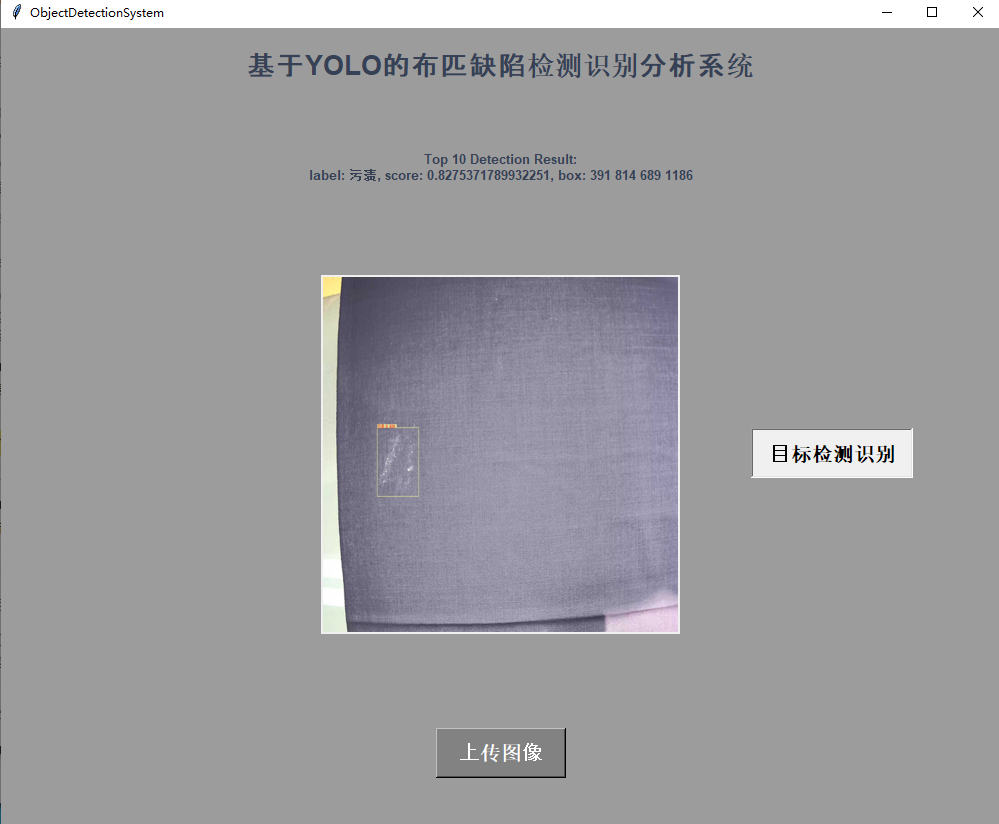
1. sklearn简介
sklearn是基于python语言的机器学习工具包,是目前做机器学习项目当之无愧的第一工具。 sklearn自带了大量的数据集,可供我们练习各种机器学习算法。 sklearn集成了数据预处理、数据特征选择、数据特征降维、分类\回归\聚类模型、模型评估等非常全面算法。
2.sklearn数据类型
机器学习最终处理的数据都是数字,只不过这些数据可能以不同的形态被呈现出来,如矩阵、文字、图片、视频、音频等。
3.sklearn总览

数据集
sklearn.datasets
获取小数据集(本地加载):datasets.load_xxx( )
获取大数据集(在线下载):datasets.fetch_xxx( )
本地生成数据集(本地构造):datasets.make_xxx( )
数据集 | 介绍 |
load_iris( ) | 鸢尾花数据集:3类、4个特征、150个样本 |
load_boston( ) | 波斯顿房价数据集:13个特征、506个样本 |
load_digits( ) | 手写数字集:10类、64个特征、1797个样本 |
load_breast_cancer( ) | 乳腺癌数据集:2类、30个特征、569个样本 |
load_diabets( ) | 糖尿病数据集:10个特征、442个样本 |
load_wine( ) | 红酒数据集:3类、13个特征、178个样本 |
load_files( ) | 加载自定义的文本分类数据集 |
load_linnerud( ) | 体能训练数据集:3个特征、20个样本 |
load_sample_image( ) | 加载单个图像样本 |
load_svmlight_file( ) | 加载svmlight格式的数据 |
make_blobs( ) | 生成多类单标签数据集 |
make_biclusters( ) | 生成双聚类数据集 |
make_checkerboard( ) | 生成棋盘结构数组,进行双聚类 |
make_circles( ) | 生成二维二元分类数据集 |
make_classification( ) | 生成多类单标签数据集 |
make_friedman1( ) | 生成采用了多项式和正弦变换的数据集 |
make_gaussian_quantiles( ) | 生成高斯分布数据集 |
make_hastie_10_2( ) | 生成10维度的二元分类数据集 |
make_low_rank_matrix( ) | 生成具有钟形奇异值的低阶矩阵 |
make_moons( ) | 生成二维二元分类数据集 |
make_multilabel_classification( ) | 生成多类多标签数据集 |
make_regression( ) | 生成回归任务的数据集 |
make_s_curve( ) | 生成S型曲线数据集 |
make_sparse_coded_signal( ) | 生成信号作为字典元素的稀疏组合 |
make_sparse_spd_matrix( ) | 生成稀疏堆成的正定矩阵 |
make_sparse_uncorrelated( ) | 使用稀疏的不相关设计生成随机回归问题 |
make_spd_matrix( ) | 生成随机堆成的正定矩阵 |
make_swiss_roll( ) | 生成瑞士卷曲线数据集 |
数据集读取的部分代码:
from sklearn import datasets
import matplotlib.pyplot as plt
iris = datasets.load_iris()
features = iris.data
target = iris.target
print(features.shape,target.shape)
print(iris.feature_names)
boston = datasets.load_boston()
boston_features = boston.data
boston_target = boston.target
print(boston_features.shape,boston_target.shape)
print(boston.feature_names)
digits = datasets.load_digits()
digits_features = digits.data
digits_target = digits.target
print(digits_features.shape,digits_target.shape)
img = datasets.load_sample_image('flower.jpg')
print(img.shape)
plt.imshow(img)
plt.show()
data,target = datasets.make_blobs(n_samples=1000,n_features=2,centers=4,cluster_std=1)
plt.scatter(data[:,0],data[:,1],c=target)
plt.show()
data,target = datasets.make_classification(n_classes=4,n_samples=1000,n_features=2,n_informative=2,n_redundant=0,n_clusters_per_class=1)
print(data.shape)
plt.scatter(data[:,0],data[:,1],c=target)
plt.show()
x,y = datasets.make_regression(n_samples=10,n_features=1,n_targets=1,noise=1.5,random_state=1)
print(x.shape,y.shape)
plt.scatter(x,y)
plt.show()数据预处理

sklearn.preprocessing
函数 | 功能 |
preprocessing.scale( ) | 标准化 |
preprocessing.MinMaxScaler( ) | 最大最小值标准化 |
preprocessing.StandardScaler( ) | 数据标准化 |
preprocessing.MaxAbsScaler( ) | 绝对值最大标准化 |
preprocessing.RobustScaler( ) | 带离群值数据集标准化 |
preprocessing.QuantileTransformer( ) | 使用分位数信息变换特征 |
preprocessing.PowerTransformer( ) | 使用幂变换执行到正态分布的映射 |
preprocessing.Normalizer( ) | 正则化 |
preprocessing.OrdinalEncoder( ) | 将分类特征转换为分类数值 |
preprocessing.LabelEncoder( ) | 将分类特征转换为分类数值 |
preprocessing.MultiLabelBinarizer( ) | 多标签二值化 |
preprocessing.OneHotEncoder( ) | 独热编码 |
preprocessing.KBinsDiscretizer( ) | 将连续数据离散化 |
