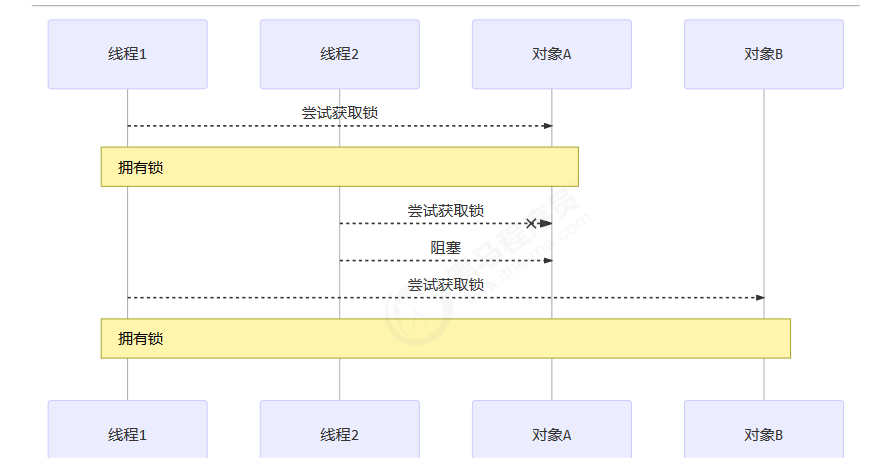
大模型
- 大模型生态
- OpenAI大模型生态:
- 全球开源大模型性能评估榜单
- 中文语言模型——ChatGLM
- 基于ChatGLM的多模态⼤模型
- 大模型微调
- LLM⼤语⾔模型 ⼀般训练过程
- 为什么需要微调
- 高效微调技术⽅法概述
- ⾼效微调⽅法一:LoRA微调方法
- 高效微调⽅法⼆:Prefix Tuning
- ⾼效微调⽅法三:Prompt Tuning
- ⾼效微调⽅法四:P-Tuning v2
本系列阅读资料来自于B站九天菜菜的大模型课堂
第一部分,需要掌握效果最好、生态最丰富、功能最齐全OpenAl发布的大模型组
第二部分,需要掌握目前中文效果最好、最具潜力、同时具备多模态功能的开源大模型一ChatGLM 6B visualGLM 6B
大模型生态
OpenAI大模型生态:
并不只有一个模型,而是提供了涵盖文本、代码、对话、语音、图像领域的一系列模型
语言类大模型:GPT-3、GPT-3.5、GPT-4系列模型。并且OpenAl在训练GPT-3的同时,训练了参数不同、复杂度各不相同的A、B、C、D四项大模型(基座模型),用于不同场景的应用;
- 其中,A、B、C、D模型的全称分别是ada、babbage、curie和davinci,四个模型并不是GPT-3的微调模型,而是独立训练的四个模型;
- 四个模型的参数规模和复杂程度按照A-B-C-D顺序依次递增;虽不如GPT-3.5和GPT-4那么有名,但A、B、C、D四大模型却是目前OpenAl大模型生态中功能最丰富、AP种类最多的四个模型;

