文章目录
- 1. BigKey
- 1.1 MoreKey
- 1.2 BigKey
- 2. 缓存双写一致性更新策略
- 2.1 读缓存数据
- 2.2 数据库和缓存一致性的更新策略
- 2.3 canal 实现双写一致性
- 3. 进阶应用
- 3.1 统计应用
- 3.2 hyperloglog
- 3.3 GEO
- 3.4 bitmap
- 4. 布隆过滤器
- 5. Redis 经典问题
- 5.1 缓存预热
- 5.2 缓存穿透
- 5.3 缓存击穿
- 5.4 缓存雪崩
- 5.5 问题总结
- 6. Redis 内存淘汰策略
- 7. Redis 分布式锁
- 7.1 分布式锁设计
- 7.2 redission
- 8. Redis 线程与 IO 多路复用
- 8.1 Redis 线程
- 8.2 网络编程
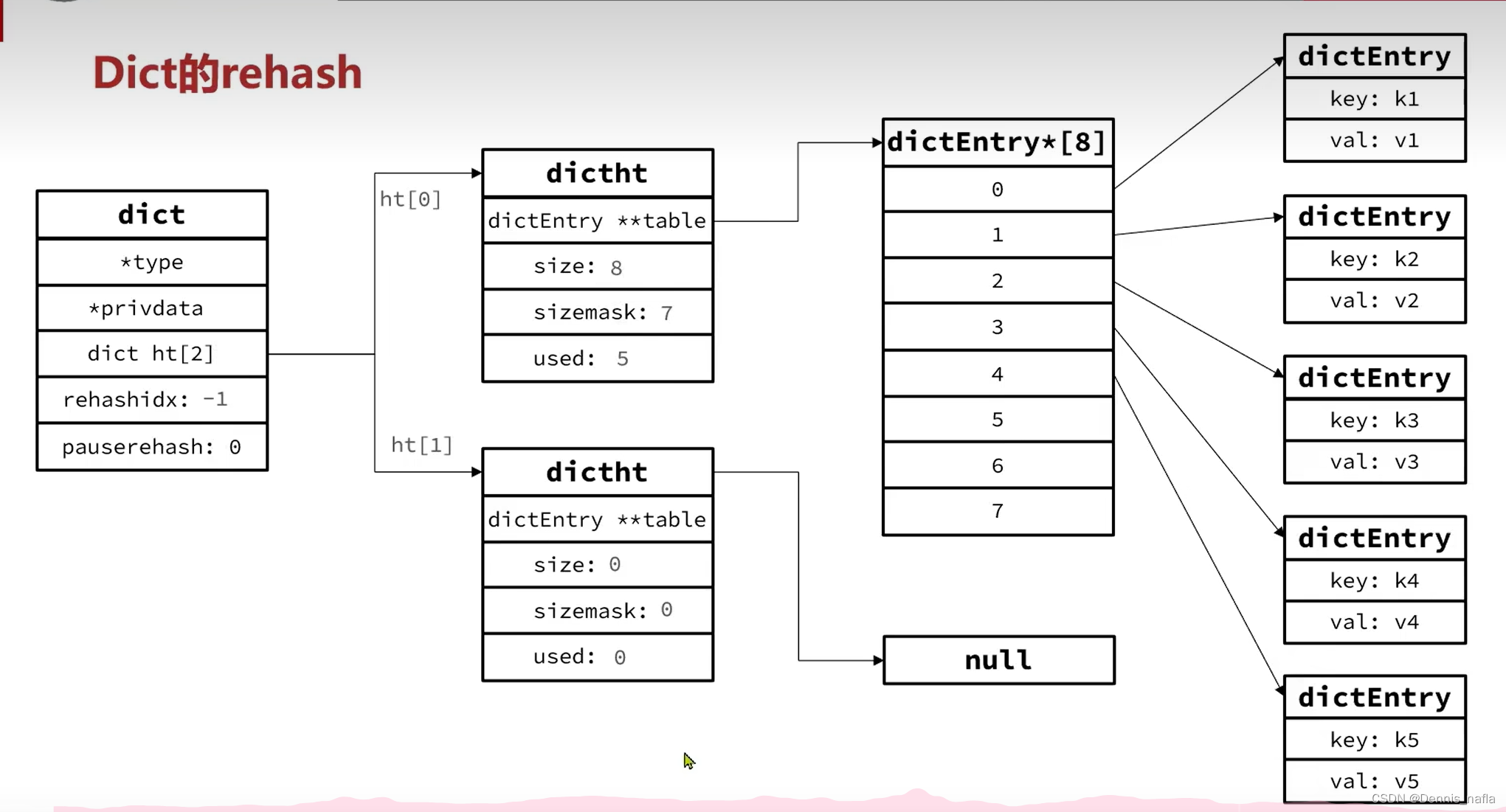
1. BigKey
1.1 MoreKey
生产上限制使用 keys * 、flushdb 、flushall 等危险命令,由于 redis 读写是单线程的,这些命令在存在千万级以上的 key 会导致 redis 服务卡顿,所有读写 redis 的其它的指令都会被延后甚至会超时报错,可能会引起缓存雪崩甚至数据库宕机。
-
测试 :导入百万级数据到 redis中
- 生成百万级导入数据脚本:
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> redisTest.txt ;done; - 导入数据脚本:
cat redisTest.txt | redis-cli -p 6379 -a redis --pipe - 执行
keys *花费了3.22s
- 生成百万级导入数据脚本:
-
配置禁用命令:
redis.conf中配置rename-commandrename-command keys "" rename-command flushdb "" rename-command flushall "" -
keys *替代方案:scan cursor [MATCH pattern] [COUNT count],基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程- 使用示例:
scan 0 MATCH k* COUNT 2,下一次迭代需要将 0 换成结果中的游标,如果游标结果为 0 表示迭代结束;COUNT默认为10可不填 - 特点:返回结果中有两个,一个是游标用于下一次迭代,一个是返回的元素集合;
- SCAN的遍历顺序:非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
- 使用示例:
1.2 BigKey
参考《阿里云 Redis 开发手册 》:【强制】拒绝 bigkey(防止网卡流量、慢查询)
- string 类型控制在 10KB 以内,hash、list、set、zset 元素个数不要超过 5000。
查找 bigkey:
redis-cli -a 密码 --bigkeys:给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小memory usage key [samples count]:返回key值及管理该key分配的内存总字节数,嵌套类型可用选项samples,count表示抽样元素个数,默认 5,当需要抽样全部元素时使用samples 0。可结合scan命令遍历所有 key 来找到所有 bigkey
bigkey删除:非字符串的 bigkey ,不要使用 del 删除,使用 hscan、sscan、zscan方式渐进式删除,同时要注意防止 bigkey 过期时间自动删除的问题(过期删除会触发 del 操作,且不会出现在慢查询中(latency可查))
String:一般用 del,如果过于庞大用 unlinkhash:使用hscan每次获取少量 field-value ,再使用hdel删除每个 fieldlist:使用ltrim渐进式删除set:使用sscan每次获取部分元素,再使用srem命令删除元素zset:使用zscan每次获取部分元素,再使用zremrangebyrank命令删除元素
生产调优:
- 非阻塞式命令:如使用
unlink命令或async参数 - 惰性释放 lazyfree 配置:
lazyfree-lazy-server-del yes、replica-lazy-flush yes以及lazyfree-lazy-user-del yes,这几个默认都是no
2. 缓存双写一致性更新策略
缓存双写是指缓存与数据库之间必然面临数据不一致的问题,这里主要谈同步直写的问题及解决方案,异步缓写一般可采用 MQ 重试重写。
2.1 读缓存数据
读缓存数据:最简单的实现逻辑是读缓存,缓存没有读数据库,读完数据库写回缓存。
