运行过程
-
逻辑图
-
是什么 怎么生成 具体怎么生成
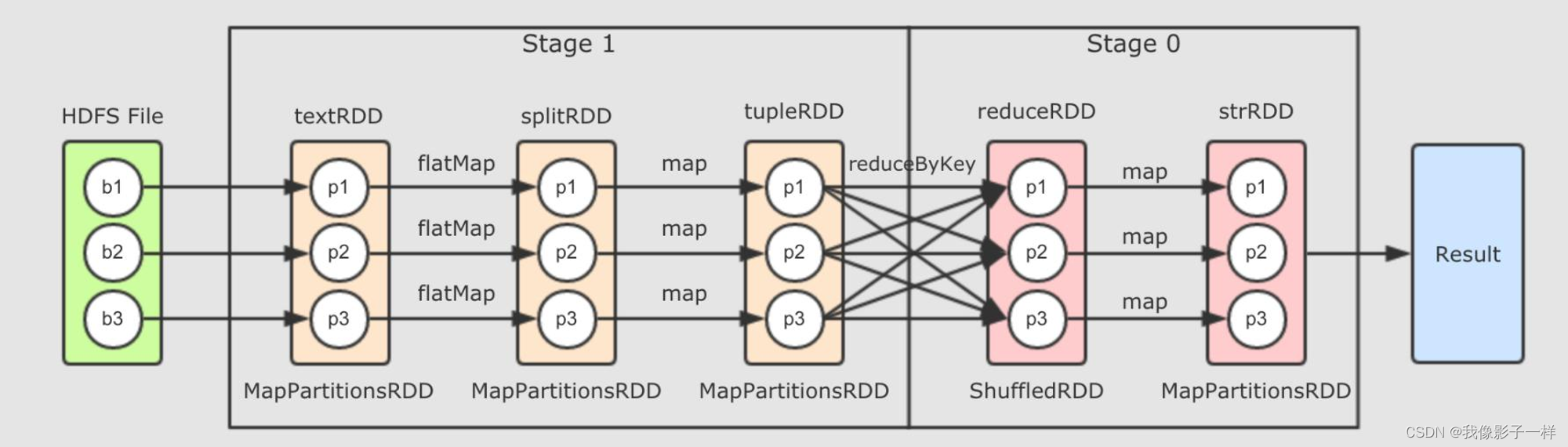
val textRDD = sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop")) val splitRDD = textRDD.flatMap(_.split(" ")) val tupleRDD = splitRDD.map((_, 1)) val reduceRDD = tupleRDD.reduceByKey(_ + _) val strRDD = reduceRDD.map(item => s"${item._1}, ${item._2}") -
逻辑图如何生成
上述代码在 Spark Application 的 main 方法中执行, 而 Spark Application 在 Driver 中执行, 所以上述代码在 Driver 中被执行, 那么这段代码执行的结果是什么呢?
一段 Scala 代码的执行结果就是最后一行的执行结果, 所以上述的代码, 从逻辑上执行结果就是最后一个 RDD, 最后一个 RDD 也可以认为就是逻辑执行图, 为什么呢?
