SA3D:Segment Anything in 3D with NeRFs
实现了3D目标分割

原理是利用SAM(segment anything) 模型和Nerf分割渲染3D目标,
SAM只能分块,是没有语义标签的,如何做到语义连续?
SA3D中用了self-prompt, 根据前一帧的mask自己给出提示点,用SAM再预测下一帧的mask.
1.准备数据
这里用llff数据的格式。
它需要的input是图像,colmap建好的poses, 训练好的nerf。
通过llff的fern文件夹说明自定义数据怎么准备。
nerf_llff_data/fern文件夹包含如下数据,
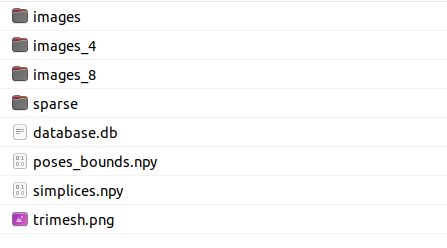
其中images是相机拍摄的原图,size为4032 * 3024,
由于图片太大,于是有了下采样4倍的images_4, 下采样8倍的images_8.
用的时候images_4就可以了。
sparse和database.db 是colmap生成的相机内外参,colmap怎么用参考其他。
poses_bounds.npy由sparse生成,后面会说。
最后2个用不到。
1.1 拍摄图片或视频
图片的话按照llff github 上的要求,
根据经验,您应该使用视图之间最大视差不超过约 64 像素的图像(观察距离相机最近的物体,不要让它移动超过视图之间水平视场的 1/8)。图片)。我们的数据集通常包含 20-30 张以粗略网格模式手持拍摄的图像。
最好是网格状拍。

如果拍的是视频,把视频转为图片序列。
把images里面拍到的图片下采样4倍,存入images_4文件夹。
1.2 生成pose
自己安装colmap. 或者用llff github 上的imgs2poses.py。
这里用colmap生成。
colmap选Reconstruction -> Automatic Reconstruction.
只需要填workspace folder和image folder.
image folder要选images,而不是images_4.
Dense model的勾可以去掉,节省时间。
然后run, 你就会得到sparse文件夹。
然后你需要用这里的pose_utils.py生成poses_bounds.npy.
需要下载这3个文件。

2.训练模型
2.1 训练nerf
设置文件:
configs/llff/fern.py
configs/liff/seg_fern.py
调整factor需要的文件
configs/llff/llff_default.py
configs/default.py
configs/llff/llff_seg_default.py
configs/seg_default.py
上面这些设置文件可以修改了直接用,也可以新建类似的。
2个设置文件中修改数据集的路径。
如果你不用下采样4倍的图片,比如要用下采样8倍的,
在后面4个文件中,把factor置8. 如果用原图,factor=1.
训练nerf
python run.py --config=configs/llff/fern.py --stop_at=20000 --render_video --i_weights=10000
你可能会遇到sam3d.py中的bug,
UnboundLocalError: local variable ‘sam_model_registry’ referenced before assignment
解决方法,修改sam3d.py,
class Sam3D(ABC):
'''TODO, add discription'''
def __init__(self, args, cfg, xyz_min, xyz_max, cfg_model, cfg_train, \
data_dict, device=torch.device('cuda'), stage='coarse', coarse_ckpt_path=None):
...
if args.mobile_sam:
...
else:
from segment_anything import sam_model_registry #加上这一句,修复bug
sam_checkpoint = "./dependencies/sam_ckpt/sam_vit_h_4b8939.pth"
...
然后会在log/xx/xx/render_video_fine_last下面得到渲染好的3D场景。
2.2 训练SAM+nerf
python run_seg_gui.py --config=configs/llff/seg/seg_fern.py --segment \
--sp_name=_gui --num_prompts=20 \
--render_opt=train --save_ckpt
会给一个链接,点进webUI,
这第一帧图包括后面训练的图,是上面训练nerf时渲染的图片,
如果你换了数据集,一定要重新训练nerf, 不然这些图片就还是之前的。
在第一帧图上选你要分割的物体。

训练中不需要再标注,SAM本身是没有语义的,为了保持语义的连续性,采用自标注的方法,
不断在mask上产生新标注的点。

分割及渲染结果。