所讨论文件大多位于src\common\backend\parser文件夹下
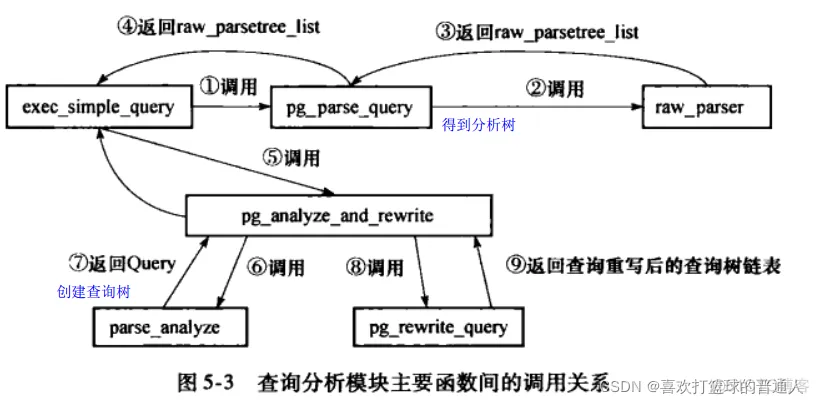
总流程

- start_xact_command():开始一个事务。
- pg_parse_query():对查询语句进行词法和语法分析,生成一个或者多个初始的语法分析树。
- 进入foreach (parsetree_item, parsetree_list)循环,对每个语法分析树执行查询。
- pg_analyze_and_rewrite():根据语法分析树生成基于Query数据结构的逻辑查询树,并进行重写等操作。
- pg_plan_queries():对逻辑查询树进行优化,生成查询计划。
- CreatePortal():创建Portal, Portal是执行SQL语句的载体,每一条SQL对应唯一的Portal。
- PortalStart():负责进行Portal结构体初始化工作,包括执行算子初始化、内存上下文分配等。
- PortalRun():负责真正的执行和运算,它是执行器的核心。
- PortalDrop():负责最后的清理工作,主要是数据结构、缓存的清理。
- finish_xact_command():完成事务提交。
- EndCommand():通知客户端查询执行完成。
进一步的函数调用关系
parse_analyze(Node* parseTree, const char* sourceText, Oid* paramTypes, int numParams, bool isFirstNode, bool isCreateView)
返回值:Query*
作用:负责sql语句的语义分析阶段,将输入的语法分析后的语法树转换成查询树(不只是select语句)即Query结构体,
实现:
Query* parse_analyze(
Node* parseTree, const char* sourceText, Oid* paramTypes, int numParams, bool isFirstNode, bool isCreateView)//parseTree是语法分析后的语法树,sourceText是整个sql语句(即使是嵌套查询),Oid* paramTypes, int numParams见补充部分,isFirstNode表示当前解析的节点是否是整个查询中的第一个节点???,isCreateView即是否创建视图
{
ParseState* pstate = make_parsestate(NULL);//为语义分析的状态结构体分配内存且初始化
Query* query = NULL;
pstate->p_sourcetext = sourceText;
//最关键函数transformTopLevelStmt,开始分析语法树
query = transformTopLevelStmt(pstate, parseTree, isFirstNode, isCreateView);
//用完就释放pstate内存
pfree_ext(pstate->p_ref_hook_state);
pstate->rightRefState = nullptr;
free_parsestate(pstate);
query->fixed_paramTypes = paramTypes;
query->fixed_numParams = numParams;
return query;
}
补充:
入参中的Oid* paramTypes, int numParams是什么?
举个例子,在C++中使用类似于 PostgreSQL 的 libpq 客户端库执行查询时,可以通过绑定变量的方式来提供参数值。示例代码可能如下:
PGresult* result;
const char* paramValues[1];
paramValues[0] = "some_value"; // 用实际的参数值替代占位符
result = PQexecParams(conn, "SELECT column1 FROM table1 WHERE column2 = $1;", 1, NULL, paramValues, NULL, NULL, 0);
具体来说,$1 是一个编号为 1 的参数占位符,表示在实际执行查询时,需要提供一个对应的值作为参数。这个值需要动态地提供。
Oid paramTypes[] = { TEXTOID }; // 数据类型为文本(字符串)
int numParams = 1; // 参数数量为 1
此处Oid本质是uint(通过typedef实现),下面是一些规定好的有意义的值(也是可以取其他值的,这样具体代表了一个表或索引或别的),Oid代表了参数的类型
#define FLOAT4OID 700
#define FLOAT8OID 701
#define INTERVALOID 1186
#define BOOLOID 16
#define INT8OID 20
#define INT2OID 21
#define INT4OID 23
#define TEXTOID 25
#define VARCHAROID 1043
#define NUMERICOID 1700
#define INT1OID 5545
#define CSTRINGOID 2275
#define FLOAT8ARRAYOID 1022
#define BOOLARRAYOID 1000
#define TEXTARRAYOID 1009
#define INT4ARRAYOID 1007
#define TIMESTAMPOID 1114
#define BPCHAROID 1042
transformTopLevelStmt(ParseState* pstate, Node* parseTree, bool isFirstNode, bool isCreateView)
返回值:Query*
作用:
实现:
Query* transformTopLevelStmt(ParseState* pstate, Node* parseTree, bool isFirstNode, bool isCreateView)
{
//如果是select语句则需要进行一些特殊处理
if (IsA(parseTree, SelectStmt)) {
/*虽然parseTree看起来只是Node类型,而Node也仅有NodeTag属性,
而实际上Node是一个父类,SelectStmt、DeleteStmt等都是继承(通过将Node作为自己的属性实现)自Node,
这些子类有很多其他属性,这在语法解析时即.y文件在遇到各种sql语句时会生成对应XXXStmt,
并根据该sql语句为XXXStmt各个属性赋值。Node是这些子类共有父类,所以适合作为参数类型传入,
到时候只需要类型转换一下就实现了多态的功能*/
SelectStmt* stmt = (SelectStmt*)parseTree;
/*如果select语句涉及到set操作(如UNION、INTERSECT、EXCEPT等)
则寻找并指向语法树中的最左子树(即最左select语句)
因为是set操作都是左结合的即先按顺序把左边的算完再和右边的搞
SELECT column1 FROM table1
UNION
SELECT column2 FROM table2
INTERSECT
SELECT column3 FROM table3;
在这个例子中,UNION 先于 INTERSECT 执行,因为它们从左到右结合。在处理这样的查询时,通常需要先处理最左边的 SELECT 语句,然后逐步处理右侧的语句,而生成的语法树中,intersect操作是union操作的父,union左右孩子对应着上面的select语句。*/
while (stmt != NULL && stmt->op != SETOP_NONE)
stmt = stmt->larg;
/*先特殊处理一下含有into子句的select语句,从语法树中提取并单独处理,
然后将into从句从原始SelectStmt中移除*/
if (stmt->intoClause) {
parseTree = parse_into_claues(parseTree, stmt->intoClause);//将into语句等价转换为CREATE TABLE AS,因为into功能上本就是将结果放到into后面跟的名字的表中,通常是临时生成的存在于内存的表,所以就需要创建一个表
stmt->intoClause = NULL;
}
}
/*检查是否存在用户自定义的转换钩子函数,
如果存在,则调用用户自定义的钩子函数进行语句转换。但一般不会有所以不用管*/
if (u_sess->hook_cxt.transformStmtHook != NULL) {
return
((transformStmtFunc)(u_sess->hook_cxt.transformStmtHook))(pstate, parseTree, isFirstNode, isCreateView);
}
//最关键函数transformStmt
return transformStmt(pstate, parseTree, isFirstNode, isCreateView);
transformStmt(ParseState* pstate, Node* parseTree, bool isFirstNode, bool isCreateView)
返回值:Query*
作用:
实现:
Query* transformStmt(ParseState* pstate, Node* parseTree, bool isFirstNode, bool isCreateView)
{
Query* result = NULL;
/*根据语法树根节点判断sql语句的类型,
并强转为对应sql类型进行对应处理,
nodeTag函数就是获取type属性*/
switch (nodeTag(parseTree)) {
//插入语句
case T_InsertStmt:
result = transformInsertStmt(pstate, (InsertStmt*)parseTree);
break;
//删除语句
case T_DeleteStmt:
result = transformDeleteStmt(pstate, (DeleteStmt*)parseTree);
break;
case T_UpdateStmt:
result = transformUpdateStmt(pstate, (UpdateStmt*)parseTree);
break;
case T_MergeStmt:
result = transformMergeStmt(pstate, (MergeStmt*)parseTree);
break;
//查找语句,
case T_SelectStmt: {
SelectStmt* n = (SelectStmt*)parseTree;
/*下面这种情况一般不常用但仍要处理
