案例用到的测试数据请参考文章:
Flink自定义Source模拟数据流
原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048
概述
之前所介绍的流处理API,无论是基本的转换、聚合,还是更为复杂的窗口操作,其实都是基于DataStream进行转换的,所以可以统称为DataStream API。
在Flink更底层,我们可以不定义任何具体的算子(比如map,filter,或者window),而只是提炼出一个统一的“处理”(process)操作——它是所有转换算子的一个概括性的表达,可以自定义处理逻辑,所以这一层接口就被叫作“处理函数”(process function)。
基本处理函数(ProcessFunction)
处理函数的功能和使用
我们之前学习的转换算子,一般只是针对某种具体操作来定义的,能够拿到的信息比较有限。如果我们想要访问事件的时间戳,或者当前的水位线信息,都是完全做不到的。跟时间相关的操作,目前我们只会用窗口来处理。而在很多应用需求中,要求我们对时间有更精细的控制,需要能够获取水位线,甚至要“把控时间”、定义什么时候做什么事,这就不是基本的时间窗口能够实现的了。
这时就需要使用底层的处理函数。处理函数提供了一个“定时服务”(TimerService),我们可以通过它访问流中的事件(event)、时间戳(timestamp)、水位线(watermark),甚至可以注册“定时事件”。而且处理函数继承了AbstractRichFunction抽象类,所以拥有富函数类的所有特性,同样可以访问状态(state)和其他运行时信息。此外,处理函数还可以直接将数据输出到侧输出流(side output)中。所以,处理函数是最为灵活的处理方法,可以实现各种自定义的业务逻辑。
处理函数的使用与基本的转换操作类似,只需要直接基于DataStream调用.process()方法就可以了。方法需要传入一个ProcessFunction作为参数,用来定义处理逻辑。
stream.process(new MyProcessFunction())
这里ProcessFunction不是接口,而是一个抽象类,继承了AbstractRichFunction;MyProcessFunction是它的一个具体实现。所以所有的处理函数,都是富函数(RichFunction),富函数可以调用的东西这里同样都可以调用。
ProcessFunction解析
在源码中我们可以看到,抽象类ProcessFunction继承了AbstractRichFunction,有两个泛型类型参数:I表示Input,也就是输入的数据类型;O表示Output,也就是处理完成之后输出的数据类型。
内部单独定义了两个方法:一个是必须要实现的抽象方法.processElement();另一个是非抽象方法.onTimer()。
public abstract class ProcessFunction<I, O> extends AbstractRichFunction {
...
public abstract void processElement(I value, Context ctx, Collector<O> out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out) throws Exception {}
...
}
抽象方法.processElement()
用于“处理元素”,定义了处理的核心逻辑。这个方法对于流中的每个元素都会调用一次,参数包括三个:输入数据值value,上下文ctx,以及“收集器”(Collector)out。方法没有返回值,处理之后的输出数据是通过收集器out来定义的。
value:当前流中的输入元素,也就是正在处理的数据,类型与流中数据类型一致。
ctx:类型是ProcessFunction中定义的内部抽象类Context,表示当前运行的上下文,可以获取到当前的时间戳,并提供了用于查询时间和注册定时器的“定时服务”(TimerService),以及可以将数据发送到“侧输出流”(side output)的方法.output()。
out:“收集器”(类型为Collector),用于返回输出数据。使用方式与flatMap算子中的收集器完全一样,直接调用out.collect()方法就可以向下游发出一个数据。这个方法可以多次调用,也可以不调用。
通过几个参数的分析不难发现,ProcessFunction可以轻松实现flatMap、map、filter这样的基本转换功能;而通过富函数提供的获取上下文方法.getRuntimeContext(),也可以自定义状态(state)进行处理,这也就能实现聚合操作的功能了。
非抽象方法.onTimer()
这个方法只有在注册好的定时器触发的时候才会调用,而定时器是通过“定时服务”TimerService来注册的。打个比方,注册定时器(timer)就是设了一个闹钟,到了设定时间就会响;而.onTimer()中定义的,就是闹钟响的时候要做的事。所以它本质上是一个基于时间的“回调”(callback)方法,通过时间的进展来触发;在事件时间语义下就是由水位线(watermark)来触发了。
定时方法.onTimer()也有三个参数:时间戳(timestamp),上下文(ctx),以及收集器(out)。这里的timestamp是指设定好的触发时间,事件时间语义下当然就是水位线了。另外这里同样有上下文和收集器,所以也可以调用定时服务(TimerService),以及任意输出处理之后的数据。
既然有.onTimer()方法做定时触发,我们用ProcessFunction也可以自定义数据按照时间分组、定时触发计算输出结果;这其实就实现了窗口(window)的功能。所以说ProcessFunction其实可以实现一切功能。
注意:在Flink中,只有“按键分区流”KeyedStream才支持设置定时器的操作。
处理函数的分类
我们知道,DataStream在调用一些转换方法之后,有可能生成新的流类型;例如调用.keyBy()之后得到KeyedStream,进而再调用.window()之后得到WindowedStream。对于不同类型的流,其实都可以直接调用.process()方法进行自定义处理,这时传入的参数就都叫作处理函数。当然,它们尽管本质相同,都是可以访问状态和时间信息的底层API,可彼此之间也会有所差异。
Flink提供了8个不同的处理函数:
(1)ProcessFunction
最基本的处理函数,基于DataStream直接调用.process()时作为参数传入。
(2)KeyedProcessFunction
对流按键分区后的处理函数,基于KeyedStream调用.process()时作为参数传入。要想使用定时器,比如基于KeyedStream。
(3)ProcessWindowFunction
