项目地址
BigCache 是一个快速,支持并发访问,自淘汰的内存型缓存,可以在存储大量元素时依然保持高性能。BigCache将元素保存在堆上却避免了GC的开销。
背景介绍
BigCache的作者在项目里遇到了如下的需求:
- 支持
http协议 - 支持 10 k 10k 10kRPS ,其中读写各占一半
cache缓存至少 10 10 10分钟- 平均
r
t
=
5
m
s
,
p
99
<
=
10
m
s
,
p
999
<
=
400
m
s
rt=5ms,p99<=10ms,p999<=400ms
rt=5ms,p99<=10ms,p999<=400ms
开发的缓存库需要保证: - 即使有百万的缓存对象速度也要很快
- 支持高并发访问
- 支持过期自动删除
简单入门
func Test_BigCache(t *testing.T) {
cache, _ := bigcache.New(context.Background(), bigcache.DefaultConfig(10*time.Minute)) //定义cache
cache.Set("my-unique-key", []byte("value")) //设置k,v键值对
entry, _ := cache.Get("my-unique-key") //获取k,v键值对
t.Log(string(entry))
}
配置文件
config字段说明
| 字段名 | 类型 | 含义 |
|---|---|---|
| Shards | int | 缓存分片数,值必须是 2 的幂 |
| LifeWindow | time.Duration | 条目可以被逐出的时间,近似可以理解为缓存时间 |
| CleanWindow | time.Duration | 删除过期条目(清理)之间的间隔。如果设置为 <= 0,则不执行任何操作。设置为 < 1 秒会适得其反,因为 bigcache 的分辨率为 1 秒。 |
| MaxEntriesInWindow | int | 生命周期窗口中的最大条目数。仅用于计算缓存分片的初始大小。如果设置了适当的值,则不会发生额外的内存分配。 |
| MaxEntrySize | int | 条目的最大大小(以字节为单位)。仅用于计算缓存分片的初始大小。 |
| StatsEnabled | bool | StatsEnabled如果为true,则计算请求缓存资源的次数。 |
| Verbose | bool | 是否以详细模式打印有关新内存分配的信息 |
| Hasher | Hasher | 哈希程序用于在字符串键和无符号 64 位整数之间进行映射,默认情况下使用 fnv64 哈希。 |
| HardMaxCacheSize | int | 是BytesQueue 大小的限制 MB。它可以防止应用程序占用计算机上的所有可用内存,从而防止运行 OOM Killer。 |
| OnRemove | func(key string, entry []byte) | OnRemove 是当最旧的条目由于过期时间或没有为新条目留出空间或调用 delete 而被删除时触发的回调。如果指定了 OnRemoveWithMetadata,则忽略。 |
| OnRemoveWithMetadata | func(key string, entry []byte, keyMetadata Metadata) | OnRemoveWithMetadata 是当最旧的条目由于过期时间或没有为新条目留出空间或调用 delete 而被删除时触发的回调,携带有关该特定条目的详细信息的结构。 |
| OnRemoveWithReason | func(key string, entry []byte, reason RemoveReason) | OnRemoveWithReason 是当最旧的条目由于过期时间或没有为新条目留出空间或调用了 delete 而被删除时触发的回调,将传递一个表示原因的常量。如果指定了 OnRemove,则忽略。 |
| onRemoveFilter | int | 和OnRemoveWithReason一起使用,阻止 bigcache 解包它们,从而节省 CPU。 |
| Logger | Logger | 日志记录接口 |
说明:
- LifeWindow 是一个时间。在此之后,条目可以称为死条目,但不能删除。
- CleanWindow 是一个时间。在此之后,将删除所有无效条目,但不会删除仍具有生命的条目。
- HardMaxCacheSize 默认值为 0,表示大小不受限制。当限制高于 0 并达到时,新条目将覆盖最旧的条目。由于 Shards 的额外内存,最大内存消耗将大于 HardMaxCacheSize。每个分片都会消耗额外的内存来映射键和统计信息 (map[uint64]uint32),此映射的大小等于缓存中的条目数 ~ 2×(64+32)×n 位 + 开销或映射本身。
- OnRemove,OnRemoveWithMetadata ,OnRemoveWithReason 这三个跟删除有关的属性默认值为 nil,表示没有回调,并且会阻止解开最早的条目。
配置代码文件
// Config for BigCache
type Config struct {
// Number of cache shards, value must be a power of two
Shards int
// Time after which entry can be evicted
LifeWindow time.Duration
// Interval between removing expired entries (clean up).
// If set to <= 0 then no action is performed. Setting to < 1 second is counterproductive — bigcache has a one second resolution.