上面的实现逻辑存在一定问题,高并发时如果缓存数据被修改,如果两个请求同时先后读缓存且后先写缓存就会造成缓存将一直是旧值的问题,这里提供一种双检加锁的实现方式:
public User findUserById(Integer id){
User user = null;
String key = CACHE_KEY_USER+id;
user = (User) redisTemplate.opsForValue().get(key);
if(user == null) {
synchronized (UserService.class){
user = (User) redisTemplate.opsForValue().get(key);
if (user == null) {
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
return null;
}else{
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
}
}
}
}
return user;
}
2.2 数据库和缓存一致性的更新策略
- 先更新数据库,再更新缓存
- 异常:如 A、B 同时做更新,A先更新数据库为 100,B再更新数据库为 80,之后 B先更新缓存为 80,A更新缓存为 100,最终缓存与数据库数据不一致
- 先更新缓存,再更新数据库
- 异常:更新缓存成功,之后更新数据库失败,缓存的数据是错误的数据
- 先删除缓存,再更新数据库
- 异常:删除缓存后,其他线程将直接访问数据库,并读到旧数据回写
- 延迟双删策略:通过在更新数据库后,增加 sleep 和再次删除缓存,等其他线程写了旧数据后再次删除数据达到最终一致性(这种方案需要评估好其他线程执行这段代码的时间,不是很好控制)
- 先更新数据库,再删除缓存:推荐方案,使用 canal 也基本上是基于该方案实现的
- 异常:在更新数据库及删除缓存之间会有短时间的旧缓存存在时期,但是可以实现最终数据一致性
分布式情况下很难做到实时一致性,如果要求必须实现实时一致性,那就需要在更新数据库时,先在 redis 缓存客户端暂停并发读请求(即加锁),等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性,这是理论可以实现的效果,但实际一般不推荐
2.3 canal 实现双写一致性
canel 基于数据库增量日志解析,提供增量数据订阅和消费,即可以用来实时监控数据库数据变化,并通知 redis 、MQ等其它应用
canel 工作原理:
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
canal 可用于实现 mysql-canal-redis 双写一致性,即当使用 canal 监听到数据库对应变化时,对 redis 缓存也直接进行修改,示例代码:
需引入依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.6</version>
</dependency>
public class RedisCanalClientExample{
public static final Integer _60SECONDS = 60;
public static final String REDIS_IP_ADDR = "192.168.115.129";
private static void redisInsert(List<Column> columns)
{
JSONObject jsonObject = new JSONObject();
for (Column column : columns)
{
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(),column.getValue());
}
if(columns.size() > 0)
{
try(Jedis jedis = RedisUtils.getJedis())
{
jedis.set(columns.get(0).getValue(),jsonObject.toJSONString());
}catch (Exception e){
e.printStackTrace();
}
}
}
private static void redisDelete(List<Column> columns)
{
JSONObject jsonObject = new JSONObject();
for (Column column : columns)
{
jsonObject.put(column.getName(),column.getValue());
}
if(columns.size() > 0)
{
