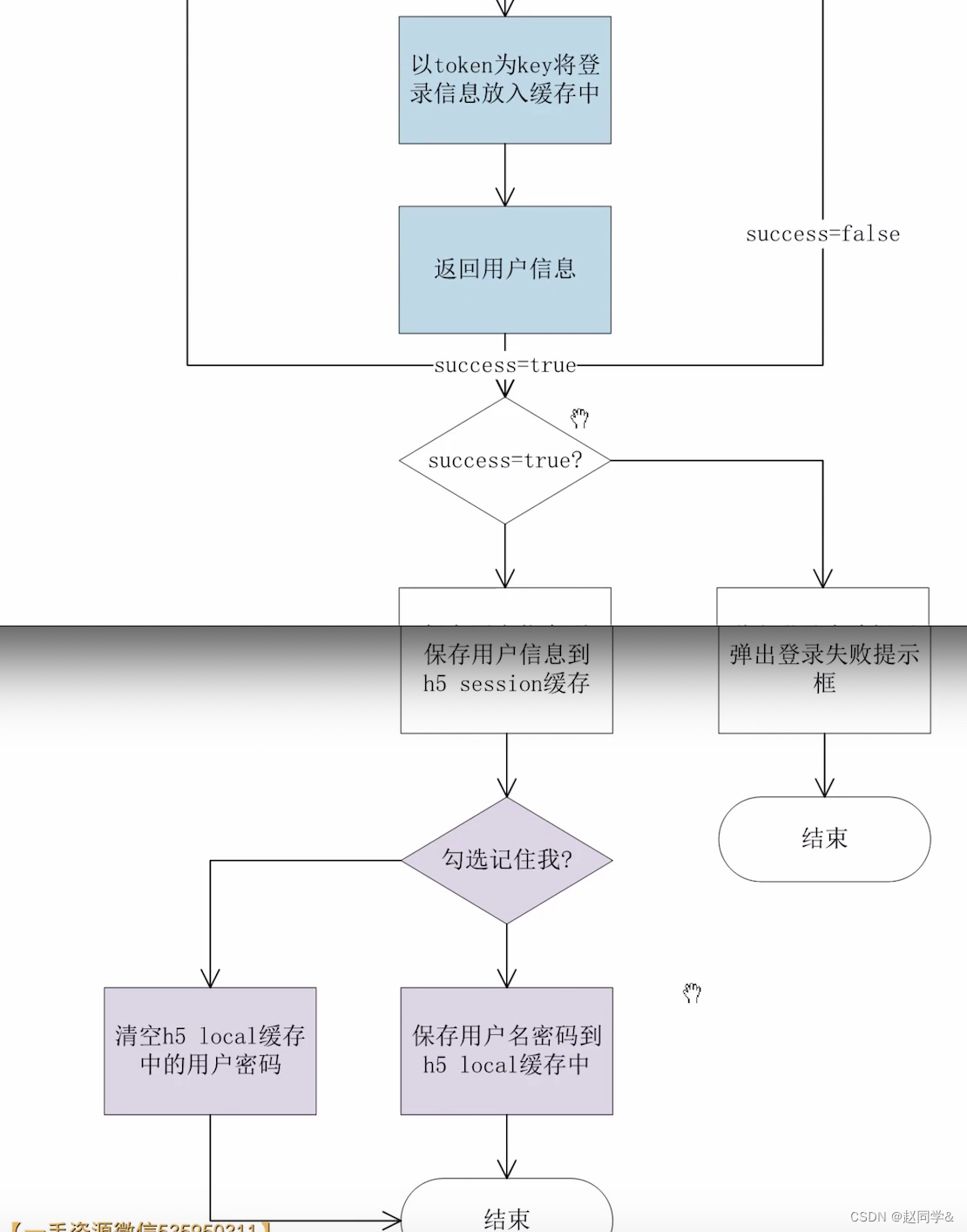
第三部分:C语言变量和数据类型
本章也是C语言的基础知识,主要讲解变量、数据类型以及运算符,这其中涉及到了数据的存储格式以及不同进制。
一、大话C语言变量和数据类型
在《数据在内存中的存储(二进制形式存储)》一节中讲到:
- 计算机要处理的数据(诸如数字、文字、符号、图形、音频、视频等)是以二进制的形式存放在内存中的;
- 我们将8个比特(Bit)称为一个字节(Byte),并将字节作为最小的可操作单元。
我们不妨先从最简单的整数说起,看看它是如何放到内存中去的。
1、变量(Variable)
现实生活中我们会找一个小箱子来存放物品,一来显得不那么凌乱,二来方便以后找到。计算机也是这个道理,我们需要先在内存中找一块区域,规定用它来存放整数,并起一个好记的名字,方便以后查找。这块区域就是“小箱子”,我们可以把整数放进去了。
C语言中这样在内存中找一块区域:
int a;
int又是一个新单词,它是 Integer 的简写,意思是整数。a 是我们给这块区域起的名字;当然也可以叫其他名字,例如 abc、mn123 等。
这个语句的意思是:在内存中找一块区域,命名为 a,用它来存放整数。
注意 int 和 a 之间是有空格的,它们是两个词。也注意最后的分号,
int a表达了完整的意思,是一个语句,要用分号来结束。
不过int a;仅仅是在内存中找了一块可以保存整数的区域,那么如何将 123、100、999 这样的数字放进去呢?
C语言中这样向内存中放整数:
a=123;
=是一个新符号,它在数学中叫“等于号”,例如 1+2=3,但在C语言中,这个过程叫做赋值(Assign)。赋值是指把数据放到内存的过程。
把上面的两个语句连起来:
int a;
a=123;
就把 123 放到了一块叫做 a 的内存区域。你也可以写成一个语句:
int a=123;
a 中的整数不是一成不变的,只要我们需要,随时可以更改。更改的方式就是再次赋值,例如:
int a=123;
a=1000;
a=9999;
第二次赋值,会把第一次的数据覆盖(擦除)掉,也就是说,a 中最后的值是9999,123、1000 已经不存在了,再也找不回来了。
因为 a 的值可以改变,所以我们给它起了一个形象的名字,叫做变量(Variable)。int a;创造了一个变量 a,我们把这个过程叫做变量定义。a=123;把 123 交给了变量 a,我们把这个过程叫做给变量赋值;又因为是第一次赋值,也称变量的初始化,或者赋初值。
你可以先定义变量,再初始化,例如:
int abc;
abc=999;
也可以在定义的同时进行初始化,例如:
int abc=999;
这两种方式是等价的。
2、数据类型(Data Type)
数据是放在内存中的,变量是给这块内存起的名字,有了变量就可以找到并使用这份数据。但问题是,该如何使用呢?
我们知道,诸如数字、文字、符号、图形、音频、视频等数据都是以二进制形式存储在内存中的,它们并没有本质上的区别,那么,00010000 该理解为数字16呢,还是图像中某个像素的颜色呢,还是要发出某个声音呢?如果没有特别指明,我们并不知道。
也就是说,内存中的数据有多种解释方式,使用之前必须要确定;上面的int a;就表明,这份数据是整数,不能理解为像素、声音等。int 有一个专业的称呼,叫做数据类型(Data Type)。
顾名思义,数据类型用来说明数据的类型,确定了数据的解释方式,让计算机和程序员不会产生歧义。在C语言中,有多种数据类型,例如:
| 说 明 | 字符型 | 短整型 | 整型 | 长整型 | 单精度浮点型 | 双精度浮点型 | 无类型 |
|---|---|---|---|---|---|---|---|
| 数据类型 | char | short | int | long | float | double | void |
这些是最基本的数据类型,是C语言自带的,如果我们需要,还可以通过它们组成更加复杂的数据类型,后面我们会一一讲解。
3、连续定义多个变量
为了让程序的书写更加简洁,C语言支持多个变量的连续定义,例如:
int a, b, c;
float m = 10.9, n = 20.56;
char p, q = '@';
连续定义的多个变量以逗号,分隔,并且要拥有相同的数据类型;变量可以初始化,也可以不初始化。
4、数据的长度(Length)
所谓数据长度(Length),是指数据占用多少个字节。占用的字节越多,能存储的数据就越多,对于数字来说,值就会更大,反之能存储的数据就有限。
多个数据在内存中是连续存储的,彼此之间没有明显的界限,如果不明确指明数据的长度,计算机就不知道何时存取结束。例如我们保存了一个整数 1000,它占用4个字节的内存,而读取时却认为它占用3个字节或5个字节,这显然是不正确的。
所以,在定义变量时还要指明数据的长度。而这恰恰是数据类型的另外一个作用。数据类型除了指明数据的解释方式,还指明了数据的长度。因为在C语言中,每一种数据类型所占用的字节数都是固定的,知道了数据类型,也就知道了数据的长度。
在32位环境中,各种数据类型的长度一般如下:
| 说 明 | 字符型 | 短整型 | 整型 | 长整型 | 单精度浮点型 | 双精度浮点型 |
|---|---|---|---|---|---|---|
| 数据类型 | char | short | int | long | float | double |
| 长 度 | 1 | 2 | 4 | 4 | 4 | 8 |
C语言有多少种数据类型,每种数据类型长度是多少、该如何使用,这是每一位C程序员都必须要掌握的,后续我们会一一讲解。
5、最后的总结
数据是放在内存中的,在内存中存取数据要明确三件事情:数据存储在哪里、数据的长度以及数据的处理方式。
变量名不仅仅是为数据起了一个好记的名字,还告诉我们数据存储在哪里,使用数据时,只要提供变量名即可;而数据类型则指明了数据的长度和处理方式。所以诸如int n;、char c;、float money;这样的形式就确定了数据在内存中的所有要素。
C语言提供的多种数据类型让程序更加灵活和高效,同时也增加了学习成本。而有些编程语言,例如PHP、JavsScript等,在定义变量时不需要指明数据类型,编译器会根据赋值情况自动推演出数据类型,更加智能。
除了C语言,Java、C++、C#等在定义变量时也必须指明数据类型,这样的编程语言称为强类型语言。而PHP、JavaScript等在定义变量时不必指明数据类型,编译系统会自动推演,这样的编程语言称为弱类型语言。
强类型语言一旦确定了数据类型,就不能再赋给其他类型的数据,除非对数据类型进行转换。弱类型语言没有这种限制,一个变量,可以先赋给一个整数,然后再赋给一个字符串。
最后需要说明的是:数据类型只在定义变量时指明,而且必须指明;使用变量时无需再指明,因为此时的数据类型已经确定了。
二、在屏幕上输出各种类型的数据
在《第一个C语言程序》一节中,我们使用 puts 来输出字符串。puts 是 output string 的缩写,只能用来输出字符串,不能输出整数、小数、字符等,我们需要用另外一个函数,那就是 printf。
printf 比 puts 更加强大,不仅可以输出字符串,还可以输出整数、小数、单个字符等,并且输出格式也可以自己定义,例如:
- 以十进制、八进制、十六进制形式输出;
- 要求输出的数字占 n 个字符的位置;
- 控制小数的位数。
printf 是 print format 的缩写,意思是“格式化打印”。这里所谓的“打印”就是在屏幕上显示内容,与“输出”的含义相同,所以我们一般称 printf 是用来格式化输出的。
先来看一个简单的例子:
printf("C语言中文网");
这个语句可以在屏幕上显示“C语言中文网”,与puts("C语言中文网");的效果类似。
输出变量 abc 的值:
int abc=999;
printf("%d", abc);
这里就比较有趣了。先来看%d,d 是 decimal 的缩写,意思是十进制数,%d 表示以十进制整数的形式输出。输出什么呢?输出变量 abc 的值。%d 与 abc 是对应的,也就是说,会用 abc 的值来替换 %d。
再来看个复杂点的:
int abc=999;
printf("The value of abc is %d !", abc);
会在屏幕上显示:
The value of abc is 999 !