例如 rdd2 = rdd1.map(…) 中, 其实本质上 rdd2 是一个类型为 MapPartitionsRDD 的对象, 而创建这个对象的时候, 会通过构造函数传入当前 RDD 对象, 也就是父 RDD, 也就是调用 map 算子的 rdd1, rdd1 是 rdd2 的父 RDD

一个 RDD 依赖另外一个 RDD, 这个 RDD 又依赖另外的 RDD, 一个 RDD 可以通过 getDependency 获得其父 RDD, 这种环环相扣的关系, 最终从最后一个 RDD 就可以推演出前面所有的 RDD
-
逻辑图是什么, 干啥用
逻辑图其实本质上描述的就是数据的计算过程, 数据从哪来, 经过什么样的计算, 得到什么样的结果, 再执行什么计算, 得到什么结果
可是数据的计算是描述好了, 这种计算该如何执行呢? 接下面物理图
-
-
物理图
-
数据的计算表示好了, 该正式执行了, 但是如何执行? 如何执行更快更好更酷? 就需要为其执行做一个规划, 所以需要生成物理执行图
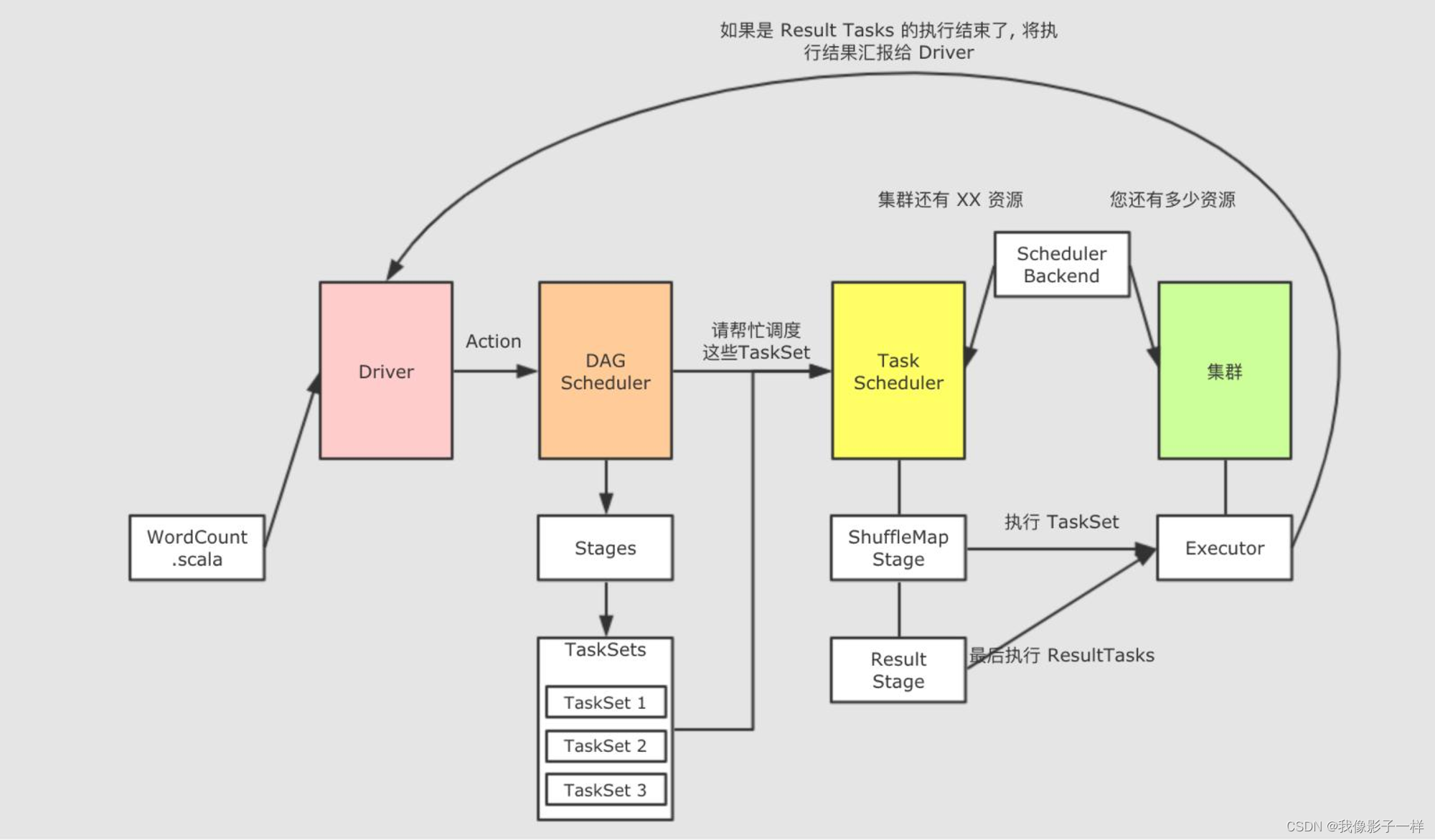
strRDD.collect.foreach(item => println(item))上述代码其实就是最后的一个 RDD 调用了 Action 方法, 调用 Action 方法的时候, 会请求一个叫做 DAGScheduler 的组件, DAGScheduler 会创建用于执行 RDD 的 Stage 和 Task
DAGScheduler 是一个由 SparkContext 创建, 运行在 Driver 上的组件, 其作用就是将由 RDD 构建出来的逻辑计划, 构建成为由真正在集群中运行的 Task 组成的物理执行计划, DAGScheduler 主要做如下三件事
- 帮助每个 Job 计算 DAG 并发给 TaskSheduler 调度
- 确定每个 Task 的最佳位置
- 跟踪 RDD 的缓存状态, 避免重新计算
从字面意思上来看, DAGScheduler 是调度 DAG 去运行的, DAG 被称作为有向无环图, 其实可以将 DAG 理解为就是 RDD 的逻辑图, 其呈现两个特点: RDD 的计算是有方向的, RDD 的计算是无环的, 所以 DAGScheduler 也可以称之为 RDD Scheduler, 但是真正运行在集群中的并不是 RDD, 而是 Task 和 Stage, DAGScheduler 负责这种转换
-
-
Job是什么
Job 什么时候生成 ?