preprocessing.FunctionTransformer( ) | 自定义特征处理函数 |
preprocessing.Binarizer( ) | 特征二值化 |
preprocessing.PolynomialFeatures( ) | 创建多项式特征 |
preprocesssing.Normalizer( ) | 正则化 |
preprocessing.Imputer( ) | 弥补缺失值 |
数据预处理代码
import numpy as np
from sklearn import preprocessing
#标准化:将数据转换为均值为0,方差为1的数据,即标注正态分布的数据
x = np.array([[1,-1,2],[2,0,0],[0,1,-1]])
x_scale = preprocessing.scale(x)
print(x_scale.mean(axis=0),x_scale.std(axis=0))
std_scale = preprocessing.StandardScaler().fit(x)
x_std = std_scale.transform(x)
print(x_std.mean(axis=0),x_std.std(axis=0))
#将数据缩放至给定范围(0-1)
mm_scale = preprocessing.MinMaxScaler()
x_mm = mm_scale.fit_transform(x)
print(x_mm.mean(axis=0),x_mm.std(axis=0))
#将数据缩放至给定范围(-1-1),适用于稀疏数据
mb_scale = preprocessing.MaxAbsScaler()
x_mb = mb_scale.fit_transform(x)
print(x_mb.mean(axis=0),x_mb.std(axis=0))
#适用于带有异常值的数据
rob_scale = preprocessing.RobustScaler()
x_rob = rob_scale.fit_transform(x)
print(x_rob.mean(axis=0),x_rob.std(axis=0))
#正则化
nor_scale = preprocessing.Normalizer()
x_nor = nor_scale.fit_transform(x)
print(x_nor.mean(axis=0),x_nor.std(axis=0))
#特征二值化:将数值型特征转换位布尔型的值
bin_scale = preprocessing.Binarizer()
x_bin = bin_scale.fit_transform(x)
print(x_bin)
#将分类特征或数据标签转换位独热编码
ohe = preprocessing.OneHotEncoder()
x1 = ([[0,0,3],[1,1,0],[1,0,2]])
x_ohe = ohe.fit(x1).transform([[0,1,3]])
print(x_ohe)
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
x = np.arange(6).reshape(3,2)
poly = PolynomialFeatures(2)
x_poly = poly.fit_transform(x)
print(x)
print(x_poly)
import numpy as np
from sklearn.preprocessing import FunctionTransformer
#自定义的特征转换函数
transformer = FunctionTransformer(np.log1p)
x = np.array([[0,1],[2,3]])
x_trans = transformer.transform(x)
print(x_trans)
import numpy as np
import sklearn.preprocessing
x = np.array([[-3,5,15],[0,6,14],[6,3,11]])
kbd = preprocessing.KBinsDiscretizer(n_bins=[3,2,2],encode='ordinal').fit(x)
x_kbd = kbd.transform(x)
print(x_kbd)
from sklearn.preprocessing import MultiLabelBinarizer
#多标签二值化
mlb = MultiLabelBinarizer()
x_mlb = mlb.fit_transform([(1,2),(3,4),(5,)])
print(x_mlb)sklearn.svm
函数 | 介绍 |
svm.OneClassSVM( ) | 无监督异常值检测 |
上述preprocessing类函数的方法如下:
http://preprocessing.xxx函数方法 | 介绍 |
xxx.fit( ) | 拟合数据 |
xxx.fit_transform( ) | 拟合并转换数据 |
xxx.get_params( ) | 获取函数参数 |
xxx.inverse_transform( ) | 逆转换 |
xxx.set_params( ) | 设置参数 |
xxx.transform( ) | 转换数据 |
特征选择
很多时候我们用于模型训练的数据集包含许多的特征,这些特征要么是有冗余,要么是对结果的相关性很小;这时通过精心挑选一些"好"的特征来训练模型,既能减小模型训练时间,也能够提升模型性能。
例如一个数据集包含(鼻翼长、眼角长、额头宽、血型)这四个特征;我们用这些数据集进行人脸识别,必定会去除(血型)这个特征后再进行人脸识别;因为(血型)这个特征对于人脸识别这个目标来说是一个无用的特征。
sklean.feature_selection
函数 | 功能 |
feature_selection.SelectKBest( ) feature_selection.chi2 feature_selection.f_regression feature_selection.mutual_info_regression | 选择K个得分最高的特征 |
feature_selection.VarianceThreshold( ) | 无监督特征选择 |
feature_selection.REF( ) | 递归式特征消除 |
feature_selection.REFCV( ) | 递归式特征消除交叉验证法 |
feature_selection.SelectFromModel( ) | 特征选择 |
特征选择实现代码
from sklearn.datasets import load_digits
from sklearn.feature_selection import SelectKBest,chi2
digits = load_digits()
data = digits.data
target = digits.target
print(data.shape)
data_new = SelectKBest(chi2,k=20).fit_transform(data,target)
print(data_new.shape)
from sklearn.feature_selection import VarianceThreshold
