目录
一、认识Python数据结构
二、列表概述
三、列表切片
(一)概述
(二)常见形式
(三)特别说明
四、列表的基本操作
(一)创建列表
(二)列表元素增加
(三)列表元素删除
(四)列表元素修改
(五)列表元素查找
五、与列表相关的其他常见函数
六、列表内建函数
七、列表推导式(list comprehensions)
一、认识Python数据结构
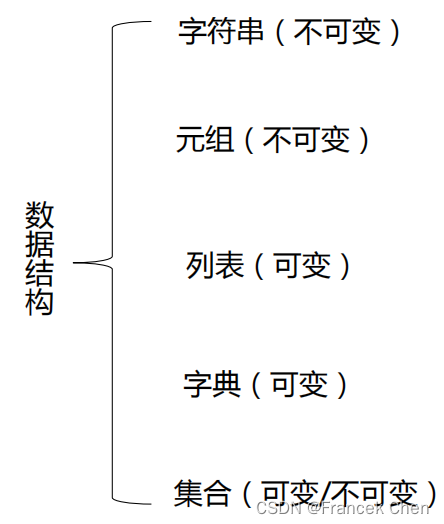
Python有4个内建的数据结构,它们可以统称为容器(container),因为它们实际上是一些“东西”组合而成的结构,而这些“东西”,可以是数字、字符甚至列表,或是它们的组合。

1、可变数据类型
可以直接对数据结构对象进行元素的赋值修改、删除或增加等操作。修改后的新结果仍与原对象引用同一个id地址值,即由始至终只对同一个对象进行了操作。
2、不可变数据类型
不能对数据结构对象的内容进行修改操作(对对象当中的元素进行增加、删除和赋值改)。试图强行修改的结果会导致变量名引用一个新对象而不会改变原对象(新旧对象两者是引用两个不同的id地址值)。
s='I like Python'
id(s)
t='too'
s+=t
id(s)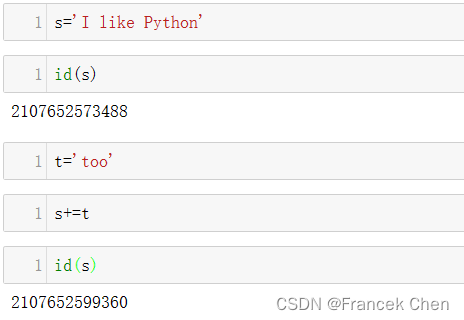
二、列表概述
列表中的元素是有序的,元素可以是任何类型,而且允许重复;
列表属于可变数据类型,允许直接对列表对象进行增、删、改操作。
all_list1 = [1,'word',{'like':'python'},True,[1,2]]因为是有序的,其元素通过索引(下标)来访问,索引的作用:取单个元素
可以从左到右(正向)索引,也可以从右到左(反向)索引
1、正向:第一个元素的索引为0,最后一个元素的索引为len(all_list1)-1
print(all_list1[0], all_list1[len(all_list1)-1])
2、反向:第一个元素(正向的最后一个元素)的索引为-1,第二个元素(正向的倒数第二个元素)的索引为-2
print(all_list1[-1], all_list1[-2])
3、当索引越界时会报错:提示IndexError: list index out of range
print(all_list1[-6])
4、根据列表内容查找索引,可以使用index()方法或find()方法:
print(all_list1.index('word'))
index()方法或find()方法的区别:找不到时前者会出错,后者会返回-1
如何访问嵌套列表中的元素?
答:使用多维索引,例如:all_list1[4][1]将指向整数对象2,
all_list1[4]指向的是列表对象[1,2]
而all_list1指向的是上面整个列表对象
三、列表切片
(一)概述
切片的作用:取列表中的0到多个元素,形成子列表
语法:sequence_name[start:end:step]
注意:取元素规则是左闭右开区间,不包含end。当step为1时,提取元素个数: (end-start)。
1、当step为正时,切片方向是从左到右,正常是要求start小于end

s='I like Python'
s[2:9:2]
s[2:-4:2]
s[-11:-4:2] 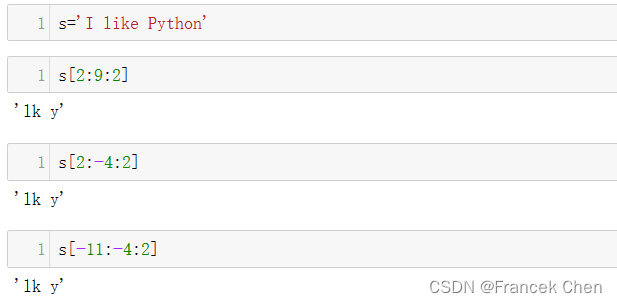
2、当step为负时,切片方向是从右向左,正常是要求start大于end

