文章目录
- 一:数据集介绍
- 二:一个完整的深度学习项目必备文件
- 三:项目代码
- (1)config.py——超参数文件
- (2)preprocess——数据预处理文件
- (3)dataloader——数据集封装
- (4)model——网络模型
- (5)trainer——训练脚本
- (6)inference——推理脚本
之前的波士顿房价预测案例非常简单,所以我们使用了几十行代码便完成了需求。但是在实际项目编写中可没有这么简单,如果把所有的内容都写入到一个文件中,那势必会让人十分混乱,因此本节通过一个十分简单的二分类任务来介绍完整的深度学习项目,本节中所涉及的损失函数、优化器、标准化等深度学习“组件”将会在下一节一一介绍,如果你现在对其中有些组件感觉不熟悉,那么可以线性略过,只关注整体逻辑即可
一:数据集介绍
anknote Dataset(chao票数据集):这是从zhi币鉴别过程中的图像里提取的数据,用来预测chao票的真假的数据集 。本数据集所给数据并非是原始图像数据,而是经过小波变化后的等价数据
- uci链接:banknote authentication Data Set

3.6216,8.6661,-2.8073,-0.44699,0
4.5459,8.1674,-2.4586,-1.4621,0
3.866,-2.6383,1.9242,0.10645,0
3.4566,9.5228,-4.0112,-3.5944,0
0.32924,-4.4552,4.5718,-0.9888,0
4.3684,9.6718,-3.9606,-3.1625,0
3.5912,3.0129,0.72888,0.56421,0
2.0922,-6.81,8.4636,-0.60216,0
3.2032,5.7588,-0.75345,-0.61251,0
1.5356,9.1772,-2.2718,-0.73535,0
...
该数据集中含有1372个样本,每个样本由5个数值型变量构成,4个输入变量和1个输出变量这是一个二元分类问题
-
第一列:图像经小波变换后的方差(variance)(连续值),用于描述分布的离散的程度
-
第二列:图像经小波变换后的偏度(skewness)(连续值),用于描述分布的偏移中心的程度
-
第三列:图像经小波变换后的峰度(curtosis)(连续值),用于描述概率密度分布曲线在平均值处峰值高低的特征数
-
第四列:图像的熵(entropy)(连续值)
-
第五列:chao票所属的类别(整数,0或1)
二:一个完整的深度学习项目必备文件
一个完整的项目由以下文件构成(假设项目文件夹叫做"test"),具体实施按需选择
README.md:项目说明config.py(必有):配置文件(模型配置、数据集配置、参数配置等等)data:数据集文件夹dataset_loader.py:数据集的dataloader脚本,pytorch中专门用于管理数据的加载等操作inference:推理脚本,模型训练完毕后运行进行测试,交给测试团队调用log(必有):存放日志(Pytorch中是TensorBoardX)loss.py:损失函数的设计model.py(必有):模型的设计model_save(必有):模型检查点保存(模型训练时间一般会很长,所以要进场保存,以防意外事件发生还需要重复训练)preprocess.py(必有):数据集预处理,例如数据集的划分工作tranier.py(必有):训练utils.py:工具
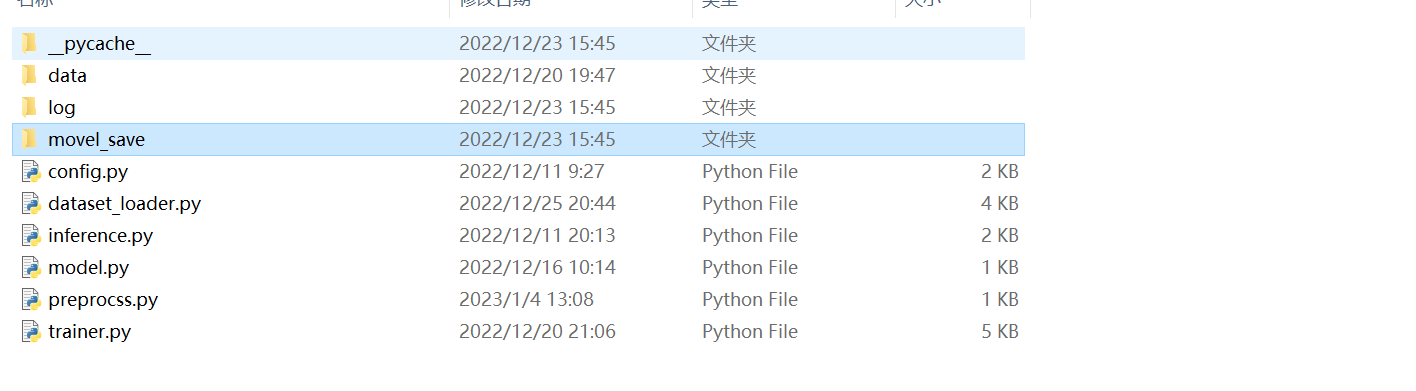
三:项目代码
整体结构如下
(1)config.py——超参数文件
该文件下需要配置项目所使用到的超参数,例如device、data_path等等,这些参数需要预先设定。主要目的是为了方便统一修改
class Parameters:
########################################## 数据 #############################################
device = 'cpu' # 指定设备(如果有GPU则为'cuda')
data_dir = r'./data/' # 所有数据所在文件夹
data_path = r'./data/data_banknote_authentication.txt' # 源数据路径
trainset_path = r'./data/train.txt' # 训练数据集路径
valset_path = r'./data/val.txt' # 验证集路径
testset_path = r'./data/test.txt' # 测试集路径
in_features = 4 # 输入数据的特征数
out_dim = 2 # 输出结果,由于是二分类问题,所以输出为2
seed = 1234 # 随机种子
########################################## 网络结构 #############################################
layer_list = [in_features, 64, 128, 64, out_dim] # 层次顺序:输入层:三个隐藏层:输出层
########################################## 环境 #############################################
batch_size = 64 # batch_size大小
init_lr = 1e-3 # 初始学习率
epochs = 100 # 训练轮数
verbose_step = 10 # 每10步打印一次
save_step = 200 # 每200步保存一次
parameters = Parameters()
(2)preprocess——数据预处理文件
该文件下需要对数据进行预处理,比如在这个例子中我把原始数据集划分为三个部分(训练、验证和测试)
import numpy as np
from config import parameters
import os
# 训练集、验证集和测试集划分比例
trainset_ratio = 0.7
valset_ratio = 0.2
test_set = 0.1
# 设置随机种子,读取源数据并打乱
np.random.seed(parameters.seed)
