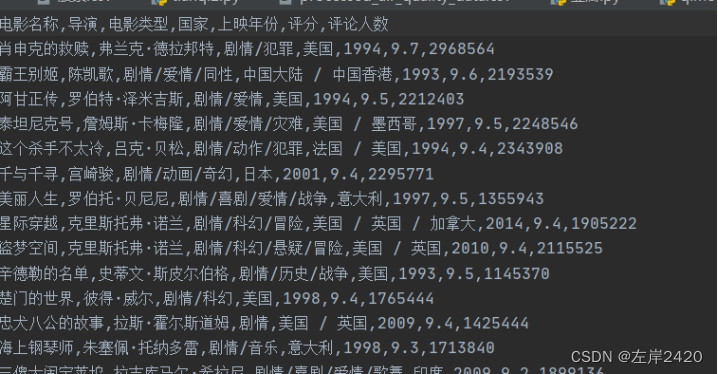
一:爬虫1、爬取的目标将豆瓣电影网上的电影的基本信息,比如:电影名称、导演、电影类型、国家、上映年份、评分、评论人数爬取出来,并将爬取的结果放入csv文件中,方便存储。 2、网站结构 图1豆瓣网网站结构详情 此次实验爬取豆瓣网中电影页面中的电影的基本信息。 每一个电影包括电影名称、导演、电影类型、国家、上映年份、评分、评论人数。页面具体情况如图2所示。
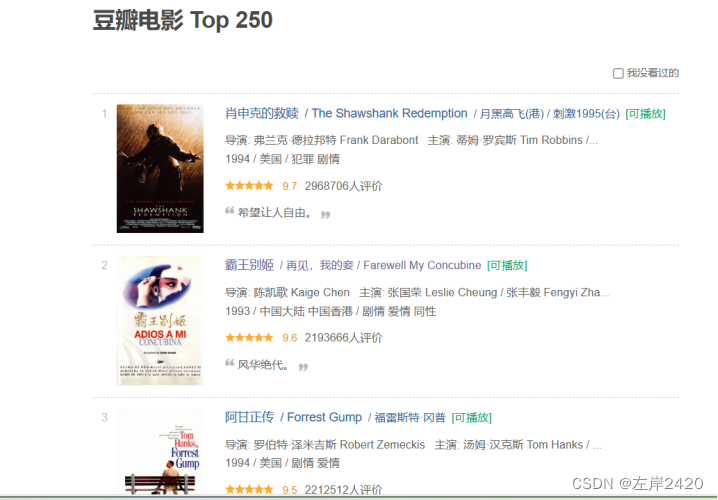
图2豆瓣网电影基本信息详情 3、爬虫技术方案1)、所用技术: 网站解析的使用的是Xpath、数据存储使用的是csv。 2)、爬取步骤: 1、导入所需的库,如re、time、requests、lxml、random和csv。 2、定义一个名为main的函数,该函数接受两个参数:page(页码)和f(文件对象)。 3、在main函数中,构造请求URL,设置请求头,并发送GET请求以获取网页内容。 4、使用lxml库解析网页内容,提取电影详情页的链接列表和电影名称列表。 5、遍历链接列表和名称列表,对于每个链接和名称,调用get_info函数来获取电影的详细信息。 6、在get_info函数中,同样构造请求URL,设置请求头,并发送GET请求以获取电影详情页的内容。 7、使用lxml库解析电影详情页的内容,提取导演、电影类型、国家、上映时间、评分和评论人数等信息。 