作者:来自 Elastic David Pilato

想象一下,圣诞老人必须向世界上所有的孩子们分发礼物。 他有很多工作要做,他需要保持高效。 他有一份所有孩子的名单,并且知道他们住在哪里。 他很可能会将礼物按区域分组,然后再交付。 但他不会在同一个地方停留太久。 他会丢下礼物然后离开。 他不会等待孩子们打开礼物。 他就会离开。

也许我们可以建议他列出一份他仍然需要访问的城市的清单。 一旦他送出了礼物,他就可以将这些城市从名单中删除。 这样,他就会知道自己还要去哪里。 而且他也不会浪费时间回到同一个地方。
为此,他只需使用他必须访问的城市的 TTL(time to live - 生存时间)即可。 他只需将 TTL 设置为他需要递送礼物的时间即可。 一旦 TTL 过期,他就会从列表中删除这些城市。
他的旅程可能是这样的:
{ "city": "Sidney", "deliver": "ASAP", "ttl": 0 }
{ "city": "Singapore", "deliver": "1 minute", "ttl": 1 }
{ "city": "Vilnius", "deliver": "3 minutes", "ttl": 3 }
{ "city": "Paris", "deliver": "5 minutes", "ttl": 5 }
{ "city": "London", "deliver": "6 minutes", "ttl": 6 }
{ "city": "Montréal", "deliver": "7 minutes", "ttl": 7 }
{ "city": "San Francisco", "deliver": "9 minutes", "ttl": 9 }
{ "city": "North Pole", "deliver": "forever" }ttl 包含我们的 TTL 值(以分钟为单位):
- 没有值意味着该文档将永远保留
- 零意味着我们要尽快删除该文档
- 任何正值都对应于删除文档之前需要等待的分钟数
ttl 摄取管道
要实现这样的功能,你只需要一个摄取管道:
PUT /_ingest/pipeline/ttl
{
"processors": [
{
"set": {
"field": "ingest_date",
"value": "{{{_ingest.timestamp}}}"
}
},
{
"script": {
"lang": "painless",
"source": """
ctx['ttl_date'] = ZonedDateTime.parse(ctx['ingest_date']).plusMinutes(ctx['ttl']);
""",
"if": "ctx?.ttl != null"
}
},
{
"remove": {
"field": [ "ingest_date", "ttl" ],
"ignore_missing": true
}
}
]
}让我们解释一下。
第一个处理器在文档中设置一个临时字段 (ingest_date),然后我们在其中注入执行管道的时间 (_ingest.timestamp),该时间或多或少是索引日期。
然后我们运行一个 painless 脚本:
ctx['ttl_date'] = ZonedDateTime.parse(ctx['ingest_date']).plusMinutes(ctx['ttl']);他的脚本根据 ingest_date 字段中可用的字符串值创建一个 ZonedDateTime java 对象。 然后我们只需调用 plusMinutes 方法并提供 ttl 的值作为参数。 这只会将摄取日期移动几分钟。 我们将结果存储在 ttl_date 新字段中。
请注意,我们需要添加一个条件,仅当 ttl 字段存在时才运行该处理器:
"if": "ctx?.ttl != null"然后,我们只需删除不需要的字段 ingest_date 和可选的 ttl(如果我们不再需要它)。 请注意,出于调试目的,保留 ttl 可能是明智之举。 如果没有设置 ttl,如果丢失,我们也需要忽略它。 这是通过 “ignore_missing”: true 参数完成的。