x = [[0,0,1],[0,1,0],[1,0,0],[0,1,1],[0,1,0],[0,1,1]]
vt = VarianceThreshold(threshold=(0.8*(1-0.8)))
x_new = vt.fit_transform(x)
print(x)
print(x_new)
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
x,y = iris.data,iris.target
lsvc = LinearSVC(C=0.01,penalty='l1',dual=False).fit(x,y)
model = SelectFromModel(lsvc,prefit=True)
x_new = model.transform(x)
print(x.shape)
print(x_new.shape)
from sklearn.svm import SVC
from sklearn.model_selection import StratifiedKFold,cross_val_score
from sklearn.feature_selection import RFECV
from sklearn.datasets import load_iris
iris = load_iris()
x,y = iris.data,iris.target
svc = SVC(kernel='linear')
rfecv = RFECV(estimator=svc,step=1,cv=StratifiedKFold(2),scoring='accuracy',verbose=1,n_jobs=1).fit(x,y)
x_rfe = rfecv.transform(x)
print(x_rfe.shape)
clf = SVC(gamma="auto", C=0.8)
scores = (cross_val_score(clf, x_rfe, y, cv=5))
print(scores)
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std()*2))
特征降维

面对特征巨大的数据集,除了进行特征选择之外,我们还可以采取特征降维算法来减少特征数;特征降维于特征选择的区别在于:特征选择是从原始特征中挑选特征;而特征降维则是从原始特征中生成新的特征。
很多人会有比较特征选择与特征降维优劣的心理,其实这种脱离实际问题的比较意义不大,我们要明白每一种算法都是有其擅长的领域。
sklearn.decomposition
函数 | 功能 |
decomposition.PCA( ) | 主成分分析 |
decomposition.KernelPCA( ) | 核主成分分析 |
decomposition.IncrementalPCA( ) | 增量主成分分析 |
decomposition.MiniBatchSparsePCA( ) | 小批量稀疏主成分分析 |
decomposition.SparsePCA( ) | 稀疏主成分分析 |
decomposition.FactorAnalysis( ) | 因子分析 |
decomposition.TruncatedSVD( ) | 截断的奇异值分解 |
decomposition.FastICA( ) | 独立成分分析的快速算法 |
decomposition.DictionaryLearning( ) | 字典学习 |
decomposition.MiniBatchDictonaryLearning( ) | 小批量字典学习 |
decomposition.dict_learning( ) | 字典学习用于矩阵分解 |
decomposition.dict_learning_online( ) | 在线字典学习用于矩阵分解 |
decomposition.LatentDirichletAllocation( ) | 在线变分贝叶斯算法的隐含迪利克雷分布 |
decomposition.NMF( ) | 非负矩阵分解 |
decomposition.SparseCoder( ) | 稀疏编码 |
特征降维代码实现
"""数据降维"""
from sklearn.decomposition import PCA
x = np.array([[-1,-1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])
pca1 = PCA(n_components=2)
pca2 = PCA(n_components='mle')
pca1.fit(x)
pca2.fit(x)
x_new1 = pca1.transform(x)
x_new2 = pca2.transform(x)
print(x_new1.shape)
print(x_new2.shape)
import numpy as np
from sklearn.decomposition import KernelPCA
import matplotlib.pyplot as plt
import math
#kernelPCA适用于对数据进行非线性降维
x = []
y = []
N = 500
for i in range(N):
deg = np.random.randint(0,360)
if np.random.randint(0,2)%2 == 0:
x.append([6*math.sin(deg),6*math.cos(deg)])
y.append(1)
else:
x.append([15*math.sin(deg),15*math.cos(deg)])
y.append(0)
y = np.array(y)
x = np.array(x)
kpca = KernelPCA(kernel='rbf',n_components=14)
x_kpca = kpca.fit_transform(x)
print(x_kpca.shape)
from sklearn.datasets import load_digits
from sklearn.decomposition import IncrementalPCA
from scipy import sparse
X, _ = load_digits(return_X_y=True)
#增量主成分分析:适用于大数据
transform = IncrementalPCA(n_components=7,batch_size=200)
transform.partial_fit(X[:100,:])
x_sparse = sparse.csr_matrix(X)
x_transformed = transform.fit_transform(x_sparse)
x_transformed.shape
import numpy as np
from sklearn.datasets import make_friedman1
from sklearn.decomposition import MiniBatchSparsePCA
x,_ = make_friedman1(n_samples=200,n_features=30,random_state=0)
transformer = MiniBatchSparsePCA(n_components=5,batch_size=50,random_state=0)
