在北极的中心地带,圣诞老人的精灵团队面临着巨大的后勤挑战:如何处理来自世界各地儿童的数百万封信件。 圣诞老人表情坚定,他决定是时候将人工智能纳入圣诞节行动了。

圣诞老人坐在配备了最新人工智能技术的电脑前,开始在 Jupyter Notebook 中编写 Python 脚本。 我们的目标既简单又雄心勃勃:利用生成式人工智能和 LLM 的力量来解释手写字母并提取必要的数据,并将其组织在 Elasticsearch 中。
安装
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:
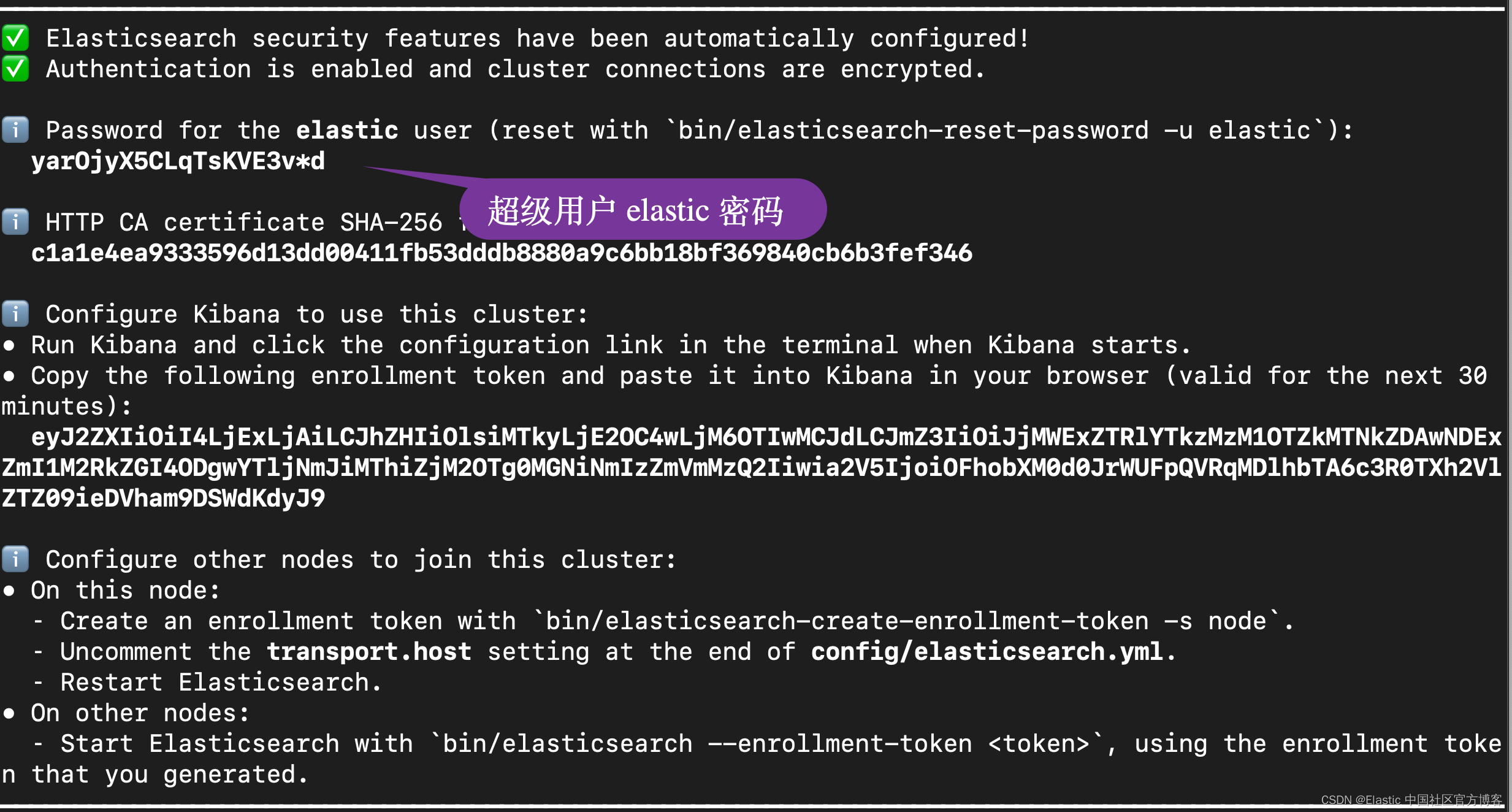
在下面的展示中,我将使用 Elastic Stack 8.11 来进行展示。
Python
你可以安装自己喜欢的 Python 版本。版本在 3.8 及以上。我们还需要安装如下的 Python 包:
pip3 install python-dotenv elasticsearch langchain openai数据
为了展示方便,我们需要在当前的目录下创建如下的 .env 文件:
.env
$ pwd
/Users/liuxg/python/elser
$ cat .env
ES_USER="elastic"
ES_PASSWORD="yarOjyX5CLqTsKVE3v*d"
ES_ENDPOINT="localhost"
OPENAI_API_KEY="YourOwnOpenAiKey"你可以根据自己的 Elasticsearch 配置进行修改上面的值。你需要申请一个 OpenAI 的 key 来进行使用。
为了能够访问 Elasticsearch,我们还需要把 Elasticsearch 的证书拷贝到当前的工作目录中:
$ pwd
/Users/liuxg/python/elser
$ cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt我们想要解密的手写信件可以在地址进行下载:

应用设计
我们在项目当前的目录下运行:
$ pwd
/Users/liuxg/python/elser
$ jupyter notebook这样我们就开创建我们的 notebook。第一步是设置环境变量,该变量将用作访问 OpenAI 和 Elasticsearch API 的凭据。
import os
from dotenv import load_dotenv
load_dotenv()
# OpenAI API Key
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
OPENAI_API_URL = "https://api.openai.com/v1/chat/completions"
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")
openai_api_key=os.getenv('OPENAI_API_KEY')接下来,圣诞老人使用圣诞信件的数字化图像编写了一个脚本,使用 “gpt-4-vision-preview” 提取文本。 这一关键步骤将手写文字转变为数字文本。 “GPT-4-vision-preview” 是 OpenAI 的 GPT-4 语言模型的实验版本,扩展后包含图像处理和分析功能。
from PIL import Image
import requests
import numpy as np
from langchain.chat_models import ChatOpenAI
from langchain.schema.messages import HumanMessage, SystemMessage
image_path = 'https://i.imgur.com/IxC9lgd.png'
chat = ChatOpenAI(model="gpt-4-vision-preview", max_tokens=512, openai_api_key=openai_api_key)
result = chat.invoke(
[
HumanMessage(
content=[
{"type": "text", "text": "What is in the picture? Please provide a detailed introduction."},
{
"type": "image_url",
"image_url": {
"url": image_path,
"detail": "auto",
},
},
]
)
]
)
print(result.content)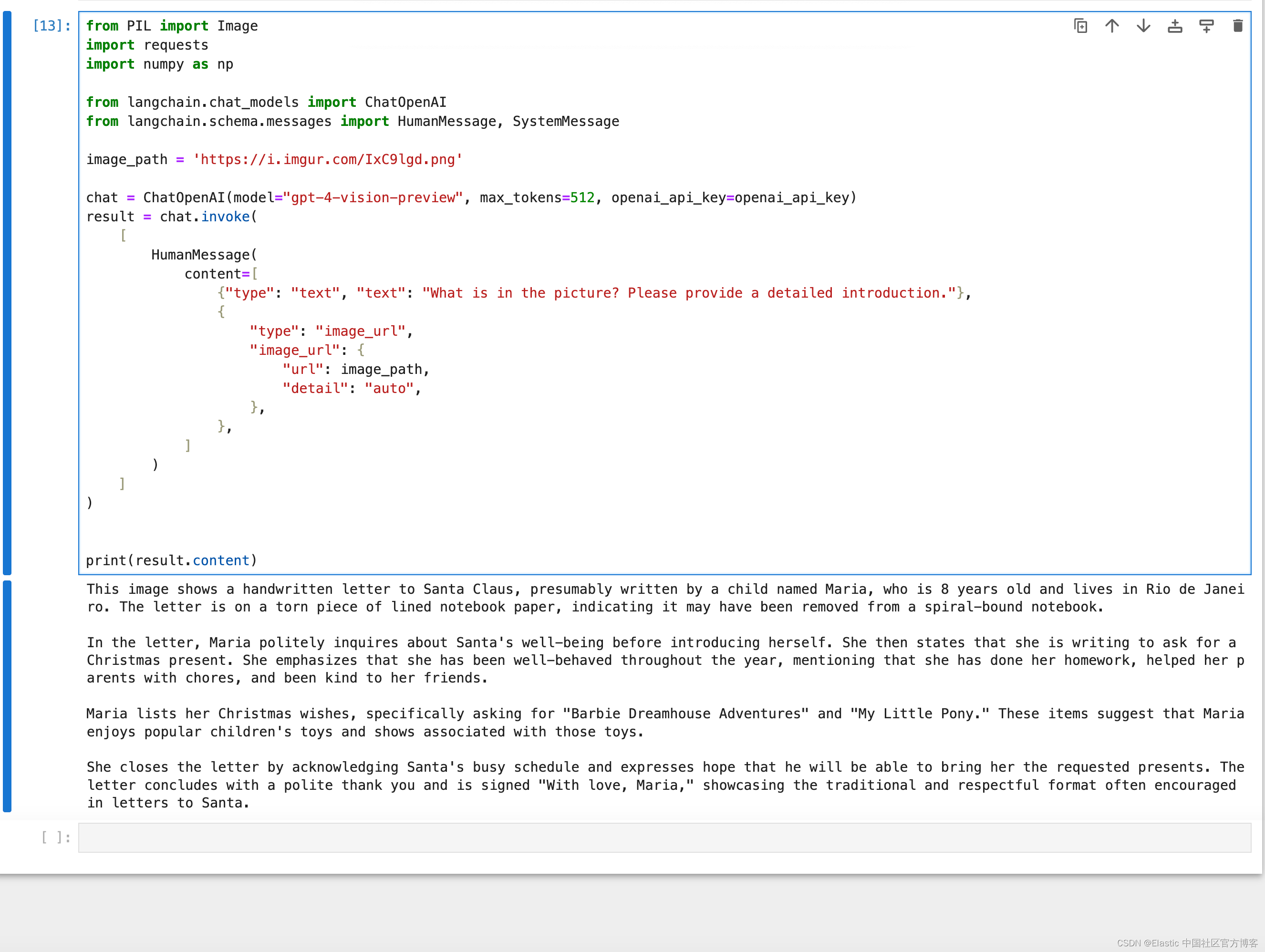
然后,LangChain 开始行动,分析文本并识别关键元素,例如孩子的名字和愿望清单。
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser
chain = ChatOpenAI(model="gpt-3.5-turbo", max_tokens=1024)
prompt = PromptTemplate.from_template(
"""
Extract the list and child's name from the text below and return the data in JSON format using the following name:
- "child_name", "wishlist".
