1.Exchanger 了解吗
Exchanger(交换者)是用于一个线程之间的协调工具类,Exchannge用于进行线程之间的数据交换,它提供一个同步点,两个线程可以交换彼此的数据。
假如两个线程有一个没有执行exchange()方法,则会一直等待,如果担心有特殊情况发生,避免一直等待,可以使用
exchange(Vx, longtimeOut,TimeUnitunit)设置最大等待时长。
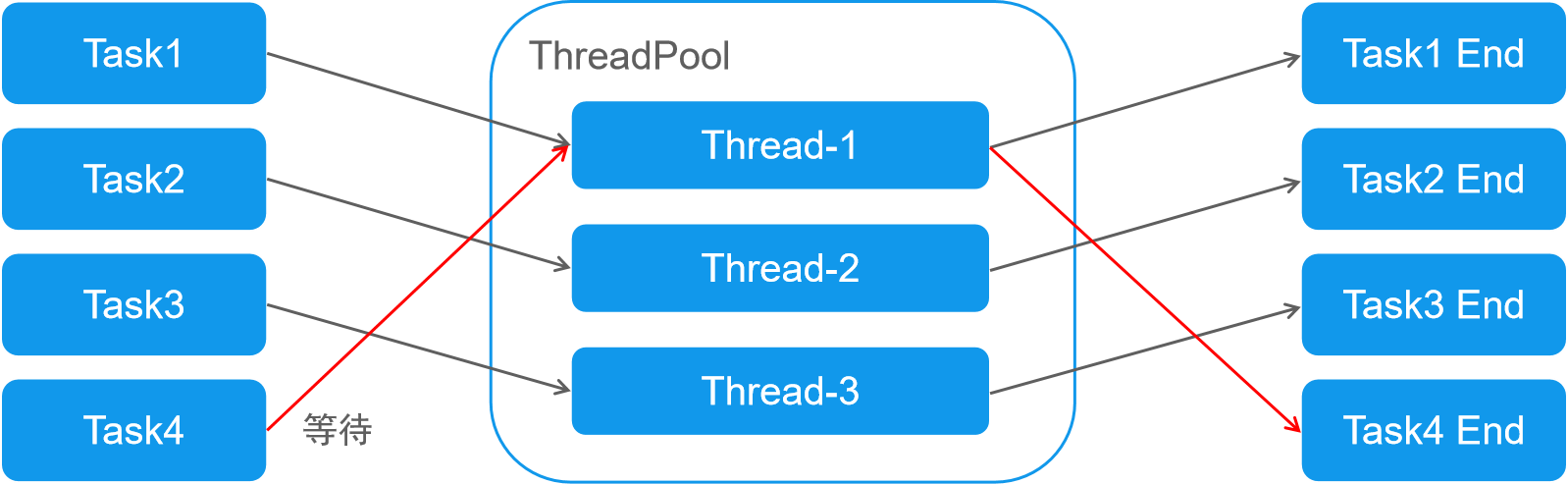
2.什么是线程池
- 帮助管理线程池,避免增加创建线程和销毁线程的开销
- 提高响应速度
- 重复利用
3.线程池的主要参数
- corePoolSize核心线程数
- maximumPoolSize最大线程数
- keepAliveTime 线程存活时间
- unit 时间单位
- workQueud 等待队列
- threadFactory 线程工厂
- handlr 拒绝策略
4.有哪几种常用线程池线程池
- newFixThreadPool(固定数目线程池)FixedThreadPool 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,
即适用执行长期的任务。 - newCacheTheadPool可缓存线程池 ,用于并发执行大量短期的小任务
- newScheduledThreadPool定时及周期线程池,周期性执行任务的场景,需要限制线程数量的场景
- newSingleThreadExecutor 单线程池 适用于串行执行任务的场景,一个任务一个任务地执行
5.线程池提交execute和submit的区别
- execute用于提交不需要返回值的。
threadsPool.execute(new Runnable()
{ @Override public void run() {
// TODO Auto-generated method stub }
});
- submit()用于需要返回值的任务,线程池会返回一个Future类型的对象,通过这个对象future对象可以判断任务是否执行成功,并且可以通过future的get方法来获取返回值。
Future<Object> future = executor.submit(harReturnValuetask);
try { Object s = future.get(); } catch (InterruptedException e) {
// 处理中断异常
} catch (ExecutionException e) {
// 处理无法执行任务异常
} finally {
// 关闭线程池 executor.shutdown();
}
6.线程池如何关闭