SELECT * FROM (VALUES
(1, 'John Doe', 50000),
(2, 'Jane Smith', 60000),
(3, 'Bob Johnson', 55000)
) AS employees(id, name, salary);
在这个例子中,valuesLists 是一个包含了三个子链表的主链表。
每个子链表表示 VALUES 子句中的一行值*/
if (n->valuesLists) {
result = transformValuesClause(pstate, n);
}
//set操作两端的select节点的op都会被设置,这里处理的是无set操作的select
else if (n->op == SETOP_NONE) {
result = transformSelectStmt(pstate, n, isFirstNode, isCreateView);
}
//处理含set操作的select
else {
result = transformSetOperationStmt(pstate, n);
}
} break;
/*
* Special cases
*/
case T_DeclareCursorStmt:
result = transformDeclareCursorStmt(pstate, (DeclareCursorStmt*)parseTree);
break;
case T_ExplainStmt:
result = transformExplainStmt(pstate, (ExplainStmt*)parseTree);
break;
#ifdef PGXC
case T_ExecDirectStmt:
result = transformExecDirectStmt(pstate, (ExecDirectStmt*)parseTree);
break;
#endif
case T_CreateTableAsStmt:
result = transformCreateTableAsStmt(pstate, (CreateTableAsStmt*)parseTree);
break;
case T_CreateModelStmt:
result = transformCreateModelStmt(pstate, (CreateModelStmt*) parseTree);
break;
case T_PrepareStmt: {
PrepareStmt* n = (PrepareStmt *)parseTree;
if (IsA(n->query, UserVar)) {
Node *uvar = transformExpr(pstate, n->query, EXPR_KIND_OTHER);
n->query = (Node *)copyObject((UserVar *)uvar);
}
result = makeNode(Query);
result->commandType = CMD_UTILITY;
result->utilityStmt = (Node*)parseTree;
} break;
case T_VariableSetStmt: {
VariableSetStmt* stmt = (VariableSetStmt*)parseTree;
if (DB_IS_CMPT(B_FORMAT) && stmt->kind == VAR_SET_VALUE &&
(u_sess->attr.attr_common.enable_set_variable_b_format || ENABLE_SET_VARIABLES)) {
transformVariableSetValueStmt(pstate, stmt);
}
result = makeNode(Query);
result->commandType = CMD_UTILITY;
result->utilityStmt = (Node*)parseTree;
} break;
case T_VariableMultiSetStmt:
result = transformVariableMutiSetStmt(pstate, (VariableMultiSetStmt*)parseTree);
break;
case T_CreateEventStmt:
result = transformVariableCreateEventStmt(pstate, (CreateEventStmt*) parseTree);
break;
case T_AlterEventStmt:
result = transformVariableAlterEventStmt(pstate, (AlterEventStmt*) parseTree);
break;
case T_CompositeTypeStmt:
result = TransformCompositeTypeStmt(pstate, (CompositeTypeStmt*) parseTree);
break;
default:
/*
* other statements don't require any transformation; just return
* the original parsetree with a Query node plastered on top.
*/
result = makeNode(Query);
result->commandType = CMD_UTILITY;
result->utilityStmt = (Node*)parseTree;
break;
}
/* To be compatible before multi-relation modification supported. */
result->resultRelation = linitial2_int(result->resultRelations);
/* Mark as original query until we learn differently */
result->querySource = QSRC_ORIGINAL;
result->canSetTag = true;
/* Mark whether synonym object is in rtables or not. */
result->hasSynonyms = pstate->p_hasSynonyms;
result->is_flt_frame = pstate->p_is_flt_frame && !IS_ENABLE_RIGHT_REF(pstate->rightRefState);
if (nodeTag(parseTree) != T_InsertStmt) {
result->rightRefState = nullptr;
}
PreventCommandDuringSSOndemandRedo(parseTree);
return result;
}
transformSelectStmt(ParseState* pstate, SelectStmt* stmt, bool isFirstNode, bool isCreateView)
返回值:Query*
作用:
实现:
static Query* transformSelectStmt(ParseState* pstate, SelectStmt* stmt, bool isFirstNode, bool isCreateView)
{
Query* qry = makeNode(Query);
Node* qual = NULL;
ListCell* l = NULL;
qry->commandType = CMD_SELECT;
/*看补充了解startWith从句的作用,
其实postgres正式支持的是with recursive,
不过也兼容了oracle原本特有的start with
因此当用户用了start with
那么这里startWithClause属性就是非空*/
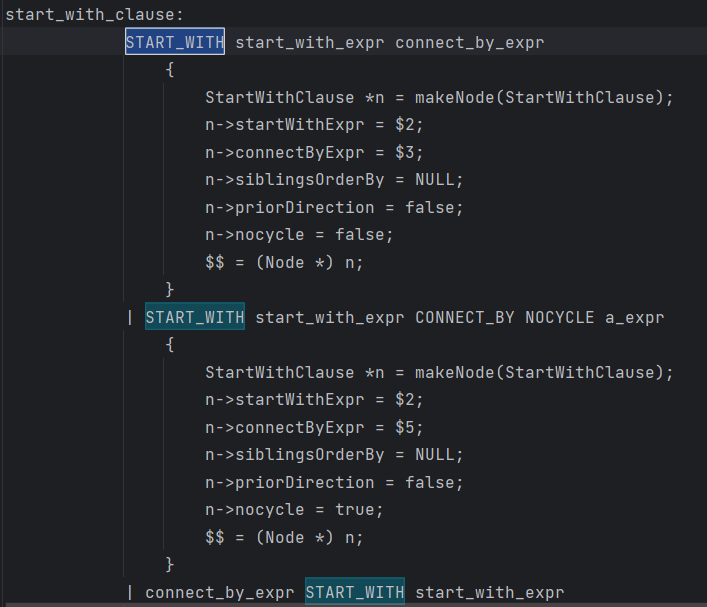
if (stmt->startWithClause != NULL) {
/*用于指示是否要在解析 SELECT 语句时
添加(作为start with的)起始条件信息*/
pstate->p_addStartInfo = true;
//tbc
pstate->p_sw_selectstmt = stmt;
//tbc
pstate->origin_with = (WithClause *)copyObject(stmt->withClause);
}
//with从句
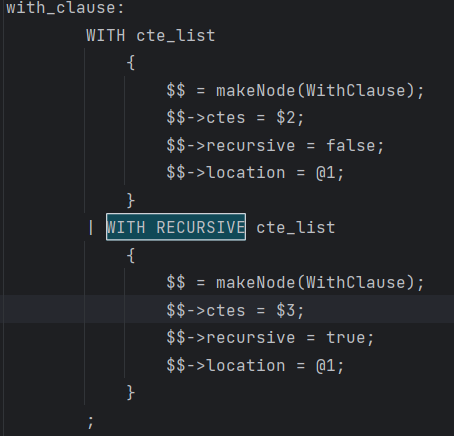
if (stmt->withClause) {
//stmt->withClause->recursive在语法分析时(具体可见gram.y文件)根据WITH RECURSIVE语句设置为true,WITH时为false
qry->hasRecursive = stmt->withClause->recursive;
/*使用 transformWithClause 函数处理 WITH 子句,
用List的一个个ListCell装着WITH子句中的CTE
下面是一个WITH子句含多个CTE的sql实例:
WITH
cte1 AS (SELECT * FROM table1),
cte2 AS (SELECT * FROM table2)*/
qry->cteList = transformWithClause(pstate, stmt->withClause);
/*p_hasModifyingCTE 表示 WITH 子句中是否包含修改数据的 CTE
(例如,包含 INSERT、UPDATE 或 DELETE 操作的 CTE),
但一般不会,我们只需focus于select的情况,
示例如下:
WITH
inserted_employee AS (
INSERT INTO employees (name,
department_id) VALUES
('John Doe', 1) RETURNING *
)*/
qry->hasModifyingCTE = pstate->p_hasModifyingCTE;
}
//将查询的锁定子句(FOR UPDATE 或 FOR SHARE)存储在解析状态的上下文中,以便后续处理。tbc
pstate->p_locking_clause = stmt->lockingClause;
/*将查询的窗口子句信息存储在解析状态的上下文中,
以便在后续处理中使用。
窗口函数通常需要窗口定义信息。tbc*/
pstate->p_windowdefs = stmt->windowClause;
/*最关键函数,
解析from从句即from后面跟的若干个表 */
transformFromClause(pstate, stmt->fromClause, isFirstNode, isCreateView);
