文章目录
- 简介
- 方式一:DJL + 飞浆引擎 + 飞桨模型
- 方式二:ONNXRuntime + 飞桨转换后的ONNX模型(Paddle2ONNX)
- 添加依赖
- 文字识别
- OCR过程分析
- 文字区域检测
- 文字角度检测
- 文字识别(裁减旋转后的文字区域)
- 高级
- 替换模型(离线)
简介
Github:https://github.com/PaddlePaddle/PaddleOCR
DJL:https://docs.djl.ai/docs/paddlepaddle/how_to_create_paddlepaddle_model_zh.html
在Java中,我发现两种主要的方式可以使用PaddleOCR。在此,我们不考虑通过Java进行本地部署服务的方式,而专注于两种更具可行性的方法。
方式一:DJL + 飞浆引擎 + 飞桨模型
通过采用DJL(Deep Java Library)结合飞浆引擎和飞桨模型的方式,我们能够实现高效的OCR推理。DJL作为一个深度学习框架无关的Java库,为我们提供了灵活性和简便性,同时能够与飞浆引擎协同工作,使得OCR模型的部署和推理变得更加便捷。
方式二:ONNXRuntime + 飞桨转换后的ONNX模型(Paddle2ONNX)
另一种方式是使用ONNXRuntime,结合经过Paddle2ONNX工具转换的飞桨模型。这种方法使得我们能够在Java环境中轻松地使用ONNXRuntime进行推理。通过将飞桨模型转换为ONNX格式,我们能够获得更大的灵活性,使得模型在不同平台上的部署更加简单。
参考:https://github.com/mymagicpower/AIAS/tree/main/1_image_sdks/ocr_v4_sdk
PaddleOCR 具有如下功能:
-
OCR
- 通用OCR
- 流程为:区域检测+方向分类+识别
- 检测模型+方向分类模型+识别模型
- 都是小模型。
- 文档场景专用OCR
- 场景应用
- 数码管识别
- 通用表单识别
- 票据识别
- 电表读数识别
- 车牌识别 轻量级车牌识别 推理模型下载链接
- 手写体识别
- 公私识别
- 化验单识别
- 更多制造、金融、交通行业的主要OCR垂类应用模型(如电表、液晶屏、高精度SVTR模型等),可参考场景应用模型下载
- 通用OCR
-
文档分析
- 版面复原:PDF转Word
- 版面分析
- 表格识别
- 关键信息抽取
-
通用信息提取
- 基于LLMS的信息抽取
- 通用信息提取
每种模型提供瘦身版和server版。
添加依赖
<dependency>
<groupId>ai.djl.paddlepaddle</groupId>
<artifactId>paddlepaddle-model-zoo</artifactId>
<version>0.25.0</version>
</dependency>
<!-- paddlepaddle 无NDArray ,需要借用pytorch-->
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-engine</artifactId>
<version>0.25.0</version>
</dependency>
文字识别
原图:
结果:
先介绍了一个整理过的OCR识别工具类,该工具类已经实现了强大的OCR功能。通过这个工具类,用户能够轻松地进行文字识别操作。
import ai.djl.inference.Predictor;
import ai.djl.modality.Classifications;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.ImageFactory;
import ai.djl.modality.cv.output.BoundingBox;
import ai.djl.modality.cv.output.DetectedObjects;
import ai.djl.modality.cv.output.Rectangle;
import ai.djl.modality.cv.util.NDImageUtils;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.paddlepaddle.zoo.cv.imageclassification.PpWordRotateTranslator;
import ai.djl.paddlepaddle.zoo.cv.objectdetection.PpWordDetectionTranslator;
import ai.djl.paddlepaddle.zoo.cv.wordrecognition.PpWordRecognitionTranslator;
import ai.djl.repository.zoo.Criteria;
import ai.djl.repository.zoo.ZooModel;
import lombok.SneakyThrows;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
public class PPOCR {
static ZooModel<Image, DetectedObjects> detectionModel = null;
static ZooModel<Image, Classifications> rotateModel = null;
static ZooModel<Image, String> recognitionModel;
static {
try {
Criteria<Image, DetectedObjects> detectionCriteria = Criteria.builder()
// 指定使用飞桨引擎执行推理
.optEngine("PaddlePaddle")
.setTypes(Image.class, DetectedObjects.class)
// 可以替换模型版本
.optModelUrls("https://resources.djl.ai/test-models/paddleOCR/mobile/det_db.zip")
.optTranslator(new PpWordDetectionTranslator(new ConcurrentHashMap<String, String>()))
.build();
detectionModel = detectionCriteria.loadModel();
Criteria<Image, Classifications> rotateCriteria = Criteria.builder()
.optEngine("PaddlePaddle")
.setTypes(Image.class, Classifications.class)
// 可以替换模型版本
.optModelUrls("https://resources.djl.ai/test-models/paddleOCR/mobile/cls.zip")
.optTranslator(new PpWordRotateTranslator())
.build();
rotateModel = rotateCriteria.loadModel();
