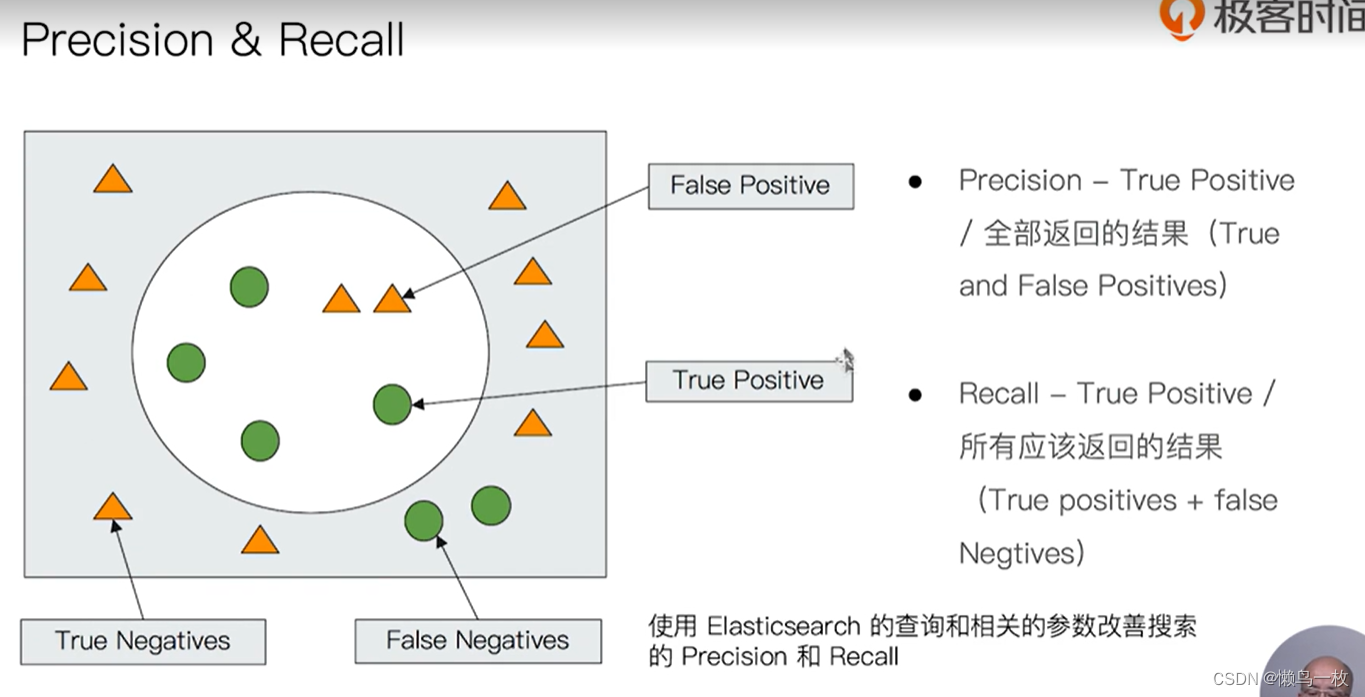
基本概念 索引、文档、节点、分片和API

json 文档

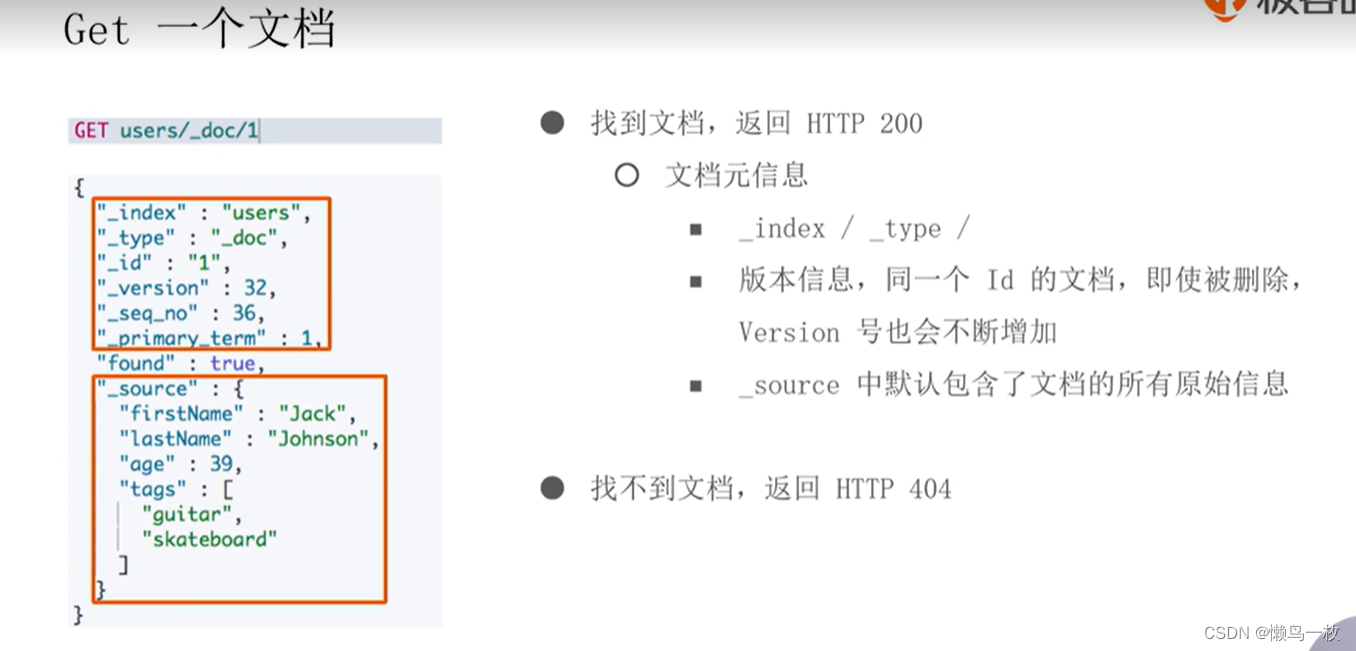
文档的元数据

需要通过Kibana导入Sample Data的电商数据。具体参考“2.2节-Kibana的安装与界面快速浏览”
索引




kibana 管理ES索引
在系统中找到kibana配置文件(我这里是etc/kibana/kibana.yml)
vim /etc/kibana/kibana.yml
#在配置文件中加入以下代码即可设置kibanan的中文界面
这块可以进行索引管理,查看索引的
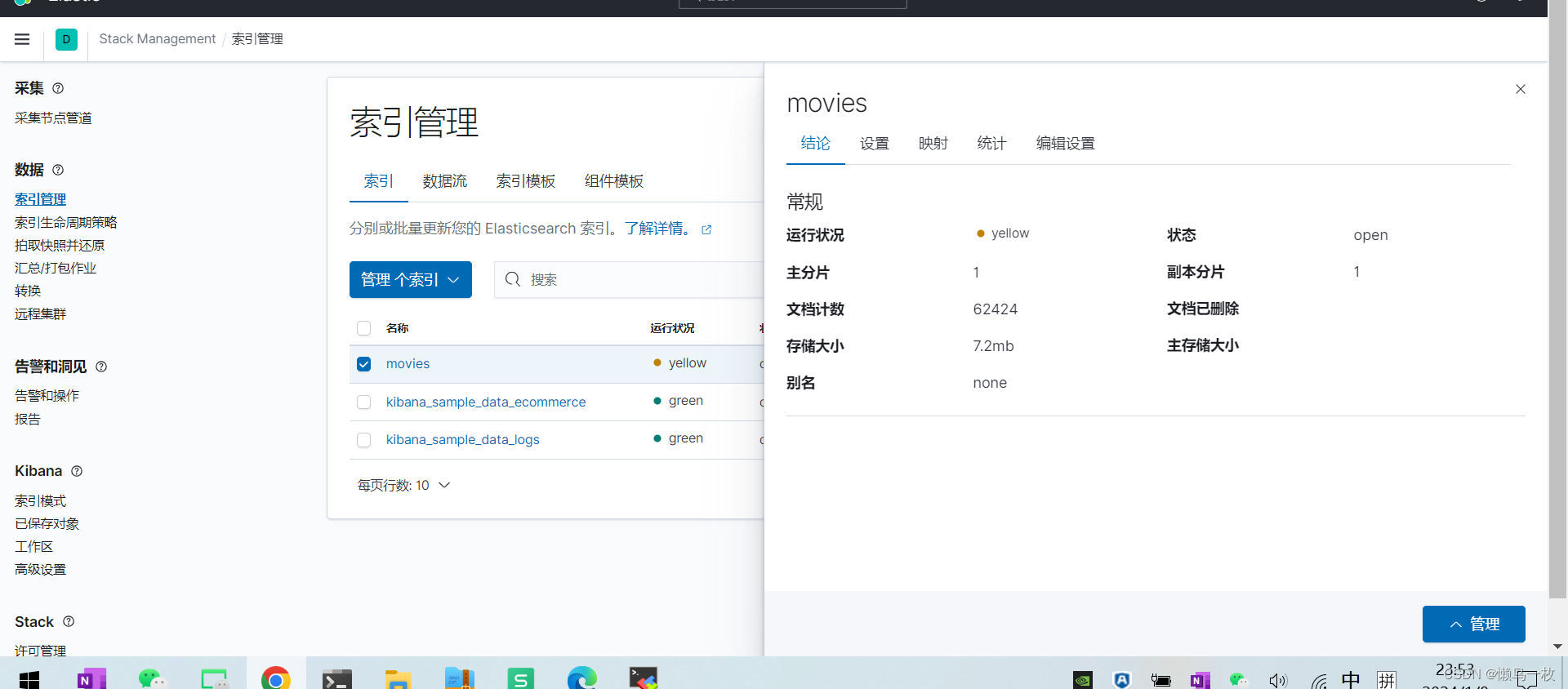
kibana的开发工使用-索引
需要通过Kibana导入Sample Data的电商数据。具体参考“2.2节-Kibana的安装与界面快速浏览”
笔记
Index 相关 API
#查看索引相关信息
GET kibana_sample_data_ecommerce
#查看索引的文档总数
GET kibana_sample_data_ecommerce/_count
#查看前10条文档,了解文档格式
POST kibana_sample_data_ecommerce/_search
{
}
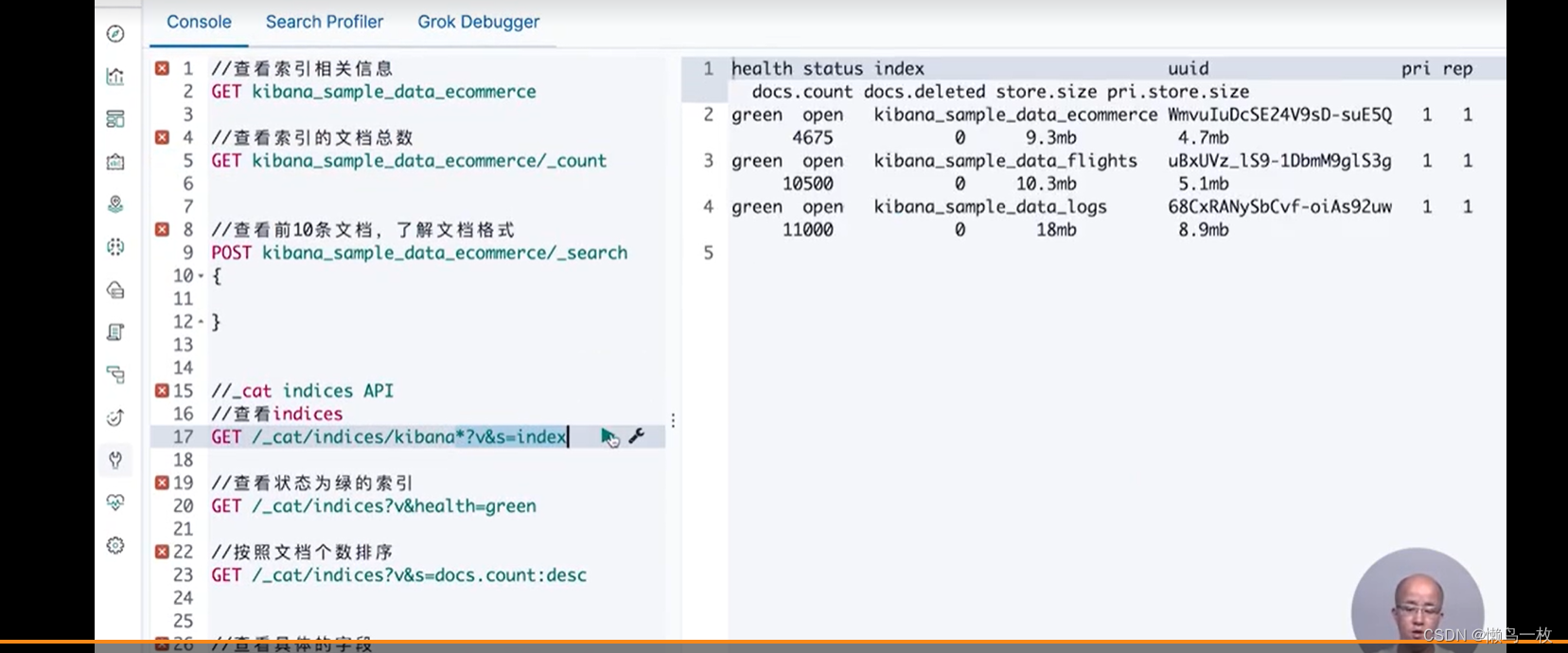
#_cat indices API
#查看indices
GET /_cat/indices/kibana*?v&s=index
#查看状态为绿的索引
GET /_cat/indices?v&health=green
#按照文档个数排序
GET /_cat/indices?v&s=docs.count:desc
#查看具体的字段
GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs.count,mt
#How much memory is used per index?
GET /_cat/indices?v&h=i,tm&s=tm:desc
为什么不再支持单个Index下,多个Tyeps https://www.elastic.co/cn/blog/moving-from-types-to-typeless-apis-in-elasticsearch-7-0
基本概念 - 节点、集群、副本、分片

节点




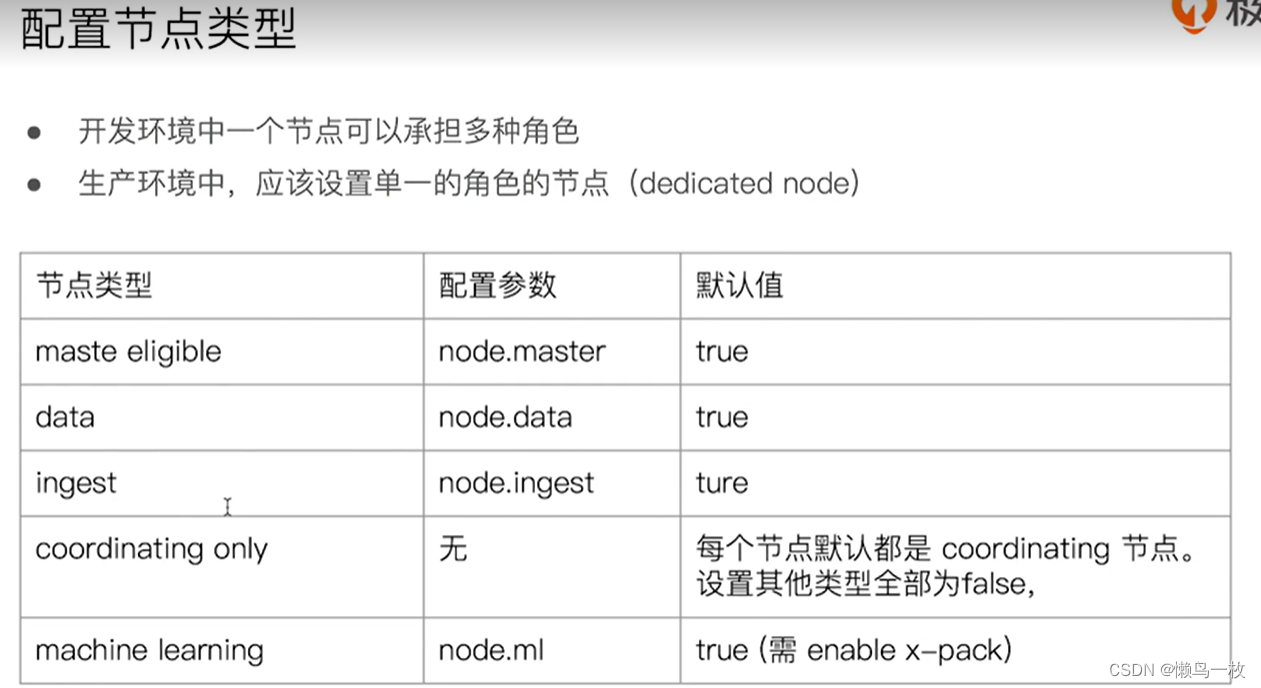
分片

分片和副本分散数据的关系
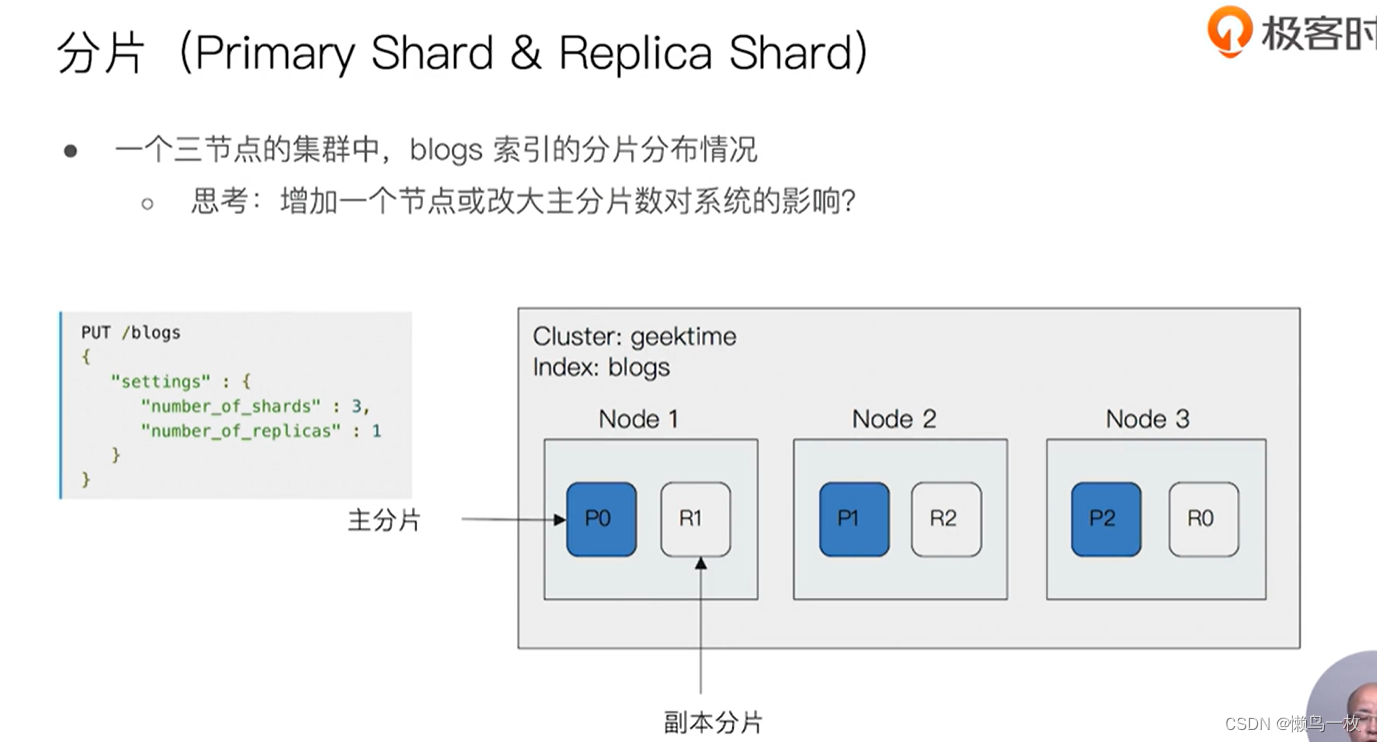
blog 索引 number_of_shards :主分片数设置成3 number_ofreplicas: 副本数 设置成1