transformer.fit(x)
x_transformed = transformer.transform(x)
print(x_transformed.shape)
from sklearn.datasets import load_digits
from sklearn.decomposition import FactorAnalysis
x,_ = load_digits(return_X_y=True)
transformer = FactorAnalysis(n_components=7,random_state=0)
x_transformed = transformer.fit_transform(x)
print(x_transformed.shape)sklearn.manifold
函数 | 功能 |
manifold.LocallyLinearEmbedding( ) | 局部非线性嵌入 |
manifold.Isomap( ) | 流形学习 |
manifold.MDS( ) | 多维标度法 |
manifold.t-SNE( ) | t分布随机邻域嵌入 |
manifold.SpectralEmbedding( ) | 频谱嵌入非线性降维 |
分类模型

分类模型是能够从数据集中学习知识,进而提升自我认知的一种模型,经过学习后,它能够区分出它所见过的事物;这种模型就非常类似一个识物的小朋友。
sklearn.tree
函数 | 功能 |
tree.DecisionTreeClassifier( ) | 决策树 |
决策树分类
from sklearn.datasets import load_iris
from sklearn import tree
x,y = load_iris(return_X_y=True)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(x,y)
tree.plot_tree(clf)sklearn.ensemble
函数 | 功能 |
ensemble.BaggingClassifier() | 装袋法集成学习 |
ensemble.AdaBoostClassifier( ) | 提升法集成学习 |
ensemble.RandomForestClassifier( ) | 随机森林分类 |
ensemble.ExtraTreesClassifier( ) | 极限随机树分类 |
ensemble.RandomTreesEmbedding( ) | 嵌入式完全随机树 |
ensemble.GradientBoostingClassifier( ) | 梯度提升树 |
ensemble.VotingClassifier( ) | 投票分类法 |
BaggingClassifier
#使用sklearn库实现的决策树装袋法提升分类效果。其中X和Y分别是鸢尾花(iris)数据集中的自变量(花的特征)和因变量(花的类别)
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
#加载iris数据集
iris=datasets.load_iris()
X=iris.data
Y=iris.target
#生成K折交叉验证数据
kfold=KFold(n_splits=9)
#决策树及交叉验证
cart=DecisionTreeClassifier(criterion='gini',max_depth=2)
cart=cart.fit(X,Y)
result=cross_val_score(cart,X,Y,cv=kfold) #采用K折交叉验证的方法来验证算法效果
print('CART数结果:',result.mean())
#装袋法及交叉验证
model=BaggingClassifier(base_estimator=cart,n_estimators=100) #n_estimators=100为建立100个分类模型
result=cross_val_score(model,X,Y,cv=kfold) #采用K折交叉验证的方法来验证算法效果
print('装袋法提升后的结果:',result.mean())AdaBoostClassifier
#基于sklearn库中的提升法分类器对决策树进行优化,提高分类准确率,其中load_breast_cancer()方法加载乳腺癌数据集,自变量(细胞核的特征)和因变量(良性、恶性)分别赋给X,Y变量
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
#加载数据
dataset_all=datasets.load_breast_cancer()
X=dataset_all.data
Y=dataset_all.target
#初始化基本随机数生成器
kfold=KFold(n_splits=10)
#决策树及交叉验证
dtree=DecisionTreeClassifier(criterion='gini',max_depth=3)
#提升法及交叉验证
model=AdaBoostClassifier(base_estimator=dtree,n_estimators=100)
result=cross_val_score(model,X,Y,cv=kfold)
print("提升法改进结果:",result.mean())RandomForestClassifier 、ExtraTreesClassifier
#使用sklearn库中的随机森林算法和决策树算法进行效果比较,数据集由生成器随机生成
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
#make_blobs:sklearn中自带的取类数据生成器随机生成测试样本,make_blobs方法中n_samples表示生成的随机数样本数量,n_features表示每个样本的特征数量,centers表示类别数量,random_state表示随机种子
x,y=make_blobs(n_samples=1000,n_features=6,centers=50,random_state=0)
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
#构造随机森林模型
clf=RandomForestClassifier(n_estimators=10,max_depth=None,min_samples_split=2,random_state=0) #n_estimators表示弱学习器的最大迭代次数,或者说最大的弱学习器的个数。如果设置值太小,模型容易欠拟合;如果太大,计算量会较大,并且超过一定的数量后,模型提升很小
scores=cross_val_score(clf,x,y)
print('RandomForestClassifier result:',scores.mean())
#构造极限森林模型
clf=ExtraTreesClassifier(n_estimators=10,max_depth=None,min_samples_split=2,random_state=0)
scores=cross_val_score(clf,x,y)
print('ExtraTreesClassifier result:',scores.mean())