Criteria<Image, String> recognitionCriteria = Criteria.builder()
.optEngine("PaddlePaddle")
.setTypes(Image.class, String.class)
// 可以替换模型版本
.optModelUrls("https://resources.djl.ai/test-models/paddleOCR/mobile/rec_crnn.zip")
.optTranslator(new PpWordRecognitionTranslator())
.build();
recognitionModel = recognitionCriteria.loadModel();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
// 识别本地图片
doOCRFromFile("C:\\laker\\demo3\\1.png");
// 识别网络图片
doOCRFromUrl("https://img-blog.csdnimg.cn/direct/96de53d999c64c2589d0ab6a630e59d6.png");
}
@SneakyThrows
public static String doOCRFromUrl(String url) {
Image img = ImageFactory.getInstance().fromUrl(url);
return doOCR(img);
}
@SneakyThrows
public static String doOCRFromFile(String path) {
Image img = ImageFactory.getInstance().fromFile(Path.of(path));
return doOCR(img);
}
@SneakyThrows
public static String doOCR(Image img) {
List<DetectedObjects.DetectedObject> boxes = detection(img);
List<String> names = new ArrayList<>();
List<Double> prob = new ArrayList<>();
List<BoundingBox> rect = new ArrayList<>();
for (int i = 0; i < boxes.size(); i++) {
System.out.println(boxes.get(i).getBoundingBox());
Image subImg = getSubImage(img, boxes.get(i).getBoundingBox());
if (subImg.getHeight() * 1.0 / subImg.getWidth() > 1.5) {
subImg = rotateImg(subImg);
}
Classifications.Classification result = getRotateResult(subImg);
if ("Rotate".equals(result.getClassName()) && result.getProbability() > 0.8) {
subImg = rotateImg(subImg);
}
String name = recognizer(subImg);
names.add(name);
prob.add(-1.0);
rect.add(boxes.get(i).getBoundingBox());
}
Image newImage = img.duplicate();
newImage.drawBoundingBoxes(new DetectedObjects(names, prob, rect));
newImage.getWrappedImage();
newImage.save(Files.newOutputStream(Paths.get("C:\\laker\\demo3\\1-1-1.png")), "png");
return "";
}
@SneakyThrows
private static List<DetectedObjects.DetectedObject> detection(Image img) {
Predictor<Image, DetectedObjects> detector = detectionModel.newPredictor();
DetectedObjects detectedObj = detector.predict(img);
System.out.println(detectedObj);
return detectedObj.items();
}
@SneakyThrows
private static Classifications.Classification getRotateResult(Image img) {
Predictor<Image, Classifications> rotateClassifier = rotateModel.newPredictor();
Classifications predict = rotateClassifier.predict(img);
System.out.println(predict);
return predict.best();
}
@SneakyThrows
private static String recognizer(Image img) {
Predictor<Image, String> recognizer = recognitionModel.newPredictor();
String text = recognizer.predict(img);
System.out.println(text);
return text;
}
static Image getSubImage(Image img, BoundingBox box) {
Rectangle rect = box.getBounds();
double[] extended = extendRect(rect.getX(), rect.getY(), rect.getWidth(), rect.getHeight());
int width = img.getWidth();
int height = img.getHeight();
int[] recovered = {
(int) (extended[0] * width),
(int) (extended[1] * height),
(int) (extended[2] * width),
(int) (extended[3] * height)
};
return img.getSubImage(recovered[0], recovered[1], recovered[2], recovered[3]);
}
static double[] extendRect(double xmin, double ymin, double width, double height) {
double centerx = xmin + width / 2;
double centery = ymin + height / 2;
if (width > height) {
