在去年 8 月份发布的 3.1.0.0 版本中,TDengine 进行了一系列重要的企业级功能更新,其中包括对多表低频场景写入性能的大幅优化。这一优化工作为有此需求的用户提供了更大的便捷性和易用性。在本文中,TDengine 的资深研发将对此次优化工作进行深入分析介绍,并从实践层面剖析本次功能升级的具体作用。
三种时序场景分析
以 TDengine 的客户群体作为分析样本,我们发现,企业的时序场景大概可以分为以下三种类型:
- 少表高频
- 表的数量小,一般少于 100 万张表。
- 数据采集频率高,多为秒级甚至毫秒级。
- 在存储引擎看来,大量写入的数据中,同一张表的数据被多次写入,且时间戳递增,或有极少数的乱序。
- 当内存中的数据积攒到一定的量需要落盘时,同一张表的数据大量存在,可以生成多个数据块。
- 多表低频(High Cardinality)
- 表的数量大,一般多于 100 万张表,达到千万、亿级别。
- 表的采集频率很低,多为分钟级采集,也有小时级和天级的采集频率。
- 在存储引擎看来,大量写入的数据中,同一张表只有几条甚至一条数据的写入。
- 数据落盘时,每张表只有一条或几条记录,无法生成一个完整的数据块。
- 无限热点表
