0.简单的处理逻辑

一.MySQL完整性约束
主键约束
primary key
自增键约束
auto_increment
唯一键约束
unique
非空约束
not null
默认值约束
default
外键约束
foreign key
下面是一个sql语句创建一个表,可以看出来了使用了哪几个约束吗?
create table user(
id int primary key auto_increment comment '主键',
nickname varchar(20) not null comment '昵称',
age int unsigned not null default 18 comment '年龄',
sex enum('男','女') default '男' comment '性别'
);
二.关系型数据库表设计
- 一对一
比如用户表和用户信息表,一个用户只能对应一个用户信息 - 一对多
电商系统中,用户,商品和订单表,其中用户和订单是一对多的关系,一个用户可以有多个订单,但一个订单只能属于一个用户 - 多对多
还是电商系统,一个商品可以存在多个订单中,同时一个订单中可以有多个商品,因此他们之间存在多对多的关系
对于一对多的关系,设计数据库的时候,只需要在子表中增加一列(父表的主键)用来关联主表
那么对于一对多的关系该如何处理呢?
首先我们还是先来考虑增加主键来关联主表,这样我们就会发现会有很多冗余的数据存储.

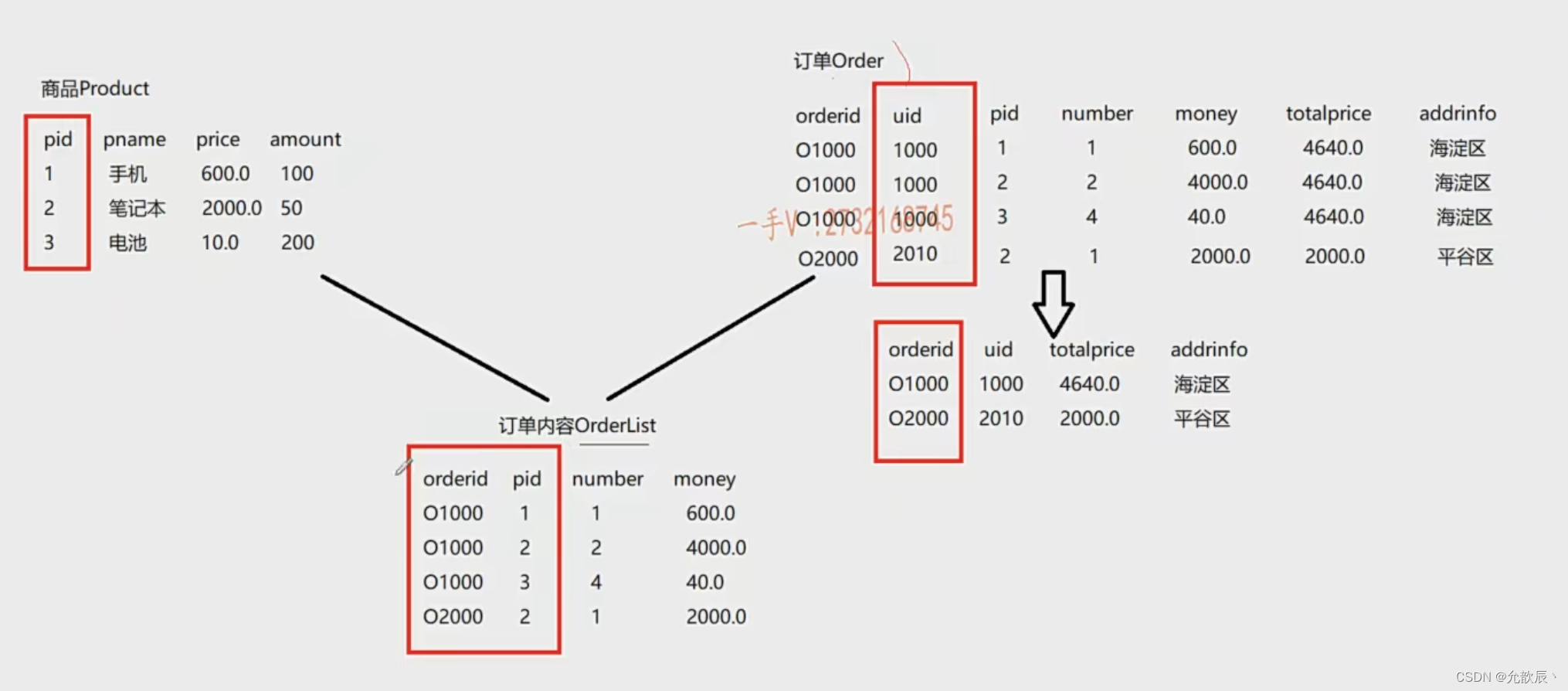
因此对于多对多的关系,需要在父表和子表之间增加一个中间表用来存储关系
可以将表改为下面的模式(商品表主键(pid),订单表主键(orderid),订单内容表主键(orderid,pid))
三.关系型数据库范式
应用数据库范式可以带来许多好处,但是最重要的好处归结为三点:
- 减少数据冗余(这是最主要的好处,其他好处都是由此而附带的)
- 消除异常(插入异常,更新异常,删除异常)
- 让数据组织的更加和谐
但是数据库范式绝对不是越高越好,范式越高,意味着表越多,多表联合查询的机率就越大,
SQL的效率就变低。
1.第一范式
每一列保持原子特性
列都是基本数据项,不能够再进行分割,否则设计成一对多的实体关系。例如表中的地址字段,可以再细分为省,市,区等不可再分割(即原子特性)的字段,如下:

上图的表就是把地址字段分成更详细的
city
,
country
,
street
三个字段,注意,不符合第一范式不能称作关系型数据库。
