论文链接:
https://arxiv.org/abs/2312.16890
代码链接:
https://github.com/HKUDS/DiffKG
实验室链接:
https://sites.google.com/view/chaoh

TLDR
知识图谱已成为提升推荐系统性能的重要资源,能提供丰富的事实信息并揭示实体间的深层语义联系。然而,并非图谱中的每一种关系都与推荐任务息息相关。事实上,一些无关的实体关系可能掺杂噪音,干扰系统对用户偏好的精准学习。
针对这一挑战,研究者们提出了 DiffKG——一种创新的知识图谱扩散模型,专为推荐系统设计。该模型巧妙地融合了生成式扩散模型和数据增强策略,有效地促进了知识图谱表示的稳健学习。这种独特的融合方式极大地优化了物品的知识感知语义及其内在的协同关系建模。此外,研究者引入了一种创新的协同知识图卷积机制,该机制能够利用用户与物品交互模式中的协同信号,有指导地促进知识图谱的有效扩散。

研究背景
在当今信息爆炸的时代背景下,推荐系统在现代网络社会扮演了极其重要的角色,有效地连接了用户与符合其个性化兴趣的物品。其中,协同过滤(Collaborative Filtering, CF)作为推荐系统的核心范式之一,基于一个核心假设:具有相似交互模式的用户可能对物品有相近的偏好。这种方法已广受关注,并已被证明在提供个性化推荐方面非常有效。
在现实应用中,推荐系统的表现往往受限于用户-物品交互数据的固有稀疏性。为了克服这一难题,将知识图谱(Knowledge Graph, KG)作为一种丰富的物品信息网络,纳入协同过滤已逐渐成为行业内的新趋势。
尽管基于知识图谱的推荐方法已展示出其有效性,但这些方法的性能极度依赖于输入的知识图谱质量,并可能受到噪音污染的负面影响。现实中的知识图谱常受限于其固有的稀疏性和噪音问题,包括长尾实体分布和大量与推荐任务无关的实体关系。