开窗之后的处理函数,也是全窗口函数的代表。基于WindowedStream调用.process()时作为参数传入。
(4)ProcessAllWindowFunction
同样是开窗之后的处理函数,基于AllWindowedStream调用.process()时作为参数传入。
(5)CoProcessFunction
合并(connect)两条流之后的处理函数,基于ConnectedStreams调用.process()时作为参数传入。
(6)ProcessJoinFunction
间隔连接(interval join)两条流之后的处理函数,基于IntervalJoined调用.process()时作为参数传入。
(7)BroadcastProcessFunction
广播连接流处理函数,基于BroadcastConnectedStream调用.process()时作为参数传入。这里的“广播连接流”BroadcastConnectedStream,是一个未keyBy的普通DataStream与一个广播流(BroadcastStream)做连接(conncet)之后的产物。
(8)KeyedBroadcastProcessFunction
按键分区的广播连接流处理函数,同样是基于BroadcastConnectedStream调用.process()时作为参数传入。与BroadcastProcessFunction不同的是,这时的广播连接流,是一个KeyedStream与广播流(BroadcastStream)做连接之后的产物。
按键分区处理函数(KeyedProcessFunction)
在上节中提到,只有在KeyedStream中才支持使用TimerService设置定时器的操作。所以一般情况下,我们都是先做了keyBy分区之后,再去定义处理操作;代码中更加常见的处理函数是KeyedProcessFunction。
定时器(Timer)和定时服务(TimerService)
在.onTimer()方法中可以实现定时处理的逻辑,而它能触发的前提,就是之前曾经注册过定时器、并且现在已经到了触发时间。注册定时器的功能,是通过上下文中提供的“定时服务”来实现的。
定时服务与当前运行的环境有关。前面已经介绍过,ProcessFunction的上下文(Context)中提供了.timerService()方法,可以直接返回一个TimerService对象。TimerService是Flink关于时间和定时器的基础服务接口,包含以下六个方法:
// 获取当前的处理时间
long currentProcessingTime();
// 获取当前的水位线(事件时间)
long currentWatermark();
// 注册处理时间定时器,当处理时间超过time时触发
void registerProcessingTimeTimer(long time);
// 注册事件时间定时器,当水位线超过time时触发
void registerEventTimeTimer(long time);
// 删除触发时间为time的处理时间定时器
void deleteProcessingTimeTimer(long time);
// 删除触发时间为time的处理时间定时器
void deleteEventTimeTimer(long time);
六个方法可以分成两大类:基于处理时间和基于事件时间。而对应的操作主要有三个:获取当前时间,注册定时器,以及删除定时器。需要注意,尽管处理函数中都可以直接访问TimerService,不过只有基于KeyedStream的处理函数,才能去调用注册和删除定时器的方法;未作按键分区的DataStream不支持定时器操作,只能获取当前时间。
TimerService会以键(key)和时间戳为标准,对定时器进行去重;也就是说对于每个key和时间戳,最多只有一个定时器,如果注册了多次,onTimer()方法也将只被调用一次。
KeyedProcessFunction案例
基于keyBy之后的KeyedStream,直接调用.process()方法,这时需要传入的参数就是KeyedProcessFunction的实现类。
stream.keyBy( t -> t.f0 )
.process(new MyKeyedProcessFunction())
类似地,KeyedProcessFunction也是继承自AbstractRichFunction的一个抽象类,与ProcessFunction的定义几乎完全一样,区别只是在于类型参数多了一个K,这是当前按键分区的key的类型。同样地,我们必须实现一个.processElement()抽象方法,用来处理流中的每一个数据;另外还有一个非抽象方法.onTimer(),用来定义定时器触发时的回调操作。
import com.zxl.bean.Orders;
import org.apache.flink.streaming.api.TimerService;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
// TODO: 2024/1/15 参数1.key的数据类型,输入格式,输出格式
public class MyKeyedProcessFunction extends KeyedProcessFunction<Integer, Orders, String> {
private Integer sum=0;
@Override
public void processElement(Orders orders, KeyedProcessFunction<Integer, Orders, String>.Context ctx, Collector<String> collector) throws Exception {
sum+=orders.getOrder_amount();
//获取当前数据的key
Integer currentKey = ctx.getCurrentKey();
// TODO 1.定时器注册
TimerService timerService = ctx.timerService();
// TODO: 2024/1/15 事件时间的案例
// TODO: 2024/1/15 数据中提取出来的事件时间
Long currentEventTime = ctx.timestamp();
// TODO: 2024/1/15 注册事件时间定时器,当水位线超过time时触发
timerService.registerEventTimeTimer(currentEventTime + 5000L);
// TODO: 2024/1/15 删除以事件事件触发时间的定时器
timerService.deleteEventTimeTimer(currentEventTime);
//System.out.println("当前key=" + currentKey + ",当前时间=" + currentEventTime + ",注册了一个5s的定时器");