try(Jedis jedis = RedisUtils.getJedis())
{
jedis.del(columns.get(0).getValue());
}catch (Exception e){
e.printStackTrace();
}
}
}
private static void redisUpdate(List<Column> columns)
{
JSONObject jsonObject = new JSONObject();
for (Column column : columns)
{
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(),column.getValue());
}
if(columns.size() > 0)
{
try(Jedis jedis = RedisUtils.getJedis())
{
jedis.set(columns.get(0).getValue(),jsonObject.toJSONString());
System.out.println("---------update after: "+jedis.get(columns.get(0).getValue()));
}catch (Exception e){
e.printStackTrace();
}
}
}
public static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
//获取变更的row数据
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error,data:" + entry.toString(),e);
}
//获取变动类型
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.INSERT) {
redisInsert(rowData.getAfterColumnsList());
} else if (eventType == EventType.DELETE) {
redisDelete(rowData.getBeforeColumnsList());
} else {//EventType.UPDATE
redisUpdate(rowData.getAfterColumnsList());
}
}
}
}
public static void main(String[] args)
{
System.out.println("---------O(∩_∩)O哈哈~ initCanal() main方法-----------");
//=================================
// 创建链接canal服务端
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(REDIS_IP_ADDR,
11111), "example", "", "");
int batchSize = 1000;
//空闲空转计数器
int emptyCount = 0;
System.out.println("---------------------canal init OK,开始监听mysql变化------");
try {
connector.connect();
//connector.subscribe(".*\\..*");
connector.subscribe("bigdata.t_user");
connector.rollback();
int totalEmptyCount = 10 * _60SECONDS;
while (emptyCount < totalEmptyCount) {
System.out.println("我是canal,每秒一次正在监听:"+ UUID.randomUUID().toString());
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
} else {
//计数器重新置零
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("已经监听了"+totalEmptyCount+"秒,无任何消息,请重启重试......");
} finally {
connector.disconnect();
}
}
}
3. 进阶应用
3.1 统计应用
亿级系统常见的四种统计:
- 聚合统计:交差并等集合统计操作
- 差集运算 A-B:属于A但不属于B的集合,命令:
sdiff key [key...] - 并集运算 AUB:属于A或属于B的集合合并后的集合,命令:
sunion key [key...] - 交集运算 A∩B:属于A也属于B的共同元素构成的集合,命令:
sinter key [key...]