s='I like Python'
s[9:2:-2]
s[-4:2:-2]
s[9:-11:-2]
s[-4:-11:-2]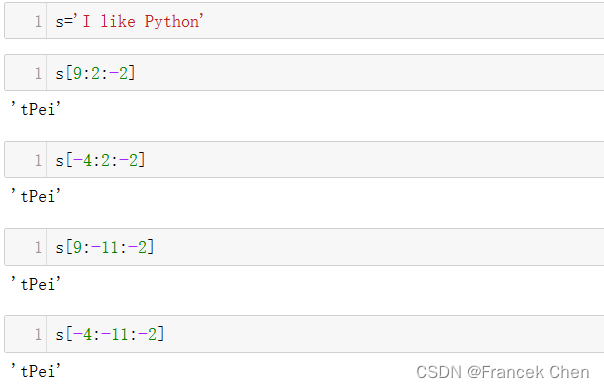
注意下面两个的区别:
s[7:]
s[7:-1]
(二)常见形式
all_list1 = [1,'word',{'like':'python'},True,[1,2]]
all_list1[2:4] #省略step,step默认为1,提取索引为2和3的两个元素
all_list1[2:] #省略end和step,提取从索引2开始的全部后面元素,包含最后一个元素
all_list1[2:-1] #提取从索引2开始的后面元素,但不包含最后一个元素
all_list1[:] #省略start,默认从0开始,提取所有元素
all_list1[::-1] #逆序整个列表
newList=all_list1[:] #复制整个all_list列表
id(all_list1)
id(newList)
注意:
切片不会改变原始列表,而是会产生一个新的列表对象!
这与Numpy中的数组切片不同,后者得到的原数组对象的一个视图,修改切片中的内容会导致修改原来的数组对象!
(三)特别说明
1、step为正:
表示提取方向是从左到右,正常情况是要求start小于end。
如果start或end超出索引的范围,或者start大于或等于end,则切片操作将会返回的是空列表,例如:all_list1[6:8]或all_list1[3:3]
2、step为负:
表示提取方向是从右到左,正常情况是要求start大于end。
如果start或end超出索引的范围,或者start小于或等于end,则切片操作将会返回的是空列表。
四、列表的基本操作
(一)创建列表
1、方法一:使用[ ]创建,列表元素间以逗号隔开
empty1 = [] #空列表
all_list1 = [1,'word',{'like':'python'},True,[1,2]]2、方法二:使用list()函数创建,可以把其他非列表类型的对象转换为列表类型
注意: list()函数只允许有一个参数
empty2 = list() #空列表
lstr = list(“student”) #lstr指向列表['s', 't', 'u', 'd', 'e', 'n', 't'](二)列表元素增加
fruit = [1,'word',True,'pear']
month=['January','February']
1、append()方法
(1)在末尾只能追加一个元素
(2)被增加的元素可以是任何类型的对象
示例:
fruit = [1,'word',True,'pear']
month=['January','February']
fruit.append(month) #month列表作为一个元素被追加到尾部
print(fruit)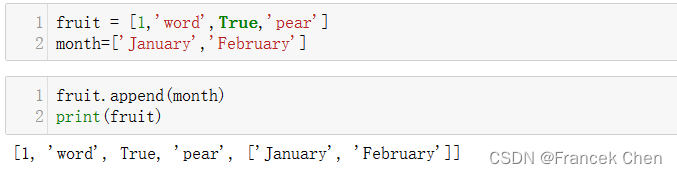
2、extend()方法
(1)在末尾合并一个可迭代对象,因此可以一次性在末尾合并吸收一个或多个元素
(2)被合并的对象必须是一个可迭代对象
示例:
fruit = [1,'word',True,'pear']
month=['January','February']
fruit.extend(month) #month列表被合并到fruit的尾部,相当于fruit+=month
print(fruit)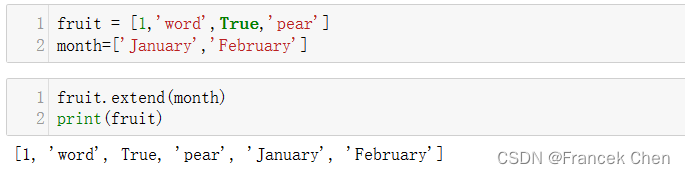
错误示例:fruit.extend(5) //整数5不是一个可迭代对象
3、insert()方法
一般用于在中间的某个指定位置(索引)插入一个新元素(两参数分别是索引和新元素)
示例:
fruit = [1,'word',True,'pear']
month=['January','February']
fruit.insert(-3,'apple')
fruit.insert(9,month)
print(fruit)
(三)列表元素删除
fruit = [1,'word',True,'pear']
1、del关键字
既可以删除整个列表对象,也可以按索引(位置)删除特定元素。
示例一:
fruit = [1,'word',True,'pear']
del fruit[0:2] #允许按切片形式进行删除,但不会返回被删除的元素
print(fruit)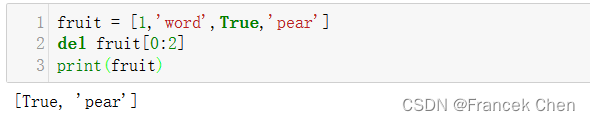
示例二:
fruit = [1,'word',True,'pear']
del fruit #删除整个列表对象
print(fruit)