width += height * 2.0;
height *= 3.0;
} else {
height += width * 2.0;
width *= 3.0;
}
double newX = centerx - width / 2 < 0 ? 0 : centerx - width / 2;
double newY = centery - height / 2 < 0 ? 0 : centery - height / 2;
double newWidth = newX + width > 1 ? 1 - newX : width;
double newHeight = newY + height > 1 ? 1 - newY : height;
return new double[]{newX, newY, newWidth, newHeight};
}
private static Image rotateImg(Image image) {
try (NDManager manager = NDManager.newBaseManager()) {
NDArray rotated = NDImageUtils.rotate90(image.toNDArray(manager), 1);
return ImageFactory.getInstance().fromNDArray(rotated);
}
}
}
第一次执行时会从网络上下载对应的模型包并解压,后面可以复用。
区域检测模型
C:\Users\xxx.djl.ai\cache\repo\model\undefined\ai\djl\localmodelzoo\0fe77cae3367aab58bd7bec22e93d818c35706c6\det_db
/det_db/
├── inference.pdiparams # inference模型的参数文件
├── inference.pdiparams.info # inference模型的参数信息,可忽略
└── inference.pdmodel # inference模型的program文件
文字识别模型
C:\Users\xxx.djl.ai\cache\repo\model\undefined\ai\djl\localmodelzoo\f78cb59b6d66764eb68a5c1fb92b4ba132dbbcfe\rec_crnn
/rec_crnn/
├── inference.pdiparams # inference模型的参数文件
├── inference.pdiparams.info # inference模型的参数信息,可忽略
└── inference.pdmodel # inference模型的program文件
└── ppocr_keys_v1.txt # OCR识别字典
角度识别模型
C:\Users\xxx.djl.ai\cache\repo\model\undefined\ai\djl\localmodelzoo\33f7a81bc13304d4b5da850898d51c94697b71a9\cls
/cls/
├── inference.pdiparams # inference模型的参数文件
├── inference.pdiparams.info # inference模型的参数信息,可忽略
└── inference.pdmodel # inference模型的program文件
OCR过程分析
文字区域检测
文字区域检测是OCR过程中的关键步骤,旨在定位并标识待识别图片中的文字区域。以下是详细的步骤分析:
- 加载待识别图片:
- 用户提供待识别的图片,该图片可能包含一个或多个文本区域。
- 加载检测模型:
- OCR系统使用预训练的文字区域检测模型,确保该模型能够准确地定位图像中的文字。
- 推理与文本区域检测:
- 通过对待识别图片进行推理,文字区域检测模型会生成一个包含所有文字区域的二进制位图(Bitmap)。
- 使用
PpWordDetectionTranslator函数将原始输出转换为包含每个文字区域位置的矩形框。
- 优化文本区域框:
- 对于由模型标注的文字区域框,进行优化以确保完整包含文字内容。
- 利用
extendRect函数,可以将文字框的宽度和高度扩展到所需的大小。 - 使用
getSubImage函数裁剪并提取出每个文本区域。
- 保存区域到本地:
- 将优化后的文本区域保存到本地,以备后续文字识别步骤使用或进行进一步的分析。
// 加载图像
String url = "https://resources.djl.ai/images/flight_ticket.jpg";
Image img = ImageFactory.getInstance().fromUrl(url);
// 保存原始图像
img.save(new FileOutputStream("C:\\laker\\demo3\\1.jpg"), "jpg");
// 加载目标检测模型
Criteria<Image, DetectedObjects> criteria1 = Criteria.builder()
.optEngine("PaddlePaddle")
.setTypes(Image.class, DetectedObjects.class)
.optModelUrls("https://resources.djl.ai/test-models/paddleOCR/mobile/det_db.zip")
.optTranslator(new PpWordDetectionTranslator(new ConcurrentHashMap<String, String>()))
.build();
ZooModel<Image, DetectedObjects> detectionModel = criteria1.loadModel();
Predictor<Image, DetectedObjects> detector = detectionModel.newPredictor();
// 进行目标检测
DetectedObjects detectedObj = detector.predict(img);
System.out.println(detectedObj);
// 在新图像上绘制边界框并保存
Image newImage = img.duplicate();
newImage.drawBoundingBoxes(detectedObj);
newImage.save(Files.newOutputStream(Paths.get("C:\\laker\\demo3\\1.png")), "png");
// 提取检测到的对象并保存为单独的图像文件
List<DetectedObjects.DetectedObject> boxes = detectedObj.items();
for (int i = 0; i < boxes.size(); i++) {
Image sample = getSubImage(img, boxes.get(i).getBoundingBox());
// 保存单独的对象图像
sample.save(Files.newOutputStream(Paths.get("C:\\laker\\demo3\\1-" + i + ".png")), "png");
}
...