为了测试这个管道,我们可以使用 simulate API:
POST /_ingest/pipeline/ttl/_simulate?filter_path=docs.doc._source,docs.doc._ingest
{
"docs": [
{
"_source": { "city": "Sidney", "deliver": "ASAP", "ttl": 0 }
},
{
"_source": { "city": "Singapore", "deliver": "1 minute", "ttl": 1 }
},
{
"_source": { "city": "Paris", "deliver": "5 minutes", "ttl": 5 }
},
{
"_source": { "city": "North Pole", "deliver": "forever" }
}
]
}
请注意在上面所显示的时间为 UTC 时间。我在当前的北京时间是下午 14点多。
我们可以看到文档删除的更改日期。
自动创建 ttl_date 字段
我们可以使用 final_pipeline 索引设置将 ttl 管道定义为在实际索引操作之前使用的管道。
PUT /ttl-demo
{
"settings": {
"final_pipeline": "ttl"
},
"mappings": {
"_source": {
"excludes": [
"ttl_date"
]
},
"properties": {
"ttl_date": {
"type": "date"
}
}
}
}你还可以使用 default_pipeline 索引设置,但你需要注意,如果一个用户想要使用用户管道索引文档,则不会调用 ttl 管道,例如:
POST /ttl-demo/_doc?pipeline=my-pipeline
{
"city": "Singapore",
"deliver": "1 minute",
"ttl": 1
}请注意,我们从 _source 字段中删除了 ttl_date 字段。 我们不想将其存储在 _source 字段中,因为它只是一个 “技术 ”字段。
索引文档
我们现在可以注入我们的数据集:
POST /ttl-demo/_bulk
{ "index": {} }
{ "city": "Sidney", "deliver": "ASAP", "ttl": 0 }
{ "index": {} }
{ "city": "Singapore", "deliver": "1 minute", "ttl": 1 }
{ "index": {} }
{ "city": "Vilnius", "deliver": "3 minutes", "ttl": 3 }
{ "index": {} }
{ "city": "Paris", "deliver": "5 minutes", "ttl": 5 }
{ "index": {} }
{ "city": "London", "deliver": "6 minutes", "ttl": 6 }
{ "index": {} }
{ "city": "Montréal", "deliver": "7 minutes", "ttl": 7 }
{ "index": {} }
{ "city": "San Francisco", "deliver": "9 minutes", "ttl": 9 }
{ "index": {} }
{ "city": "North Pole", "deliver": "forever" }删除经过 TTL 处理的文档
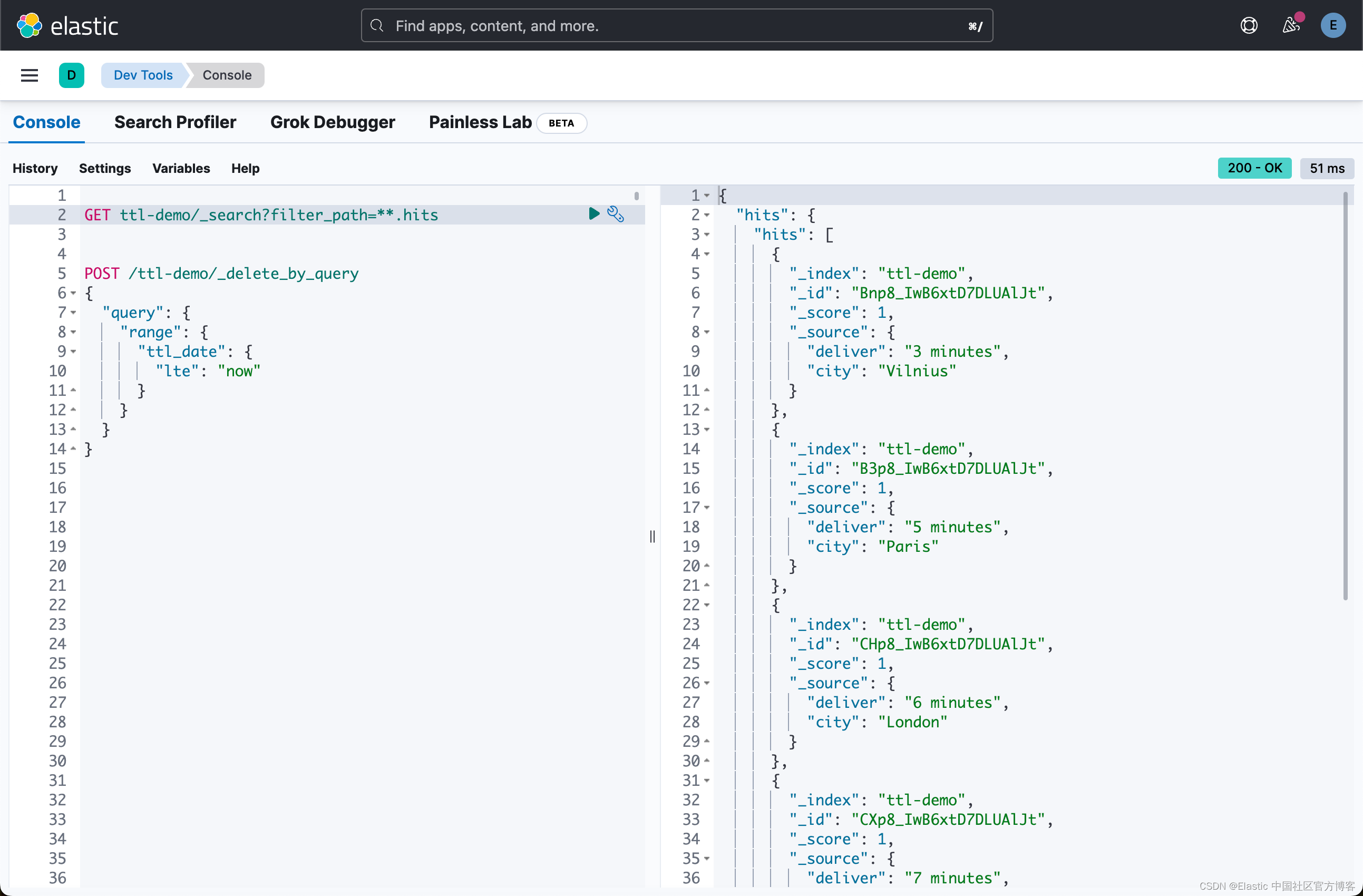
现在可以轻松运行 “Delete By Query” 调用:
POST /ttl-demo/_delete_by_query
{