/*// TODO: 2024/1/15 2.处理时间的案例
// TODO: 2024/1/15 获取当前处理时间
long currentTs = timerService.currentProcessingTime();
// TODO: 2024/1/15 注册处理时间定时器,当处理时间超过time时触发
timerService.registerProcessingTimeTimer(currentTs + 5000);
// TODO: 2024/1/15 删除以处理时间为触发时间的定时器
//deleteProcessingTimeTimer(currentWatermark);
System.out.println("当前key=" + currentKey + ",当前时间=" + currentTs + ",注册了一个5s后的定时器");*/
/*// TODO: 2024/1/15 3、获取 process的 当前watermark
long currentWatermark = timerService.currentWatermark();
System.out.println("当前数据=" + orders + ",当前watermark=" + currentWatermark);*/
}
// TODO: 2024/1/15 触发执行器,编写写触发后的逻辑运行
@Override
public void onTimer(long timestamp, KeyedProcessFunction<Integer, Orders, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
super.onTimer(timestamp, ctx, out);
// TODO: 2024/1/15 触发是执行
Integer currentKey = ctx.getCurrentKey();
out.collect(sum.toString());
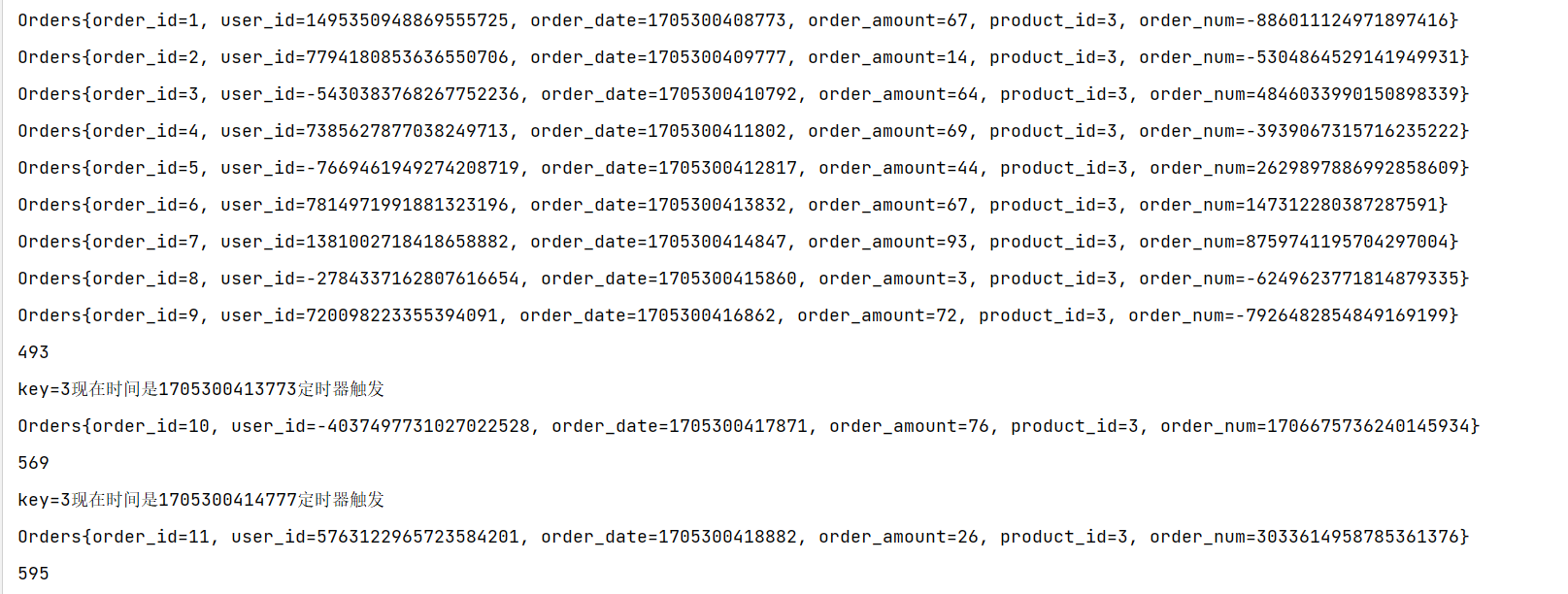
System.out.println("key=" + currentKey + "现在时间是" + timestamp + "定时器触发");
}
}
import com.zxl.Functions.MyKeyedProcessFunction;
import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
public class KeyedProcessTimerDemo {
public static void main(String[] args) throws Exception {
// TODO: 2024/1/15 创建Flink流处理执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO: 2024/1/15 设置并行度为1
environment.setParallelism(1);
// TODO: 2024/1/7 定义时间语义
environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// TODO: 2024/1/6 订单数据
DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());
// TODO: 2024/1/15 设置水位线
WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy
// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值
.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))
// TODO: 2024/1/15 指定水位线中对应的时间字段
.withTimestampAssigner((orders, l) -> orders.getOrder_date())
// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力
.withIdleness(Duration.ofSeconds(3));
// TODO: 2024/1/15 添加水位线
SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);
// TODO: 2024/1/15 设置分区key
KeyedStream<Orders, Integer> keyedStream = operator.keyBy(Orders::getProduct_id);
// TODO: 2024/1/15 注意只有keyedstream流能重写KeyedProcessFunction方法
SingleOutputStreamOperator<String> process = keyedStream.process(new MyKeyedProcessFunction());
// TODO: 2024/1/15 打印数据
ordersDataStreamSource.print();
process.print();
// TODO: 2024/1/15 执行程序
environment.execute();
}
}
窗口处理函数
除了KeyedProcessFunction,另外一大类常用的处理函数,就是基于窗口的ProcessWindowFunction和ProcessAllWindowFunction了。在第六章窗口函数的介绍中,我们之前已经简单地使用过窗口处理函数了。
窗口处理函数的使用
进行窗口计算,我们可以直接调用现成的简单聚合方法(sum/max/min),也可以通过调用.reduce()或.aggregate()来自定义一般的增量聚合函数(ReduceFunction/AggregateFucntion);而对于更加复杂、需要窗口信息和额外状态的一些场景,我们还可以直接使用全窗口函数、把数据全部收集保存在窗口内,等到触发窗口计算时再统一处理。窗口处理函数就是一种典型的全窗口函数。
窗口处理函数ProcessWindowFunction的使用与其他窗口函数类似,也是基于WindowedStream直接调用方法就可以,只不过这时调用的是.process()。
stream.keyBy( t -> t.f0 )
.window( TumblingEventTimeWindows.of(Time.seconds(10)) )
.process(new MyProcessWindowFunction())
ProcessWindowFunction解析