列表对象fruit已被删除,故报错“name 'fruit' is not defined”。
2、pop(index)方法
删除index给出的列表指定位置元素的同时,还可以返回被删除的元素值。
示例:
fruit = [1,'word',True,'pear']
temp = fruit.pop(2) #pop删除能返回被删除的元素
print(fruit)
当没有index参数时,默认删除列表的最后一个元素。
3、remove()方法
与前面两个按位置删除不同,它按元素值删除(删除第1个匹配项),找不到删除项则报错。
示例:
fruit = [1,'word',True,'pear']
fruit.remove('pear')
print(fruit)
4、clear()方法
清空整个列表(使之成为空列表,但不删除列表对象)
示例:
fruit = [1,'word',True,'pear']
fruit.clear()
print(fruit)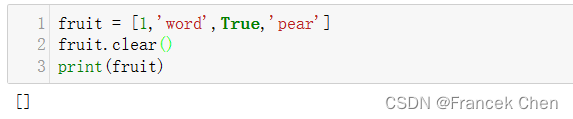
(四)列表元素修改
对列表的索引/切片赋值
fruit = [1,'word',True,'pear']
fruit[0] = ‘orange’
print(fruit) 
(五)列表元素查找
fruit = [1,'word',True,'pear']
fruit[3] #按索引找元素
fruit.index(‘pear’) #按元素找索引也可以使用find()方法
五、与列表相关的其他常见函数
all_list = [1,2,'hello','word']
长度:len(all_list)
计数:all_list.count(‘word’) //统计元素’word’出现的次数
反转:all_list[::-1] 或者 all_list.reverse()或者reversed(list)
合并:list1+list2(注意:list1.extend(list2)相当于list1+=list2)
重复:all_list * 2 (例如:
all_list = [1,2,'hello','word']
all_list * 2
返回列表元素(数值型)的最大、最小值:max(list)、 min(list)
判断元素是否存在:'word' in all_list(注意:与 in 相反的运算符是 not in)
排序:(1)list.sort()函数会改变列表对象本身;
(2)sorted(list)全局方法不会改变列表对象本身,却会产生一个排好序的新列表对象。
注意:
ls.sort(reverse=True)表示排序时按降序排列,它与反转元素顺序的ls.reverse()方法的作用是不同的。
六、列表内建函数


web = 'www.jou.edu.cn'
str1 = web.split('.')
str1
str1.sort() #默认按首字母升序
str1
str1.sort(key=len,reverse=True) #当指定关键字为长度len,并且reverse=True时,将按长度大小降序排列
str1

all_list1 = list((1,'word',{'like':'python'},True,[1,2]))
list3=list(enumerate(all_list1))
print(list3)
七、列表推导式(list comprehensions)
Python推导式(又称解析式)允许以简洁的方式从一个可迭代对象构建出一个新的数据结构,共有三种推导:列表推导式(构建出列表)、字典推导式(构建出字典)和集合推导式(构建出集合)。
列表推导式的基本语法为:
1、不带条件的列表推导式:[表达式 for 变量 in 可迭代对象]
2、带条件的列表推导式,又分为
(1)单分支:[表达式 for 变量 in 可迭代对象 if 条件]
(2)双分支:[表达式1 if 条件 else 表达式2 for 变量 in 可迭代对象]
list1 = [i**2 for i in range(1,11)]
print(list1)
print([i for i, x in enumerate(list1) if x%3 ==0])
list2 = [1 if x%3 == 0 else 0 for x in list1]
print(list2)
3、列表推导式的嵌套:[for 变量1 in 可迭代对象1 if 条件1 for 变量2 in 可迭代对象2 if 条件2]
list3 = [(x,y) for x in range(5) if x%2 == 0 for y in range(5) if y%2 == 1]
print(list3)![]()
列表推导式有助于简化for循环的写法!
data = [num for num in range(20) if num%2==1]等价于
data = []
for num in range(20):
if num%2 == 1:
data.append(num)