环境准备
预先安装 docker、perf、hping3、curl 等工具,如 apt install docker.io linux-tools-common hping3
操作和分析
Linux 在启动过程中,有三个特殊的进程,也就是 PID 号最小的三个进程。
0 号进程为 idle 进程,这也是系统创建的第一个进程,它在初始化 1 号和 2 号进程后,演变为空闲任务。当 CPU 上没有其他任务执行时,就会运行它。
1 号进程为 init 进程,通常是 systemd 进程,在用户态运行,用来管理其他用户态进程。
2 号进程为 kthreadd 进程,在内核态运行,用来管理内核线程。
要查找内核线程,我们只需要从 2 号进程开始,查找它的子孙进程即可。比如,你可以使用 ps 命令,来查找 kthreadd 的子进程:
ps -f --ppid 2 -p 2
UID PID PPID C STIME TTY TIME CMD
root 2 0 0 1月04 ? 00:00:00 [kthreadd]
root 4 2 0 1月04 ? 00:00:00 [kworker/0:0H]
root 6 2 0 1月04 ? 00:00:40 [ksoftirqd/0]
root 7 2 0 1月04 ? 00:00:20 [migration/0]
root 8 2 0 1月04 ? 00:00:00 [rcu_bh]
root 9 2 0 1月04 ? 00:02:36 [rcu_sched]
root 10 2 0 1月04 ? 00:00:00 [lru-add-drain]
root 11 2 0 1月04 ? 00:00:00 [watchdog/0]
root 12 2 0 1月04 ? 00:00:00 [watchdog/1]
很多常见的内核线程,我们在性能分析中都经常会碰到,比如下面这几个内核线程。
kswapd0:用于内存回收。在 Swap 变高 案例中,我曾介绍过它的工作原理。