ProcessWindowFunction既是处理函数又是全窗口函数。从名字上也可以推测出,它的本质似乎更倾向于“窗口函数”一些。事实上它的用法也确实跟其他处理函数有很大不同。我们可以从源码中的定义看到这一点:
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> extends AbstractRichFunction {
...
public abstract void process(
KEY key, Context context, Iterable<IN> elements, Collector<OUT> out) throws Exception;
public void clear(Context context) throws Exception {}
public abstract class Context implements java.io.Serializable {...}
}
ProcessWindowFunction依然是一个继承了AbstractRichFunction的抽象类,它有四个类型参数:
IN:input,数据流中窗口任务的输入数据类型。
OUT:output,窗口任务进行计算之后的输出数据类型。
KEY:数据中键key的类型。
W:窗口的类型,是Window的子类型。一般情况下我们定义时间窗口,W就是TimeWindow。
ProcessWindowFunction里面处理数据的核心方法.process()。方法包含四个参数。
key:窗口做统计计算基于的键,也就是之前keyBy用来分区的字段。
context:当前窗口进行计算的上下文,它的类型就是ProcessWindowFunction内部定义的抽象类Context。
elements:窗口收集到用来计算的所有数据,这是一个可迭代的集合类型。
out:用来发送数据输出计算结果的收集器,类型为Collector。
可以明显看出,这里的参数不再是一个输入数据,而是窗口中所有数据的集合。而上下文context所包含的内容也跟其他处理函数有所差别:
public abstract class Context implements java.io.Serializable {
public abstract W window();
public abstract long currentProcessingTime();
public abstract long currentWatermark();
public abstract KeyedStateStore windowState();
public abstract KeyedStateStore globalState();
public abstract <X> void output(OutputTag<X> outputTag, X value);
}
除了可以通过.output()方法定义侧输出流不变外,其他部分都有所变化。这里不再持有TimerService对象,只能通过currentProcessingTime()和currentWatermark()来获取当前时间,所以失去了设置定时器的功能;另外由于当前不是只处理一个数据,所以也不再提供.timestamp()方法。与此同时,也增加了一些获取其他信息的方法:比如可以通过.window()直接获取到当前的窗口对象,也可以通过.windowState()和.globalState()获取到当前自定义的窗口状态和全局状态。注意这里的“窗口状态”是自定义的,不包括窗口本身已经有的状态,针对当前key、当前窗口有效;而“全局状态”同样是自定义的状态,针对当前key的所有窗口有效。
所以我们会发现,ProcessWindowFunction中除了.process()方法外,并没有.onTimer()方法,而是多出了一个.clear()方法。从名字就可以看出,这主要是方便我们进行窗口的清理工作。如果我们自定义了窗口状态,那么必须在.clear()方法中进行显式地清除,避免内存溢出。
至于另一种窗口处理函数ProcessAllWindowFunction,它的用法非常类似。区别在于它基于的是AllWindowedStream,相当于对没有keyBy的数据流直接开窗并调用.process()方法:
stream.windowAll( TumblingEventTimeWindows.of(Time.seconds(10)) )
.process(new MyProcessAllWindowFunction())
应用案例——Top N
案例需求:实时统计一段时间内的出现次数最多的水位。例如,统计最近10秒钟内出现次数最多的两个水位,并且每5秒钟更新一次。我们知道,这可以用一个滑动窗口来实现。于是就需要开滑动窗口收集传感器的数据,按照不同的水位进行统计,而后汇总排序并最终输出前两名。这其实就是著名的“Top N”问题。
案例需求:实时统计一段时间内的出现次数最多的水位。例如,统计最近10秒钟内出现次数最多的两个水位,并且每5秒钟更新一次。我们知道,这可以用一个滑动窗口来实现。于是就需要开滑动窗口收集传感器的数据,按照不同的水位进行统计,而后汇总排序并最终输出前两名。这其实就是著名的“Top N”问题。
使用ProcessAllWindowFunction
思路一:一种最简单的想法是,我们干脆不区分不同水位,而是将所有访问数据都收集起来,统一进行统计计算。所以可以不做keyBy,直接基于DataStream开窗,然后使用全窗口函数ProcessAllWindowFunction来进行处理。
在窗口中可以用一个HashMap来保存每个水位的出现次数,只要遍历窗口中的所有数据,自然就能得到所有水位的出现次数。最后把HashMap转成一个列表ArrayList,然后进行排序、取出前两名输出就可以了。
代码具体实现如下:
import com.zxl.bean.Orders;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.windowing.ProcessAllWindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.*;
public class MyTopNPAWF extends ProcessAllWindowFunction<Orders, String, TimeWindow> {
@Override
public void process(ProcessAllWindowFunction<Orders, String, TimeWindow>.Context context, Iterable<Orders> elements, Collector<String> out) throws Exception {
// 定义一个hashmap用来存,key=商品ID,value=count值
Map<Integer, Integer> vcCountMap = new HashMap<>();