CleanWindow time.Duration
// Max number of entries in life window. Used only to calculate initial size for cache shards.
// When proper value is set then additional memory allocation does not occur.
MaxEntriesInWindow int
// Max size of entry in bytes. Used only to calculate initial size for cache shards.
MaxEntrySize int
// StatsEnabled if true calculate the number of times a cached resource was requested.
StatsEnabled bool
// Verbose mode prints information about new memory allocation
Verbose bool
// Hasher used to map between string keys and unsigned 64bit integers, by default fnv64 hashing is used.
Hasher Hasher
// HardMaxCacheSize is a limit for BytesQueue size in MB.
// It can protect application from consuming all available memory on machine, therefore from running OOM Killer.
// Default value is 0 which means unlimited size. When the limit is higher than 0 and reached then
// the oldest entries are overridden for the new ones. The max memory consumption will be bigger than
// HardMaxCacheSize due to Shards' s additional memory. Every Shard consumes additional memory for map of keys
// and statistics (map[uint64]uint32) the size of this map is equal to number of entries in
// cache ~ 2×(64+32)×n bits + overhead or map itself.
HardMaxCacheSize int
// OnRemove is a callback fired when the oldest entry is removed because of its expiration time or no space left
// for the new entry, or because delete was called.
// Default value is nil which means no callback and it prevents from unwrapping the oldest entry.
// ignored if OnRemoveWithMetadata is specified.
OnRemove func(key string, entry []byte)
// OnRemoveWithMetadata is a callback fired when the oldest entry is removed because of its expiration time or no space left
// for the new entry, or because delete was called. A structure representing details about that specific entry.
// Default value is nil which means no callback and it prevents from unwrapping the oldest entry.
OnRemoveWithMetadata func(key string, entry []byte, keyMetadata Metadata)
// OnRemoveWithReason is a callback fired when the oldest entry is removed because of its expiration time or no space left
// for the new entry, or because delete was called. A constant representing the reason will be passed through.
// Default value is nil which means no callback and it prevents from unwrapping the oldest entry.
// Ignored if OnRemove is specified.
OnRemoveWithReason func(key string, entry []byte, reason RemoveReason)
onRemoveFilter int
// Logger is a logging interface and used in combination with `Verbose`
// Defaults to `DefaultLogger()`
Logger Logger
}
默认配置
DefaultConfig 使用默认值初始化配置。当可以提前预测 BigCache 的负载时,最好使用自定义配置。
| 字段名 | 值 | 含义 |
|---|---|---|
| Shards | 1024 | 缓存分片数是1024 |
| LifeWindow | eviction | 自定义过期时间 |
| CleanWindow | 1 * time.Second | 每隔1秒就清理失效数据 |
| MaxEntriesInWindow | 1000 * 10 * 60 | 生命周期窗口中的最大条目数为6e5 |
| MaxEntrySize | 500 | 条目的最大大小为500字节 |
| StatsEnabled | false | 不计算请求缓存资源的次数 |
| Verbose | true | 以详细模式打印有关新内存分配的信息 |
| Hasher | fnv64 | 哈希程序,fnv64 哈希 |
| HardMaxCacheSize | 0 | BytesQueue 大小无限制 |
| Logger | DefaultLogger | 日志记录接口 |
优点:支持自定义过期时间,清理失效数据的间隔为最小间隔、效率高
缺点:BytesQueue 大小无限制,容易造成内存占用过高
默认配置代码:
func DefaultConfig(eviction time.Duration) Config {
return Config{
Shards: 1024,
LifeWindow: eviction,
CleanWindow: 1 * time.Second,
MaxEntriesInWindow: 1000 * 10 * 60,
MaxEntrySize: 500,
StatsEnabled: false,
Verbose: true,
Hasher: newDefaultHasher(),
HardMaxCacheSize: 0,
Logger: DefaultLogger(),