8、打印提取到的信息,并将其写入CSV文件中。 9、在主程序中,创建一个CSV文件,并写入表头标题。 10、使用for循环遍历10个页面,调用main函数来爬取每一页的电影信息。 11、在每次循环之间,让程序休息一段时间,以避免过于频繁的请求导致IP被封禁。 4、爬取过程:
1)、导入所需要的包
import re:导入正则表达式模块,用于处理字符串。 from time import sleep:从time模块导入sleep函数,用于让程序暂停执行一段时间。 import requests:导入requests模块,用于发送HTTP请求。 from lxml import etree:从lxml模块导入etree函数,用于解析HTML文档。 import random:导入random模块,用于生成随机数。 import csv:导入csv模块,用于操作CSV文件。 2)、设置请求头,定义min函数接收参数,访问连接提取列表
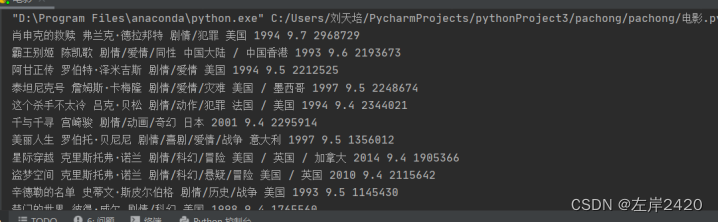
3)、使用正则表达式开始爬取网页信息4)、将爬取结果放入csv文件中5、爬虫结果
 二:预处理1、删除列
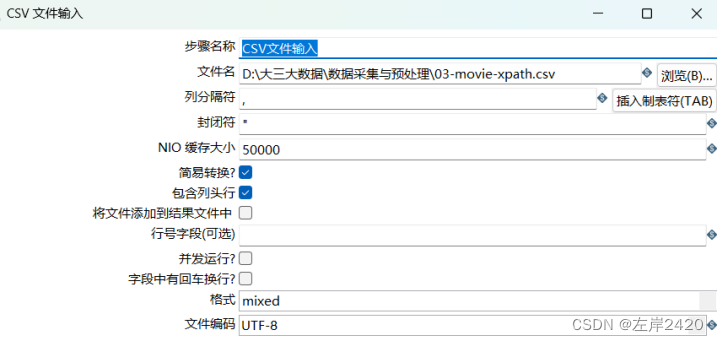
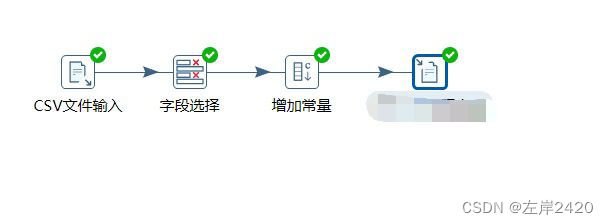