- 每张表只在一段时间内数据频繁更新写入,成为写入热点,其后很少或根本不再有数据的写入。
- 在不同的时间段内,写入热点表一直改变,且持续创建新的表。
- 如果以 TDengine 的数据模型建表,表数将达到无限。
- 在存储看来,该场景兼具多表低频和少表高频的特点。
- 在一段时间内,某些表写入数据非常多。落盘时,同一张表的数据可能会产生多个数据块,表现出高频的特性。而大部分表不写入数据。
- 随着时间的推移,表的数量会非常庞大,表现出多表的特性。
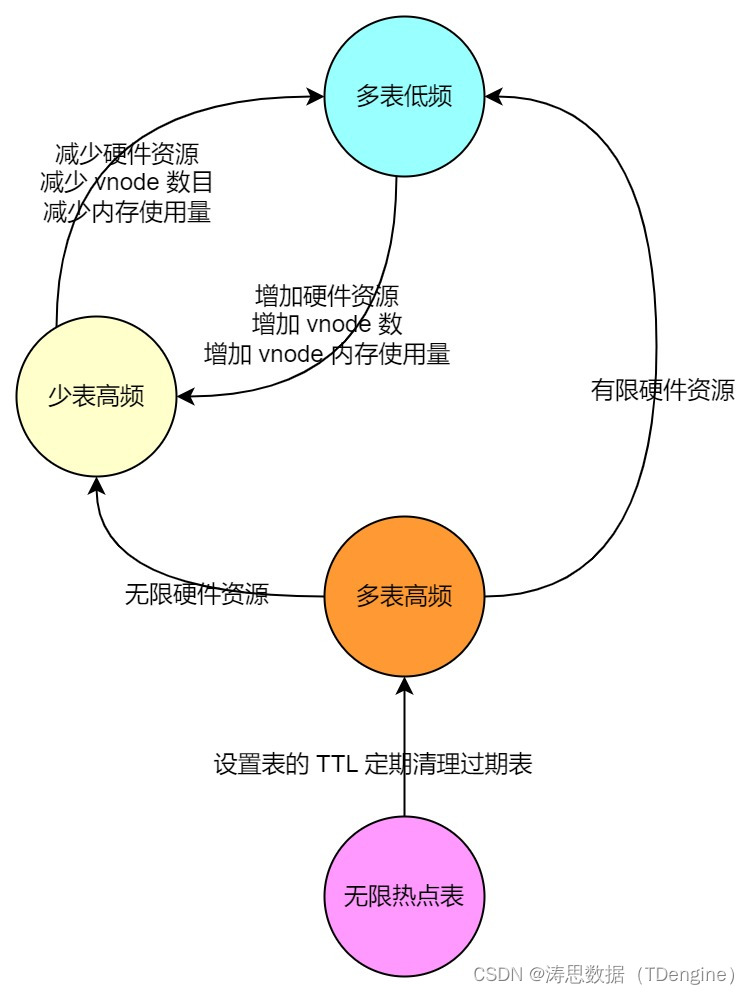
对于少表低频的场景来说,由于数据量不大,用任何方案都可以解决。而多表高频的场景,在有限的硬件资源下会转变为多表低频场景,在无限的硬件资源下,则会转变为少表高频场景。
在 TDengine 的用户群体中,部分多表低频的用户也可以通过增加节点,即增加 vnode 个数,使用更多的硬件资源将多表低频场景转化为了少表高频场景,从而较为高效地利用 TDengine 在少表高频场景下的高性能,但增加硬件资源本身和 TDengine 的初衷(为用户节省硬件资源)相违背。以北京燃气举例,在 300万+ 燃气表、每个燃气表每天采集一条记录的场景下,用 TDengine 3.0 处理,通过增大 vnode 个数将之转化为少表高频的场景后,相比用户以前用 Oracle 时成本并未节省多少。