}
}
数据结构
前提说明:BigCache 是快速、并发、逐出缓存,旨在保留大量条目而不影响性能。它将条目保留在堆上,但省略了它们的 GC。为了实现这一点,操作发生在字节数组上,因此在大多数用例中,都需要在缓存前面进行条目**(反序列化)**。
BigCache数据结构
| 字段名 | 类型 | 含义 |
|---|---|---|
| shards | []*cacheShard | 缓存分片数据 |
| lifeWindow | uint64 | 缓存时间,对应配置里的LifeWindow |
| clock | clock | 时间计算函数 |
| hash | Hasher | 哈希函数 |
| config | Config | 配置文件 |
| shardMask | uint64 | 值为(config.Shards-1),寻找分片位置时使用的参数,可以理解为对config.Shards取余后的最大值 |
| close | chan struct{} | 关闭通道 |
type BigCache struct {
shards []*cacheShard
lifeWindow uint64
clock clock
hash Hasher
config Config
shardMask uint64
close chan struct{}
}
cacheShard数据结构
| 字段名 | 类型 | 含义 |
|---|---|---|
| hashmap | map[uint64]uint32 | 索引列表,key为存储的key,value为该key在entries里的位置 |
| entries | queue.BytesQueue | 实际数据存储的地方 |
| lock | sync.RWMutex | 互斥锁,用于并发读写 |
| entryBuffer | []byte | 入口缓冲区 |
| onRemove | onRemoveCallback | 删除回调函数 |
| isVerbose | bool | 是否详细模式打印有关新内存分配的信息 |
| statsEnabled | bool | 是否计算请求缓存资源的次数 |
| logger | Logger | 日志记录函数 |
| clock | clock | 时间计算函数 |
| lifeWindow | uint64 | 缓存时间,对应配置里的LifeWindow |
| hashmapStats | map[uint64]uint32 | 存储缓存请求次数 |
| stats | Stats | 存储缓存统计信息 |
| cleanEnabled | bool | 是否可清理,由config.CleanWindow决定 |
type cacheShard struct {
hashmap map[uint64]uint32
entries queue.BytesQueue
lock sync.RWMutex
entryBuffer []byte
onRemove onRemoveCallback
isVerbose bool
statsEnabled bool
logger Logger
clock clock
lifeWindow uint64
hashmapStats map[uint64]uint32
stats Stats
cleanEnabled bool
}
BytesQueue数据结构
BytesQueue 是一种基于 bytes 数组的 fifo 非线程安全队列类型。对于每个推送操作,都会返回条目的索引。它可用于稍后读取条目。
| 字段名 | 类型 | 含义 |
|---|---|---|
| full | bool | 队列是否已满 |
| array | []byte | 实际数据存储的地方 |
| capacity | int | 容量 |
| maxCapacity | int | 最大容量 |
| head | int | 队首位置 |
| tail | int | 下次可以插入的元素位置 |
| count | int | 当前存在的元素数量 |
| rightMargin | int | 右边界 |
| headerBuffer | []byte | 插入时的临时缓冲区 |
| verbose | bool | 是否详细模式打印有关新内存分配的信息 |
type BytesQueue struct {
full bool
array []byte
capacity int
maxCapacity int
head int
tail int
count int
rightMargin int
headerBuffer []byte
verbose bool
}
优秀设计
处理并发访问
设计点1:将数据打散后存储
通用解法: 缓存支持并发访问是很基本的要求,比较常见的解决访问是对缓存整体加读写锁,在同一时间只允许一个协程修改缓存内容。这样的缺点是锁可能会阻塞后续的操作,而且高频的加锁、解锁操作会导致缓存性能降低。
设计点: B i g C a c h e BigCache BigCache使用一个 s h a r d shard shard数组来存储数据,将数据打散到不同的 s h a r d shard shard里,每个 s h a r d shard shard里都有一个小的 l o c k lock lock,从而减小了锁的粒度,提高访问性能。
设计点2:打散数据过程中借助位运算加快计算速度
接下来看一下将某个数据放到缓存的过程的源代码:
// Set saves entry under the key
func (c *BigCache) Set(key string, entry []byte) error {
hashedKey := c.hash.Sum64(key)
shard := c.getShard(hashedKey)
return shard.set(key, hashedKey, entry)
}
func (c *BigCache) getShard(hashedKey uint64) (shard *cacheShard) {
return c.shards[hashedKey&c.shardMask]
}
可以得到 s e t set set的过程如下:
- 进行 h a s h hash hash操作,将 s t r i n g string string类型 k e y key key哈希为一个 u i n t 64 uint64 uint64类型的 h a s h e d K e y hashedKey hashedKey
- 根据 h a s h e d K e y hashedKey hashedKey做 s h a r d i n g sharding sharding,最后落到的 s h a r d shard shard的下标为 h a s h e d K e y % n hashedKey\%n hashedKey%n,其中 n n n是分片数量。理想情况下,每次请求会均匀地落在各自的分片上,单个 s h a r d shard shard的压力就会很小。
- 调用对应 s h a r d shard shard的set方法来设置缓存
设计点:
当
n
n
n为
2
2
2的幂次方的时候,对于任意的
x
x
x,下面的公式都成立的。
x
m
o
d
N
=
(
x
&
(
N
−
1
)
)
x\ mod\ N = (x \& (N − 1))
x mod N=(x&(N−1))
所以可以借助位运算快速计算余数,因此倒推回去 缓存分片数必须要设置为
2
2
2的幂次方。
设计点3 避免栈上的内存分配
默认的哈希算法为 f n v 64 fnv64 fnv64算法,该算法采用位运算的方式在栈上运算,避免了在堆上分配内存
package bigcache
// newDefaultHasher returns a new 64-bit FNV-1a Hasher which makes no memory allocations.