/*处理表的索引提示,将索引提示信息存储在查询的上下文中。tbc*/
qry->indexhintList = lappend3(qry->indexhintList, pstate->p_indexhintLists);
/* 处理oracle的START WITH从句*/
if (shouldTransformStartWithStmt(pstate, stmt, qry)) {
transformStartWith(pstate, stmt, qry);
}
/* transform targetlist */
qry->targetList = transformTargetList(pstate, stmt->targetList, EXPR_KIND_SELECT_TARGET);
/* Transform operator "(+)" to outer join */
if (stmt->hasPlus && stmt->whereClause != NULL) {
transformOperatorPlus(pstate, &stmt->whereClause);
}
qry->starStart = list_copy(pstate->p_star_start);
qry->starEnd = list_copy(pstate->p_star_end);
qry->starOnly = list_copy(pstate->p_star_only);
/* mark column origins */
markTargetListOrigins(pstate, qry->targetList);
/* transform WHERE
* Only "(+)" is valid when it's in WhereClause of Select, set the flag to be trure
* during transform Whereclause.
*/
setIgnorePlusFlag(pstate, true);
qual = transformWhereClause(pstate, stmt->whereClause, EXPR_KIND_WHERE, "WHERE");
setIgnorePlusFlag(pstate, false);
/*
* Initial processing of HAVING clause is just like WHERE clause.
*/
qry->havingQual = transformWhereClause(pstate, stmt->havingClause, EXPR_KIND_HAVING, "HAVING");
pstate->shouldCheckOrderbyCol = (!ALLOW_ORDERBY_UNDISTINCT_COLUMN &&
stmt->distinctClause && linitial(stmt->distinctClause) == NULL &&
!IsInitdb && DB_IS_CMPT(B_FORMAT));
/*
* Transform sorting/grouping stuff. Do ORDER BY first because both
* transformGroupClause and transformDistinctClause need the results. Note
* that these functions can also change the targetList, so it's passed to
* them by reference.
*/
qry->sortClause = transformSortClause(
pstate, stmt->sortClause, &qry->targetList, EXPR_KIND_ORDER_BY, true /* fix unknowns */, false /* allow SQL92 rules */);
pstate->shouldCheckOrderbyCol = false;
/*
* Transform A_const to columnref type in group by clause, So that repeated group column
* will deleted in function transformGroupClause. If not to delete repeated column, for
* group by rollup can have error result, because we need set null to non- group column.
*
* select a, b, b
* from t1
* group by rollup(1, 2), 3;
*
* To this example, column b should not be set to null, but if not to delete repeated column
* b will be set to null and two b value is not equal.
*/
if (include_groupingset((Node*)stmt->groupClause)) {
transformGroupConstToColumn(pstate, (Node*)stmt->groupClause, qry->targetList);
}
qry->groupClause = transformGroupClause(pstate,
stmt->groupClause,
&qry->groupingSets,
&qry->targetList,
qry->sortClause,
EXPR_KIND_GROUP_BY,
false /* allow SQL92 rules */);
if (stmt->distinctClause == NIL) {
qry->distinctClause = NIL;
qry->hasDistinctOn = false;
} else if (linitial(stmt->distinctClause) == NULL) {
/* We had SELECT DISTINCT */
qry->distinctClause = transformDistinctClause(pstate, &qry->targetList, qry->sortClause, false);
qry->hasDistinctOn = false;
} else {
/* We had SELECT DISTINCT ON */
qry->distinctClause =
transformDistinctOnClause(pstate, stmt->distinctClause, &qry->targetList, qry->sortClause);
qry->hasDistinctOn = true;
}
/* transform LIMIT */
qry->limitOffset = transformLimitClause(pstate, stmt->limitOffset, EXPR_KIND_OFFSET, "OFFSET");
qry->limitCount = transformLimitClause(pstate, stmt->limitCount, EXPR_KIND_LIMIT, "LIMIT");
/* transform window clauses after we have seen all window functions */
qry->windowClause = transformWindowDefinitions(pstate, pstate->p_windowdefs, &qry->targetList);
/* resolve any still-unresolved output columns as being type text */
if (pstate->p_resolve_unknowns) {
resolveTargetListUnknowns(pstate, qry->targetList);
}
qry->rtable = pstate->p_rtable;
qry->jointree = makeFromExpr(pstate->p_joinlist, qual);
qry->hasSubLinks = pstate->p_hasSubLinks;
qry->hasWindowFuncs = pstate->p_hasWindowFuncs;
if (pstate->p_hasWindowFuncs) {
parseCheckWindowFuncs(pstate, qry);
}
qry->hasTargetSRFs = pstate->p_hasTargetSRFs;
qry->hasAggs = pstate->p_hasAggs;
foreach (l, stmt->lockingClause) {
transformLockingClause(pstate, qry, (LockingClause*)lfirst(l), false);
}
qry->hintState = stmt->hintState;
/*
* If query is under one insert statement and include a foreign table,
* then set top level parsestate p_is_foreignTbl_exist to true.
*/
if (u_sess->attr.attr_sql.td_compatible_truncation && u_sess->attr.attr_sql.sql_compatibility == C_FORMAT &&
pstate->p_is_in_insert && checkForeignTableExist(pstate->p_rtable))
set_ancestor_ps_contain_foreigntbl(pstate);
assign_query_collations(pstate, qry);
/* this must be done after collations, for reliable comparison of exprs */
if (pstate->p_hasAggs || qry->groupClause || qry->groupingSets || qry->havingQual) {
parseCheckAggregates(pstate, qry);
}
/*
* If SelectStmt has been rewrite by startwith/connectby, it should
* return as With-Recursive for upper level. So we need to fix fromClause.