对于无限热点表场景来说,如果用 TDengine 来处理该场景,随着时间的推移,表的数量会越来越多,效率会越来越低,成本会越来越高直至不可用。不过,TDengine 3.0 提供了表的 TTL(Time-To-Live)功能,用户可以通过该功能设置过期表自动删除,从而控制表的数目不至于达到无限。但该场景最终也退化成了多表高频场景。
有人说这三种场景可以统一为一种模型处理,即 InfluxDB 的模型:对一个时间线指定 tag,数据为采集数据。鉴于 InfluxDB 以该数据模型设计的存储模型的表现,个人认为,InfluxDB 的数据模型除了能帮助大家很好地理解时序数据这个优点之外,对于解决上述多表低频和无限热点表场景没有任何实际价值。且 InfluxDB 本身对于 tag 取值范围大的场景(High Cardinality)处理非常差,以致于被竞品攻击。
从以上角度出发,随着 TDengine 3.0 版本的逐步更新,我们开始针对多表低频场景写入性能开展优化工作。
TDengine 存储引擎设计概述
从根本上来说,TDengine 的设计和实现来自于对时序数据十大特点的总结和一个数据模型的确定。
- 时序数据十大特点:

- TDengine 数据模型:一个采集点一张表
TDengine 采用一个采集点一张表的数据模型,主要是要利用时序这一特点。
TDengine 存储引擎整体采用了 LSM 的存储架构。其结构如下图所示:
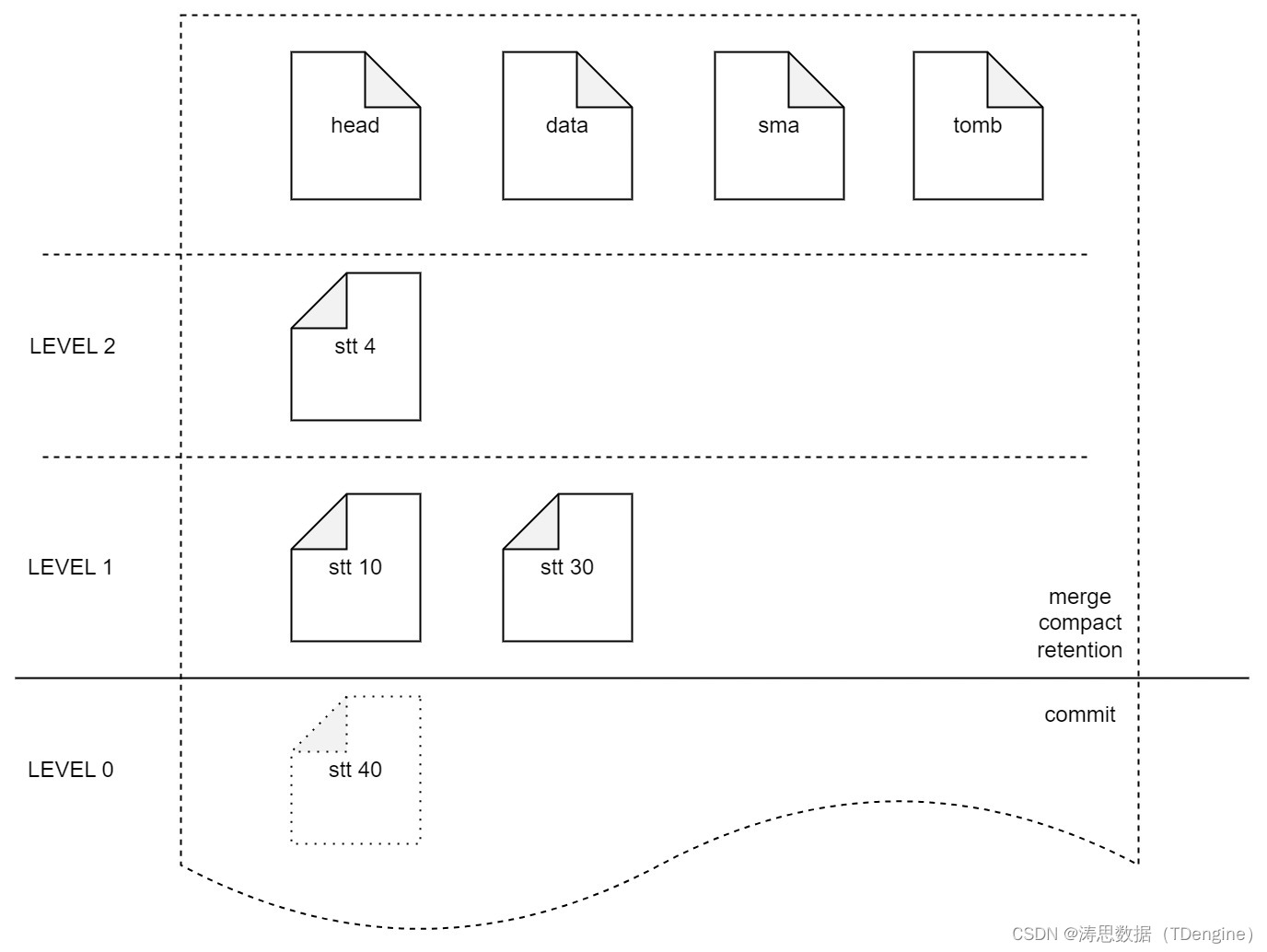
TDengine 的文件系统如下:
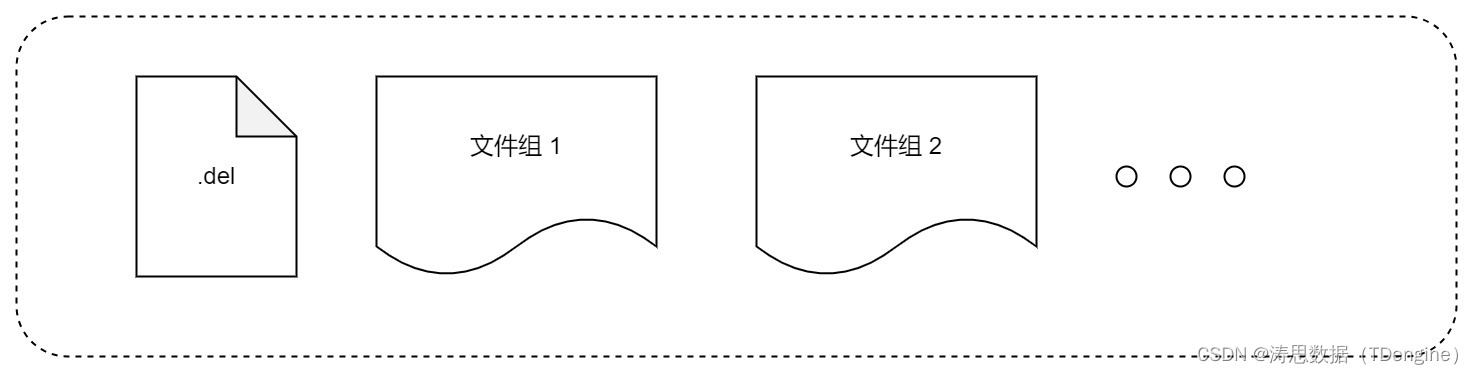
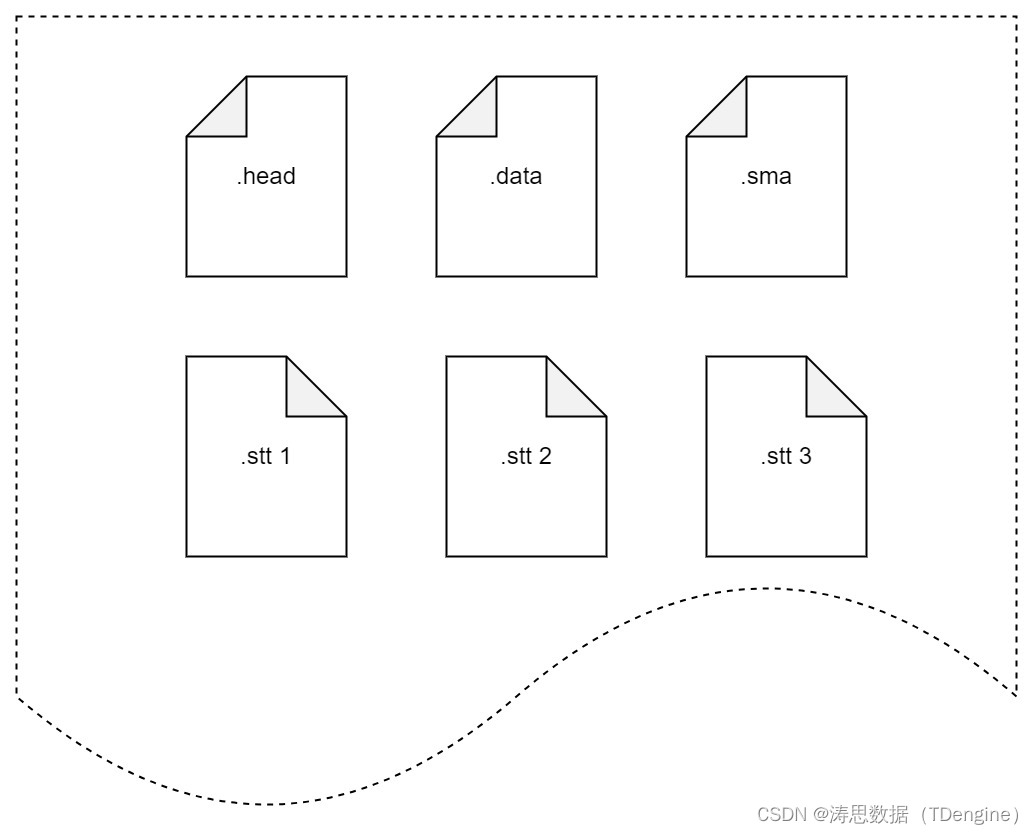
文件组的结构如下:
存储引擎优化工作的具体展开
明确优化要解决的问题
- 解决在多表场景下写放大问题
在少表高频的场景下,TDengine 充分利用了有序这个特点,在该场景下的写入性能相比同类型数据库高出一个甚至几个数量级,达到最优 O(N) 的时间复杂度。在存储格式上,我们假设落盘时一张表的数据大量存在,从而设计了硬盘上一个数据块只包含一张表的数据这样一种结构。