// 提取目标框内的子图像
static Image getSubImage(Image img, BoundingBox box) {
Rectangle rect = box.getBounds();
double[] extended = extendRect(rect.getX(), rect.getY(), rect.getWidth(), rect.getHeight());
int width = img.getWidth();
int height = img.getHeight();
int[] recovered = {
(int) (extended[0] * width),
(int) (extended[1] * height),
(int) (extended[2] * width),
(int) (extended[3] * height)
};
return img.getSubImage(recovered[0], recovered[1], recovered[2], recovered[3]);
}
// 扩展目标框
static double[] extendRect(double xmin, double ymin, double width, double height) {
double centerx = xmin + width / 2;
double centery = ymin + height / 2;
if (width > height) {
width += height * 2.0;
height *= 3.0;
} else {
height += width * 2.0;
width *= 3.0;
}
double newX = centerx - width / 2 < 0 ? 0 : centerx - width / 2;
double newY = centery - height / 2 < 0 ? 0 : centery - height / 2;
double newWidth = newX + width > 1 ? 1 - newX : width;
double newHeight = newY + height > 1 ? 1 - newY : height;
return new double[]{newX, newY, newWidth, newHeight};
}
}
以下为日志和结果
ai.djl.paddlepaddle.jni.LibUtils -- Downloading https://publish.djl.ai/paddlepaddle-2.3.2/cpu/win/native/lib/paddle_inference.dll.gz ...
ai.djl.paddlepaddle.jni.LibUtils -- Downloading https://publish.djl.ai/paddlepaddle-2.3.2/cpu/win/native/lib/openblas.dll.gz ...
ai.djl.paddlepaddle.jni.LibUtils -- Downloading https://publish.djl.ai/paddlepaddle-2.3.2/cpu/win/native/lib/onnxruntime.dll.gz ...
INFO ai.djl.paddlepaddle.jni.LibUtils -- Downloading https://publish.djl.ai/paddlepaddle-2.3.2/cpu/win/native/lib/paddle2onnx.dll.gz ...
ai.djl.paddlepaddle.jni.LibUtils -- Extracting jnilib/win-x86_64/cpu/djl_paddle.dll to cache ...
ai.djl.pytorch.engine.PtEngine -- PyTorch graph executor optimizer is enabled, this may impact your inference latency and throughput. See: https://docs.djl.ai/docs/development/inference_performance_optimization.html#graph-executor-optimization
ai.djl.pytorch.engine.PtEngine -- Number of inter-op threads is 4
ai.djl.pytorch.engine.PtEngine -- Number of intra-op threads is 4
WARNING: Logging before InitGoogleLogging() is written to STDERR
W0110 22:31:36.663225 34380 analysis_predictor.cc:1736] Deprecated. Please use CreatePredictor instead.