Kibana 和Cerebro管理ES集群

command+/ 跳到官方的API说明
Mapping中的字段一旦设定后,禁止直接修改。因为倒排索引生成后不允许直接修改。需要重新建立新的索引,做reindex操作。
类似数据库中的表结构定义,主要作用
- 定义所以下的字段名字
- 定义字段的类型
- 定义倒排索引相关的配置(是否被索引?采用的Analyzer)
- 对新增字段的处理 true false strict
在object下,支持做dynamic的属性的定义
课程Demo
#写入文档,查看 Mapping
PUT mapping_test/_doc/1
{
"firstName":"Chan",
"lastName": "Jackie",
"loginDate":"2018-07-24T10:29:48.103Z"
}
#查看 Mapping文件
GET mapping_test/_mapping
#Delete index
DELETE mapping_test
#dynamic mapping,推断字段的类型
PUT mapping_test/_doc/1
{
"uid" : "123",
"isVip" : false,
"isAdmin": "true",
"age":19,
"heigh":180
}
#查看 Dynamic
GET mapping_test/_mapping
#默认Mapping支持dynamic,写入的文档中加入新的字段
PUT dynamic_mapping_test/_doc/1
{
"newField":"someValue"
}
#该字段可以被搜索,数据也在_source中出现
POST dynamic_mapping_test/_search
{
"query":{
"match":{
"newField":"someValue"
}
}
}
#修改为dynamic false
PUT dynamic_mapping_test/_mapping
{
"dynamic": false
}
#新增 anotherField
PUT dynamic_mapping_test/_doc/10
{
"anotherField":"someValue"
}
#该字段不可以被搜索,因为dynamic已经被设置为false
POST dynamic_mapping_test/_search
{
"query":{
"match":{
"anotherField":"someValue"
}
}
}
get dynamic_mapping_test/_doc/10
#修改为strict
PUT dynamic_mapping_test/_mapping
{
"dynamic": "strict"
}
#写入数据出错,HTTP Code 400
PUT dynamic_mapping_test/_doc/12
{
"lastField":"value"
}
DELETE dynamic_mapping_test
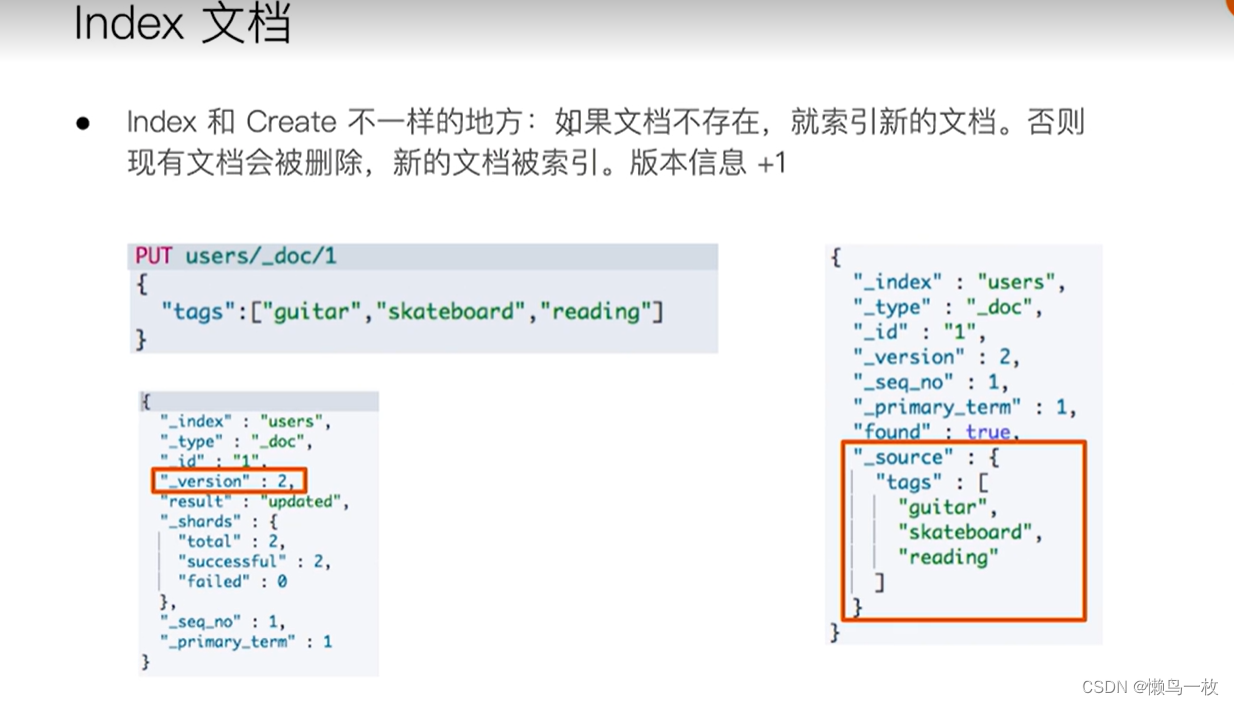
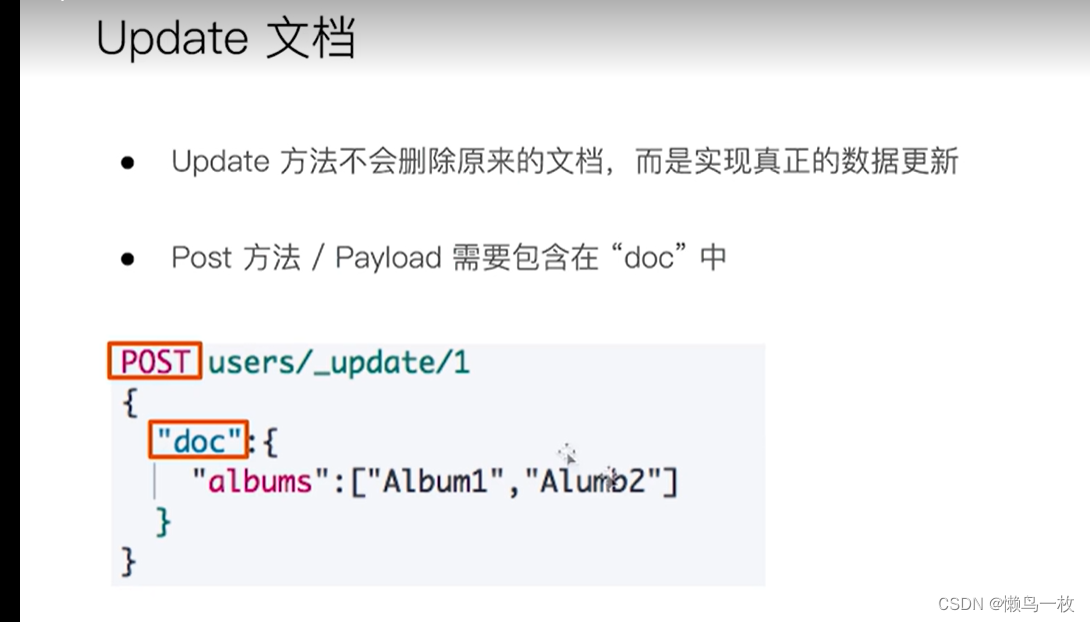
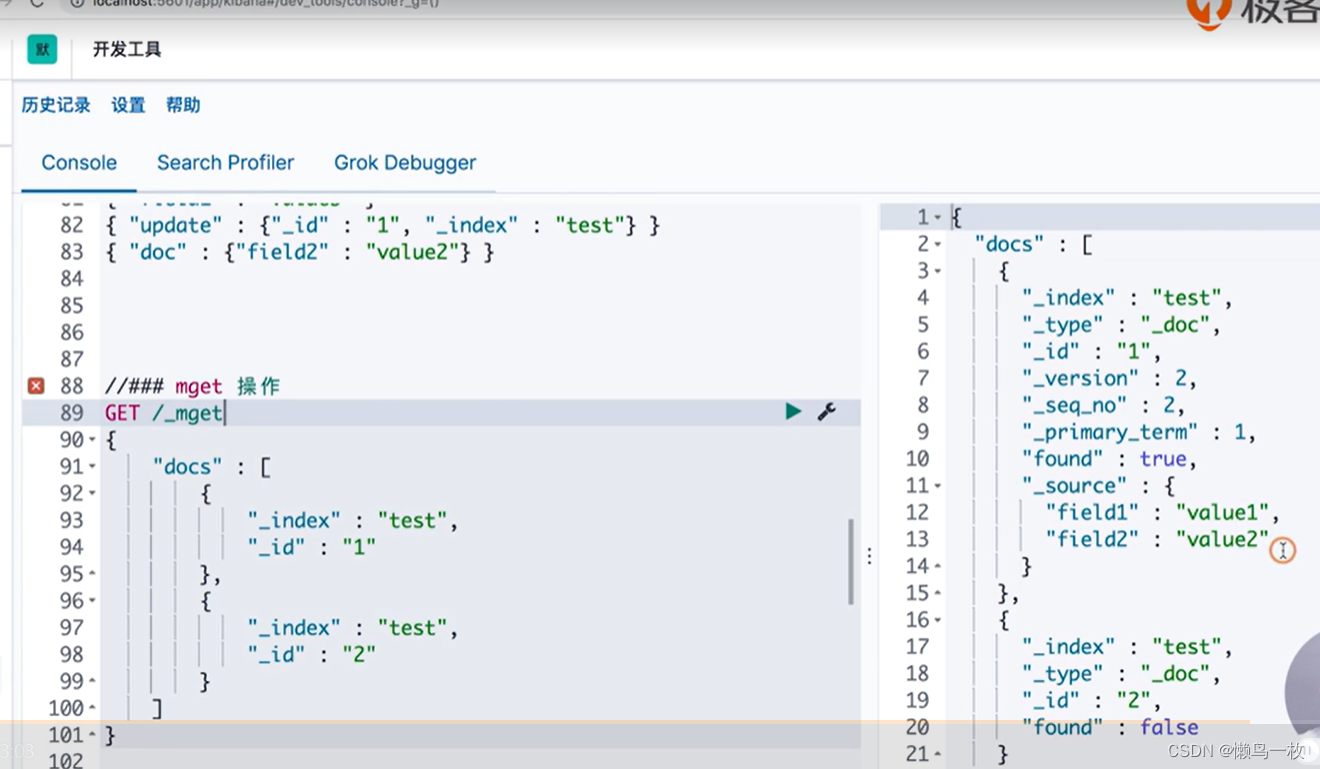
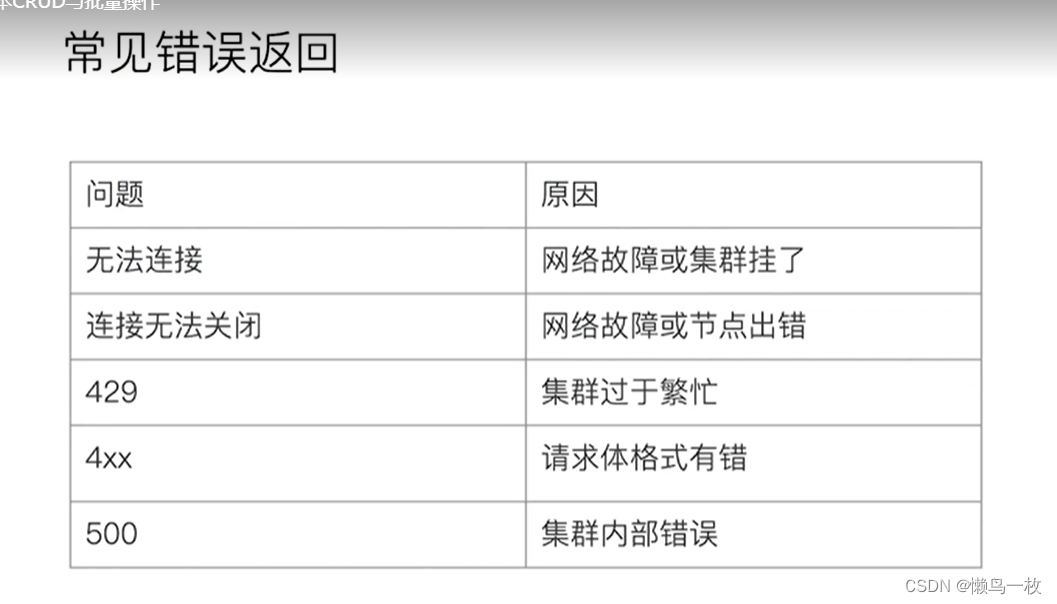
文档的CRUD与文档的基本操作