你看,字符串 "The value of abc is %d !" 中的 %d 被替换成了 abc 的值,其他字符没有改变。这说明 %d 比较特殊,不会原样输出,会被替换成对应的变量的值。
再来看:
int a=100;
int b=200;
int c=300;
printf("a=%d, b=%d, c=%d", a, b, c);
会在屏幕上显示:
a=100, b=200, c=300
再次证明了 %d 与后面的变量是一一对应的,第一个 %d 对应第一个变量,第二个 %d 对应第二个变量……%d称为格式控制符,它指明了以何种形式输出数据。格式控制符均以%开头,后跟其他字符。%d 表示以十进制形式输出一个整数。除了 %d,printf 支持更多的格式控制,例如:
- %c:输出一个字符。c 是 character 的简写。
- %s:输出一个字符串。s 是 string 的简写。
- %f:输出一个小数。f 是 float 的简写。
除了这些,printf 支持更加复杂和优美的输出格式,考虑到读者的基础暂时不够,我们将在《C语言数据输出大汇总以及轻量进阶》一节中展开讲解。
我们把代码补充完整,体验一下:
#include <stdio.h>
int main()
{
int n = 100;
char c = '@'; //字符用单引号包围,字符串用双引号包围
float money = 93.96;
printf("n=%d, c=%c, money=%f\n", n, c, money);
return 0;
}
输出结果:
n=100, c=@, money=93.959999
要点提示:
1) \n是一个整体,组合在一起表示一个换行字符。换行符是 ASCII 编码中的一个控制字符,无法在键盘上直接输入,只能用这种特殊的方法表示,被称为转义字符,我们将在《C语言转义字符》一节中有具体讲解,请大家暂时先记住\n的含义。
所谓换行,就是让文本从下一行的开头输出,相当于在编辑 Word 或者 TXT 文档时按下回车键。
puts 输出完成后会自动换行,而 printf 不会,要自己添加换行符,这是 puts 和 printf 在输出字符串时的一个区别。
2) //后面的为注释。注释用来说明代码是什么意思,起到提示的作用,可以帮助我们理解代码。注释虽然也是代码的一部分,但是它并不会给程序带来任何影响,编译器在编译阶段会忽略注释的内容,或者说删除注释的内容。我们将在《C语言标识符、关键字、注释、表达式和语句》一节中详细讲解。
3) money 的输出值并不是 93.96,而是一个非常接近的值,这与小数本身的存储机制有关,这种机制导致很多小数不能被精确地表示,即使像 93.96 这种简单的小数也不行。我们将在《小数在内存中是如何存储的,揭秘诺贝尔奖级别的设计(长篇神文)》一节详细介绍。
我们也可以不用变量,将数据直接输出:
#include <stdio.h>
int main()
{
float money = 93.96;
printf("n=%d, c=%c, money=%f\n", 100, '@', money);
return 0;
}
输出结果与上面相同。
在以后的编程中,我们会经常使用 printf,说它是C语言中使用频率最高的一个函数一点也不为过,每个C语言程序员都应该掌握 printf 的用法,这是最基本的技能。
不过 printf 的用法比较灵活,也比较复杂,初学者知识储备不足,不能一下子掌握,目前大家只需要掌握最基本的用法,以后随着编程知识的学习,我们会逐步介绍更加高级的用法,最终让大家完全掌握 printf。
1、【脑筋急转弯】%ds输出什么
%d 输出整数,%s 输出字符串,那么 %ds 输出什么呢?
我们不妨先来看一个例子:
#include <stdio.h>
int main()
{
int a=1234;
printf("a=%ds\n", a);
return 0;
}
运行结果:
a=1234s
从输出结果可以发现,%d被替换成了变量 a 的值,而s没有变,原样输出了。这是因为, %d才是格式控制符,%ds在一起没有意义,s仅仅是跟在%d后面的一个普通字符,所以会原样输出。
2、【拓展】如何在字符串中书写长文本
假设现在我们要输出一段比较长的文本,它的内容为:
C语言中文网,一个学习C语言和C++的网站,他们坚持用工匠的精神来打磨每一套教程。坚持做好一件事情,做到极致,让自己感动,让用户心动,这就是足以传世的作品!C语言中文网的网址是:http://c.biancheng.net
如果将这段文本放在一个字符串中,会显得比较臃肿,格式也不好看,就像下面这样:
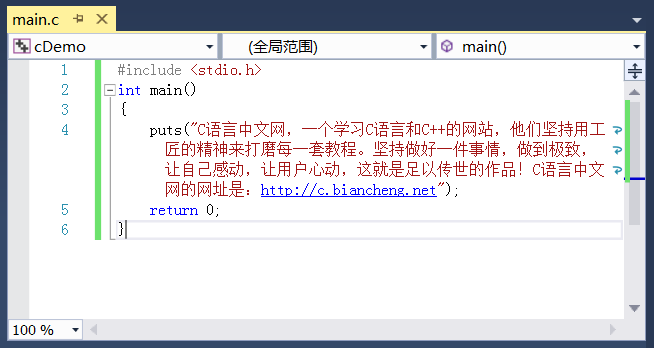
超出编辑窗口宽度的文本换行
超出编辑窗口宽度的文本隐藏
当文本超出编辑窗口的宽度时,可以选择将文本换行,也可以选择将文本隐藏(可以在编辑器里面自行设置),但是不管哪种形式,在一个字符串里书写长文本总是不太美观。
当然,你可以多写几个 puts 函数,就像下面这样:
我不否认这种写法也比较美观,但是这里我要讲的是另外一种写法:
#include <stdio.h>
int main()
{
puts(
"C语言中文网,一个学习C语言和C++的网站,他们坚持用工匠的精神来打磨每一套教程。"
"坚持做好一件事情,做到极致,让自己感动,让用户心动,这就是足以传世的作品!"