// 1.遍历数据, 统计交易额大于50出现的次数
for (Orders element : elements) {
Integer vc = element.getOrder_amount();
Integer productId = element.getProduct_id();
if (vc > 50) {
// 1.1 key存在,不是这个key的第一条数据,直接累加
if (vcCountMap.containsKey(productId)) {
vcCountMap.put(productId, vcCountMap.get(productId) + 1);
} else {
vcCountMap.put(productId, 1);
}
} else {
// 1.2 key不存在,初始化
vcCountMap.put(productId, 1);
}
}
// 2.对 count值进行排序: 利用List来实现排序
List<Tuple2<Integer, Integer>> datas = new ArrayList<>();
for (Integer vc : vcCountMap.keySet()) {
datas.add(Tuple2.of(vc, vcCountMap.get(vc)));
}
// 对List进行排序,根据count值 降序
datas.sort(new Comparator<Tuple2<Integer, Integer>>() {
@Override
public int compare(Tuple2<Integer, Integer> o1, Tuple2<Integer, Integer> o2) {
// 降序, 后 减 前
return o2.f1 - o1.f1;
}
});
// 3.取出 count最大的2个 vc
StringBuilder outStr = new StringBuilder();
outStr.append("================================\n");
// 遍历 排序后的 List,取出前2个, 考虑可能List不够2个的情况 ==》 List中元素的个数 和 2 取最小值
for (int i = 0; i < Math.min(2, datas.size()); i++) {
Tuple2<Integer, Integer> vcCount = datas.get(i);
outStr.append("Top" + (i + 1) + "\n");
outStr.append("vc=" + vcCount.f0 + "\n");
outStr.append("count=" + vcCount.f1 + "\n");
outStr.append("窗口开始时间=" + DateFormatUtils.format(context.window().getStart(), "yyyy-MM-dd HH:mm:ss.SSS") + "\n" + "窗口结束时间=" + DateFormatUtils.format(context.window().getEnd(), "yyyy-MM-dd HH:mm:ss.SSS") + "\n");
outStr.append("================================\n");
}
out.collect(outStr.toString());
}
}
import com.zxl.Functions.MyTopNPAWF;
import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
public class ProcessAllWindowTopNDemo {
public static void main(String[] args) throws Exception {
// TODO: 2024/1/15 创建Flink流处理执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO: 2024/1/15 设置并行度为1
environment.setParallelism(1);
// TODO: 2024/1/7 定义时间语义
environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// TODO: 2024/1/6 订单数据
DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());
// TODO: 2024/1/15 设置水位线
WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy
// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值
.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))
// TODO: 2024/1/15 指定水位线中对应的时间字段
.withTimestampAssigner((orders, l) -> orders.getOrder_date())
// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力
.withIdleness(Duration.ofSeconds(3));
// TODO: 2024/1/15 添加水位线
SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);
// TODO: 2024/1/15 设置窗口
SingleOutputStreamOperator<String> process = operator.windowAll(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)))
.process(new MyTopNPAWF());
// TODO: 2024/1/15 打印数据
ordersDataStreamSource.print();
process.print();
// TODO: 2024/1/15 执行程序
environment.execute();
}
}

使用KeyedProcessFunction
思路二:在上一小节的实现过程中,我们没有进行按键分区,直接将所有数据放在一个分区上进行了开窗操作。这相当于将并行度强行设置为1,在实际应用中是要尽量避免的,所以Flink官方也并不推荐使用AllWindowedStream进行处理。另外,我们在全窗口函数中定义了HashMap来统计vc的出现次数,计算过程是要先收集齐所有数据、然后再逐一遍历更新HashMap,这显然不够高效。
