文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 二.前提
- 三.本文方法
- 3.1 总结为两阶段学习
- 3.1.1 基础系统
- 3.2 重构文本摘要
- 四 实验效果
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
- 4.6 细粒度分析
- 五 总结
- 思考
前言

Abstractive Text Summarization: Enhancing Sequence-to-Sequence Models Using Word Sense Disambiguation and Semantic Content Generalization(21)
0、论文摘要
如今,大多数在抽象文本摘要领域进行的研究都只关注基于神经的模型,而没有考虑将其与基于知识的方法相结合以进一步提高其效率。在这个方向上,这项工作提出了一种新颖的框架,它将基于序列到序列的神经文本摘要与基于结构和语义的方法相结合。所提出的框架能够处理词汇外或罕见词的问题,提高深度学习模型的性能。整体方法基于基于知识的内容概括和深度学习预测的明确理论模型,用于生成抽象摘要。该框架由三个关键要素组成:(i) 预处理任务,(ii) 机器学习方法,以及 (iii) 后处理任务。预处理任务是一种基于知识的方法,基于本体知识资源、词义消歧、命名实体识别以及内容概括,将普通文本转换为概括形式。一种专注编码器-解码器架构的深度学习模型,扩展以实现应对和覆盖机制,以及强化学习和基于变压器的架构,在文本摘要对的通用版本上进行训练,学习以通用形式预测摘要。后处理任务利用知识资源、词嵌入、词义消歧和基于文本相似性方法的启发式算法,以便将预测摘要的广义版本转换为最终的、人类可读的形式。对三个流行数据集进行的广泛实验过程评估了所提出框架的关键方面,而获得的结果表现出有希望的性能,验证了所提出方法的稳健性。
一、Introduction
大量且不断增长的在线文本信息使其访问成为一项具有挑战性的任务,因此,增加了以自动化方式摄取文本信息的必要性。实现这一目标的主要方法之一是通过数据缩减技术将一段文本转换为简洁的摘要。文本摘要(TS),这个过程更正式地被称为,半个多世纪以来一直是一个活跃的研究领域(Gambhir 和 Gupta 2017)。自动 TS 的主要目标是生成内容丰富且人类可读的文档摘要,并保留其显着内容。自从自动 TS 领域的早期工作出现以来(Luhn 1958;Edmundson 1969),已经提出了几种方法和系统,主要分为单文档 TS(例如文章、新闻、故事、书籍、科学论文或天气预报)、多文档 TS(例如,用户评论、来自多个来源的新闻或电子邮件)和基于查询的 TS(即关注文本中的特定信息)(Nenkova 和 McKeown 2012)。
此外,自动 TS 技术进一步大致分为两类: (i) 提取 TS 和 (ii) 抽象 TS(Yao、Wan 和 Xiao,2017 年;Allahyari 等人,2017 年)。前者旨在通过从原始文本中提取包含重要信息方面的句子子集来创建摘要,从而最大限度地减少冗余。后者旨在构建原始文本的抽象表示,使用自然语言生成来生成摘要。换句话说,抽象 TS 系统会生成新文本,其中包含最初可能未出现的表达、句子或单词,同时包含初始文档的整体含义。摘要 TS 旨在生成具有内聚性、可读性和冗余性的高质量摘要。因此,这是一项具有挑战性的任务,因为它生成的摘要类似于或近似于人类编写的摘要。