dataset = np.loadtxt(parameters.data_path, delimiter=',')
np.random.shuffle(dataset)
# 样本数量
n_items = np.shape(dataset)[0]
# 划分数据
trainset = dataset[:int(trainset_ratio*n_items), ]
valset = dataset[int(trainset_ratio*n_items):int(trainset_ratio*n_items)+int(valset_ratio*n_items), :]
testset = dataset[int(trainset_ratio*n_items)+int(valset_ratio*n_items):, ]
# 存储
np.savetxt(os.path.join(parameters.data_dir, 'train.txt'), trainset, delimiter=',')
np.savetxt(os.path.join(parameters.data_dir, 'val.txt'), valset, delimiter=',')
np.savetxt(os.path.join(parameters.data_dir, 'test.txt'), testset, delimiter=',')
(3)dataloader——数据集封装
Pytorch中使用DataLoader加载数据集时,需要统一继承torch.utils.data.Dataset类,所以这里书写如下
import torch
from torch.utils.data import DataLoader
from torch.utils.data import sampler
from config import parameters
import numpy as np
class BankfakeDataset(torch.utils.data.Dataset):
def __init__(self, data_path):
self.dataset = np.loadtxt(data_path, delimiter=',')
# 返回其X和y(输入数据和标签)
# 至少要重写__getitem__和__len__方法
def __getitem__(self, idx):
item = self.dataset[idx]
X, y = item[:parameters.in_features], item[parameters.in_features:]
"""
to(parameters.device):会把数据送到CPU或GPU
squeeze():会把维度为1的那个维度去掉
"""
return torch.Tensor(X).float().to(parameters.device), \
torch.Tensor(y).squeeze().long().to(parameters.device)
def __len__(self):
return np.shape(self.dataset)[0]
(4)model——网络模型
该文件用于存放你的模型设计,具体问题有具体的模型结构。对于本案例,是一个简单的二分类问题,所以搭建几个全连接层就ok了
import torch
from config import parameters
from torch import nn
class BankfakeModel(nn.Module):
def __init__(self, ):
super(BankfakeModel, self).__init__()
self.linear_layer = nn.ModuleList([
nn.Linear(in_features=in_dim, out_features=out_dim)
for in_dim, out_dim in zip(parameters.layer_list[:-1], parameters.layer_list[1:])
])
def forward(self, input_x):
for layer in self.linear_layer:
input_x = layer(input_x)
input_x = nn.functional.relu(input_x)
return input_x
# 测试
if __name__ == '__main__':
model = BankfakeModel()
X = torch.randn(size=(16, parameters.in_features)).to(parameters.device)
y_pred = model(X)
print(y_pred)
print(y_pred.size())
(5)trainer——训练脚本
该文件用于对模型进行训练和验证,对于大多数问题来说,该文件的写法比较固定,有的也是些许的改动
import os
import torch
import random
import numpy as np
from tensorboardX import SummaryWriter
from argparse import ArgumentParser
from torch.utils.data import DataLoader
from config import parameters
from dataset_loader import BankfakeDataset
from model import BankfakeModel
# 日志记录
logger = SummaryWriter('./log')
# 随机种子
torch.manual_seed(parameters.seed) # CPU随机种子
# torch.cuda.manual_seed(parameters.seed) # GPU随机种子(若有)
random.seed(parameters.seed) # random随机种子
np.random.seed(parameters.seed) # numpy随机种子
# 使用验证集对模型进行评估
def evaluate(model, val_loader, loss_func):
# 进入eval模式
model.eval()
sum_loss = 0.