- 差集运算 A-B:属于A但不属于B的集合,命令:
- 排序统计:大数据排序统计如最新列表,排行榜等,使用
zset命令,即Sorted set有序集合 - 二值统计:集合元素只有 0,1两种取值,使用
bitmap位图 - 基数统计:统计一个集合中不重复元素的个数,使用
hyperloglog估算,误差不超过0.815 %。12KB可计算解决2^64个不同元素的基数。- 【拓展】UV(独立访客数)、PV(页面浏览量)、DAU(日活跃用户量)、MAU(月活跃用户量)
3.2 hyperloglog
在 Redis 中每个 hyperloglog 键只需要花费 12 KB 内存就可以计算接近 2^64 个不同元素的基数,误差为 1.04/ sqrt(16384) = 0.008125 。
为什么只需要花费 12 KB?
Redis 使用了 2^14 = 16384 个桶,用前 14 位来确定桶编号,剩下 50 位用来做基数估计。而 2^6 = 64 > 50 ,所以只需要用 6 位来表示下标值,一般情况下 hyperloglog 数据结构占用内存的大小为 16384 * 6 / 8 = 12 KB,Redis 将这种情况称为密集存储。
3.3 GEO
使用该类型的 georadius api可以快速找出以某个点为中心,半径为 r(传参) 的其他地理位置。
3.4 bitmap
签到日历,电影、广告是否被点击过,可基于 bitmap 实现,以达到极好的空间利用率。也可用于实现布隆过滤器。
4. 布隆过滤器
布隆过滤器是一个很长的初值为0的二进制数组(00000000)+一系列随机hash算法映射函数高级数据结构,主要用于判断一个元素是否在集合中。
特点:
- 高效的插入和查询
- 一个元素如果通过布隆过滤器判断结果为存在时,元素不一定存在;但是判断结果为不存在时,则一定不存在
- 布隆过滤器不能删除元素,由于涉及 hashcode 判断依据,删掉某个元素可能会导致其他落在相同位置的元素一起被删掉,导致误判率增加
应用场景:布隆过滤器可用于防止重复推荐、安全连接网址的判断、白名单黑名单校验以及解决缓存穿透问题
布隆过滤器原理:
- 初始化:初始化数组所有值均为 0
- 添加:多次 hash(key) ,取模运算,所有位置置为 1
- 判断存在:多次 hash(key) + 取模运算,判断所有位置,只要一个位置为0,则该 key 必然不在集合中,而所有位置均为 1 ,则集合该 key 极有可能存在
- 使用时最好不要让实际元素远大于初始化数量,一次给够,避免扩容;如需扩容,扩容时应重新建立布隆过滤器,重新 add 历史元素
使用 guava 自带的布隆过滤器(该功能类被标注为 @Beta ,谨慎使用),需先引入依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.0.0-android</version>
</dependency>
@Test
public void test2() {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()),
1000, // 数据量
0.001); // 误判率
bloomFilter.put("天");
bloomFilter.put("地");
bloomFilter.put("通信");
System.out.println(bloomFilter.mightContain("天"));
System.out.println(bloomFilter.mightContain("没有"));
}
另外还有优化的布谷鸟过滤器,可支持对元素的删除,因为应用还不够成熟,这里不多加篇幅叙述。
5. Redis 经典问题
5.1 缓存预热
避免用户使用时才将数据加入到缓存,而是在项目启动时或对应功能上线时就将缓存加入到 redis 中。
5.2 缓存穿透
去查一条不存在的记录,查 redis 查不到,会再查 mysql ,都查不到该条记录,但是请求每次都会到 mysql 数据库。
解决方案:
- 空对象缓存或者缺省值:当第一次查不到时,将空对象缓存或者缺省值存入缓存中,一定要设置过期时间。缺点:无法防止不同 key 的恶意攻击。
- 布隆过滤器:白名单过滤,将合法的元素加入过滤器中,通过过滤的才考虑查缓存查数据库
5.3 缓存击穿
缓存击穿就是热点 key 突然失效,大量请求直达数据库。
预防及解决方案:一般技术部门需要知道热点 key 是哪些,做到心里有数防止击穿
-
方案一:差异化失效时间或者不设置过期时间:一种差异化失效时间的实现方式是使用双缓存架构,对于热点 key ,开辟两块缓存,主A从B,更新时先更新 B 再更新 A;查询时先查询主缓存 A ,没有才查询从缓存 B