1)、新建转换,之后使用文件输入,将csv文件输入进行处理
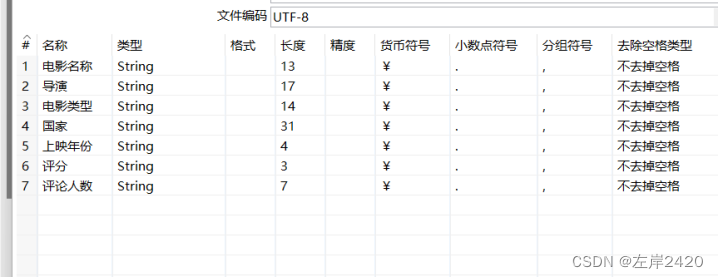
之后进行字段获取。
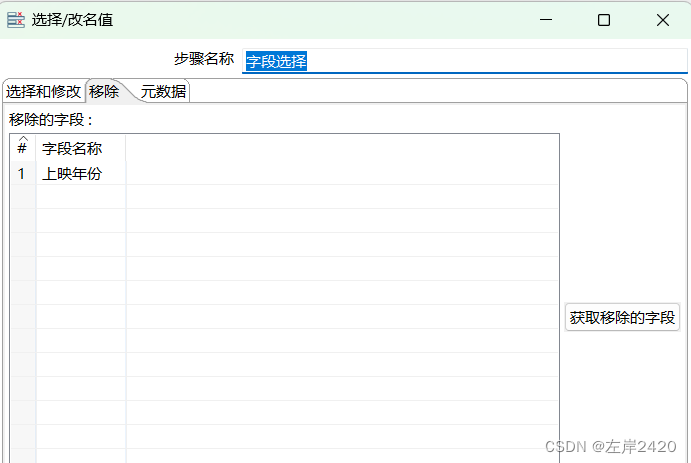
2)、选择转换中的字段选择进行列删除,将上映时间这个列进行删除。
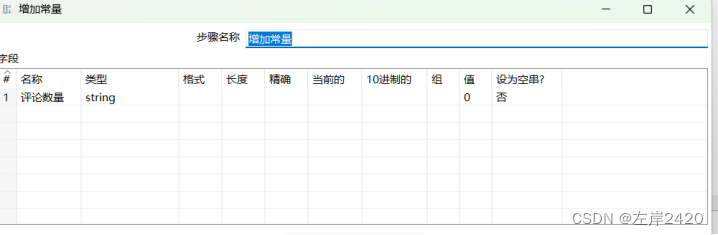
2、选择转换中的增加常量,增加评论数量这一列,查询电影评论的数量这一情况。
4、预处理完全处理全流程:
三:爬虫数据源代码代码: |
基于爬虫和Kettle的豆瓣电影的采集与预处理
news2026/2/11 13:49:22
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1378435.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

Vue3:vue-cli项目创建及vue.config.js配置
一、node.js检测或安装:
node -v node.js官方
二、vue-cli安装:
npm install -g vue/cli
# OR
yarn global add vue/cli/*如果安装的时候报错,可以尝试一下方法
删除C:\Users**\AppData\Roaming下的npm和npm-cache文件夹