# with torch.no_grad()含义:https://blog.csdn.net/qq_42251157/article/details/124101436
with torch.no_grad():
for batch in val_loader:
X, y = batch
pred = model(X)
loss = loss_func(pred, y)
sum_loss += loss.item()
# 特别注意返回train模式
model.train()
return sum_loss / len(val_loader)
# 保存模型
def save_checkpoint(model, epoch, optimizer, checkpoint_path):
save_dict = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict()
}
torch.save(save_dict, checkpoint_path)
# 训练函数
def train():
# 有关argparse.ArgumentParser用法:https://blog.csdn.net/u011913417/article/details/109047850
# 其作用是解析命令行参数,目的是在终端窗口(ubuntu是终端窗口,windows是命令行窗口)输入训练的参数和选项
parser = ArgumentParser(description='Model Training')
parser.add_argument(
'--c',
# 当模型再次训练时选择从头开始还是从上次停止的地方开始
default=None, # 当参数未在命令行中出现时使用的值
type=str, # 参数类型
help='from head or last checkpoint?' # 参数说明
)
args = parser.parse_args()
# 模型实例
model = BankfakeModel()
model = model.to(parameters.device)
# 损失函数(这里比较简单所以直接定义,否则需要新建文件loss.py存放)
loss_func = torch.nn.CrossEntropyLoss() # 交叉熵损失函数
# 优化器
optimizer = torch.optim.Adam(model.parameters(), parameters.init_lr)
# 训练数据加载
trainset = BankfakeDataset(parameters.trainset_path)
train_loader = DataLoader(trainset, batch_size=parameters.batch_size, shuffle=True, drop_last=True)
# 验证数据加载(在evaluation函数中进行评估)
valset = BankfakeDataset(parameters.valset_path)
val_loader = DataLoader(valset, batch_size=parameters.batch_size, shuffle=True, drop_last=False)
# 起始训练轮数, 步数
start_epoch, step = 0, 0
# 判断参数,是否需要从检查点开始训练
# 主要针对大型数据,可能会训练几个小时或几天,所以容易出现问题
if args.c:
checkpoint = torch.load(args.c) # 加载模型
# 加载参数(权重系数、偏置值、梯度等等)
start_epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
print("参数加载成功")
else:
print("从头开始训练")
# 关于model.train()说明:https://blog.csdn.net/weixin_44211968/article/details/123774649
model.train() # 启用 batch normalization 和 dropout
# 训练过程
for epoch in range(start_epoch, parameters.epochs):
print("-----------当前epoch:{}-----------".format(epoch))
for i, batch in enumerate(train_loader):
print("-----------当前batch:{}/{}-----------".format(i, len(trainset)//(parameters.batch_size)))
X, y = batch
pred = model(X)
loss = loss_func(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
logger.add_scalar('loss/train', loss, step)
# 每10步进行验证集评估并保存
if not step % parameters.verbose_step:
eval_loss = evaluate(model, val_loader, loss_func)
logger.add_scalar('loss/val', eval_loss, step)
if not step % parameters.save_step:
model_path = "epoch-{}_step-{}.pth".format(epoch, step)
save_checkpoint(model, epoch, optimizer, os.path.join('movel_save', model_path))
step += 1
logger.flush()
print("当前step:{};当前train_loss:{:.5f};当前val_loss:{:.5f}".format(step, loss.item(), eval_loss))
logger.close()
if __name__ == '__main__':
train()
(6)inference——推理脚本
模型训练完毕,然后选择出最佳模型后,就可以在该文件中加载模型对测试集上的数据做出预测
import torch
from torch.utils.data import DataLoader
from dataset_loader import BankfakeDataset
from model import BankfakeModel
from config import parameters
# 网络实例
model = BankfakeModel()
# 加载模型:观察tensorboard可知,迭代600次时模型收敛
checkpoint = torch.load('./movel_save/epoch-40_step-600.pth')
# 加载模型参数
model.load_state_dict(checkpoint['model_state_dict'])
# 加载测试数据
testset = BankfakeDataset(parameters.testset_path)
test_loader = DataLoader(testset, batch_size=parameters.batch_size, shuffle=True, drop_last=False)
# 预测时,进入eval模式
model.eval()
# 分别表示总的数据个数和预测正确的个数
total_num = 0
correct_num = 0
with torch.no_grad():
for batch in test_loader:
X, y = batch
pred = model(X)
total_num += pred.size(0)
"""
pred是一个有2个元素的列表,分别表示当前纸币真假的概率,所以
我们只需选择最大概率即可,这里选择索引后正好就和真实标签中的
0/1对应了
"""
correct_num += (torch.argmax(pred, 1) == y).sum()
print("测试数据{}个,正确预测{}个,预测准确率:{}%".format(total_num, correct_num, (correct_num / total_num) * 100))