学习目标:
提示:导入包
例如:
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import KFold, train_test_split
from sklearn.metrics import mean_squared_error as mse
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from folium import Map
from folium.plugins import HeatMap
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import seaborn as sns
sns.set_style('whitegrid')
!pip install -q flaml
import flaml
!pip install -q autogluon
from autogluon.tabular import TabularPredictor
数据:
提示:这里可以添加要学的内容
df_train = pd.read_csv('/kaggle/input/playground-series-s3e1/train.csv', index_col=0)
df_test = pd.read_csv('/kaggle/input/playground-series-s3e1/test.csv', index_col=0)
features, target = df_train.columns[:-1], df_train.columns[-1]
特征构造
original = fetch_california_housing()
assert original['feature_names'] == list(features)
assert original['target_names'][0] == target
df_original = pd.DataFrame(original['data'], columns=features)
df_original[target] = original['target']
EDA:
提示:Missing values
df_train.isna().sum()
查看分布
ncols = 3
nrows = np.ceil(len(df_train.columns)/ncols).astype(int)
cols = df_train.corrwith(df_train[target]).abs().sort_values(ascending=False)
fig, axs = plt.subplots(ncols=ncols, nrows=nrows, figsize=(10,nrows*2))
for idx, (c, corr) in enumerate(cols.items()):