2.第二范式
属性完全依赖于主键 - 主要针对联合主键
非主属性完全依赖于主关键字,如果不是完全依赖主键,应该拆分成新的实体,设计成一对多的实体关系。
例如:选课关系表为
SelectCourse(
学号
,
姓名
,
年龄
,
课程名称
,
成绩
,
学分
)
,(学号,课程名称)是联合主键,但是学分字段只和课程名称有关,和学号无关,相当于只依赖联合主键的其中一个字段,不符合第二范式。
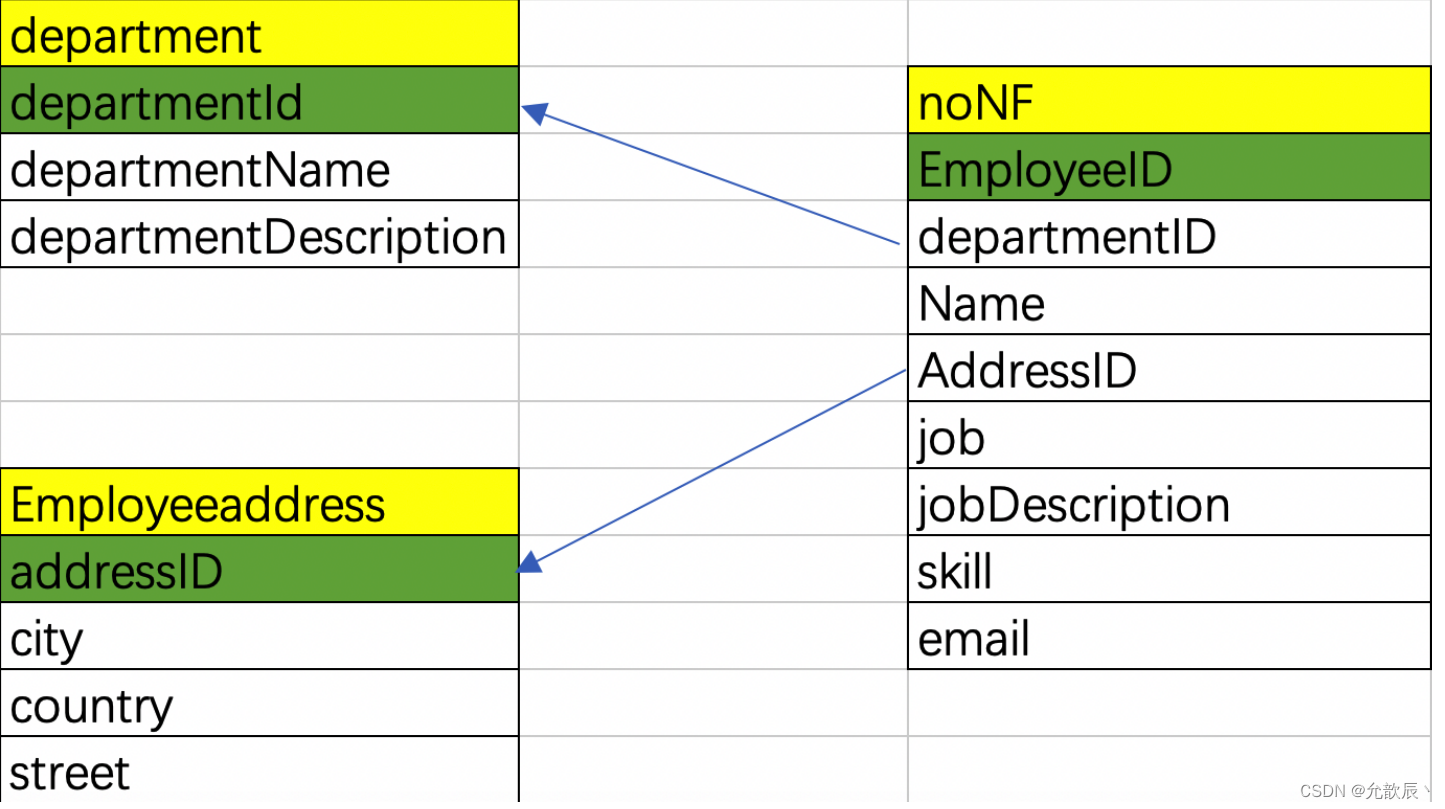
3.第三范式
属性不依赖于其它非主属性
要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
示例:学生关系表为
Student
(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),学号是主键,但是学院电话只依赖于所在学院,并不依赖于主键学号,因此该设计不符合第三范式,应该把学院专门设计成一张表,学生表和学院表,两个是一对多的关系。
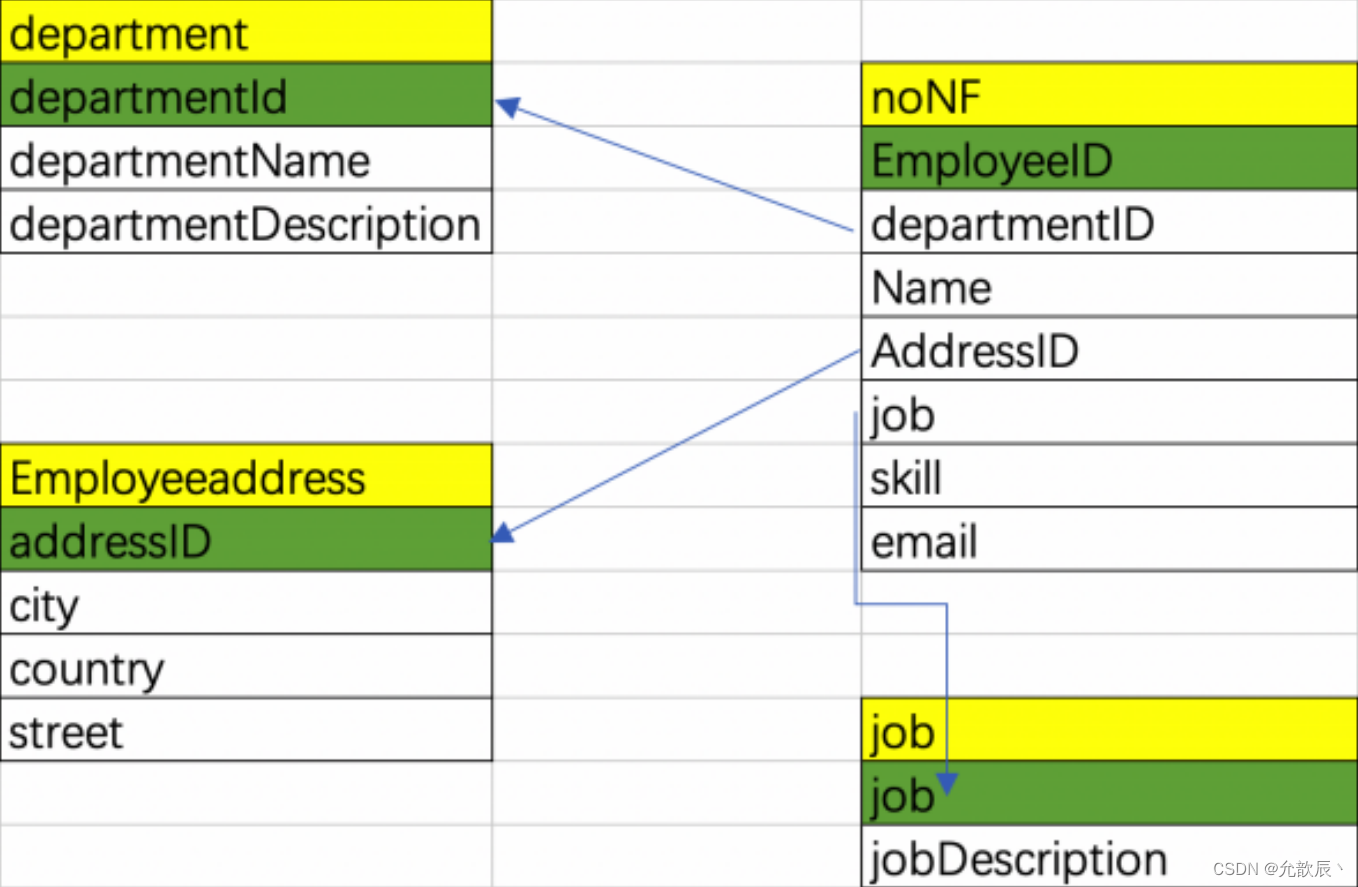
4.BC范式(BCNF)
每个表中只有一个候选键
简单的说,
BC