基于这样的想法,我们可以从两个方面去做优化:一是对数据进行按键分区,分别统计vc的出现次数;二是进行增量聚合,得到结果最后再做排序输出。所以,我们可以使用增量聚合函数AggregateFunction进行浏览量的统计,然后结合ProcessWindowFunction排序输出来实现Top N的需求。
具体实现可以分成两步:先对每个vc统计出现次数,然后再将统计结果收集起来,排序输出最终结果。由于最后的排序还是基于每个时间窗口的,输出的统计结果中要包含窗口信息,我们可以输出包含了vc、出现次数(count)以及窗口结束时间的Tuple3。之后先按窗口结束时间分区,然后用KeyedProcessFunction来实现。
用KeyedProcessFunction来收集数据做排序,这时面对的是窗口聚合之后的数据流,而窗口已经不存在了;我们需要确保能够收集齐所有数据,所以应该在窗口结束时间基础上再“多等一会儿”。具体实现上,可以采用一个延迟触发的事件时间定时器。基于窗口的结束时间来设定延迟,其实并不需要等太久——因为我们是靠水位线的推进来触发定时器,而水位线的含义就是“之前的数据都到齐了”。所以我们只需要设置1毫秒的延迟,就一定可以保证这一点。
而在等待过程中,之前已经到达的数据应该缓存起来,我们这里用一个自定义的HashMap来进行存储,key为窗口的标记,value为List。之后每来一条数据,就把它添加到当前的HashMap中,并注册一个触发时间为窗口结束时间加1毫秒(windowEnd + 1)的定时器。待到水位线到达这个时间,定时器触发,我们可以保证当前窗口所有vc的统计结果Tuple3都到齐了;于是从HashMap中取出进行排序输出。
具体代码实现如下:
package com.zxl.Functions;
import com.zxl.bean.Orders;
import org.apache.flink.api.common.functions.AggregateFunction;
// TODO: 2024/1/16 三个参数:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。
public class VcCountAgg implements AggregateFunction<Orders, Integer, Integer> {
// TODO: 2024/1/16 创建一个新的累加器,开始一个新的聚合。累加器是正在运行的聚合的状态。
@Override
public Integer createAccumulator() {
return 0;
}
// TODO: 2024/1/16 将给定的输入添加到给定的累加器,并返回新的累加器值。
@Override
public Integer add(Orders orders, Integer o) {
return orders.getOrder_amount() + o;
}
// TODO: 2024/1/16 从累加器获取聚合结果。
@Override
public Integer getResult(Integer o) {
return o;
}
// TODO: 2024/1/16 合并两个累加器,返回合并后的累加器的状态。
@Override
public Integer merge(Integer o, Integer acc1) {
return o + acc1;
}
}
package com.zxl.Functions;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
// TODO: 2024/1/16 四个参数:输入类型(IN)、输出类型(OUT)、key的类型、窗口
public class WindowResult extends ProcessWindowFunction<Integer, Tuple3<Integer, Integer, Long>, Integer, TimeWindow> {
@Override
public void process(Integer key, ProcessWindowFunction<Integer, Tuple3<Integer, Integer, Long>, Integer, TimeWindow>.Context context, Iterable<Integer> elements, Collector<Tuple3<Integer, Integer, Long>> collector) throws Exception {
// 迭代器里面只有一条数据,next一次即可
Integer count = elements.iterator().next();
long windowEnd = context.window().getEnd();
collector.collect(Tuple3.of(key, count, windowEnd));
}
}
package com.zxl.Functions;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.util.*;
public class TopNDemo extends KeyedProcessFunction<Long, Tuple3<Integer, Integer, Long>, String> {
// 存不同窗口的 统计结果,key=windowEnd,value=list数据
Map<Long, List<Tuple3<Integer, Integer, Long>>> dataListMap = new HashMap<>();
@Override
public void processElement(Tuple3<Integer, Integer, Long> value, Context ctx, Collector<String> out) throws Exception {
// 进入这个方法,只是一条数据,要排序,得到齐才行 ===》 存起来,不同窗口分开存
System.out.println(value);
// 1. 存到HashMap中
Long windowEnd = value.f2;
// System.out.println(dataListMap.containsKey(windowEnd));
if (dataListMap.containsKey(windowEnd)) {
// 1.1 包含vc,不是该vc的第一条,直接添加到List中
List<Tuple3<Integer, Integer, Long>> dataList = dataListMap.get(windowEnd);
dataList.add(value);
dataListMap.put(windowEnd,dataList);
} else {
