1.腾讯发布PhotoMaker
《PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding》
作者机构:南开大学&腾讯 PCG ARC 实验室&东京大学
相关链接
[Paper] [Code] [Demo] [Model Card] [BibTeX]

摘要
文本到图像生成的最新进展在根据给定文本提示合成逼真的人类照片方面取得了显着进展。然而,现有的个性化生成方法无法同时满足高效率、有前途的身份(ID)保真度和灵活的文本可控性的要求。在这项工作中,文章介绍了PhotoMaker,一种高效的个性化文本到图像生成方法,它主要将任意数量的输入 ID 图像编码为堆栈 ID 嵌入,以保存 ID 信息。这种嵌入作为统一的ID表示,不仅可以全面封装同一输入ID的特征,而且可以容纳不同ID的特征以便后续集成。这为更有趣且具有实际价值的应用铺平了道路。此外,为了推动 PhotoMaker 的训练,文章提出了一个面向 ID 的数据构建管道来组装训练数据。在通过所提出的管道构建的数据集的滋养下,我们的 PhotoMaker 表现出了比基于测试时微调的方法更好的 ID 保存能力,同时提供了显着的速度改进、高质量的生成结果、强大的泛化能力和广泛的应用程序。
方法
文中的方法将一些具有相同身份的输入图像转换为堆叠的 ID 嵌入。这种嵌入可以看作是要生成的ID的统一表示。在推理阶段,构成堆叠ID嵌入的图像可以源自不同的ID。然后我们可以在不同的上下文中合成定制的 ID。
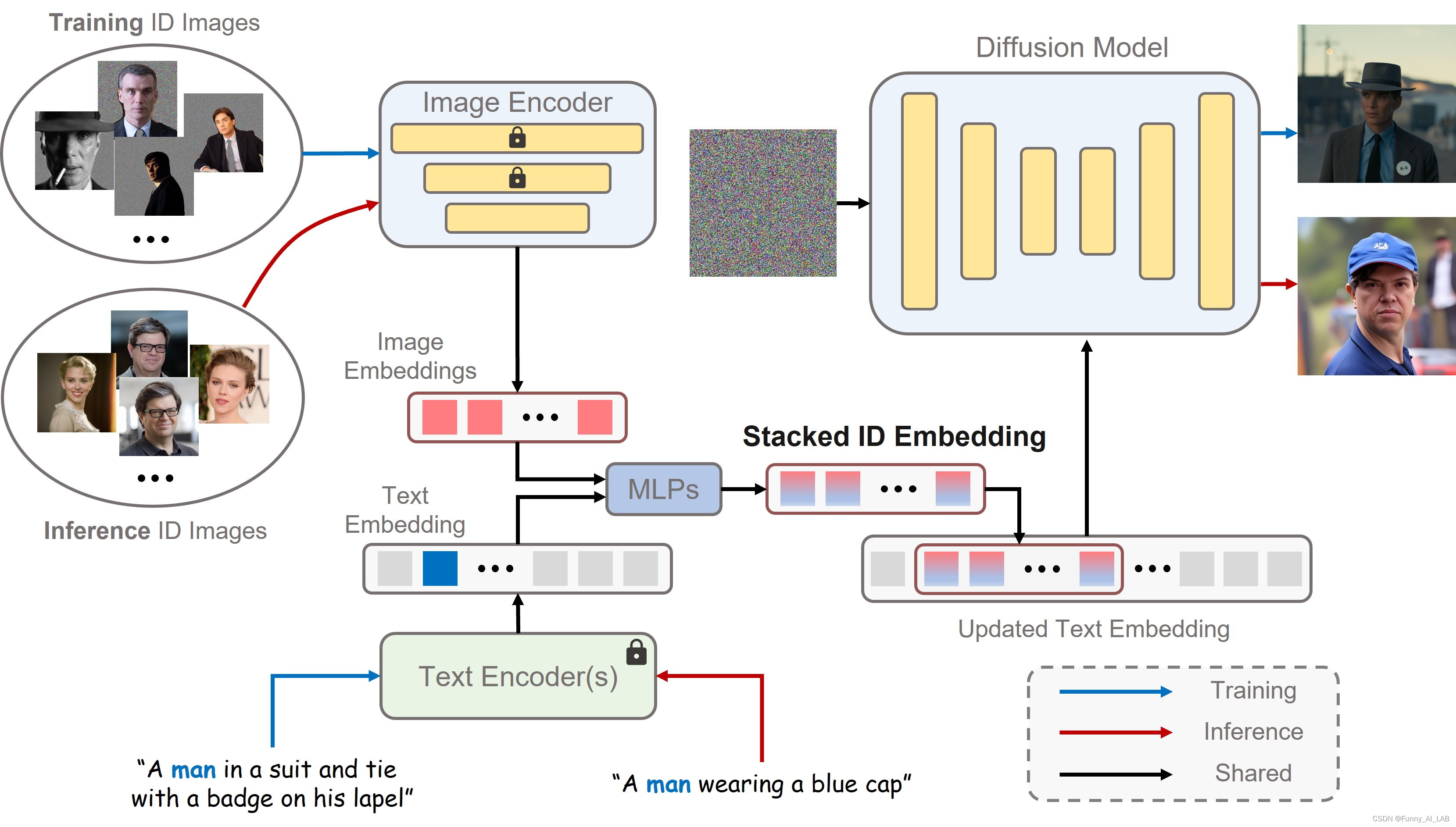 首先分别从文本编码器和图像编码器获得文本嵌入和图像嵌入。然后,通过合并相应的类嵌入(例如,男人和女人)和每个图像嵌入来提取融合嵌入。接下来,我们沿着长度维度连接所有融合的嵌入以形成堆叠的 ID 嵌入。最后,将堆叠的 ID 嵌入提供给所有交叉注意力层,以自适应地合并扩散模型中的 ID 内容。请注意,虽然在训练过程中使用具有遮蔽背景的相同ID的图像,但可以在推理过程中直接输入不同ID的图像而没有背景失真来创建新的ID。