删除项目下的node…
Vue入门六(前端路由的概念与原理|Vue-router简单使用|登录跳转案例|scoped样式)
文章目录 前要:前端路由的概念与原理1)什么是路由2)SPA与前端路由3)什么是前端路由4)前端路由的工作方式 一、Vue-router简单使用1)什么是vue-router2) vue-router 安装和配置的步骤① 安装 vue-router 包②…
为什么企业容易陷入“自嗨式营销”,媒介盒子分析
互联网时代,各类信息都传播的非常快,同时信息技术的成熟也让许多企业可以监测广告效果,比如曝光、互动、转化等都可以通过数据体现,然而很多企业在营销过程中却发现,大部分的钱、精力、人力等都被浪费了。出现这种情况…

Android开发基础(三)
Android开发基础(三) 本篇将介绍Android权限管理。
Android权限管理
Android权限管理主要是为了保护用户的隐私和设备的安全性; 在Android系统中,应用在请求权限时必须进行明确的申请,根据权限的保护级别࿰…
C语言——(printf和scanf介绍)
一.printf
1.基本用法
printf()的作用是将参数文本输出的屏幕。如下;
2.占位符
printf()可以在输出文本中指定占位符 ,“占位符”,也就是这个位置可以用其他值代入。
如: …
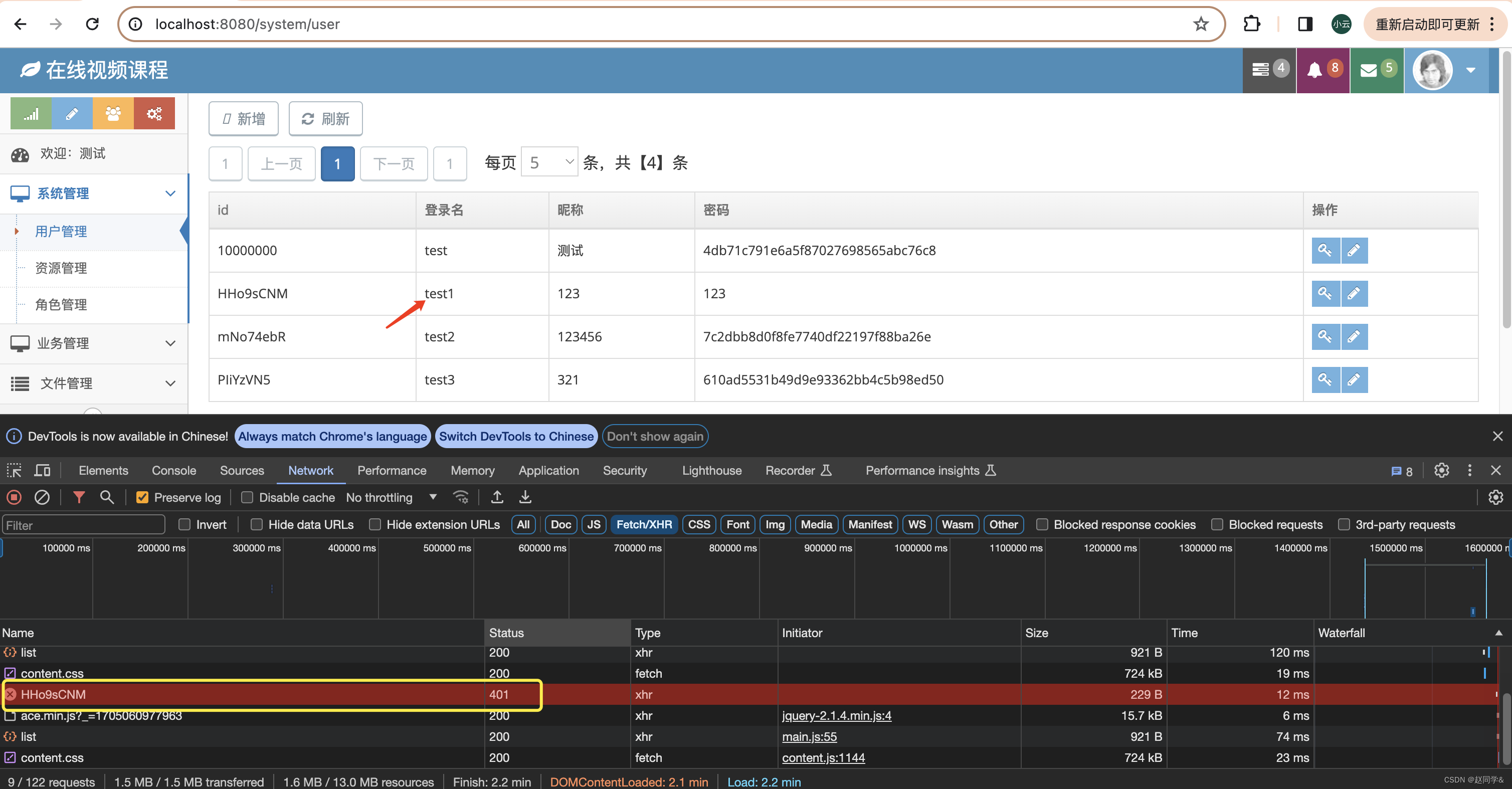