#极限随机数的效果好于随机森林,原因在于计算分割点方法中的随机性进一步增强;相较于随机森林,其阈值是针对每个候选特征随机生成的,并且选择最佳阈值作为分割规则,这样能够减少一点模型的方程,总体上效果更好GradientBoostingClassifier
importpandasaspdfromsklearn.model_selectionimporttrain_test_splitfromsklearn.ensembleimportGradientBoostingClassifierfromsklearn.datasetsimportmake_blobs#make_blobs:sklearn中自带的取类数据生成器随机生成测试样本,make_blobs方法中n_samples表示生成的随机数样本数量,n_features表示每个样本的特征数量,centers表示类别数量,random_state表示随机种子x,y=make_blobs(n_samples=1000,n_features=6,centers=50,random_state=0)plt.scatter(x[:,0],x[:,1],c=y)plt.show()x_train,x_test,y_train,y_test=train_test_split(x,y)# 模型训练,使用GBDT算法gbr=GradientBoostingClassifier(n_estimators=3000,max_depth=2,min_samples_split=2,learning_rate=0.1)gbr.fit(x_train,y_train.ravel())y_gbr=gbr.predict(x_train)y_gbr1=gbr.predict(x_test)acc_train=gbr.score(x_train,y_train)acc_test=gbr.score(x_test,y_test)print(acc_train)print(acc_test)VotingClassifier
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.ensemble import VotingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
#VotingClassifier方法是一次使用多种分类模型进行预测,将多数预测结果作为最终结果
x,y = datasets.make_moons(n_samples=500,noise=0.3,random_state=42)
plt.scatter(x[y==0,0],x[y==0,1])
plt.scatter(x[y==1,0],x[y==1,1])
plt.show()
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
voting_hard = VotingClassifier(estimators=[
('log_clf', LogisticRegression()),
('svm_clf', SVC()),
('dt_clf', DecisionTreeClassifier(random_state=10)),], voting='hard')
voting_soft = VotingClassifier(estimators=[
('log_clf', LogisticRegression()),
('svm_clf', SVC(probability=True)),
('dt_clf', DecisionTreeClassifier(random_state=10)),
], voting='soft')
voting_hard.fit(x_train,y_train)
print(voting_hard.score(x_test,y_test))
voting_soft.fit(x_train,y_train)
print(voting_soft.score(x_test,y_test))sklearn.linear_model
函数 | 功能 |
linear_model.LogisticRegression( ) | 逻辑回归 |
linear_model.Perceptron( ) | 线性模型感知机 |
linear_model.SGDClassifier( ) | 具有SGD训练的线性分类器 |
linear_model.PassiveAggressiveClassifier( ) | 增量学习分类器 |
LogisticRegression
import numpy as np
from sklearn import linear_model,datasets
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
x = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
logreg = linear_model.LogisticRegression(C=1e5)
logreg.fit(x_train,y_train)
prepro = logreg.score(x_test,y_test)
print(prepro)Perceptron
from sklearn.datasets import load_digits
from sklearn.linear_model import Perceptron
x,y = load_digits(return_X_y=True)
clf = Perceptron(tol=1e-3,random_state=0)
clf.fit(x,y)
clf.score(x,y)SGDClassifier
import numpy as np
from sklearn.linear_model import SGDClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
x = np.array([[-1,-1],[-2,-1],[1,1],[2,1]])
y = np.array([1,1,2,2])
clf = make_pipeline(StandardScaler(),SGDClassifier(max_iter=1000,tol=1e-3))
clf.fit(x,y)
print(clf.score(x,y))
print(clf.predict([[-0.8,-1]]))PassiveAggressiveClassifier
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
x,y = make_classification(n_features=4,random_state=0)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
clf = PassiveAggressiveClassifier(max_iter=1000,random_state=0,tol=1e-3)
clf.fit(x_train,y_train)
print(clf.score(x_test,y_test))sklearn.svm
函数 | 功能 |
svm.SVC( ) | 支持向量机分类 |
svm.NuSVC( ) | Nu支持向量分类 |
svm.LinearSVC( ) | 线性支持向量分类 |
SVC