首先分别从文本编码器和图像编码器获得文本嵌入和图像嵌入。然后,通过合并相应的类嵌入(例如,男人和女人)和每个图像嵌入来提取融合嵌入。接下来,我们沿着长度维度连接所有融合的嵌入以形成堆叠的 ID 嵌入。最后,将堆叠的 ID 嵌入提供给所有交叉注意力层,以自适应地合并扩散模型中的 ID 内容。请注意,虽然在训练过程中使用具有遮蔽背景的相同ID的图像,但可以在推理过程中直接输入不同ID的图像而没有背景失真来创建新的ID。
2.智谱AI推出GLM-4 All Tools和GLMs
GLM-3开源地址:THUDM/ChatGLM3
chatGLM相关历程:chatglm.cn/blog
智谱清言体验最新版 GLM4 All tools
API平台 最新版API
2024年1月16日,在智谱AI技术开放日上,智谱AICEO张鹏发布新一代底层大模型GLM-4。据介绍,GLM-4性能相比GLM-3提升60%,逼近GPT-4(2023年11月6日最新版本效果)。同时智谱AI发布了GLMs,为所有开发者提供AI智能体定制能力,依靠简单的prompt指令创建个性化GLM智能体。

GLM-4 All Tools实现了根据用户意图自动理解规划复杂的指令,自动调用多项工具来完成复杂任务,包括文生图、代码解释器、网页浏览、Function Call等。这意味着GLM系列模型的全家桶能力实现工业化,开发者及用户可以更轻松地使用GLM-4模型,不再为提示词而担心。
智谱AI宣布GLMs个性化智能体定制能力同时上线,基于GLM-4模型,任何用户只要登陆智谱清言观望,使用简单的提示词指令就能创建属于自己的智能体。在同期上线的智能体中心中,用户可分享各种智能体。没有编程基础的用户也能实现大模型的便捷开发。
GLM-4 相关评价讨论
3.DreamDistribution(哈佛大学联合微软推文生图模型)
《DreamDistribution: Prompt Distribution Learning for Text-to-Image Diffusion Models》—github