row = idx // ncols
col = idx % ncols
sns.histplot(df_train, x=c, ax=axs[row, col])
axs[row,col].set_xlabel(f'{c}, corr = {corr:.3f}')
plt.tight_layout()
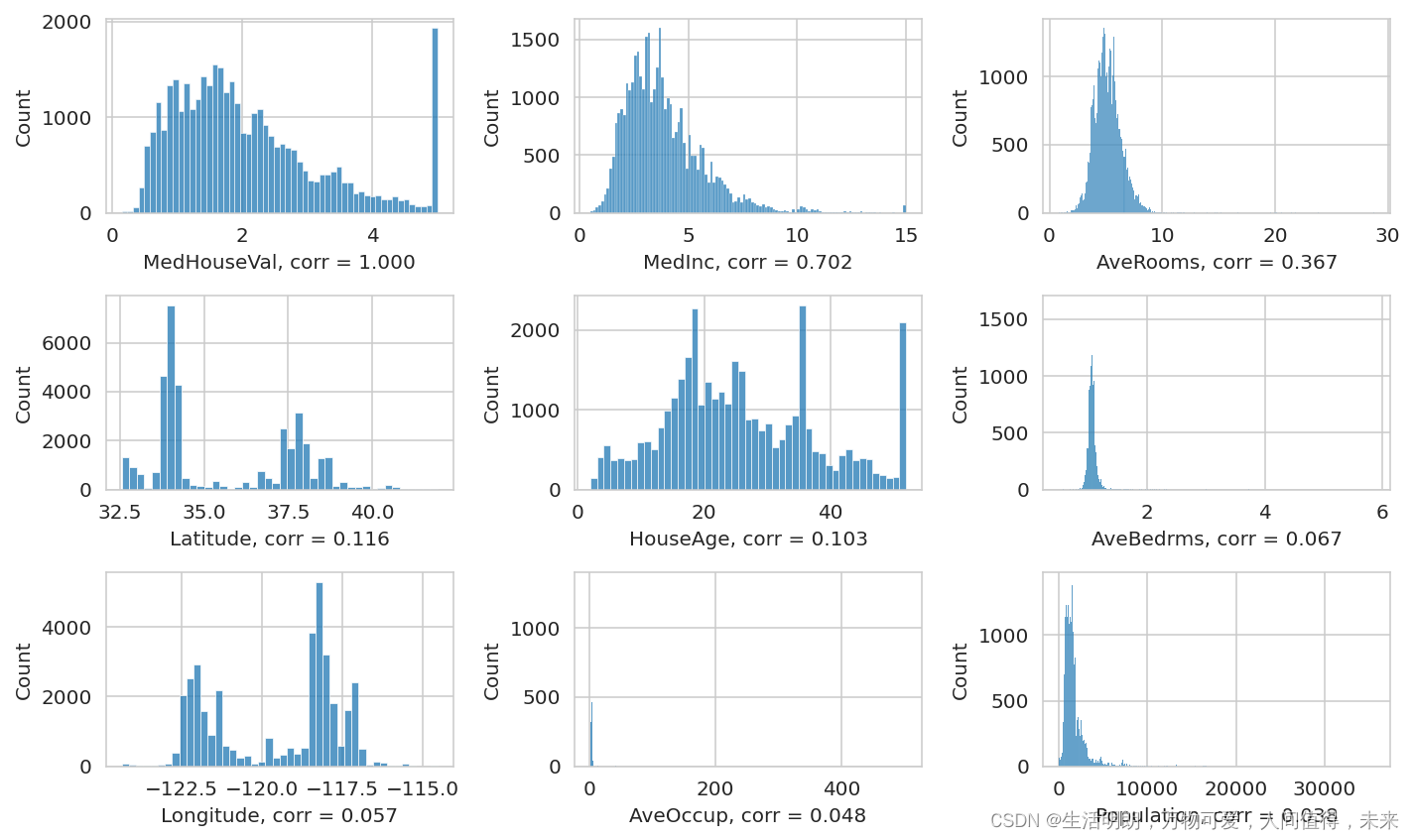
Some observations:
House value is capped
MedInc has the highest correlation with house value
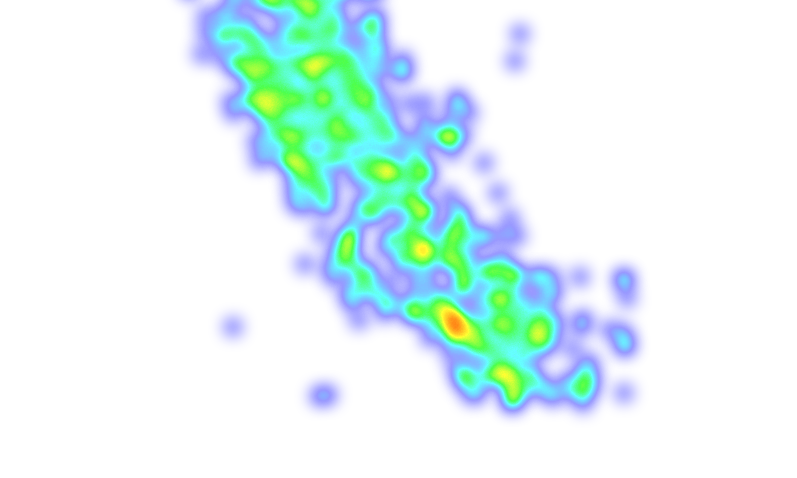
Look at the data on a map
Credit: https://www.kaggle.com/code/jcaliz/ps-s03e01-a-complete-eda
heat_data = [[row['Latitude'],row['Longitude']] for _, row in df_train.iterrows()]
heat_map = Map(df_train[['Latitude', 'Longitude']].mean(axis=0), zoom_start=6)
HeatMap(heat_data, radius=10).add_to(heat_map)
heat_map
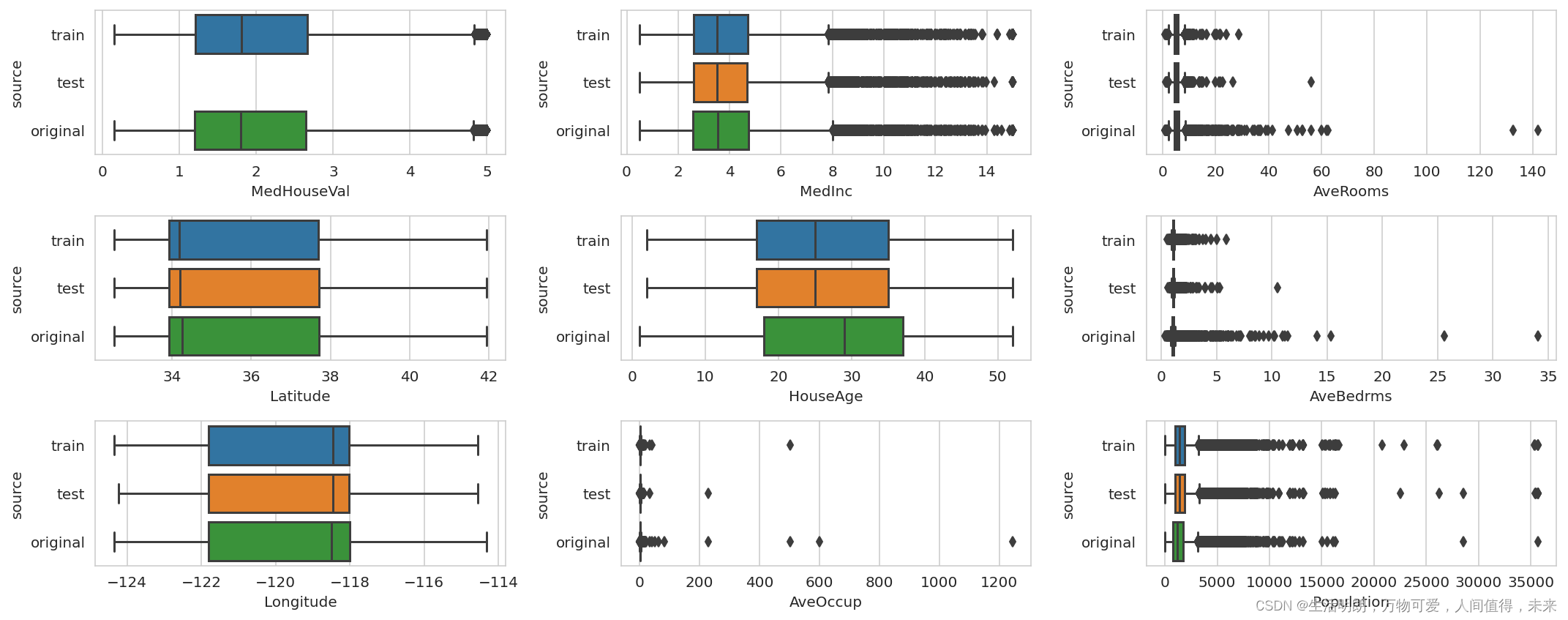
Compare with original data:
提示:这里统计学习计划的总量
例如:
df_train['source'] = 'train'
df_test['source'] = 'test'
df_original['source'] = 'original'
df_mixed = pd.concat([df_train, df_test, df_original])
fig, axs = plt.subplots(ncols=ncols, nrows=nrows, figsize=(15,nrows*2))
for idx, (c, corr) in enumerate(cols.items()):
row = idx // ncols
col = idx % ncols
sns.boxplot(data=df_mixed, x=c, y='source', ax=axs[row, col])
plt.tight_layout()
Baseline with gradient boosting
X_train, y_train = df_train[features].values, df_train[target].values
X_test = df_test[features].values
oof = np.zeros(len(df_train))
models = []