*/
if (pstate->p_addStartInfo) {
AdaptSWSelectStmt(pstate, stmt);
}
return qry;
}
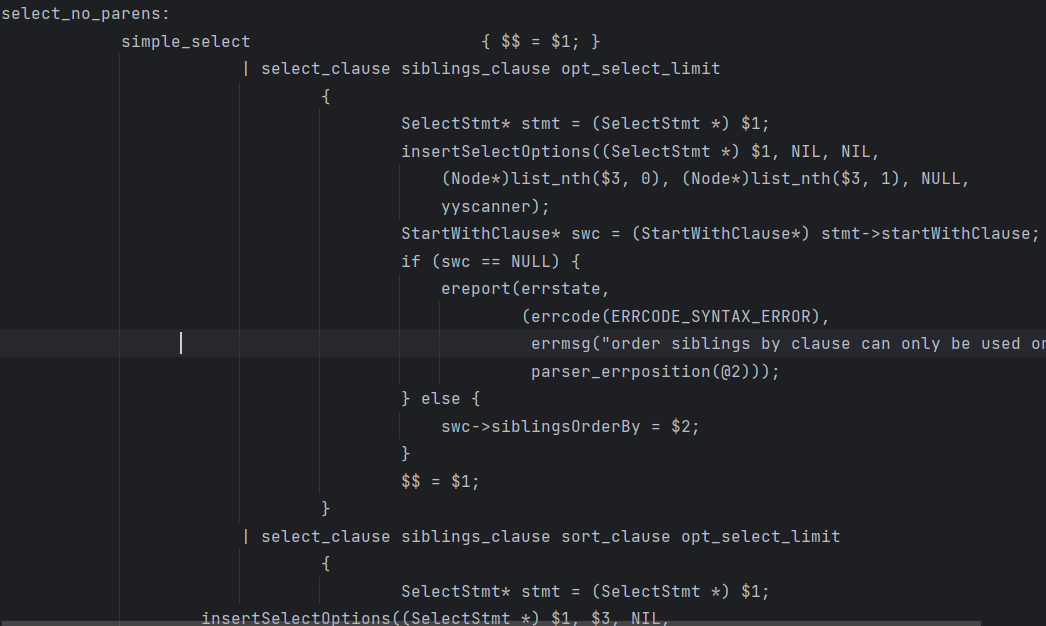
补充:
CTE是Common Table Expression,在 SQL 查询中定义临时结果集的方式,类似于一个命名的子查询,可以在查询的其他部分引用
start with类型语句用于处理递归查询,START WITH是Oracle特有的,WITH RECURSIVE这个称呼更常见,如PostgreSQL 和 MySQL,因为是 SQL 标准的一部分,二者功能相似
下面是员工表,manager_id代表了该员工的直属领导是哪个员工,为NULL时代表此人是最高领导
emp_id | name | manager_id
--------+---------+------------
1 | David | 2
2 | Bob | 1
3 | Eve | 2
4 | Alice | NULL
5 | Charlie | 1
假设我们想要根据manager_id形成自上而下的层级关系的表(表中的元组越靠上面身份越高级),则按照下列sql语句可实现:
WITH RECURSIVE EmployeeHierarchy AS (
SELECT emp_id, name, manager_id
FROM employees
WHERE manager_id IS NULL//这里代表将临时表EmployeeHierarchy初始化为该select语句的结果
UNION
//下面是对临时表EmployeeHierarchy的递归操作
SELECT e.emp_id, e.name, e.manager_id
FROM employees e, EmployeeHierarchy eh
ON e.manager_id = eh.emp_id
)
SELECT * FROM EmployeeHierarchy;
最终结果如下,根据manager_id形成了层级关系
emp_id | name | manager_id
--------+---------+------------
4 | Alice | NULL
2 | Bob | 1
5 | Charlie | 1
1 | David | 2
3 | Eve | 2
transformFromClause(ParseState* pstate, List* frmList, bool isFirstNode, bool isCreateView, bool addUpdateTable)
作用:
补充:
命名空间,如下sql,cte1处于外部查询的命名空间中,子查询可以引用,但不在子查询的命名空间中(原理是通过遍历当前解析状态的父解析状态的命名空间找到cte1的定义,相当于cte1是父解析状态即外部查询的内部变量)
WITH cte1 AS (
SELECT column1
FROM table1
WHERE condition1
), cte2 AS (
SELECT column2 FROM table2
)
SELECT *
FROM (
SELECT cte1.column1
FROM cte1
);
下面则是一种例子,使得CTE只在子查询的命名空间中(而不在父查询的),又由于只能向上向父的命名空间查找,所以这里的父查询访问不到cte1
SELECT *
FROM (
WITH cte1 AS (
SELECT column1
FROM table1
)
SELECT cte1.column1
FROM cte1
)
实现:
void transformFromClause(ParseState* pstate, List* frmList, bool isFirstNode, bool isCreateView, bool addUpdateTable)
{
ListCell* fl = NULL;
/*
* copy original fromClause for future start with rewrite
*/
if (pstate->p_addStartInfo) {
pstate->sw_fromClause = (List *)copyObject(frmList);
}
foreach (fl, frmList) {
Node* n = (Node*)lfirst(fl);
RangeTblEntry* rte = NULL;
int rtindex;
List* relnamespace = NIL;
//最关键,处理from后面跟着的若干表
n = transformFromClauseItem(
pstate, n, &rte, &rtindex, NULL, NULL, &relnamespace, isFirstNode, isCreateView, false, addUpdateTable);
/* Mark the new relnamespace items as visible to LATERAL */
setNamespaceLateralState(relnamespace, true, true);
checkNameSpaceConflicts(pstate, pstate->p_relnamespace, relnamespace);
pstate->p_joinlist = lappend(pstate->p_joinlist, n);
pstate->p_relnamespace = list_concat(pstate->p_relnamespace, relnamespace);
pstate->p_varnamespace = lappend(pstate->p_varnamespace, makeNamespaceItem(rte, true, true));
}
/*
* We're done parsing the FROM list, so make all namespace items
* unconditionally visible. Note that this will also reset lateral_only
* for any namespace items that were already present when we were called;
* but those should have been that way already.
*/
setNamespaceLateralState(pstate->p_relnamespace, false, true);
setNamespaceLateralState(pstate->p_varnamespace, false, true);
}
transformFromClauseItem(ParseState* pstate, Node* n, RangeTblEntry** top_rte, int* top_rti, RangeTblEntry** right_rte, int* right_rti, List** relnamespace, bool isFirstNode, bool isCreateView, bool isMergeInto, bool addUpdateTable)
返回值:Node*
作用:
实现:
Node* transformFromClauseItem(ParseState* pstate, Node* n, RangeTblEntry** top_rte, int* top_rti,
RangeTblEntry** right_rte, int* right_rti, List** relnamespace, bool isFirstNode,
bool isCreateView, bool isMergeInto, bool addUpdateTable)
{
//如果是from后面跟的是普通的表或者CTE,RangeVar就是普通表的意思
if (IsA(n, RangeVar)) {
/* Plain relation reference, or perhaps a CTE reference */
RangeVar* rv = (RangeVar*)n;
RangeTblRef* rtr = NULL;
RangeTblEntry* rte = NULL;
/*如果该表没有schemaname作为限定则很有可能是CTE*/
if (!rv->schemaname) {
CommonTableExpr* cte = NULL;
Index levelsup;
/*
CommonTableExpr* scanNameSpaceForCTE(ParseState* pstate, const char* refname, Index* ctelevelsup)
{
Index levelsup;
/*levelsup代表当前CTE
位于当前解析状态(即当前子查询)的第几重父解析状态的命名空间,
比如levelsup=2,就代表是当前解析状态的爷解析状态
(即当前解析状态的父解析状态的父解析状态,解析状态可以理解为外部查询)*/
for (levelsup = 0; pstate != NULL; pstate = pstate->parentParseState, levelsup++) {
ListCell* lc = NULL;
foreach (lc, pstate->p_ctenamespace) {
CommonTableExpr* cte = (CommonTableExpr*)lfirst(lc);
if (strcmp(cte->ctename, refname) == 0) {
*ctelevelsup = levelsup;
return cte;
}
}
}
return NULL;
}*/
/*从当前解析状态的命名空间开始遍历搜索是否存在rv->relname这个名字的表
(即with table_name as的table_name,
我们给临时表CTE起的表名,
from从句后面的若干表的表名字符串
会在语法分析时会生成若干RangeVar节点即表,
并对应将表名赋值给RangeVar节点的relname属性,
所以这里就相当于解析with语句结束后
下面的select语句的from从句中对with的CTE的引用),
没有就继续到父解析状态的命名空间遍历找,
以此往复,解析状态的命名空间见补充*/
cte = scanNameSpaceForCTE(pstate, rv->relname, &levelsup);
/*下面这个判断意思是实锤了from后面的入参这个表是CTE,
因为在上面scanNameSpaceForCTE找到了这个临时表(CTE)*/
if (cte != NULL) {
rte = transformCTEReference(pstate, rv, cte, levelsup);
}
}
/* if not found as a CTE, must be a table reference */
if (rte == NULL) {
rte = transformTableEntry(pstate, rv, isFirstNode, isCreateView);
}
rtr = transformItem(pstate, rte, top_rte, top_rti, relnamespace);
/* If UPDATE multiple relations in sql_compatibility B, add target table here. */
if (addUpdateTable) {
pstate->p_updateRelations = lappend_int(pstate->p_updateRelations,
setTargetTable(pstate, rv, interpretInhOption(rv->inhOpt), true, ACL_UPDATE, true));
}
/* add startinfo if needed */
if (pstate->p_addStartInfo) {
AddStartWithTargetRelInfo(pstate, n, rte, rtr);
}
return (Node*)rtr;
} else if (IsA(n, RangeSubselect)) {
/* sub-SELECT is like a plain relation */
RangeTblRef* rtr = NULL;
RangeTblEntry* rte = NULL;
Node *sw_backup = NULL;
if (pstate->p_addStartInfo) {
/*
* In start with case we should back up SubselectStmt for further
* SW Rewrite.