格式 索引名称/_doc/索引id




倒排索引
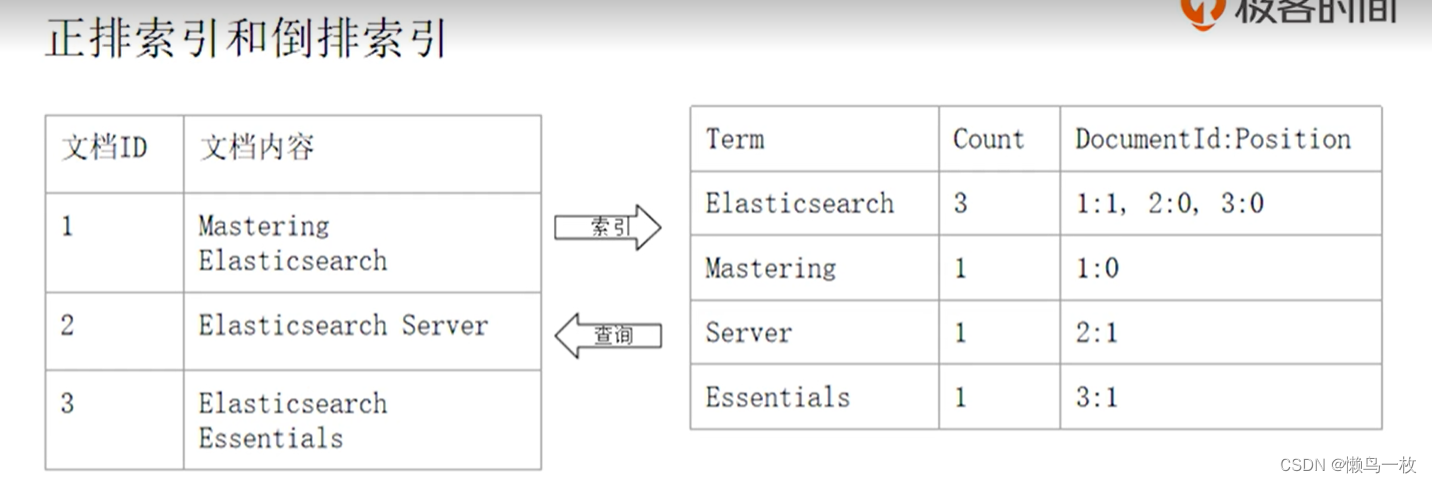




课程Demo
POST _analyze
{
"analyzer": "standard",
"text": "Mastering Elasticsearch"
}
POST _analyze
{
"analyzer": "standard",
"text": "Elasticsearch Server"
}
POST _analyze
{
"analyzer": "standard",
"text": "Elasticsearch Essentials"
}
通过Analyzer 进行分词
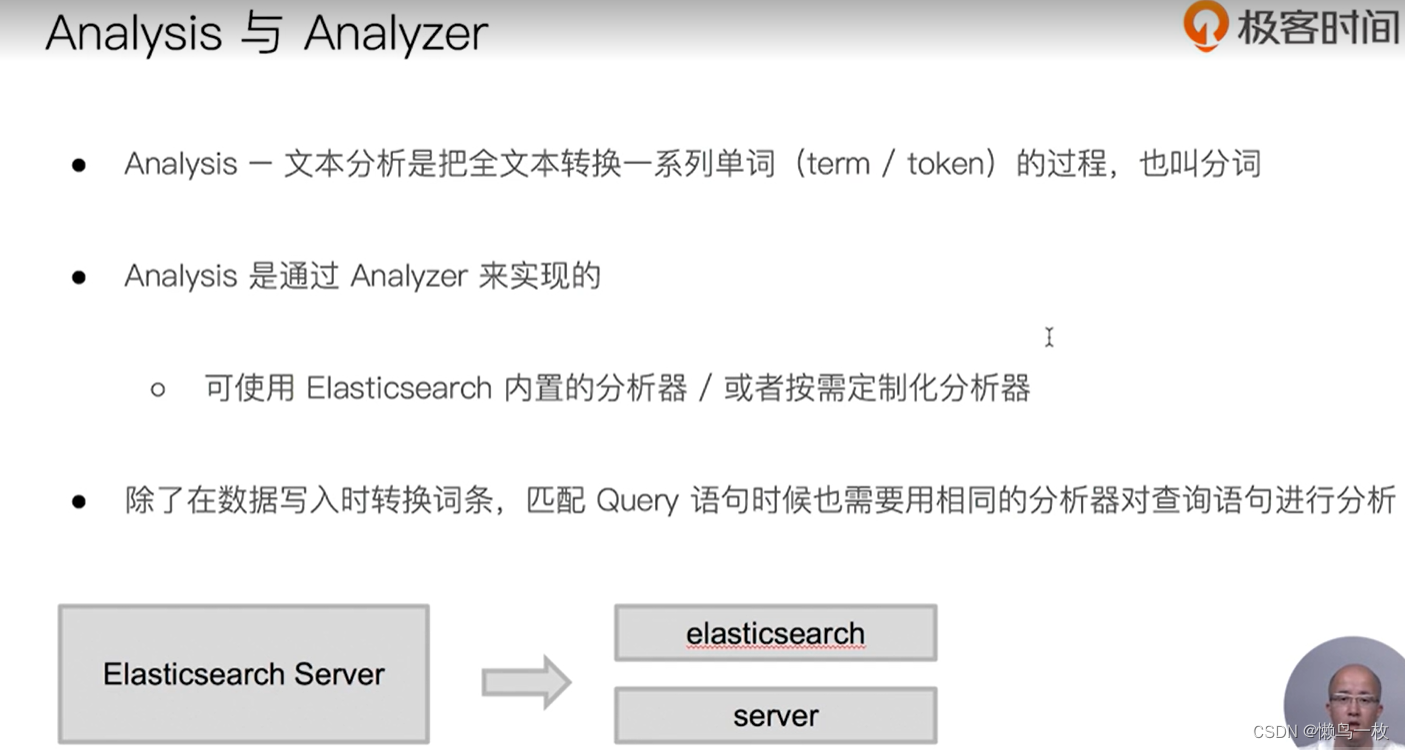
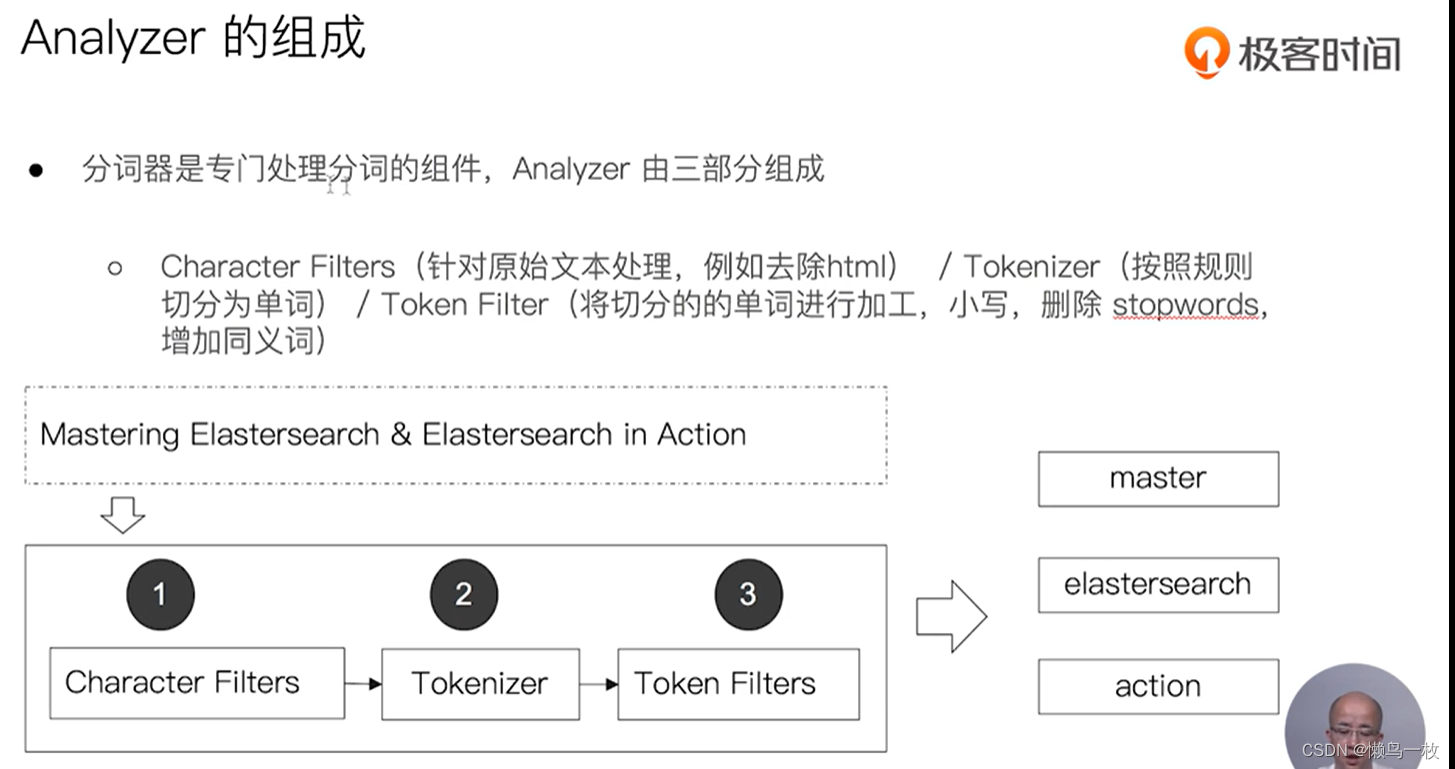

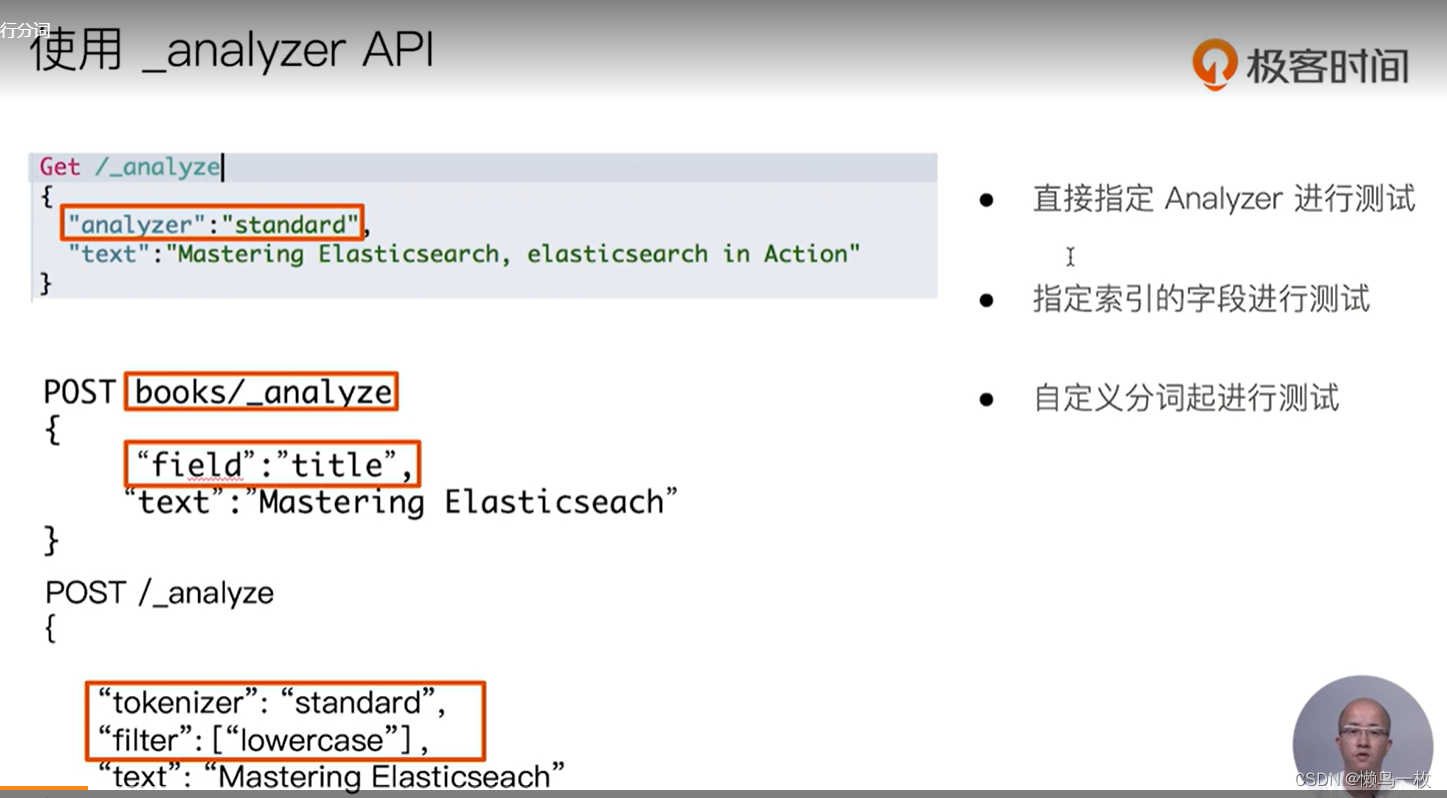
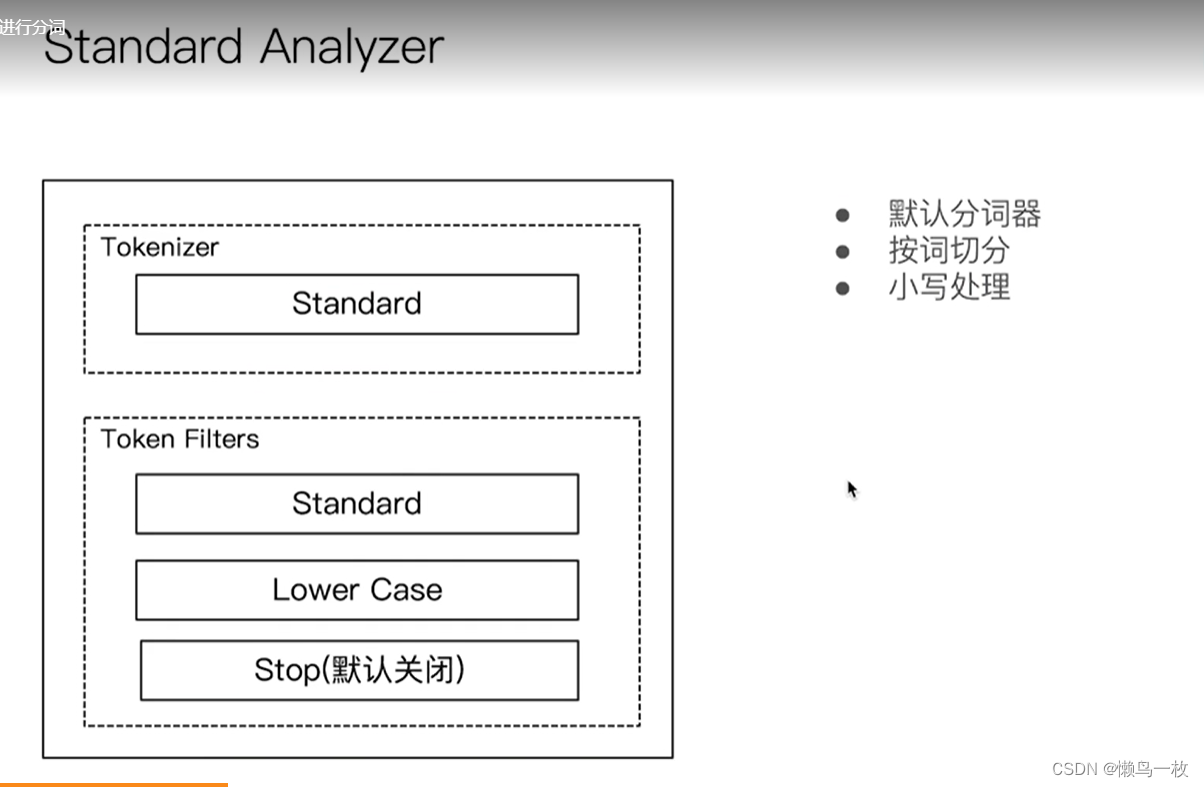
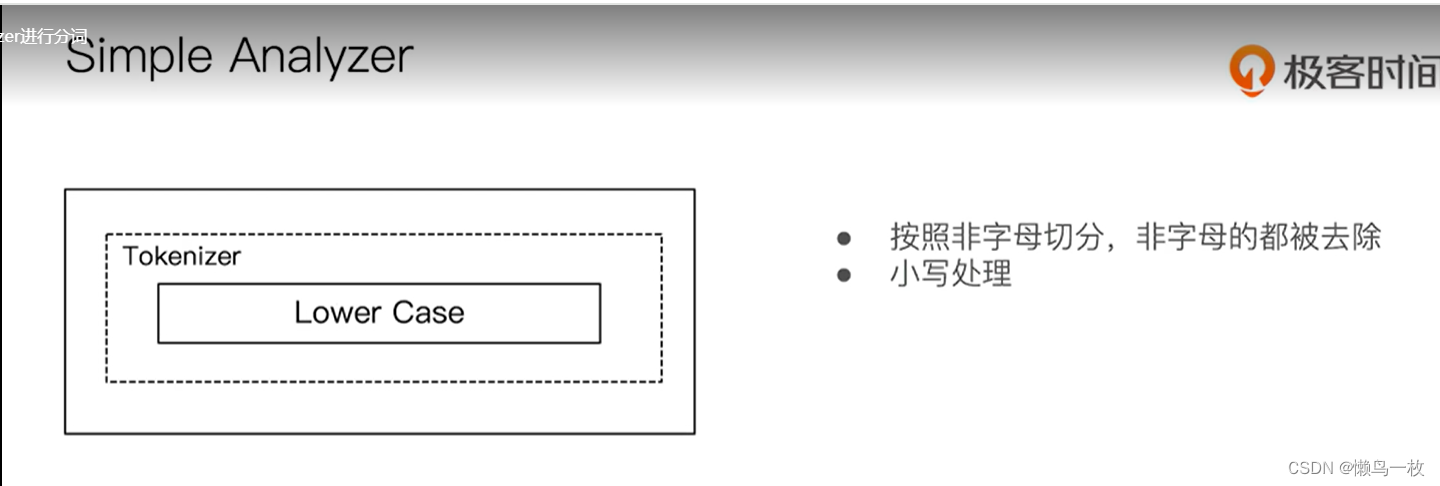
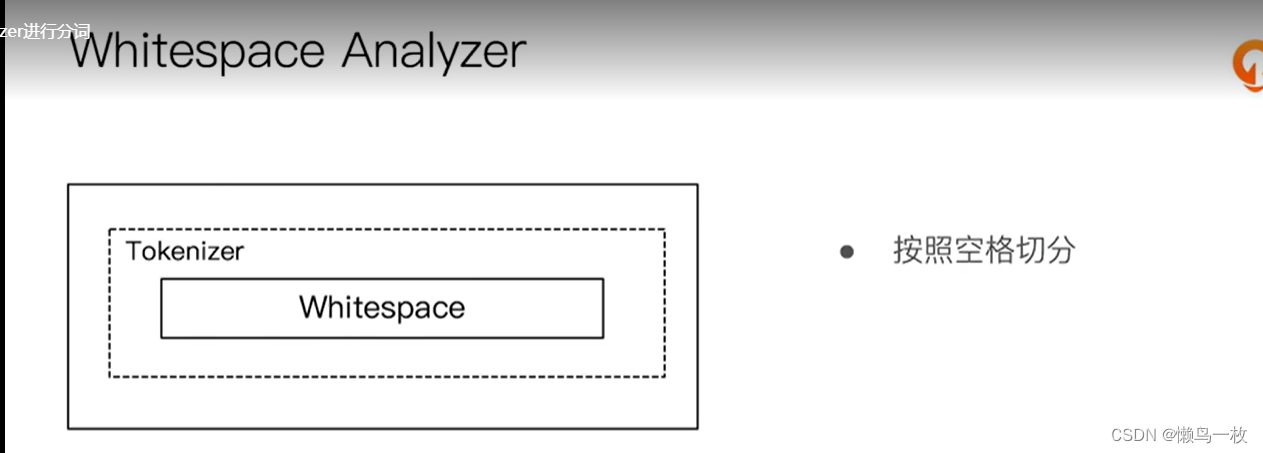
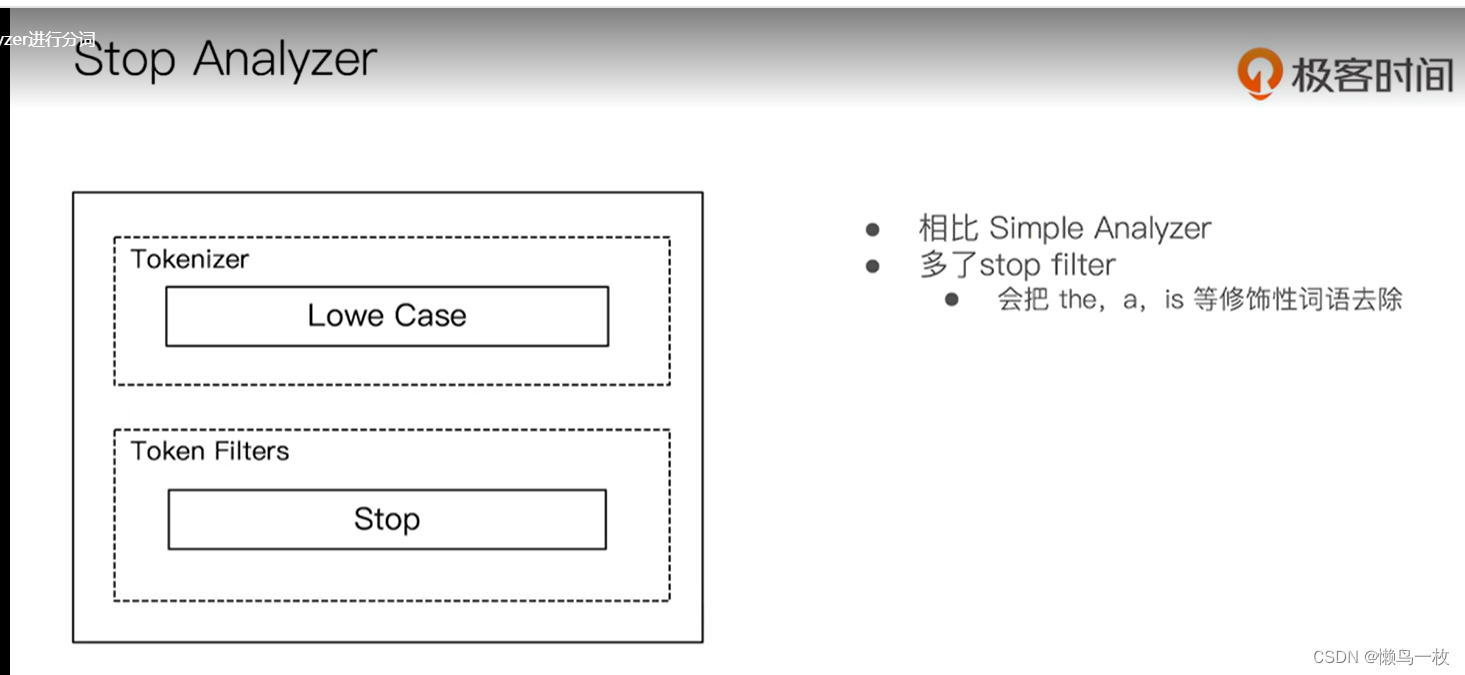
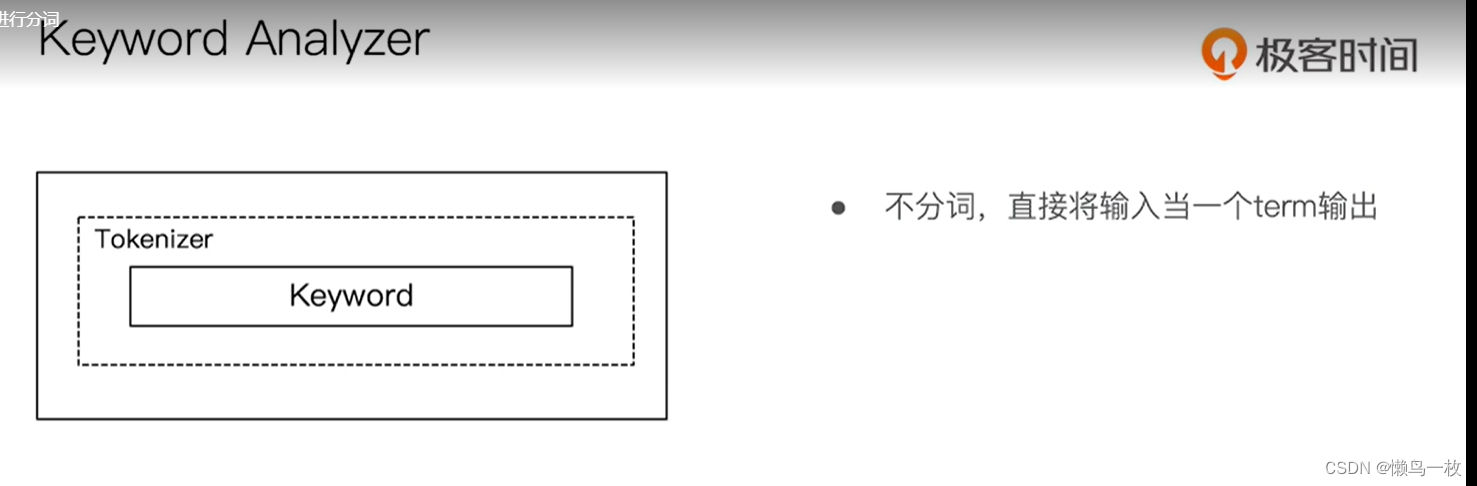