Spring Cloud + Vue前后端分离-第12章 通用权限设计
源代码在GitHub - 629y/course: Spring Cloud Vue前后端分离-在线课程
Spring Cloud Vue前后端分离-第12章 通用权限设计
这一章我们不依赖第三方框架,我会从权限相关表的设计,到权限的配置,到权限的拦截,带大家一步一步的做出…
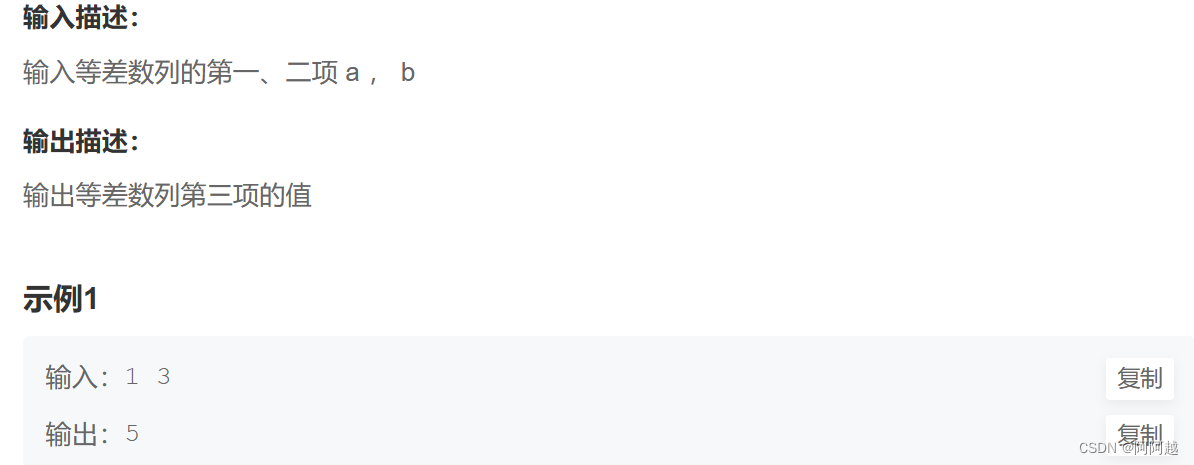
C语言基础语法跟练 day3
31、不使用累计乘法的基础上,通过移位运算(<<)实现2的n次方的计算。 #include <stdio.h>
int main()
{int i 0;scanf("%d",&i);printf("%d",1<<i);return 0;
} 32、问题:一年约有 3.…

使用postman做接口测试(一)
如何执行HTTP接口测试。包括如下三步:
构造一条符合要求的HTTP请求消息;发给我,我给你回响应;你读取HTTP响应,检查响应内容是否正确。
今天我们就讲,如何使用postman发送符合要求的HTTP请求。 how-如何安…

Redis重点总结补充
Redis重点总结
1.redis分布式锁 2.redission实现分布式锁 注意:加锁、设置过期时间等操作都是基于lua脚本完成.
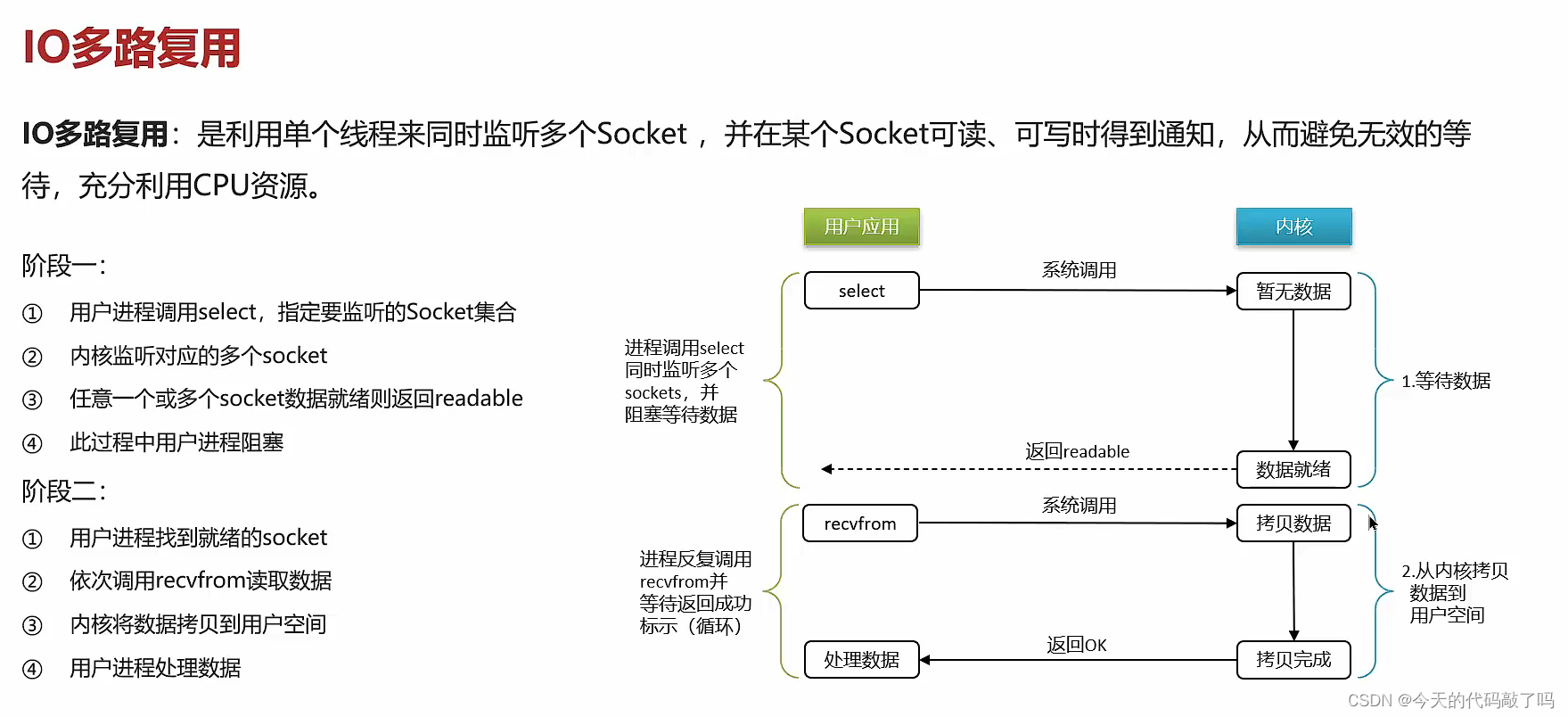
