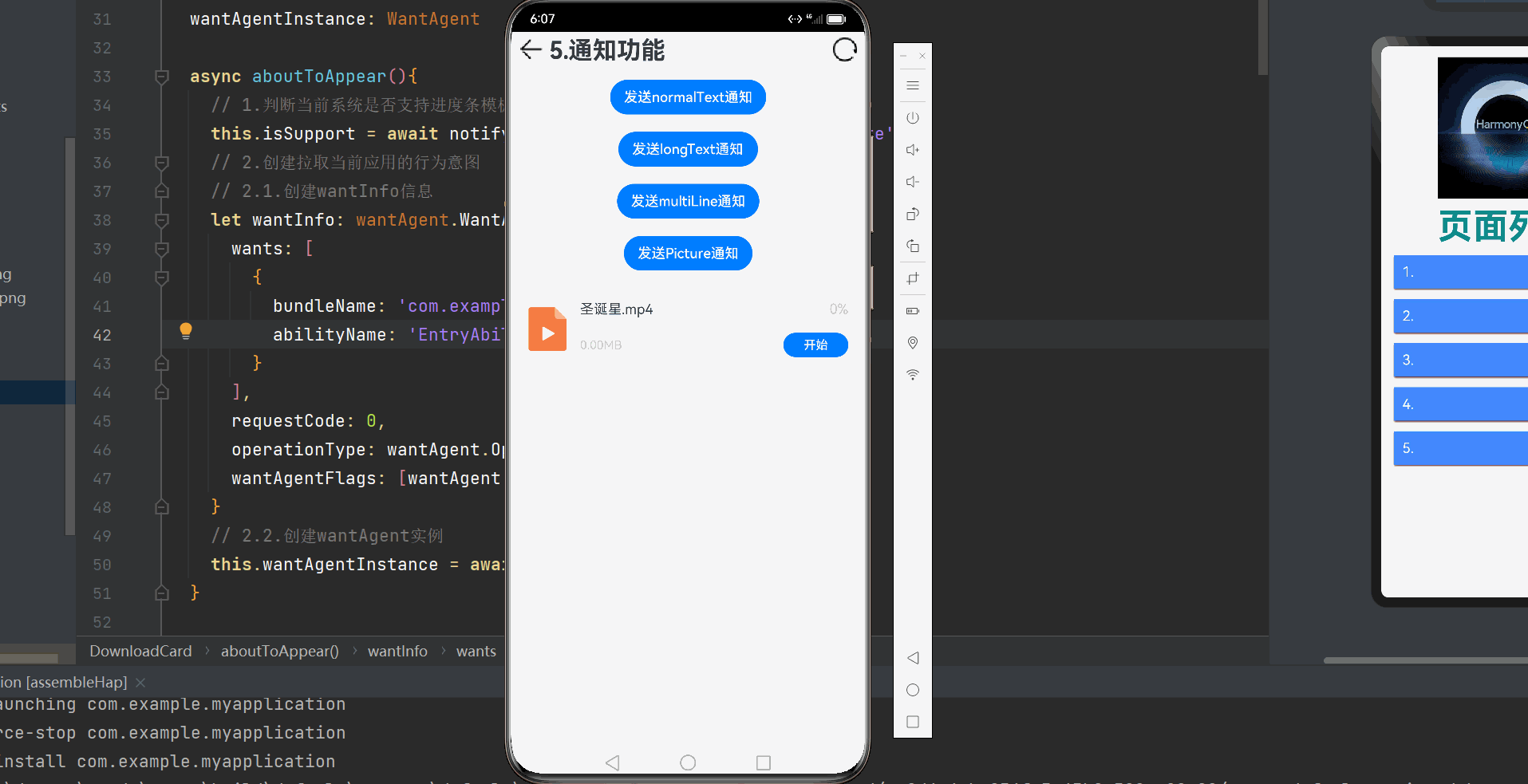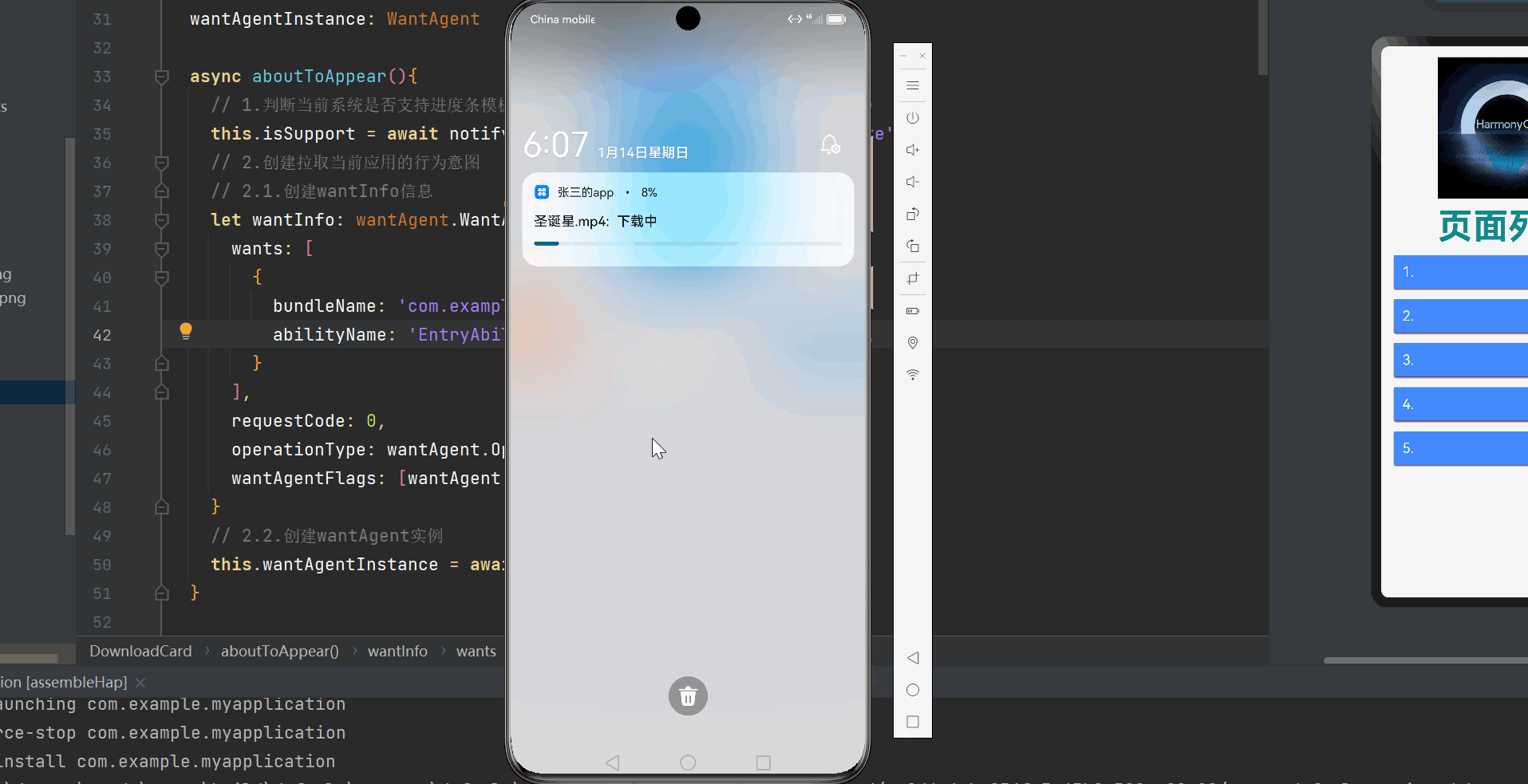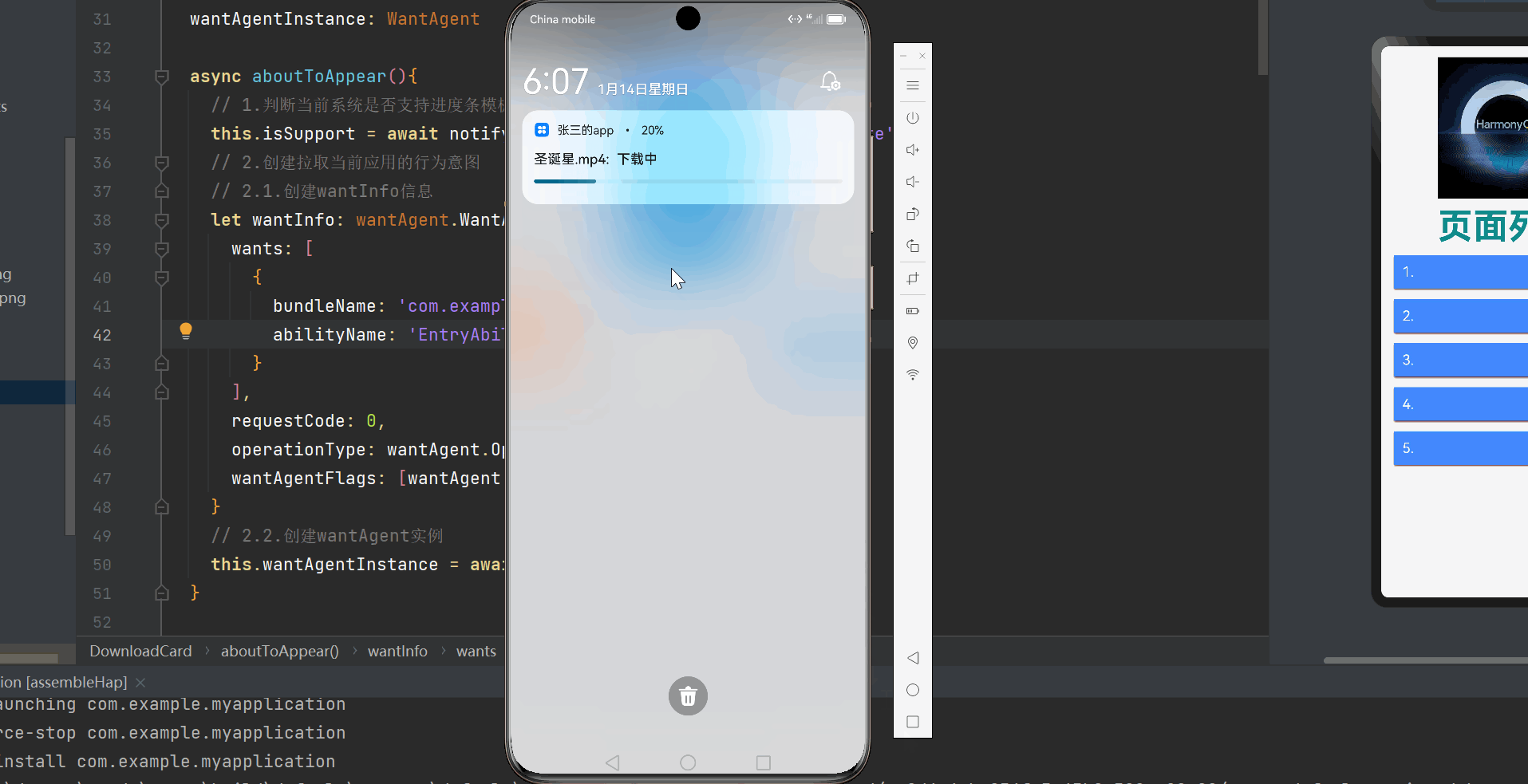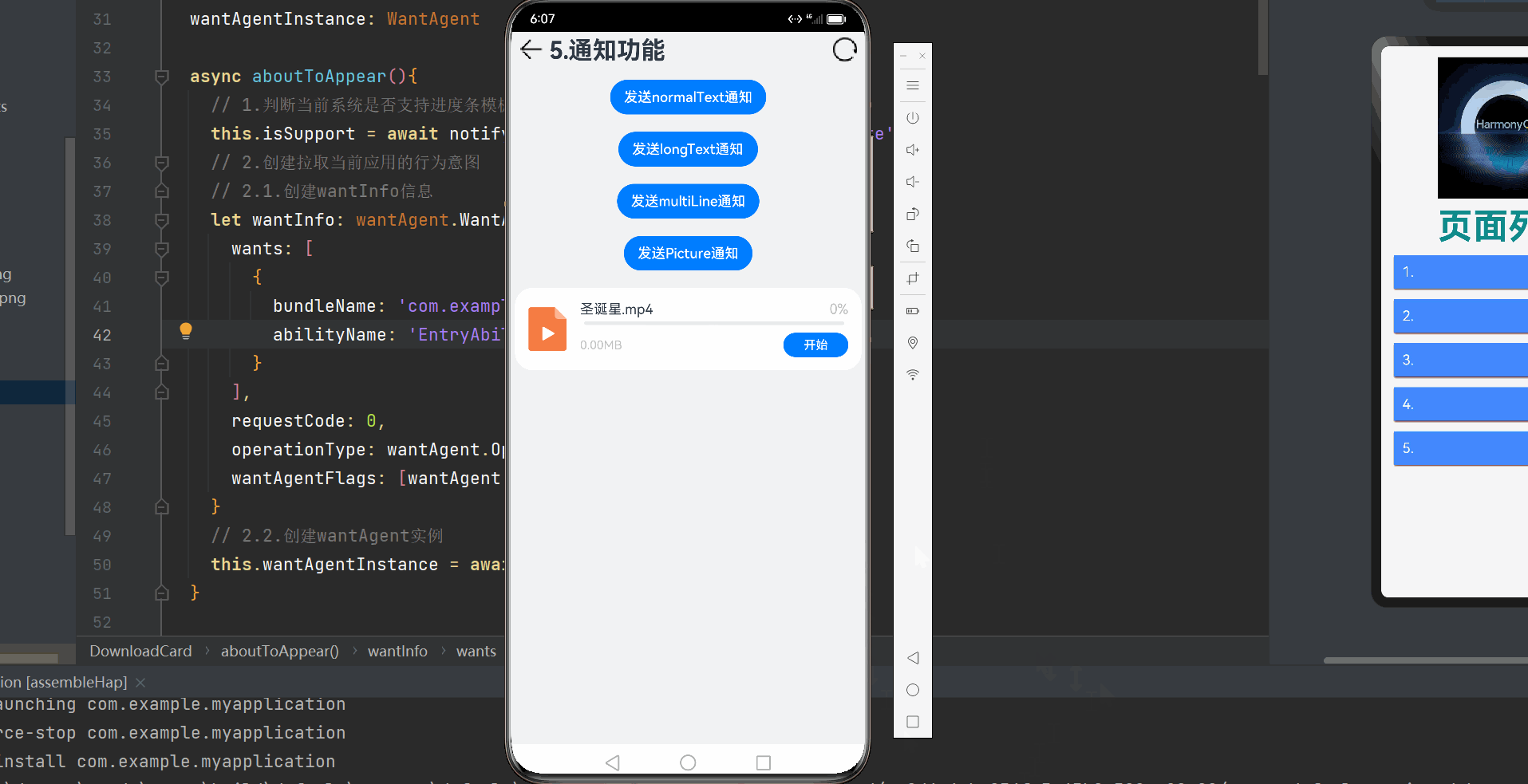
NMS
对一个目标生成了多个检测窗口,但是事实上这些窗口中大部分内容都是重复的,找到目标检测最优的窗口
选取多个检测窗口中分数最高的窗口,剔除掉其他同类型的窗口
anchor generator
首先在该点生成scale=512, aspect ratio={1:2,1:1,2:1}的三个anchor,size分别为{362x724, 512x512, 724x362}。
中心点坐标{8,8},原图和P6之间的高宽scale为{64,64},得到原图上的映射点坐标{8x64, 8x64}。