//先更新B缓存 redisTemplate.delete(JHS_KEY_B); redisTemplate.opsForList().leftPushAll(JHS_KEY_B,list); redisTemplate.expire(JHS_KEY_B, 86410L, TimeUnit.SECONDS); //再更新A缓存 redisTemplate.delete(JHS_KEY_A); redisTemplate.opsForList().leftPushAll(JHS_KEY_A,list); redisTemplate.expire(JHS_KEY_A, 86400L, TimeUnit.SECONDS); -
方案二:互斥更新,查询时采用双检加锁策略
-
方案三:随机退避,即 redis 获取不到值时休眠+重试
5.4 缓存雪崩
主要有两种情况,
- 偏向硬件运维:redis 主机挂了
- 偏向软件开发:redis 有大量 key 同时过期,大面积失效
预防+解决方案:
- redis 中 key 设置永不过期或者过期时间错开
- redis 缓存使用集群实现高可用
- 多缓存结合预防雪崩:使用 ehcache 本地缓存 + redis 缓存
- 服务降级:Hystrix 或者 sentinel 限流 & 降级
- 使用云数据库 redis 版
5.5 问题总结
| 缓存问题 | 产生原因 | 解决方案 |
|---|---|---|
| 缓存一致性 | 数据变更、缓存时效性 | 同步更新(canal)、失效更新、异步更新(MQ)、定时更新(xxl-job) |
| 缓存不一致 | 同步更新、异步更新 | 增加重试、补偿机制、最终一致 |
| 初次加载速度慢 | 初次加载无缓存 | 缓存预热 |
| 缓存穿透 | 恶意攻击 | 空对象缓存、布隆过滤器 |
| 缓存击穿 | 热点 key 失效 | 双检互斥更新、双缓存架构差异失效时间、随机退避(重试) |
| 缓存雪崩 | 缓存挂了、大量 key 过期 | 差异失效时间、快速失败熔断、集群模式 |
6. Redis 内存淘汰策略
Redis 最大占用内存默认为 0,表示不限制 Redis 内存使用,一般推荐设置内存最大为物理内存的四分之三。
- 修改最大内存,配置文件中参数:
maxmemory <bytes>;命令临时修改:config set maxmemory <bytes> - 查询内存使用情况:
info memory查询最大内存:config get maxmemory - 默认超过最大使用内存会报错
OOM
redis 过期键的删除策略:
- 立即删除:对CPU不太友好,用处理器性能换取存储空间(时间换空间)
- 惰性删除:再次访问过期键才删除,对 memory 不友好,用存储空间换处理器性能(空间换时间)
- 配置文件中参数:
lazyfree-lazy-eviction,默认 no
- 配置文件中参数:
- 定期删除:折中,但服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
LRU算法:最近最少使用页面置换算法,淘汰最长时间未被使用的页面。
LFU算法:最近最不常用页面置换算法,淘汰一定时期内被访问次数最少的页。
上面方式都不是那么好,redis 还提供了超出最大内存的兜底方案:redis 缓存淘汰策略,配置文件中检索 MAXMEMORY POLICY ,共有以下 8 种:
volatile-lru:对所有设置了过期的 key 使用 LRU 算法删除allkeys-lru:对所有 key 使用 LRU 算法删除volatile-lfu:对所有设置了过期的 key 使用 LFU 算法删除allkeys-lfu:对所有 key 使用 LFU 算法删除volatile-random:对所有设置了过期的 key 随机删除allkeys-random:对所有 key 随机删除volatile-ttl:删除马上要过期的 keynoeviction:默认方案,不驱逐任何 key ,只报错
使用选择:
- 在所有 key 都是最近最常使用,那么就需要选择 allkeys-lru 进行置换,如果不确定使用哪种策略,那么推荐使用
allkeys-lru - 如果所有的 key 的访问概率差不多,那么可选用
allkeys-random策略 - 如果对数据足够了解,能够为 key 指定过期时间,那么可以选择
volatile-ttl
7. Redis 分布式锁
一个靠谱分布式锁需要具备以下特点:
- 独占性:只能有一个线程持有
- 高可用:高并发情况下,性能良好;集群情况下,不会因为单点故障导致获取锁或释放锁失败