for fold, (idx_tr, idx_vl) in enumerate(cv.split(X_train)):
X_tr, y_tr = X_train[idx_tr], y_train[idx_tr]
X_vl, y_vl = X_train[idx_vl], y_train[idx_vl]
model = LGBMRegressor()
model.fit(X_tr, y_tr)
oof[idx_vl] = model.predict(X_vl)
models.append(model)
r = mse(y_vl, oof[idx_vl], squared=False)
print(f'Fold {fold} rmse: {r:.4}')
print(f'OOF rmse: {mse(y_train, oof, squared=False):.4}')
Fold 0 rmse: 0.5708
Fold 1 rmse: 0.5685
Fold 2 rmse: 0.5595
Fold 3 rmse: 0.5704
Fold 4 rmse: 0.5764
OOF rmse: 0.5692
Adding original data
df_combined = pd.concat([df_train, df_original]).drop(columns=['source'])
X_train, y_train = df_combined[features].values, df_combined[target].values
oof = np.zeros(len(X_train))
models = []
for fold, (idx_tr, idx_vl) in enumerate(cv.split(X_train)):
X_tr, y_tr = X_train[idx_tr], y_train[idx_tr]
X_vl, y_vl = X_train[idx_vl], y_train[idx_vl]
model = LGBMRegressor()
model.fit(X_tr, y_tr)
oof[idx_vl] = model.predict(X_vl)
models.append(model)
r = mse(y_vl, oof[idx_vl], squared=False)
print(f'Fold {fold} rmse: {r:.4}')
print(f'OOF rmse: {mse(y_train, oof, squared=False):.4}')
Fold 0 rmse: 0.53
Fold 1 rmse: 0.5367
Fold 2 rmse: 0.5385
Fold 3 rmse: 0.5372
Fold 4 rmse: 0.5411
OOF rmse: 0.5367
参考文章:https://www.kaggle.com/code/phongnguyen1/s03e01-original-data-boost-automl