使用分析器进行分词
课程Demo
#Simple Analyzer – 按照非字母切分(符号被过滤),小写处理
#Stop Analyzer – 小写处理,停用词过滤(the,a,is)
#Whitespace Analyzer – 按照空格切分,不转小写
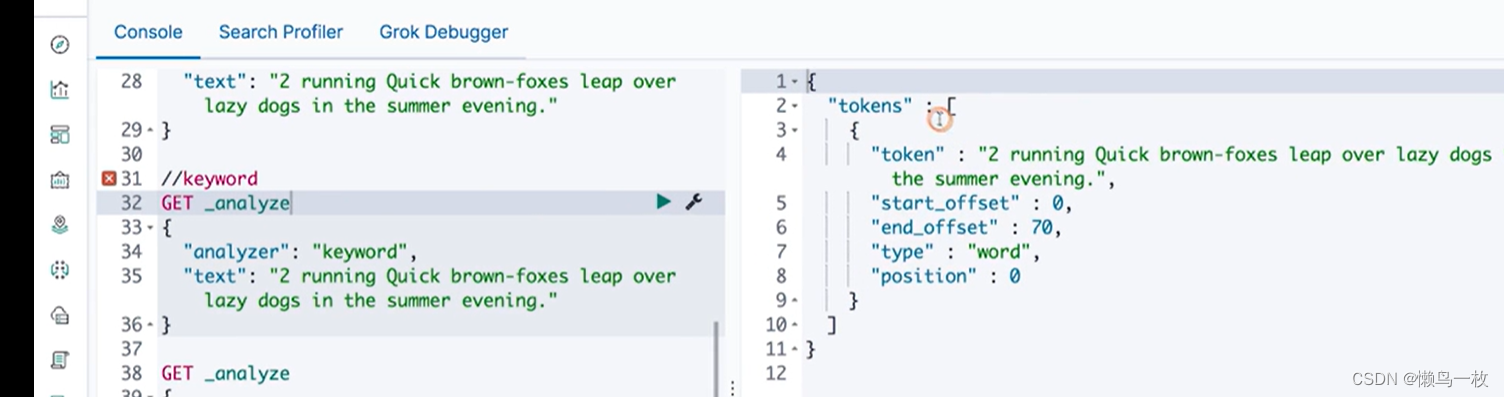
#Keyword Analyzer – 不分词,直接将输入当作输出
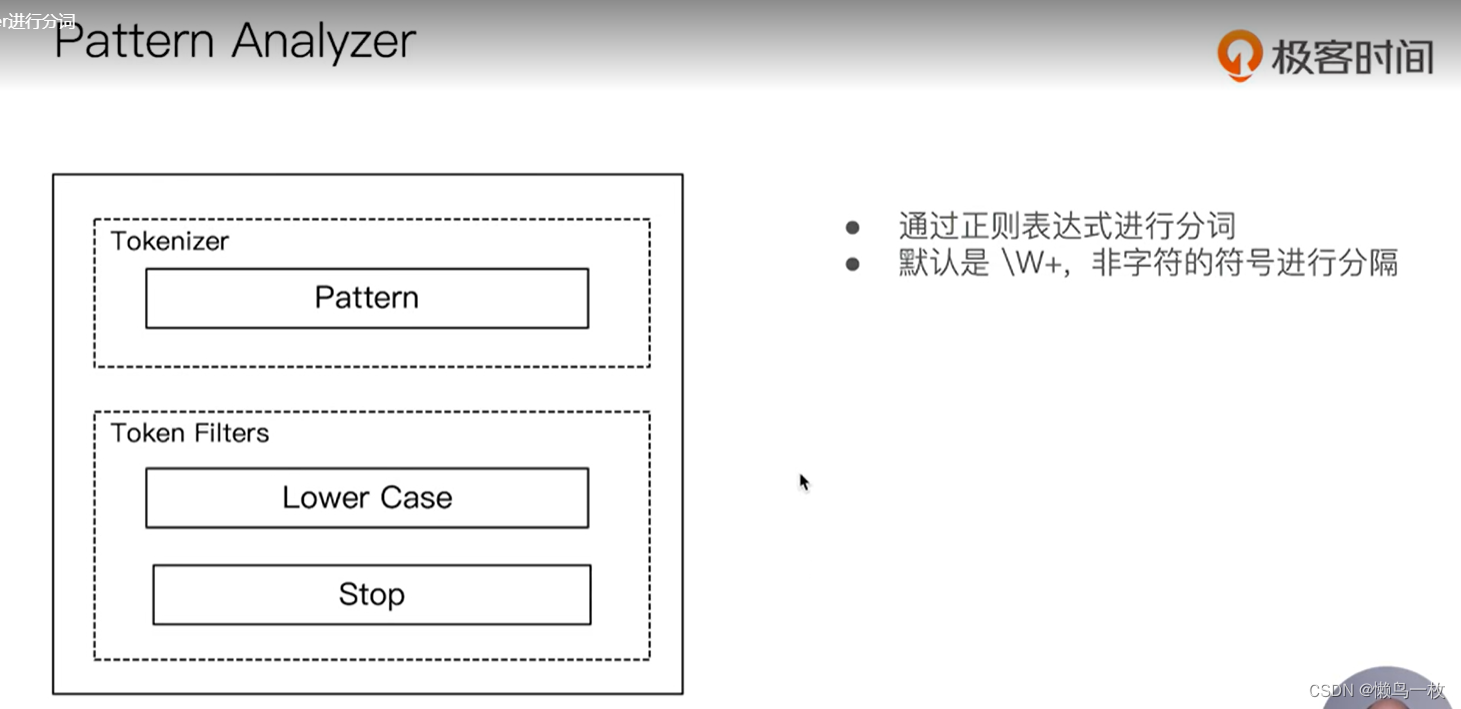
#Patter Analyzer – 正则表达式,默认 \W+ (非字符分隔)
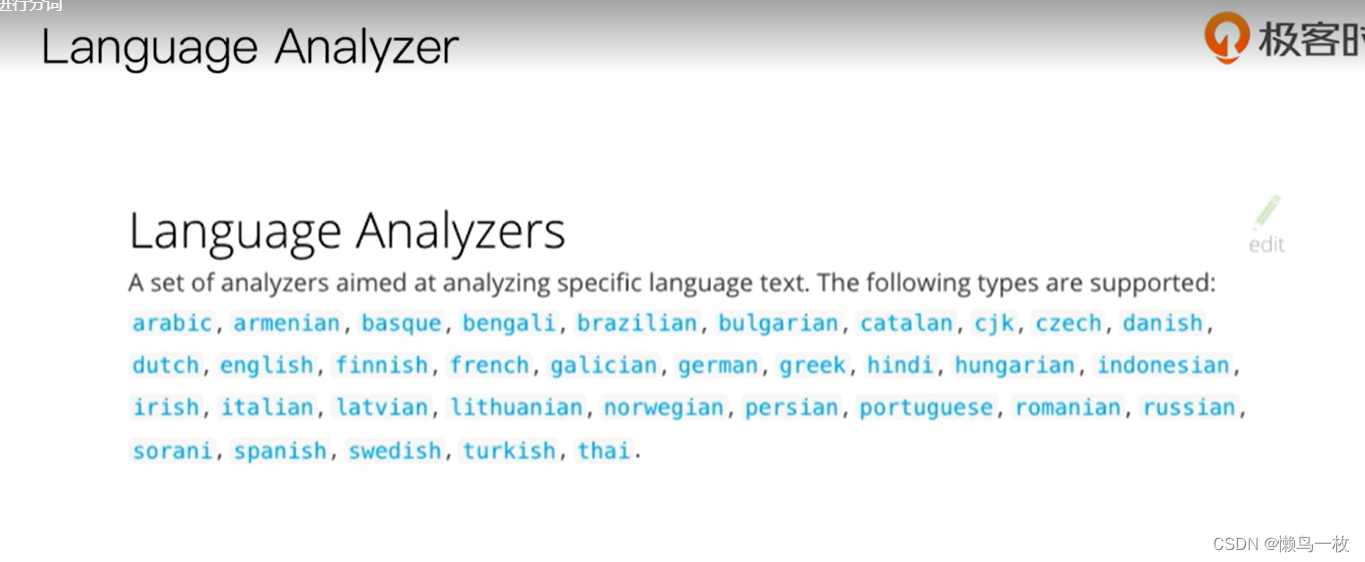
#Language – 提供了30多种常见语言的分词器
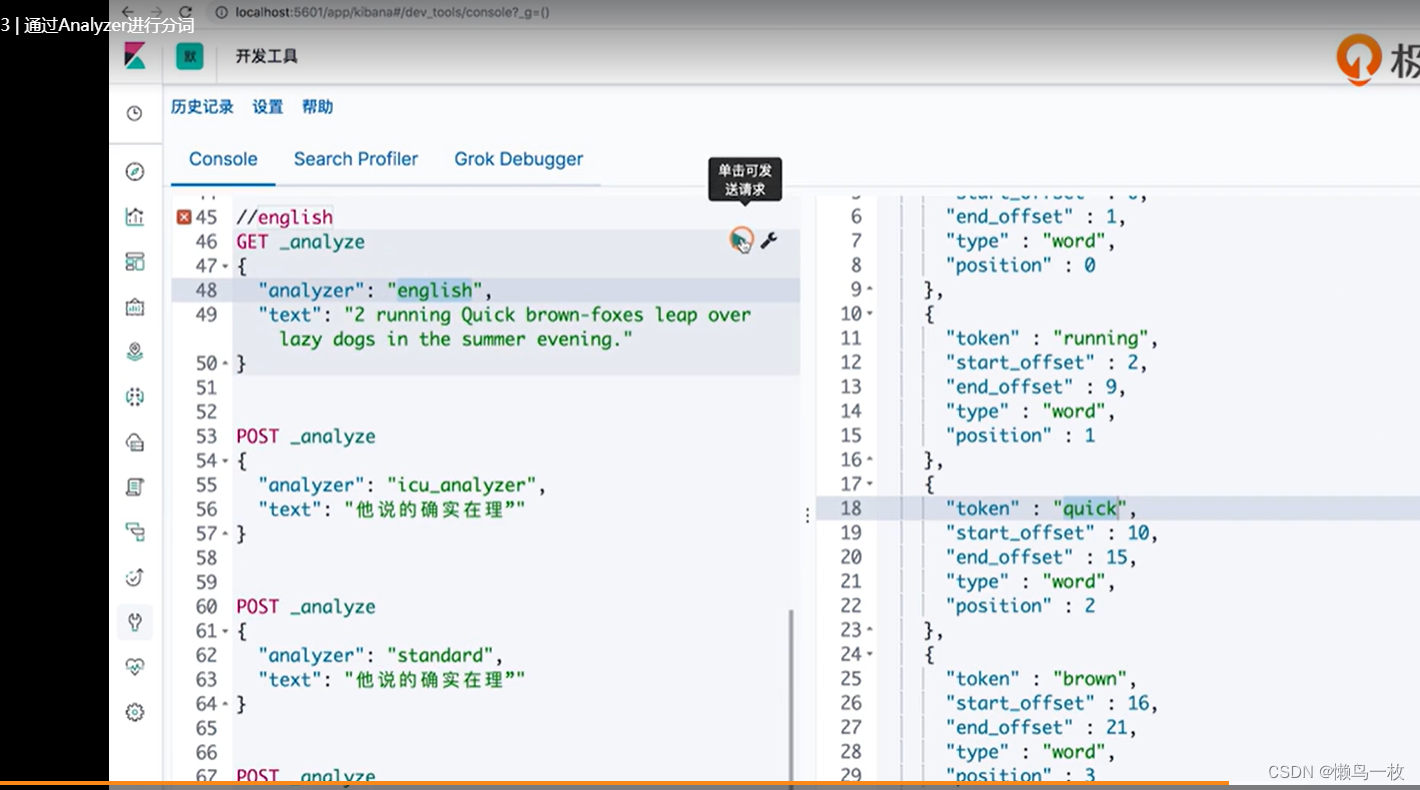
#2 running Quick brown-foxes leap over lazy dogs in the summer evening
查看不同的analyzer的效果
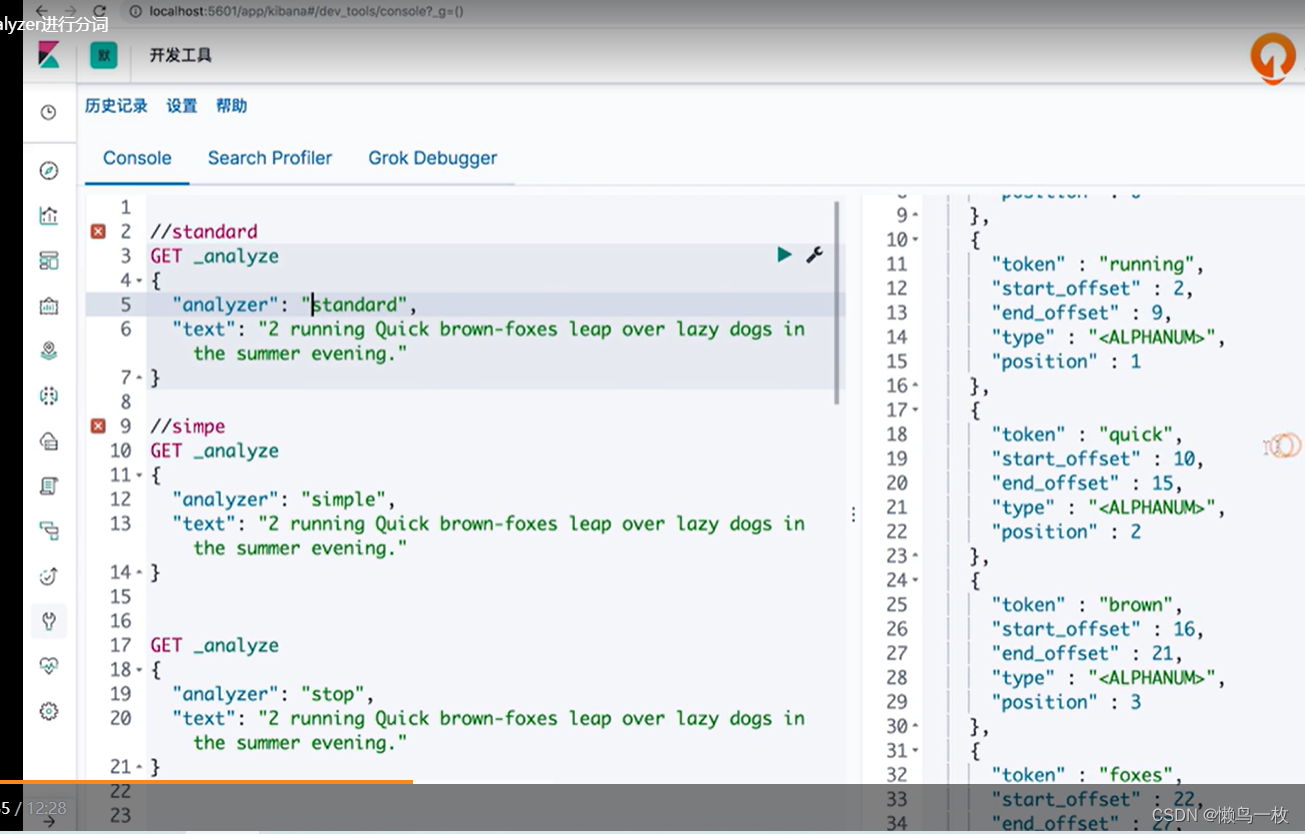
#standard
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
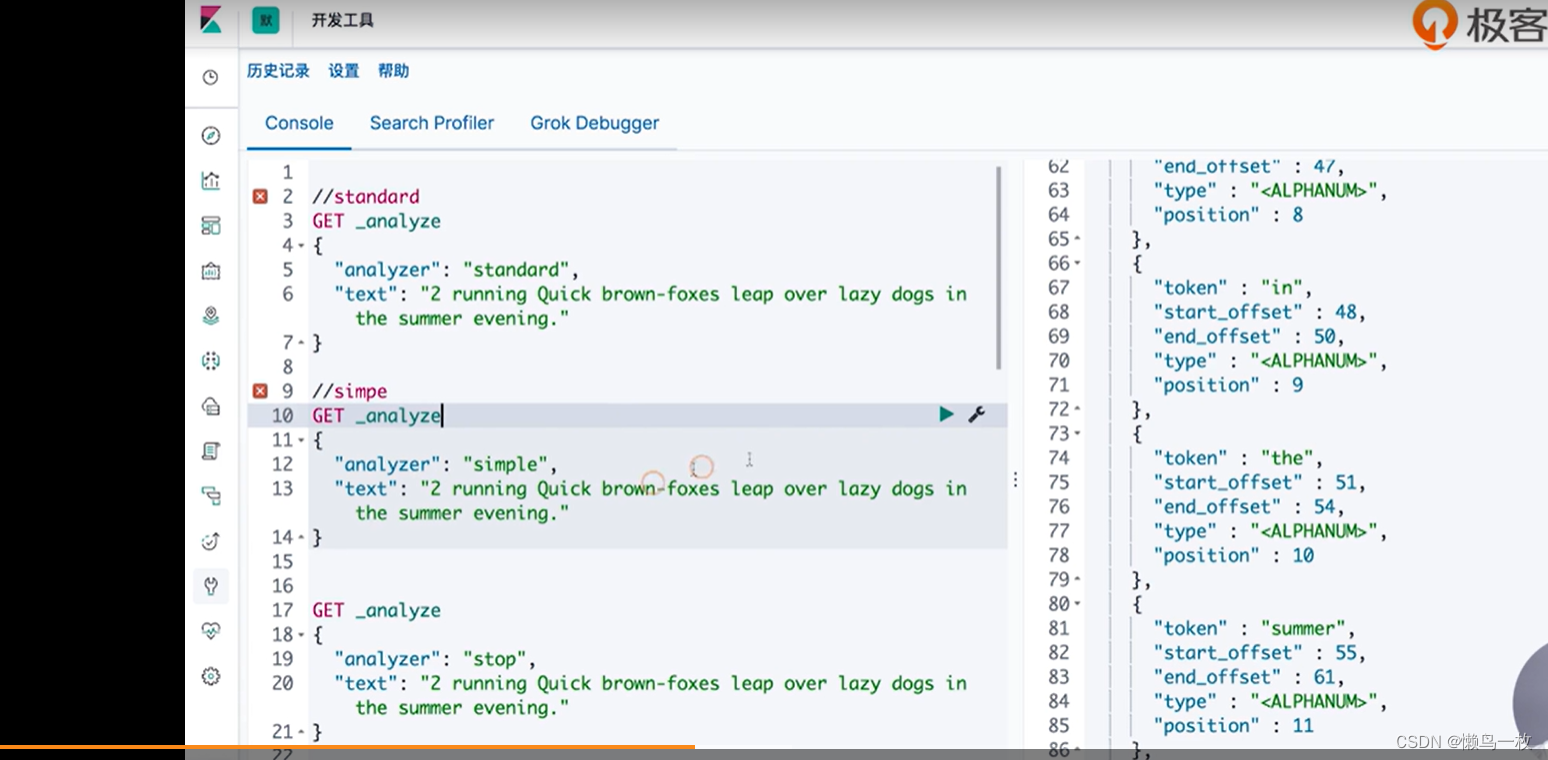
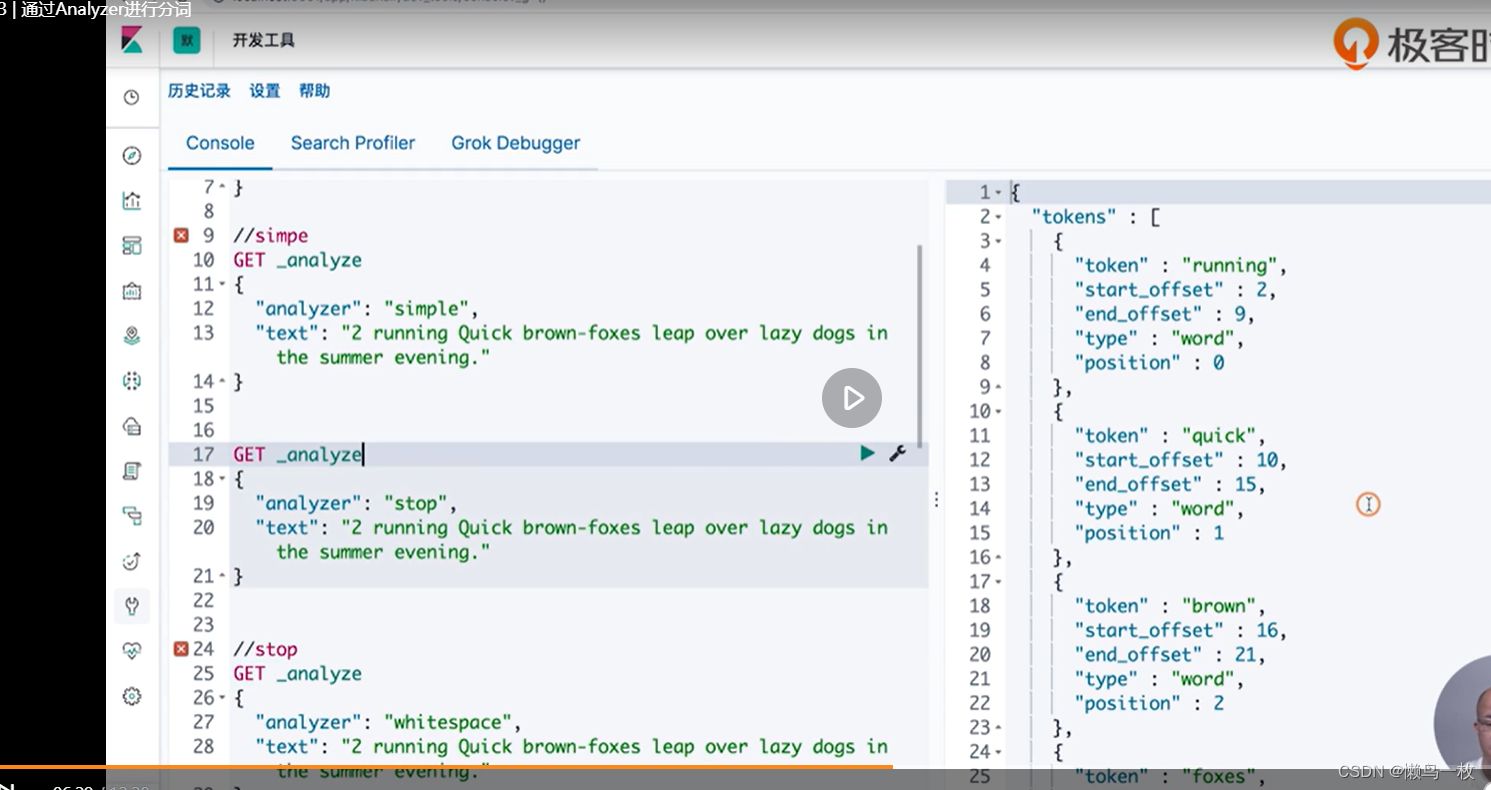