redisson分布式锁,实现可重入(前提是同一个线程下 3.redis主从集群 实现主从复制 ( Master-slave Replication)的工作原理 :
…

Linux中关于echo命令详解
echo的作用
echo用于输出字符或字符串或者回显。 echo的参数说明
-n不换行输出内容-e解析转义字符-E不使用解析转义字符 使用 "-e" 参数拓展参数
\b删除前一个字符\c最后不加上换行号\f换页\n换行并将光标移动到行首\r光标移动到行首切不换行,如果\r后面还有字符,…
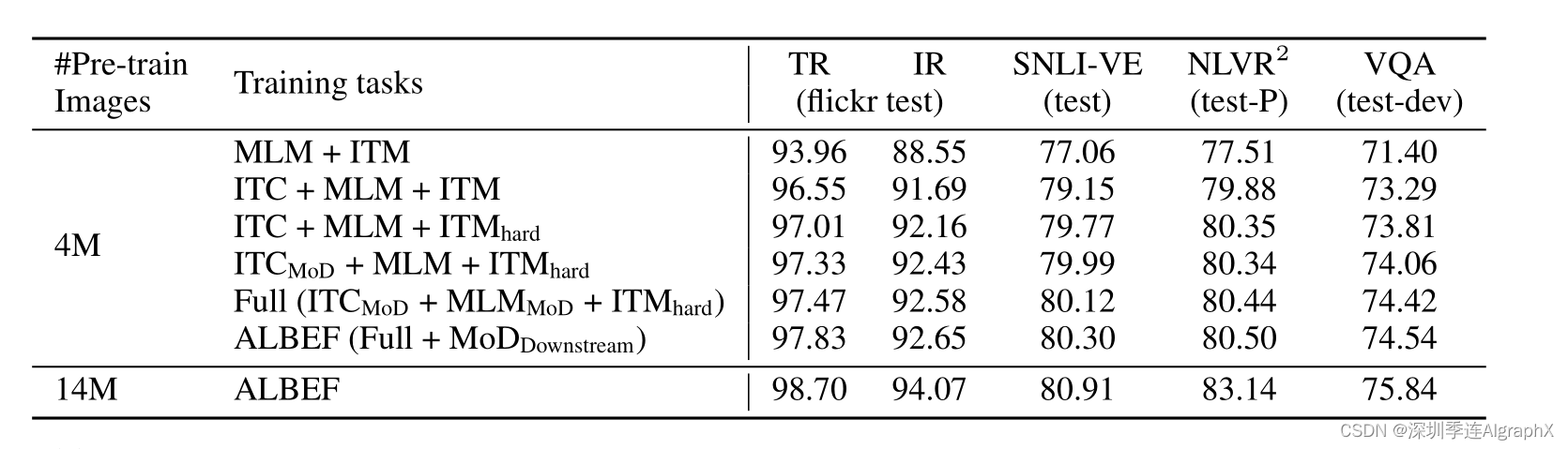
51-10 多模态论文串讲—ALBEF 论文精读
今天我们就来过一下多模态的串讲,其实之前,我们也讲了很多工作了,比如说CLIP,还有ViLT,以及CLIP的那么多后续工作。多模态学习在最近几年真的是异常的火爆,那除了普通的这种多模态学习,比如说视…
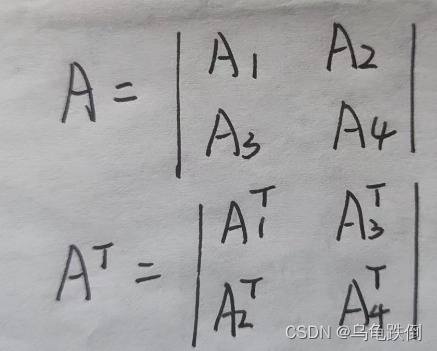
分块矩阵的定义、计算
目录 一、定义
二、分块矩阵的加减乘法
三、考点 一、定义
分块,顾名思义,将整个矩阵分成几部分,如下图所示
二、分块矩阵的加减乘法 三、考点
分块矩阵的考点不多,一般来说,有一种:
求分块矩阵的转置…
基于 IDEA 创建 Maven 的 Java SE 工程和 Java Web 工程