图像多模态大模型:最新版为DALL·E达利)V2,是DALL·E模型的第二版训练版,能够根据描述生成图像;
- DALL·E模型为基于GPT-3开发的模型,总共包含120亿个参数,不难看出DALL·E对图像的理解能力源于大语言模型;
- OpenAl将大语言模型的理解能力“复制”到视觉领域的核心方法:将图像视作一种一种语言,将其转化为Token,并和文本Token一起进行训练;
语音识别模型:最新版为Whisper v2-large model,是Whispert模型的升级版,能够执行多语言语音识别以及语音翻译和语言识别;
-
Whisper模型是为数不多的OpenAlf的开源模型,改模型通过68万小时的多语言和多任务监督数据进行的训练,目前提供了原始论文进行方法介绍
-
Whispert模型可以本地部署,也可以像其他OpenAlz大模型一样通过调用API进行在线使用,并且根据官网介绍,Whisper在线模型会有额外运行速度上的优化,通过调用API进行使田效率更高(当然也雲要支付一定的费用)
文本向量化模型:Embedding⽂本嵌⼊模型,⽤于将⽂本转化为词向量,即⽤⼀ 个数组(向量)来表示⼀个⽂本,该⽂本可以是短语、句⼦或者⽂章;
- 最新⼀代Embedding模型是基于ada模型微调的text-embedding-ada-002模型;
- 通过将⽂本转化为词向量,就可以让计算机进⼀步的“读懂⽂本”,通过词向量的计算和分析和相似度计算,可以对其背后的⽂本进⾏搜索、聚类、推荐、异常检测和分类等
- 最终,Embedding会将词、句⼦或者更⾼级别的语⾔结构,映射到⾼维空间的向量中,使得语义上相近的词或者句⼦在向量空间中的距离也较近;
- 例如Embedding后的句⼦,“⽼⿏在找吃的”将和 “奶酪”词向ᰁ接近,因为⼆者表意类似。⽽与之句式格式与之相近的“猫在找⻝物”,则距离更远; ○ GPT模型的Embedding层往往是在与训练过程中通过⾃回归训练完成,同时在微调时,也往往会修改Embedding层;
审查模型:Moderation模型,旨在检查内容是否符合 OpenAI 的使⽤政策。 这 些模型提供了查找以下类别内容的分类功能:仇恨、仇恨/威胁、⾃残、性、性/ 未成年⼈、暴⼒和暴⼒/图⽚等。
编程⼤模型:Codex⼤模型,⽤GitHub数⼗亿⾏代码训练⽽成,能够“读懂”代码,并且能够根据⾃然语⾔描述进⾏代码创建;
-
Codex最擅⻓Python,同时精通JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL,
甚⾄ Shell 等⼗⼏种编程语⾔; -
该模型发布于2021年8⽉10⽇,⽬前代码编写功能已经合并⼊GPT-3.5,官⽹显示该模型为已弃⽤(deprecated)状态,意为后续不再单独维护,但并不表示OpenAI已放弃编程⼤模型,相反越来越多的编程功能被集成到语⾔⼤模型中
-
⽬前该模型集成于Visual Studio Code、GitHub Copilot、Azure OpenAI
Service等产品中,⽤于提 供⾃动编程功能⽀持; • 在models->overiew中可查看⽬前OpenAI模型⼤类;
• 地址:https://platform.openai.com/docs/models/overview
OpenAI API命名规则
• 通⽤模型API:如GPT-3.5-turbo,GPT-4,ada…
• 停⽌维护但仍可使⽤的API:如GPT-3.5-turbo-0301(3⽉1号停⽌维护), GPT-4-0314(3⽉14号停⽌维护)…
• ⾯向特定功能的微调模型API:如ada-code-search-code(基于ada微调的编程 ⼤模型),babbage-similarity(基于babbage微调的的⽂本相似度检索模型)
• 多版本编号模型API:如text-davinci-001(达芬奇⽂本模型1号)、textembedding-ada-002(基于ada的Embedding模型2号)…
谷歌PaLM2 Models:
四项大模型:Gecko(壁虎)、Otter(水獭)Bison(野牛)、Unicorn(独角兽),最小的Gecko模型可以在移动端运行,并计划在下一代安卓系统中集成;
全球开源大模型性能评估榜单