#simpe
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#stop
GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#keyword
GET _analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
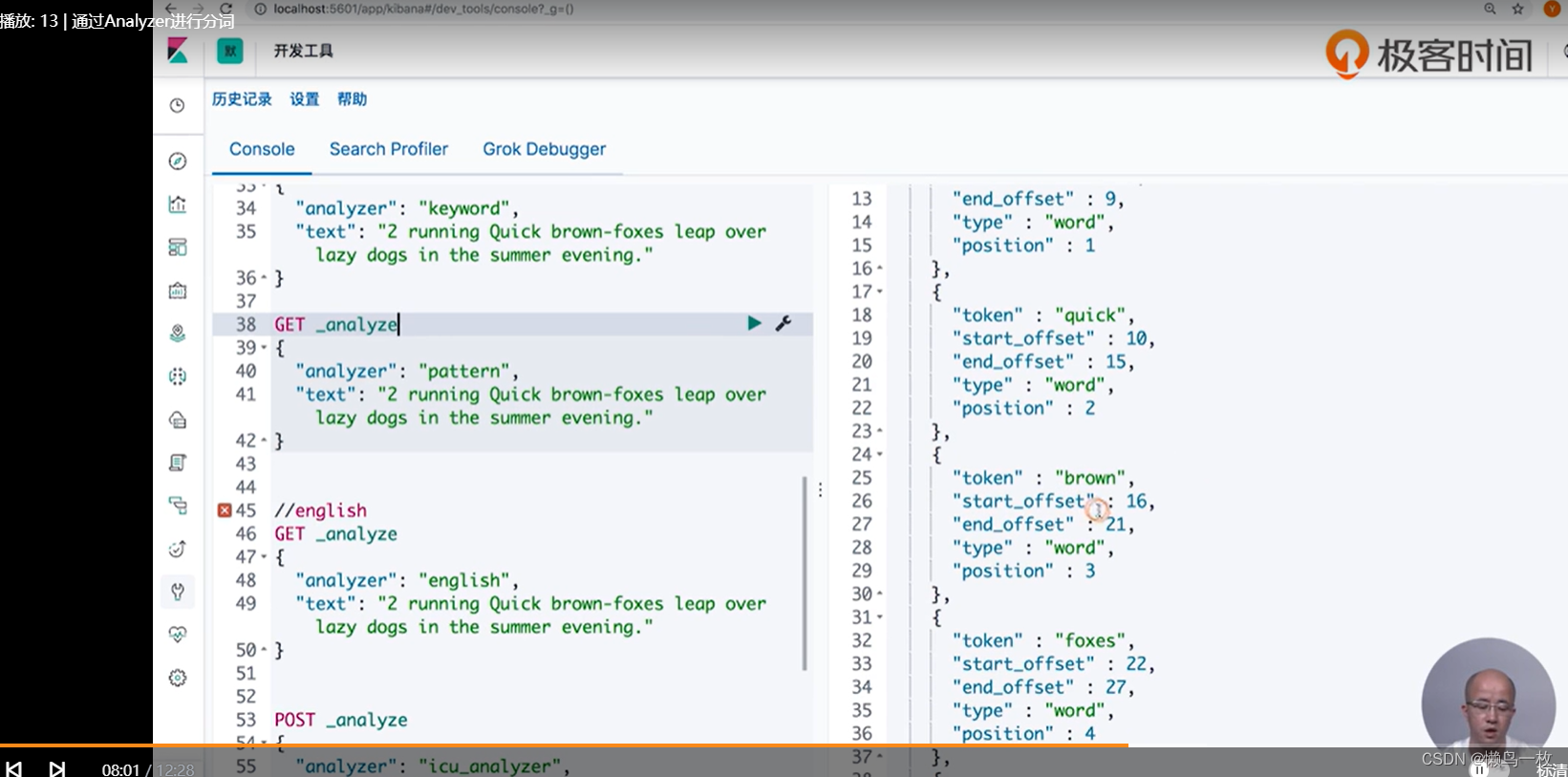
GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#english
GET _analyze
{
"analyzer": "english",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
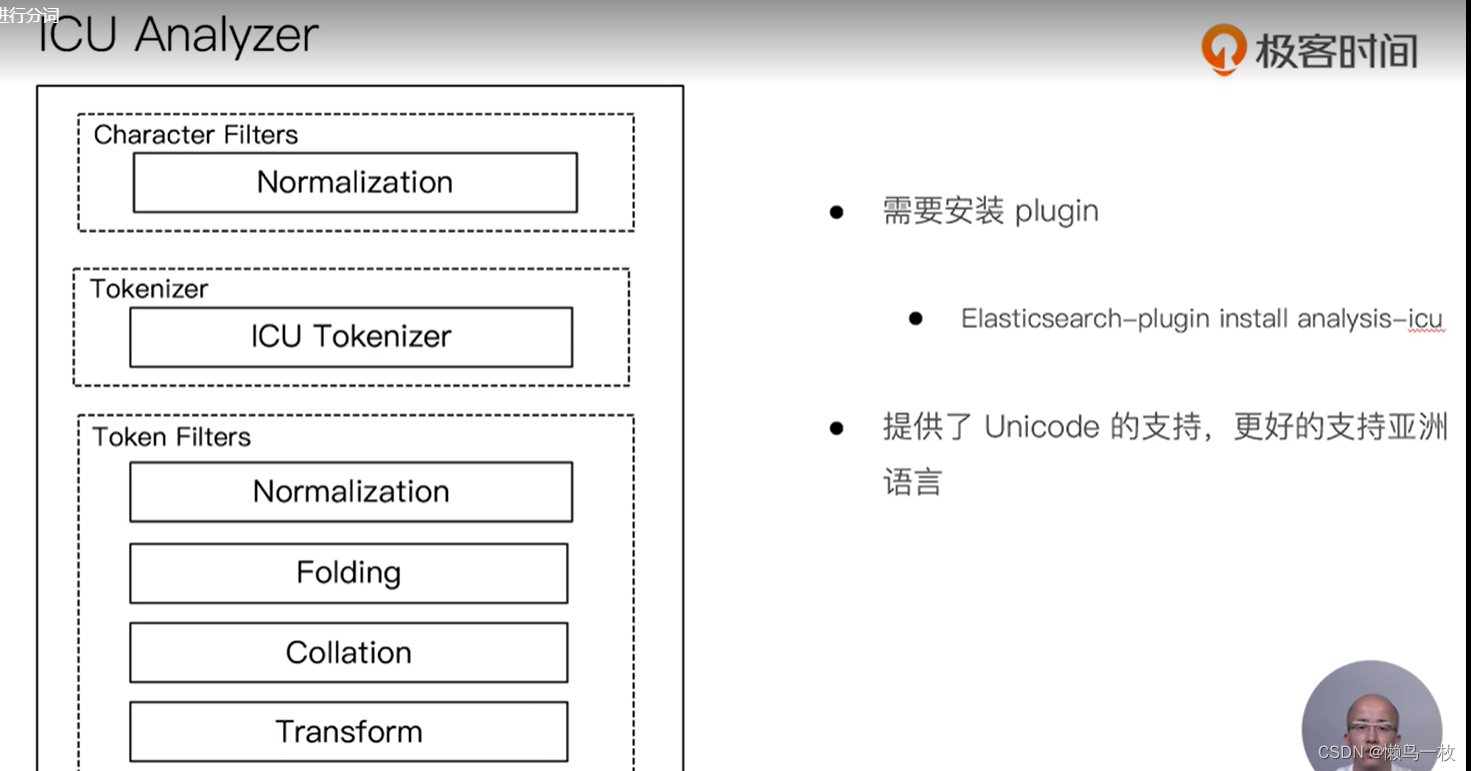
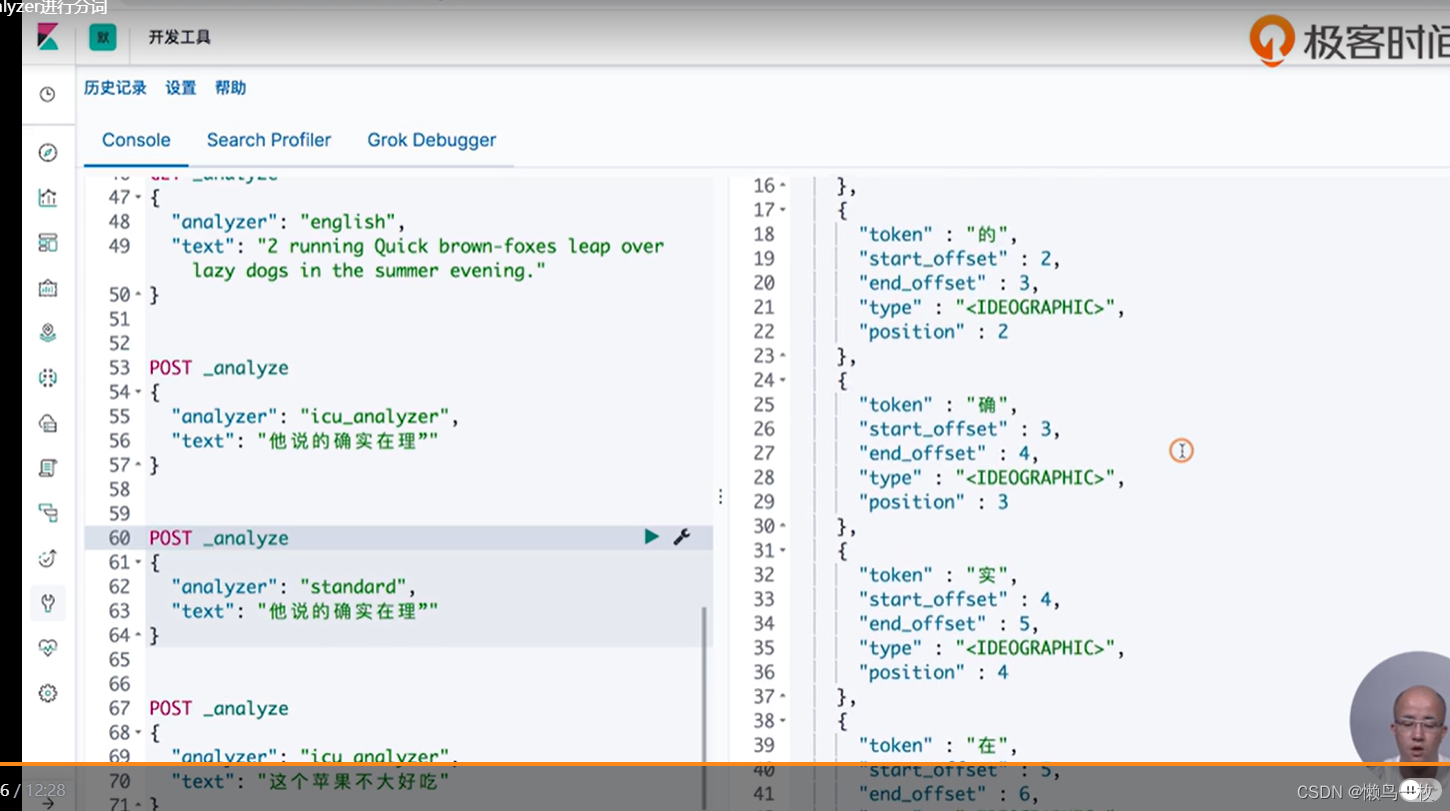
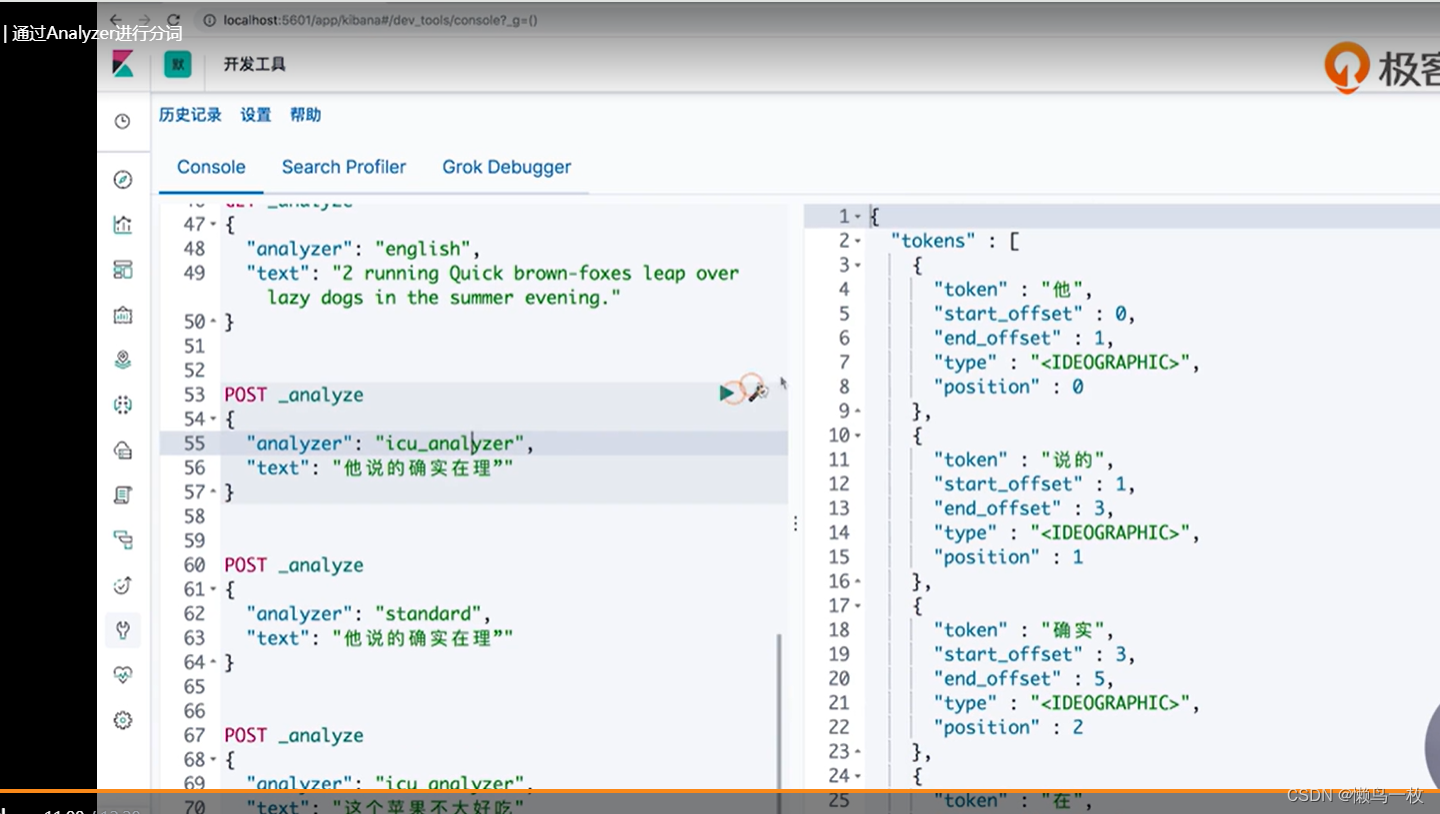
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "这个苹果不大好吃"
}
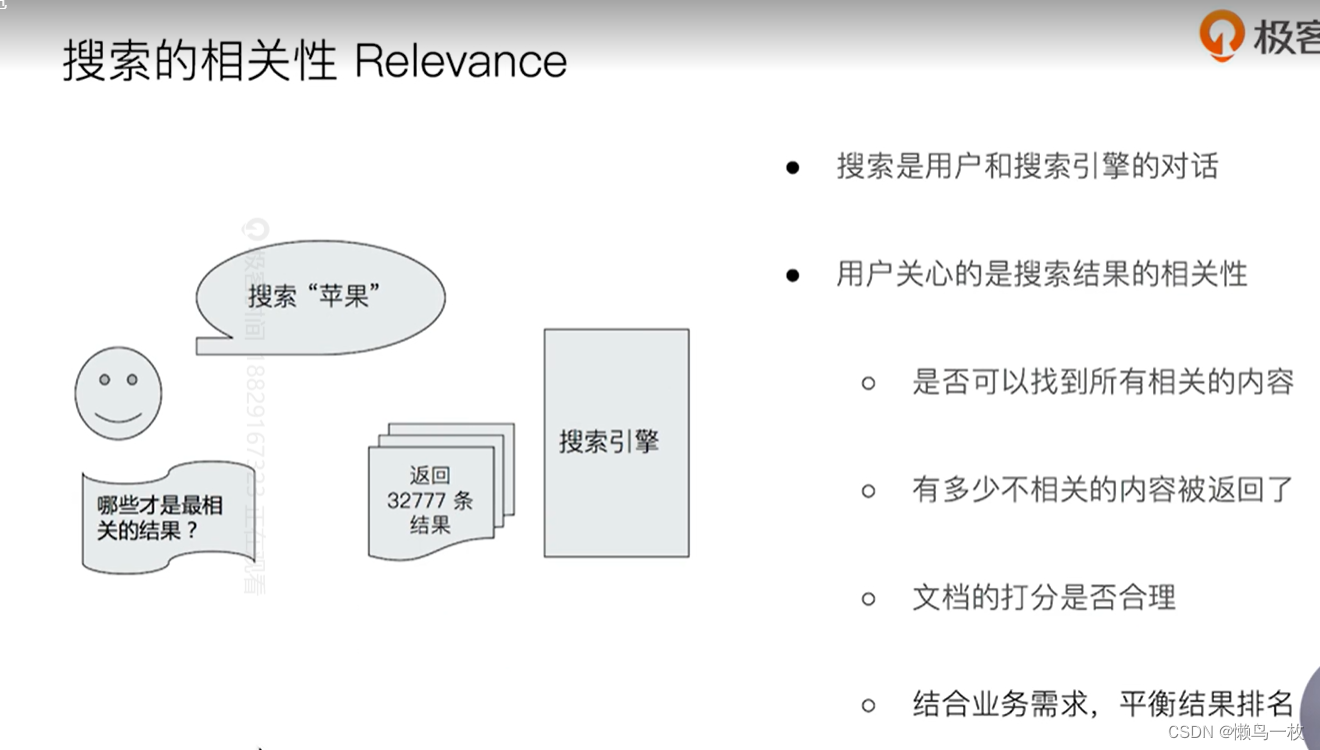
SearchAPI概览