可以通过调用线程池的shutdown和shutdownNew方法来关闭线程池,它们的原理都是遍历线程池中的工作线程,然后逐步调用线程的interrupt方法来中断线程,所以无法响应中断的任务永远无法中止。
shutdown 和shutdownnow简单来说区别如下:
- shutdownNow()能立即停止线程池,正在跑的和正在等待的任务都停下了。这样做立即生效,但是风险也比较大。
- shutdown()只是关闭了提交通道,用submit()是无效的;而内部的任务该怎么跑还是怎么跑,跑完再彻底停止线程池
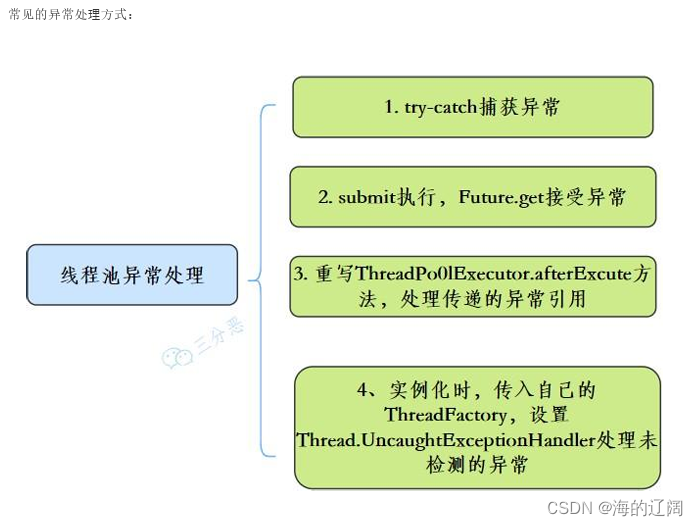
7.线程池的异常处理方式
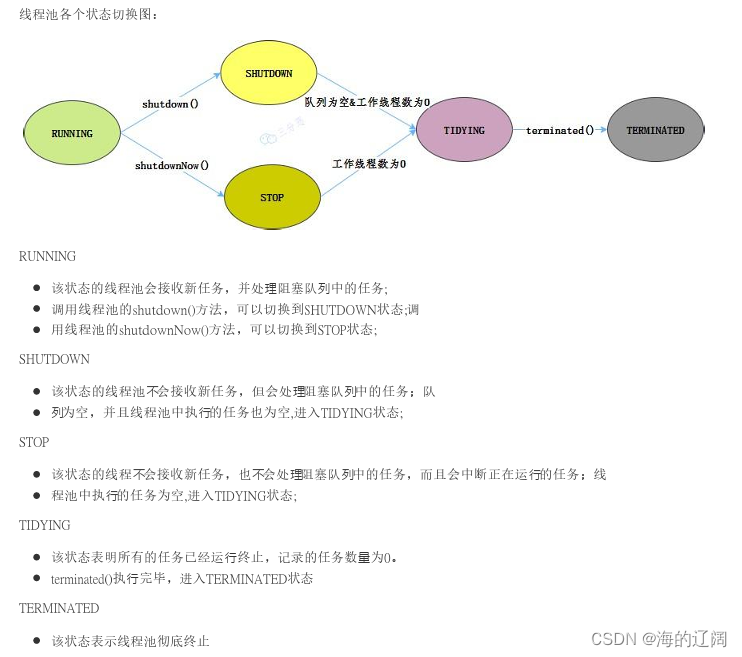
8.线程池的状态
线程池有RUNNING.SHUTDOWN,STOP,TIDYING,TERMNATED
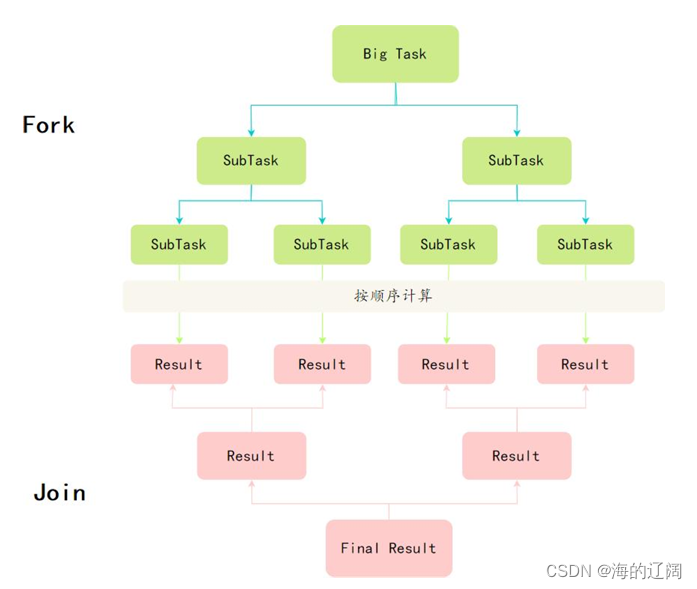
9.Fork/Join框架了解吗
Fork/Join框架是java7之后提供的一个用于并行的框架,是一个把大任务分解为若干小任务,最终汇总每个小任务结果后得到大任务的框架。
掌握Fork/Join需要理解两个点 分而治之和工作窃取算法
分而治之::将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相
互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解
工作窃取算法:大任务拆成了若干个小任务,把这些小任务放到不同的队列里,各自创建单独线程来执行队列里的任务。
那么问题来了,有的线程干活块,有的线程干活慢。干完活的线程不能让它空下来,得让它去帮没干完活的线程干活。
它去其它线程的队列里窃取一个任务来执行,这就是所谓的工作窃取。
工作窃取发生的时候,它们会访问同一个队列,为了减少窃取任务线程和被窃取任务线程之间的竞争,通常任务会使
用双端队列,被窃取任务线程永远从双端队列的头部拿,而窃取任务的线程永远从双端队列的尾部拿任务执行。

看一个Fork/Join框架应用的例子,计算1~n之间的和:1+2+3+…+n
- 设置一个分割阈值,任务大于阈值就拆分任务
- 任务有结果,所以需要继承RecursiveTask
package com.liu.ThreadPool;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
/**
* @description:
* @author: LCY
* @time: 2024-01-15 14:31
**/
public class ForkJoin extends RecursiveTask {
/**
* The main computation performed by this task.
*