* */
sw_backup = (Node *)copyObject(n);
}
rte = transformRangeSubselect(pstate, (RangeSubselect*)n);
rtr = transformItem(pstate, rte, top_rte, top_rti, relnamespace);
/* add startinfo if needed */
if (pstate->p_addStartInfo) {
AddStartWithTargetRelInfo(pstate, sw_backup, rte, rtr);
/*
* (RangeSubselect*)n is mainly related to RTE during whole transform as pointer,
* so anything fixed on sw_backup could also fix back to (RangeSubselect*)n.
* */
((RangeSubselect*)n)->alias->aliasname = ((RangeSubselect*)sw_backup)->alias->aliasname;
rte->eref->aliasname = ((RangeSubselect*)sw_backup)->alias->aliasname;
}
return (Node*)rtr;
} else if (IsA(n, RangeFunction)) {
/* function is like a plain relation */
RangeTblRef* rtr = NULL;
RangeTblEntry* rte = NULL;
rte = transformRangeFunction(pstate, (RangeFunction*)n);
rtr = transformItem(pstate, rte, top_rte, top_rti, relnamespace);
return (Node*)rtr;
} else if (IsA(n, RangeTableSample)) {
/* TABLESAMPLE clause (wrapping some other valid FROM NODE) */
RangeTableSample* rts = (RangeTableSample*)n;
Node* rel = NULL;
RangeTblRef* rtr = NULL;
RangeTblEntry* rte = NULL;
/* Recursively transform the contained relation. */
rel = transformFromClauseItem(pstate, rts->relation, top_rte, top_rti, NULL, NULL, relnamespace);
if (unlikely(rel == NULL)) {
ereport(
ERROR, (errmodule(MOD_OPT), errcode(ERRCODE_UNEXPECTED_NULL_VALUE), errmsg("rel should not be NULL")));
}
/* Currently, grammar could only return a RangeVar as contained rel */
Assert(IsA(rel, RangeTblRef));
rtr = (RangeTblRef*)rel;
rte = rt_fetch(rtr->rtindex, pstate->p_rtable);
/* We only support this on plain relations */
if (rte->relkind != RELKIND_RELATION) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("TABLESAMPLE clause can only be applied to tables."),
parser_errposition(pstate, exprLocation(rts->relation))));
}
if (REL_COL_ORIENTED != rte->orientation && REL_ROW_ORIENTED != rte->orientation) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
(errmsg("TABLESAMPLE clause only support relation of oriented-row, oriented-column and oriented-inplace."))));
}
/* Transform TABLESAMPLE details and attach to the RTE */
rte->tablesample = transformRangeTableSample(pstate, rts);
return (Node*)rtr;
} else if (IsA(n, RangeTimeCapsule)) {
/* TABLECAPSULE clause (wrapping some other valid FROM NODE) */
RangeTimeCapsule* rtc = (RangeTimeCapsule *)n;
Node* rel = NULL;
RangeTblRef* rtr = NULL;
RangeTblEntry* rte = NULL;
/* Recursively transform the contained relation. */
rel = transformFromClauseItem(pstate, rtc->relation, top_rte, top_rti, NULL, NULL, relnamespace);
if (unlikely(rel == NULL)) {
ereport(
ERROR, (errmodule(MOD_OPT), errcode(ERRCODE_UNEXPECTED_NULL_VALUE),
errmsg("Range table with timecapsule clause should not be null")));
}
/* Currently, grammar could only return a RangeVar as contained rel */
Assert(IsA(rel, RangeTblRef));
rtr = (RangeTblRef*)rel;
rte = rt_fetch(rtr->rtindex, pstate->p_rtable);
TvCheckVersionScan(rte);
/* Transform TABLECAPSULE details and attach to the RTE */
rte->timecapsule = transformRangeTimeCapsule(pstate, rtc);
return (Node*)rtr;
} else if (IsA(n, JoinExpr)) {
/* A newfangled join expression */
JoinExpr* j = (JoinExpr*)n;
RangeTblEntry* l_rte = NULL;
RangeTblEntry* r_rte = NULL;
int l_rtindex;
int r_rtindex;
List* l_relnamespace = NIL;
List* r_relnamespace = NIL;
List* my_relnamespace = NIL;
List* l_colnames = NIL;
List* r_colnames = NIL;
List* res_colnames = NIL;
List* l_colvars = NIL;
List* r_colvars = NIL;
List* res_colvars = NIL;
bool lateral_ok = false;
int sv_relnamespace_length, sv_varnamespace_length;
RangeTblEntry* rte = NULL;
int k;
/*
* Recursively process the left and right subtrees
* For merge into clause, left arg is alse the target relation, which has been
* added to the range table. Here, we only build RangeTblRef.
*/
if (isMergeInto == false) {
j->larg = transformFromClauseItem(pstate, j->larg, &l_rte, &l_rtindex, NULL, NULL, &l_relnamespace,
true, false, false, addUpdateTable);
} else {
RangeTblRef* rtr = makeNode(RangeTblRef);
rtr->rtindex = list_length(pstate->p_rtable);
j->larg = (Node*)rtr;
l_rte = (RangeTblEntry*)linitial(pstate->p_target_rangetblentry);
l_rtindex = rtr->rtindex;
l_relnamespace = list_make1(makeNamespaceItem(l_rte, false, true));
}
/*
* Make the left-side RTEs available for LATERAL access within the
* right side, by temporarily adding them to the pstate's namespace
* lists. Per SQL:2008, if the join type is not INNER or LEFT then
* the left-side names must still be exposed, but it's an error to
* reference them. (Stupid design, but that's what it says.) Hence,
* we always push them into the namespaces, but mark them as not
* lateral_ok if the jointype is wrong.
*
* NB: this coding relies on the fact that list_concat is not
* destructive to its second argument.
*/
lateral_ok = (j->jointype == JOIN_INNER || j->jointype == JOIN_LEFT);
setNamespaceLateralState(l_relnamespace, true, lateral_ok);
sv_relnamespace_length = list_length(pstate->p_relnamespace);
pstate->p_relnamespace = list_concat(pstate->p_relnamespace,
l_relnamespace);
sv_varnamespace_length = list_length(pstate->p_varnamespace);
pstate->p_varnamespace = lappend(pstate->p_varnamespace,
makeNamespaceItem(l_rte, true, lateral_ok));
/* And now we can process the RHS */
j->rarg = transformFromClauseItem(pstate, j->rarg, &r_rte, &r_rtindex, NULL, NULL, &r_relnamespace,
true, false, false, addUpdateTable);
/* Remove the left-side RTEs from the namespace lists again */
pstate->p_relnamespace = list_truncate(pstate->p_relnamespace,sv_relnamespace_length);
pstate->p_varnamespace = list_truncate(pstate->p_varnamespace, sv_varnamespace_length);
/*
* Check for conflicting refnames in left and right subtrees. Must do
* this because higher levels will assume I hand back a self-
* consistent namespace subtree.