// 1.1 不包含vc,是该vc的第一条,需要初始化list
List<Tuple3<Integer, Integer, Long>> dataList = new ArrayList<>();
dataList.add(value);
// System.out.println(dataList);
dataListMap.put(windowEnd, dataList);
}
// 2. 注册一个定时器, windowEnd+1ms即可(
// 同一个窗口范围,应该同时输出,只不过是一条一条调用processElement方法,只需要延迟10ms即可
ctx.timerService().registerEventTimeTimer(windowEnd + 1);
System.out.println(dataListMap);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
super.onTimer(timestamp, ctx, out);
// 定时器触发,同一个窗口范围的计算结果攒齐了,开始 排序、取TopN
Long windowEnd = ctx.getCurrentKey();
// 1. 排序
List<Tuple3<Integer, Integer, Long>> dataList = dataListMap.get(windowEnd);
dataList.sort(new Comparator<Tuple3<Integer, Integer, Long>>() {
@Override
public int compare(Tuple3<Integer, Integer, Long> o1, Tuple3<Integer, Integer, Long> o2) {
// 降序, 后 减 前
return o2.f1 - o1.f1;
}
});
// 2. 取TopN
StringBuilder outStr = new StringBuilder();
outStr.append("================================\n");
for (int i = 0; i < dataList.size(); i++) {
Tuple3<Integer, Integer, Long> vcCount = dataList.get(i);
System.out.println("vcCount" + vcCount);
outStr.append("Top" + (i + 1) + "\n");
outStr.append("vc=" + vcCount.f0 + "\n");
outStr.append("count=" + vcCount.f1 + "\n");
outStr.append("窗口结束时间=" + vcCount.f2 + "\n");
outStr.append("================================\n");
}
out.collect(outStr.toString());
}
}
package com.zxl.ProcessFunction;
import com.zxl.Functions.TopNDemo;
import com.zxl.Functions.VcCountAgg;
import com.zxl.Functions.WindowResult;
import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import java.time.Duration;
public class KeyedProcessFunctionTopNDemo {
public static void main(String[] args) throws Exception {
// TODO: 2024/1/15 创建Flink流处理执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO: 2024/1/15 设置并行度为1
environment.setParallelism(1);
// TODO: 2024/1/7 定义时间语义
environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// TODO: 2024/1/6 订单数据
DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());
// TODO: 2024/1/15 设置水位线
WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy
// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值
.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))
// TODO: 2024/1/15 指定水位线中对应的时间字段
.withTimestampAssigner((orders, l) -> orders.getOrder_date())
// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力
.withIdleness(Duration.ofSeconds(3));
// TODO: 2024/1/15 添加水位线
SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);
WindowedStream<Orders, Integer, TimeWindow> windowedStream = operator.keyBy(orders -> orders.getProduct_id())
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(2)));
SingleOutputStreamOperator<Tuple3<Integer, Integer, Long>> streamOperator = windowedStream.aggregate(new VcCountAgg(),new WindowResult());
SingleOutputStreamOperator<String> process = streamOperator.keyBy(m -> m.f2)
.process(new TopNDemo());
process.print();
environment.execute();
}
}
侧输出流(Side Output)
处理函数还有另外一个特有功能,就是将自定义的数据放入“侧输出流”(side output)输出。这个概念我们并不陌生,之前在讲到窗口处理迟到数据时,最后一招就是输出到侧输出流。而这种处理方式的本质,其实就是处理函数的侧输出流功能。