{santalist}
"""
)
runnable = prompt | chain | StrOutputParser()
letter = result.content
wishlist = runnable.invoke({"santalist": letter})
print(wishlist)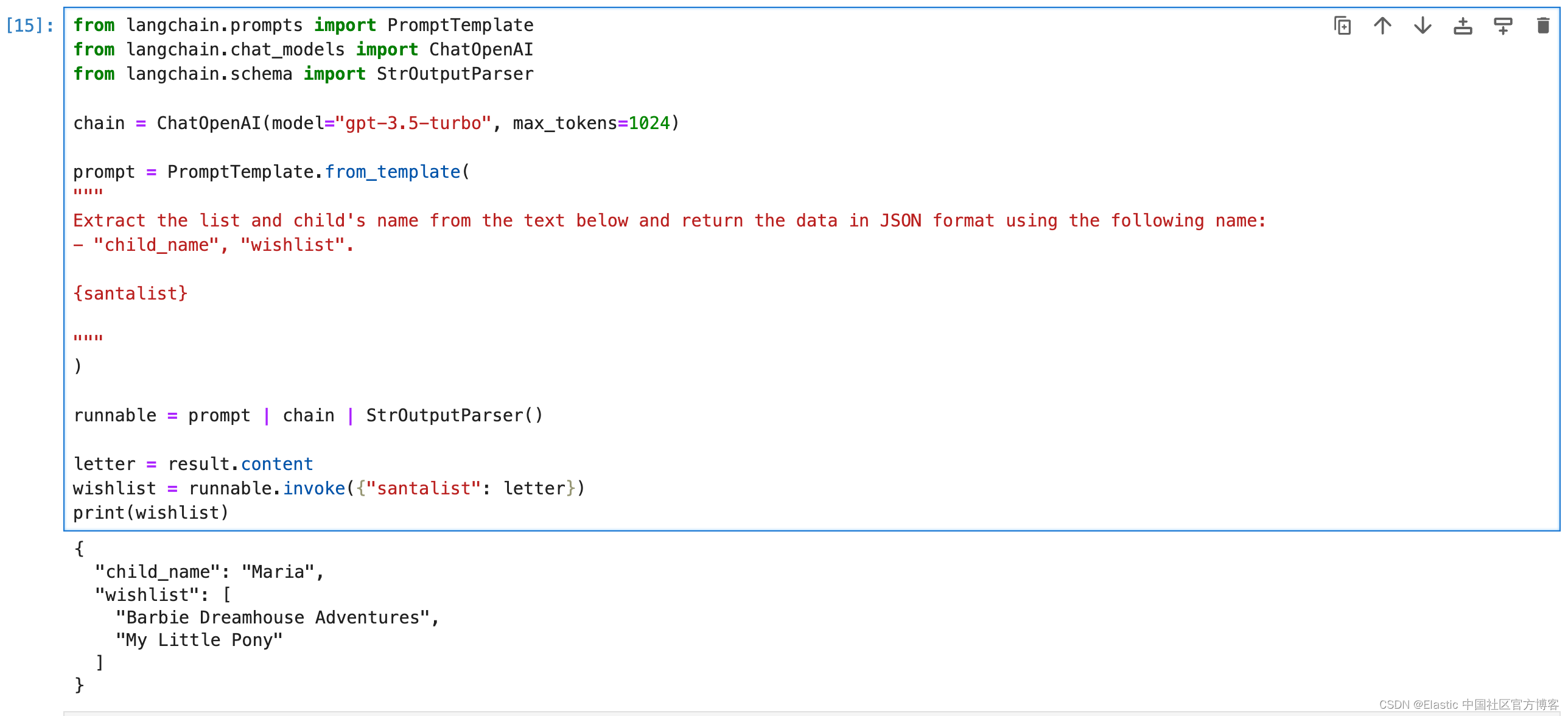
圣诞老人决定丰富一下数据库,并要求人工智能估算这些礼物的重量。 这样,他就可以在 Kibana 中生成一份清单,将孩子们的礼物分为每个袋子并放入雪橇的空间中 - 什么组织!
chain = ChatOpenAI(model="gpt-3.5-turbo", max_tokens=1024)
prompt = PromptTemplate.from_template(
"""
{santalist_json}
From the JSON above, include a new attribute in the JSON called 'weight',
which will calculate the total estimated weight of each item in the list in kilograms.