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
x = [[2,0],[1,1],[2,3]]
y = [0,0,1]
clf = SVC(kernel='linear')
clf.fit(x,y)
print(clf.predict([[2,2]]))
NuSVC
from sklearn import svm
from numpy import *
x = array([[0],[1],[2],[3]])
y = array([0,1,2,3])
clf = svm.NuSVC()
clf.fit(x,y)
print(clf.predict([[4]]))LinearSVC
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris.data
y = iris.target
plt.scatter(X[y==0, 0], X[y==0, 1], color='red')
plt.scatter(X[y==1, 0], X[y==1, 1], color='blue')
plt.show()
svc = LinearSVC(C=10**9)
svc.fit(X, y)
print(svc.score(X,y))sklearn.neighbors
函数 | 功能 |
neighbors.NearestNeighbors( ) | 无监督学习临近搜索 |
neighbors.NearestCentroid( ) | 最近质心分类器 |
neighbors.KNeighborsClassifier() | K近邻分类器 |
neighbors.KDTree( ) | KD树搜索最近邻 |
neighbors.KNeighborsTransformer( ) | 数据转换为K个最近邻点的加权图 |
NearestNeighbors
import numpy as np
from sklearn.neighbors import NearestNeighbors
samples = [[0,0,2],[1,0,0],[0,0,1]]
neigh = NearestNeighbors(n_neighbors=2,radius=0.4)
neigh.fit(samples)
print(neigh.kneighbors([[0,0,1.3]],2,return_distance=True))
print(neigh.radius_neighbors([[0,0,1.3]],0.4,return_distance=False))NearestCentroid
from sklearn.neighbors import NearestCentroid
import numpy as np
x = np.array([[-1,-1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])
y = np.array([1,1,1,2,2,2])
clf = NearestCentroid()
clf.fit(x,y)
print(clf.predict([[-0.8,-1]]))KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
x,y = [[0],[1],[2],[3]],[0,0,1,1]
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(x,y)
print(neigh.predict([[1.1]]))KDTree
import numpy as np
from sklearn.neighbors import KDTree
rng = np.random.RandomState(0)
x = rng.random_sample((10,3))
tree = KDTree(x,leaf_size=2)
dist,ind = tree.query(x[:1],k=3)
print(ind)KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
X = [[0], [1], [2], [3], [4], [5], [6], [7], [8]]
y = [0, 0, 0, 1, 1, 1, 2, 2, 2]
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(X, y)
print(neigh.predict([[1.1]]))sklearn.discriminant_analysis
函数 | 功能 |
discriminant_analysis.LinearDiscriminantAnalysis( ) | 线性判别分析 |
discriminant_analysis.QuadraticDiscriminantAnalysis( ) | 二次判别分析 |
LDA
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
iris = datasets.load_iris()
X = iris.data[:-5]
pre_x = iris.data[-5:]
y = iris.target[:-5]
print ('first 10 raw samples:', X[:10])
clf = LDA()
clf.fit(X, y)
X_r = clf.transform(X)
pre_y = clf.predict(pre_x)
#降维结果
print ('first 10 transformed samples:', X_r[:10])
#预测目标分类结果
print ('predict value:', pre_y)
QDA
from sklearn import datasets
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as QDA
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
x = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
clf = QDA()
clf.fit(x_train,y_train)
print(clf.score(x_test,y_test))
sklearn.gaussian_process
函数 | 功能 |
gaussian_process.GaussianProcessClassifier( ) | 高斯过程分类 |
sklearn.naive_bayes
函数 | 功能 |
naive_bayes.GaussianNB( ) | 朴素贝叶斯 |
naive_bayes.MultinomialNB( ) | 多项式朴素贝叶斯 |
naive_bayes.BernoulliNB( ) | 伯努利朴素贝叶斯 |
GaussianNB
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
iris = datasets.load_iris()
clf = GaussianNB()
clf = clf.fit(iris.data,iris.target)
y_pre = clf.predict(iris.data)MultinomialNB
