ConcurrentHashMap在哪些地方做了并发控制
- ✅典型解析
- ✅初始化桶阶段
- 🟢桶满了会自动扩容吗
- 🟠自动扩容的时间频率是多少
- ✅put元素阶段
- ✅扩容阶段
- 🟠 拓展知识仓
- 🟢ConcurrentSkipListMap和ConcurrentHashMap有什么区别
- ☑️简单介绍一下什么是跳表
- 🟢跳表和普通链表有什么区别
- 🟡为什么跳表比普通链表更快
- 🟠跳表的优点和缺点是什么
- ✅SynchronizedList和Vector的区别
✅典型解析
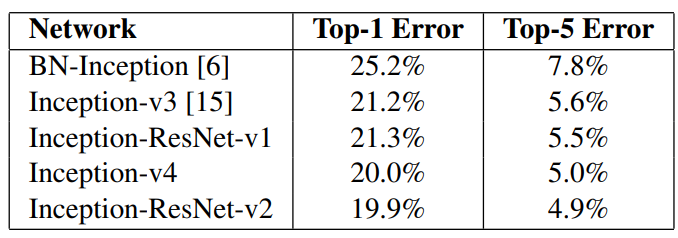
对于JDK1.8来说,如果用一句话来讲的话,
ConcurrentHashMap是通过synchronized和CAS自旋保证的线程安全,要想知道ConcurrentHashMap是如何加锁的,就要知道HashMap在哪些地方会导致线程安全问题,如初始化桶数组阶段和设置桶,插入链表,树化等阶段,都会有并发问题。
解决这些问题的前提,就要知道到底有多少线程在对map进行写入操作,这里ConcurrentHashMap通过sizeCtl变量完成,如果其为负数,则说明有多线程在操作,且 Math.abs(sizeCtl)即为线程的数目。
✅初始化桶阶段
如果在此阶段不做并发控制,那么极有可能出现多个线程都去初始化桶的问题,导致内存浪费。所以Map在此外采用自旋操作和CAS提作,如果此时没有线程初始化,则去初始化,否则当前线程让出CPU时间片,等待下一次唤醒,源码如下:
while ((tab = table) == null tab.length == 0) {
if ((sc = sizeCt1) < 0) {
Thread.yield(); // lost initialization race; just spin
}
else if (U.compareAndSetInt(this,SIZECTL,sc,-1)) {
try {
if ((tab = table) == null || tab.length == 0) {
//省略
}
} finally {
sizeCtl = sc;
}
break;
}
}
随着时间的推移,ConcurrentHashMap可能需要重新哈希(rehashing)来调整桶的数量以适应数据的变化。这通常发生在添加或删除元素时,如果发现当前桶的数量不足以容纳所有元素,就会触发重新哈希过程。
🟢桶满了会自动扩容吗
当ConcurrentHashMap中的桶满了,它会自动进行扩容。这个过程是自动的,由集合自动完成的。具体的扩容阈值是集合的当前数组长度乘以负载因子。负载因子在ConcurrentHashMap中的默认值是0.75。当某个桶中的实体数量超过这个阈值时,就会触发扩容操作。扩容操作会创建新的桶,并将原有数据重新散列到新的桶中,以确保数据始终是均匀分布的。在ConcurrentHashMap中,扩容操作通过分段锁实现,这意味着扩容只需要锁定当前段,不需要锁定整个表,从而不会影响其他线程的读写操作。总的来说,ConcurrentHashMap的扩容机制既简单又高效。
🟠自动扩容的时间频率是多少
在ConcurrentHashMap中,自动扩容的时间频率是由数据插入和读取的频率决定的。当某个桶中的实体数量超过设定的阈值时,就会触发扩容操作。这个阈值是集合的当前数组长度乘以负载因子,默认负载因子是0.75。因此,当数据频繁插入或读取时,如果超过了阈值,就会触发扩容操作。
注意:ConcurrentHashMap的扩容操作是自动的,不需要手动触发。扩容操作通过重新散列原有数据到新的桶中来实现,这个过程是线程安全的,不会影响其他线程的读写操作。
由于ConcurrentHashMap的扩容机制是根据数据插入和读取的频率动态调整的,因此无法确定具体的扩容时间频率。扩容的时间频率取决于实际的使用情况,例如数据的插入和读取频率,以及数据的分布情况等因素。
我们来看一个代码片段Demo,将用Java代码详细解释ConcurrentHashMap的自动扩容机制:
首先,我们先创建一个简单的ConcurrentHashMap实例:
import java.util.concurrent.ConcurrentHashMap;
/**
* ConcurrentHashMap实例
*/
public class ConcurrentHashMapDemo {