以此为中心,以{362x724, 512x512, 724x362}为高宽,求得左上角、右下角坐标,得到anchor box**{xmin,ymin,xmax,ymax}**
RCNN算法分为4个步骤
- 候选区域生成: 一张图像生成1K~2K个候选区域 (采用Selective Search 方法)
- 特征提取: 对每个候选区域,使用深度卷积网络提取特征 (CNN)
- 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类
- 位置精修: 使用回归器精细修正候选框位置
Selective Search 主要思想:
- 使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
- 查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置
- 输出所有曾经存在过的区域,所谓候选区域
其中合并规则如下: 优先合并以下四种区域:
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的: 保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域 (例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。 不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh)
- 合并后,总面积在其BBOX中所占比例大的: 保证合并后形状规则。

上述四条规则只涉及区域的颜色直方图、梯度直方图、面积和位置。合并后的区域特征可以直接由子区域特征计算而来,速度较快。
卷积的四个张量
维度一(B)是批量大小,有多少个样本
维度二(C)颜色通道的数量,RGB图像的值为3,灰色图像的值为1
维度三四(H,W),对应高和宽。
假设我们有一个给定的张量,其形状为[4,3,32,16],使用这个张量,我们可以确定这个批次有四张图形图像,每个图像都有三个彩色通道,图像的高度和宽度分别为32*16。这给了我们一个四阶张量,他最终会经过我们的卷积神经网络。对于这个张量,我们可以使用四个索引在一个特定图像的特定颜色通道中导航到特定的像素。
模型
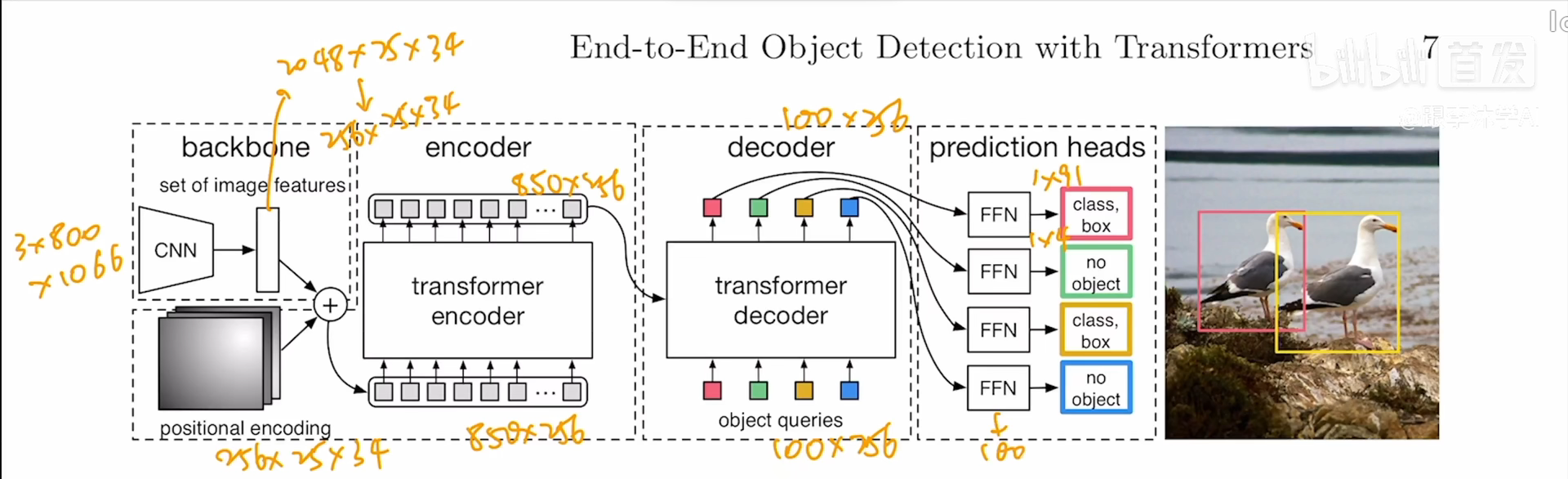
输入图片,通过卷积网络获得特征,到达conv5(卷积层的第五层)的时候会得到一个特征
要把特征给Transformer,这里用1*1的卷积做降维操作
通过Positional encoding加上一个位置编码(位置编码出来的大小要和卷积出来的大小一致,方便相加)
作者的encoder和decoder都是六个叠起来的
decoder是 learnable positional embedding,里面做的是一个cross attention,
编码器进来的图像特征和object queries反复做注意力机制,每层的输入和输出维度都是不变的,都是object queries的大小
解码器输出后加一个检测头,(Feed forward network)也就是MLP全连接层
全连接层做一个物体类别预测和一个出框的预测
类别如果是CoCo的话就是91类,出框主要是四个,出框的中心点坐标x,y以及框的高度和宽度
我们把预测框拿出来,和正确的框去做最优匹配,使用匈牙利算法得出最后的目标函数,然后梯度反向回传来更新模型
细节
object queries每一次要先做自注意力操作,(第一层是可以不做的)这样做是为了消除冗余框,互相通信后会知道每个query可能得到一个什么框,尽量不去做重复的框
为了让模型更加收敛(训练的更快)每个decoder后面都做了auxiliary loss(很常见的trick)检测或者分割非常常见,每个decoder后面都做ffn