范式是在第三范式的基础上的一种特殊情况,即每个表中只有一个
候选键(在一个数据库
中每行的值都不相同,则可称为候选键)
,在上面第三范式的
noNF
表(上面图
3
)中可以看出,每一个员工的email
都是唯一的(不可能两个人用同一个
email
),则此表不符合
BC
范式,对其进行
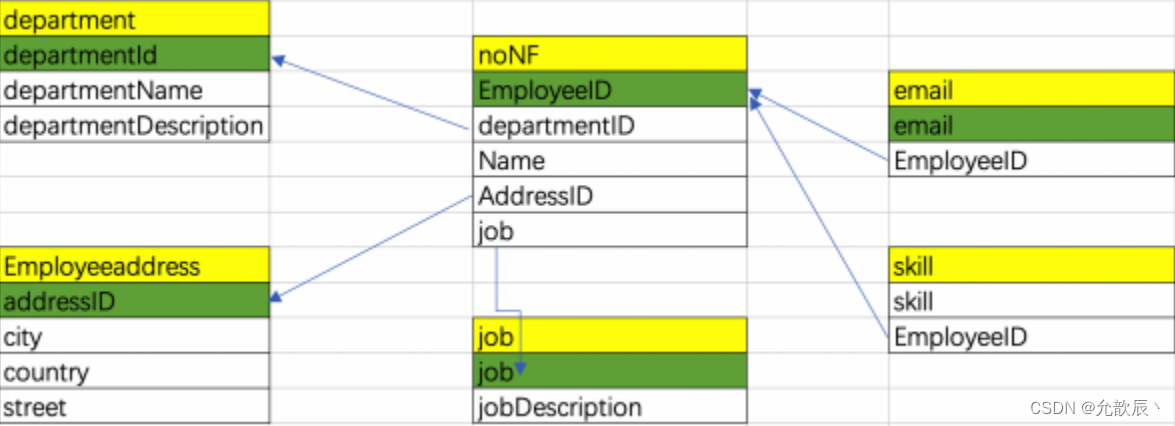
BC
范式化后的关系图为:

5.第四范式
消除表中的多值依赖
简单来说,第四范式就是要消除表中的多值依赖,也就是说可以减少维护数据一致性的工作。比如图
4 中的noNF
表中的
skill
技能这个字段,有的人是
“java
,
mysql”
,有的人描述的是
“Java
,
MySQL”
,这样数据就不一致了,解决办法就是将多值属性放入一个新表,所以满足第四范式的关系图如下:
总结:
从上面对于数据库范式进行分解的过程中不难看出,应用的范式越高,表越多。表多会带来很多问题:
- 查询时需要连接多个表,增加了SQL查询的复杂度
- 查询时需要连接多个表,降低了数据库查询性能
因此,并不是应用的范式越高越好,视实际情况而定。
第三范式已经很大程度上减少了数据冗余,并且
基本预防了数据插入异常,更新异常,和删除异常了
。