为应对这些挑战,最新研究开始探索利用对比学习(Contrastive Learning, CL)来增强基于知识图谱的推荐方法。例如,KGCL [1] 提出了一种在知识图谱上进行随机图增强的方法,并采用对比学习策略来解决知识图谱的长尾分布问题。同理,MCCLK [2] 和 KGIC [3] 方法采用了跨视图对比学习范式,该范式致力于将外部的物品知识与用户-物品交互模式整合,以更好地建模交互。
但这些方法主要依赖于简单的随机增强或是直观的跨视图信息传递,并未充分考虑到知识图谱中大量与特定推荐任务不相关的信息。因此,有效地筛选知识图谱中的噪声,对于实现更健壮的用户偏好建模至关重要。
为解决上述问题,本研究提出了 DiffKG,一种创新的知识图谱扩散模型,专门用于提升推荐系统性能。受到最新扩散模型研究的启发,该模型采用了一种独特的知识图谱扩散范式,有效实现了破坏与重构的平衡。
在模型的前向过程中,原始知识图谱逐步被引入的随机噪声破坏,模拟了知识图谱在现实世界中逐渐累积噪声的过程,并通过迭代恢复机制来还原图谱结构。这一创新的前向过程构建了一个可靠的后验分布,并通过反向生成的神经网络模型来迭代地建模复杂分布。
为了有效应对知识图谱中的噪声和无关信息,本研究还设计了一种协同知识图谱卷积机制,该机制通过整合用户-物品交互中的协同信号到知识图谱的扩散过程,进一步强化了知识图谱扩散范式。这种机制能够引导扩散过程,确保保留与推荐任务紧密相关的知识,从而帮助扩散模型更准确地识别和利用有价值的信息。

模型方法
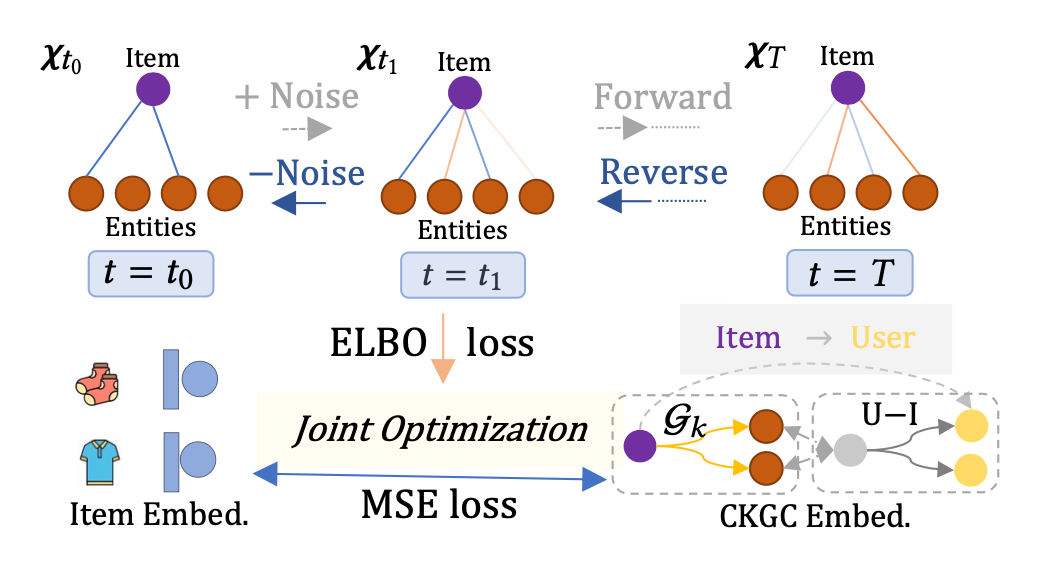
DiffKG 的架构在下图中展示,它整合了三大关键模块:首先是异构知识聚合模块,其目的是汇聚知识图谱中的丰富信息;随后是知识图谱扩散模型,负责创造出经过精细去噪处理的知识图谱;最后是一个增强的数据增强范式,该范式利用知识图谱扩散的成果来提升推荐系统的综合表现。