kworker:用于执行内核工作队列,分为绑定 CPU (名称格式为 kworker/CPU:ID)和未绑定 CPU(名称格式为 kworker/uPOOL:ID)两类。
migration:在负载均衡过程中,把进程迁移到 CPU 上。每个 CPU 都有一个 migration 内核线程。
jbd2/sda1-8:jbd 是 Journaling Block Device 的缩写,用来为文件系统提供日志功能,以保证数据的完整性;名称中的 sda1-8,表示磁盘分区名称和设备号。每个使用了 ext4 文件系统的磁盘分区,都会有一个 jbd2 内核线程。
pdflush:用于将内存中的脏页(被修改过,但还未写入磁盘的文件页)写入磁盘(已经在 3.10 中合并入了 kworker 中)。
案例用到两台虚拟机

在第一个终端,执行下面的命令运行案例,也就是一个最基本的 Nginx 应用:
# 运行Nginx服务并对外开放80端口
docker run -itd --name=nginx -p 80:80 nginx
在第二个终端,使用 curl 访问 Nginx 监听的端口,确认 Nginx 正常启动。假设 192.168.0.30 是 Nginx 所在虚拟机的 IP 地址,运行 curl 命令后,你应该会看到下面这个输出界面:
curl http://xxx.xxx.xxx.xxx/
还是在第二个终端中,运行 hping3 命令,模拟 Nginx 的客户端请求:
hping3 -S -p 80 -i u1 xxx.xxx.xxx.xxx
执行top命令
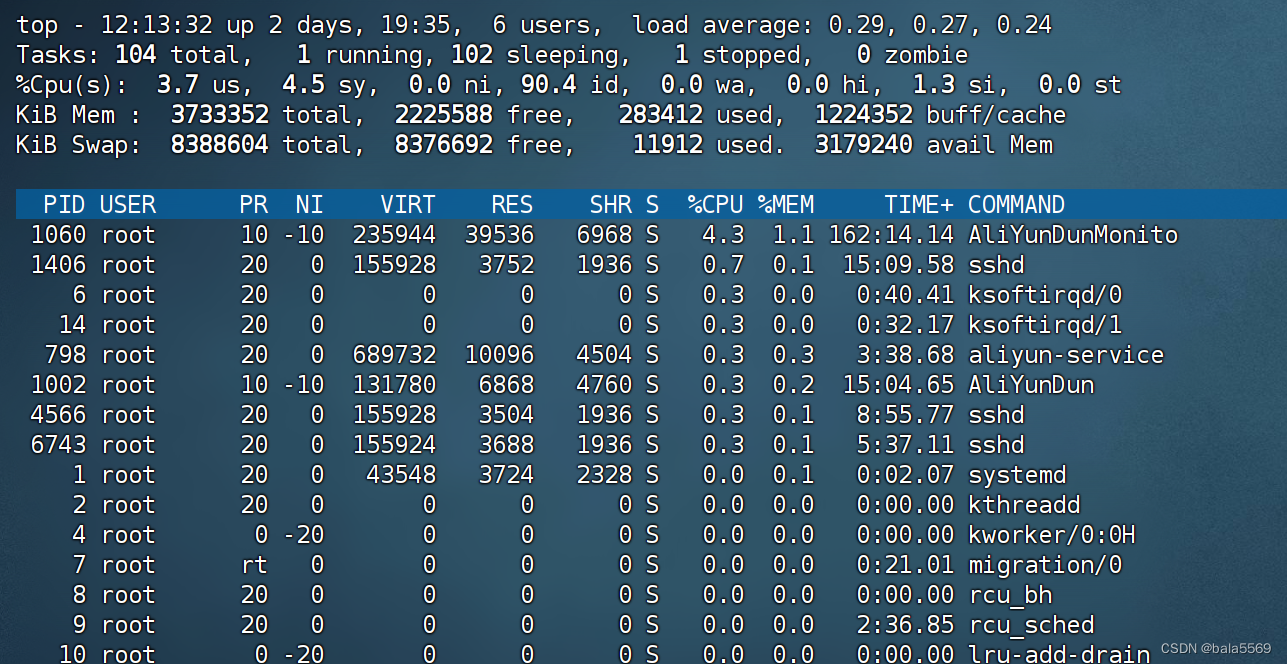
CPU 的软中断使用率都超过了 30%;而 CPU 使用率最高的进程,正好是软中断内核线程 ksoftirqd/0 和 ksoftirqd/1。
已经知道了 ksoftirqd 的基本功能,可以猜测是因为大量网络收发,引起了 CPU 使用率升高;但它到底在执行什么逻辑,我们却并不知道。
那还有没有其他方法,来观察内核线程 ksoftirqd 的行为呢?