Hugging Face
LMSYS组织(UC伯克利背景):通过匿名PK进⾏模型性能⽐较,同时纳⼊开源⼤ 模型和在线⼤模型进⾏PK,其中GPT-4排名第⼀,
中文语言模型——ChatGLM
ChatGLM130B模型是由清华⼤学团队开发的⼤语⾔模型,该模型借鉴了ChatGPT 的设计思路,在千亿基座模型 GLM-130B1 中注⼊了代码预训练,通过有监督微调(Supervised FineTuning)等技术实现⼈类意图对⻬。2022年11 ⽉,斯坦福⼤学⼤模型中⼼对全球30个主流⼤ 模型进⾏了全⽅位的评测,GLM-130B 是亚洲 唯⼀⼊选的⼤模型。在与 OpenAI、⾕歌⼤脑、微软、英伟达、脸书的各⼤模型对⽐中, 评测报告显示 GLM-130B 在准确性和恶意性 指标上与 GPT-3 175B (davinci) 接近或持平。
此外,清华⼤学团队同时开源 ChatGLM-6B 模型。 ChatGLM-6B 是⼀个具有62亿参数的中英双语语⾔模型。通过使⽤与 ChatGLM(chatglm.cn)相同的技术,ChatGLM-6B 初具中⽂问答和对话功能,并⽀持在单张 2080Ti 上进⾏推理使⽤。具体来说,
ChatGLM-6B 有如下特点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 ⽐例的中英语料上训练了 1T token 量,兼具双语能⼒;
- 较低的部署⻔槛: FP16 半精度下,ChatGLM-6B 需要⾄少 13GB 的显存进⾏推理,结合模型量化技术,这⼀需求可以进⼀步降低到
10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上;
ChatGLM 6B丰富的开源⽣态
• 微调框架:ChatGLM 6B + P- Tuning微调,项⽬地址:
https://github.com/THUDM/ChatGLM-6B/blob/main/ptuning/README.md •
微调框架:ChatGLM 6B + LoRA微调,项⽬地址:
https://github.com/mymusise/ChatGLM-Tuning • 本地知识库:ChatGLM 6B +
LangChain,项⽬地址: https://github.com/imClumsyPanda/langchain-ChatGLM •
多轮对话前端:ChatGLM 6B多轮对话的Web UI展示,项⽬地址:
https://github.com/Akegarasu/ChatGLM-webui
基于ChatGLM的多模态⼤模型
VisualGLM 6B :https://github.com/THUDM/VisualGLM-6B
-
VisualGLM-6B 是⼀个开源的,⽀持图像、中⽂和英⽂的多模态对话语⾔模型, 语⾔模型基于 ChatGLM-6B,具有 62
亿参数;图像部分通过训练 BLIP2- Qformer 构建起视觉模型与语⾔模型的桥梁,整体模型共78亿参数。 -
VisualGLM-6B 依靠来⾃于 CogView 数据集的30M⾼质量中⽂图⽂对,与300M 经过筛选的英⽂图⽂对进⾏预训练,中英⽂权重相同。该训练⽅式较好地将视觉信息对⻬到ChatGLM的语义空间;之后的微调阶段,模型在⻓视觉问答数据上训练,以⽣成符合⼈类偏好的答案
模型实现思路区别
-
Dall·E:将图像视作⼀种语⾔,将其转化为离散化的Token并进⾏训练,优势在 于能够⾮常详细的描述⼀张图⽚,但缺点在于图像的Token利⽤率较低,需要 1000以上的Token才能描述⼀张256分辨率的图;
-
VisualGLM:考虑到⼈类在认识图⽚的时候,往往只对少量视觉语意信息感兴趣,因此可以不⽤将整个图⽚全部离散化为图⽚,只将图⽚特征对其到预训练语⾔模型即可,这也是BLIP-2的视觉语⾔与训练⽅法实现策略。优势在于能够 充分语⾔模型,缺点在于会缺失图像部分底层信息(细节信息);
医学影像诊断⼤模型:XrayGLM 6B:https://github.com/WangRongsheng/XrayGLM
-
基于VisualGLM模型,在UI-XRay医学诊断报告数据集上进⾏微调⽽来;
-
报告翻译借助OpenAI GPT模型完成翻译,微调框架为LoRA;
大模型微调