在具体实践中,经扩散模型处理后得到的洁净知识图谱将通过异构知识聚合以及用户-物品交互网络的图卷积操作,从而得到一个全新的视图。这一视图与从原始知识图谱中以相似方式得到的视图相互对照,在对比学习的框架下,借助 InfoNCE 损失函数进行优化。此外,为了精确调优推荐任务,系统还采用了 BPR 损失函数进行优化,确保推荐结果的准确性和个性化。
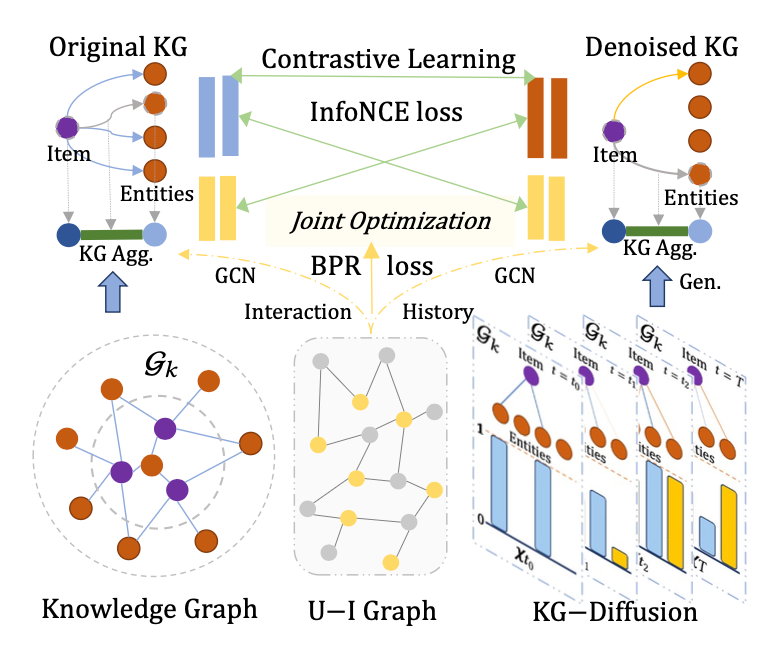
3.1 异构知识聚合
现实世界中的知识图谱中的知识关系往往是异构的,为了捕捉知识图谱连接结构中固有的多样化关系,作者受到过往工作中使用的图注意力机制的启发,设计了一种关系感知知识嵌入层。通过引入参数化的注意力矩阵,该嵌入层能够将实体相关的上下文和关系相关的上下文投影到特定的表示中,克服了在知识图谱上手动设计路径的局限性。物品与其连接的实体之间的消息聚合机制如下:
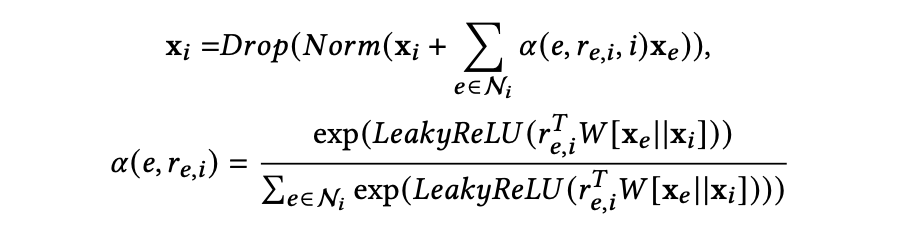
3.2 知识图谱增强的数据增强范式
目前对比学习在推荐系统领域取得了巨大的成功。在知识图谱感知的推荐系统相关工作中,比如 KGCL [1],MCCLK [2] 及 KGIC [3] 都引入了对比学习技术。这些方法要么依赖简单的随机增强方式,要么通过在知识图谱视图和协同过滤视图之间进行简单的跨视图对比。
然而,随机的数据增强会引入不必要的噪声,并且额外的知识图谱视图也包含与下游推荐任务不相关的信息。只有一部分原始知识图谱的子集包含推荐任务相关的信息,不相关信息的引入会对推荐系统的性能产生负面影响。
为了解决这一问题,作者提出使用一个生成模型来重建知识图谱 的子图 ,该子图 特别包含与下游推荐任务相关的物品-实体关系。在完成任务相关的知识图谱的构建后,作者通过图协同过滤范式和异构知识聚合两种编码器的组合来得到用户和物品的表示。具体地,作者受 LightGCN [4] 影响,设计了本地图嵌入传播层:
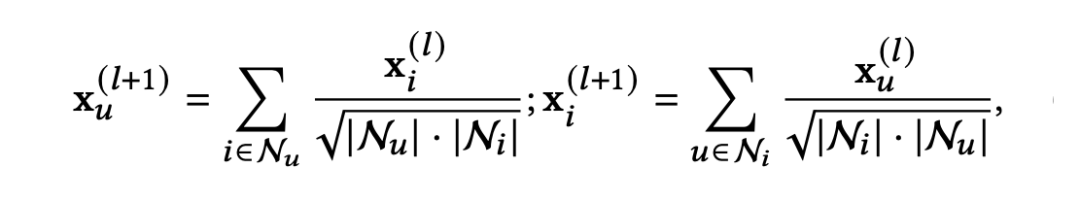
通过多个图传播层,基于图的协同过滤范式可以捕捉高阶的协同关系。在作者设计的模型流程中,原始知识图谱 和生成的知识图谱 都进行异构知识聚合,以获得保留知识图谱语义信息的物品特征向量。这些物品特征向量之后会被进一步进入基于图的协同过滤范式以再次提升表达建模。
在构建完成两个知识增强的图视图后,作者将同一个节点的两个视图的嵌入表示作为正对((, )|),将不同节点在两个视图的嵌入表示作为负对((, )|, )。作者使用一个对比损失函数来最大化正对之间的一致性并最小化负对之间的一致性:
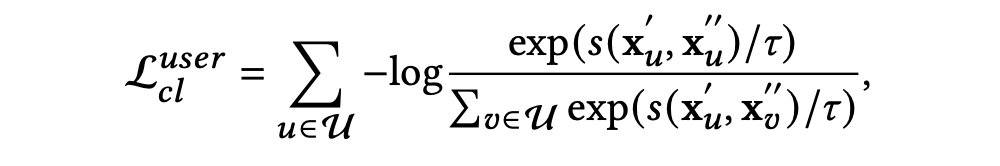
3.3 知识图谱扩散模型
受到扩散模型在从噪声输入中生成数据方面的有效性的启发,作者提出了一个知识图谱扩散模型。作者的目标在于从原始知识图谱 中生成与推荐相关的子图 。
为了实现这一目标,模型需要在经过训练后,能够识别出在经过噪声扩散处理后的知识图谱中物品和实体之间的真实关系。作者通过一个逐步引入噪声的前向过程来模拟知识图谱中关系的破坏,之后,再通过迭代学习来恢复知识图谱中的原始关系,这种迭代去噪训练使得模型能够建模复杂的关系生成过程,并减少噪声关系的影响。最终,恢复的关系概率被用于从原始知识图谱 中重建子图 。
3.3.1 噪声扩散过程
和其他的扩散模型类似,知识图谱扩散包含两个主要的过程,分别是前向过程和逆向过程。为了在知识图谱上实现这两个过程,作者将知识图谱表示为一个邻接矩阵。
具体地,考虑一个与实体集合 中的实体有关系的物品 ,将这些关系定义为 ,这里 的值为 1 或者 0,表示物品 与实体 是否存在连接。
在前向过程中,知识图谱的原始结构通过逐步添加高斯噪声而被破坏。作者使用一个初始状态 来表示物品 的原始邻接矩阵。这个前向过程之后在 步中逐渐添加高斯噪声,以马尔可夫链的形式构建 ,其中 到 的转化如下:
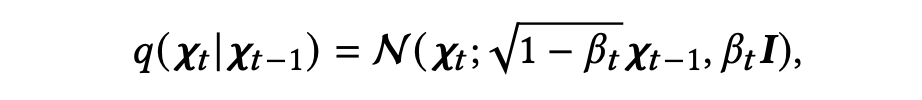
当 时,状态 逐渐趋向于一个标准的高斯分布。作者使用重参数技巧并且利用了两个独立高斯噪声可相加的性质,直接从初始状态 得到状态 :
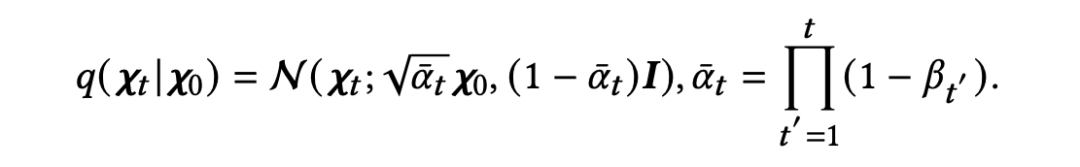
其中, 可以进行重参数:
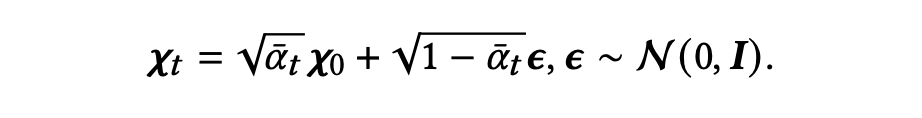
在这之后,扩散模型需要使用神经网络学习如何从 中去除之前添加的噪声以恢复 。从 开始,逆向过程通过去噪转化步逐渐重建知识图谱中的关系。去噪转化步如下:
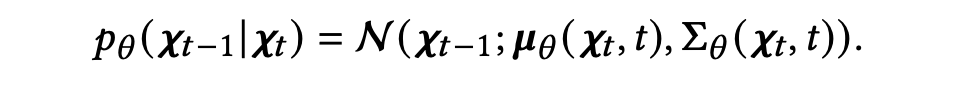
作者使用参数为 的神经网络来生成一个高斯分布的均值 和协方差 。
3.3.2 知识图谱扩散过程的训练
为了训练扩散模型,作者最大化原始知识图关系 的似然的 Evidence Lower Bound(ELBO)。作者提出的概率扩散模型的优化目标可以总结如下:
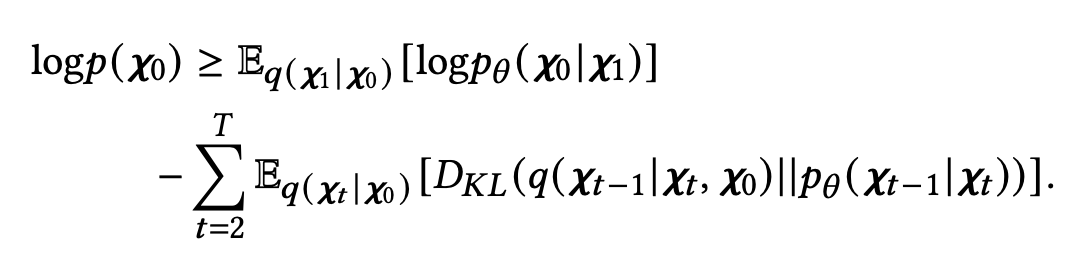
该优化目标包含两部分,第一部分衡量了 的恢复概率,表示模型重建原始知识图谱的能力,第二部分则调节了反向过程中 从 到 的 的恢复。
优化目标中的第二部分旨在通过 KL 离散度使分布 近似于可计算的分布 。第二项 在时间步 时表示如下:
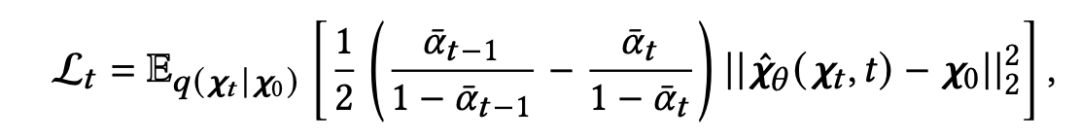
为了计算上式,作者使用神经网络实现了 。具体而言,作者通过一个多层感知器(MLP)来实例化 ,该 MLP 以 和时间步 的嵌入表示作为输入来预测 。
对于优化目标中的第一部分,作者经过推导得出其是第二部分的一个特殊情况()。最终,ELBO 可以被表示为 。因此,为了最大化 ELBO,可以通过最小化 来优化 中的 。具体而言,作者对时间步 均匀采样,以便在 上优化 :
