目录
一、pytorch环境搭建
1.创建新环境
2.激活环境
3.按照版本下载
二、labelimg的安装
三、数据处理部分
1、rename数据文件
2、数据加强
四、yolov4训练过程
五、租用GPU
一、pytorch环境搭建
在安装anaconda的前提下
在编译器pycharm的终端
1.创建新环境
conda create -n pytorch1.6_cuda10.2 python=3.7
//创从大python3.7pytorch1.6的编译环境
2.激活环境
conda activate pytorch1.6_cuda10.2
3.按照版本下载
conda install pytorch==1.6.0 torchvision==0.7.0 cpuonly -c pytorch
//只安装cpu版本的pytorch1.6
(这个地方我不确定你是不是能装gpu 先用cpu试试看训练效果)
txt中的文件包含现在需要的环境
设置一个requirements.txt
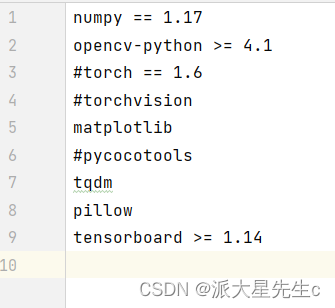
pip install -r requirements.txt -i ttps://pypi.doubanio.com/simple/
剩下的一些函数或者函数名调用过程中出现问题
直接用pycharm 设置部分的可用包直接pip

或者pip install scipy -i Simple Index
改红色地方的东西为 函数名比如yaml
二、labelimg的安装
1.win+R输入cmd打开终端
conda activate pytorch1.6_cuda10.2 (激活环境)
2、直接pip install labelimg
三、数据处理部分
1、rename数据文件
保证你的文件要是jpg形式或者png 若出现前后不一致 在python文件中无法调用
数据处理部分

改正文件路径
在之前文件是jpg 修改if后面的‘.jpg’
JPG文件 的时候 j=2进行修改 续在之前文件的后面
①打标记的时候用有序序列的图像 可以不标注图片 但是一定要用labelimg所有图片都过一便,否则会在voc_label处出现 images和annotation处无法对应。
②数据加强可以通过opencv简单处理 或者有旋转即可
按照 images和annatation分别放置文件夹 按照yolo操作步骤重新操作
2、数据加强
● 将数据增强模块嵌入model中
● 在Dataset数据集中进行数据增强
或者可以自定义函数来增强数据
如:调整图像饱和度
#visualize(image, saturated)
image = tf.expand_dims(images[3]*255, 0)
saturated = tf.image.adjust_saturation(image, 3)
plt.figure(figsize=(8, 8))
for i in range(9):
augmented_image = aug_img(saturated)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
对图像进行裁剪等
image = tf.expand_dims(images[3]*255, 0)
cropped = tf.image.central_crop(image, central_fraction=0.5)
plt.figure(figsize=(8, 8))
for i in range(9):
augmented_image = aug_img(cropped)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")四、yolov4训练过程
1.data数据当中

改文件中类的名称和数据
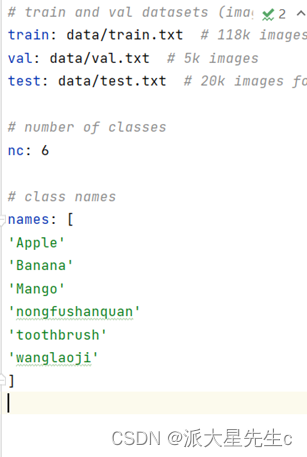
例如:
6类水果
Apple
Mango
Banana
nongfushanquan
toothbrush
wanglaoji

2.运行文件中的kmeans文件

出现上述问题 说明标签的大小统一 无法进行k聚类算法 调整k值为2或者3(正常为6)
运行结束后打开 kmeans.txt文件
复制结果

3.打开cfg文件中的yolo—tiny
快捷键ctrl+f 搜索yolo
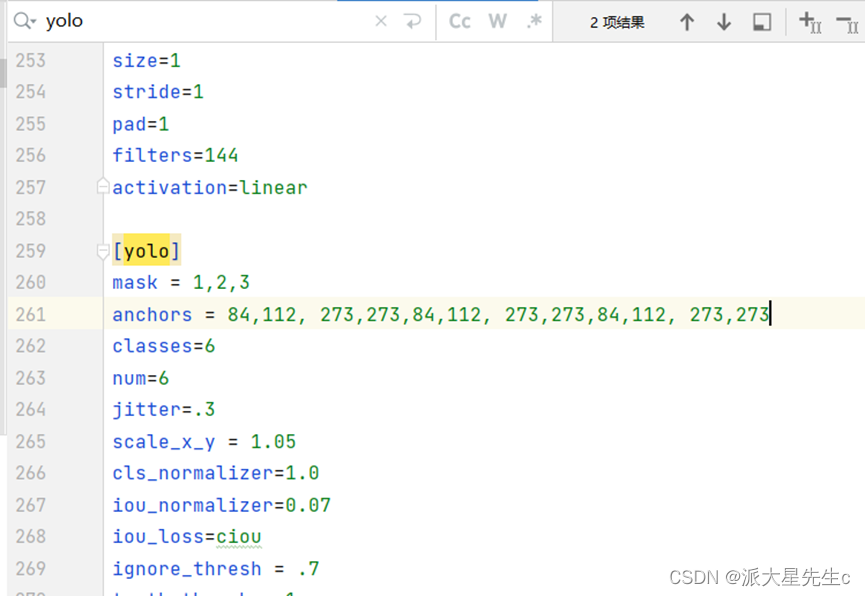
anchors = 84,112, 273,273,84,112, 273,273,84,112, 273,273
classes=6
上一层的filter (类别数+5)*3 先验框
filters=33
yolo有两处 均需要改
4.运行makeTxt.py
区分训练集和验证集
5.voc_label.py
其中修改classes为数据内容
并改正list_file.write当中的文件路径
运行voc_label.py文件
6.可以开始训练程序

对当前的数据集和训练要求来改正其中的default内容
注意在路径部分 可以用///来更改路径 或者在路径前面+r //
train.py
parser.add_argument('--cfg', type=str, default='cfg/csdarknet53s-BIFPN-spp-CA-GTSDB.cfg', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/GTSDB.yaml', help='data.yaml path')
五、租用GPU
如果自己没有训练条件的话,可以租用网上的gpu 教程如下
- 百度搜索gpushare
- 创建pytorch环境

3.点击文件 站点管理器登录

4.将压缩文件传输至hy-tmp文件夹中

先把requirements文件放进去 后面备用
5.

打开jupyterlab 终端
创建环境
conda create -n py python=3.7
conda activate py
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=10.2 -c pytorch
cd /hy-tmp #1s ##打开文件夹
pip install -r requirements.txt 安装所需要的文件
记得里面要加 pyyaml 和 scipy
解压:unzip 1.zip
打开文件夹:cd tea #1s
运行代码 python train.py