作者机构:南加州大学&哈佛大学&微软亚洲研究院&微软雷德蒙研究院
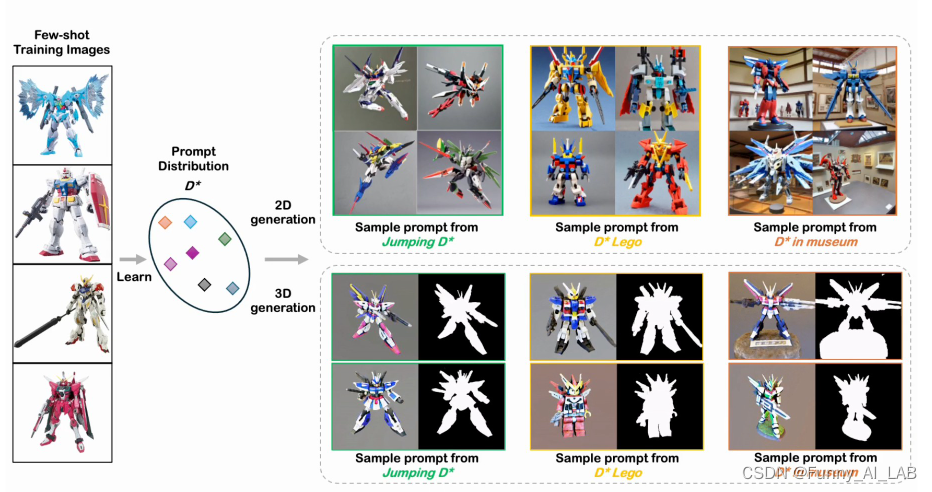
来自南加州大学、哈佛大学等机构的研究团队最近提出了一项创新性的生成模型方法,名为DreamDistribution。这一方法基于提示学习,能够通过仅有的几张参照图片学习文本提示分。
DreamDistribution找到参考图像的提示分布,然后可用于生成新的 2D/3D 实例,能够进行文本引导编辑等。
摘要
文本到图像(T2I)扩散模型的普及使得从文本描述生成高质量图像成为可能。然而,生成具有参考视觉属性的多样化定制图像仍然具有挑战性。这项工作的重点是在更抽象的概念或类别级别个性化 T2I 扩散模型,适应一组参考图像的共性,同时创建具有足够变化的新实例。我们引入了一种解决方案,允许预训练的 T2I 扩散模型学习一组软提示,从而通过从学习的分布中采样提示来生成新颖的图像。这些提示提供了文本引导的编辑功能以及控制多个发行版之间的变化和混合的额外灵活性。我们还展示了学习到的提示分布对其他任务(例如文本转 3D)的适应性。最后,我们通过定量分析(包括自动评估和人工评估)证明了我们方法的有效性。
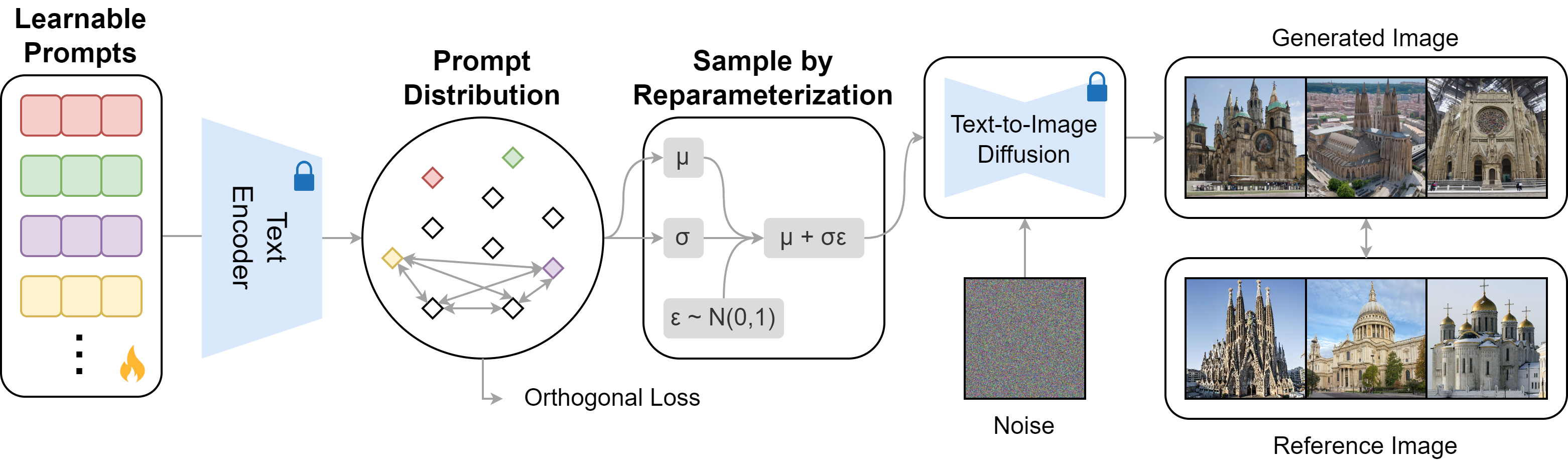
方法:
保留一组 K 个可学习的软提示,并在 CLIP 文本编码器特征空间中对它们的分布进行建模。只有提示是可以学习的,CLIP编码器和T2I扩散模型都是固定的。使用重新参数化技巧从提示分布中进行采样,并通过反向传播更新可学习的提示。训练目标是使生成的图像与参考图像对齐。纳入额外的正交损失以促进可学习提示之间的区分。为了进行推理,同样从文本特征空间的提示分布中进行采样,以指导预训练的 T2I 生成。
关注@funyai分享更多最新的前沿技术

![[C#]winform部署官方yolov8-obb旋转框检测的onnx模型](https://img-blog.csdnimg.cn/direct/ced49909c78847f2982c9a8d4ecb9aa8.jpeg)