public static void main(String[] args) {
ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap<>();
}
}
在ConcurrentHashMap中,桶的数量是通过数组长度来表示的。默认情况下,桶的数量是2的N次方,这样可以更有效地利用位运算进行索引计算。当我们向ConcurrentHashMap中插入元素时,它会根据元素的hash值计算出对应的桶索引,并将元素存储在该桶的链表中。
当某个桶中的元素数量超过设定的阈值时,就会触发扩容操作。扩容操作的实现方式是创建一个新的桶数组,并将原有数据重新散列到新的桶中。下面是一个简单的扩容示例:
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapDemo {
public static void main(String[] args) {
ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap<>();
// 添加元素,触发扩容操作
for (int i = 0; i < 1000; i++) {
map.put(i, "value" + i);
}
// 输出桶的数量和每个桶的元素数量
System.out.println("桶数量:" + map.capacity());
for (int i = 0; i < map.capacity(); i++) {
System.out.println("桶" + i + "de元素数量:" + map.segmentFor(i).hashTable.length);
}
}
}
上面示例中,通过循环向ConcurrentHashMap中添加了1000个元素。由于默认的负载因子是0.75,当元素数量超过数组长度的0.75倍时,就会触发扩容操作。扩容操作会创建一个新的桶数组,并将原有数据重新散列到新的桶中。我们可以使用map.capacity()方法获取当前桶的数量,并通过map.segmentFor(i).hashTable.length获取每个桶的元素数量。输出结果将会显示桶的数量和每个桶的元素数量。
关于这个知识点不明白,可以去专栏里自行查阅,有讲。
在这里我先方一个链接:【Java集合篇】为什么HashMap的Cap是2^n,如何保证?
🟡注意,在ConcurrentHashMap中,扩容操作是通过分段锁实现的。这意味着扩容只需要锁定当前段,不需要锁定整个表,从而不会影响其他线程的读写操作。这种机制使得ConcurrentHashMap能够支持高并发访问,并且能够随着数据的变化自动调整桶的数量,以适应实际的使用情况。
✅put元素阶段
如果hash后发现桶中没有值,则会直接采用CAS插入并且返回
如果发现桶中有值,则对流程按照当前的桶节点为维度进行加锁,将值插入链表或者红黑树中,源码如下:
//省略....
//如果当前桶节点为nu11,直接CAS插入
else if ((f = tabAt(tab,i = (n - 1) & hash)) == null) {
if (casTabAt(tab,i,null, new Node<K,V>(hash, key,value))) {
break; // no lock when adding to empty bin
}
} else { //省略....
//如果桶节点不为空,则对当前桶进行加锁
V oldVal = null:
synchronized (f) {
}
}
✅扩容阶段
多线程最大的好处就是可以充分利用CPU的核数,带来更高的性能,所以ConcurrentHashMap并没有一味的通过CAS或者锁去限制多线程,在扩容阶段,ConcurrentHashMap就通过多线程来加加速扩容。
在分析之前,我们需要知道两件事情:
1 .
ConcurrentHashMap通过ForwardingNode来记录当前已经桶是否被迁移,如果oldTable[i] instance0f ForwardingNode则说明处于节点的桶已经被移动到newTable中了。它里面有一个变量nextTable,指向的是下一次扩容后的table。
2 .transterindex记录了当前扩容的桶索引,最开始为oldlale.ength,它给下一个线程指定了要扩容的节点。
得知到这两点后,我们可以梳理出如下扩容流程:
1 .