但是在多表场景下,从存储引擎的角度来讲,上述的很多特性会发生改变。由于存储引擎可以利用的内存资源有限,在内存可缓存的数据里,属于同一张表的数据只有很少的几条,甚至一条。在这种情况下,有序这个特点几乎无用,我们针对有序做的优化在多表场景下趋于无效,甚至会导致写放大问题。

在存储引擎看来,多表低频场景下的数据写入是纯乱序的。从理论上来讲,该场景下数据写入的最优处理复杂度为 O(NlogN)。
- 在多表低频场景下,stt_trigger 配置大以后写入周期性出现卡顿的问题
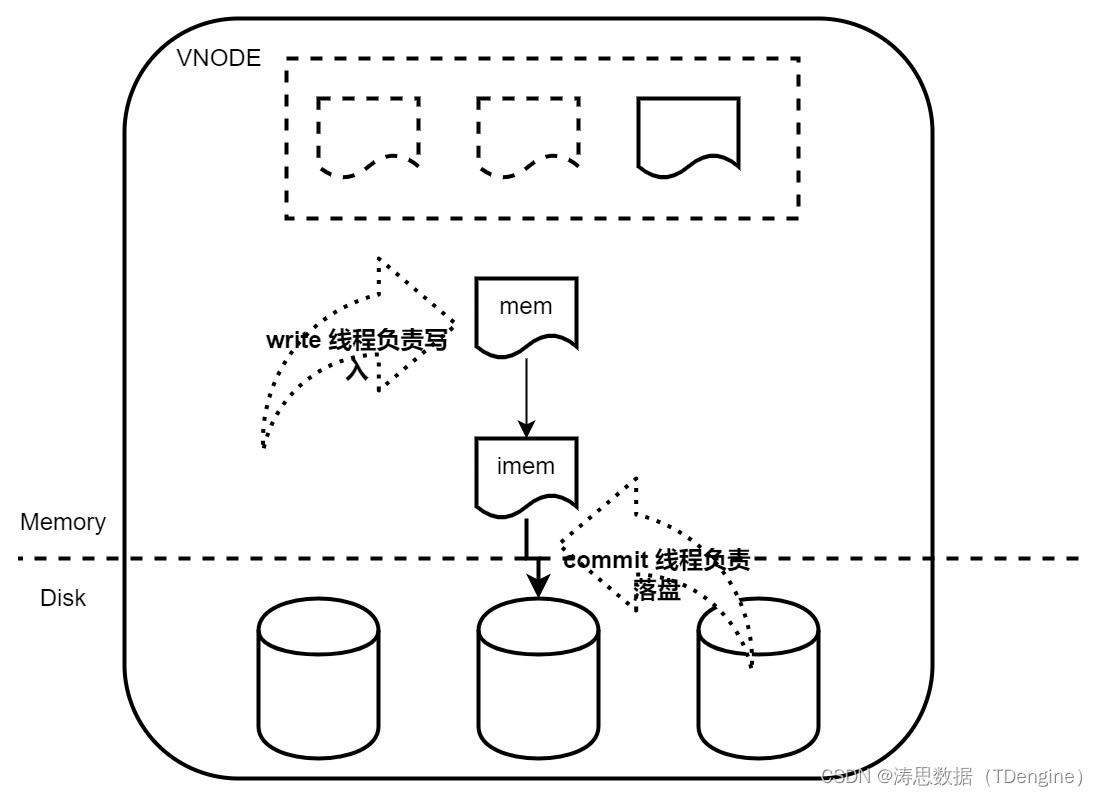
TDengine 后台有一个专门用来落盘的线程池,负责将 imem 中的数据持久化到硬盘文件上。这个文件可能是 stt 文件,也有可能是 data 文件中。如果生成了 stt 文件,并且 stt 个数达到了 stt_trigger,commit 线程则会将 imem 和 多个 stt 文件中的数据合并,写入 data 文件或者生成新的 stt 文件。这个合并可能涉及非常多的数据的读和写,从而使得落盘时间非常久,久到新的 mem 被写满,会阻塞写入进程一段时间,直至合并完成。
- compact、retention 功能阻塞写入的问题