"C语言中文网的网址是:http://c.biancheng.net"
);
return 0;
}
在 puts 函数中,可以将一个较长的字符串分割成几个较短的字符串,这样会使得长文本的格式更加整齐。
注意,这只是形式上的分割,编译器在编译阶段会将它们合并为一个字符串,它们放在一块连续的内存中。
多个字符串并不一定非得换行,也可以将它们写在一行中,例如:
#include <stdio.h>
int main()
{
puts("C语言中文网!" "C语言和C++!" "http://c.biancheng.net");
return 0;
}
本节讲到的 puts、printf,以及后面要讲到的 fprintf、fputs 等与字符串输出有关的函数,都支持这种写法。
三、C语言中的整数(short,int,long)
整数是编程中常用的一种数据,C语言通常使用int来定义整数(int 是 integer 的简写),这在《大话C语言变量和数据类型》中已经进行了详细讲解。
在现代操作系统中,int 一般占用 4 个字节(Byte)的内存,共计 32 位(Bit)。如果不考虑正负数,当所有的位都为 1 时它的值最大,为 -1 = 4,294,967,295 ≈ 43亿,这是一个很大的数,实际开发中很少用到,而诸如 1、99、12098 等较小的数使用频率反而较高。
使用 4 个字节保存较小的整数绰绰有余,会空闲出两三个字节来,这些字节就白白浪费掉了,不能再被其他数据使用。现在个人电脑的内存都比较大了,配置低的也有 2G,浪费一些内存不会带来明显的损失;而在C语言被发明的早期,或者在单片机和嵌入式系统中,内存都是非常稀缺的资源,所有的程序都在尽力节省内存。
反过来说,43 亿虽然已经很大,但要表示全球人口数量还是不够,必须要让整数占用更多的内存,才能表示更大的值,比如占用 6 个字节或者 8 个字节。
让整数占用更少的内存可以在 int 前边加 short,让整数占用更多的内存可以在 int 前边加 long,例如:
short int a = 10;
short int b, c = 99;
long int m = 102023;
long int n, p = 562131;
这样 a、b、c 只占用 2 个字节的内存,而 m、n、p 可能会占用 8 个字节的内存。
也可以将 int 省略,只写 short 和 long,如下所示:
short a = 10;
short b, c = 99;
long m = 102023;
long n, p = 562131;
这样的写法更加简洁,实际开发中常用。
int 是基本的整数类型,short 和 long 是在 int 的基础上进行的扩展,short 可以节省内存,long 可以容纳更大的值。
short、int、long 是C语言中常见的整数类型,其中 int 称为整型,short 称为短整型,long 称为长整型。
1、整型的长度
细心的读者可能会发现,上面我们在描述 short、int、long 类型的长度时,只对 short 使用肯定的说法,而对 int、long 使用了“一般”或者“可能”等不确定的说法。这种描述的言外之意是,只有 short 的长度是确定的,是两个字节,而 int 和 long 的长度无法确定,在不同的环境下有不同的表现。
一种数据类型占用的字节数,称为该数据类型的长度。例如,short 占用 2 个字节的内存,那么它的长度就是 2。
实际情况也确实如此,C语言并没有严格规定 short、int、long 的长度,只做了宽泛的限制:
- short 至少占用 2 个字节。
- int 建议为一个机器字长。32 位环境下机器字长为 4 字节,64 位环境下机器字长为 8 字节。
- short 的长度不能大于 int,long 的长度不能小于 int。
总结起来,它们的长度(所占字节数)关系为:
2 ≤ short ≤ int ≤ long
这就意味着,short 并不一定真的”短“,long 也并不一定真的”长“,它们有可能和 int 占用相同的字节数。
在 16 位环境下,short 的长度为 2 个字节,int 也为 2 个字节,long 为 4 个字节。16 位环境多用于单片机和低级嵌入式系统,在PC和服务器上已经见不到了。
对于 32 位的 Windows、Linux 和 Mac OS,short 的长度为 2 个字节,int 为 4 个字节,long 也为 4 个字节。PC和服务器上的 32 位系统占有率也在慢慢下降,嵌入式系统使用 32 位越来越多。
在 64 位环境下,不同的操作系统会有不同的结果,如下所示:
| 操作系统 | short | int | long |
|---|---|---|---|
| Win64(64位 Windows) | 2 | 4 | 4 |
| 类Unix系统(包括 Unix、Linux、Mac OS、BSD、Solaris 等) | 2 | 4 | 8 |
目前我们使用较多的PC系统为 Win XP、Win 7、Win 8、Win 10、Mac OS、Linux,在这些系统中,short 和 int 的长度都是固定的,分别为 2 和 4,大家可以放心使用,只有 long 的长度在 Win64 和类 Unix 系统下会有所不同,使用时要注意移植性。
2、sizeof 操作符
获取某个数据类型的长度可以使用 sizeof 操作符,如下所示:
#include <stdio.h>
int main()
{
short a = 10;
int b = 100;
int short_length = sizeof a;
int int_length = sizeof(b);
int long_length = sizeof(long);
int char_length = sizeof(char);
printf("short=%d, int=%d, long=%d, char=%d\n", short_length, int_length, long_length, char_length);
return 0;
}
在 32 位环境以及 Win64 环境下的运行结果为:
short=2, int=4, long=4, char=1
在 64 位 Linux 和 Mac OS 下的运行结果为:
short=2, int=4, long=8, char=1
sizeof 用来获取某个数据类型或变量所占用的字节数,如果后面跟的是变量名称,那么可以省略( ),如果跟的是数据类型,就必须带上( )。
需要注意的是,sizeof 是C语言中的操作符,不是函数,所以可以不带( ),后面会详细讲解。
3、不同整型的输出
使用不同的格式控制符可以输出不同类型的整数,它们分别是:
%hd用来输出 short int 类型,hd 是 short decimal 的简写;%d用来输出 int 类型,d 是 decimal 的简写;%ld用来输出 long int 类型,ld 是 long decimal 的简写。
下面的例子演示了不同整型的输出:
#include <stdio.h>
int main()
{
short a = 10;
int b = 100;
long c = 9437;
printf("a=%hd, b=%d, c=%ld\n", a, b, c);
return 0;
}
运行结果:
a=10, b=100, c=9437
在编写代码的过程中,我建议将格式控制符和数据类型严格对应起来,养成良好的编程习惯。当然,如果你不严格对应,一般也不会导致错误,例如,很多初学者都使用%d输出所有的整数类型,请看下面的例子:
#include <stdio.h>
int main()
{
short a = 10;
int b = 100;
long c = 9437;
printf("a=%d, b=%d, c=%d\n", a, b, c);
return 0;
}
运行结果仍然是:
a=10, b=100, c=9437
当使用%d输出 short,或者使用%ld输出 short、int 时,不管值有多大,都不会发生错误,因为格式控制符足够容纳这些值。
当使用%hd输出 int、long,或者使用%d输出 long 时,如果要输出的值比较小(就像上面的情况),一般也不会发生错误,如果要输出的值比较大,就很有可能发生错误,例如:
#include <stdio.h>
int main()
{
int m = 306587;
long n = 28166459852;
printf("m=%hd, n=%hd\n", m, n);
printf("n=%d\n", n);
return 0;
}
在 64 位 Linux 和 Mac OS 下(long 的长度为 8)的运行结果为:
m=-21093, n=4556
n=-1898311220
输出结果完全是错误的,这是因为%hd容纳不下 m 和 n 的值,%d也容纳不下 n 的值。
读者需要注意,当格式控制符和数据类型不匹配时,编译器会给出警告,提示程序员可能会存在风险。
编译器的警告是分等级的,不同程度的风险被划分成了不同的警告等级,而使用
%d输出 short 和 long 类型的风险较低,如果你的编译器设置只对较高风险的操作发出警告,那么此处你就看不到警告信息。
四、C语言中的二进制数、八进制数和十六进制数
C语言中的整数除了可以使用十进制,还可以使用二进制、八进制和十六进制。
1、二进制数、八进制数和十六进制数的表示
一个数字默认就是十进制的,表示一个十进制数字不需要任何特殊的格式。但是,表示一个二进制、八进制或者十六进制数字就不一样了,为了和十进制数字区分开来,必须采用某种特殊的写法,具体来说,就是在数字前面加上特定的字符,也就是加前缀。
(1) 二进制
二进制由 0 和 1 两个数字组成,使用时必须以0b或0B(不区分大小写)开头,例如:
//合法的二进制
int a = 0b101; //换算成十进制为 5
int b = -0b110010; //换算成十进制为 -50 i
nt c = 0B100001; //换算成十进制为 33
//非法的二进制
int m = 101010; //无前缀 0B,相当于十进制
int n = 0B410; //4不是有效的二进制数字
读者请注意,标准的C语言并不支持上面的二进制写法,只是有些编译器自己进行了扩展,才支持二进制数字。换句话说,并不是所有的编译器都支持二进制数字,只有一部分编译器支持,并且跟编译器的版本有关系。
下面是实际测试的结果:
- Visual C++6.0 不支持。
- Visual Studio 2015 支持,但是 Visual Studio 2010 不支持;可以认为,高版本的 Visual Studio 支持二进制数字,低版本的 Visual Studio 不支持。
- GCC 4.8.2 支持,但是 GCC 3.4.5 不支持;可以认为,高版本的 GCC 支持二进制数字,低版本的 GCC 不支持。
- LLVM/Clang 支持(内嵌于 Mac OS 下的 Xcode 中)。
(2) 八进制
八进制由 0~7 八个数字组成,使用时必须以0开头(注意是数字 0,不是字母 o),例如:
//合法的八进制数
int a = 015; //换算成十进制为 13 i
nt b = -0101; //换算成十进制为 -65
int c = 0177777; //换算成十进制为 65535
//非法的八进制
int m = 256; //无前缀 0,相当于十进制
int n = 03A2; //A不是有效的八进制数字
(3) 十六进制
十六进制由数字 0~9、字母 A~F 或 a~f(不区分大小写)组成,使用时必须以0x或0X(不区分大小写)开头,例如:
//合法的十六进制
int a = 0X2A; //换算成十进制为 42
int b = -0XA0; //换算成十进制为 -160
int c = 0xffff; //换算成十进制为 65535
//非法的十六进制
int m = 5A; //没有前缀 0X,是一个无效数字
int n = 0X3H; //H不是有效的十六进制数字
(4)十进制
十进制由 0~9 十个数字组成,没有任何前缀,和我们平时的书写格式一样,不再赘述。
2、二进制数、八进制数和十六进制数的输出