我们之前讲到的绝大多数转换算子,输出的都是单一流,流里的数据类型只能有一种。而侧输出流可以认为是“主流”上分叉出的“支流”,所以可以由一条流产生出多条流,而且这些流中的数据类型还可以不一样。利用这个功能可以很容易地实现“分流”操作。
具体应用时,只要在处理函数的.processElement()或者.onTimer()方法中,调用上下文的.output()方法就可以了。
DataStream<Integer> stream = env.fromSource(...);
OutputTag<String> outputTag = new OutputTag<String>("side-output") {};
SingleOutputStreamOperator<Long> longStream = stream.process(new ProcessFunction<Integer, Long>() {
@Override
public void processElement( Integer value, Context ctx, Collector<Integer> out) throws Exception {
// 转换成Long,输出到主流中
out.collect(Long.valueOf(value));
// 转换成String,输出到侧输出流中
ctx.output(outputTag, "side-output: " + String.valueOf(value));
}
});
这里output()方法需要传入两个参数,第一个是一个“输出标签”OutputTag,用来标识侧输出流,一般会在外部统一声明;第二个就是要输出的数据。
我们可以在外部先将OutputTag声明出来:
OutputTag<String> outputTag = new OutputTag<String>("side-output") {};
如果想要获取这个侧输出流,可以基于处理之后的DataStream直接调用.getSideOutput()方法,传入对应的OutputTag,这个方式与窗口API中获取侧输出流是完全一样的。
DataStream<String> stringStream = longStream.getSideOutput(outputTag);
案例需求:对每个订单,订单金额超过60提醒
代码如下:
package com.zxl.ProcessFunction;
import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
public class SideOutputDemo {
public static void main(String[] args) throws Exception {
// TODO: 2024/1/15 创建Flink流处理执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO: 2024/1/15 设置并行度为1
environment.setParallelism(1);
// TODO: 2024/1/7 定义时间语义
environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// TODO: 2024/1/6 订单数据
DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());
// TODO: 2024/1/15 设置水位线
WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy
// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值
.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))
// TODO: 2024/1/15 指定水位线中对应的时间字段
.withTimestampAssigner((orders, l) -> orders.getOrder_date())
// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力
.withIdleness(Duration.ofSeconds(3));
// TODO: 2024/1/15 添加水位线
SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);
// TODO: 2024/1/16 侧输出流标签
OutputTag<String> warnTag = new OutputTag<>("warn", Types.STRING);
SingleOutputStreamOperator<String> process = operator.keyBy(orders -> orders.getProduct_id())
.process(new KeyedProcessFunction<Integer, Orders, String>() {
@Override
public void processElement(Orders orders, KeyedProcessFunction<Integer, Orders, String>.Context context, Collector<String> collector) throws Exception {
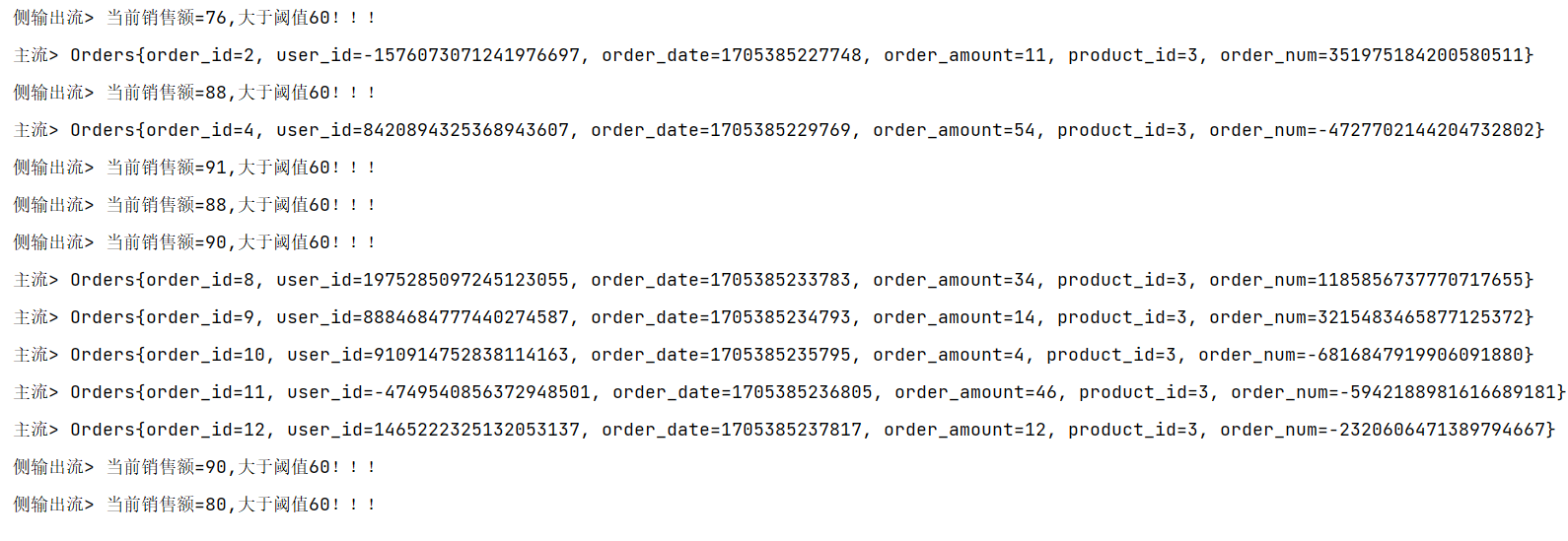
if (orders.getOrder_amount() > 60) {
context.output(warnTag, "当前销售额=" + orders.getOrder_amount() + ",大于阈值60!!!");
} else {
collector.collect(orders.toString());
}
}
});
process.getSideOutput(warnTag).print("侧输出流");
process.print("主流");
environment.execute();
}
}



![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://img-blog.csdnimg.cn/direct/a736d872c6fc410b9c31bb70c1d3f03b.png)

![[足式机器人]Part2 Dr. CAN学习笔记-Advanced控制理论 Ch04-17 串讲](https://img-blog.csdnimg.cn/direct/d133933db11248f5a59dae0d309219fa.png#pic_center)