一、概念简介 Maven 工程相对之前的项目,多出一组 gavp 属性,gav 需要我们在创建项目的时候指定,p 有默认值,我们先行了解下这组属性的含义。 Maven 中的 GAVP 是指 GroupId、ArtifactId、Version、Packaging 等四个属性的缩写&am…
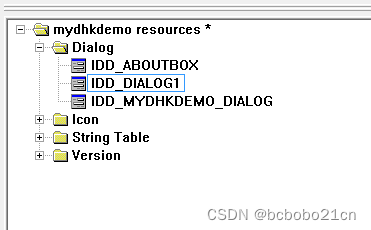
MFC为对话框资源添加类
VC6新建一个对话框类型的工程;
建立之后资源中默认有2个对话框,一个是主对话框,About这个是默认建立的关于版权信息的; 然后主对话框有对应的.h和.cpp文件;可以在其中进行编程; 默认建立的有一个 关于 对话框; 在资源中新插入一个对话框,IDD_DIALOG1是对话框ID; 新加…
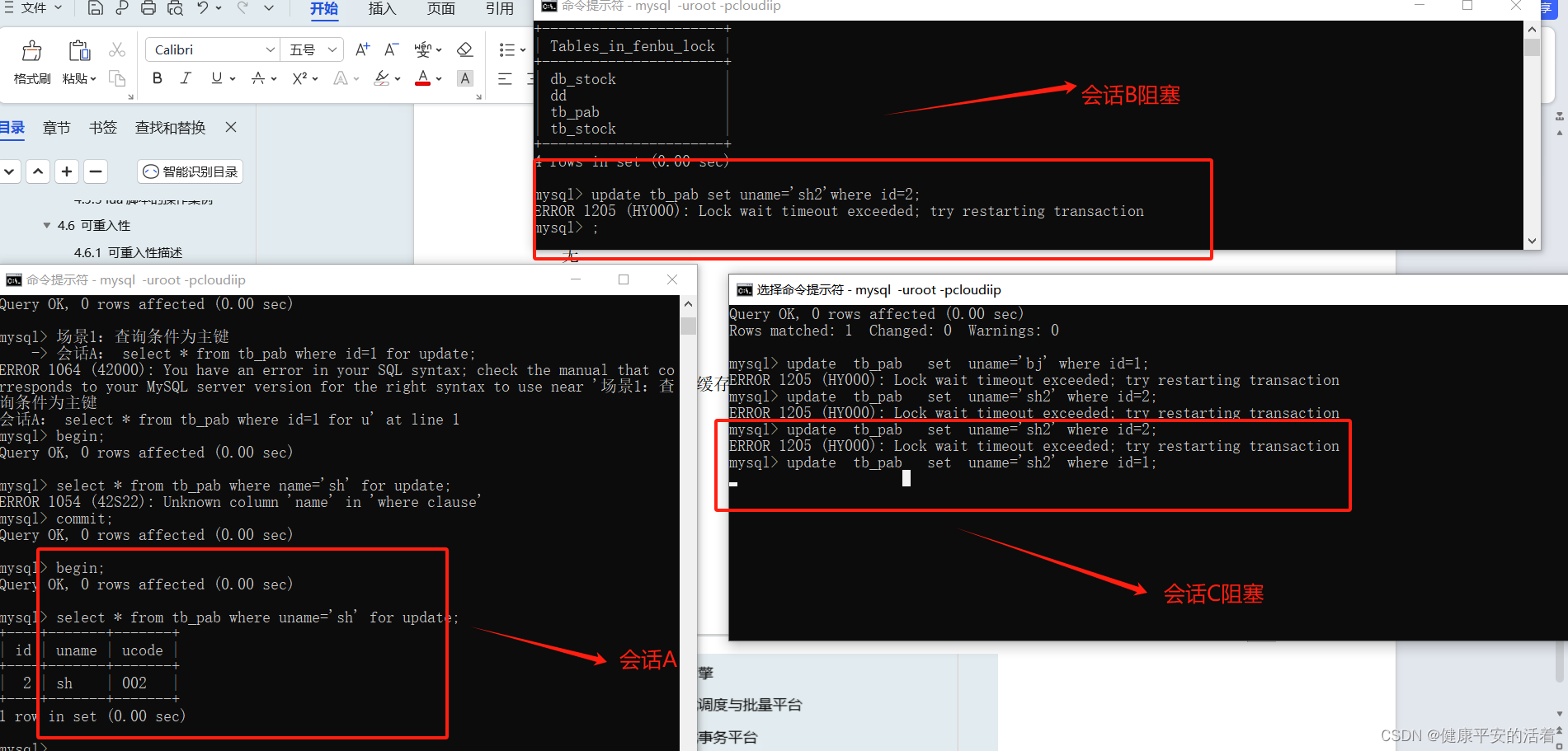
数据库悲观锁 select for update的详解
一 作用
1.1 结论
在mysql中,select ... for update 仅适用于InnoDB,且必须在事务块中才能生效。Innodb引擎默认是行锁。 Select .... from where .... for update 如果在where的查询条件字段使用了【主键|索引】,则此命令上行锁。否…
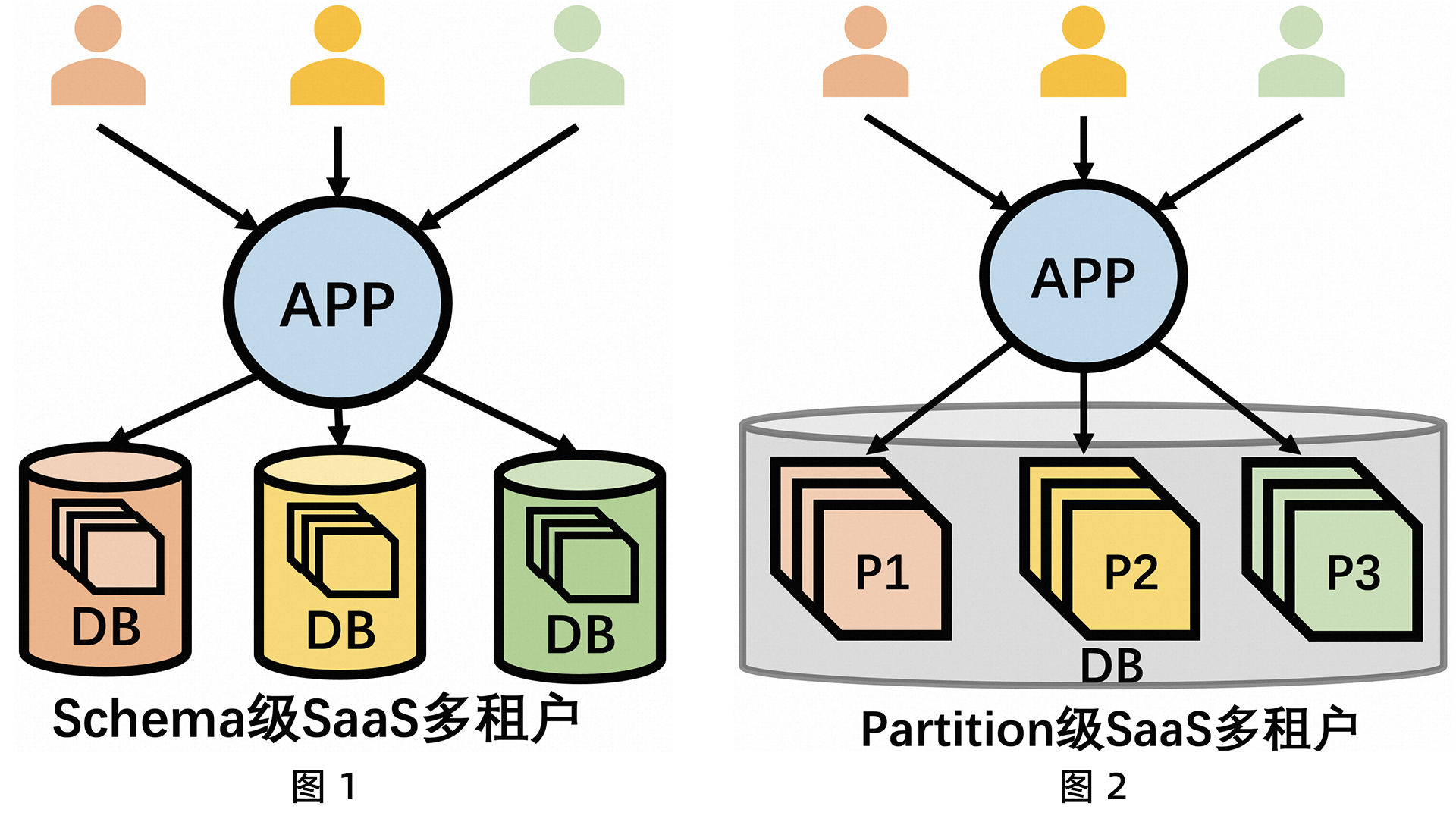
典型场景解析|PolarDB分布式版如何支撑SaaS多租户?