C语言中常用的整数有 short、int 和 long 三种类型,通过 printf 函数,可以将它们以八进制、十进制和十六进制的形式输出。上节我们讲解了如何以十进制的形式输出,这节我们重点讲解如何以八进制和十六进制的形式输出,下表列出了不同类型的整数、以不同进制的形式输出时对应的格式控制符:
| short | int | long | |
|---|---|---|---|
| 八进制 | %ho | %o | %lo |
| 十进制 | %hd | %d | %ld |
| 十六进制 | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
十六进制数字的表示用到了英文字母,有大小写之分,要在格式控制符中体现出来:
- %hx、%x 和 %lx 中的
x小写,表明以小写字母的形式输出十六进制数; - %hX、%X 和 %lX 中的
X大写,表明以大写字母的形式输出十六进制数。
八进制数字和十进制数字不区分大小写,所以格式控制符都用小写形式。如果你比较叛逆,想使用大写形式,那么行为是未定义的,请你慎重:
- 有些编译器支持大写形式,只不过行为和小写形式一样;
- 有些编译器不支持大写形式,可能会报错,也可能会导致奇怪的输出。
注意,虽然部分编译器支持二进制数字的表示,但是却不能使用 printf 函数输出二进制,这一点比较遗憾。当然,通过转换函数可以将其它进制数字转换成二进制数字,并以字符串的形式存储,然后在 printf 函数中使用%s输出即可。考虑到读者的基础还不够,这里就先不讲这种方法了。
【实例】以不同进制的形式输出整数:
#include <stdio.h>
int main()
{
short a = 0b1010110; //二进制数字
int b = 02713; //八进制数字
long c = 0X1DAB83; //十六进制数字
printf("a=%ho, b=%o, c=%lo\n", a, b, c); //以八进制形似输出
printf("a=%hd, b=%d, c=%ld\n", a, b, c); //以十进制形式输出
printf("a=%hx, b=%x, c=%lx\n", a, b, c); //以十六进制形式输出(字母小写)
printf("a=%hX, b=%X, c=%lX\n", a, b, c); //以十六进制形式输出(字母大写)
return 0;
}
运行结果:
a=126, b=2713, c=7325603
a=86, b=1483, c=1944451
a=56, b=5cb, c=1dab83
a=56, b=5CB, c=1DAB83
从这个例子可以发现,一个数字不管以何种进制来表示,都能够以任意进制的形式输出。数字在内存中始终以二进制的形式存储,其它进制的数字在存储前都必须转换为二进制形式;同理,一个数字在输出时要进行逆向的转换,也就是从二进制转换为其他进制。
输出时加上前缀
请读者注意观察上面的例子,会发现有一点不完美,如果只看输出结果:
- 对于八进制数字,它没法和十进制、十六进制区分,因为八进制、十进制和十六进制都包含 0~7 这几个数字。
- 对于十进制数字,它没法和十六进制区分,因为十六进制也包含 0~9 这几个数字。如果十进制数字中还不包含 8 和 9,那么也不能和八进制区分了。
- 对于十六进制数字,如果没有包含 a~f 或者 A~F,那么就无法和十进制区分,如果还不包含 8 和 9,那么也不能和八进制区分了。
区分不同进制数字的一个简单办法就是,在输出时带上特定的前缀。在格式控制符中加上#即可输出前缀,例如 %#x、%#o、%#lX、%#ho 等,请看下面的代码:
#include <stdio.h>
int main()
{
short a = 0b1010110; //二进制数字
int b = 02713; //八进制数字
long c = 0X1DAB83; //十六进制数字
printf("a=%#ho, b=%#o, c=%#lo\n", a, b, c); //以八进制形似输出
printf("a=%hd, b=%d, c=%ld\n", a, b, c); //以十进制形式输出
printf("a=%#hx, b=%#x, c=%#lx\n", a, b, c); //以十六进制形式输出(字母小写)
printf("a=%#hX, b=%#X, c=%#lX\n", a, b, c); //以十六进制形式输出(字母大写)
return 0;
}
运行结果:
a=0126, b=02713, c=07325603
a=86, b=1483, c=1944451
a=0x56, b=0x5cb, c=0x1dab83
a=0X56, b=0X5CB, c=0X1DAB83
十进制数字没有前缀,所以不用加#。如果你加上了,那么它的行为是未定义的,有的编译器支持十进制加#,只不过输出结果和没有加#一样,有的编译器不支持加#,可能会报错,也可能会导致奇怪的输出;但是,大部分编译器都能正常输出,不至于当成一种错误。
五、C语言中的正负数及其输出
在数学中,数字有正负之分。在C语言中也是一样,short、int、long 都可以带上正负号,例如:
//负数
short a1 = -10;
short a2 = -0x2dc9; //十六进制
//正数
int b1 = +10;
int b2 = +0174; //八进制
int b3 = 22910;
//负数和正数相加
long c = (-9) + (+12);
如果不带正负号,默认就是正数。
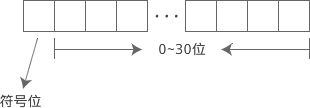
符号也是数字的一部分,也要在内存中体现出来。符号只有正负两种情况,用1位(Bit)就足以表示;C语言规定,把内存的最高位作为符号位。以 int 为例,它占用 32 位的内存,0~30 位表示数值,31 位表示正负号。如下图所示:
在编程语言中,计数往往是从0开始,例如字符串 "abc123",我们称第 0 个字符是 a,第 1 个字符是 b,第 5 个字符是 3。这和我们平时从 1 开始计数的习惯不一样,大家要慢慢适应,培养编程思维。
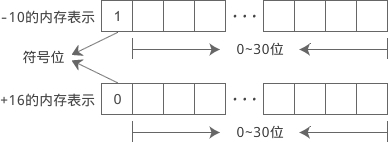
C语言规定,在符号位中,用 0 表示正数,用 1 表示负数。例如 int 类型的 -10 和 +16 在内存中的表示如下:
short、int 和 long 类型默认都是带符号位的,符号位以外的内存才是数值位。如果只考虑正数,那么各种类型能表示的数值范围(取值范围)就比原来小了一半。
但是在很多情况下,我们非常确定某个数字只能是正数,比如班级学生的人数、字符串的长度、内存地址等,这个时候符号位就是多余的了,就不如删掉符号位,把所有的位都用来存储数值,这样能表示的数值范围更大(大一倍)。
C语言允许我们这样做,如果不希望设置符号位,可以在数据类型前面加上 unsigned 关键字,例如:
unsigned short a = 12;
unsigned int b = 1002;
unsigned long c = 9892320;
这样,short、int、long 中就没有符号位了,所有的位都用来表示数值,正数的取值范围更大了。这也意味着,使用了 unsigned 后只能表示正数,不能再表示负数了。
如果将一个数字分为符号和数值两部分,那么不加 unsigned 的数字称为有符号数,能表示正数和负数,加了 unsigned 的数字称为无符号数,只能表示正数。
请读者注意一个小细节,如果是unsigned int类型,那么可以省略 int ,只写 unsigned,例如:
unsigned n = 100;
它等价于:
unsigned int n = 100;
1、无符号数的输出
无符号数可以以八进制、十进制和十六进制的形式输出,它们对应的格式控制符分别为:
| unsigned short | unsigned int | unsigned long | |
|---|---|---|---|
| 八进制 | %ho | %o | %lo |
| 十进制 | %hu | %u | %lu |
| 十六进制 | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
上节我们也讲到了不同进制形式的输出,但是上节我们还没有讲到正负数,所以也没有关心这一点,只是“笼统”地介绍了一遍。现在本节已经讲到了正负数,那我们就再深入地说一下。
严格来说,格式控制符和整数的符号是紧密相关的,具体就是:
- %d 以十进制形式输出有符号数;
- %u 以十进制形式输出无符号数;
- %o 以八进制形式输出无符号数;
- %x 以十六进制形式输出无符号数。
那么,如何以八进制和十六进制形式输出有符号数呢?很遗憾,printf 并不支持,也没有对应的格式控制符。在实际开发中,也基本没有“输出负的八进制数或者十六进制数”这样的需求,我想可能正是因为这一点,printf 才没有提供对应的格式控制符。
下表全面地总结了不同类型的整数,以不同进制的形式输出时对应的格式控制符(--表示没有对应的格式控制符)。
| short | int | long | unsigned short | unsigned int | unsigned long | |
|---|---|---|---|---|---|---|
| 八进制 | -- | -- | -- | %ho | %o | %lo |
| 十进制 | %hd | %d | %ld | %hu | %u | %lu |
| 十六进制 | -- | -- | -- | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
有读者可能会问,上节我们也使用 %o 和 %x 来输出有符号数了,为什么没有发生错误呢?这是因为:
- 当以有符号数的形式输出时,printf 会读取数字所占用的内存,并把最高位作为符号位,把剩下的内存作为数值位;
- 当以无符号数的形式输出时,printf 也会读取数字所占用的内存,并把所有的内存都作为数值位对待。
对于一个有符号的正数,它的符号位是 0,当按照无符号数的形式读取时,符号位就变成了数值位,但是该位恰好是 0 而不是 1,所以对数值不会产生影响,这就好比在一个数字前面加 0,有多少个 0 都不会影响数字的值。
如果对一个有符号的负数使用 %o 或者 %x 输出,那么结果就会大相径庭,读者可以亲试。
可以说,“有符号正数的最高位是 0”这个巧合才使得 %o 和 %x 输出有符号数时不会出错。
再次强调,不管是以 %o、%u、%x 输出有符号数,还是以 %d 输出无符号数,编译器都不会报错,只是对内存的解释不同了。%o、%d、%u、%x 这些格式控制符不会关心数字在定义时到底是有符号的还是无符号的:
- 你让我输出无符号数,那我在读取内存时就不区分符号位和数值位了,我会把所有的内存都看做数值位;
- 你让我输出有符号数,那我在读取内存时会把最高位作为符号位,把剩下的内存作为数值位。
说得再直接一些,我管你在定义时是有符号数还是无符号数呢,我只关心内存,有符号数也可以按照无符号数输出,无符号数也可以按照有符号数输出,至于输出结果对不对,那我就不管了,你自己承担风险。
下面的代码进行了全面的演示:
#include <stdio.h>
int main()
{
short a = 0100; //八进制
int b = -0x1; //十六进制
long c = 720; //十进制
unsigned short m = 0xffff; //十六进制
unsigned int n = 0x80000000; //十六进制
unsigned long p = 100; //十进制
//以无符号的形式输出有符号数
printf("a=%#ho, b=%#x, c=%ld\n", a, b, c);
//以有符号数的形式输出无符号类型(只能以十进制形式输出)
printf("m=%hd, n=%d, p=%ld\n", m, n, p);
return 0;
}
运行结果:
a=0100, b=0xffffffff, c=720
m=-1, n=-2147483648, p=100
对于绝大多数初学者来说,b、m、n 的输出结果看起来非常奇怪,甚至不能理解。按照一般的推理,b、m、n 这三个整数在内存中的存储形式分别是:

当以 %x 输出 b 时,结果应该是 0x80000001;当以 %hd、%d 输出 m、n 时,结果应该分别是 -7fff、-0。但是实际的输出结果和我们推理的结果却大相径庭,这是为什么呢?