*/
checkNameSpaceConflicts(pstate, l_relnamespace, r_relnamespace);
/*
* Generate combined relation membership info for possible use by
* transformJoinOnClause below.
*/
my_relnamespace = list_concat(l_relnamespace, r_relnamespace);
/*
* Extract column name and var lists from both subtrees
*
* Note: expandRTE returns new lists, safe for me to modify
*/
expandRTE(l_rte, l_rtindex, 0, -1, false, &l_colnames, &l_colvars);
expandRTE(r_rte, r_rtindex, 0, -1, false, &r_colnames, &r_colvars);
if (right_rte != NULL) {
*right_rte = r_rte;
}
if (right_rti != NULL) {
*right_rti = r_rtindex;
}
/*
* Natural join does not explicitly specify columns; must generate
* columns to join. Need to run through the list of columns from each
* table or join result and match up the column names. Use the first
* table, and check every column in the second table for a match.
* (We'll check that the matches were unique later on.) The result of
* this step is a list of column names just like an explicitly-written
* USING list.
*/
if (j->isNatural) {
List* rlist = NIL;
ListCell* lx = NULL;
ListCell* rx = NULL;
/* shouldn't have USING() too */
Assert(j->usingClause == NIL);
foreach (lx, l_colnames) {
char* l_colname = strVal(lfirst(lx));
Value* m_name = NULL;
foreach (rx, r_colnames) {
char* r_colname = strVal(lfirst(rx));
if (strcmp(l_colname, r_colname) == 0) {
m_name = makeString(l_colname);
break;
}
}
/* matched a right column? then keep as join column... */
if (m_name != NULL) {
rlist = lappend(rlist, m_name);
}
}
j->usingClause = rlist;
}
/*
* Now transform the join qualifications, if any.
*/
res_colnames = NIL;
res_colvars = NIL;
if (j->usingClause) {
/*
* JOIN/USING (or NATURAL JOIN, as transformed above). Transform
* the list into an explicit ON-condition, and generate a list of
* merged result columns.
*/
List* ucols = j->usingClause;
List* l_usingvars = NIL;
List* r_usingvars = NIL;
ListCell* ucol = NULL;
/* shouldn't have ON() too */
Assert(j->quals == NULL);
foreach (ucol, ucols) {
char* u_colname = strVal(lfirst(ucol));
ListCell* col = NULL;
int ndx;
int l_index = -1;
int r_index = -1;
Var *l_colvar = NULL;
Var *r_colvar = NULL;
/* Check for USING(foo,foo) */
foreach (col, res_colnames) {
char* res_colname = strVal(lfirst(col));
if (strcmp(res_colname, u_colname) == 0) {
ereport(ERROR,
(errcode(ERRCODE_DUPLICATE_COLUMN),
errmsg("column name \"%s\" appears more than once in USING clause", u_colname)));
}
}
/* Find it in left input */
ndx = 0;
foreach (col, l_colnames) {
char* l_colname = strVal(lfirst(col));
if (strcmp(l_colname, u_colname) == 0) {
if (l_index >= 0)
ereport(ERROR,
(errcode(ERRCODE_AMBIGUOUS_COLUMN),
errmsg(
"common column name \"%s\" appears more than once in left table", u_colname)));
l_index = ndx;
}
ndx++;
}
if (l_index < 0) {
ereport(ERROR,
(errcode(ERRCODE_UNDEFINED_COLUMN),
errmsg("column \"%s\" specified in USING clause does not exist in left table", u_colname)));
}
/* Find it in right input */
ndx = 0;
foreach (col, r_colnames) {
char* r_colname = strVal(lfirst(col));
if (strcmp(r_colname, u_colname) == 0) {
if (r_index >= 0) {
ereport(ERROR,
(errcode(ERRCODE_AMBIGUOUS_COLUMN),
errmsg(
"common column name \"%s\" appears more than once in right table", u_colname)));
}
r_index = ndx;
}
ndx++;
}
if (r_index < 0) {
ereport(ERROR,
(errcode(ERRCODE_UNDEFINED_COLUMN),
errmsg(
"column \"%s\" specified in USING clause does not exist in right table", u_colname)));
}
l_colvar = (Var*)list_nth(l_colvars, l_index);
l_usingvars = lappend(l_usingvars, l_colvar);
r_colvar = (Var*)list_nth(r_colvars, r_index);
r_usingvars = lappend(r_usingvars, r_colvar);
res_colnames = lappend(res_colnames, lfirst(ucol));
res_colvars = lappend(res_colvars, buildMergedJoinVar(pstate, j->jointype, l_colvar, r_colvar));
}
j->quals = transformJoinUsingClause(pstate, l_rte, r_rte, l_usingvars, r_usingvars);
} else if (j->quals) {
/* User-written ON-condition; transform it */
j->quals = transformJoinOnClause(pstate, j, l_rte, r_rte, my_relnamespace);
} else {
/* CROSS JOIN: no quals */
}
/* Add remaining columns from each side to the output columns */
extractRemainingColumns(res_colnames, l_colnames, l_colvars, &l_colnames, &l_colvars);
extractRemainingColumns(res_colnames, r_colnames, r_colvars, &r_colnames, &r_colvars);
res_colnames = list_concat(res_colnames, l_colnames);
res_colvars = list_concat(res_colvars, l_colvars);
res_colnames = list_concat(res_colnames, r_colnames);
res_colvars = list_concat(res_colvars, r_colvars);
/*
* Check alias (AS clause), if any.
*/
if (j->alias) {
if (j->alias->colnames != NIL) {
if (list_length(j->alias->colnames) > list_length(res_colnames))
ereport(ERROR,
(errcode(ERRCODE_SYNTAX_ERROR),
errmsg("column alias list for \"%s\" has too many entries", j->alias->aliasname)));
}
}
/*
* Now build an RTE for the result of the join
*/
rte = addRangeTableEntryForJoin(pstate, res_colnames, j->jointype, res_colvars, j->alias, true);
/* assume new rte is at end */
j->rtindex = list_length(pstate->p_rtable);
Assert(rte == rt_fetch(j->rtindex, pstate->p_rtable));
*top_rte = rte;
*top_rti = j->rtindex;
/* make a matching link to the JoinExpr for later use */
for (k = list_length(pstate->p_joinexprs) + 1; k < j->rtindex; k++) {
pstate->p_joinexprs = lappend(pstate->p_joinexprs, NULL);
}
pstate->p_joinexprs = lappend(pstate->p_joinexprs, j);
Assert(list_length(pstate->p_joinexprs) == j->rtindex);
/*
* Prepare returned namespace list. If the JOIN has an alias then it
* hides the contained RTEs as far as the relnamespace goes;
* otherwise, put the contained RTEs and *not* the JOIN into
* relnamespace.