perf 可以对指定的进程或者事件进行采样,并且还可以用调用栈的形式,输出整个调用链上的汇总信息。 我们不妨就用 perf ,来试着分析一下进程号为 6 的 ksoftirqd。
$ perf record -a -g -p 9 -- sleep 30
执行 perf report命令,你就可以得到 perf 的汇总报告。按上下方向键以及回车键,展开比例最高的 ksoftirqd
net_rx_action 和 netif_receive_skb,表明这是接收网络包(rx 表示 receive)。
br_handle_frame ,表明网络包经过了网桥(br 表示 bridge)。br_nf_pre_routing ,表明在网桥上执行了 netfilter 的 PREROUTING(nf 表示 netfilter)。而我们已经知道 PREROUTING 主要用来执行 DNAT,所以可以猜测这里有 DNAT 发生。br_pass_frame_up,表明网桥处理后,再交给桥接的其他桥接网卡进一步处理。比如,在新的网卡上接收网络包、执行 netfilter 过滤规则等等。
用火焰图来查看层级太多的调用栈
假设刚才用 perf record 生成的文件路径为 /root/perf.data,执行下面的命令,你就可以直接生成火焰图:
perf script -i /root/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > ksoftirqd.svg
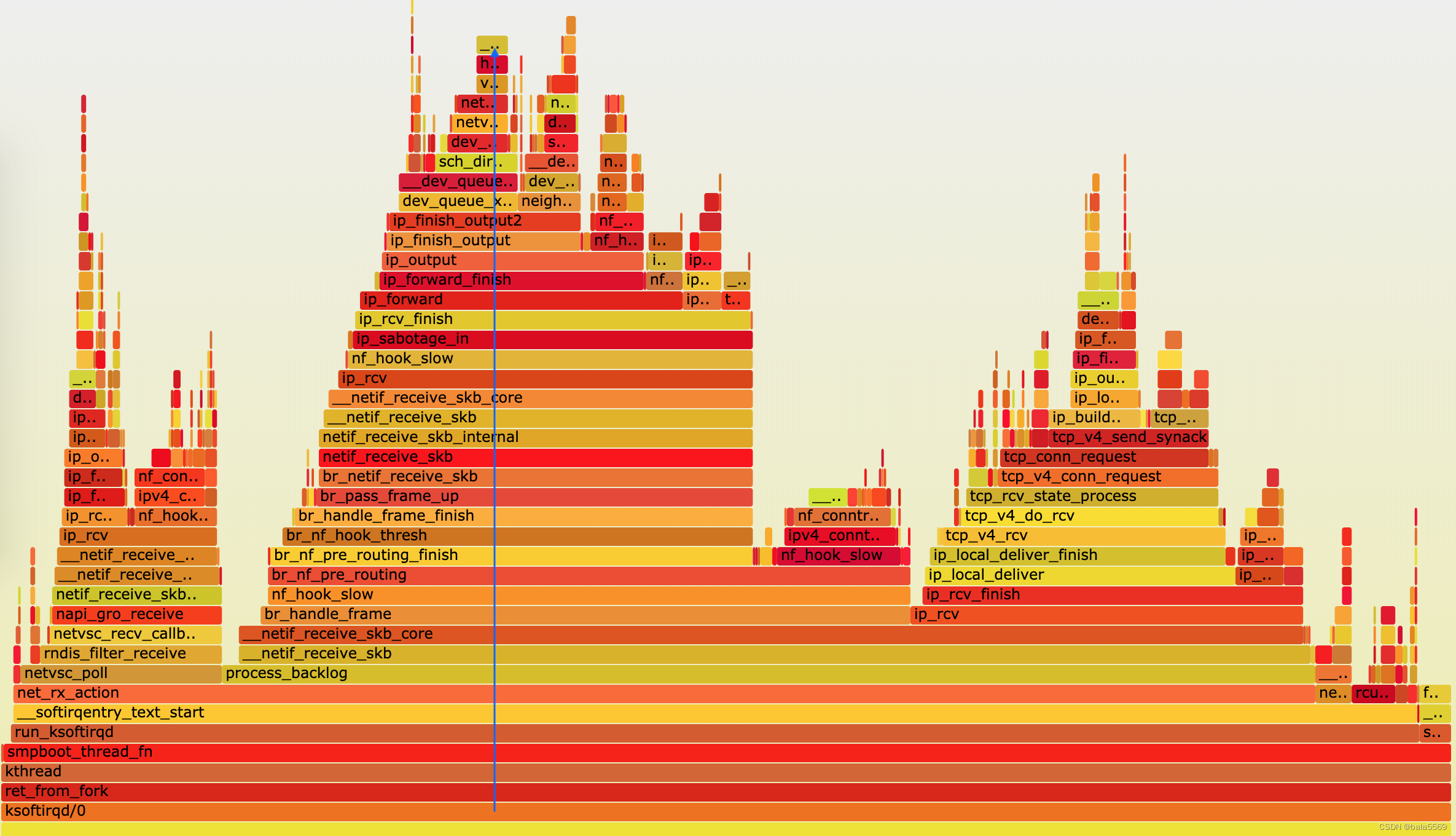
我们就找出了内核线程 ksoftirqd 执行最频繁的函数调用堆栈,而这个堆栈中的各层级函数,就是潜在的性能瓶颈来源。这样,后面想要进一步分析、优化时,也就有了根据。

![[Linux 进程(二)] Linux进程状态](https://img-blog.csdnimg.cn/direct/be26df3244f840f8b8c04fb488fbded7.png)