ConcurrentHashMap通过ForwardingNode来记录当前已经桶是否被迁移,如果oldTable[i] instanceof ForwardingNode则说明处于节点的桶已经被移动到newTable中了。它里面有一个变量nextTable,指向的是下一次扩容后的table。
2 .transterindex记录了当前扩容的桶索引,最开始为oldlale.ength,它给下一个线程指定了要容的节点。
3 . 再将当前线程扩容后的索引赋值给transferlndex,譬如,如果transferlndex原来是32,那么赋值之后transferlndex应该变为16,这样下一个线程就可以从16开始扩容了。这里有一个小问题,如果两个线程同时拿到同一段范围之后,该怎么处理? 答案是ConcurrentHashMap会通过CAS对transferlndex进行设置,只可能有一个成功,所以就不会存在上面的问题
之后就可以对真正的扩容流程进行加锁操作了。
🟠 拓展知识仓
🟢ConcurrentSkipListMap和ConcurrentHashMap有什么区别
ConcurrentSkipListMap 是一个内部使用跳表,并且支持排序和并发的一个Map,是线程安全的。一般很少会被用到,也是一个比较偏门的数据结构。
首先,我们来看看ConcurrentHashMap:
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapDemo {
public static void main(String[] args) {
ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap<>();
// 添加元素
for (int i = 0; i < 1000; i++) {
map.put(i, "value" + i);
}
// 查询元素
for (int i = 0; i < 1000; i++) {
String value = map.get(i);
System.out.println("Key " + i + " maps to value " + value);
}
}
}
代码中,创建了一个ConcurrentHashMap实例并向其中添加了1000个元素。我们可以通过get()方法来查询元素的值。由于ConcurrentHashMap使用了分段锁技术,多个线程可以同时访问不同的段,从而实现高并发访问。
接下来,我们来看看ConcurrentSkipListMap:
import java.util.concurrent.ConcurrentSkipListMap;
public class ConcurrentSkipListMapDemo {
public static void main(String[] args) {
ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();
// 添加元素
for (int i = 0; i < 1000; i++) {
map.put(i, "value" + i);
}
// 查询元素
for (int i = 0; i < 1000; i++) {
String value = map.get(i);
System.out.println("Key " + i + " maps to value " + value);
}
}
}
代码中,我们创建了一个ConcurrentSkipListMap实例并向其中添加了1000个元素。我们同样可以通过get()方法来查询元素的值。ConcurrentSkipListMap使用了跳表数据结构,可以保证元素的有序性,并且查询效率较高。与ConcurrentHashMap相比,它在插入和删除操作上具有更高的开销,但查询效率更高。
ConcurrentSkipListMap 和 ConcurrentHashMap 的主要区别:
1 . 底层实现方式不同。ConcurrentSkipListMap底层基于跳表。ConcurrentHashMap底层基于Hash桶和红黑树。
2 . ConcurrentHashMap不支持排序。ConcurrentSkipListMap支持排序。

☑️简单介绍一下什么是跳表
跳表(Skip List)是一种数据结构,它可以在有序链表的基础上增加多级索引,通过索引来实现快速查找。跳表全称为跳跃列表,它允许快速查询、插入和删除一个有序连续元素的数据链表。