当一个 RDD 调用了 Action 算子的时候, 在 Action 算子内部, 会使用 sc.runJob() 调用 SparkContext 中的 runJob 方法, 这个方法又会调用 DAGScheduler 中的 runJob, 后在 DAGScheduler 中使用消息驱动的形式创建 Job
简而言之, Job 在 RDD 调用 Action 算子的时候生成, 而且调用一次 Action 算子, 就会生成一个 Job, 如果一个 SparkApplication 中调用了多次 Action 算子, 会生成多个 Job 串行执行, 每个 Job 独立运作, 被独立调度, 所以 RDD 的计算也会被执行多次
Job 是什么 ?
如果要将 Spark 的程序调度到集群中运行, Job 是粒度最大的单位, 调度以 Job 为最大单位, 将 Job 拆分为 Stage 和 Task 去调度分发和运行, 一个 Job 就是一个 Spark 程序从 读取 → 计算 → 运行 的过程
一个 Spark Application 可以包含多个 Job, 这些 Job 之间是串行的, 也就是第二个 Job 需要等待第一个 Job 的执行结束后才会开始执行
-
Job 和 Stage 的关系
Job 是一个最大的调度单位, 也就是说 DAGScheduler 会首先创建一个 Job 的相关信息, 后去调度 Job, 但是没办法直接调度 Job, 比如说现在要做一盘手撕包菜, 不可能直接去炒一整颗包菜, 要切好撕碎, 再去炒
为什么 Job 需要切分 ?
- 因为 Job 的含义是对整个 RDD 血统求值, 但是 RDD 之间可能会有一些宽依赖 (Job太大,所以要切分)
- 如果遇到宽依赖的话, 两个 RDD 之间需要进行数据拉取和复制如果要进行拉取和复制的话, 那么一个 RDD 就必须等待它所依赖的 RDD 所有分区先计算完成, 然后再进行拉取
- 由上得知, 一个 Job 是无法计算完整个 RDD 血统的
如何切分 ?