e[1me[35m--- Running analysis [ir_graph_build_pass]e[0m
I0110 22:31:36.928385 34380 analysis_predictor.cc:1035] ======= optimize end =======
I0110 22:31:36.928385 34380 naive_executor.cc:102] --- skip [feed], feed -> x
I0110 22:31:36.931370 34380 naive_executor.cc:102] --- skip [save_infer_model/scale_0.tmp_1], fetch -> fetch
I0110 22:31:36.935369 34380 naive_executor.cc:102] --- skip [feed], feed -> x
I0110 22:31:36.938895 34380 naive_executor.cc:102] --- skip [save_infer_model/scale_0.tmp_1], fetch -> fetch
[
{"class": "word", "probability": 1.00000, "bounds": {"x"=0.071, "y"=0.033, "width"=0.067, "height"=0.008}}
{"class": "word", "probability": 1.00000, "bounds": {"x"=0.797, "y"=0.055, "width"=0.107, "height"=0.031}}
{"class": "word", "probability": 1.00000, "bounds": {"x"=0.485, "y"=0.063, "width"=0.238, "height"=0.029}}
]
有用的只有bounds这个字段
文字角度检测
文字角度检测也是OCR过程中的一个关键环节,其主要目的是确认图片中的文字是否需要旋转,以确保后续的文字识别能够准确进行。
String url = "https://resources.djl.ai/images/flight_ticket.jpg";
Image img = ImageFactory.getInstance().fromUrl(url);
img.getWrappedImage();
Criteria<Image, Classifications> criteria2 = Criteria.builder()
.optEngine("PaddlePaddle")
.setTypes(Image.class, Classifications.class)
.optModelUrls("https://resources.djl.ai/test-models/paddleOCR/mobile/cls.zip")
.optTranslator(new PpWordRotateTranslator())
.build();
ZooModel<Image, Classifications> rotateModel = criteria2.loadModel();
Predictor<Image, Classifications> predictor = rotateModel.newPredictor();
Classifications classifications = predictor.predict(img);
System.out.println(classifications);
System.out.println(classifications.best());
}
结果
[
{"class": "Rotate", "probability": 0.60876}
{"class": "No Rotate", "probability": 0.39123}
]
{"class": "Rotate", "probability": 0.60876}
这里旋转的可能性为0.60876,可以设置个阈值,如果大于阈值则需要旋转
// 获取图像的旋转分类结果
Classifications.Classification result = getRotateResult(subImg);
// 判断是否需要旋转,并且置信度大于 0.8
if ("Rotate".equals(result.getClassName()) && result.getProbability() > 0.8) {
// 如果需要旋转,则调用 rotateImg 方法进行图像旋转
subImg = rotateImg(subImg);
}
// 图像旋转方法
private static Image rotateImg(Image image) {
try (NDManager manager = NDManager.newBaseManager()) {
// 利用 NDImageUtils.rotate90 进行图像旋转,参数 1 表示顺时针旋转 90 度
NDArray rotated = NDImageUtils.rotate90(image.toNDArray(manager), 1);
// 将旋转后的 NDArray 转换回 Image 对象并返回
return ImageFactory.getInstance().fromNDArray(rotated);
}
}
文字识别(裁减旋转后的文字区域)
在文字识别的过程中,我们注意到处理大图片时可能导致效果较差。为了优化识别效果,建议将输入的 img 替换为经过前面两部处理后文字区域检测出来的仅包含文字的图片,以获得更好的效果。
String url = "https://resources.djl.ai/images/flight_ticket.jpg";
Image img = ImageFactory.getInstance().fromUrl(url);
img.getWrappedImage();
Criteria<Image, String> criteria3 = Criteria.builder()
.optEngine("PaddlePaddle")
.setTypes(Image.class, String.class)
.optModelUrls("https://resources.djl.ai/test-models/paddleOCR/mobile/rec_crnn.zip")
.optTranslator(new PpWordRecognitionTranslator())
.build();
ZooModel<Image, String> recognitionModel = criteria3.loadModel();
Predictor<Image, String> recognizer = recognitionModel.newPredictor();
String predict = recognizer.predict(img);
System.out.println(predict); // 输出示例:laker
高级
替换模型(离线)
在模型的选择方面,建议考虑替换
paddlepaddle-model-zoo中自带的模型,因为这些模型可能相对较老。为了提高推理效果,我们可以选择更先进、性能更好的模型。以文字识别模型示例,区域检测和角度检测更简单。
获取推理模型文件:https://github.com/PaddlePaddle/PaddleOCR
- 模型列表,注意跟随版本号(当前2.7)变更地址:
- https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/models_list.md
获取字典文件:wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.7/ppocr/utils/ppocr_keys_v1.txt
-
ppocr_keys_v1.txt是中文字典文件,如果使用的模型是英文数字或其他语言的模型,需要更换为对应语言的字典.
