本到图像扩散模型中的文本。通常,预测噪声的扩散模型的训练目标(表示为 ε)被定义为变分边界的简化变体:
![]() 其中 x表示带有附加条件 c 的真实数据,t ∈ [0, T ] 表示扩散过程的时间步长,x= αx+ σε 是 t 步的噪声数据,α,σ 是确定扩散过程的 t 预定义函数。一旦模型ε被训练,就可以以迭代的方式从随机噪声中生成图像。通常,在推理阶段采用DDIM [21]、PNDM [36]和DPM-Solver[37,38]等快速采样器来加速生成过程。
其中 x表示带有附加条件 c 的真实数据,t ∈ [0, T ] 表示扩散过程的时间步长,x= αx+ σε 是 t 步的噪声数据,α,σ 是确定扩散过程的 t 预定义函数。一旦模型ε被训练,就可以以迭代的方式从随机噪声中生成图像。通常,在推理阶段采用DDIM [21]、PNDM [36]和DPM-Solver[37,38]等快速采样器来加速生成过程。
对于条件扩散模型,分类器引导[ 23]是一种简单的技术,用于通过利用来自单独训练的分类器的梯度来平衡图像保真度和样本多样性。消除培训的需要独立分类器、无分类器指导[39]通常被用作替代方法。在这种方法中,条件和无条件扩散模型是通过在训练过程中随机丢弃 c 来联合训练的。在采样阶段,根据条件模型ε(x, c, t)和非条件模型ε(x, t)的预测来计算预测噪声:
![]() 在这里,W,通常称为指导刻度或指导权重,是一个标量值,用于调整与条件 C 的对齐方式。对于文本到图像扩散模型,无分类器引导在增强生成样本的图像-文本对齐方面起着至关重要的作用。
在这里,W,通常称为指导刻度或指导权重,是一个标量值,用于调整与条件 C 的对齐方式。对于文本到图像扩散模型,无分类器引导在增强生成样本的图像-文本对齐方面起着至关重要的作用。
在我们的研究中,我们利用开源 SD 模型作为示例基础模型来实现 IP 适配器。SD 是一种潜在扩散模型,以从冻结的 CLIP 文本编码器中提取的文本特征为条件。扩散模型的架构基于带有注意力层的UNet[40]。与 Imagen 等基于像素的扩散模型相比,SD 效率更高,因为它是在预训练的自动编码器模型的潜在空间上构建的。
图像提示适配器
在本文中,图像提示适配器旨在使预训练的文本到图像扩散模型能够生成具有图像提示的图像。如前几节所述,当前的适配器很难与微调的图像提示模型或从头开始训练的模型的性能相匹配。主要原因是图像特征无法有效地嵌入到预训练模型中。大多数方法只是将串联的特征馈送到冻结的交叉注意力层中,从而防止扩散模型从图像提示中捕获细粒度特征。为了解决这个问题,我们提出了一种解耦的交叉注意力策略,其中图像特征被新添加的交叉注意力层嵌入。我们提出的 IP 适配器的整体架构如图 2 所示。所提出的 IP 适配器由两部分组成:用于从图像提示中提取图像特征的图像编码器,以及具有解耦交叉注意力的适配模块,用于将图像特征嵌入到预训练的文本到图像扩散模型中。
图像编码器
在大多数方法之后,我们使用预训练的 CLIP 图像编码器模型从图像提示中提取图像特征。CLIP 模型是一种多模态模型,通过对比学习在包含图像文本对的大型数据集上进行训练。我们利用 CLIP 图像编码器的全局图像嵌入,它与图像标题很好地对齐,可以表示图像的丰富内容和风格。在训练阶段,CLIP图像编码器被冻结。
为了有效地分解全局图像嵌入,我们使用一个小型可训练投影网络将图像嵌入投影到长度为N的特征序列中(本研究使用N = 4),图像特征的维度与预训练扩散模型中文本特征的维度相同。我们在这项研究中使用的投影网络由线性层和层归一化组成[41]。
解耦的交叉注意力
图像特征通过具有解耦交叉注意力的自适应模块集成到预训练的 UNet 模型中。在原始 SD 模型中,来自 CLIP 文本编码器的文本特征通过馈送到交叉注意力层中插入到 UNet 模型中。给定查询特征 Z 和文本特征 c,交叉注意力 Z 的输出可以由以下等式定义:
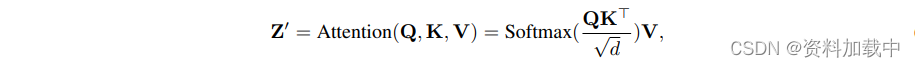
其中 Q = ZW, K = cW, V = cWare 分别是注意力操作的查询、键和值矩阵,W, W, Ware 是可训练线性投影层的权重矩阵。