创建一个 Stage, 从后向前回溯 RDD, 遇到 Shuffle 依赖就结束 Stage, 后创建新的 Stage 继续回溯. 这个过程上面已经详细的讲解过, 但是问题是切分以后如何执行呢, 从后向前还是从前向后, 是串行执行多个 Stage, 还是并行执行多个 Stage
问题一: 执行顺序
在图中, Stage 0 的计算需要依赖 Stage 1 的数据, 因为 reduceRDD 中一个分区可能需要多个 tupleRDD 分区的数据, 所以 tupleRDD 必须先计算完, 所以, 应该在逻辑图中自左向右执行 Stage
问题二: 串行还是并行
还是同样的原因, Stage 0 如果想计算, Stage 1 必须先计算完, 因为 Stage 0 中每个分区都依赖 Stage 1 中的所有分区, 所以 Stage 1 不仅需要先执行, 而且 Stage 1 执行完之前 Stage 0 无法执行, 它们只能串行执行
注意: Stage 1先执行,所以WebUI 先是Stage 0,然后再调度Stage0
-
Stage 和 Task 的关系
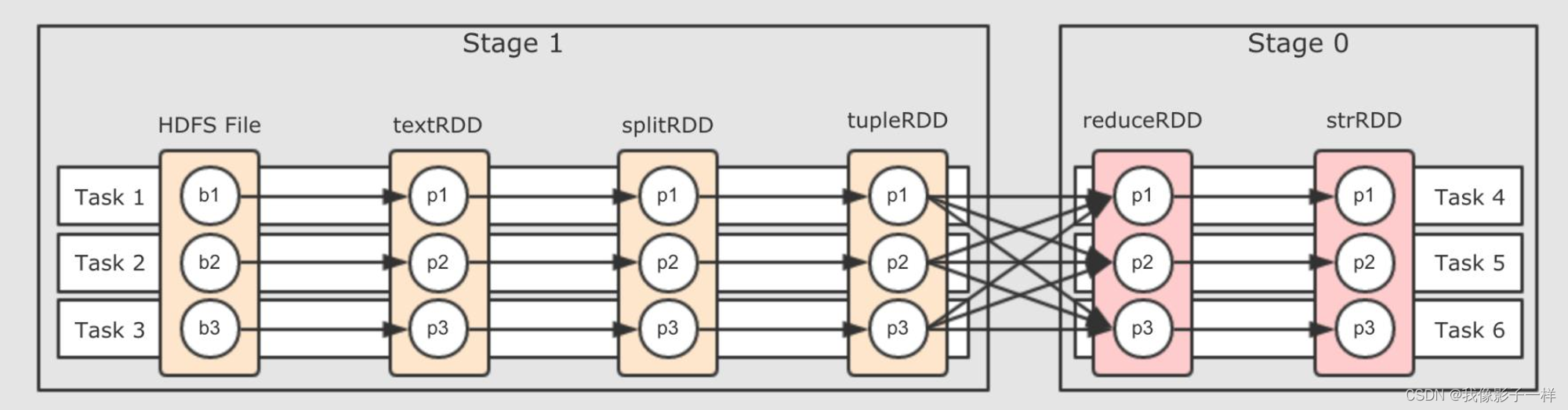
前面我们说到 Job 无法直接执行, 需要先划分为多个 Stage, 去执行 Stage, 那么 Stage 可以直接执行吗?
-
第一点: Stage 中的 RDD 之间是窄依赖
因为 Stage 中的所有 RDD 之间都是窄依赖, 窄依赖 RDD 理论上是可以放在同一个 Pipeline(管道, 流水线) 中执行的, 似乎可以直接调度 Stage 了? 其实不行, 看第二点
-
第二点: 别忘了 RDD 还有分区
一个 RDD 只是一个概念, 而真正存放和处理数据时, 都是以分区作为单位的
Stage 对应的是多个整体上的 RDD, 而真正的运行是需要针对 RDD 的分区来进行的
-
第三点: 一个 Task 对应一个 RDD 的分区
一个比 Stage 粒度更细的单元叫做 Task, Stage 是由 Task 组成的, 之所以有 Task 这个概念, 是因为 Stage 针对整个 RDD, 而计算的时候, 要针对 RDD 的分区
假设一个 Stage 中有 10 个 RDD, 这些 RDD 中的分区各不相同, 但是分区最多的 RDD 有 30 个分区, 而且很显然, 它们之间是窄依赖关系
那么, 这个 Stage 中应该有多少 Task 呢? 应该有 30 个 Task, 因为一个 Task 计算一个 RDD 的分区. 这个 Stage 至多有 30 个分区需要计算
总结
- 一个 Stage 就是一组并行的 Task 集合
- Task 是 Spark 中最小的独立执行单元, 其作用是处理一个 RDD 分区
- 一个 Task 只可能存在于一个 Stage 中, 并且只能计算一个 RDD 的分区
-
-
TaskSet
梳理一下这几个概念, Job > Stage > Task, Job 中包含 Stage 中包含 Task
而 Stage 中经常会有一组 Task 需要同时执行, 所以针对于每一个 Task 来进行调度太过繁琐, 而且没有意义, 所以每个 Stage 中的 Task 们会被收集起来, 放入一个 TaskSet 集合中
- 一个 Stage 有一个 TaskSet
- TaskSet 中 Task 的个数由 Stage 中的最大分区数决定
整体执行流程