// Its Sum64 method will lay the value out in big-endian byte order.
// See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function
func newDefaultHasher() Hasher {
return fnv64a{}
}
type fnv64a struct{}
const (
// offset64 FNVa offset basis. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hash
offset64 = 14695981039346656037
// prime64 FNVa prime value. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hash
prime64 = 1099511628211
)
// Sum64 gets the string and returns its uint64 hash value.
func (f fnv64a) Sum64(key string) uint64 {
var hash uint64 = offset64
for i := 0; i < len(key); i++ {
hash ^= uint64(key[i])
hash *= prime64
}
return hash
}
减少GC开销
设计点1:利用go1.5+特性,减少GC扫描
g
o
l
a
n
g
golang
golang里实现缓存最简单的方式是
m
a
p
map
map来存储元素,比如
m
a
p
[
s
t
r
i
n
g
]
I
t
e
m
map[string]Item
map[string]Item。
使用
m
a
p
map
map的缺点为垃圾回收器
G
C
GC
GC会在标记阶段访问
m
a
p
map
map里的每一个元素,当
m
a
p
map
map里存储了大量数据的时候会降低程序性能。
B
i
g
C
a
c
h
e
BigCache
BigCache使用了
g
o
1.5
go1.5
go1.5版本以后的特性:如果使用的map的key和value中都不包含指针,那么GC会忽略这个map
具体而言,
B
i
g
C
a
c
h
e
BigCache
BigCache使用
m
a
p
[
u
i
n
t
64
]
u
i
n
t
32
map[uint64]uint32
map[uint64]uint32
来存储数据,不包含指针,
G
C
GC
GC就会自动忽略这个
m
a
p
map
map。
m
a
p
map
map的
k
e
y
key
key存储的是缓存的
k
e
y
key
key经过
h
a
s
h
hash
hash函数后得到的值
m
a
p
map
map的
v
a
l
u
e
value
value存储的是序列化后的数据在全局
[
]
b
y
t
e
[]byte
[]byte中的下标。
因为
B
i
g
C
a
c
h
e
BigCache
BigCache是将存入缓存的
v
a
l
u
e
value
value序列化为
b
y
t
e
byte
byte数组,然后将该数组追加到全局的
b
y
t
e
byte
byte数组里(说明:结合前面的打散思想可以得知一个
s
h
a
r
d
shard
shard对应一个全局的
b
y
t
e
byte
byte数组)
这样做的缺点是删除元素的开销会很大,因此
B
i
g
C
a
c
h
e
BigCache
BigCache里也没有提供删除指定
k
e
y
key
key的接口,删除元素靠的是全局的过期时间或是缓存的容量上限,是先进先出的队列类型的过期。
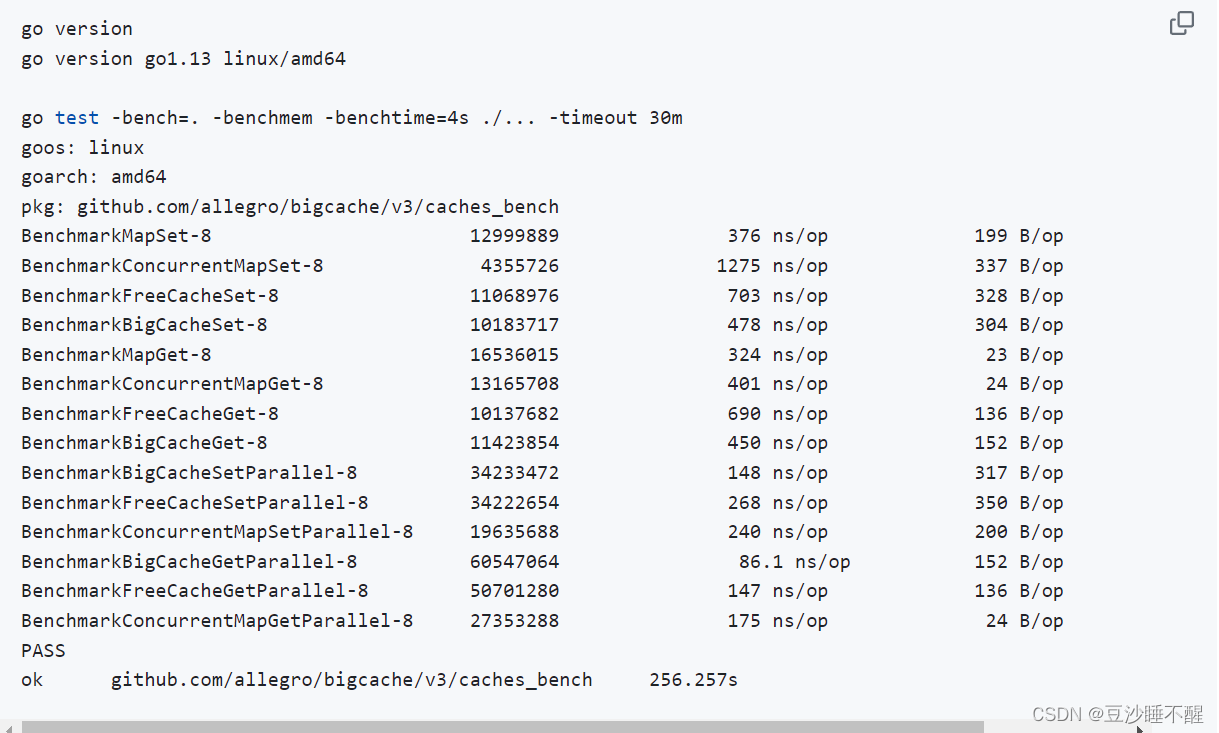
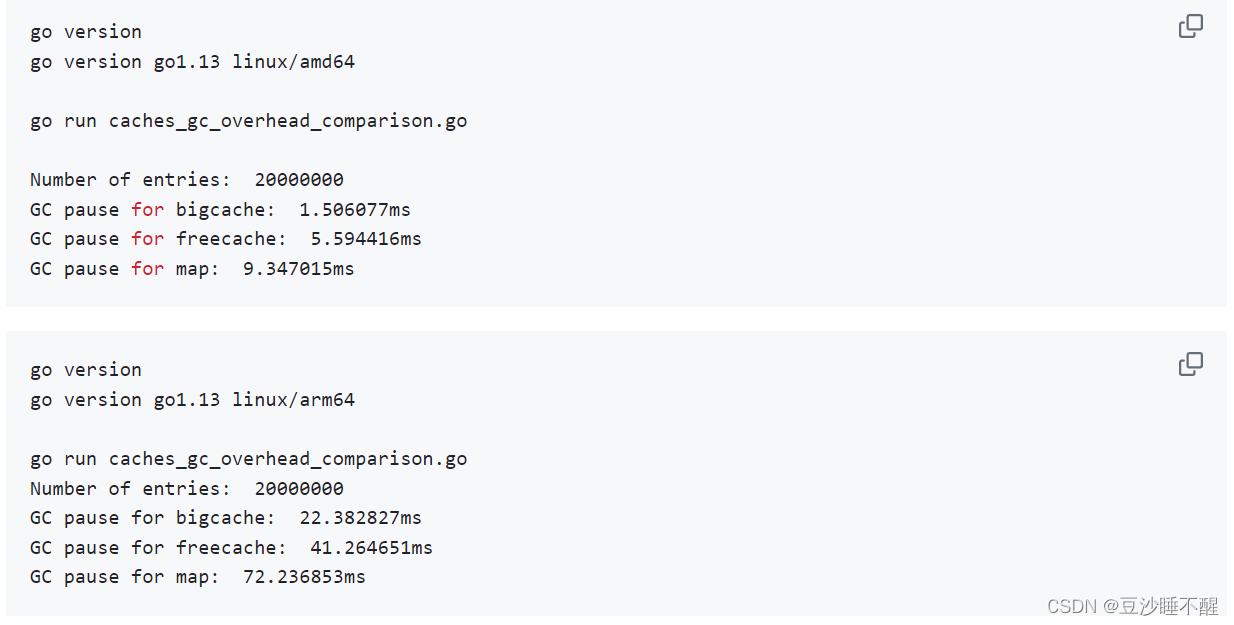
性能测试
项目开发者给出了项目和主流缓存方案的
B
e
n
c
h
m
a
r
k
s
Benchmarks
Benchmarks结果和
G
C
GC
GC测试结果
测试文件链接
参考
妙到颠毫: bigcache优化技巧
[译] Go开源项目BigCache如何加速并发访问以及避免高额的GC开销