"query": {
"range": {
"ttl_date": {
"lte": "now"
}
}
}
}我们只想删除所有早于现在(即请求执行时间)的文档。
如果我们立即运行它,我们可以看到只有文档 { "city": "Sidney", "deliver": "ASAP", "ttl": 0 } 被删除。
一分钟后,{ "city": "Singapore”, "deliver": "1 minute", "ttl": 1 }。 再过几分钟,就只剩下 { "city": "North Pole", "deliver": "forever" } 了。 它将永远保留。
使用 Watcher 每分钟运行一次
你可以使用 crontab 每分钟运行一次这样的查询:
* * * * * curl -XPOST -u elastic:changeme https://127.0.0.1:9200/ttl-demo/_delete_by_query -H 'Content-Type: application/json' -d '{"query":{"range":{"ttl_date":{"lte":"now"}}}}'请注意,你必须监视此作业。 但如果你有商业许可证,你也可以使用 Watcher 直接从 Elasticsearch 运行它:
PUT _watcher/watch/ttl
{
"trigger": {
"schedule": {
"interval": "1m"
}
},
"input": {
"simple" : {}
},
"condition": {
"always" : {}
},
"actions": {
"call_dbq": {
"webhook": {
"url": "https://127.0.0.1:9200/ttl-demo/_delete_by_query",
"method": "post",
"body": "{\"query\":{\"range\":{\"ttl_date\":{\"lte\":\"now\"}}}}",
"auth": {
"basic": {
"username": "elastic",
"password": "changeme"
}
}
}
}
}
}请注意,我们使用 interval 参数每分钟运行此操作。 我们使用 Webhook 来调用按查询删除 API。 另请注意,我们需要提供身份验证信息。在上面,你需要根据自己的用户账号修改上面的身份信息。
如果你不是在 cloud.elastic.co 上运行,而是在本地使用自签名证书运行,因为 Elasticsearch 默认情况下是安全的,你需要将 xpack.http.ssl.verification_mode 设置为 none。 否则 Elasticsearch 将不会接受自签名证书。 当然,这只是为了测试目的。 不要在生产中这样做!如果我们不设置这个参数为 none,我们可以看到如下的错误信息:

最多一分钟后,圣诞老人就会看到他必须访问的城市已从列表中删除:
GET /ttl-demo/_search{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "ttl-demo",
"_id": "IBTn-4sBOKvQy-0aU35M",
"_score": 1,
"_source": {
"deliver": "3 minutes",
"city": "Vilnius"
}
},
{
"_index": "ttl-demo",
"_id": "IRTn-4sBOKvQy-0aU35M",
"_score": 1,
"_source": {
"deliver": "5 minutes",
"city": "Paris"
}
},
{
"_index": "ttl-demo",
"_id": "IhTn-4sBOKvQy-0aU35M",
"_score": 1,
"_source": {
"deliver": "6 minutes",