由于 compact、retention、commit 均需对文件进行操作,且这些操作可能动相同的文件,因此这三个操作只能串行操做,从而导致 compact 或 retention 阻塞 commit,出现阻塞写入进程的问题。
存储数据调整
- stt 文件中一个数据块中可以包含多张表的数据(3.0 发布时已完成)
从上面的分析可以看到,一个数据块只有一张表的数据,在多表低频场景下,会导致数据写放大严重,且不利于压缩,读取时效率也非常低。因此,在优化中,我们将 stt 中属于同一个超级表的数据合并在一个数据块中,该数据块可能含有多个表的数据,这样就使得 stt 文件中的数据块数量减少了至少 3 个数量级。
- stt 文件中添加统计信息
为了提升 TDengine 查询引擎对于 stt 的处理效率,我们在新的 stt 文件中增加了每张表的统计信息。
- 删除数据(Tombstone Data)分布到各个文件组
在老的存储中删除文件是单独存在的。为了避免 commit 与其他操作处理同一个文件,我们决定将删除数据分布到不同的文件组中,并增加 tomb 文件。删除数据可能存在于 tomb 文件中或者 stt 文件中。
LSM 实现完善
在新的优化中,我们补齐了 LSM 的另一环,即后台的 merge。后台的 merge 线程将多个 stt 文件合并到 data 文件中或者生成新的 stt 文件。
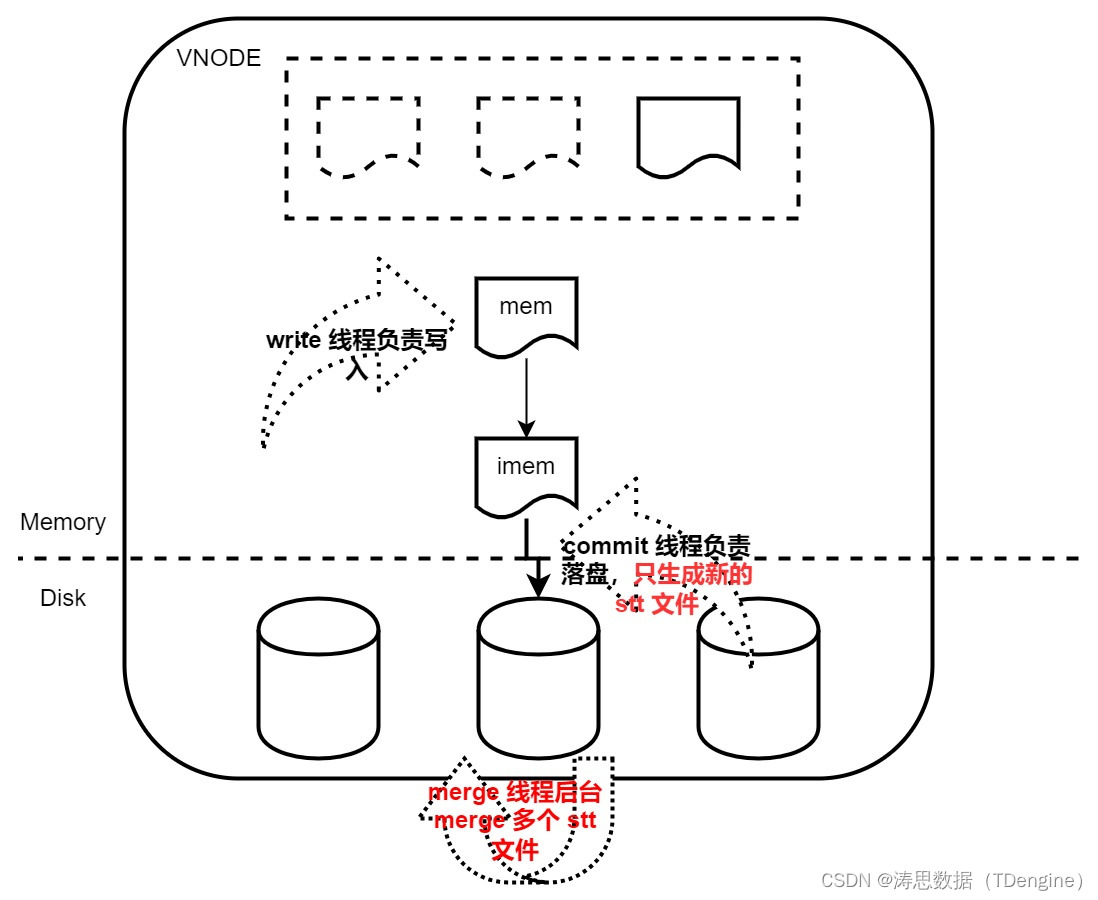
commit 只负责生成新的 stt 文件,不再负责向 data 中写入。这样就可以将 commit 操作的文件和 compact、retetion 以及 merge 操作的文件隔离开,从而实现并行进行,避免 commit 被阻塞而出现写入阻塞的情况。
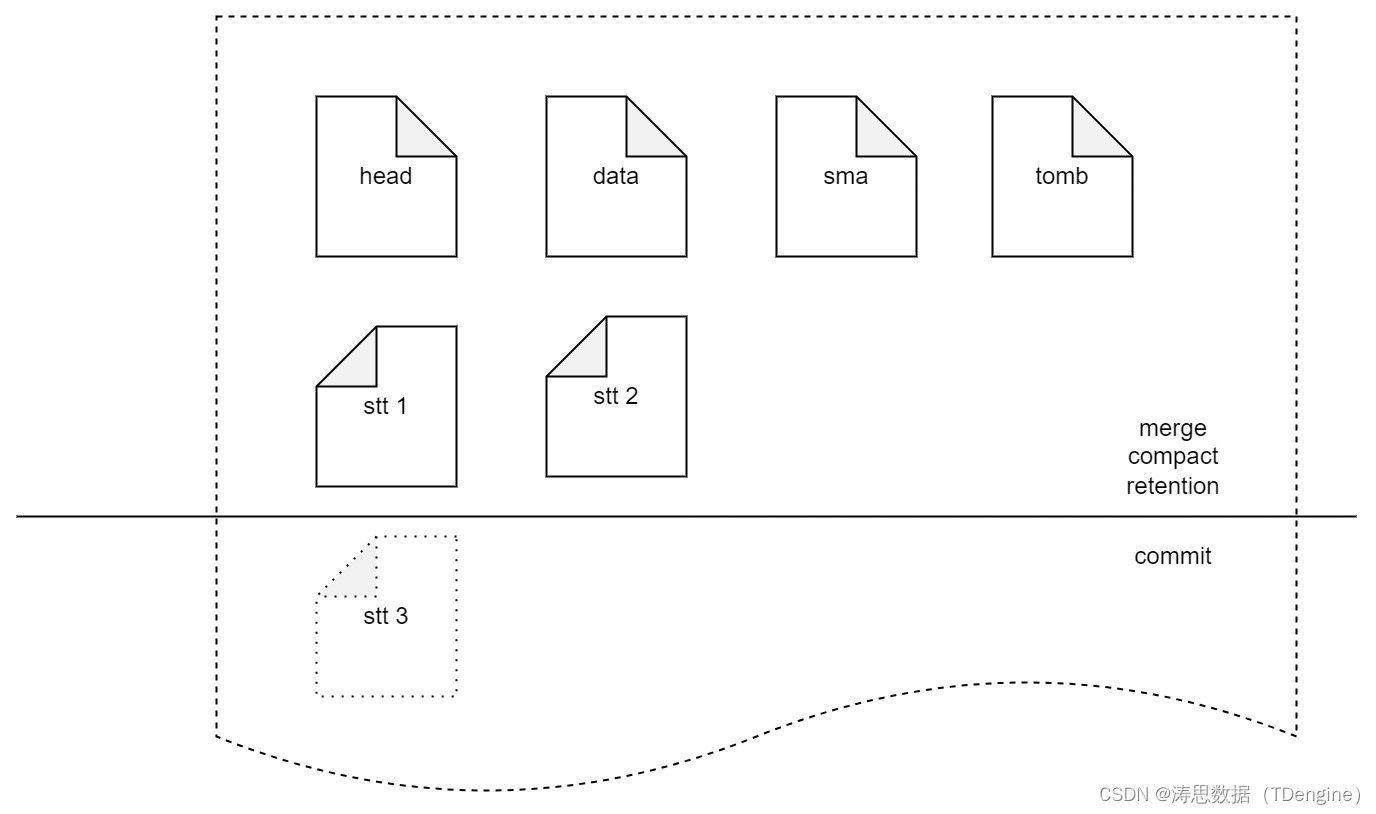
为了尽量减少多表低频场景下数据被多次 merge,我们还为 stt 文件引入了分层的概念。
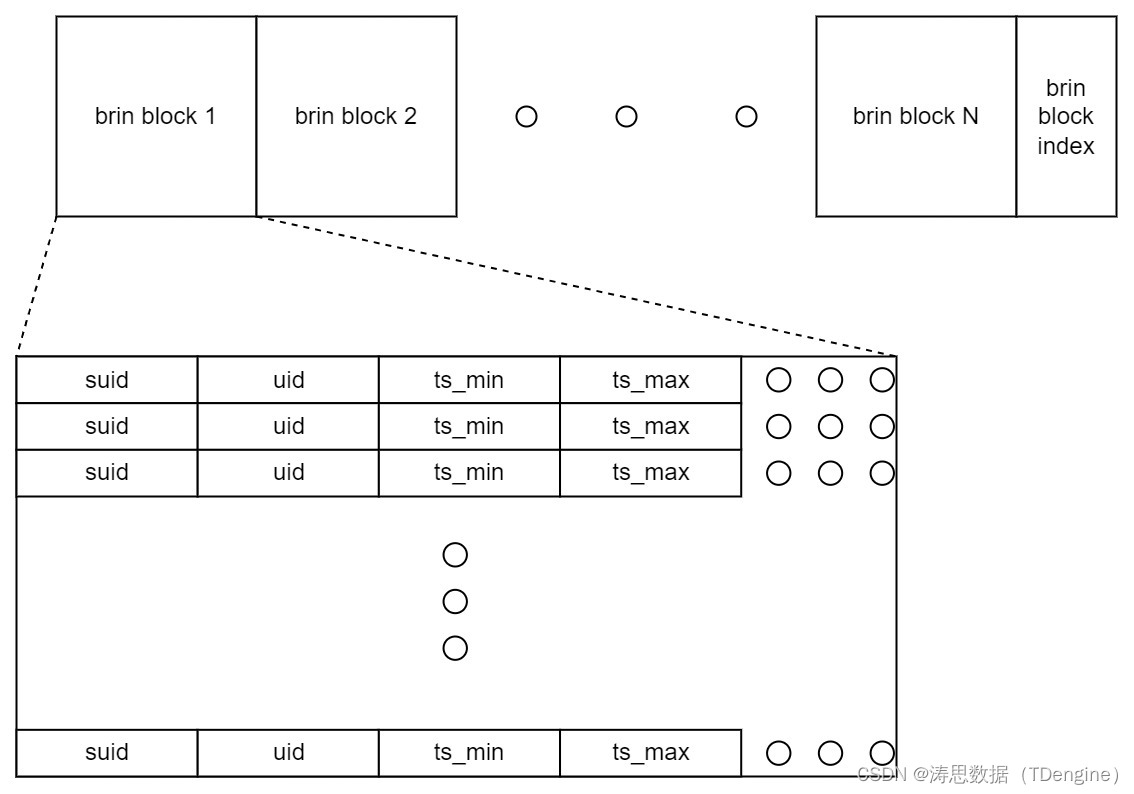
头文件列存
头文件列存的优化动力来源于国家地震局台网中心的用户场景。该用户的场景属于少表高频,表的数据量不大,但是采集频率是毫秒级的,因此数据量非常大,一天就有 3000 亿条记录写入。由于数据写入量非常大,导致数据块非常多,这也导致头文件非常大。由于头文件在每次落盘时都可能重写,就导致读写放大都十分严重。
因此,在本次优化中,我们将头文件改为列存,并对每一列配以压缩,从而使得头文件缩小到原来的 1/10。改造后的头文件格式如下:
优化结果反馈
此次优化一方面是为了提高多表低频写入的性能,另一方面是为了解决各种问题。整体来讲,本次优化的结果是:在少表高频场景下,写入性能不降;多表低频场景写入性能提升,并且写入速度稳定。此次优化在用户实践角度也反馈出良好效果——在北京燃气 300 万智能电表项目中,3 个 vnode 即可满足写入需求,且写入速度稳定;在河南智能电表项目中,用一台较好的机器,如 64 核 128GB 内存,就可以解决以前需要几十台机器才能满足的写入、查询需求。
同时,这种优化方式对于数据的乱序更新也带来了显著的好处。在一些无法在落盘时进行排序或合并的更新数据情况下,通过后台的 merge 操作,为乱序数据提供了额外的处理机会。这样,乱序数据可以被重新排序,未合并的更新数据也可以得到更新。这种优化机制有效地提高了数据的整体处理效率和准确性。
结语
总而言之,通过此次优化,TDengine 进一步提升了在低频场景下的写入性能,使用户能够更高效地存储和管理数据。这对于需要进行大规模数据处理的能源企业来说,将带来更加卓越的数据处理能力和用户体验。如果你也有此场景需求,可以添加小T vx:tdengine 进行咨询交流。