跳表实质上是一种可以进行二分查找的有序链表,它在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。索引的层级通过随机技术决定,元素应该在哪几层,其中的搜索、插入、删除操作的时间均为O(logn),因此跳表的平均查找和插入时间复杂度都是O(logn)。
相比之下,在一个有序数组或链表中进行插入/删除操作的时间为O(n),最坏情况下为O(n)。而跳表的原理非常简单,目前在Redis和LevelDB中都有用到。
🟢跳表和普通链表有什么区别
跳表和普通链表的区别主要在于数据结构的设计和查询、插入、删除操作的性能。
首先,普通链表是线性数据结构,每个节点包含数据域和指针域,指针域指向下一个节点。普通链表中的节点只有一个指针,只能顺序扫描,查询效率相对较低,需要遍历链表直到找到目标节点。
而跳表则通过增加维度来提升查询效率。跳表中的节点有多层索引,每层索引都有一个指针指向下一层索引,最下一层是数据域。跳表的查询、插入、删除操作可以在O(logn)的时间复杂度内完成,因为可以通过多级索引快速定位到目标节点。
其次,普通链表的节点只有一个指针,只能顺序扫描,插入和删除操作需要移动大量节点,时间复杂度为O(n)。而跳表的插入和删除操作可以在O(logn)的时间复杂度内完成,因为可以通过多级索引快速定位到目标节点,然后调整指针即可。
最后,普通链表的查询、插入、删除操作需要遍历链表元素,空间复杂度为O(n)。而跳表的查询、插入、删除操作可以在O(logn)的时间复杂度内完成,因此空间复杂度也为O(logn)。
总之,跳表通过增加维度来提升查询效率,同时减少插入和删除操作的时间复杂度。相比普通链表,跳表在空间和时间效率上都有更好的表现。
🟡为什么跳表比普通链表更快
跳表比普通链表更快的原因在于其数据结构的设计和查询、插入、删除操作的实现方式。
首先,跳表通过在链表中添加多级索引,实现了快速查找。在跳表中,每一层索引都是前一层的子集,且每一层索引都是有序的。这样,在查找元素时,可以从最高层索引开始,逐层向下查找,直到找到目标元素或到达最底层。这种分层查找的方式大大减少了搜索范围,提高了查询效率。
其次,跳表的插入和删除操作也更加高效。在普通链表中,插入和删除操作需要移动大量节点,时间复杂度为O(n)。而在跳表中,插入和删除操作可以在O(logn)的时间复杂度内完成。这是因为跳表通过多级索引快速定位到目标节点,然后调整指针即可。这种设计方式减少了插入和删除操作的时间复杂度,提高了数据操作的效率。
跳表通过增加多级索引和优化查询、插入、删除操作的实现方式,提高了空间和时间效率,因此比普通链表更快。
🟠跳表的优点和缺点是什么
跳表的优点主要包括:
- 查询效率高:跳表通过多级索引实现了快速查找,查询时间复杂度为O(logn),比普通链表更高效。
- 插入和删除操作效率高:跳表的插入和删除操作可以在O(logn)的时间复杂度内完成,比普通链表更快。
- 支持有序性:跳表可以保证元素的有序性,因为每一层索引都是有序的。
- 空间效率高:跳表的空间复杂度为O(logn),比普通链表更节省空间。
跳表存在缺点:
- 实现复杂度较高:跳表的实现比普通链表更复杂,需要维护多级索引和指针。
- 代码实现难度大:由于跳表的实现较为复杂,因此代码实现难度较大。
- 需要额外空间:跳表需要额外的空间来存储索引和指针信息。
跳表具有查询效率高、插入和删除操作效率高、支持有序性和空间效率高等优点,但也存在实现复杂度高、代码实现难度大和需要额外空间等缺点。在实际应用中,需要根据具体需求选择是否使用跳表。
✅SynchronizedList和Vector的区别
Vector是 java.util 包中的一个类。SynchronizedList是java.util.Collections中的一人静态内部类,在多线程的场景中可以直接使用Vector类,也可以使用Collections.synchronizedList(List list)方法来返回一个线程安全的List。
1 . 如果使用add方法,那么他们的扩容机制不一样
2 . SynchronizedList可以指定锁定的对象。即锁粒度是同步代码块。而Vector的锁粒度是同步方法
3 . SynchronizedList有很好的扩展和兼容功能。他可以将所有的List的子类转成线程安全的类
4 . 使用SynchronizedList的时候,进行遍历时要手动进行同步处理
5 . SynchronizedList可以指定锁定的对象。












![[足式机器人]Part2 Dr. CAN学习笔记-动态系统建模与分析 Ch02-7二阶系统](https://img-blog.csdnimg.cn/direct/7f1982b78d7f4338becc106b80a464f0.png#pic_center)