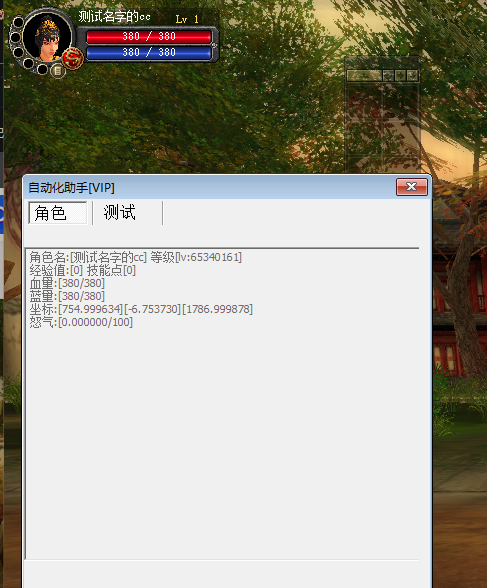
基于扩散的视频编辑已经取得了令人瞩目的质量,可以根据文本编辑提示转换给定视频输入的全局风格、局部结构和属性。然而,这类解决方案通常需要大量的内存和计算成本来生成时间上连贯的帧,无论是以扩散反演还是跨帧注意力的形式。在本文中,我们对这些低效性进行了分析,并提出了简单而有效的修改,可以在保持质量的同时实现显著的加速。此外,我们引入了Object-Centric Diffusion,简称OCD,通过将计算更多地分配到在感知质量上可能更重要的前景编辑区域,进一步减少延迟。我们通过两个新颖的提议实现了这一点:i)Object-Centric Sampling,将分配给显着区域或背景的扩散步骤解耦,将模型容量的大部分分配给前者;ii)Object-Centric 3D Token Merging,通过融合不重要的背景区域中的冗余标记,降低了跨帧注意力成本。这两种技术都可以轻松应用于给定的视频编辑模型,无需重新训练,并且可以显著降低其内存和计算成本。我们在基于反演和基于控制信号的编辑pipeline上评估了方法,并展示了在可比较的综合质量下延迟减少达到10倍的效果。
主要贡献
总结下来本文贡献如下:
-
分析了最近基于反演的视频编辑方法的成本和低效性,并提出了简单的方法,显著提高了它们的速度。
-
引入了Object-Centric Sampling,它将编辑对象和背景区域的扩散采样分开,将大部分去噪步骤限制在前者,以提高效率。
-
引入了Object-Centric 3D ToMe,通过主要在背景区域融合冗余的跨帧注意力标记,减少了跨帧注意的标记数量。
-
通过优化两个最近的视频编辑模型展示了OCD的有效性,实现了非常快的编辑速度,而不损害保真度。
方法
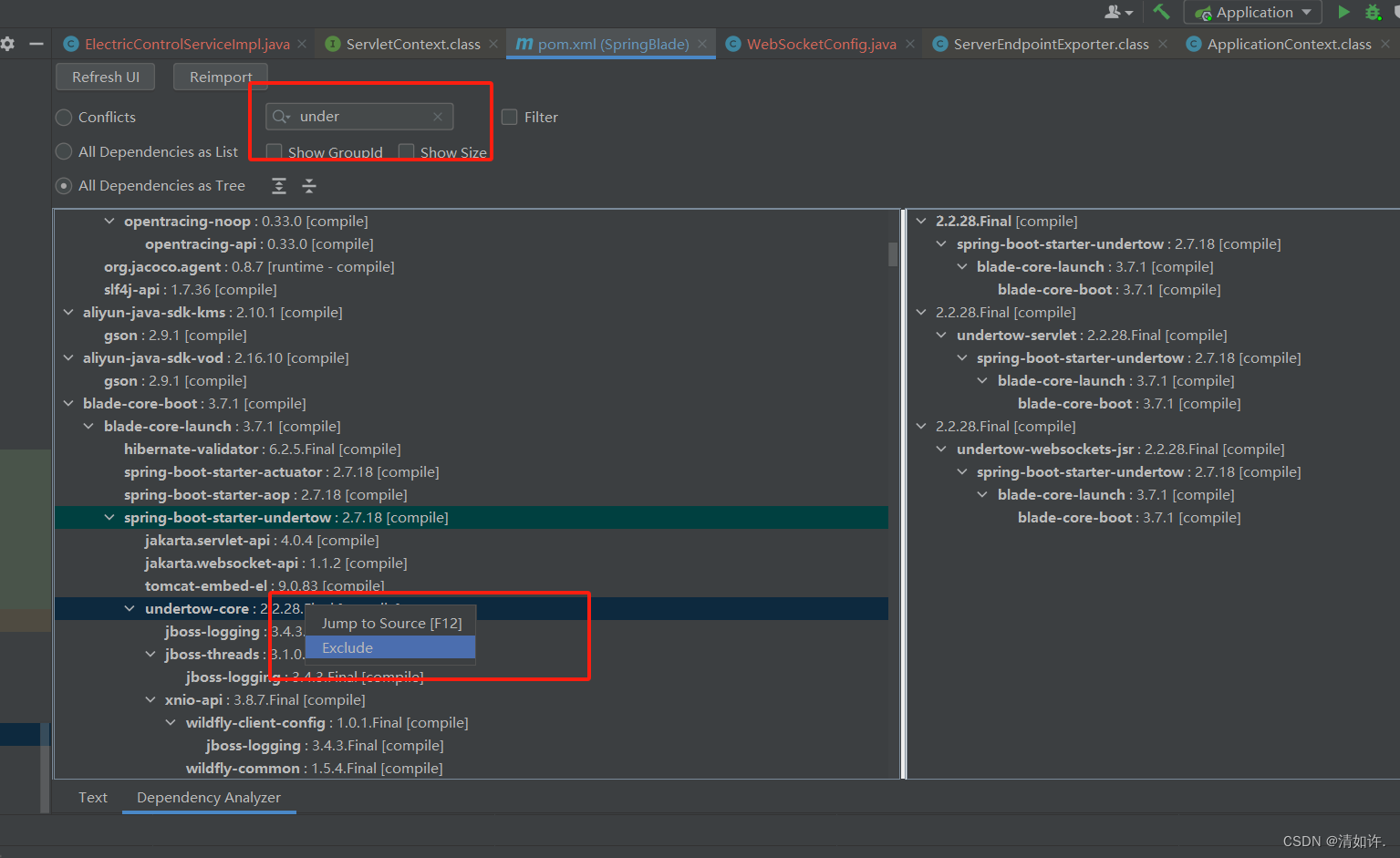
现成的加速方法: 通过采用现成的技术并进行一些非平凡的修改,获得了显著的延迟优势。如下图3所示,首先,我们用 DPM++替换 (b) 默认的 DDIM采样器,这使能够将采样步骤从 50 减少到 20 而不会严重降低质量。接下来,应用 ToMe 以减少由于注意力模块引起的内存和计算开销。尽管加速了生成过程,但生成结果明显变差 (d)。为了解决这个问题,我们实施了 (e) 在反演和生成之间对标记位置(目标和未合并源)进行配对,以及 (f) 对每一帧重新采样目标标记位置,从而恢复了质量。总体来说,这些优化的结果被称为 Optimized-FateZero。