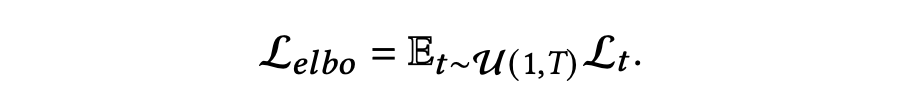
3.3.3 使用扩散模型进行知识图谱的生成
与其他扩散模型随机抽取高斯噪声进行逆向生成的方法不同,作者设计了一种简单的推理策略,这与 DiffKG 在知识图谱中的关系预测训练相一致,避免了用纯噪声破坏知识图谱,因为这可能会对知识图谱的结构信息造成严重损害。
具体而言,作者通过逐步在前向过程中破坏原始知识图谱关系 ,从而得到 。之后使得 ,进行逆向去噪过程,这其中作者忽略了方差并且使用 进行确定性推理。
接下来,作者使用得到的 来重建去噪后的知识图谱 的结构。对于每个物品 ,选择前 个 (,,并在物品 和实体 ()之间添加 个关系。这旨在在前向过程中引入噪声的同时保留知识图谱的信息结构,并在逆向过程中进行确定性推理。
3.3.4 协同知识图卷积
为了缓解扩散模型在生成去噪知识图谱方面可能存在的局限性,以包含下游推荐任务所需的相关的关系信息,作者提出了一种协同知识图卷积(CKGC)机制。这种方法利用用户-物品历史交互数据,将推荐任务中的监督信号融入到知识图谱扩散模型的训练过程中。
通过融合用户-物品历史交互数据,扩散模型能够学习捕捉用户偏好,并将其无缝地融入到去噪的知识图谱中去,从而增强其与推荐任务的相关性。这种用户偏好的融合有效地将知识图谱去噪和推荐任务相联系。CKGC 损失的定义如下:
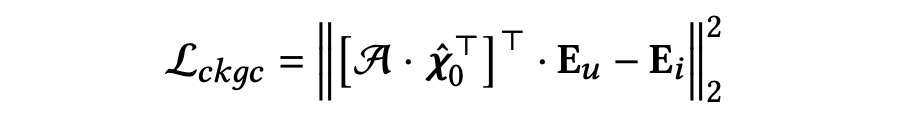
3.3.5 DiffKG的训练
DiffKG 的训练主要包括两个部分:推荐任务的训练和知识图谱扩散模型的训练。知识图谱扩散模型的联合训练包括两个损失:ELBO 损失和 CKGC 损失,它们同时进行优化。
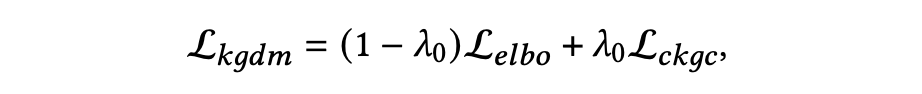