注意,-7fff 是十六进制形式。%d 本来应该输出十进制,这里只是为了看起来方便,才改为十六进制。
其实这跟整数在内存中的存储形式以及读取方式有关。b 是一个有符号的负数,它在内存中并不是像上图演示的那样存储,而是要经过一定的转换才能写入内存;m、n 的内存虽然没有错误,但是当以 %d 输出时,并不是原样输出,而是有一个逆向的转换过程(和存储时的转换过程恰好相反)。
也就是说,整数在写入内存之前可能会发生转换,在读取时也可能会发生转换,而我们没有考虑这种转换,所以才会导致推理错误。那么,整数在写入内存前,以及在读取时究竟发生了怎样的转换呢?为什么会发生这种转换呢?我们将在《整数在内存中是如何存储的,为什么它堪称天才般的设计》一节中揭开谜底。
六、整数在内存中是如何存储的,为什么它堪称天才般的设计
加法和减法是计算机中最基本的运算,计算机时时刻刻都离不开它们,所以它们由硬件直接支持。为了提高加减法的运算效率,硬件电路要设计得尽量简单。
对于有符号数,内存要区分符号位和数值位,对于人脑来说,很容易辨别,但是对于计算机来说,就要设计专门的电路,这无疑增加了硬件的复杂性,增加了计算的时间。要是能把符号位和数值位等同起来,让它们一起参与运算,不再加以区分,这样硬件电路就变得简单了。
另外,加法和减法也可以合并为一种运算,就是加法运算,因为减去一个数相当于加上这个数的相反数,例如,5 - 3 等价于 5 + (-3),10 - (-9) 等价于 10 + 9。
相反数是指数值相同,符号不同的两个数,例如,10 和 -10 就是一对相反数,-98 和 98 也是一对相反数。
如果能够实现上面的两个目标,那么只要设计一种简单的、不用区分符号位和数值位的加法电路,就能同时实现加法和减法运算,并且非常高效。实际上,这两个目标都已经实现了,真正的计算机硬件电路就是如此简单。
然而,简化硬件电路是有代价的,这个代价就是有符号数在存储和读取时都要进行转化。那么,这个转换过程究竟是怎样的呢?接下来我们就详细地讲解一下。
首先,请读者先记住下面的几个概念。
1、原码
将一个整数转换成二进制形式,就是其原码。例如short a = 6;,a 的原码就是0000 0000 0000 0110;更改 a 的值a = -18;,此时 a 的原码就是1000 0000 0001 0010。
通俗的理解,原码就是一个整数本来的二进制形式。
2、反码
谈到反码,正数和负数要区别对待,因为它们的反码不一样。
对于正数,它的反码就是其原码(原码和反码相同);负数的反码是将原码中除符号位以外的所有位(数值位)取反,也就是 0 变成 1,1 变成 0。例如short a = 6;,a 的原码和反码都是0000 0000 0000 0110;更改 a 的值a = -18;,此时 a 的反码是1111 1111 1110 1101。
3、补码
正数和负数的补码也不一样,也要区别对待。
对于正数,它的补码就是其原码(原码、反码、补码都相同);负数的补码是其反码加 1。例如short a = 6;,a 的原码、反码、补码都是0000 0000 0000 0110;更改 a 的值a = -18;,此时 a 的补码是1111 1111 1110 1110。
可以认为,补码是在反码的基础上打了一个补丁,进行了一下修正,所以叫“补码”。
原码、反码、补码的概念只对负数有实际意义,对于正数,它们都一样。
最后我们总结一下 6 和 -18 从原码到补码的转换过程:

在计算机内存中,整数一律采用补码的形式来存储。这意味着,当读取整数时还要采用逆向的转换,也就是将补码转换为原码。正数的补码和原码相同,负数的补码转换为原码也很简单:先减去 1,再将数值位取反即可。
4、补码到底是如何简化硬件电路的
假设 6 和 18 都是 short 类型的,现在我们要计算 6 - 18 的结果,根据运算规则,它等价于 6 + (-18)。
如果采用原码计算,那么运算过程为:
6 - 18 = 6 + (-18)
= [0000 0000 0000 0110]原 + [1000 0000 0001 0010]原
= [1000 0000 0001 1000]原
= -24
直接用原码表示整数,让符号位也参与运算,对于类似上面的减法来说,结果显然是不正确的。
于是人们开始继续探索,不断试错,后来设计出了反码。下面就演示了反码运算的过程:
6 - 18 = 6 + (-18)
= [0000 0000 0000 0110]反 + [1111 1111 1110 1101]反
= [1111 1111 1111 0011]反
= [1000 0000 0000 1100]原
= -12
这样一来,计算结果就正确了。
然而,这样还不算万事大吉,我们不妨将减数和被减数交换一下位置,也就是计算 18 - 6 的结果:
18 - 6 = 18 + (-6)
= [0000 0000 0001 0010]反 + [1111 1111 1111 1001]反
= [1 0000 0000 0000 1011]反
= [0000 0000 0000 1011]反
= [0000 0000 0000 1011]原
= 11
按照反码计算的结果是 11,而真实的结果应该是 12 才对,它们相差了 1。
蓝色的 1 是加法运算过程中的进位,它溢出了,内存容纳不了了,所以直接截掉。
6 - 18 的结果正确,18 - 6 的结果就不正确,相差 1。按照反码来计算,是不是小数减去大数正确,大数减去小数就不对了,始终相差 1 呢?我们不妨再看两个例子,分别是 5 - 13 和 13 - 5。
5 - 13 的运算过程为:
5 - 13 = 5 + (-13)
= [0000 0000 0000 0101]原 + [1000 0000 0000 1101]原
= [0000 0000 0000 0101]反 + [1111 1111 1111 0010]反
= [1111 1111 1111 0111]反
= [1000 0000 0000 1000]原
= -8
13 - 5 的运算过程为:
13 - 5 = 13 + (-5)
= [0000 0000 0000 1101]原 + [1000 0000 0000 0101]原
= [0000 0000 0000 1101]反 + [1111 1111 1111 1010]反
= [1 0000 0000 0000 0111]反
= [0000 0000 0000 0111]反
= [0000 0000 0000 0111]原
= 7
这足以证明,刚才的猜想是正确的:小数减去大数不会有问题,而大数减去小数的就不对了,结果始终相差 1。
相差的这个 1 要进行纠正,但是又不能影响小数减去大数,怎么办呢?于是人们又绞尽脑汁设计出了补码,给反码打了一个“补丁”,终于把相差的 1 给纠正过来了。
下面演示了按照补码计算的过程:
6 - 18 = 6 + (-18)
= [0000 0000 0000 0110]补 + [1111 1111 1110 1110]补
= [1111 1111 1111 0100]补
= [1111 1111 1111 0011]反
= [1000 0000 0000 1100]原
= -12
18 - 6 = 18 + (-6)
= [0000 0000 0001 0010]补 + [1111 1111 1111 1010]补
= [1 0000 0000 0000 1100]补
= [0000 0000 0000 1100]补
= [0000 0000 0000 1100]反
= [0000 0000 0000 1100]原
= 12
5 - 13 = 5 + (-13)
= [0000 0000 0000 0101]补 + [1111 1111 1111 0011]补
= [1111 1111 1111 1000]补
= [1111 1111 1111 0111]反
= [1000 0000 0000 1000]原
= -8
13 - 5 = 13 + (-5)
= [0000 0000 0000 1101]补 + [1111 1111 1111 1011]补
= [1 0000 0000 0000 1000]补
= [0000 0000 0000 1000]补
= [0000 0000 0000 1000]反
= [0000 0000 0000 1000]原
= 8
你看,采用补码的形式正好把相差的 1 纠正过来,也没有影响到小数减去大数,这个“补丁”真是巧妙。
小数减去大数,结果为负数,之前(负数从反码转换为补码要加 1)加上的 1,后来(负数从补码转换为反码要减 1)还要减去,正好抵消掉,所以不会受影响。
而大数减去小数,结果为正数,之前(负数从反码转换为补码要加 1)加上的 1,后来(正数的补码和反码相同,从补码转换为反码不用减 1)就没有再减去,不能抵消掉,这就相当于给计算结果多加了一个 1。
补码这种天才般的设计,一举达成了本文开头提到的两个目标,简化了硬件电路。
除了整数的存储,小数的存储也非常巧妙,也堪称天才般的设计,它的设计者还因此获得了图灵奖(计算机界的诺贝尔奖),我们将在《小数在内存中是如何存储的,揭秘诺贝尔奖级别的设计(长篇神文)》一节中介绍。
5、实例分析
上一节我们还留下了一个谜团,就是有符号数以无符号的形式输出,或者无符号数以有符号的形式输出时,会得到一个奇怪的值,请看下面的代码:
#include <stdio.h>
int main()
{
short a = 0100; //八进制
int b = -0x1; //十六进制
long c = 720; //十进制
unsigned short m = 0xffff; //十六进制
unsigned int n = 0x80000000; //十六进制
unsigned long p = 100; //十进制
//以无符号的形式输出有符号数
printf("a=%#ho, b=%#x, c=%lu\n", a, b, c);
//以有符号数的形式输出无符号类型(只能以十进制形式输出)
printf("m=%hd, n=%d, p=%ld\n", m, n, p);
return 0;
}
运行结果:
a=0100, b=0xffffffff, c=720
m=-1, n=-2147483648, p=100
其中,b、m、n 的输出结果看起来非常奇怪。
b 是有符号数,它在内存中的存储形式(也就是补码)为:
b = -0x1
= [1000 0000 …… 0000 0001]原
= [1111 1111 …… 1111 1110]反
= [1111 1111 …… 1111 1111]补
= [0xffffffff]补
%#x表示以无符号的形式输出,而无符号数的补码和原码相同,所以不用转换了,直接输出 0xffffffff 即可。
m 和 n 是无符号数,它们在内存中的存储形式为:
m = 0xffff
= [1111 1111 1111 1111]补
n = 0x80000000
= [1000 0000 …… 0000 0000]补
%hd和%d表示以有符号的形式输出,所以还要经过一个逆向的转换过程:
[1111 1111 1111 1111]补
= [1111 1111 1111 1110]反
= [1000 0000 0000 0001]原
= -1