- 防死锁:杜绝死锁,必须有超时控制或者撤销操作,有兜底终止跳出方案
- 可重入性:同一线程获得锁后,可再次获得该锁
常见实现分布式锁方式:
- MySQL:基于唯一索引
- ZooKeeper:基于临时有序节点
- Redis:利用 redis 操作时单线程,基于
setnx或hset命令实现
7.1 分布式锁设计
- 单机锁应用:使用
synchronized或者lock - 使用
setnx实现分布式锁:添加 key 为上锁,删除 key 为解锁,继承Lock接口 - 自旋优化:使用 while 替换 if 判断,实现自旋重试
- 过期时间优化:上锁时设置过期时间,如果不设置过期时间,当微服务部署的机器上锁后未解锁便挂了将导致无法解锁,注意命令执行要求原子性
- 自动续期:当实际业务执行时间超过过期时间,为防止锁过期导致其他线程进来,需另外启动守护线程,自动加过期时间,一般频率为过期时间的 三分之一
- 防止误删key:确定 value,value 使用
UUID:threadId,确保只有锁所有者线程才能解锁 - 可重入性:改用
hset实现分布式锁,使用key field value中的 value 表示重入次数 - 使用
lua脚本保证命令原子性,使用工厂模式方便分布式锁使用对象的创建lua脚本的执行命令EVAL script numkeys key [key ...] arg [arg ...],在script中可用KEYS[1]和ARGV[1]动态传入参数
自研分布式锁重点:
- 实现
Lock接口 - 加锁关键逻辑:
- 加锁:设置 hash 对象类型 key 并设置过期时间
- 自旋
- 续期
- 解锁关键逻辑:删除 key ,但不能乱删,只能删除自己设置的 key
进阶:使用分布式锁可能会导致功能阻塞时间过长,可考虑使用分段锁概念进行优化
上面还有一个问题没解决,就是当 redis 宕机时,分布式锁也可能会受到影响而无法使用。
7.2 redission
redission 是 java 的 redis 客户端之一,提供了一些 api 方便操作。其中有支持分布式锁的实现。并实现了红锁算法 为 7.1 中分布锁存在的问题提供了解决方案。该依赖包比较重,相比 redisTemplate 多了更多分布式相关的功能但也有了更多复杂功能,有一定学习成本,个人认为可以仅当成使用 redis 的补充。
redission 的分布式锁实现逻辑与上面差不多,如不想引入 redisssion 也可考虑按上面步骤自行实现分布式锁,但需清楚无法抵御 redis 宕机情况。
- 默认锁失效时间:30s,可修改
- 看门狗(watch dog):获取锁后即添加一个看门狗线程用于续期,每
1/3过期时间检查一次锁并续期 - 红锁算法:如果需解决7.1遗留问题,则需要另外设置 redis 机器,
RedLock已被弃用,建议使用MultiLock- 容错公式:
N=2*X+1其中 N 是最终部署机器数,X 是容错机器数,注意:这里部署的机器与 redis 集群是分开的,且部署方式均非集群且均为主机。 - 红锁算法下加锁成功的条件:
- 条件1:客户端从超过半数(大于等于N/2+1)的Redis实例上成功获取到了锁;
- 条件2:客户端获取锁的总耗时没有超过锁的有效时间
- 容错公式:
springboot中同时使用 redisTemplate 与 redissonClient
引入依赖:这里没使用 redisson 的 starter 的原因是 spring-boot-starter-data-redis 与 redisson-spring-boot-starter 自动装配存在冲突问题(这里就不展开了)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.25.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
配置 redisTemplate 和 redissonClient
@MapperScan("com.springboot.mapper")
@SpringBootApplication
@EnableConfigurationProperties(RedisProperties.class)
public class SpringBootApplicationMain {
@Autowired private RedisProperties redisProperties;
public static void main(String[] args) {