* @return the result of the computation
*/
private static final int THRESHOLD = 16;//阈值
private int start;
private int end;
public ForkJoin(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Object compute() {
int sum = 0;
//如果任务足够小就计算任务
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
//如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
ForkJoin leftTask = new ForkJoin(start, middle);
ForkJoin rightTask = new ForkJoin(middle + 1, end);
//执行子任务
leftTask.fork();
// 看一个Fork/Join框架应用的例子,计算1~n之间的和:1+2+3+…+n
//设置一个分割阈值,任务大于阈值就拆分任务
// 任务有结果,所以需要继承RecursiveTask
rightTask.fork();//等待子任务执行完,并得到其结果
int leftResult = (int) leftTask.join();
int rightResult = (int) rightTask.join();//合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();//生成一个计算任务,负责计算
ForkJoin task = new ForkJoin(1, 100); //执行一个任务
Future<Integer> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
}
}
ForkJoinTask与一般Task的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如
果足够小就直接执行任务。如果比较大,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进compute
方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用
join方法会等待子任务执行完并得到其结果。
ps:喜欢请点点关注,你的赞是我前进的动力。







![[zabbix] zabbix监控其他](https://img-blog.csdnimg.cn/direct/5e2ec9e265984b4cb0c8c7bfc67b8cb1.png)