You will first need to estimate the weight of each item individually.
After that, sum these values to obtain the total weight.
Extract only the numerical value.
"""
)
runnable = prompt | chain | StrOutputParser()
new_wishlist = runnable.invoke({"santalist_json": wishlist})
print(new_wishlist)
现在,数据已结构化,是时候将它们写入到 Elasticsearch 了。
from elasticsearch import Elasticsearch
import json
url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
es = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
es.info() # should return cluster info
# Parse the JSON string
json_string = new_wishlist
data = json.loads(json_string)
# Index name
index_name = "santa_claus_list"
# Index the document
response = es.index(index=index_name, document=data)
# Print the response from Elasticsearch
print(response)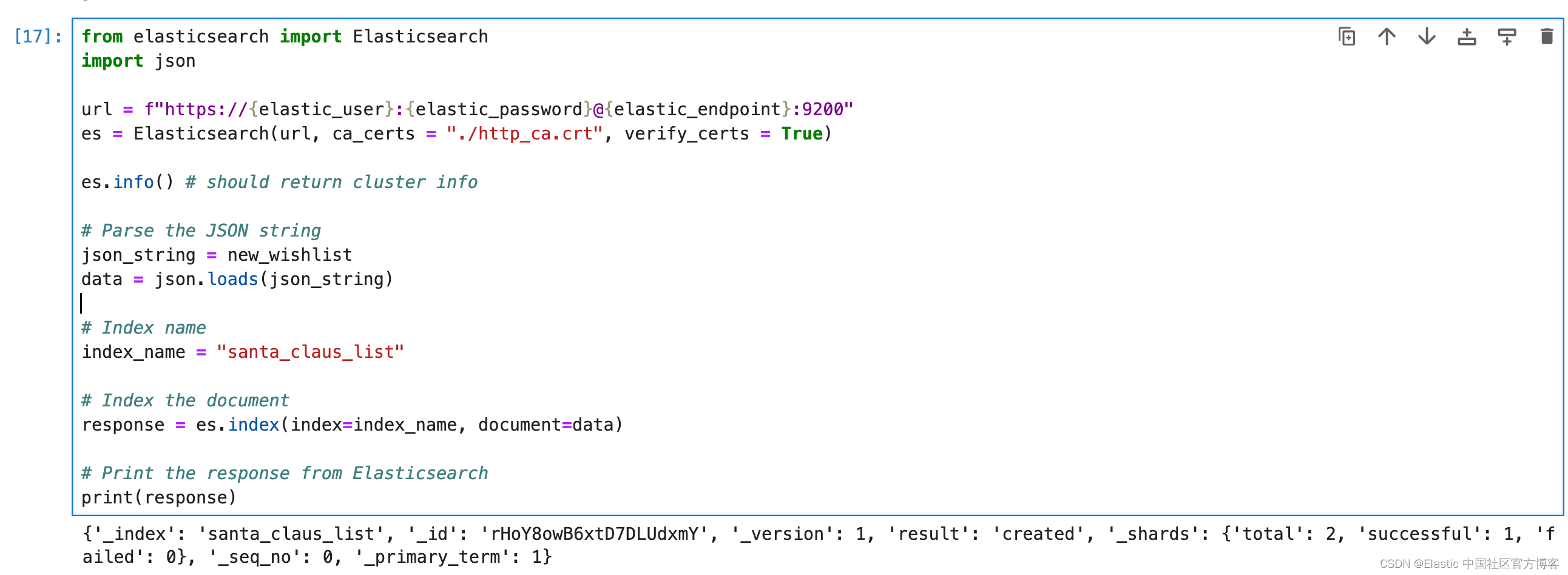