from sklearn import datasets
from sklearn.naive_bayes import MultinomialNB
iris = datasets.load_iris()
clf = MultinomialNB()
clf = clf.fit(iris.data, iris.target)
y_pred=clf.predict(iris.data)
BernoulliNB
from sklearn import datasets
from sklearn.naive_bayes import BernoulliNB
iris = datasets.load_iris()
clf = BernoulliNB()
clf = clf.fit(iris.data, iris.target)
y_pred=clf.predict(iris.data)回归模型

sklearn.tree
函数 | 功能 |
tree.DecisionTreeRegress( ) | 回归决策树 |
tree.ExtraTreeRegressor( ) | 极限回归树 |
DecisionTreeRegressor、ExtraTreeRegressor
"""回归"""
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor,ExtraTreeRegressor
from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error
import numpy as np
boston = load_boston()
x = boston.data
y = boston.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
dtr = DecisionTreeRegressor()
dtr.fit(x_train,y_train)
etr = ExtraTreeRegressor()
etr.fit(x_train,y_train)
yetr_pred = etr.predict(x_test)
ydtr_pred = dtr.predict(x_test)
print(dtr.score(x_test,y_test))
print(r2_score(y_test,ydtr_pred))
print(etr.score(x_test,y_test))
print(r2_score(y_test,yetr_pred))
sklearn.ensemble
函数 | 功能 |
ensemble.GradientBoostingRegressor( ) | 梯度提升法回归 |
ensemble.AdaBoostRegressor( ) | 提升法回归 |
ensemble.BaggingRegressor( ) | 装袋法回归 |
ensemble.ExtraTreeRegressor( ) | 极限树回归 |
ensemble.RandomForestRegressor( ) | 随机森林回归 |
GradientBoostingRegressor
import numpy as np
from sklearn.ensemble import GradientBoostingRegressor as GBR
from sklearn.datasets import make_regression
X, y = make_regression(1000, 2, noise=10)
gbr = GBR()
gbr.fit(X, y)
gbr_preds = gbr.predict(X)
AdaBoostRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.datasets import make_regression
x,y = make_regression(n_features=4,n_informative=2,random_state=0,shuffle=False)
regr = AdaBoostRegressor(random_state=0,n_estimators=100)
regr.fit(x,y)
regr.predict([[0,0,0,0]])BaggingRegressor
from sklearn.ensemble import BaggingRegressor
from sklearn.datasets import make_regression
from sklearn.svm import SVR
x,y = make_regression(n_samples=100,n_features=4,n_informative=2,n_targets=1,random_state=0,shuffle=False)
br = BaggingRegressor(base_estimator=SVR(),n_estimators=10,random_state=0).fit(x,y)
br.predict([[0,0,0,0]])ExtraTreesRegressor
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.ensemble import ExtraTreesRegressor
x,y = load_diabetes(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(X,y,random_state=0)
etr = ExtraTreesRegressor(n_estimators=100,random_state=0).fit(x_train,y_train)
print(etr.score(x_test,y_test))RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
x,y = make_regression(n_features=4,n_informative=2,random_state=0,shuffle=False)
rfr = RandomForestRegressor(max_depth=2,random_state=0)
rfr.fit(x,y)
print(rfr.predict([[0,0,0,0]]))sklearn.linear_model
函数 | 功能 |
linear_model.LinearRegression( ) | 线性回归 |
linear_model.Ridge( ) | 岭回归 |
linear_model.Lasso( ) | 经L1训练后的正则化器 |
linear_model.ElasticNet( ) | 弹性网络 |
linear_model.MultiTaskLasso( ) | 多任务Lasso |
linear_model.MultiTaskElasticNet( ) | 多任务弹性网络 |
linear_model.Lars( ) | 最小角回归 |
linear_model.OrthogonalMatchingPursuit( ) | 正交匹配追踪模型 |
linear_model.BayesianRidge( ) | 贝叶斯岭回归 |
linear_model.ARDRegression( ) | 贝叶斯ADA回归 |