如下面算法1所述,根据前景掩码m(例如,在视频数据集中通常可用的分割掩码或来自检测器)将潜变量划分为前景和背景潜变量,分别表示为和。并不对前景和背景区域运行相同数量的采样步骤,而是基于超参数φ减少背景上的采样步骤。为了避免在前景和背景之间生成不一致的结果,在由超参数γ指定的某个采样步骤合并去噪的潜变量。经验证明,将大约25%的采样步骤分配给这个混合阶段通常足以生成在空间和时间上一致的帧。

目标中心的3D token合并: 通过人为地降低前景对象的源tokens之间的相似性,在它们的位置上累积未合并的tokens(蓝色)。目标tokens(红色)仍然在网格内随机采样,保留一些背景信息。已合并的源tokens(为避免混乱而未表示)将来自背景。如下图4所示:

效果比较
与最先进技术的定性比较: 展示了使用我们的方法编辑的视频帧,与FateZero 、Tune-A-Video、TokenFlow 和SDEdit的输出进行比较。在这里,Tune-A-Video 始终是对每个序列进行1-shot微调(用*表示),而其他方法是zero-shot。我们的方法在保持质量的同时比基于其上构建的基线(即FateZero)生成速度显着更快。与其他最先进的视频基线相比,它还更高效。

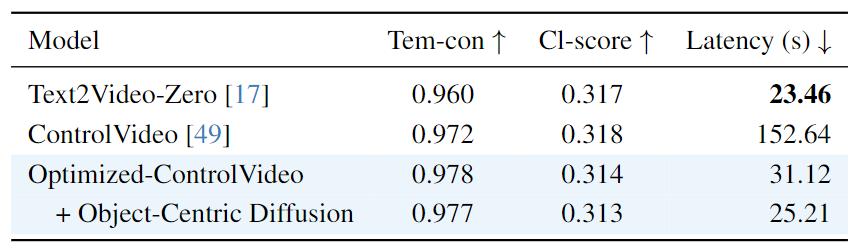
与基于反演的视频编辑流程的定量比较: 在这里,考虑了FateZero的基准设置。报告了CLIP指标的保真度(时态一致性、CLIP分数)和延迟。我们的方法在不牺牲生成质量的情况下,相较于基线和其他最先进的方法(无论是视频还是逐帧),取得了显著的加速。