URL 查询

Request Body 查询

查询响应结果
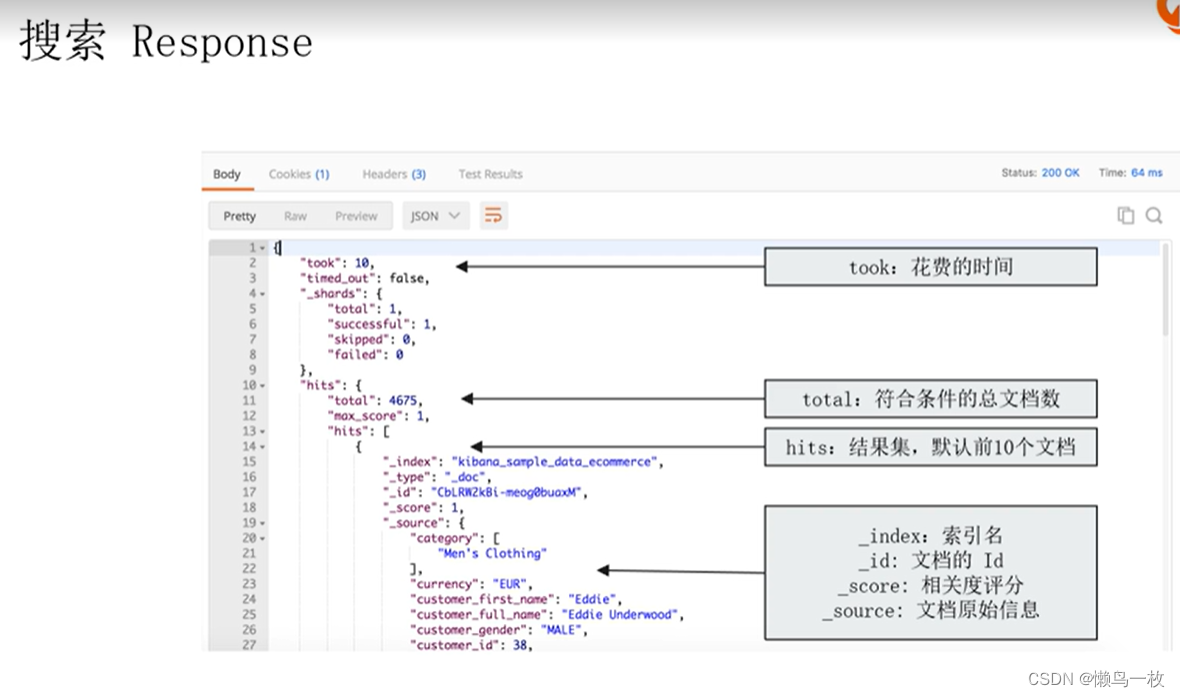

需要通过Kibana导入Sample Data的电商数据。 具体参考“2.2节-Kibana的安装与界面快速浏览”一节教程
#URI Query
GET kibana_sample_data_ecommerce/_search?q=customer_first_name:Eddie
GET kibana*/_search?q=customer_first_name:Eddie
GET /_all/_search?q=customer_first_name:Eddie
#REQUEST Body
POST kibana_sample_data_ecommerce/_search
{
"profile": true,
"query": {
"match_all": {}
}
}
URI Search详解