对于推荐任务,作者使用了贝叶斯个性化排名(BPR)推荐损失和前文提到的对比损失 ,BPR 损失定义如下:
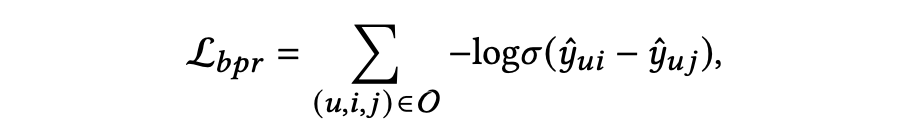
因此,对于推荐任务的集成优化目标如下:
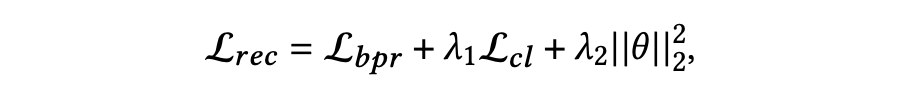

实验结果
本文在三个公开数据集上对比了多个最新的基线模型,并进行了广泛而充分的实验,实验结果表明提出的 DiffKG 在总体性能上具有最优的性能。
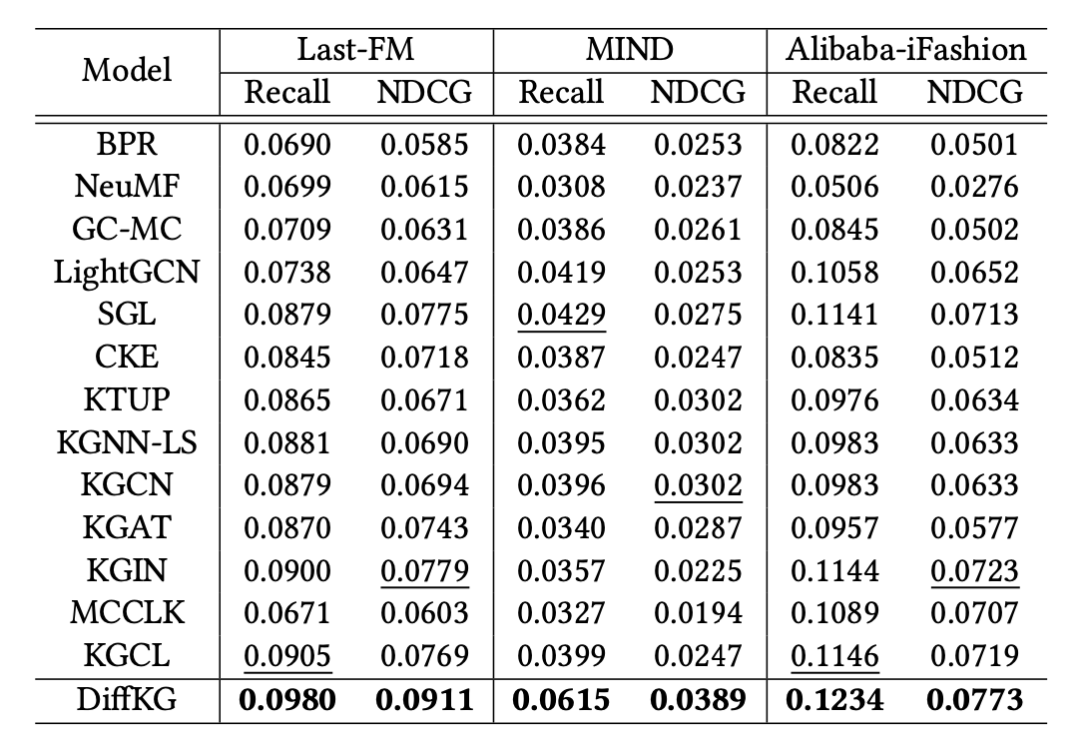
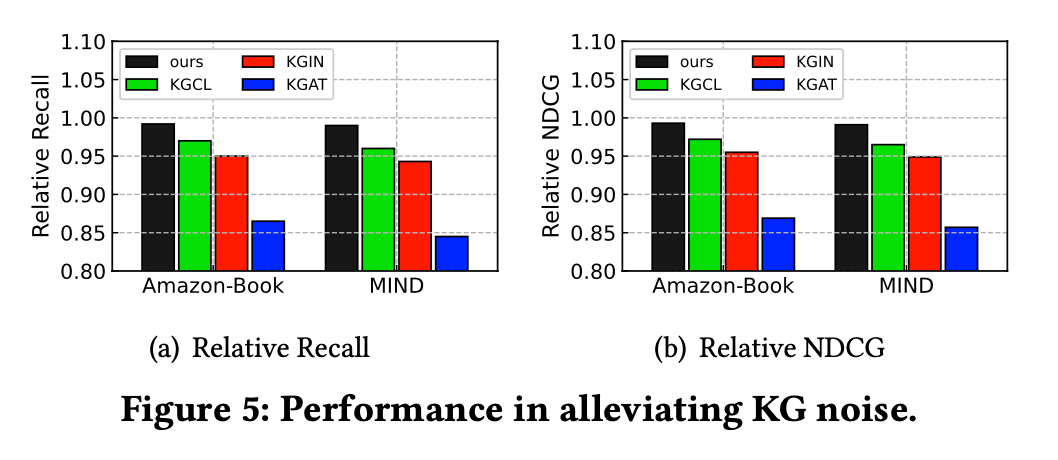
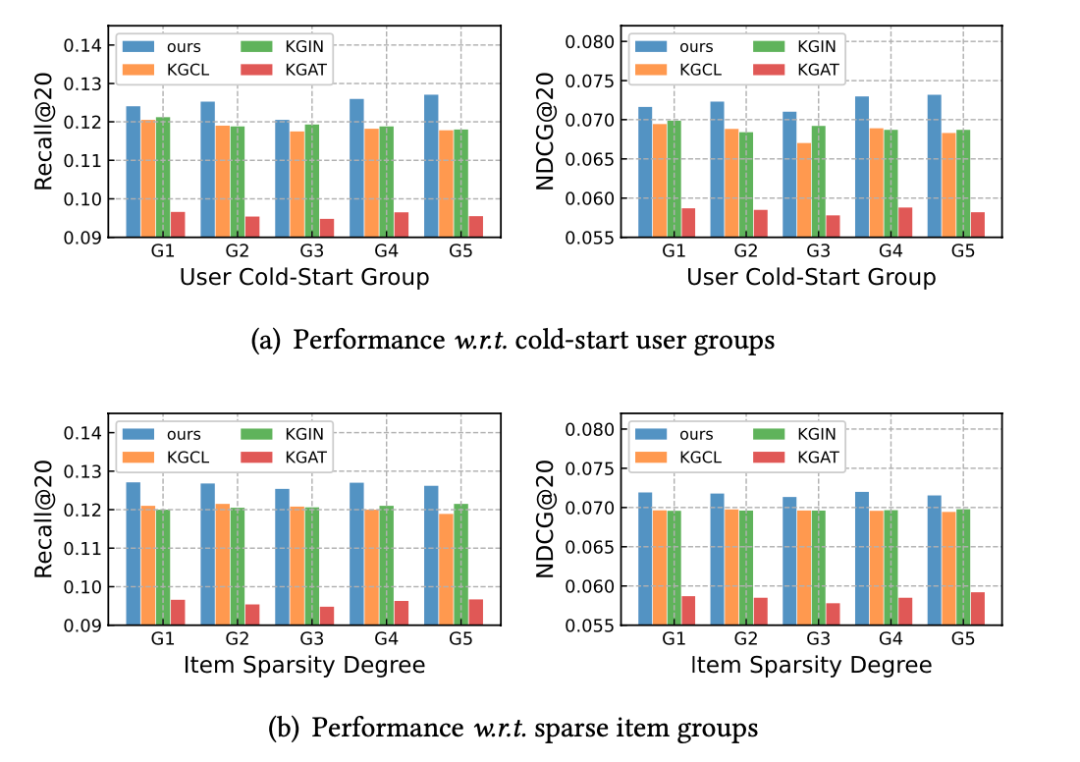
作者进一步研究了 DiffKG 在知识图谱噪声以及数据稀疏问题上的表现,结果表明知识图谱扩散模型可以有效地缓解知识图谱中存在不相关关系的噪声问题,而知识增强的数据增强范式则有效地缓解了数据稀疏问题,提升了模型的性能。
作者还进行了完整的消融实验,实验结果表明所提出的各个子组件均有提升推荐效果的功能:
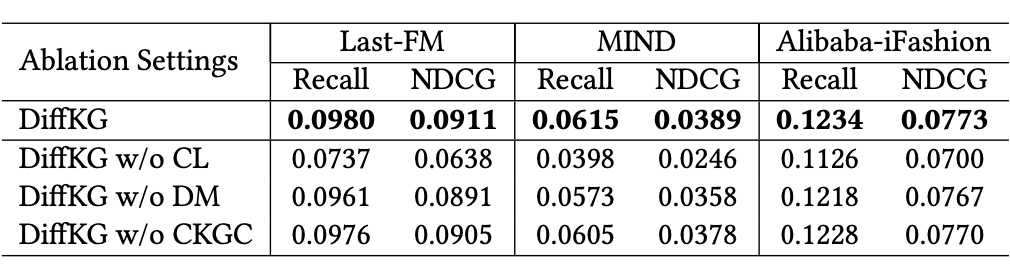
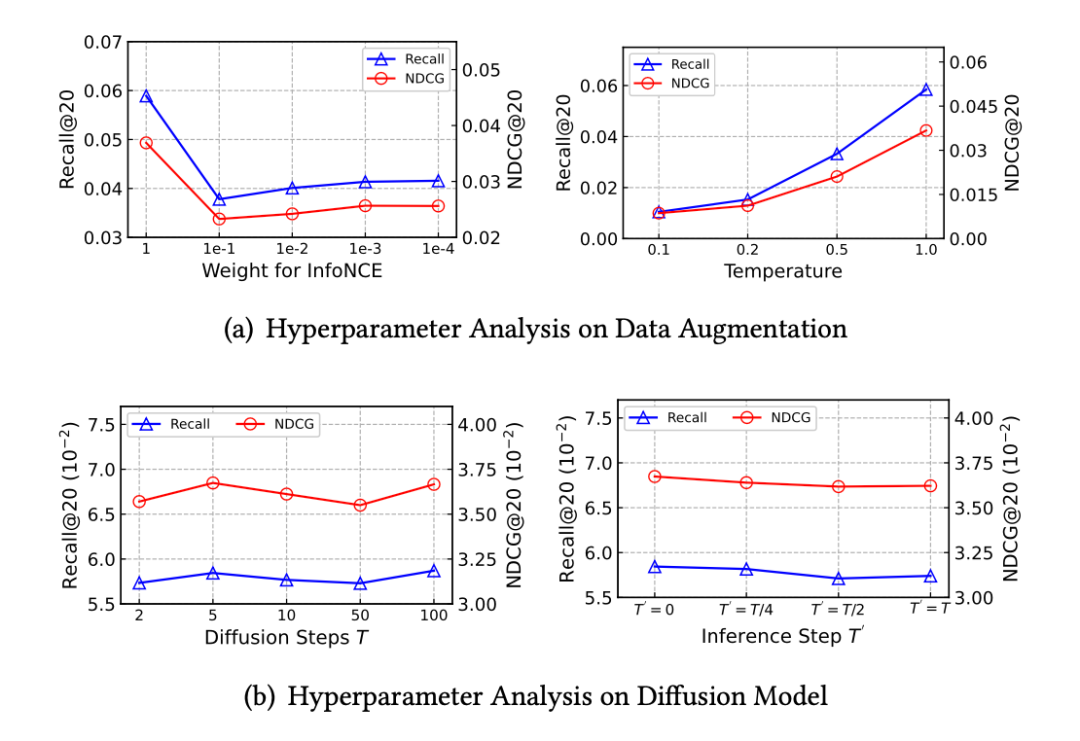
对于所提出的 DiffKG,作者对一些重要超参数进行了分析,包含了数据增强范式中的超参数和扩散模型训练及推理过程中的时间步:
除此之外,作者还在新闻推荐的数据集上进行了案例分析,通过关于 George Lucas 的新闻,对与其相关的知识图谱关系进行去噪,发现去噪后的知识图关系能够更准确地引导推荐系统进行相关新闻的推荐,证明了所提出的知识图谱扩散模型的有效性。


总结
本文提出了一种新颖的推荐模型,名为 DiffKG,它利用任务相关的物品知识来增强协同过滤范式。该框架提出了一种从包含噪声的知识图谱中提取高质量信息的独特方法。
通过将一个生成扩散模型与专为知识感知推荐系统定制的知识图学习框架无缝集成,该模型有效地将知识增强物品的语义信息与协同关系建模对齐,从而进行精准的推荐。通过在多样化的基准数据集上进行广泛的评估,作者提出的 DiffKG 框架相较于各种基线模型表现出了显著的性能提升。

参考文献
[1] Yuhao Yang, Chao Huang, Lianghao Xia, and Chenliang Li. 2022. Knowledge graph contrastive learning for recommendation. In SIGIR. 1434–1443.
[2] Ding Zou, Wei Wei, Xian-Ling Mao, Ziyang Wang, Minghui Qiu, Feida Zhu, and Xin Cao. 2022. Multi-level cross-view contrastive learning for knowledge-aware recommender system. In SIGIR. 1358–1368.
[3] Ding Zou, Wei Wei, Ziyang Wang, Xian-Ling Mao, Feida Zhu, Rui Fang, and Dangyang Chen. 2022. Improving knowledge-aware recommendation with multi-level interactive contrastive learning. In CIKM. 2817–2826.
[4] Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. In SIGIR. 639–648.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
·