使用 Dev Tools(集成到 Kibana 中的工具),圣诞老人和精灵可以轻松搜索和分析数据。 这样可以清楚地了解今年的礼物趋势、信件最常出现的位置,甚至可以识别那些表达特殊或紧急愿望的信件,当然还有礼物的重量。 正如使用 ES|QL 的查询一样 (你需要安装 Elastic Stack 8.11 及以上版本才可以使用 ES|QL)。
POST /_query?format=txt
{
"query": """
FROM santa_claus_list
| STATS sum_toy = SUM(weight) BY child_name
| LIMIT 100
"""
}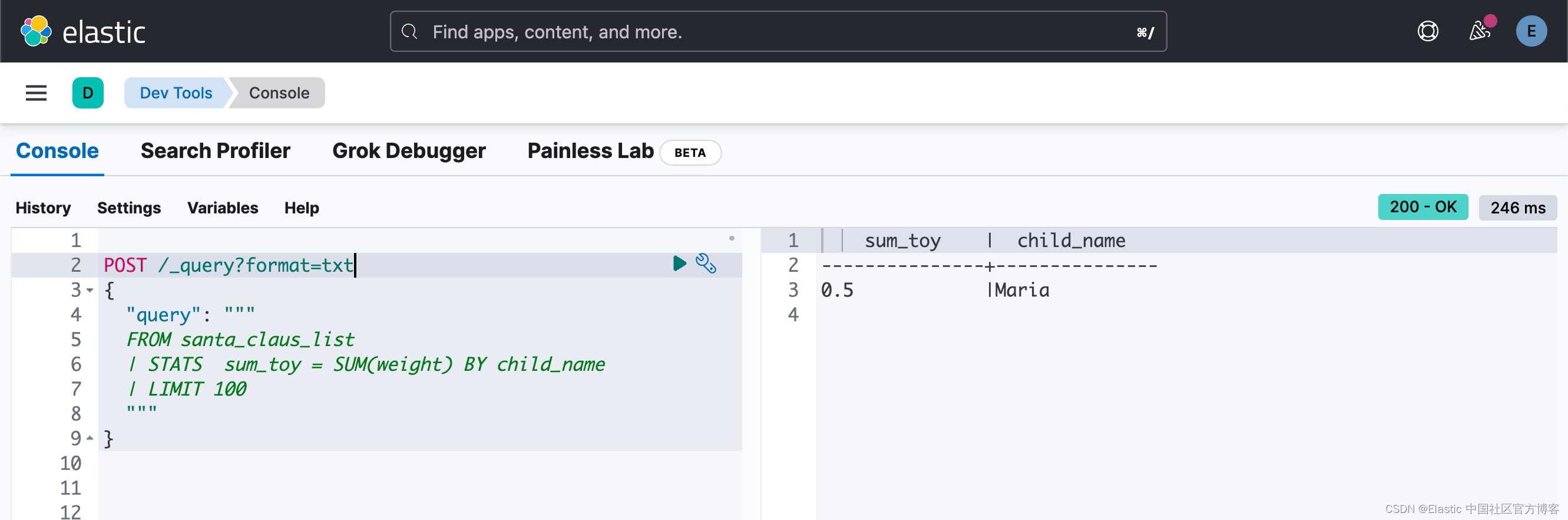
到目前为止,我们只处理了一封信。我们可以按照同样的套路对多封信进行处理。最终我们可以得到像如下的数据统计:
# result
sum_toy | child_name
---------------+---------------
30.5 |Maria
1.5 |Mike
3.0 |Theo
2.5 |Isabella
40.0 |William
30.0 |Olivia 
借助这一创新解决方案,圣诞老人不仅能够更高效地满足请求,而且还获得了对世界各地儿童的欢乐和希望的宝贵洞察,这一切都得益于人工智能、LangChain和 Elasticsearch 的力量。 今年的圣诞节注定会是最神奇、最井然有序的一个!
上面的代码可以在地址下载:https://github.com/liu-xiao-guo/semantic_search_es/blob/main/Deciphering%20Handwritten%20Christmas%20Letters%20with%20LLM%2C%20LangChain%20and%20Elasticsearch.ipynb