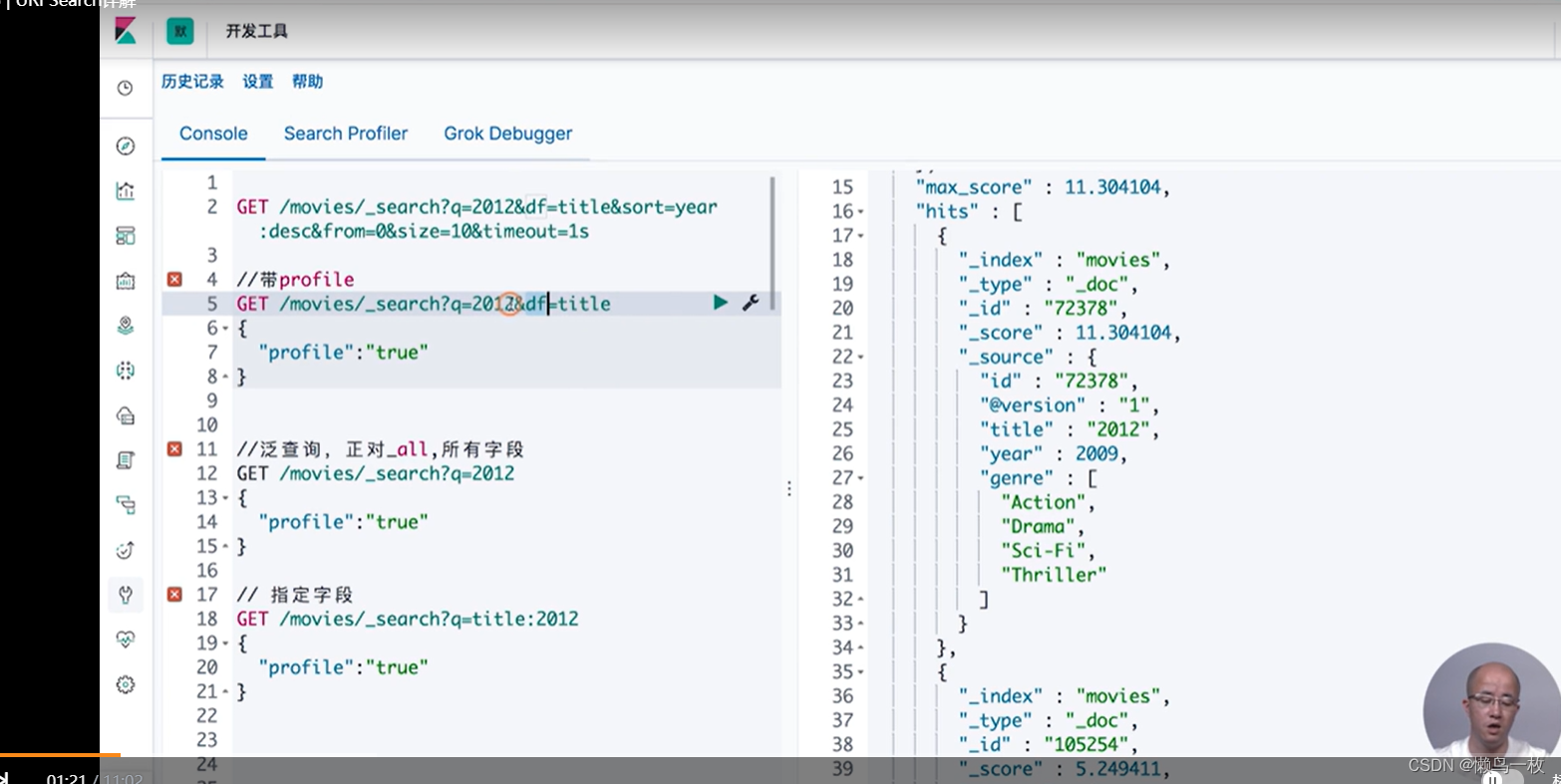
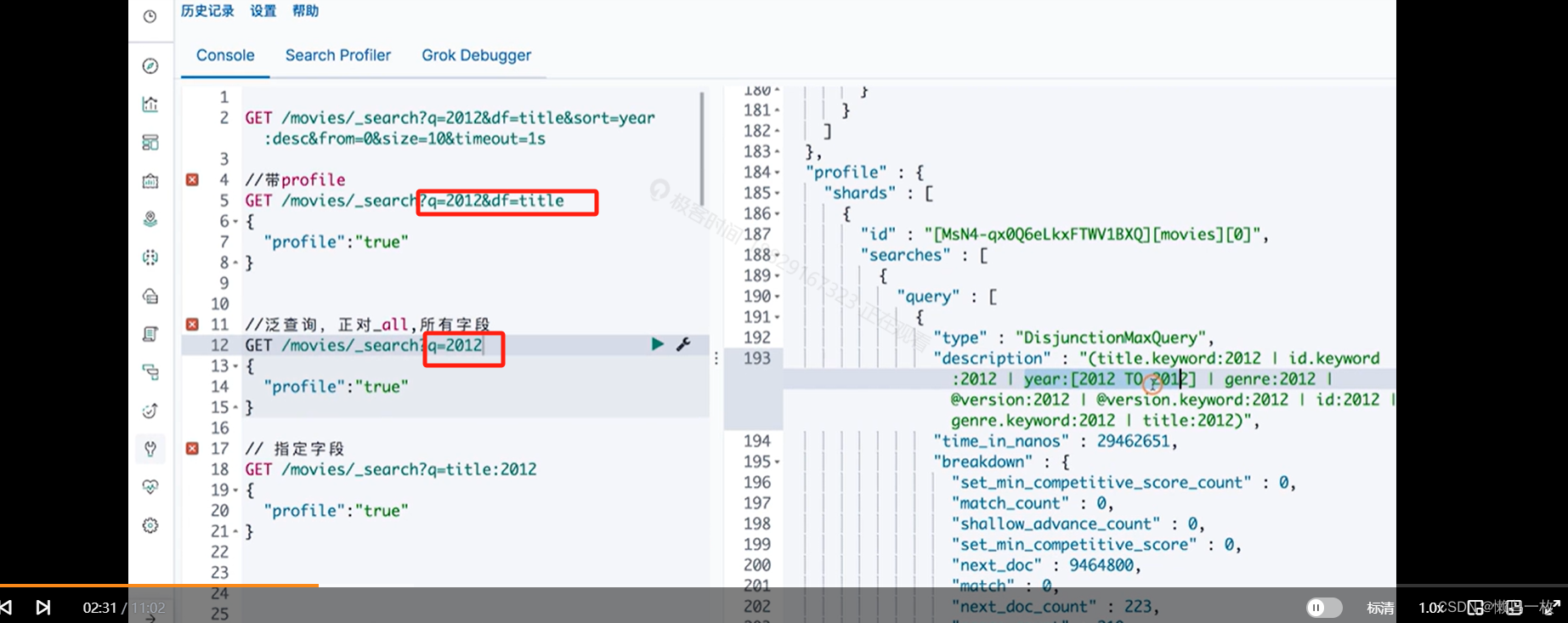
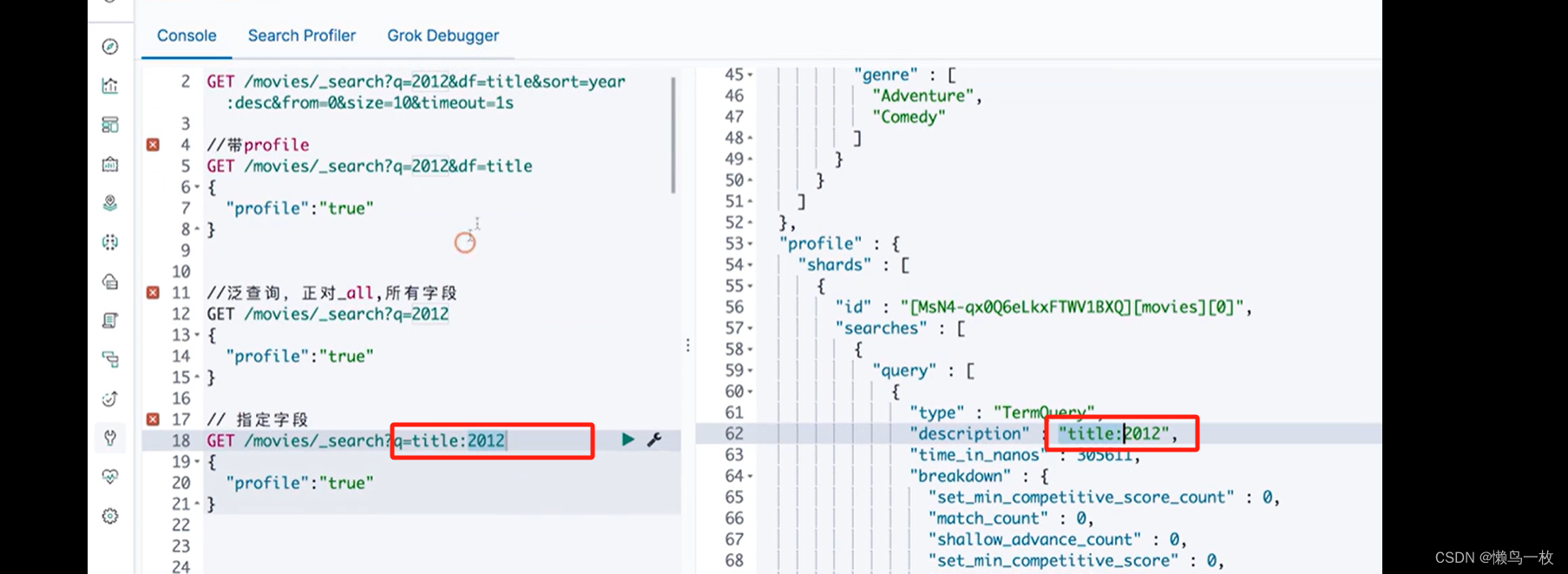
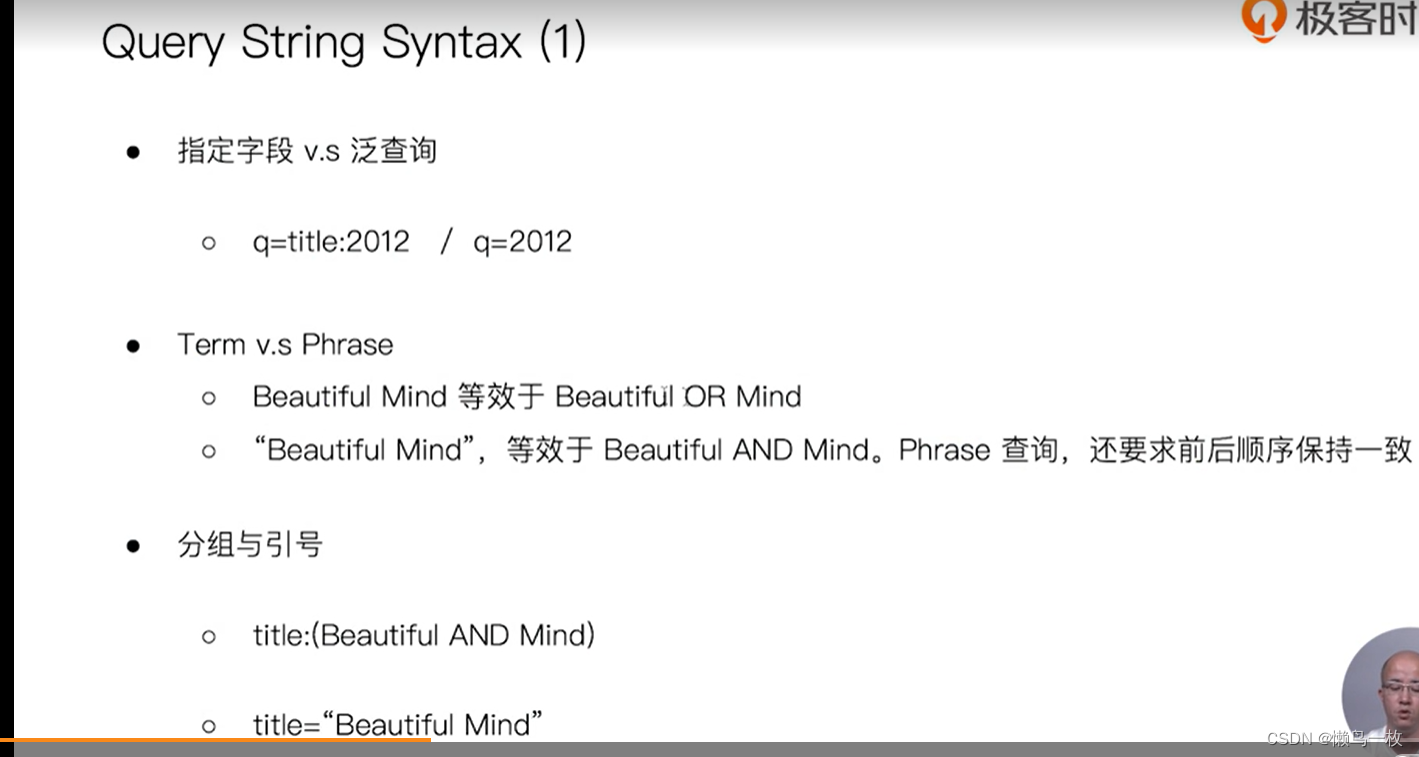
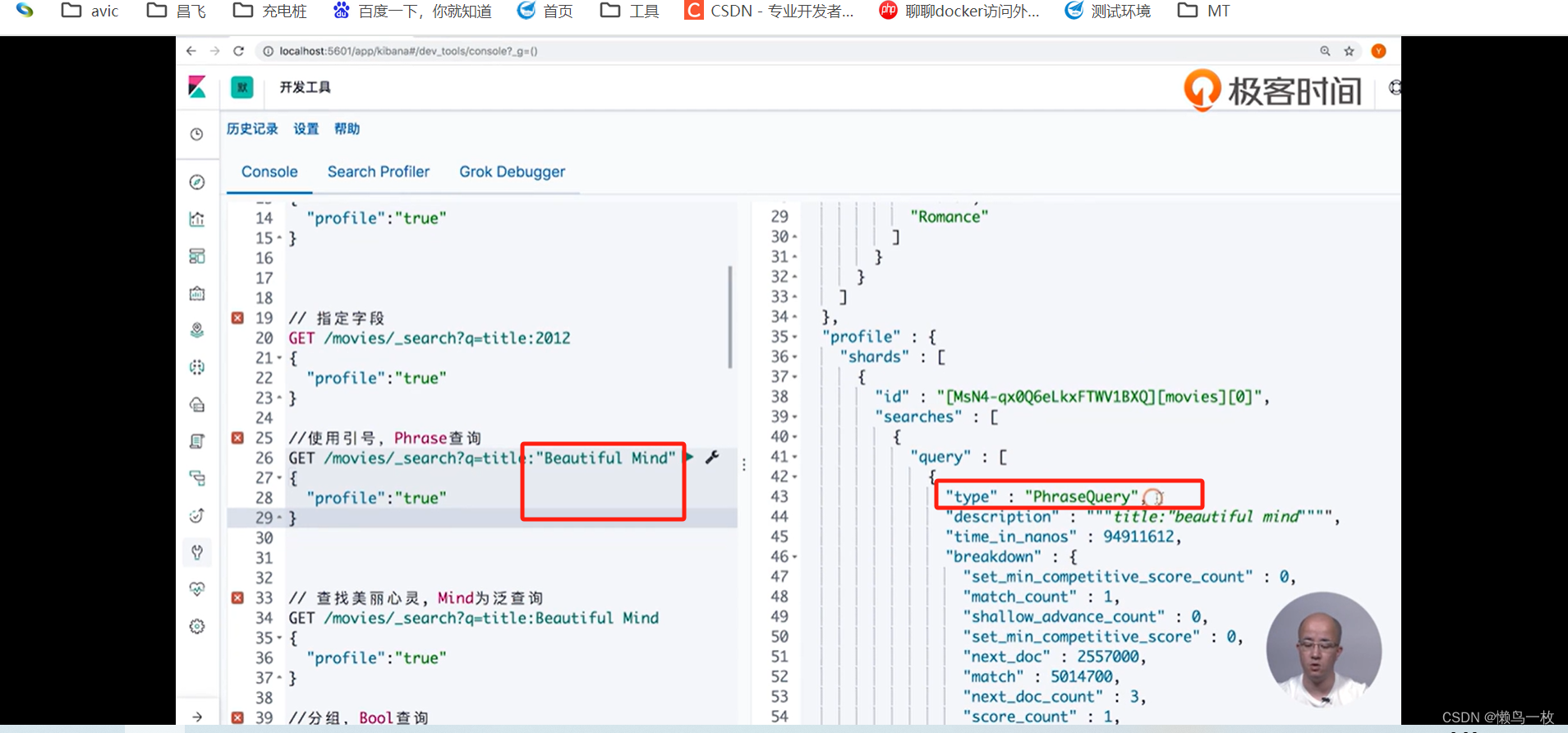
指定df 字段 会对查询字段进行查询,不指定df 字段会对查询的全文进行检索,包括字段和值,符合的都会被查询出来。query 中的 profile 会显示检索的详情
GET /goods/_doc/_search?q=name:dior222
GET /goods/_doc/_search?q=name:chengyi
GET /goods/_doc/_search?q=name:dior222
GET /goods/_doc/_search?q=name:222
GET /goods/_doc/_search?q=name:(chengyi dior222)