LLM⼤语⾔模型 ⼀般训练过程

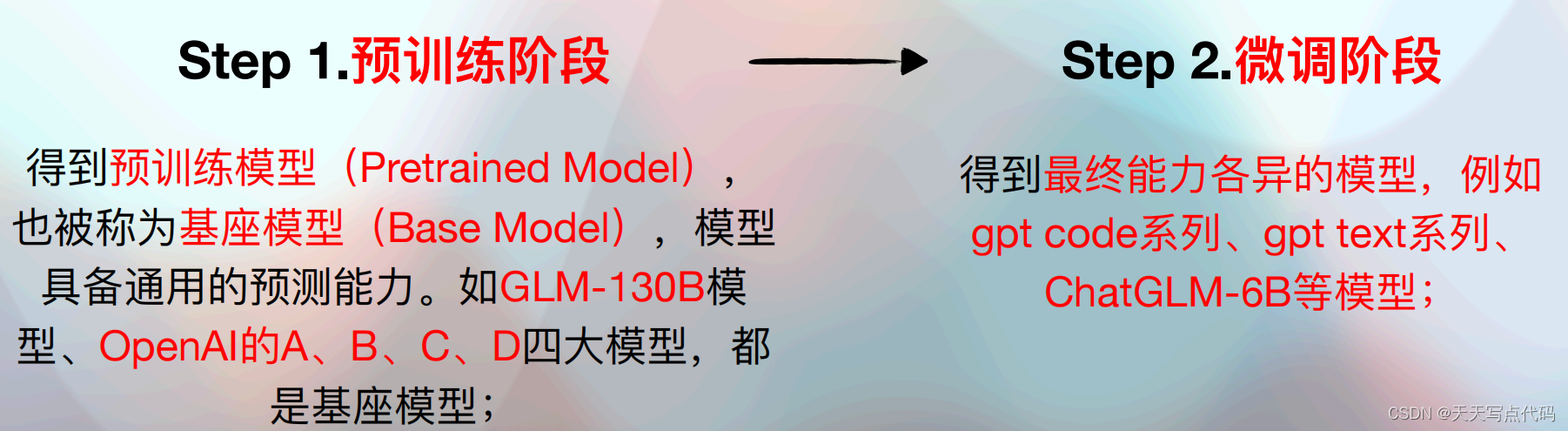
感性理解:⼤模型微调指的是“喂”给模型更多信息,对模型的特定功能进⾏ “调教” ,即通过输⼊特定领域的数据集,让其学习这个领域的知识,从⽽让⼤模型能够更好的完成特定领域的NLP任务,例如情感分析、命名实体识别、⽂本分类、对话聊天等;
为什么需要微调
核⼼原因还是在于需要“赋予”⼤模型更加定制化的功能,例如结合本地知识库进⾏检索、围绕特定领域问题进⾏问答等;
-
例如,VisualGLM是通⽤多模态⼤模型,但应⽤于医学影像判别领域,则需要代⼊医学影像领域的数据集来进⾏⼤模型微调,从⽽使得模型能够更好的围绕医学影像图⽚进⾏识别;
-
就像机器学习模型的超参数优化,只有调整了超参数,才能让模型更佳适⽤于当前的数据 集
-
同时,⼤模型是可以多次进⾏微调,每次微调都是⼀次能⼒的调整,即我们可以在现有的、 已经具备某些特定能⼒的⼤模型基础上进⼀步进⾏微调;
自回归概念:⼤模型的预训练过程是采⽤了⼀种名为⾃回归(Autoregressive)的⽅法,⾃回归模型是⼀种序列模型,它在预测下⼀个输出时,会将之前的所有输出作为输⼊,然后根据统计规律、结合已经输⼊的样本,预测下个位置各单词出现的概率,然后输出概率最⼤的单词,类似于完形填空;
生成式概念:与之类似的还有⼀个名为⽣成式模型的概念,也就是GPT中的G(Generative),所谓⽣成式模型的预测过程和⾃回归模型类似,都是根据统计规律预测下个单词的概率,所不同的是,⽣成式模型可以根据之前的样本的概率分布⽣成下⼀个词,⽣成式模型预测时会存在⼀定的随机性;


⼀个经过预训练的⼤语⾔模型,就具备“⼀定程度的”通⽤能⼒,⽽只有经过微调,才能够让模型具备解决某项具体任务的能⼒
-
微调并不是大模型领域独有的概念,而是伴随着深度学习技术发展,自然诞生的一个技术分支,旨在能够有针对性的调整深度学习模型的参数(或者模型结构),从而能够使得其更佳高效的执行某些特定任务,而不用重复训练模型;
-
伴随着大模型技术的蓬勃发展,微调技术一跃成为大模型工程师必须要掌握的核心技术。并且,伴随着大模型技术的蓬勃发展,越来越多的微调技术也在不断涌现;