一般来说,与提取 TS 相比,抽象 TS 方法的性能较差(Gambhir 和 Gupta 2017;Joshi、Fern ́ andez 和 Alegre 2018)。尽管如此,尽管存在缺陷,抽象 TS 系统仍在不断改进。它们的主要优点是能够解决内聚、冗余和悬空照应等问题,这些问题很难用提取技术来解决。此外,抽象 TS 方法可以生成简洁的摘要,减少原始句子的大小(即应用句子压缩或句子合并),同时生成连贯、语法正确且可读的摘要。影响抽象 TS 的问题之一是词汇外 (OOV) 或罕见单词。这个问题具有很强的负面影响,特别是对于机器学习系统,它需要足够的使用示例的训练集来进行有效的预测。此外,在抽象 TS 中实现最先进性能的深度学习系统(Gupta 和 Gupta 2019)在接收新的数据时几乎总是无法做出准确的预测。
具有罕见或未见过的单词的实例(即,很少出现的单词或未包含在训练集中的单词)。从这个意义上说,我们的工作旨在提供一种处理此类单词的解决方案,以帮助基于神经的抽象 TS。
特别是,这项工作侧重于单个文档的抽象 TS,提出了一种利用基于知识的词义消歧(WSD)和语义内容泛化的新颖框架,以增强基于序列到序列(seq2seq)神经的 TS 的性能。该框架的主要贡献是结合了抽象 TS 的三个主要方面的特征,更具体地说,是结构、语义和基于神经的方法(Gupta 和 Gupta 2019)的特征的组合,这些特征在相关领域中主要被视为独立的方法。文献(第 2 节),尤其是深度学习方法方面的文献。另一方面,所提出的框架试图通过机器学习和基于知识的技术的结合使用来统一它们。
在这个方向上,所提出的方法由三个不同的步骤组成,用于生成最终摘要; (i) 预处理任务,(ii) 机器学习方法,以及 (iii) 后处理任务。第一步通过利用基于知识的语义本体和命名实体识别(NER)来实现文本泛化,以便从原始文档中提取命名实体、概念和含义。随后,将广义文本提供给专注编码器-解码器架构的 seq2seq 深度学习模型,该模型学习预测摘要的广义版本。特别是,研究了深度学习模型的五个变体:(i)具有注意机制的 seq2seq 模型,(ii)指针生成器网络,(iii)强化学习模型,(iv)变压器方法,以及( v) 预训练的编码器变压器架构(第 5 节)。最后,后处理任务基于启发式算法和将广义摘要的概念与特定概念相匹配的文本相似性度量来创建最终摘要。在三个广泛使用的数据集(Gigaword [Napoles, Gormley, and Van Durme 2012]、Duc 2004 [Over, Dang, and Harman 2007] 和 CNN/DailyMail [Hermann et al. 2015])上进行的广泛实验程序产生了有希望的结果结果,缓解了稀有词和 OOV 词的问题,并超越了最先进的 seq2seq 深度学习技术。
本文的其余部分组织如下:第 2 节概述了相关文献。第 3 节概述了拟议的框架,第 4 节(预处理任务)、第 5 节(机器学习方法)和第 6 节(后处理任务)对此进行了进一步分析。第 7 节描述了实验过程,第 8 节介绍了获得的结果,这些结果将在第 9 节中讨论。最后,第 10 节总结了这项工作,并提出了一些最后的评论和未来的工作方向。
二.前提
三.本文方法
3.1 总结为两阶段学习
3.1.1 基础系统
3.2 重构文本摘要
四 实验效果
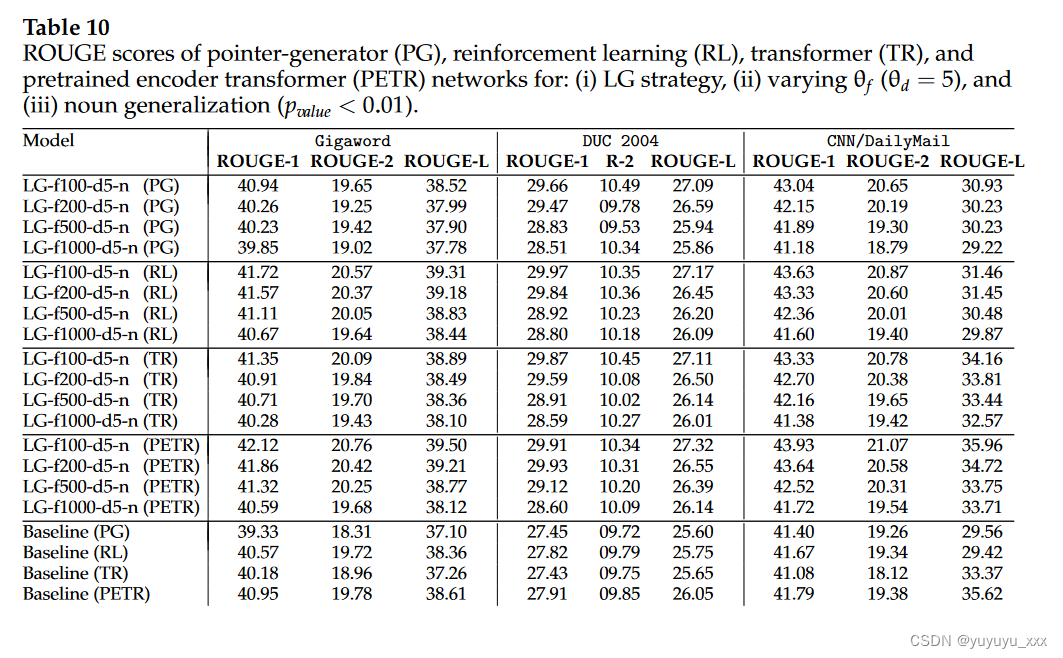
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果