"city": "London"
}
},
{
"_index": "ttl-demo",
"_id": "IxTn-4sBOKvQy-0aU35M",
"_score": 1,
"_source": {
"deliver": "7 minutes",
"city": "Montréal"
}
},
{
"_index": "ttl-demo",
"_id": "JBTn-4sBOKvQy-0aU35M",
"_score": 1,
"_source": {
"deliver": "9 minutes",
"city": "San Francisco"
}
},
{
"_index": "ttl-demo",
"_id": "JRTn-4sBOKvQy-0aU35M",
"_score": 1,
"_source": {
"city": "North Pole",
"deliver": "forever"
}
}
]
}
}到最后,这里就只剩下他的家了:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "ttl-demo",
"_id": "JRTn-4sBOKvQy-0aU35M",
"_score": 1,
"_source": {
"city": "North Pole",
"deliver": "forever"
}
}
]
}
}这是一个简单快速但不够规范的解决方案,用于从 Elasticsearch 集群中删除旧数据。 但请注意,你永远不应该将此技术应用于日志或任何基于时间的索引,或者如果要以这种方式删除的数据量超过数据集的 10%。
相反,你应该更喜欢使用 delete index API 立即删除完整索引,而不是删除整套文档。 这是一种更有效的方式。
删除索引(首选)
为此,我们实际上可以更改管道以将数据发送到名称包含 ttl 日期的索引:
PUT /_ingest/pipeline/ttl
{
"processors": [
{
"set": {
"field": "ingest_date",
"value": "{{{_ingest.timestamp}}}"
}
},
{
"script": {
"lang": "painless",
"source": """
ctx['ttl_date'] = ZonedDateTime.parse(ctx['ingest_date']).plusDays(ctx['ttl']);
""",
"ignore_failure": true
}
},
{
"date_index_name" : {
"field" : "ttl_date",
"index_name_prefix" : "ttl-demo-",
"date_rounding" : "d",
"date_formats": ["yyyy-MM-dd'T'HH:mm:ss.nz"],
"index_name_format": "yyyy-MM-dd",
"if": "ctx?.ttl_date != null"
}
},
{
"set": {
"field" : "_index",
"value": "ttl-demo-forever",
"if": "ctx?.ttl_date == null"
}
},
{
"remove": {
"field": [ "ingest_date", "ttl", "ttl_date" ],
"ignore_missing": true
}
}
]
}在此示例中,我切换到每日索引,因为它比你在生产中看到的要准确得多,因为通常数据不会在几分钟后过期,但会在几天或几个月后过期。有关 date_index_name 的用法,请阅读文章 “Elasticsearch:使用 pipelines 路由文档到想要的 Elasticsearch 索引中去”。
我们更改了脚本以添加天数:
ctx['ttl_date'] = ZonedDateTime.parse(ctx['ingest_date']).plusDays(ctx['ttl']);如果 ttl_date 字段存在,我们使用 date_index_name 处理器根据 ttl_date 字段创建一个新的索引名称。 我们使用 date_rounding 参数将日期四舍五入到当天。 我们使用 index_name_format 参数将日期格式化为 yyyy-MM-dd。 这将使用索引名称,例如 ttl-demo-2023-11-27:
{
"date_index_name" : {
"field" : "ttl_date",
"index_name_prefix" : "ttl-demo-",
"date_rounding" : "d",
"date_formats": ["yyyy-MM-dd'T'HH:mm:ss.nz"],
"index_name_format": "yyyy-MM-dd",
"if": "ctx?.ttl_date != null"
}
}如果 ttl_date 字段不存在,我们只需将索引名称设置为 ttl-demo-forever:
{
"set": {
"field" : "_index",
"value": "ttl-demo-forever",
"if": "ctx?.ttl_date == null"
}
}我们可以重新索引我们的数据集:
POST /ttl-demo/_bulk?pipeline=ttl
{ "index": {} }
{ "city": "Sidney", "deliver": "ASAP", "ttl": 0 }
{ "index": {} }
{ "city": "Singapore", "deliver": "1 day", "ttl": 1 }
{ "index": {} }
{ "city": "Vilnius", "deliver": "3 days", "ttl": 3 }
{ "index": {} }
{ "city": "Paris", "deliver": "5 days", "ttl": 5 }
{ "index": {} }
{ "city": "North Pole", "deliver": "forever" }我们可以看到这些文档现在位于不同的索引中:
GET /ttl-demo-*/_search?filter_path=hits.hits._index,hits.hits._source.deliver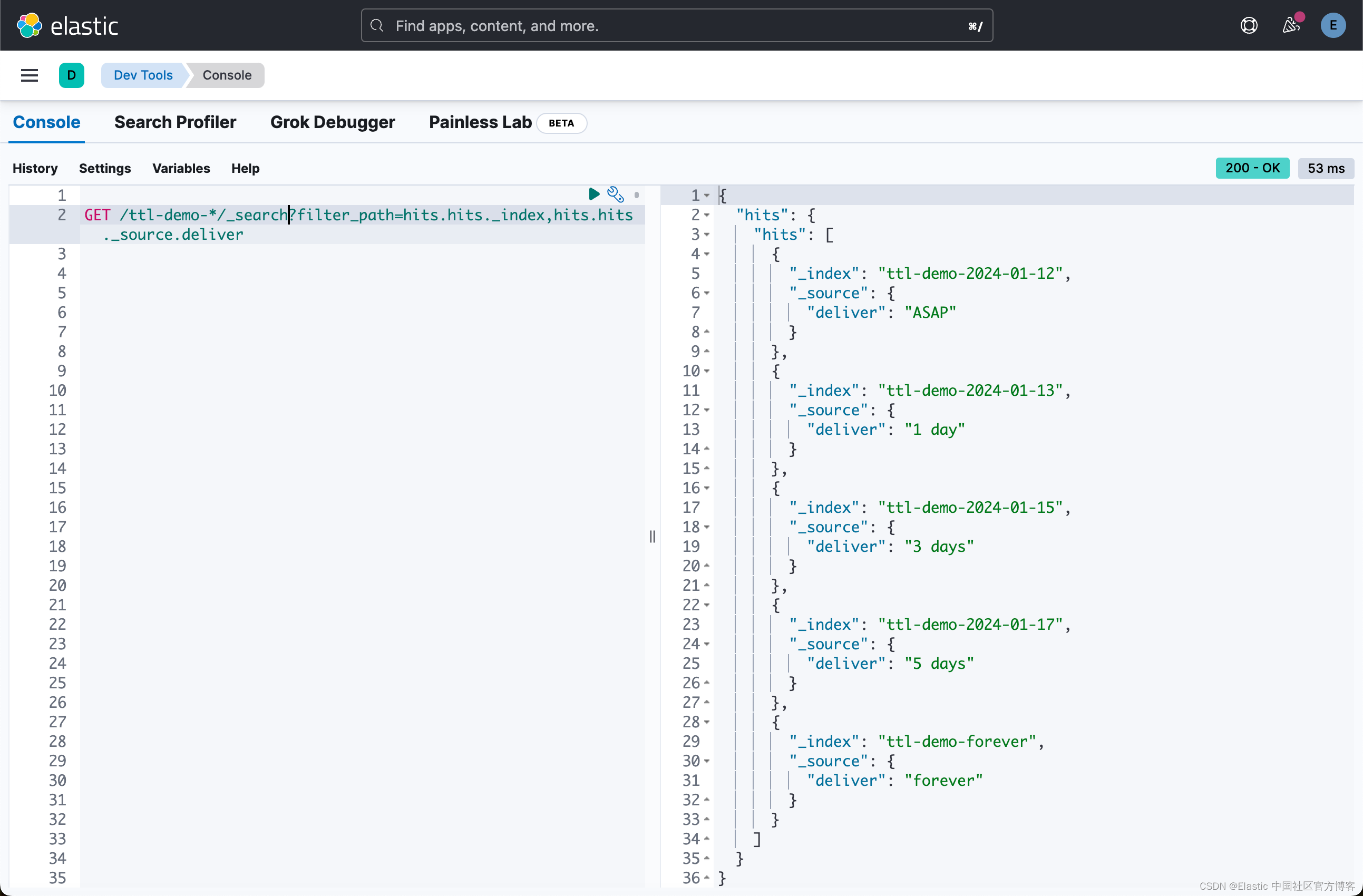
索引名称不再引用,因为我们习惯于查看数据的日期,而是删除数据的日期。 因此我们可以每天再次运行 crontab 来删除旧索引。 以下脚本旨在在 Mac OS X 系统上运行:
0 0 * * * curl -XDELETE -u elastic:changeme https://127.0.0.1:9200/ttl-demo-$(date -v -1d -j +%F)总结起来
我们看到了在 Elasticsearch 文档上执行 TTL 的两种方法。 第一个是使用 TTL 字段并使用 “Delete By Query ” 调用来删除文档。 第二种(效率更高,需要删除大量数据)是使用 TTL 字段将文档路由到不同的索引,然后使用 crontab 删除索引。
但对于这两种解决方案,在 contrab 运行之前文档仍然可见。
你可以考虑使用索引过滤别名来隐藏旧文档:
POST _aliases
{
"actions": [
{
"add": {
"index": "ttl-demo",
"alias": "ttl-filtered",
"filter": {
"bool": {
"filter": [
{
"range": {
"ttl_date": {
"gt": "now/m"
}
}
}
]
}
}
}
}
]
}即使批处理(crontab 或 watcher)尚未删除过期文档,在 ttl-filtered 别名内搜索也只会返回尚未过期的文档。
圣诞老人现在可以知道接下来安全地去哪里,然后享受当之无愧的休息一年!