*/
if (j->alias) {
*relnamespace = list_make1(makeNamespaceItem(rte, false, true));
} else
*relnamespace = my_relnamespace;
return (Node*)j;
} else
ereport(
ERROR, (errcode(ERRCODE_UNRECOGNIZED_NODE_TYPE), errmsg("unrecognized node type: %d", (int)nodeTag(n))));
return NULL; /* can't get here, keep compiler quiet */
}
transformCTEReference(ParseState* pstate, RangeVar* r, CommonTableExpr* cte, Index levelsup)
返回值:RangeTblEntry*
作用:
实现:
addRangeTableEntryForCTE(ParseState* pstate, CommonTableExpr* cte, Index levelsup, RangeVar* rv, bool inFromCl)
返回值:RangeTblEntry*
作用:
补充:
负责创建CTE的with语句会在语法分析阶段为每个CTE(即每个AS后面的select语句)的ctename赋值为AS前面的那个字符串,又将aliascolnames赋值为AS前面的括号部分即CTE每一列的别名,下面是例子
WITH my_cte (alias_col1, alias_col2) AS (
SELECT column1, column2
FROM my_table
)
SELECT alias_col1, alias_col2
FROM my_cte;
以及ctequery赋值为AS后面的select语句,需要注意,这里的AS不同于SELECT *
FROM table_name AS alias_name;中的AS,后者的AS是会为表table_name的alias属性的aliasname赋值为alias_name的
实现:
RangeTblEntry* addRangeTableEntryForCTE(
ParseState* pstate, CommonTableExpr* cte, Index levelsup, RangeVar* rv, bool inFromCl)
{
/*在查询解析和规划阶段,
PostgreSQL 使用 RTE 对象来管理与表格相关的信息,
以便后续生成查询计划*/
RangeTblEntry* rte = makeNode(RangeTblEntry);
Alias* alias = rv->alias;
//如果select中的from从句引用该CTE时使用了as从句修改别名则别名优先即alias->aliasname,否则按照with从句时对CTE定义的名字来即cte->ctename
char* refname = alias ? alias->aliasname : cte->ctename;
Alias* eref = NULL;
int numaliases;
int varattno;
ListCell* lc = NULL;
rte->rtekind = RTE_CTE;
rte->ctename = cte->ctename;
rte->ctelevelsup = levelsup;
/*代表在当前解析状态下(当前查询),
此CTE定义在其外部查询中,所以说该CTE是被子查询引用到了,所以为true*/
if (levelsup > 0) {
cte->referenced_by_subquery = true;
}
/* Self-reference if and only if CTE's parse analysis isn't completed */
rte->self_reference = !IsA(cte->ctequery, Query);
cte->self_reference = rte->self_reference;
rte->cterecursive = cte->cterecursive;
/*引用计数表示有多少个查询正在引用相同的 CTE 定义,
如果不是自引用的 CTE则引用有效,于是自增*/
if (!rte->self_reference) {
cte->cterefcount++;
}
/*
* We throw error if the CTE is INSERT/UPDATE/DELETE without RETURNING.
* This won't get checked in case of a self-reference, but that's OK
* because data-modifying CTEs aren't allowed to be recursive anyhow.
*/
if (IsA(cte->ctequery, Query)) {
Query* ctequery = (Query*)cte->ctequery;
if (ctequery->commandType != CMD_SELECT && ctequery->returningList == NIL) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("WITH query \"%s\" does not have a RETURNING clause", cte->ctename),
parser_errposition(pstate, rv->location)));
}
}
rte->ctecoltypes = cte->ctecoltypes;
rte->ctecoltypmods = cte->ctecoltypmods;
rte->ctecolcollations = cte->ctecolcollations;
rte->alias = alias;
//如果在select语句中对CTE使用了AS命别名,那么eref指向AS的别名结构体,否则利用新建一个refname实锤了定义CTE时的名字
if (alias != NULL) {
eref = (Alias*)copyObject(alias);
} else {
eref = makeAlias(refname, NIL);
}
numaliases = list_length(eref->colnames);
/* fill in any unspecified alias columns */
varattno = 0;
/*这里的cte->ctecolnames就是cte->aliascolnames
即with语句时定义CTE后面紧跟着的括号的内容
就是在前面的analyzeCTETargetList函数中简单的复制过来实现的
WITH my_cte (col1, col2) AS (
SELECT column1, column2 FROM my_table
)
SELECT col1 AS new_name1, col2 FROM my_cte;
在上面实例中,cte->ctecolnames和cte->aliascolnames的值都是col1和col2,rv->alias非空,因为select处有as,
这里函数做的事情,比如select语句中,为其中没有起别名的列填充为cte->ctecolnames对应起的列名
*/
foreach (lc, cte->ctecolnames) {
varattno++;
if (varattno > numaliases) {
eref->colnames = lappend(eref->colnames, lfirst(lc));
}
}
if (varattno < numaliases) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
errmsg(
"table \"%s\" has %d columns available but %d columns specified", refname, varattno, numaliases)));
}
rte->eref = eref;
/* ----------
* Flags:
* - this RTE should be expanded to include descendant tables,
* - this RTE is in the FROM clause,
* - this RTE should be checked for appropriate access rights.
*
* Subqueries are never checked for access rights.
* ----------
*/
rte->lateral = false;
rte->inh = false; /* never true for subqueries */
rte->inFromCl = inFromCl;
rte->requiredPerms = 0;
rte->checkAsUser = InvalidOid;
rte->selectedCols = NULL;
rte->insertedCols = NULL;
rte->updatedCols = NULL;
rte->extraUpdatedCols = NULL;
rte->orientation = REL_ORIENT_UNKNOWN;
/*
* Add completed RTE to pstate's range table list, but not to join list
* nor namespace --- caller must do that if appropriate.
*/
if (pstate != NULL) {
pstate->p_rtable = lappend(pstate->p_rtable, rte);
}
/*
* If the CTE is rewrited from startwith/connectby. We need to add pseudo columns
* because it return parser tree from sub level and don't have pseudo column infos.
*/
if (cte->swoptions != NULL && IsA(cte->ctequery, Query) && pstate != NULL) {
AddStartWithCTEPseudoReturnColumns(cte, rte, list_length(pstate->p_rtable));
}
return rte;
}
结构体
ParseState
描述当前语义分析的解析状态
struct ParseState {
struct ParseState* parentParseState;//嵌套查询的时候,内部的是子查询,外部的查询是其父查询,于是外部查询的解析状态就是内部查询的父解析状态
const char* p_sourcetext; /* source text, or NULL if not available */
List* p_rtable; /* range table so far */
List* p_joinexprs; /* JoinExprs for RTE_JOIN p_rtable entries */
List* p_joinlist; /* join items so far (will become FromExpr
node's fromlist) */
List* p_relnamespace; /* current namespace for relations */
List* p_varnamespace; /* current namespace for columns */
bool p_lateral_active; /* p_lateral_only items visible? */
bool p_is_flt_frame; /* Indicates whether it is a flattened expr frame */
List* p_ctenamespace; /* current namespace for common table exprs */
List* p_future_ctes; /* common table exprs not yet in namespace */
CommonTableExpr* p_parent_cte; /* this query's containing CTE */
List* p_windowdefs; /* raw representations of window clauses */
ParseExprKind p_expr_kind; /* what kind of expression we're parsing */
List* p_rawdefaultlist; /* raw default list */
int p_next_resno; /* next targetlist resno to assign */
List* p_locking_clause; /* raw FOR UPDATE/FOR SHARE info */
Node* p_value_substitute; /* what to replace VALUE with, if any */
/* Flags telling about things found in the query: */
bool p_hasAggs;
bool p_hasWindowFuncs;
bool p_hasTargetSRFs;
bool p_hasSubLinks;
bool p_hasModifyingCTE;
bool p_is_insert;
bool p_locked_from_parent;
bool p_resolve_unknowns; /* resolve unknown-type SELECT outputs as type text */
bool p_hasSynonyms;
List* p_target_relation;
List* p_target_rangetblentry;
bool p_is_decode;
Node *p_last_srf; /* most recent set-returning func/op found */
/*
* used for start with...connect by rewrite
*/
bool p_addStartInfo;
List *p_start_info;
int sw_subquery_idx; /* given unname-subquery unique name when sw rewrite */
SelectStmt *p_sw_selectstmt;
List *sw_fromClause;
WithClause *origin_with;
bool p_hasStartWith;
bool p_has_ignore; /* whether SQL has ignore hint */
/*
* Optional hook functions for parser callbacks. These are null unless
* set up by the caller of make_parsestate.