SaaS多租户背景 很多平台类应用或系统(如电商CRM平台、仓库订单平台等等),它们的服务模型是围绕用户维度(这里的用户维度可以是一个卖家或品牌,可以是一个仓库等)展开的。因此,这类型的平台业务…
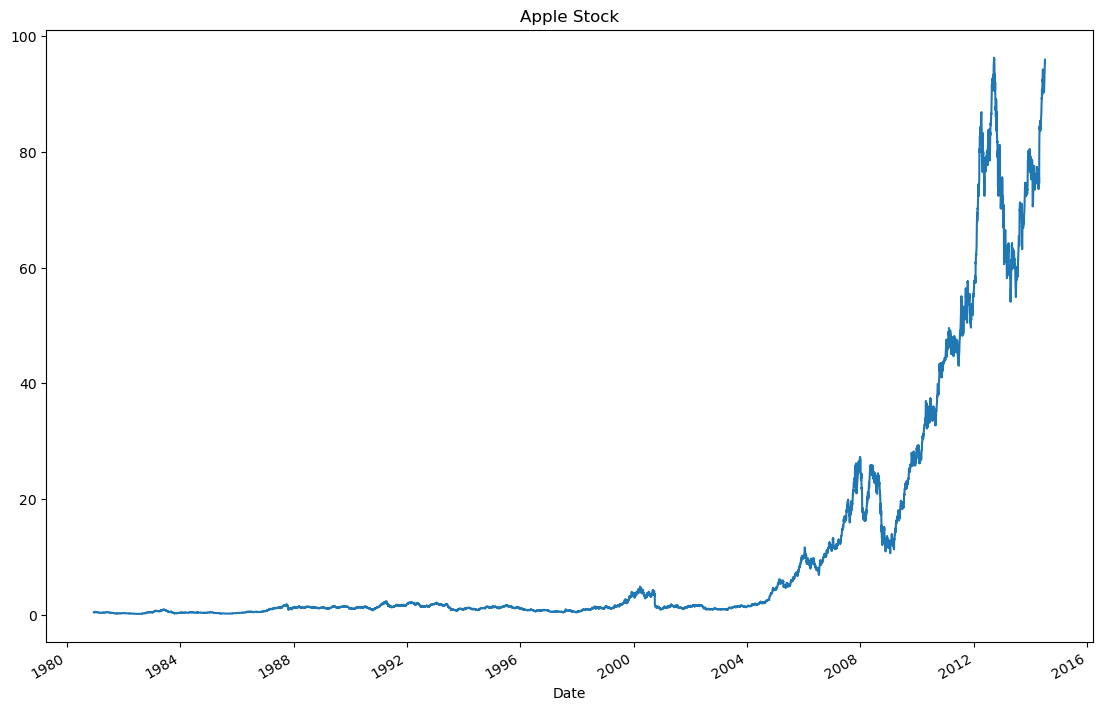
Pandas十大练习题,掌握常用方法
文章目录 Pandas分析练习题1. 获取并了解数据2. 数据过滤与排序3. 数据分组4. Apply函数5. 合并数据6. 数据统计7. 数据可视化8. 创建数据框9. 时间序列10. 删除数据 代码均在Jupter Notebook上完成 Pandas分析练习题 数据集可从此获取: 链接: https://pan.baidu.co…
开源知识库工具推荐:低成本搭建知识库
在信息爆炸的时代,企业和个体对知识的存储和管理需求日益增强。开源知识库工具因其开源、免费、高效的特性,成为了众多组织和个人的首选。如果你正在寻找一款优秀的开源知识库工具,本文将为你推荐三款性能优异的产品,感兴趣就往下…