-
其他语言的字典文件,可从 PaddleOCR 仓库下载:https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7/ppocr/utils/dict
中文识别模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ch_PP-OCRv4_rec | 【最新】超轻量模型,支持中英文、数字识别 | ch_PP-OCRv4_rec_distill.yml | 10M | 推理模型 / 训练模型 |
| ch_PP-OCRv4_server_rec | 【最新】高精度模型,支持中英文、数字识别 | ch_PP-OCRv4_rec_hgnet.yml | 88M | 推理模型 / 训练模型 |
| ch_PP-OCRv3_rec_slim | slim量化版超轻量模型,支持中英文、数字识别 | ch_PP-OCRv3_rec_distillation.yml | 4.9M | 推理模型 / 训练模型 / nb模型 |
| ch_PP-OCRv3_rec | 原始超轻量模型,支持中英文、数字识别 | ch_PP-OCRv3_rec_distillation.yml | 12.4M | 推理模型 / 训练模型 |
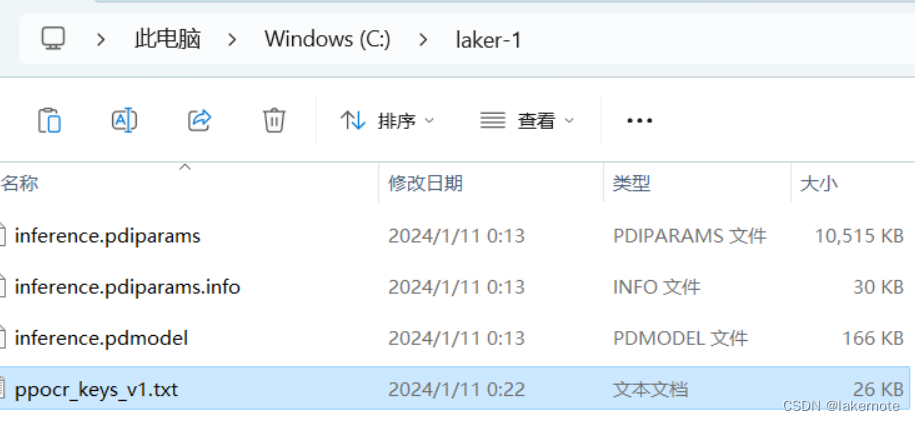
我们以ch_PP-OCRv4_rec为例,下载推理模型和ppocr_keys_v1.txt文件,然后放到如下目录中:
字典文件名称必须为
ppocr_keys_v1.txt,选择其他语言模型,也要把文件名改成这个。
示例代码如下:
Image img = ImageFactory.getInstance().fromFile(Path.of("C:\\laker\\demo3\\1-26.png"));
img.getWrappedImage();
Criteria<Image, String> criteria3 = Criteria.builder()
.optEngine("PaddlePaddle")
.setTypes(Image.class, String.class)
.optModelPath(Paths.get("C:\\laker-1")) // 这里指定模型
.optTranslator(new PpWordRecognitionTranslator())
.build();
ZooModel<Image, String> recognitionModel = criteria3.loadModel();
Predictor<Image, String> recognizer = recognitionModel.newPredictor();
String predict = recognizer.predict(img);
System.out.println(predict);
还有其他方式可以替换,例如:
// 其他方式一 把zip包上传到 s3 指定其url
Criteria<Image, String> criteria3 = Criteria.builder()
.optEngine("PaddlePaddle")
.setTypes(Image.class, String.class)
.optModelUrls("https://xxx.com/models/xxx_det_infer.zip")
.optTranslator(new PpWordRecognitionTranslator())
.build();
// 其他方式二 加载本地zip文件
Criteria<Image, String> criteria3 = Criteria.builder()
.optEngine("PaddlePaddle")
.setTypes(Image.class, String.class)
.optModelPath(Paths.get("/laker/xxx_det_infer.zip"))
.optTranslator(new PpWordRecognitionTranslator())
.build();
// 其他方式三 加载位于JAR文件中模型
Criteria<Image, String> criteria3 = Criteria.builder()
.optEngine("PaddlePaddle")
.setTypes(Image.class, String.class)
.optModelUrls("jar:///xxx_det_infer.zip")
.optTranslator(new PpWordRecognitionTranslator())
.build();