*/
PreParseColumnRefHook p_pre_columnref_hook;
PostParseColumnRefHook p_post_columnref_hook;
PreParseColumnRefHook p_bind_variable_columnref_hook;
PreParseColumnRefHook p_bind_describe_hook;
ParseParamRefHook p_paramref_hook;
CoerceParamHook p_coerce_param_hook;
CreateProcOperatorHook p_create_proc_operator_hook;
CreateProcInsertrHook p_create_proc_insert_hook;
void* p_ref_hook_state; /* common passthrough link for above */
void* p_cl_hook_state; /* cl related state - SQLFunctionParseInfoPtr */
List* p_target_list;
void* p_bind_hook_state;
void* p_describeco_hook_state;
/*
* star flag info
*
* create table t1(a int, b int);
* create table t2(a int, b int);
*
* For query: select * from t1
* star_start = 1;
* star_end = 2;
* star_only = 1;
*
* For query: select t1.*, t2.* from t1, t2
* star_start = 1, 3;
* star_end = 2, 4;
* star_only = -1, -1;
*/
List* p_star_start;
List* p_star_end;
List* p_star_only;
/*
* The p_is_in_insert will indicate the sub link is under one top insert statement.
* When p_is_in_insert is true, then we will check if sub link include foreign table,
* If foreign is found, we will set top level insert ParseState's p_is_foreignTbl_exist to true.
* Finially, we will set p_is_td_compatible_truncation to true if the td_compatible_truncation guc
* parameter is on, no foreign table involved in this insert statement.
*/
bool p_is_foreignTbl_exist; /* make there is foreign table founded. */
bool p_is_in_insert; /* mark the subquery is under one insert statement. */
bool p_is_td_compatible_truncation; /* mark the auto truncation for insert statement is enabled. */
TdTruncCastStatus tdTruncCastStatus; /* Auto truncation Cast added, only used for stmt in stored procedure or
prepare stmt. */
bool isAliasReplace; /* Mark if permit replace. */
/*
* Fields for transform "(+)" to outerjoin
*/
bool ignoreplus; /*
* Whether ignore "(+)" during transform stmt? False is default,
* report error when found "(+)". Only true when transform WhereClause
* in SelectStmt.
*/
bool use_level; /* When selecting a column with the same name in an RTE list, whether to consider the
* priority of RTE.
* The priority refers to the index of RTE in the list. The smaller the index value, the
* higher the priority.
*/
PlusJoinRTEInfo* p_plusjoin_rte_info; /* The RTE info while processing "(+)" */
List* p_updateRelations; /* For multiple-update, this is used to record the target table in the
* update statement, then assign to qry->resultRelations.
*/
List* p_updateRangeVars; /* For multiple-update, use relationClase to generate RangeVar list. */
RightRefState* rightRefState;
/*
* whether to record the columns referenced by the ORDER BY statement
* when transforming the SortClause.
*/
bool shouldCheckOrderbyCol;
/*
* store the columns that ORDER BY statement referencing
* if shouldCheckOrderbyCol is true else NIL.
*/
List* orderbyCols;
List* p_indexhintLists; /*Force or use index in index hint list*/
};
Query
typedef struct Query {
NodeTag type;
CmdType commandType; /* select|insert|update|delete|merge|utility */
QuerySource querySource; /* where did I come from? */
uint64 queryId; /* query identifier (can be set by plugins) */
bool canSetTag; /* do I set the command result tag? */
bool is_flt_frame; /* Indicates whether it is a flattened expr frame */
Node* utilityStmt; /* non-null if this is DECLARE CURSOR or a
* non-optimizable statement */
int resultRelation; /* instead by resultRelations */
bool hasAggs; /* has aggregates in tlist or havingQual */
bool hasWindowFuncs; /* has window functions in tlist */
bool hasTargetSRFs; /* has set-returning functions in tlist */
bool hasSubLinks; /* has subquery SubLink */
bool hasDistinctOn; /* distinctClause is from DISTINCT ON */
bool hasRecursive; /* WITH RECURSIVE was specified */
bool hasModifyingCTE; /* has INSERT/UPDATE/DELETE in WITH */
bool hasForUpdate; /* FOR [KEY] UPDATE/SHARE was specified */
bool hasRowSecurity; /* rewriter has applied some RLS policy */
bool hasSynonyms; /* has synonym mapping in rtable */
bool hasIgnore; /* has keyword ignore in query string */
List* cteList; /* WITH list (of CommonTableExpr's) */
List* rtable; /* list of range table entries */
FromExpr* jointree; /* table join tree (FROM and WHERE clauses) */
List* targetList; /* target list (of TargetEntry) */
List* starStart; /* Corresponding p_star_start in ParseState */
List* starEnd; /* Corresponding p_star_end in ParseState */
List* starOnly; /* Corresponding p_star_only in ParseState */
List* returningList; /* return-values list (of TargetEntry) */
List* groupClause; /* a list of SortGroupClause's */
List* groupingSets; /* a list of GroupingSet's if present */
Node* havingQual; /* qualifications applied to groups */
List* windowClause; /* a list of WindowClause's */
List* distinctClause; /* a list of SortGroupClause's */
List* sortClause; /* a list of SortGroupClause's */
Node* limitOffset; /* # of result tuples to skip (int8 expr) */
Node* limitCount; /* # of result tuples to return (int8 expr) */
List* rowMarks; /* a list of RowMarkClause's */
Node* setOperations; /* set-operation tree if this is top level of
* a UNION/INTERSECT/EXCEPT query */
List *constraintDeps; /* a list of pg_constraint OIDs that the query
* depends on to be semantically valid */
HintState* hintState;
#ifdef PGXC
/* need this info for PGXC Planner, may be temporary */
char* sql_statement; /* original query */
bool is_local; /* enforce query execution on local node
* this is used by EXECUTE DIRECT especially. */
bool has_to_save_cmd_id; /* true if the query is such an INSERT SELECT
* that inserts into a child by selecting
* from its parent OR a WITH query that
* updates a table in main query and inserts
* a row to the same table in WITH query */
bool vec_output; /* true if it's vec output. this flag is used in FQS planning */
TdTruncCastStatus tdTruncCastStatus; /* Auto truncation Cast added, only used for stmt in stored procedure or
prepare stmt. */
List* equalVars; /* vars appears in UPDATE/DELETE clause */
#endif
ParamListInfo boundParamsQ;
int mergeTarget_relation;
List* mergeSourceTargetList;
List* mergeActionList; /* list of actions for MERGE (only) */
Query* upsertQuery; /* insert query for INSERT ON DUPLICATE KEY UPDATE (only) */
UpsertExpr* upsertClause; /* DUPLICATE KEY UPDATE [NOTHING | ...] */
bool isReplace;
bool isRowTriggerShippable; /* true if all row triggers are shippable. */
bool use_star_targets; /* true if use * for targetlist. */
bool is_from_full_join_rewrite; /* true if the query is created when doing
* full join rewrite. If true, we should not
* do some expression processing.
* Please refer to subquery_planner.
*/
bool is_from_inlist2join_rewrite; /* true if the query is created when applying inlist2join optimization */
bool is_from_sublink_rewrite; /* true if the query is created when applying pull sublink optimization */
bool is_from_subquery_rewrite; /* true if the query is created when applying pull subquery optimization */
uint64 uniqueSQLId; /* used by unique sql id */
#ifndef ENABLE_MULTIPLE_NODES
char* unique_sql_text; /* used by unique sql plain text */
#endif
bool can_push;
bool unique_check; /* true if the subquery is generated by general
* sublink pullup, and scalar output is needed */
Oid* fixed_paramTypes; /* For plpy CTAS query. CTAS is a recursive call.CREATE query is the first rewrited.
* thd 2nd rewrited query is INSERT SELECT.whithout this attribute, DB will have
* an error that has no idea about $x when INSERT SELECT query is analyzed. */
int fixed_numParams;
List* resultRelations; /* rtable index list of target relation for INSERT/UPDATE/DELETE/MERGE. */
RightRefState* rightRefState;
List* withCheckOptions; /* a list of WithCheckOption's */
List* indexhintList; /* a list of b mode index hint members */
#ifdef USE_SPQ
void* intoPolicy;
ParentStmtType parentStmtType;
#endif
} Query;