插入图像特征的一种直接方法是将图像特征和文本特征连接起来,然后将它们馈送到交叉注意力层中。然而,我们发现这种方法不够有效。取而代之的是,我们提出了一种解耦的交叉注意力机制,其中文本特征和图像特征的交叉注意力层是分开的。具体来说,我们在原始UNet模型中为每个交叉注意力层添加了一个新的交叉注意力层,以插入图像特征。给定图像特征c,新的交叉注意力Zis的输出计算如下:
其中,Q = ZW,K= cW和 V= cWare 来自图像特征的查询、键和值矩阵。W 和 Ware 相应的权重矩阵。应该注意的是,我们对图像交叉注意力使用与文本交叉注意力相同的查询。因此,我们只需要为每个交叉注意力层添加两个参数 W, W。为了加快收敛速度,Wand Ware 从 Wand W 初始化。然后,我们只需将图像交叉注意力的输出添加到文本交叉注意力的输出中即可。因此,解耦交叉注意力的最终公式定义如下:
我们冻结了原来的UNet模型,只有魔杖器皿可以在上面解耦的交叉注意力中训练。
训练与推理
在训练过程中,我们只优化 IP-Adapter,同时保持预训练扩散模型的参数固定。IP-Adapter 还使用图像-文本对在数据集上进行训练,使用与原始 SD 相同的训练目标:
我们还在训练阶段随机丢弃图像条件,以便在推理阶段启用无分类器指导:
在这里,如果图像条件被删除,我们只需将 CLIP 图像嵌入归零。 由于文本交叉注意力和图像交叉注意力是分离的,我们也可以在推理阶段调整图像条件的权重:
![]()
其中 λ 是权重因子,如果 λ = 0,则模型将成为原始文本到图像扩散模型。
实验
为了训练 IP-Adapter,我们构建了一个多模态数据集,其中包括来自两个开源数据集 LAION-2B [42] 和 COYO-700M [43] 的大约 1000 万个文本图像对。
我们的实验基于SD v1.5,我们使用OpenCLIP ViT-H/14 [44 ]作为图像编码器。SD 模型中有 16 个交叉注意力层,我们为每个层添加了一个新的图像交叉注意力层。我们的 IP 适配器的总可训练参数(包括投影网络和适配模块)约为 22M,使 IP 适配器非常轻巧。我们使用 HuggingFace diffusers库 [45] 实现我们的 IP 适配器,并使用 DeepSpeed ZeRO-2 [ 13 ] 进行快速训练。IP-Adapter 在具有 8 个 V100 GPU 的单台机器上进行 1M 步长训练,每个 GPU 的批处理大小为 8 个。我们使用AdamW优化器[46],固定学习率为0.0001,权重衰减为0.01。在训练过程中,我们将图像的最短边调整为 512,然后以 512 × 512 分辨率对图像进行居中裁剪。为了实现无分类器指导,我们使用 0.05 的概率分别删除文本和图像,并使用 0.05 的概率同时删除文本和图像。在推理阶段,我们采用 50 步的 DDIM 采样器,并将引导等级设置为 7.5。当仅使用图像提示时,我们将文本提示设置为空且 λ = 1.0。
结论
在这项工作中,我们提出了 IP-Adapter 来实现预训练文本到图像扩散模型的图像提示功能。我们的 IP 适配器的核心设计基于解耦的交叉注意力策略,该策略为图像特征整合了单独的交叉注意力层。定量和定性实验结果表明,我们的IP适配器只有22M参数,其性能与一些完全微调的图像提示模型和现有适配器相当,甚至更好。此外,我们的 IP 适配器只需经过一次训练,就可以直接与从同一基础模型和现有结构可控工具派生的自定义模型集成,从而扩大其适用性。更重要的是,图像提示可以与文本提示相结合,实现多模态图像生成。
尽管我们的 IP 适配器很有效,但它只能生成在内容和样式上类似于参考图像的图像。换句话说,它不能像一些现有的方法那样合成与给定图像的主题高度一致的图像,例如Textual Inversion [ 51 ]和DreamBooth [52 ]。未来,我们的目标是开发更强大的图像提示适配器,以增强一致性。
参考链接
https://arxiv.org/pdf/2308.06721.pdf
GitHub - tencent-ailab/IP-Adapter: The image prompt adapter is designed to enable a pretrained text-to-image diffusion model to generate images with image prompt.