SpringApplication.run(SpringBootApplicationMain.class);
}
@Bean
public RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory)
{
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式json,使用GenericJackson2JsonRedisSerializer替换默认序列化
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://" + redisProperties.getHost() + ":" + redisProperties.getPort())
.setPassword(redisProperties.getPassword());
return Redisson.create(config);
}
}
测试代码
@SpringBootTest(classes = SpringBootApplicationMain.class)
public class MainTest {
@Autowired private RedisTemplate redisTemplate;
@Autowired private RedissonClient redissonClient;
@Test
public void test1() throws InterruptedException {
redisTemplate.opsForValue().set("bbb", "人才");
RLock lock = redissonClient.getLock("aaaa");
lock.lock();
System.out.println("加锁成功");
TimeUnit.SECONDS.sleep(100);
lock.unlock();
System.out.println("解锁成功");
redisTemplate.delete("bbb");
}
}
8. Redis 线程与 IO 多路复用
Redis 快速的主要原因:
- 基于内存操作
- 优异的数据结构:Redis 的数据结构时专门设计的,而这些简单的数据结构的查找和操作的大部分时间复杂度是 O(1) 的,因此性能较高
- 多路复用和非阻塞 I/O:Redis 使用 I/O 多路复用监听多个 socket 连接客户端
- 单线程模型:单线程模型可以避免上下文切换和多线程竞争,且单线程不存在死锁问题
8.1 Redis 线程
Redis 的工作线程是单线程的,但是整个 redis 来说是多线程的。
使用单线程模型的主要原因:作者原话
- 使用单线程模型是 Redis 的开发和维护更简单,因为单线程模型方便开发和调试
- 即使使用单线程模型也并发的处理多客户端的请求,主要使用的是IO多路复用和非阻塞IO
- 对于Redis系统来说,主要的性能瓶颈是内存或者网络带宽而并非 CPU
另外,由于大 key 问题,redis 引入一些异步删除的命令,如 unlink key / flushall async 等命令
在 Redis6/7 中,Redis 将网络数据读写、请求协议解析通过多个IO线程的来处理,但真正命令的执行仍然使用主线程操作。
Redis 7 中网络I/O多线程默认关闭,如果发现 Redis 实例的 CPU 开销不大但吞吐量却没有提升,可以考虑使用多线程机制,加锁网络处理:
io-thread-do-reads:配置项为yes,表示启动多线程io-thread:设置线程个数,官方的建议是如果为 4 核的 CPU,建议线程数设置为 2 或 3,如果为 8 核 CPU 建议线程数设置为 6,线程数一定要小于机器核数,线程数并不是越大越好
8.2 网络编程
Unix网络编程中的五种 IO 模型:
- Blocking IO:阻塞 IO
- NoneBlocking IO:非阻塞 IO
- IO Multiplexing:IO 多路复用
- signal driven IO:信号驱动 IO,这里不展开讨论
- asynchronous:异步 IO,这里不展开讨论
同步和异步的理解:讨论对象是被调用者(服务提供者),重点在于获得调用结果的消息通知方式上
- 同步:要求调用者必须等待调用结果的通知
- 异步:调用者无需等待,一般由被调用方调用回调通知调用者
阻塞与非阻塞的理解:讨论对象是调用者,重点在于等消息时候的行为,调用者是否可以干别的
- 阻塞:调用方必须等待,当前线程会被挂起,什么都不能干
- 非阻塞:不会阻塞当前线程,而会立即返回(可以返回待执行等状态),可以去干别的
各种 IO 模型如何应对多连接?