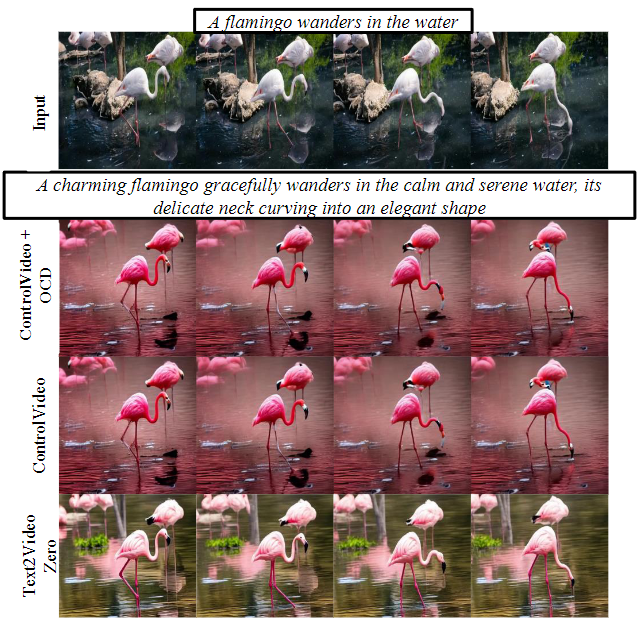
在ControlVideo设置中的定性比较: 展示了使用我们的方法编辑的视频帧,与ControlVideo 进行了比较。两种方法都使用深度调节。我们的方法在保持不可区分或可比较的编辑质量的情况下,将延迟降低了6倍。

与基于ControlNet的视频编辑流程的定量比较: 在ControlVideo 基准设置中使用深度调节计算的保真度(时态一致性、CLIP分数)和延迟的CLIP指标。在具有可比较生成质量的情况下,我们的方法相对于基线实现了显著的6倍加速。
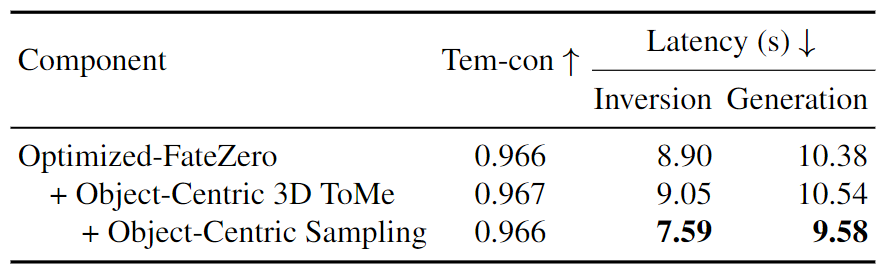
本文贡献定性分析: 展示了使用Optimized-FateZero、Object-Centric 3D ToMe以及Object-Centric 3D ToMe + Object-Centric Sampling (OCD)进行编辑的帧和延迟。我们使用红色轮廓突出生成中的伪影。计时报告为反演/生成。如下图7所示:

本文贡献量化分析: 在这里,我们考虑FateZero基准设置。Object-Centric 3D ToMe在不牺牲延迟的情况下改善了时域一致性和保真度(请参阅上图7以进行定性比较)。通过在其上应用Object-Centric Sampling,看到了延迟的进一步改善,实现了最快的生成。
在不同目标尺寸下Object-Centric Sampling的影响:在这里,我们设计了一个新的基准,具有大、中和小的前景对象。在较小的前景对象中实现了更多的延迟节省,而不会牺牲生成质量,同时还提供了更真实的背景区域重建(参见上面的图7的最后两行)。

总结
本文介绍了一些用于加速基于扩散的视频编辑的解决方案。在这方面,首先对反演模型的延迟来源进行了分析,并识别和采用了一些现成的技术,如快速采样和 Token Merging,经过适当修改后,这些技术能够在不牺牲生成质量的情况下显著降低成本。此外,由于视频编辑通常需要对特定对象进行修改,我们引入了Object-Centric Diffusion,包括:i) 仅在背景区域合并tokens的技术,以及 ii) 在前景区域限制大部分扩散采样步骤的技术。我们在基于反演的模型和基于 ControlNet 的模型上验证了我们的解决方案,在这两种情况下,我们的策略分别实现了10倍和6倍的更快编辑。




参考文献
[1] Object-Centric Diffusion for Efficient Video Editing
链接:https://arxiv.org/pdf/2401.05735
更多精彩内容,请关注公众号:AI生成未来