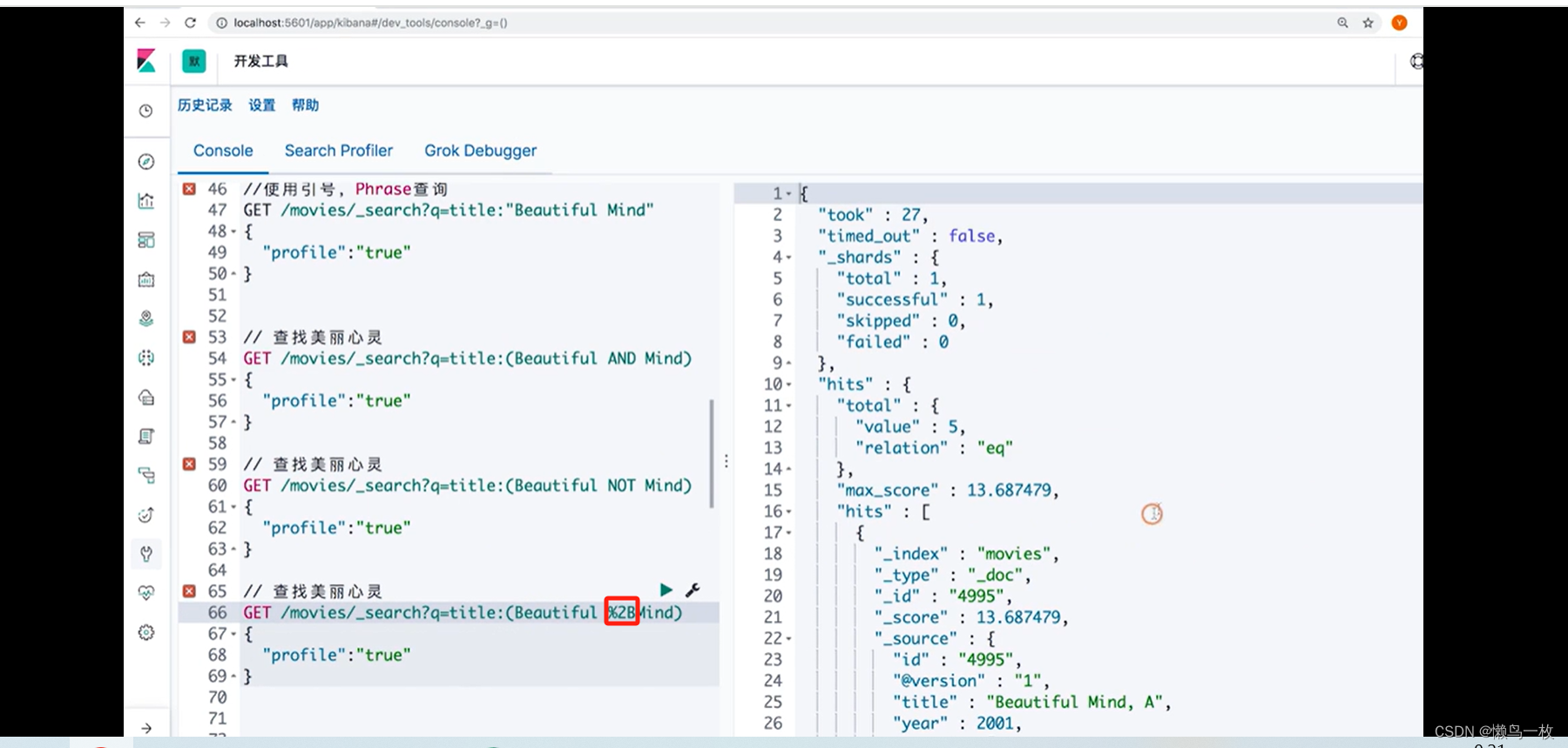
%2B 代表+


- 代表相对位置 ~2 代表相隔 两个位置出现 ,不加~2 代表必须要在相隔的位置出现
课程Demo
#基本查询
GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s
#带profile
GET /movies/_search?q=2012&df=title
{
"profile":"true"
}
#泛查询,正对_all,所有字段
GET /movies/_search?q=2012
{
"profile":"true"
}
#指定字段
GET /movies/_search?q=title:2012&sort=year:desc&from=0&size=10&timeout=1s
{
"profile":"true"
}
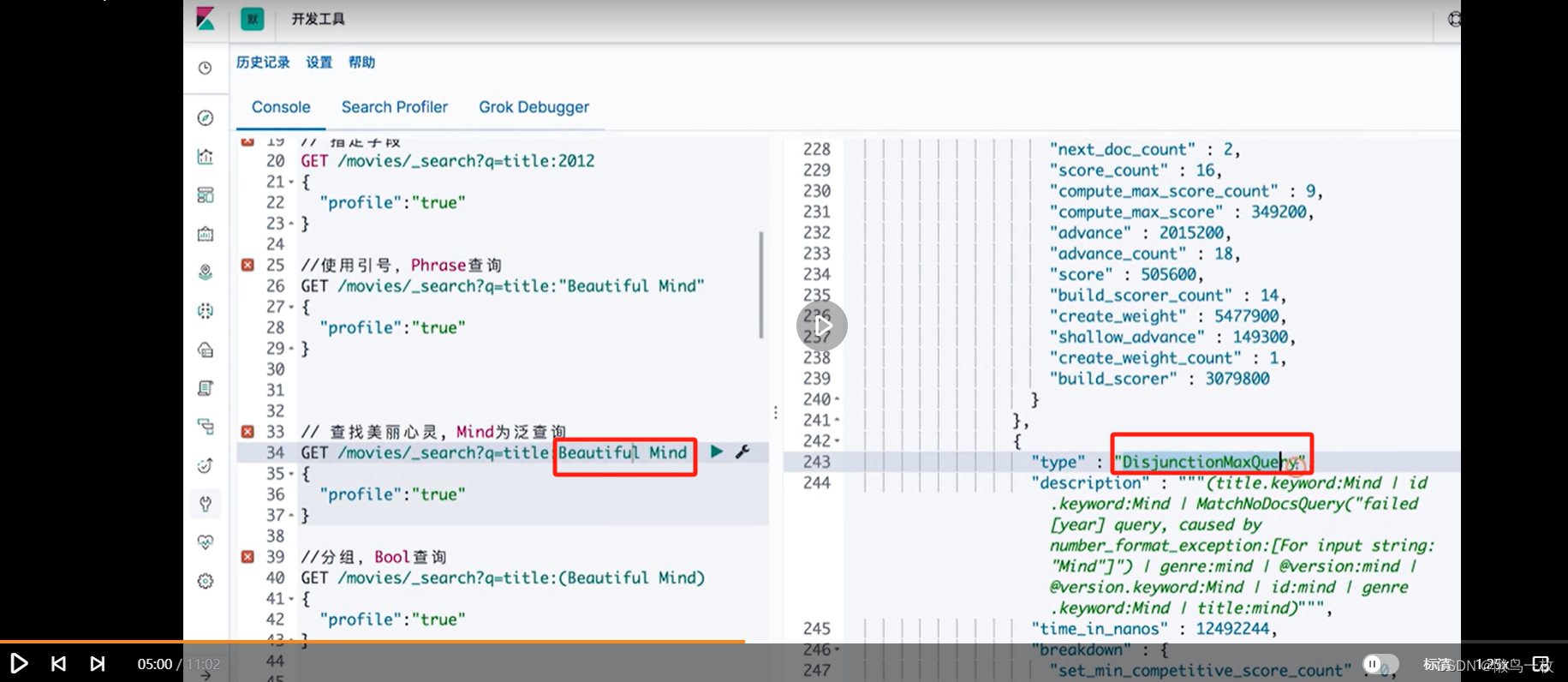
# 查找美丽心灵, Mind为泛查询
GET /movies/_search?q=title:Beautiful Mind
{
"profile":"true"
}
# 泛查询
GET /movies/_search?q=title:2012
{
"profile":"true"
}
#使用引号,Phrase查询
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile":"true"
}
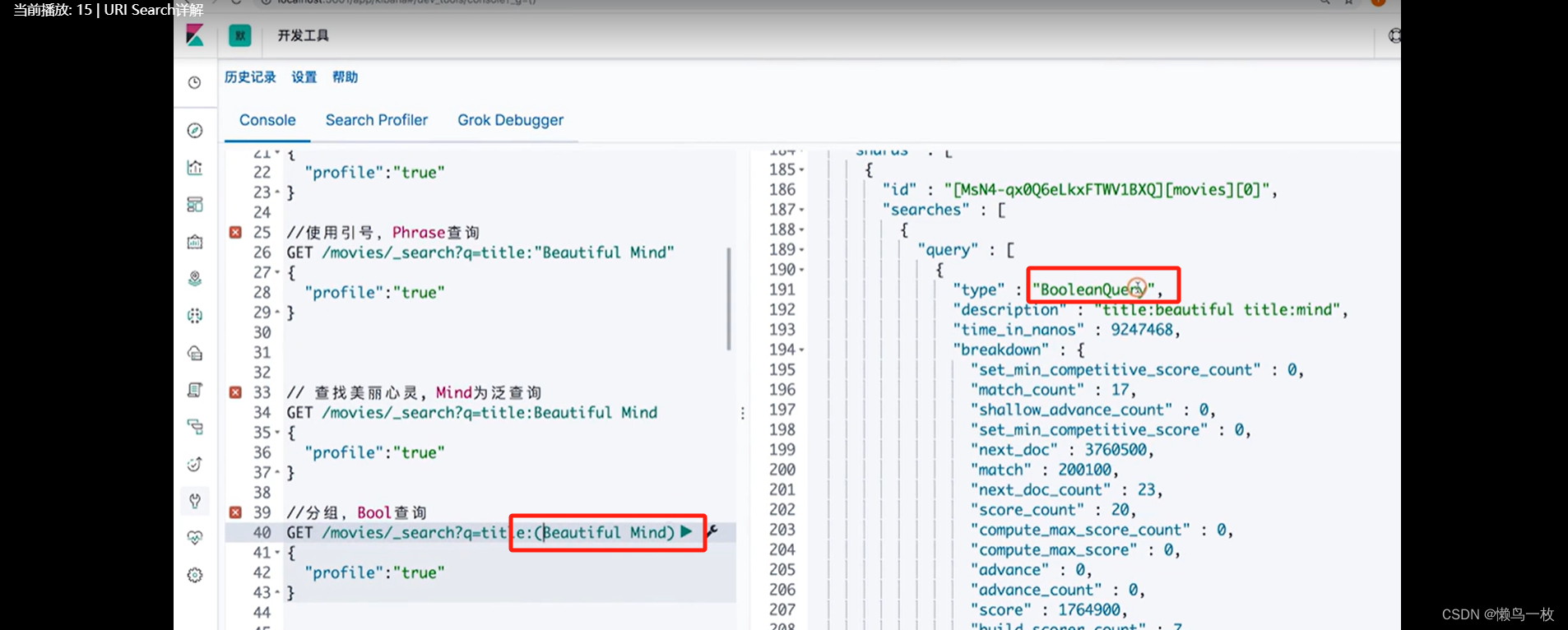
#分组,Bool查询
GET /movies/_search?q=title:(Beautiful Mind)
{
"profile":"true"
}
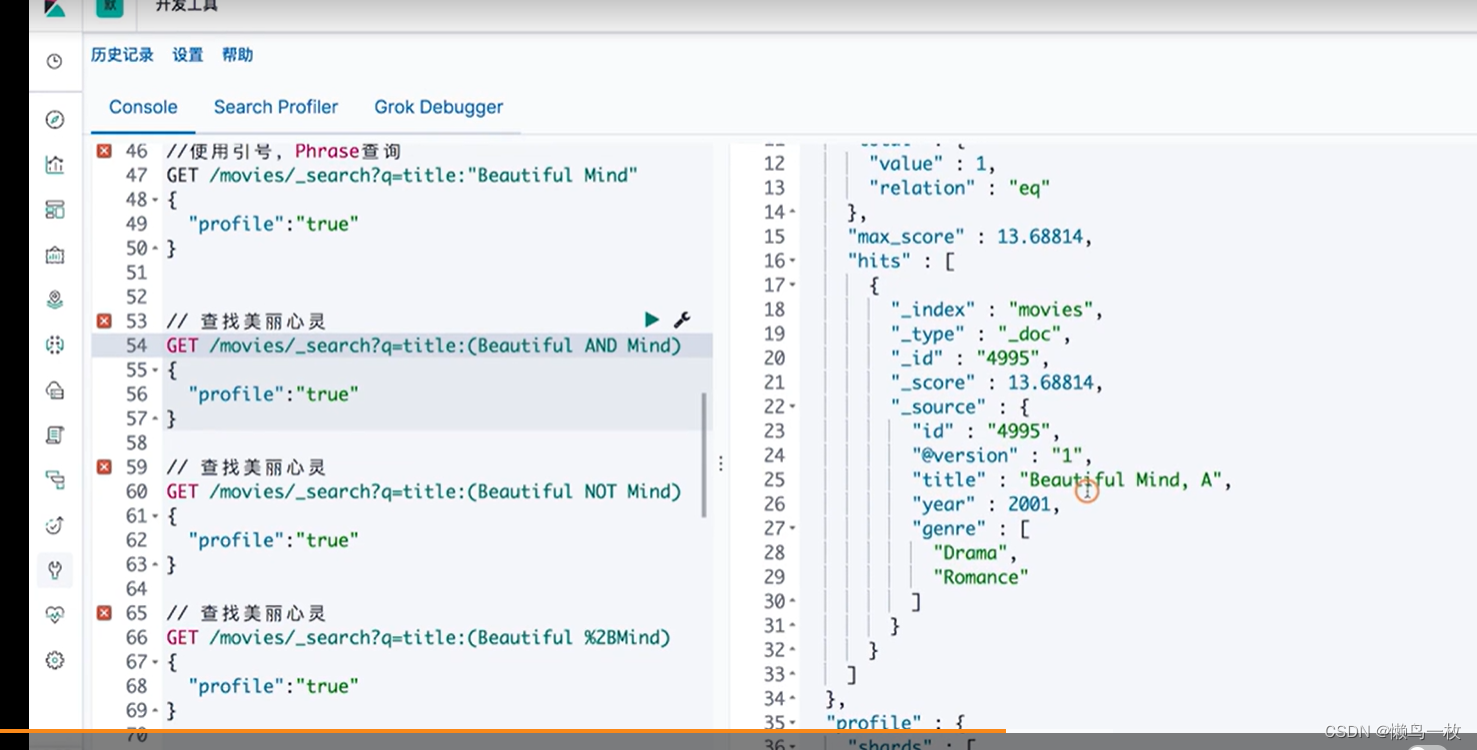
#布尔操作符
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful AND Mind)
{
"profile":"true"
}
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful NOT Mind)
{
"profile":"true"
}
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful %2BMind)
{
"profile":"true"
}
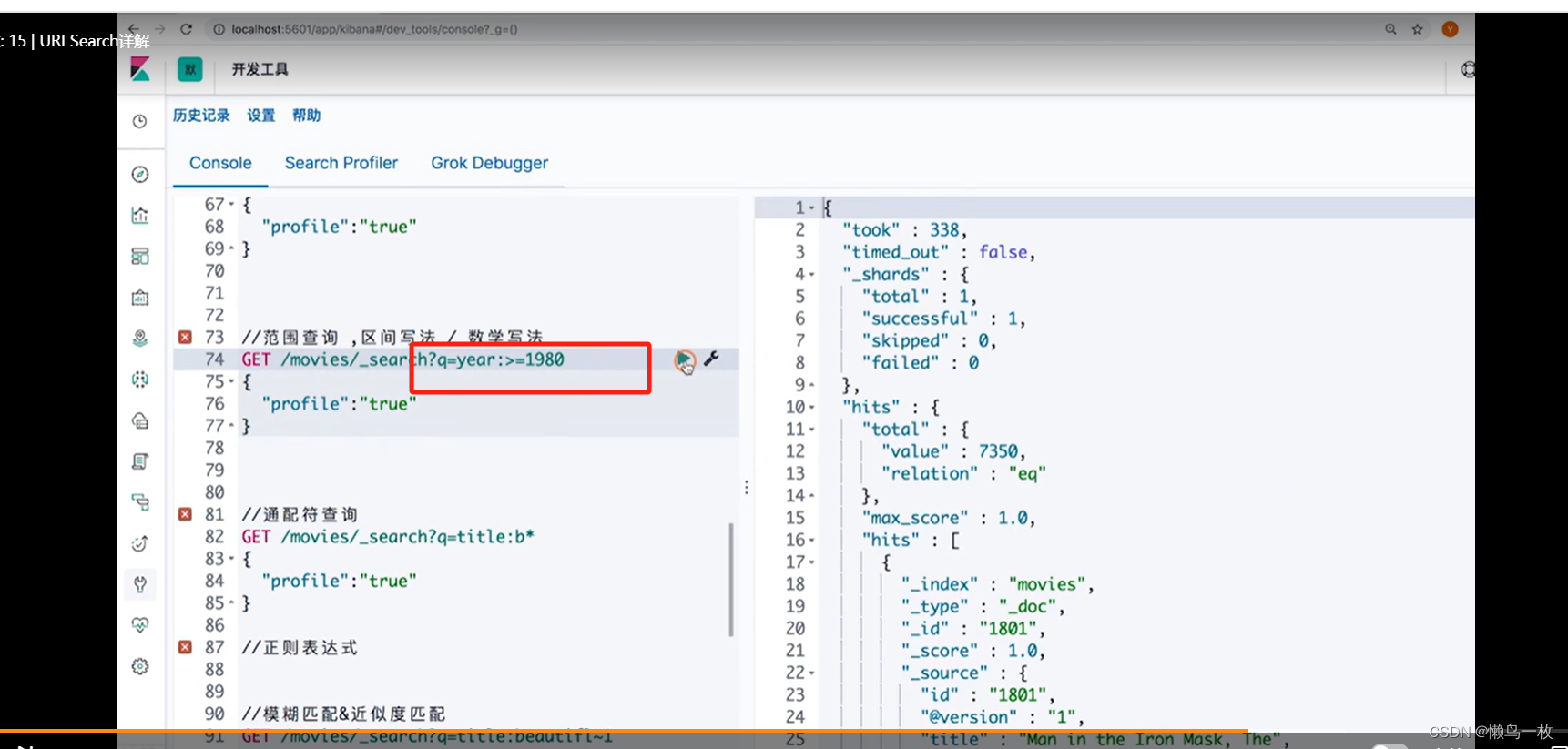
#范围查询 ,区间写法
GET /movies/_search?q=title:beautiful AND year:[2002 TO 2018%7D
{
"profile":"true"
}
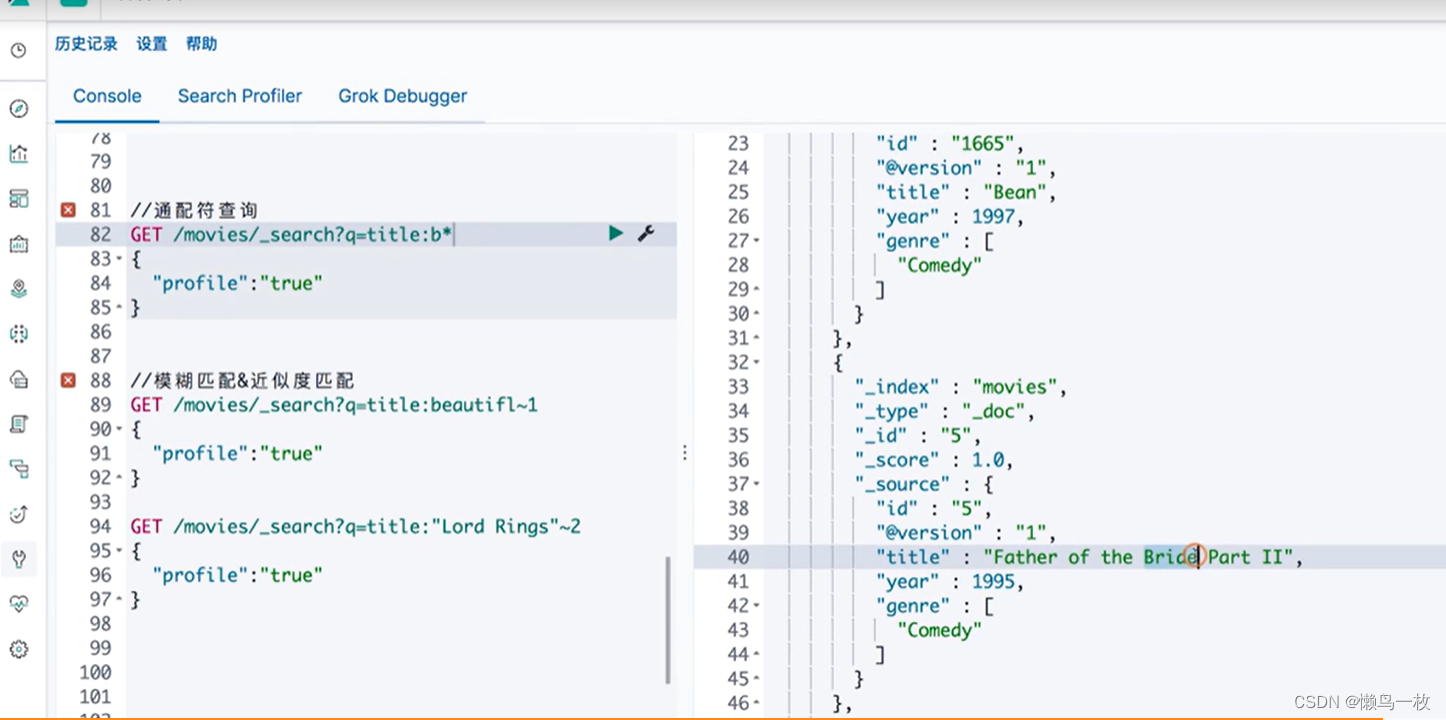
#通配符查询
GET /movies/_search?q=title:b*
{
"profile":"true"
}
//模糊匹配&近似度匹配
GET /movies/_search?q=title:beautifl~1
{
"profile":"true"
}
GET /movies/_search?q=title:"Lord Rings"~2
{
"profile":"true"
}