什么是hash冲突
哈希函数是一个映像,把任意长度的输入,通过Hash算法变换成固定长度的输出,这个输出就是Hash值; 当两个不同的输入,产生了同一个输出值即为哈希冲突
解决方式
开放定址法
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一一个空闲位置,将其插入。比如,我们可以使用线性探测法。当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,如果遍历到尾部都没有找到空闲的位置,那么我们就再从表头开始找,直到找到为止

①. 线性探测 :按顺序决定哈希值时,如果某数据的哈希值已经存在,则在原来哈希值的基础上往后加一个单位,直至不发生哈希冲突。
②. 再平方探测 :按顺序决定哈希值时,如果某数据的哈希值已经存在,则在原来哈希值的基础上先加1的平方个单位,若仍然存在则减1的平方个单位。随之是2的平方,3的平方等等。直至不发生哈希冲突。
③. 伪随机探测 :按顺序决定哈希值时,如果某数据已经存在,通过随机函数随机生成一个数,在原来哈希值的基础上加上随机数,直至不发生哈希冲突。
链地址法(拉链法)
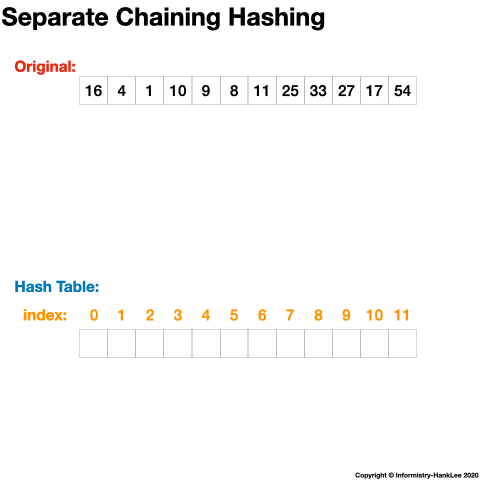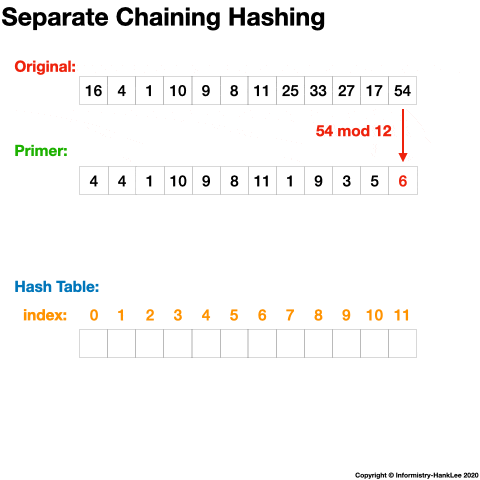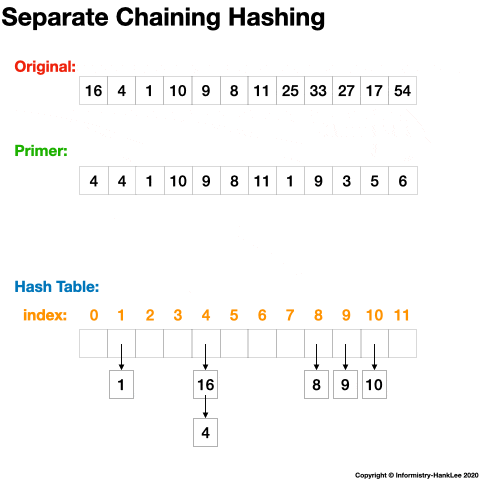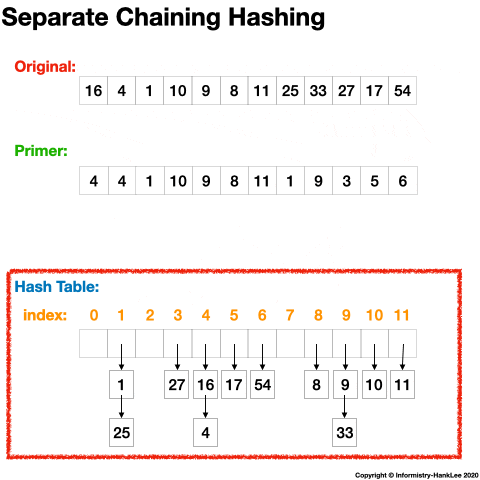
链地址法(Separate Chaining)的思路是将哈希值相同的元素构成一个同义词的单向链表,并将单向链表的头指针存放在哈希表的第 i 个单元中,查找、插入和删除主要在同义词链表中进行。
如下一组数字:(32、40、36、53、16、46、71、27、42、24、49、64),哈希表长度为13,哈希函数为 H(key)=key%13,则链表法结果如下:
0
1 -> 40 -> 27 -> 53
2
3 -> 16 -> 42
4
5
6 -> 32 -> 71
7 -> 46
8
9
10 -> 36 -> 49
11 -> 24
12 -> 64下面看一张动态图可能会更清晰(图片均来源于网络):
注意: 链地址法是主流开发语言中 HashMap 冲突的解决办法,如 Java、Go 等。以 Java 为例,JDK1.7 完全采用单链表来存储同义词,JDK 1.8 则采用了一种混合模式,对于链表长度大于 8 的,会转换为红黑树存储。
优点:处理简单,容易删除,只需要简单地删去链表上相应的结点即可;
缺点:一旦哈希冲突多了,哈希表会退化成链表,查询效率会从O(1)变为O(n)。JDK8的HashMap针对这种情况有做优化,冲突超过8个会将链表转换为红黑树,提高查询效率。
再哈希法
对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
采用哈希函数,而不是一个; 如果第一个哈希函数计算的哈希码发生冲突了,就采用第二个哈希函数重新计算哈希码,直到不冲突为止; 查询时也是一样,依次调用不同的哈希函数计算哈希码,直到Key相等。
int hash = hash1(key)、hash2(key)、hash3(key)......缺点:这种方式会增加哈希计算的开销,影响读写的效率。
建立公共溢出区
在创建哈希表的同时,再额外创建一个公共溢出区,专门用来存放发生哈希冲突的元素。查找时,先从哈希表查,查不到再去公共溢出区查。
缺点:哈希冲突多了,公共溢出区会膨胀的非常厉害,查询的效率也有影响。
最后总结
-
拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
-
由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
-
开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时, 拉链法中增加的指针域可忽略不计,因此节省空间;
-
在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表, 删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。