linear_model.SGDRegressor( ) | 随机梯度下降回归 |
linear_model.PassiveAggressiveRegressor( ) | 增量学习回归 |
linear_model.HuberRegression( ) | Huber回归 |
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
np.random.seed(0)
x = np.random.randn(10,5)
y = np.random.randn(10)
clf1 = Ridge(alpha=1.0)
clf2 = Lasso()
clf2.fit(x,y)
clf1.fit(x,y)
print(clf1.predict(x))
print(clf2.predict(x))sklearn.svm
函数 | 功能 |
svm.SVR( ) | 支持向量机回归 |
svm.NuSVR( ) | Nu支持向量回归 |
svm.LinearSVR( ) | 线性支持向量回归 |
sklearn.neighbors
函数 | 功能 |
neighbors.KNeighborsRegressor( ) | K近邻回归 |
neighbors.RadiusNeighborsRegressor( ) | 基于半径的近邻回归 |
sklearn.kernel_ridge
函数 | 功能 |
kernel_ridge.KernelRidge( ) | 内核岭回归 |
sklearn.gaussian_process
函数 | 功能 |
gaussian_process.GaussianProcessRegressor( ) | 高斯过程回归 |
GaussianProcessRegressor
from sklearn.datasets import make_friedman2
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import DotProduct,WhiteKernel
x,y = make_friedman2(n_samples=500,noise=0,random_state=0)
kernel = DotProduct()+WhiteKernel()
gpr = GaussianProcessRegressor(kernel=kernel,random_state=0).fit(x,y)
print(gpr.score(x,y))sklearn.cross_decomposition
函数 | 功能 |
cross_decomposition.PLSRegression( ) | 偏最小二乘回归 |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cross_decomposition import PLSRegression
from sklearn.model_selection import train_test_split
boston = datasets.load_boston()
x = boston.data
y = boston.target
x_df = pd.DataFrame(x,columns=boston.feature_names)
y_df = pd.DataFrame(y)
pls = PLSRegression(n_components=2)
x_train,x_test,y_train,y_test = train_test_split(x_df,y_df,test_size=0.3,random_state=1)
pls.fit(x_train,y_train)
print(pls.predict(x_test))聚类模型

sklearn.cluster
函数 | 功能 |
cluster.DBSCAN( ) | 基于密度的聚类 |
cluster.GaussianMixtureModel( ) | 高斯混合模型 |
cluster.AffinityPropagation( ) | 吸引力传播聚类 |
cluster.AgglomerativeClustering( ) | 层次聚类 |
cluster.Birch( ) | 利用层次方法的平衡迭代聚类 |
cluster.KMeans( ) | K均值聚类 |
cluster.MiniBatchKMeans( ) | 小批量K均值聚类 |
cluster.MeanShift( ) | 平均移位聚类 |
cluster.OPTICS( ) | 基于点排序来识别聚类结构 |
cluster.SpectralClustering( ) | 谱聚类 |
cluster.Biclustering( ) | 双聚类 |
cluster.ward_tree( ) | 集群病房树 |
模型方法
方法 | 功能 |
xxx.fit( ) | 模型训练 |
xxx.get_params( ) | 获取模型参数 |
xxx.predict( ) | 预测新输入数据 |
xxx.score( ) | 评估模型分类/回归/聚类模型 |
xxx.set_params( ) | 设置模型参数 |
模型评估

分类模型评估
函数 | 功能 |
metrics.accuracy_score( ) | 准确率 |
metrics.average_precision_score( ) | 平均准确率 |
metrics.log_loss( ) | 对数损失 |
metrics.confusion_matrix( ) | 混淆矩阵 |
metrics.classification_report( ) | 分类模型评估报告:准确率、召回率、F1-score |
metrics.roc_curve( ) | 受试者工作特性曲线 |
metrics.auc( ) | ROC曲线下面积 |
metrics.roc_auc_score( ) | AUC值 |
回归模型评估
函数 | 功能 |
metrics.mean_squared_error( ) | 平均决定误差 |
metrics.median_absolute_error( ) | 中值绝对误差 |
metrics.r2_score( ) | 决定系数 |
聚类模型评估
函数 | 功能 |
metrics.adjusted_rand_score( ) | 随机兰德调整指数 |
metrics.silhouette_score( ) | 轮廓系数 |
模型优化
函数 | 功能 |
model_selection.cross_val_score( ) | 交叉验证 |
model_selection.LeaveOneOut( ) | 留一法 |
model_selection.LeavePout( ) | 留P法交叉验证 |
model_selection.GridSearchCV( ) | 网格搜索 |
model_selection.RandomizedSearchCV( ) | 随机搜索 |
model_selection.validation_curve( ) | 验证曲线 |
model_selection.learning_curve( ) | 学习曲线 |
写在最后
单纯的通过文章来学习机器学习、学习编程是很容易遇到非常多的Bug,这对一个新手来说,无疑会浪费很多时间,也会打击大家学习掌握机器学习的信心。
利用sklearn库来学习机器学习,是能够非常快速的入门的。