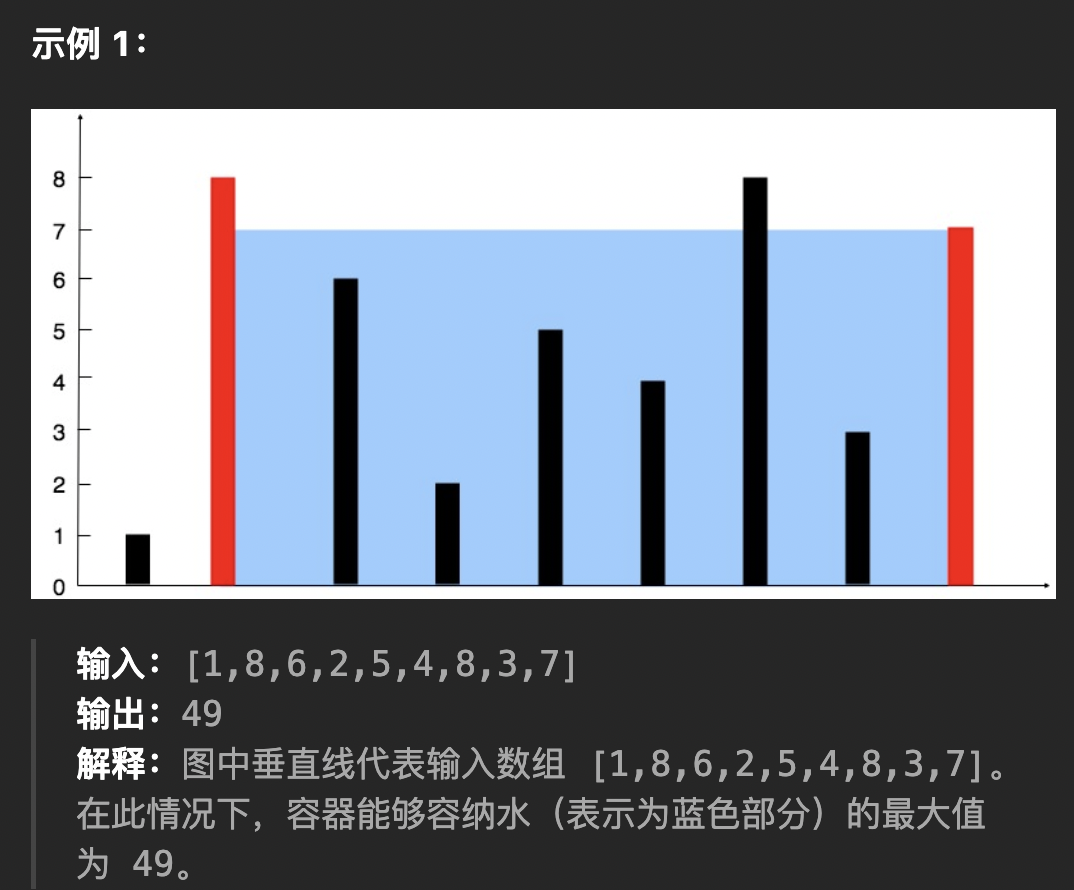
1、牢记Context
Context是Nginx中每条指令都会附带的信息,用来说明指令在哪个指令块中使用,可以将Context 理解为配置环境。
每个指令都拥有自己的配置环境,如果把配置环境记错了,或者在设计时未考虑配置环境的作用,就很可能导致配置无法达到预期。举例来说,观察下图所示的根据请求参数定制响应头的逻辑。

根据上图的需求,有的读者可能会不假思索地写出如下代码:
if($arg_id){
proxy_set_header X-id '1' #设置请求头
}
proxy_pass http://backed
但启动Nginx却出现如下报错信息:

通过阅读Nginx的官方Wiki可以找到出现错误的原因:

可知proxy_set_header所支持的配置环境(Context),只有http、server、location这三个指令块,不支持if语句。因此对于要用到的指令,使用前需要知道它的配置环境。
2、获取请求的IP地址
Nginx会将客户端的IP地址信息存放在¥remote_addr变量中,但在生产环境下往往会有各种代理,让获取真实的IP地址变得困难重重。
2.1、获取用户的真实IP地址
大部分互联网公司的反向代理都会用到下图所示的CDN加速代理流程图。
用户的请求并不直接和Nginx打交道,而是由CDN(Content Delivery Network,即内容分发网络)传递给Nginx。所以在默认情况下,Nginx 看到的客户端IP地址是经过CDN 处理后的IP地址,这对日志的记录和分析、后端服务的业务逻辑都可能产生不良的影响。如果需要获取用户的真实IP地址,就要用到realip模块。

使用realip模块需要执行–with-http_realip_module命令,并在Nginx的http块中配置如下代码:

- set_real_ip_from:设置可信任的IP地址,即白名单,之后会使用real_ip_header从这些IP地址中获取请求头信息。
- real_ip_header:从指定的请求头中获取客户端的IP地址,IP地址是通过请求头传递给Nginx的,请求头可能包括多个IP地址(以逗号分隔),此时只会获取最左边的IP地址并赋值给$remote_addr(客户端地址),此请求头一般会用到X-Forwarded-For。
- real_ip_recursive:如果设置为on,则表示启用递归搜索,realip_module在获取客户端地址时,会在real_ip_header指定的请求头信息中逐个匹配IP地址,最后一个不在白名单中的IP地址会被当作客户端地址。默认为off,表示禁用递归搜索,此时,只要匹配到白名单中的IP地址,就会把它作为客户端地址。
由此,可以获取到用户的真实IP地址,如果希望获取CDN的节点IP地址(有助于排查和CDN有关的问题),可以使用$realip_remote_addr(此变量在2.5.2小节中有介绍)。
2.2、防止IP地址伪造
X-Forwarded-For请求头已经是业界的通用请求头,有些恶意攻击会伪造这个请求头进行访问,通过混淆服务器的判断来掩藏攻击者的真实IP地址。但如果在Nginx之前还有一个CDN的话,可以使用如下方案解决这个问题。
- 和CDN厂商确定约束规范,使用一个新的秘密的请求头,如X_Cdn_Ip。
- 在CDN代理客户端请求时,要求CDN传递用户的IP地址,并且在建立连接的过程中,通过CDN清除伪造的请求头,避免透传到后端。下图是CDN传递用户IP地址的流程图。

注意:如果没有使用CDN,客户端的请求会直接和Nginx打交道。Nginx可以使用自定义的请求头传递用户的IP地址,如proxy_set_header X-Real-IP $remote_addr。
2.3、后端服务器对IP地址的需求
有时后端服务器也要用到用户的客户端IP地址,在这种情况下,研发团队需要在IP地址的获取上制定统一的规范,从规定的请求头信息中获取客户端IP地址。请求头中的IP地址可能有多个(经过了多次代理),它们以逗号分隔,其中第一个IP地址就是客户端IP地址。
3、管理请求的行为
作为HTTP服务,有些请求不适合暴露在公网上,那么就需要配置访问限制来提高安全性,此时可以通过Nginx来限制后台或内部的接口。
3.1、限制IP地址的访问
要对IP地址的访问进行限制,首先需要了解allow和deny这两个指令,allow和deny指令的说明见下表:

指令allow和deny都可以在多个指令块中配置,下图是指令deny在不同指令块中的配置效果,allow的配置亦是如此:
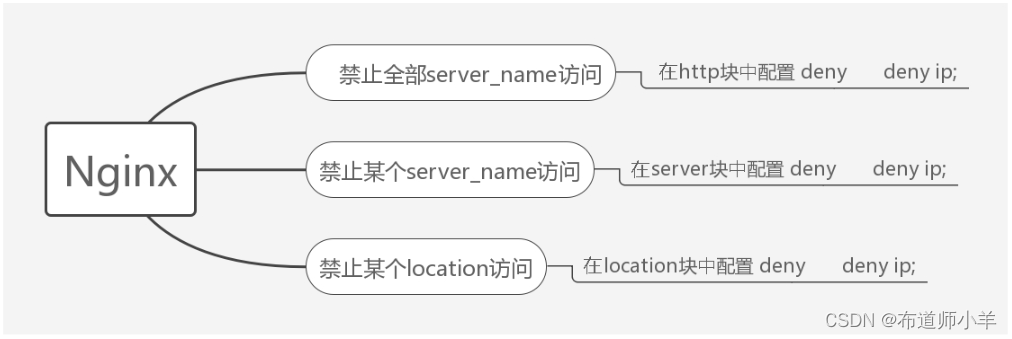
举个例子,对访问某个location块的IP地址进行限制,代码如下:

通过对访问的IP地址进行限制,可以阻挡可疑IP地址对服务的攻击,也可以确保内部接口只被内网访问。
3.2、auth身份验证
指令allow和deny基于IP地址来配置访问限制,除此之外,还可以通过密码验证的方式对访问进行限制,即通过配置auth_basic来设置用户须输入指定的用户名和密码才能访问相关资源。这样做既不用限制用户的IP地址,又在一定程度上保证了资源的安全。
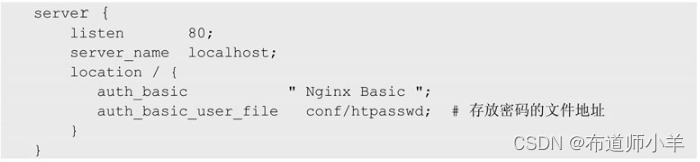
相关指令说明如下:
- 指令:auth_basic
- 语法:auth_basic string/off;
- 默认值:auth_basic off;
- 环境:http、server、location、limit_except
含义:其中string指的是字符串信息,是用户自定义的内容。如果设置为off,表示禁用此功能;如果不设置为off,则会在浏览器访问时看到string 字符串的内容被输出。
- 指令:auth_basic_user_file
- 语法:auth_basic_user_file file;
- 默认值:无
- 环境:http、server、location、limit_except
含义:file指的是文件名,该文件存放的是登录用户名和密码,形式类似于testuser: 1 1 1XlKs2P mC$xfxImYPQPMTloK5J7dar.1。
其中密码并不是明文显示的,而是加密过的。加密工具可以用htpasswd或OpenSSL。OpenSSL是进行HTTPS加密、解密时常用的工具,它也可以用来对密码进行加密,以账号testuser、密码Pass123为例,执行加密命令如下:

得到的加密后的内容是testuser:
1
1
1DRCZTLTx$dRBMISe3SBnw/VZdBfhCg1,把它存放到file文件中,这样密码就更加安全了。重启Nginx,打开浏览器输入IP地址进行访问就会显示如下图所示的界面:
注意:对于配置了密码加密的文件,一定要确保在Nginx进程中用户有可读权限,否则会出现的403错误。
3.3、利用LDAP服务加强安全
如果auth_basic使用统一的账号和密码会让请求无法对访问的用户进行区分,这对安全性要求较高的服务,还是不够安全,特别是当用户流动性较大时。此时,可以使用更精确的账号管理接口。常用的接口是LDAP(Lightweight Directory Access Protocol,即轻量目录访问协议),LDAP最基础的功能就是让每个用户都使用自己的账号和密码。通过配置LDAP认证,可以提升Nginx权限配置的灵活性。
首先,需要让Nginx能够读取LDAP的内容:
然后,添加对LDAP的支撑,在编译Nginx时,添加模块编译参数:

最后,在server块中配置如下内容:

配置了LDAP认证,就可以在人员变更后,快速更新用户的账号和密码,并可以定期通知使用者更新密码,加强安全管理。
3.4、satisfy二选一的访问限制功能
那么,如果希望在公司时不用输入账号和密码就能直接登录,该怎么办呢?很简单,加入satisfy指令,satisfy指令可以提供二选一的逻辑判断,配置如下:

上述配置的作用是当请求的IP地址在192.168.0.0/16和10.10.10.10/32 网段内时,不需要使用LDAP认证即可直接登录;如果IP地址不在这两个网段内,则需要通过LDAP认证进行登录。如此,鱼与熊掌可以兼得。
4、proxy代理
Nginx使用ngx_http_proxy_module来完成对后端服务的代理。这一节,我们将一起来见识Nginx最流行的proxy代理功能。
4.1、proxy_pass请求代理规则
语法:proxy_pass URL;
环境:location、if in location、limit_except
含义:将请求代理到后端服务器,设置后端服务的IP地址、端口号以及HTTP/HTTPS。
示例:将URI为/test的请求代理到127.0.0.1上,端口号为81,使用HTTP,代码如下:

在代理过程中,URL的传递会有如下几种变化:

注意:如果location块配置的URI使用了正则表达式,那么在使用proxy_pass时,就不能将URI配置到 proxy_pass指定的后端服务器的最后面了,即禁止使用类似proxy_pass http://127.0.0.1:81/abc/的方式,否则可能会导致一些不可预测的问题出现。
4.2、减少后端服务器的网络开销
有很多请求的内容只和URL有关,即后端服务器不需要读取请求体和请求头,只根据URL的信息即可生成所需的数据。在这种情况下,可以使用如下两个指令,并将其配置为off,禁止传输请求体和请求头。
- proxy_pass_request_body:确定是否向后端服务器发送HTTP请求体,支持配置的环境有http、server、location。
- proxy_pass_request_headers:确定是否向后端服务器发送HTTP请求头,支持的配置的环境有http、server、location。
通过配置以上两个指令,后端服务接收到的流量将会变小。
4.3、控制请求头和请求体
在请求被代理到后端服务器时,可以通过下表所示的指令去控制请求头和请求体:
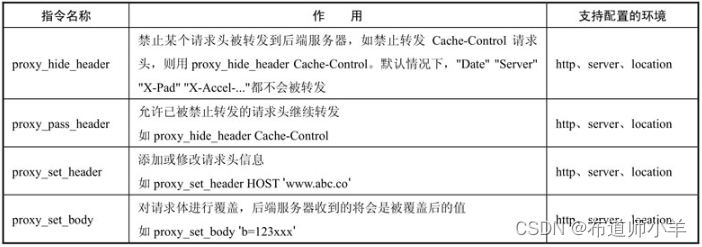
注意:在设置proxy_set_header后,下一层级会继承这个请求头的内容。但如果下一层级也配置了proxy_set_header指令,那么当请求到达下一层级时,在上一层级配置的请求头将会被全部清除。
举例如下:

如果要A和AB两个请求头都保留下来,可以用下面的方法:

4.4、控制请求和后端服务器的交互时间
控制请求和后端服务器交互时间的指令见下表:
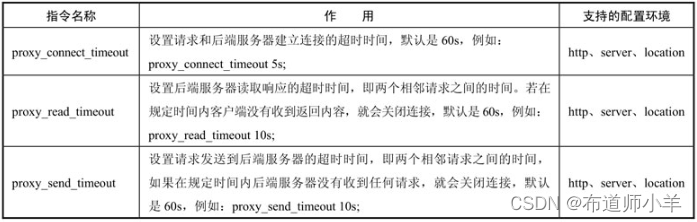
如果使用默认的设置,即60s,请求可能需要等待很久才会做出下一步反应,而客户端往往不会等待那么久,所以需要合理设置交互时间,并且最好能在超时后做一些合理的措施。如搭配使用proxy_next_upstream*命令。
5、upstream使用手册
利用proxy_pass可以将请求代理到后端服务器,上一节中的配置示例都指向同一台服务器,如果需要指向多台服务器就要用到ngx_http_upstream_module。它为反向代理提供了负载均衡及故障转移等重要功能。
5.1、代理多台服务器
先来看一个简单的版本:
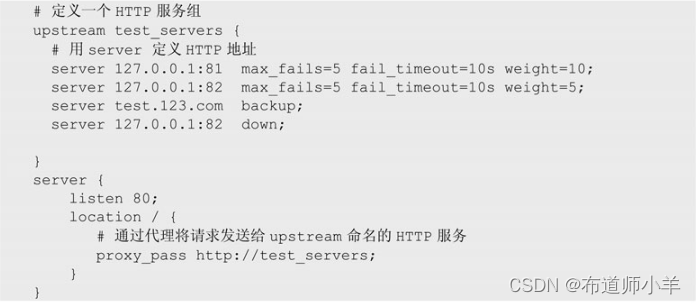
指令:upstream
语法:upstream name {…}
环境:http
含义:定义一组HTTP服务器,这些服务器可以监听不同的端口,以及TCP和UNIX 套接字。在同一个upstream中可以混合使用不同的端口、TCP和UNIX 套接字。
指令:server
语法:server address [parameters];
环境:upstream
含义:配置后端服务器,参数可以是不同的IP地址、端口号,甚至域名。
server指令拥有丰富的参数,其参数说明见下表:

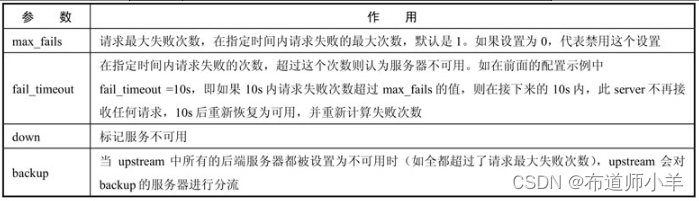
5.2、故障转移
如果在前面的配置示例中出现了超过请求失败次数的服务器,下面这些参数可以用来对这些服务器进行配置:proxy_next_upstream、fastcgi_next_upstream、uwsgi_next_upstream、scgi_next_upstream、memcached_next_upstream和grpc_next_upstream。下面用最常见的proxy_next_upstream为例进行说明。
指令:proxy_next_upstream
语法:proxy_next_upstream error|timeout|invalid_header|http_500|http_502|http_503|http_504|http_403|http_404|http_429|non_idempotent|off …;
默认值:proxy_next_upstream error timeout;
环境:http、server、location
含义:定义转发条件,当请求返回Nginx时,如果HTTP状态满足proxy_next_upstream设置的条件,就会触发Nginx将请求重新转发到下一台后端服务器,并累加出现此状态的服务器的失败次数(当超过max_fails和fail_timeout的值时就会设置此服务器为不可用)。如果设置为off,则表示关闭此功能。
指令:proxy_next_upstream_tries
语法:proxy_next_upstream_tries number;
默认值:proxy_next_upstream_tries 0;
环境:http、server、location
含义:定义尝试请求的次数,达到次数上限后就停止转发,并将请求内容返回客户端。
指令:proxy_next_upstream_timeout
语法:proxy_next_upstream_timeout time;
默认值:proxy_next_upstream_timeout 0;
环境:http、server、location
含义:限制尝试请求的超时时间,如果第一次请求失败,下一次请求就会被此参数值控制。若设置为 0,则表示无超时时间,但尝试的请求仍会受到proxy_read_timeout、proxy_send_timeout、proxy_connect_timeout的影响。
注意:通过这些配置,可以在后端服务器的某些节点出现请求异常时,快速做出故障切换的操作,从而屏蔽这些异常的请求。但是这存在一种隐患,即如果proxy_next_upstream_tries设置的值比较大,且proxy_next_upstream也设置了很多状态,当发生大面积异常时,重试不断累加,可能会导致请求反复向多个服务器发送,这样会给后端服务器带来更大的压力。
5.3、负载均衡
Nginx不仅支持代理多台后端服务器,也支持各种负载均衡模式,负载均衡在upstream的配置环境内设置(默认根据权重轮询)。负载均衡指令见下表:
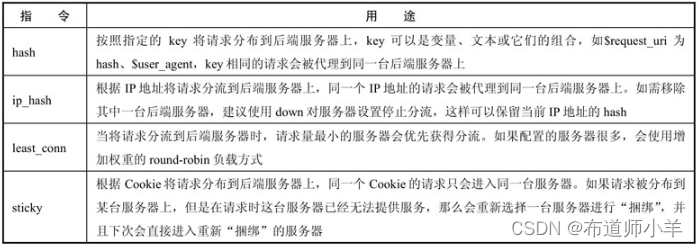
5.4、通过hash分片提升缓存命中率
缓存系统是减少后端服务压力的重要组件,常见的 HTTP缓存系统有 Nginx的proxy_cache、varnish、squid。如果通过反向代理去获取缓存数据,一般需要使用hash分片,以避免URL的请求随机进入缓存系统的某个分片,导致缓存命中率低、后端服务器压力上升。
基于URL缓存的服务配置一般如下所示,相同的URL(包含参数)会进入相同的后端缓存系统:

注意:
- 增减节点会导致hash重新计算,因此增减节点最好选择在服务的低峰期进行。
- 在缓存系统上使用max_fails不一定是最好的选择,但一旦使用请确保proxy_next_upstream的合理性,尽量不要配置各种HTTP状态码,因为缓存系统代理的是后端服务,当后端服务异常时会将错误的状态码返回给Nginx,这样会让Nginx以为缓存系统出了问题,从而将缓存节点当作失败的节点,停止分流。
缓存系统的故障转移应该只以存活检查方式(一般指检查缓存系统的端口是否存活,以及固定检查一个接口是否能返回正常的响应)为主。可以结合健康检测功能,或者动态剔除异常缓存节点的功能来使用。
5.5、利用长连接提升性能
在Nginx中,使用upstream进行后端访问默认用的是短连接,但这会增加网络资源的消耗。可以通过配置长连接,来减少因建立连接产生的开销、提升性能。和长连接有关的配置示例如下:
#user root;
keepalive_timeout 600;
keepalive_requests 1000;
upstream test_servers{
server 127.0.0.1:81 max_fails=5 fail_timeout=10s weight=10;
server 127.0.0.1:82 max_fails=5 fail_timeout=10s weight=10;
keepalive 300;
}
server {
listen 9898;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Ssl on;
proxy_set_header X-Forwarded-Port $server_port;
location /{
proxy_pass http://test_serves;
}
}
长连接配置指令说明见下表:
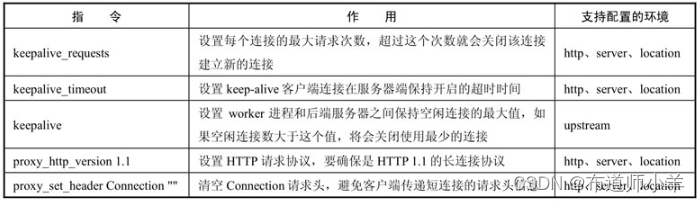
注意:如果没有添加长连接,在压力测试(以下简称压测)环境中,可能会出现这样的情景:当压测达到一定的QPS(Query Per Second,每秒查询率)后,Nginx服务器突然“卡死”,QPS直接降到几乎为0,但是压测并没有停;几分钟后又会自动恢复,然后再压测一段时间后,QPS 又会突然降到接近于0。这种情况就要考虑是不是timewait的状态过多了。
5.6、利用resolver加速对内部域名的访问
proxy_pass可以直接将域名代理到后端服务器上,请求前会先解析出IP地址,例如:
proxy_pass http:// www.baidu.com
反复的DNS(Domain Name System,域名系统)解析会影响请求的速度,并且如果出现连接DNS服务器超时的情况,可能会导致请求无法发送,这里需要用DNS缓存来解决这个问题,示例代码如下:
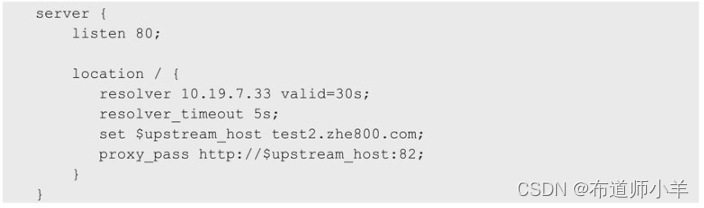
resolver指令说明见下表:

注意:解析DNS后,通过set $upstream_host test2.zhe800.com的方式,将获取的IP地址再赋值给proxy_pass,这是为了让Nginx重新去解析DNS中的IP地址。利用valid的配置,可以减少DNS的解析次数,从而提高请求的效率。当然对DNS缓存时间的控制也要有度,避免出现DNS切换IP地址后,Nginx无法快速切换到新IP地址的情况。
如果需要在upstream内部对域名的配置进行解析,使用Nginx的开源版会受到一些限制,因为此功能被放到了商业版中,需要和zone的功能配合使用。
6、rewrite使用手册
rewrite是ngx_http_rewrite_module模块下的指令,使用频率非常高,本节会列举一些rewrite的常见配置。
6.1、内部重定向
rewrite支持的配置环境有server、location、if,它通过break和last来完成内部重定向功能。内部重定向是在Nginx内部发送请求的操作,它可以将请求转发到其他的location或对URL进行修改,而不必通过HTTP连接请求,整个操作非常高效。
相关示例如下:
# 匹配以/a结尾的URI,匹配成功后将其修改成/b的URI,即后端服务看到的URI会是/b,并停止rewrite阶段,执行下一个阶段,即proxy_pass
rewrite /a$ /b break;
# 匹配以/a开头的URI,匹配成功后将其修改成/b的URI,并停止rewtite阶段。执行下一个阶段。即proxy_passs
rewrite ^/a /b break;
# 匹配/a的URI,匹配成功将其修改成/b的URI,并停止rewrite阶段,执行下一个阶段,即proxy_pass
rewrite ^/a$ /b break;
# 匹配以/a/开头的请求,并将/a/后面的URI全部捕获,(。*)的作用就是捕获全部URI,然后重定向成 /b/$1,其中$1就是前面捕获到的URI。并停止rewrite阶段,执行下一个阶段,即proxy_pass
rewrite ^/a/(.*) /b/$1 break;
#last 的匹配规则和break完全一样,只是当它匹配并修改完URI后会将请求从当前的location中“跳”出来,找到对应的location
rewrite /a /b last/;
proxy_pass http://test_servers;
如果需要将内部重定向的请求记录到日志里,清使用rewrite_log;
指令:rewrite_log
语法:rewrite_log on|off;
默认值:rewrite_log off;
环境:http、server、location、if
注意:在rewrite后面跟随的参数始终是正则表达式,并且当内部重定向时URL的参数是不会丢失的。
6.2、域名跳转
通过rewrite可以实现域名间的跳转,常见的跳转类型有301、302。
# permanent 参数表示永久重定向,将所有的请求全部跳转到指定域名上,通过(。*)将URL保留下来,跳转过程中参数不会丢失。HTTP状态码为301
rewrite ^/(.*)$ http://www.baidu.com/$1 permanent;
# permanent 参数表示临时重定向,将所有的请求全部跳转到指定域名上,通过(。*)将URL保留下来,跳转过程中参数不会丢失。HTTP状态码为302
rewrite ^/(.*)$ http://www.baidu.com/$1 erdirect;
永久重定向和临时重定向的区分是为爬取搜索引擎而设置的。如果状态码是301,表示网页地址永久改变,搜索引擎会将旧页面的地址替换成新页面的地址,用户在搜索引擎搜索网站时,就不会再去旧地址了。
如果状态码是302,表示临时重定向,搜索引擎会保留旧页面的地址,因为它认为跳转只是暂时的。当用户使用搜索引擎搜索网站时,会首先进入旧地址然后再被跳转到302指定的新地址。
6.3、跳转POST请求
301和302的跳转并不适合用于POST请求,如果POST请求被跳转的话,会先被转化为GET请求,且请求体的内容会丢失,为此HTTP 1.1提供了新的跳转状态码307和308。
状态码307的意义和302 一样,都是临时重定向;而308和301 一样,都是永久重定向。但如果要求在跳转过程中保持客户端的请求方法不变,需要使用return指令,示例如下:

指令:return
语法:return code [text];
其中code是状态码。return指令会立即返回一个HTTP状态码给客户端,并附加一个文本信息到响应体中,因为此方式缺少Default_Type 响应头,所以当使用浏览器打开时无法直接展示文本信息,而会将文本下载到本地。
return指令用法示例如下:
- return code URL;支持301、302、303、307和308跳转。
- return URL; 默认支持302跳转。
环境:server、location、if
注意:如果把return和proxy_pass配置为同一级别,那么会直接执行return,而不会执行proxy_pass,同一location块下的其他指令也不会再被执行。
6.4、设置变量的值
指令:set
语法:set $variable value;
环境:server、location、if
含义:设置指定变量的值,值可以是文本、变量或文本和变量的组合。因为是为当前请求设置的值,所以会在请求结束后被清除掉。
location /{
set $a '1';
set $b '2';
set $ab $a$b; # 可以合并两个变量的值
return 200 $ab; # 输出为12,状态码为200
}
7、限速白名单
Nginx提供了ngx_http_limit_req_module和ngx_http_limit_conn_module等模块来完成限制请求访问的功能,可以对请求的访问频率、User-Agent、带宽等各种条件进行限速。
例如当User-Agent有问题时,要对其进行限速,则代码如下:
# 当匹配到MSIE类型的用户时,客户端限速2kb/s
if ($http_user_agent ~* "MSIE"){
limit_rate 2k;
}
限速一般会对请求的访问频率进行控制,但如果有些请求是内部访问不需要限速该如何处理呢?相关配置如下所示:


注意:整个配置都在http块内。
8、日志
Nginx通过ngx_http_log_module来对日志的记录进行配置。
8.1、记录自定义变量
指令:log_format
语法:log_format name [escape=default|json|none] string …;
默认值:log_format combined “…”;
环境:http含义:配置日志的格式。
绝大部分请求信息都可以通过Nginx现有的变量来获取,例如常见的Cookie、IP地址、User_Agent、请求体大小、单个请求头、server_ip、后端节点和端口号等。当然还有自定义变量,如需将自定义变量存放到日志中,只需简单的两步。
使用自定义变量前需要先进行初始化:set $a '123'
为自定义变量添加日志格式:log_fromat main remote_addr-$remote_user [$time_local] $a"
8.2、日志格式规范
日志经常会被用来分析和查找问题,为了提升日志的可读性,需要规范日志的格式以减少解析日志时出现的麻烦。
在Nginx 1.11.8版本之后,提供了[escape=default|json|none]配置,它可以让Nginx在记录变量时使用JSON格式或默认字符。如果使用默认字符则会被转义,特别是当POST请求中包含中文字符或需要转义的字符时,默认转义的操作会使日志无法记录明确的信息。
日志记录推荐使用如下格式:

使用escape=json 则日志内容不会被转义,中文字符可以直接在日志里面显示。日志的格式采用JSON的方式进行配置,对后期的数据采集会有很大的帮助,当在日志里添加新的变量时,不会影响日志分析的流程。
8.3、日志存储
日志存储通过access_log来完成。
指令:access_log
语法:access_log path [format [buffer=size] [gzip[=level]] [flush=time][if=condition]];access_log off;默认值:access_log logs/access.log combined;
环境:http、server、location、if in location、limit_except
注意:日志应该存放在独立的硬盘上,最好和系统盘及存放Nginx配置文件的硬盘相互独立,避免让日志硬盘的I/O影响服务器的其他服务。在高并发的情况下,可能每秒会生成几十兆的日志。
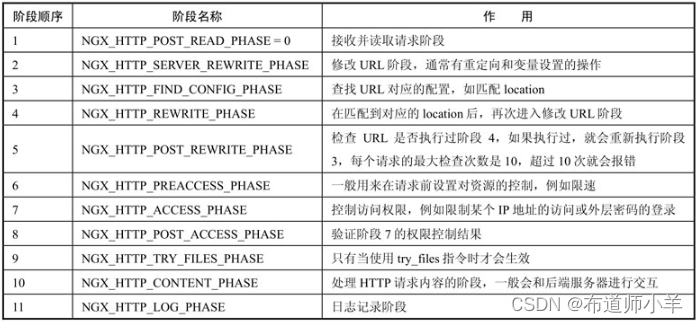
9、HTTP执行阶段
Nginx对请求的处理发生在多个HTTP执行阶段,前面介绍的指令都是在这些阶段中执行的,了解这些阶段的执行顺序和用途,对后续原生模块、第三方模块的学习,以及使用Lua开发新的功能都有非常重要的作用。
HTTP执行阶段配置在ngx_http_core_module中,下载Nginx的源码包后在src/http/ngx_http_core_module.h中可以看到。
下面是ngx_http_core_module.h中的一段源码:

通过上述配置,可以看出Nginx包含11个阶段,当请求进入Nginx后,每个HTTP执行阶段的作用见下表(按照执行顺序进行排列)。