高效微调技术⽅法概述

-
深度学习微调⽅法⾮常多,主流⽅法包括LoRA、Prefix Tuning、P- Tuning、Promt Tuning、
AdaLoRA等; -
目前这些⽅法的实现均已集成⾄Hugging Face项⽬的库中,我们可以通过安装和调Hugging
Face的PEFT(⾼效微调)库,来快速使⽤这些⽅法; https://github.com/huggingface/peft -
Hugging Face 是⼀家专注于⾃然语⾔处理 (NLP)技术的公司,同时也开发并维护了多个⼴ 受欢迎的⾃然语⾔处理的开源库和⼯具,如
Transformers 库、ChatGLM-6B库等; -
⾼效微调,State-of-the-art Parameter-Efficient Fine-Tuning (SOTA
PEFT),与之对应的更早期的简单的全量参数训练微调的⽅法(Fine- Tuning), ⾼效微调则是⼀类算⼒功耗⽐更⾼的⽅法;
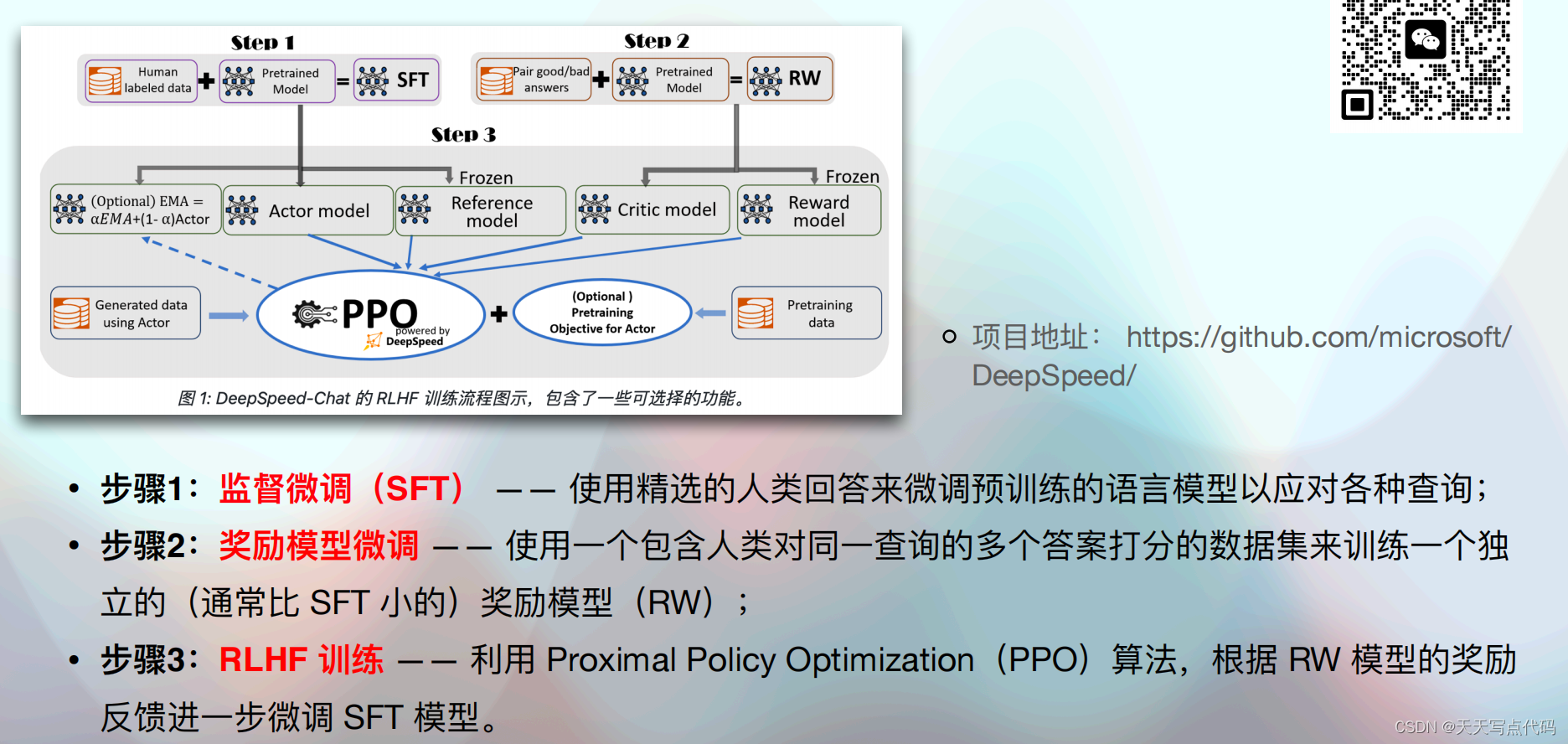
基于强化学习的进阶微调⽅法RLHF⽅法
-
RLHF:Reinforcement Learning from Human
Feedback,即基于⼈⼯反馈机制的强化学习。最早与2022年4⽉,由OpenAI研究团队系统总结并提出,并在GPT模型的对话类任务微调中⼤放异彩,被称为ChatGPT“背后的功⾂”; -
RLHF也是⽬前为⽌常⽤的、最为复杂的基于强化学习的⼤语⾔模型微调⽅法,⽬前最好的端到端RLHF实现是DeepSpeedChat库,由微软开源并维护;

⾼效微调⽅法一:LoRA微调方法


Github: https://github.com/microsoft/LoRA
论文地址:https://arxiv.org/abs/2106.09685
高效微调⽅法⼆:Prefix Tuning

⾼效微调⽅法三:Prompt Tuning

⾼效微调⽅法四:P-Tuning v2

GitHub:地址:https://github.com/THUDM./P-tuning-v2
论文地址:https://aclanthology.org/2021.ac-long.353/
ChatGLM-6B+P-Tuning微调项目地址:https://github.com/THUDM/ChatGLM-6B/blob/main/ptuning/README.md