-
BIO 阻塞 IO:服务端通过多线程解决多连接问题(Tomcat 7 之前就是使用该方案);两个痛点,1调用者线程阻塞,必须等待返回。2被调用者资源有限,而创建线程比较耗费系统资源,高并发情况下,可能无法支撑过多连接
public class RedisServerBIOMultiThread { public static void main(String[] args) throws IOException { ServerSocket serverSocket = new ServerSocket(6379); while(true) { Socket socket = serverSocket.accept();//阻塞1 ,等待客户端连接 new Thread(() -> { try { InputStream inputStream = socket.getInputStream(); int length = -1; byte[] bytes = new byte[1024]; System.out.println("-----333 等待读取"); while((length = inputStream.read(bytes)) != -1)//阻塞2 ,等待客户端发送数据 { System.out.println("-----444 成功读取"+new String(bytes,0,length)); System.out.println("===================="); System.out.println(); } inputStream.close(); socket.close(); } catch (IOException e) { e.printStackTrace(); } },Thread.currentThread().getName()).start(); System.out.println(Thread.currentThread().getName()); } } }public class RedisClient { public static void main(String[] args) throws IOException { Socket socket = new Socket("127.0.0.1",6379); OutputStream outputStream = socket.getOutputStream(); //socket.getOutputStream().write("RedisClient01".getBytes()); while(true) { Scanner scanner = new Scanner(System.in); String string = scanner.next(); if (string.equalsIgnoreCase("quit")) { break; } socket.getOutputStream().write(string.getBytes()); System.out.println("------input quit keyword to finish......"); } outputStream.close(); socket.close(); } } -
NIO 非阻塞 IO:在 NIO 中,一切都是非阻塞式的,在NIO模式中,只有一个线程:当一个客户端与服务端进行连接,这个socket就会加入到一个数组中,隔一段时间遍历一次(像自旋锁自旋),看这个socket的read()方法能否读到数据,这样一个线程就能处理多个客户端的连接和读取了
- accept():非阻塞式,如果没有客户端连接就返回无连接标识
- read():非阻塞式,读不到数据就返回空闲中标识,如果读取到数据时只阻塞 read() 方法读数据的时间
public class RedisServerNIO { static ArrayList<SocketChannel> socketList = new ArrayList<>(); static ByteBuffer byteBuffer = ByteBuffer.allocate(1024); public static void main(String[] args) throws IOException { System.out.println("---------RedisServerNIO 启动等待中......"); ServerSocketChannel serverSocket = ServerSocketChannel.open(); serverSocket.bind(new InetSocketAddress("127.0.0.1",6379)); serverSocket.configureBlocking(false);//设置为非阻塞模式 while (true) { for (SocketChannel element : socketList) { int read = element.read(byteBuffer); if(read > 0) { System.out.println("-----读取数据: "+read); byteBuffer.flip(); byte[] bytes = new byte[read]; byteBuffer.get(bytes); System.out.println(new String(bytes)); byteBuffer.clear(); } } SocketChannel socketChannel = serverSocket.accept(); if(socketChannel != null) { System.out.println("-----成功连接: "); socketChannel.configureBlocking(false);//设置为非阻塞模式 socketList.add(socketChannel); System.out.println("-----socketList size: "+socketList.size()); } } } } -
IO 多路复用 :多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。 采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈
select:select 其实就是把NIO中用户态要遍历的fd数组(我们的每一个socket链接,安装进ArrayList里面的那个)拷贝到了内核态,让内核态来遍历,因为用户态判断socket是否有数据还是要调用内核态的,所有拷贝到内核态后,这样遍历判断的时候就不用一直用户态和内核态频繁切换了,但存在以下几个缺点- bitmap最大1024位,一个进程最多只能处理1024个客户端
- &rset不可重用,每次socket有数据就相应的位会被置位
- 文件描述符数组拷贝到了内核态(只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)),仍然有开销。select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
- select并没有通知用户态哪一个socket有数据,仍然需要
O(n)的遍历。select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
poll:poll使用pollfd数组来代替select中的bitmap,数组没有1024的限制,可以一次管理更多的client。它和 select 的主要区别就是,去掉了 select 只能监听 1024 个文件描述符的限制;当pollfds数组中有事件发生,相应的revents置位为1,遍历的时候又置位回零,实现了pollfd数组的重用epoll:epoll 通过三步调用epoll_create、epoll_ctl和epoll_wait只轮询那些真正发出了事件的流。

| select | poll | epoll | |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | 回调 |
| 数据结构 | bitmap | 数组 | 红黑树 |
| 最大连接数 | 1024(x86) 或 2048(x64) | 无上限 | 无上限 |
| 最大支持文件描述符数 | 一般有最大值限制 | 65535 | 65535 |
| fd拷贝 | 每次调用 select ,都需要把 fd 集合从用户态拷贝到内核态 | 同 select | fd 首次调用 epoll_ctl 拷贝,每次调用 epoll_wait 不拷贝 |
| 工作效率 | 每次调用线性遍历,O(n) | 同 select | 事件通知方式,每当 fd 就绪,系统注册的回调函数就会被调用,将就绪 fd 放在 readList 里面,时间复杂度 O(1) |