[1000 0000 …… 0000 0000]补
= -231
= -2147483648
由此可见,-1 和 -2147483648 才是最终的输出值。
注意,
[1000 0000 …… 0000 0000]补是一个特殊的补码,无法按照本节讲到的方法转换为原码,所以计算机直接规定这个补码对应的值就是 -231,至于为什么,下节我们会详细分析。
七、C语言整数的取值范围以及数值溢出
short、int、long 是C语言中常用的三种整数类型,分别称为短整型、整型、长整型。
在现代操作系统中,short、int、long 的长度分别是 2、4、4 或者 8,它们只能存储有限的数值,当数值过大或者过小时,超出的部分会被直接截掉,数值就不能正确存储了,我们将这种现象称为溢出(Overflow)。
溢出的简单理解就是,向木桶里面倒入了过量的水,木桶盛不了了,水就流出来了。
要想知道数值什么时候溢出,就得先知道各种整数类型的取值范围。
1、无符号数的取值范围
计算无符号数(unsigned 类型)的取值范围(或者说最大值和最小值)很容易,将内存中的所有位(Bit)都置为 1 就是最大值,都置为 0 就是最小值。
以 unsigned char 类型为例,它的长度是 1,占用 8 位的内存,所有位都置为 1 时,它的值为 - 1 = 255,所有位都置为 0 时,它的值很显然为 0。由此可得,unsigned char 类型的取值范围是 0~255。
前面我们讲到,char 是一个字符类型,是用来存放字符的,但是它同时也是一个整数类型,也可以用来存放整数,请大家暂时先记住这一点,更多细节我们将在《在C语言中使用英文字符》一节中介绍。
有读者可能会对 unsigned char 的最大值有疑问,究竟是怎么计算出来的呢?下面我就讲解一下这个小技巧。
将 unsigned char 的所有位都置为 1,它在内存中的表示形式为1111 1111,最直接的计算方法就是:
+
+
+
+
+
+
+
= 1 + 2 + 4 + 8 + 16 + 32 + 64 + 128 = 255
这种“按部就班”的计算方法虽然有效,但是比较麻烦,如果是 8 个字节的 long 类型,那足够你计算半个小时的了。
我们不妨换一种思路,先给 1111 1111 加上 1,然后再减去 1,这样一增一减正好抵消掉,不会影响最终的值。
给 1111 1111 加上 1 的计算过程为:
0B1111 1111 + 0B1 = 0B1 0000 0000 =
= 256
可以发现,1111 1111 加上 1 后需要向前进位(向第 9 位进位),剩下的 8 位都变成了 0,这样一来,只有第 9 位会影响到数值的计算,剩下的 8 位对数值都没有影响。第 9 位的权值计算起来非常容易,就是:
-1 =
然后再减去 1:
加上 1 是为了便于计算,减去 1 是为了还原本来的值;当内存中所有的位都是 1 时,这种“凑整”的技巧非常实用。
按照这种巧妙的方法,我们可以很容易地计算出所有无符号数的取值范围(括号内为假设的长度):
| unsigned char | unsigned short | unsigned int(4字节) | unsigned long(8字节) | |
|---|---|---|---|---|
| 最小值 | 0 | 0 | 0 | 0 |
| 最大值 |
255 |
65,535 ≈ 6.5万 |
4,294,967,295 ≈ 42亿 |
1.84×1019 |
2、有符号数的取值范围
有符号数以补码的形式存储,计算取值范围也要从补码入手。我们以 char 类型为例,从下表中找出它的取值范围:
| 补码 | 反码 | 原码 | 值 |
|---|---|---|---|
| 1111 1111 | 1111 1110 | 1000 0001 | -1 |
| 1111 1110 | 1111 1101 | 1000 0010 | -2 |
| 1111 1101 | 1111 1100 | 1000 0011 | -3 |
| …… | …… | …… | …… |
| 1000 0011 | 1000 0010 | 1111 1101 | -125 |
| 1000 0010 | 1000 0001 | 1111 1110 | -126 |
| 1000 0001 | 1000 0000 | 1111 1111 | -127 |
| 1000 0000 | -- | -- | -128 |
| 0111 1111 | 0111 1111 | 0111 1111 | 127 |
| 0111 1110 | 0111 1110 | 0111 1110 | 126 |
| 0111 1101 | 0111 1101 | 0111 1101 | 125 |
| …… | …… | …… | …… |
| 0000 0010 | 0000 0010 | 0000 0010 | 2 |
| 0000 0001 | 0000 0001 | 0000 0001 | 1 |
| 0000 0000 | 0000 0000 | 0000 0000 | 0 |
我们按照从大到小的顺序将补码罗列出来,很容易发现最大值和最小值。
淡黄色背景的那一行是我要重点说明的。如果按照传统的由补码计算原码的方法,那么 1000 0000 是无法计算的,因为计算反码时要减去 1,1000 0000 需要向高位借位,而高位是符号位,不能借出去,所以这就很矛盾。
是不是该把 1000 0000 作为无效的补码直接丢弃呢?然而,作为无效值就不如作为特殊值,这样还能多存储一个数字。计算机规定,1000 0000 这个特殊的补码就表示 -128。
为什么偏偏是 -128 而不是其它的数字呢?
首先,-128 使得 char 类型的取值范围保持连贯,中间没有“空隙”。
其次,我们再按照“传统”的方法计算一下 -128 的补码:
- -128 的数值位的原码是 1000 0000,共八位,而 char 的数值位只有七位,所以最高位的 1 会覆盖符号位,数值位剩下 000 0000。最终,-128 的原码为 1000 0000。
- 接着很容易计算出反码,为 1111 1111。
- 反码转换为补码时,数值位要加上 1,变为 1000 0000,而 char 的数值位只有七位,所以最高位的 1 会再次覆盖符号位,数值位剩下 000 0000。最终求得的 -128 的补码是 1000 0000。
-128 从原码转换到补码的过程中,符号位被 1 覆盖了两次,而负数的符号位本来就是 1,被 1 覆盖多少次也不会影响到数字的符号。
你看,虽然从 1000 0000 这个补码推算不出 -128,但是从 -128 却能推算出 1000 0000 这个补码,这么多么的奇妙,-128 这个特殊值选得恰到好处。
负数在存储之前要先转换为补码,“从 -128 推算出补码 1000 0000”这一点非常重要,这意味着 -128 能够正确地转换为补码,或者说能够正确的存储。
3、关于零值和最小值
仔细观察上表可以发现,在 char 的取值范围内只有一个零值,没有+0和-0的区别,并且多存储了一个特殊值,就是 -128,这也是采用补码的另外两个小小的优势。
如果直接采用原码存储,那么0000 0000和1000 0000将分别表示+0和-0,这样在取值范围内就存在两个相同的值,多此一举。另外,虽然最大值没有变,仍然是 127,但是最小值却变了,只能存储到 -127,不能存储 -128 了,因为 -128 的原码为 1000 0000,这个位置已经被-0占用了。
按照上面的方法,我们可以计算出所有有符号数的取值范围(括号内为假设的长度):
| char | short | int(4个字节) | long(8个字节) | |
|---|---|---|---|---|
| 最小值 | - | - | - | - |
| 最大值 |
上节我们还留下了一个疑问,[1000 0000 …… 0000 0000]补这个 int 类型的补码为什么对应的数值是 -,有了本节对 char 类型的分析,相信聪明的你会举一反三,自己解开这个谜团。
4、数值溢出
char、short、int、long 的长度是有限的,当数值过大或者过小时,有限的几个字节就不能表示了,就会发生溢出。发生溢出时,输出结果往往会变得奇怪,请看下面的代码:
#include <stdio.h>
int main()
{
unsigned int a = 0x100000000;
int b = 0xffffffff;
printf("a=%u, b=%d\n", a, b);
return 0;
}
运行结果:
a=0, b=-1
变量 a 为 unsigned int 类型,长度为 4 个字节,能表示的最大值为 0xFFFFFFFF,而 0x100000000 = 0xFFFFFFFF + 1,占用33位,已超出 a 所能表示的最大值,所以发生了溢出,导致最高位的 1 被截去,剩下的 32 位都是0。也就是说,a 被存储到内存后就变成了 0,printf 从内存中读取到的也是 0。
变量 b 是 int 类型的有符号数,在内存中以补码的形式存储。0xffffffff 的数值位的原码为 1111 1111 …… 1111 1111,共 32 位,而 int 类型的数值位只有 31 位,所以最高位的 1 会覆盖符号位,数值位只留下 31 个 1,所以 b 的原码为:
1111 1111 …… 1111 1111
这也是 b 在内存中的存储形式。
当 printf 读取到 b 时,由于最高位是 1,所以会被判定为负数,要从补码转换为原码:
[1111 1111 …… 1111 1111]补
= [1111 1111 …… 1111 1110]反
= [1000 0000 …… 0000 0001]原
= -1
最终 b 的输出结果为 -1。
八、C语言中的小数(float,double)
小数分为整数部分和小数部分,它们由点号.分隔,例如 0.0、75.0、4.023、0.27、-937.198 -0.27 等都是合法的小数,这是最常见的小数形式,我们将它称为十进制形式。
此外,小数也可以采用指数形式,例如 7.25×、0.0368×
、100.22×
、-27.36×
等。任何小数都可以用指数形式来表示。
C语言同时支持以上两种形式的小数。但是在书写时,C语言中的指数形式和数学中的指数形式有所差异。
C语言中小数的指数形式为:
aEn 或 aen
a 为尾数部分,是一个十进制数;n 为指数部分,是一个十进制整数;E或e是固定的字符,用于分割尾数部分和指数部分。整个表达式等价于 a×。
指数形式的小数举例:
- 2.1E5 = 2.1×
,其中 2.1 是尾数,5 是指数。
- 3.7E-2 = 3.7×
,其中 3.7 是尾数,-2 是指数。
- 0.5E7 = 0.5×
,其中 0.5 是尾数,7 是指数。
C语言中常用的小数有两种类型,分别是 float 或 double;float 称为单精度浮点型,double 称为双精度浮点型。
不像整数,小数没有那么多幺蛾子,小数的长度是固定的,float 始终占用4个字节,double 始终占用8个字节。
1、小数的输出
小数也可以使用 printf 函数输出,包括十进制形式和指数形式,它们对应的格式控制符分别是:
- %f 以十进制形式输出 float 类型;
- %lf 以十进制形式输出 double 类型;
- %e 以指数形式输出 float 类型,输出结果中的 e 小写;
- %E 以指数形式输出 float 类型,输出结果中的 E 大写;
- %le 以指数形式输出 double 类型,输出结果中的 e 小写;
- %lE 以指数形式输出 double 类型,输出结果中的 E 大写。
下面的代码演示了小数的表示以及输出:
#include <stdio.h>
#include <stdlib.h>
int main()
{
float a = 0.302;
float b = 128.101;double c = 123;
float d = 112.64E3;
double e = 0.7623e-2;
float f = 1.23002398;
printf("a=%e \nb=%f \nc=%lf \nd=%lE \ne=%lf \nf=%f\n", a, b, c, d, e, f);
return 0;
}
运行结果:
a=3.020000e-01
b=128.100998
c=123.000000
d=1.126400E+05
e=0.007623
f=1.230024
对代码的说明:
1) %f 和 %lf 默认保留六位小数,不足六位以 0 补齐,超过六位按四舍五入截断。
2) 将整数赋值给 float 变量时会变成小数。
3) 以指数形式输出小数时,输出结果为科学计数法;也就是说,尾数部分的取值为:0 ≤ 尾数 < 10。
4) b 的输出结果让人费解,才三位小数,为什么不能精确输出,而是输出一个近似值呢?这和小数在内存中的存储形式有关,很多简单的小数压根不能精确存储,所以也就不能精确输出,我们将在下节《小数在内存中是如何存储的,揭秘诺贝尔奖级别的设计(长篇神文)》中详细讲解。
另外,小数还有一种更加智能的输出方式,就是使用%g。%g 会对比小数的十进制形式和指数形式,以最短的方式来输出小数,让输出结果更加简练。所谓最短,就是输出结果占用最少的字符。
%g 使用示例:
#include <stdio.h>
#include <stdlib.h>
int main()
{
float a = 0.00001;
float b = 30000000;
float c = 12.84;
float d = 1.229338455;
printf("a=%g \nb=%g \nc=%g \nd=%g\n", a, b, c, d);
return 0;
}
运行结果:
a=1e-05
b=3e+07
c=12.84
d=1.22934
对各个小数的分析:
- a 的十进制形式是 0.00001,占用七个字符的位置,a 的指数形式是 1e-05,占用五个字符的位置,指数形式较短,所以以指数的形式输出。
- b 的十进制形式是 30000000,占用八个字符的位置,b 的指数形式是 3e+07,占用五个字符的位置,指数形式较短,所以以指数的形式输出。
- c 的十进制形式是 12.84,占用五个字符的位置,c 的指数形式是 1.284e+01,占用九个字符的位置,十进制形式较短,所以以十进制的形式输出。
- d 的十进制形式是 1.22934,占用七个字符的位置,d 的指数形式是 1.22934e+00,占用十一个字符的位置,十进制形式较短,所以以十进制的形式输出。
读者需要注意的两点是:
- %g 默认最多保留六位有效数字,包括整数部分和小数部分;%f 和 %e 默认保留六位小数,只包括小数部分。
- %g 不会在最后强加 0 来凑够有效数字的位数,而 %f 和 %e 会在最后强加 0 来凑够小数部分的位数。
总之,%g 要以最短的方式来输出小数,并且小数部分表现很自然,不会强加零,比 %f 和 %e 更有弹性,这在大部分情况下是符合用户习惯的。
除了 %g,还有 %lg、%G、%lG:
- %g 和 %lg 分别用来输出 float 类型和 double 类型,并且当以指数形式输出时,
e小写。 - %G 和 %lG 也分别用来输出 float 类型和 double 类型,只是当以指数形式输出时,
E大写。
2、数字的后缀
一个数字,是有默认类型的:对于整数,默认是 int 类型;对于小数,默认是 double 类型。
请看下面的例子:
long a = 100;
int b = 294;
float x = 52.55;
double y = 18.6;
100 和 294 这两个数字默认都是 int 类型的,将 100 赋值给 a,必须先从 int 类型转换为 long 类型,而将 294 赋值给 b 就不用转换了。
52.55 和 18.6 这两个数字默认都是 double 类型的,将 52.55 赋值给 x,必须先从 double 类型转换为 float 类型,而将 18.6 赋值给 y 就不用转换了。
如果不想让数字使用默认的类型,那么可以给数字加上后缀,手动指明类型:
- 在整数后面紧跟 l 或者 L(不区分大小写)表明该数字是 long 类型;
- 在小数后面紧跟 f 或者 F(不区分大小写)表明该数字是 float 类型。
请看下面的代码:
long a = 100l;
int b = 294;
short c = 32L;
float x = 52.55f;
double y = 18.6F;
float z = 0.02;
加上后缀,虽然数字的类型变了,但这并不意味着该数字只能赋值给指定的类型,它仍然能够赋值给其他的类型,只要进行了一下类型转换就可以了。
对于初学者,很少会用到数字的后缀,加不加往往没有什么区别,也不影响实际编程,但是既然学了C语言,还是要知道这个知识点的,万一看到别人的代码这么用了,而你却不明白怎么回事,那就尴尬了。
关于数据类型的转换,我们将在《C语言数据类型转换(自动类型转换+强制类型转换)》一节中深入探讨。
3、小数和整数相互赋值
在C语言中,整数和小数之间可以相互赋值:
- 将一个整数赋值给小数类型,在小数点后面加 0 就可以,加几个都无所谓。
- 将一个小数赋值给整数类型,就得把小数部分丢掉,只能取整数部分,这会改变数字本来的值。注意是直接丢掉小数部分,而不是按照四舍五入取近似值。
请看下面的代码:
#include <stdio.h>
int main(){
float f = 251;
int w = 19.427;
int x = 92.78;
int y = 0.52;
int z = -87.27;
printf("f = %f, w = %d, x = %d, y = %d, z = %d\n", f, w, x, y, z);
return 0;
}
运行结果:
f = 251.000000, w = 19, x = 92, y = 0, z = -87
由于将小数赋值给整数类型时会“失真”,所以编译器一般会给出警告,让大家引起注意。
九、小数在内存中是如何存储的,揭秘诺贝尔奖级别的设计(长篇神文)
小数在内存中是以浮点数的形式存储的。浮点数并不是一种数值分类,它和整数、小数、实数等不是一个层面的概念。浮点数是数字(或者说数值)在内存中的一种存储格式,它和定点数是相对的。
C语言使用定点数格式来存储 short、int、long 类型的整数,使用浮点数格式来存储 float、double 类型的小数。整数和小数在内存中的存储格式不一样。
我们在学习C语言时,通常认为浮点数和小数是等价的,并没有严格区分它们的概念,这也并没有影响到我们的学习,原因就是浮点数和小数是绑定在一起的,只有小数才使用浮点格式来存储。
其实,整数和小数可以都使用定点格式来存储,也可以都使用浮点格式来存储,但实际情况却是,C语言使用定点格式存储整数,使用浮点格式存储小数,这是在“数值范围”和“数值精度”两项重要指标之间追求平衡的结果,稍后我会给大家带来深入的剖析。
计算机的设计是一门艺术,很多实用技术都是权衡和妥协的结果。
浮点数和定点数中的“点”指的就是小数点!对于整数,可以认为小数点后面都是零,小数部分是否存在并不影响整个数字的值,所以干脆将小数部分省略,只保留整数部分。
1、定点数
所谓定点数,就是指小数点的位置是固定的,不会向前或者向后移动。
假设我们用4个字节(32位)来存储无符号的定点数,并且约定,前16位表示整数部分,后16位表示小数部分,如下图所示:

如此一来,小数点就永远在第16位之后,整数部分和小数部分一目了然,不管什么时候,整数部分始终占用16位(不足16位前置补0),小数部分也始终占用16位(不足16位后置补0)。例如,在内存中存储了 10101111 00110001 01011100 11000011,那么对应的小数就是 10101111 00110001 . 01011100 11000011,非常直观。
(1)精度
小数部分的最后一位可能是精确数字,也可能是近似数字(由四舍五入、向零舍入等不同方式得到);除此以外,剩余的31位都是精确数字。从二进制的角度看,这种定点格式的小数,最多有 32 位有效数字,但是能保证的是 31 位;也就是说,整体的精度为 31~32 位。
(2)数值范围
将内存中的所有位(Bit)都置为 1,小数的值最大,为 -
,极其接近
,换算成十进制为 65 536。将内存中最后一位(第32位)置1,其它位都置0,小数的值最小,为
。
这里所说的最小值不是 0 值,而是最接近 0 的那个值。
(3)综述
用定点格式来存储小数,优点是精度高,因为所有的位都用来存储有效数字了,缺点是取值范围太小,不能表示很大或者很小的数字。
(4)反面例子
在科学计算中,小数的取值范围很大,最大值和最小值的差距有上百个数量级,使用定点数来存储将变得非常困难。
例如,电子的质量为:
0.0000000000000000000000000009 克 = 9 ×
克
太阳的质量为:
2000000000000000000000000000000000 克 = 2 ×
克
如果使用定点数,那么只能按照=前面的格式来存储,这将需要很大的一块内存,大到需要几十个字节。
更加科学的方案是按照=后面的指数形式来存储,这样不但节省内存,也非常直观。这种以指数的形式来存储小数的解决方案就叫做浮点数。浮点数是对定点数的升级和优化,克服了定点数取值范围太小的缺点。
2、浮点数
C语言标准规定,小数在内存中以科学计数法的形式来存储,具体形式为:
flt =
× mantissa ×
对各个部分的说明:
- flt 是要表示的小数。
- sign 用来表示 flt 的正负号,它的取值只能是 0 或 1:取值为 0 表示 flt 是正数,取值为 1 表示 flt 是负数。
- base 是基数,或者说进制,它的取值大于等于 2(例如,2 表示二进制、10 表示十进制、16 表示十六进制……)。数学中常见的科学计数法是基于十进制的,例如 6.93 ×
;计算机中的科学计数法可以基于其它进制,例如 1.001 ×
- mantissa 为尾数,或者说精度,是 base 进制的小数,并且 1 ≤ mantissa < base,这意味着,小数点前面只能有一位数字;
- exponent 为指数,是一个整数,可正可负,并且为了直观一般采用十进制表示。
下面我们以 19.625 为例来演示如何将小数转换为浮点格式。
当 base 取值为 10 时,19.625 的浮点形式为:
19.625 = 1.9625 ×
当 base 取值为 2 时,将 19.625 转换成二进制为 10011.101,用浮点形式来表示为:
19.625 = 10011.101 = 1.0011101×
19.625 整数部分的二进制形式为:
19 = 1×
小数部分的二进制形式为:
0.625 = 1×+ 0×
+ 1×
= 101
将整数部分和小数部分合并在一起:
19.625 = 10011.101
可以看出,当基数(进制)base 确定以后,指数 exponent 实际上就成了小数点的移动位数:
- exponent 大于零,mantissa 中的小数点右移 exponent 位即可还原小数的值;
- exponent 小于零,mantissa 中的小数点左移 exponent 位即可还原小数的值。
换句话说,将小数转换成浮点格式后,小数点的位置发生了浮动(移动),并且浮动的位数和方向由 exponent 决定,所以我们将这种表示小数的方式称为浮点数。
3、二进制形式的浮点数的存储
虽然C语言标准没有规定 base 使用哪种进制,但是在实际应用中,各种编译器都将 base 实现为二进制,这样不仅贴近计算机硬件(任何数据在计算机底层都以二进制形式表示),还能减少转换次数。
接下来我们就讨论一下如何将二进制形式的浮点数放入内存中。
原则上讲,上面的科学计数法公式中,符号 sign、尾数 mantissa、基数 base 和指数 exponent 都是不确定因素,都需要在内存中体现出来。但是现在基数 base 已经确定是二进制了,就不用在内存中体现出来了,这样只需要在内存中存储符号 sign、尾数 mantissa、指数 exponent 这三个不确定的元素就可以了。
仍然以 19.625 为例,将它转换成二进制形式的浮点数格式:
19.625 = 1.0011101×
此时符号 sign 为 0,尾数 mantissa 为 1.0011101,指数 exponent 为 4。
(1)符号的存储
符号的存储很容易,就像存储 short、int 等普通整数一样,单独分配出一个位(Bit)来,用 0 表示正数,用 1 表示负数。对于 19.625,这一位的值是 0。
(2)尾数的存储
当采用二进制形式后,尾数部分的取值范围为 1 ≤ mantissa < 2,这意味着:尾数的整数部分一定为 1,是一个恒定的值,这样就无需在内存中提现出来,可以将其直接截掉,只要把小数点后面的二进制数字放入内存中即可。对于 1.0011101,就是把 0011101 放入内存。
我们不妨将真实的尾数命名为 mantissa,将内存中存储的尾数命名为 mant,那么它们之间的关系为:
mantissa = 1.mant
如果 base 采用其它进制,那么尾数的整数部分就不是固定的,它有多种取值的可能,以十进制为例,尾数的整数部分可能是 1~9 之间的任何一个值,这样一来尾数的整数部分就不能省略了,必须在内存中体现出来。而将 base 设置为二进制就可以节省掉一个位(Bit)的内存,这也算是采用二进制的一点点优势。
(3) 指数的存储
指数是一个整数,并且有正负之分,不但需要存储它的值,还得能区分出正负号来。
short、int、long 等类型的整数在内存中的存储采用的是补码加符号位的形式,数值在写入内存之前必须先进行转换,读取以后还要再转换一次。但是为了提高效率,避免繁琐的转换,指数的存储并没有采用补码加符号位的形式,而是设计了一套巧妙的解决方案,稍等我会为您解开谜团。
4、为二进制浮点数分配内存
C语言中常用的浮点数类型为 float 和 double;float 始终占用 4 个字节,double 始终占用 8 个字节。
下图演示了 float 和 double 的存储格式:

浮点数的内存被分成了三部分,分别用来存储符号 sign、尾数 mantissa 和指数 exponent ,当浮点数的类型确定后,每一部分的位数就是固定的。
符号 sign 可以不加修改直接放入内存中,尾数 mantissa 只需要将小数部分放入内存中,最让人疑惑的是指数 exponent 如何放入内存中,这也是我们在前面留下的一个谜团,下面我们以 float 为例来揭开谜底。
float 的指数部分占用 8 Bits,能表示从 0~255 的值,取其中间值 127,指数在写入内存前先加上127,读取时再减去127,正数负数就显而易见了。19.625 转换后的指数为 4,4+127 = 131,131 换算成二进制为 1000 0011,这就是 19.626 的指数部分在 float 中的最终存储形式。
先确定内存中指数部分的取值范围,得到一个中间值,写入指数时加上这个中间值,读取指数时减去这个中间值,这样符号和值就都能确定下来了。
中间值的求取有固定的公式。设中间值为 median,指数部分占用的内存为 n 位,那么中间值为:
median =
- 1
对于 float,中间值为 - 1 = 127;对于 double,中间值为
-1 = 1023。
我们不妨将真实的指数命名为 exponent,将内存中存储的指数命名为 exp,那么它们之间的关系为:
exponent = exp - median
也可以写作:
exp = exponent + median
为了方便后续文章的编写,这里我强调一下命名:
- mantissa 表示真实的尾数,包括整数部分和小数部分;mant 表示内存中存储的尾数,只有小数部分,省略了整数部分。
- exponent 表示真实的指数,exp 表示内存中存储的指数,exponent 和 exp 并不相等,exponent 加上中间数 median 才等于 exp。
5、用代码验证 float 的存储
19.625 转换成二进制的指数形式为:
19.625 = 1.0011101×
此时符号为 0;尾数为 1.0011101,截掉整数部分后为 0011101,补齐到 23 Bits 后为 001 1101 0000 0000 0000 0000;指数为 4,4+127 = 131,131 换算成二进制为 1000 0011。
综上所述,float 类型的 19.625 在内存中的值为:0 - 10000011 - 001 1101 0000 0000 0000 0000。
下面我们通过代码来验证一下:
#include <stdio.h>
#include <stdlib.h>
//浮点数结构体
typedef struct {
unsigned int nMant : 23; //尾数部分
unsigned int nExp : 8; //指数部分
unsigned int nSign : 1; //符号位
} FP_SINGLE;
int main()
{
char strBin[33] = { 0 };
float f = 19.625;
FP_SINGLE *p = (FP_SINGLE*)&f;
itoa(p->nSign, strBin, 2);
printf("sign: %s\n", strBin);
itoa(p->nExp, strBin, 2);
printf("exp: %s\n", strBin);
itoa(p->nMant, strBin, 2);
printf("mant: %s\n", strBin);
return 0;
}
运行结果:
sign: 0
exp: 10000011
mant: 111010000000000000000
mant 的位数不足,在前面补齐两个 0 即可。
printf() 不能直接输出二进制形式,这里我们借助 itoa() 函数将十进制数转换成二进制的字符串,再使用%s输出。itoa() 虽然不是标准函数,但是大部分编译器都支持。不过 itoa() 在 C99 标准中已经被指定为不可用函数,在一些严格遵循 C99 标准的编译器下会失效,甚至会引发错误,例如在 Xcode(使用 LLVM 编译器)下就会编译失败。如果 itoa() 无效,请使用%X输出十六进制形式,十六进制能够很方便地转换成二进制。
6、精度问题
对于十进制小数,整数部分转换成二进制使用“展除法”(就是不断除以 2,直到余数为 0),一个有限位数的整数一定能转换成有限位数的二进制。但是小数部分就不一定了,小数部分转换成二进制使用“乘二取整法”(就是不断乘以 2,直到小数部分为 0),一个有限位数的小数并不一定能转换成有限位数的二进制,只有末位是 5 的小数才有可能转换成有限位数的二进制,其它的小数都不行。
float 和 double 的尾数部分是有限的,固然不能容纳无限的二进制;即使小数能够转换成有限的二进制,也有可能会超出尾数部分的长度,此时也不能容纳。这样就必须“四舍五入”,将多余的二进制“处理掉”,只保留有效长度的二进制,这就涉及到了精度的问题。也就是说,浮点数不一定能保存真实的小数,很有可能保存的是一个近似值。
对于 float,尾数部分有 23 位,再加上一个隐含的整数 1,一共是 24 位。最后一位可能是精确数字,也可能是近似数字(由四舍五入、向零舍入等不同方式得到);除此以外,剩余的23位都是精确数字。从二进制的角度看,这种浮点格式的小数,最多有 24 位有效数字,但是能保证的是 23 位;也就是说,整体的精度为 23~24 位。如果转换成十进制, = 16 777 216,一共8位;也就是说,最多有 8 位有效数字,但是能保证的是 7 位,从而得出整体精度为 7~8 位。
对于 double,同理可得,二进制形式的精度为 52~53 位,十进制形式的精度为 15~16 位。
7、IEEE 754 标准
浮点数的存储以及加减乘除运算是一个比较复杂的问题,很多小的处理器在硬件指令方面甚至不支持浮点运算,其他的则需要一个独立的协处理器来处理这种运算,只有最复杂的处理器才会在硬件指令集中支持浮点运算。省略浮点运算,可以将处理器的复杂度减半!如果硬件不支持浮点运算,那么只能通过软件来实现,代价就是需要容忍不良的性能。
PC 和智能手机上的处理器就是最复杂的处理器了,它们都能很好地支持浮点运算。
在六七十年代,计算机界对浮点数的处理比较混乱,各家厂商都有自己的一套规则,缺少统一的业界标准,这给数据交换、计算机协同工作带来了很大不便。
作为处理器行业的老大,Intel 早就意识到了这个问题,并打算一统浮点数的世界。Intel 在研发 8087 浮点数协处理器时,聘请到加州大学伯克利分校的 William Kahan 教授(最优秀的数值分析专家之一)以及他的两个伙伴,来为 8087 协处理器设计浮点数格式,他们的工作完成地如此出色,设计的浮点数格式具有足够的合理性和先进性,被 IEEE 组织采用为浮点数的业界标准,并于 1985 年正式发布,这就是 IEEE 754 标准,它等同于国际标准 ISO/IEC/IEEE 60559。
IEEE 是 Institute of Electrical and Electronics Engineers 的简写,中文意思是“电气和电子工程师协会”。
IEEE 754 简直是天才一般的设计,William Kahan 教授也因此获得了 1987 年的图灵奖。图灵奖是计算机界的“诺贝尔奖”。
目前,几乎所有的计算机都支持 IEEE 754 标准,大大改善了科学应用程序的可移植性,C语言编译器在实现浮点数时也采用了该标准。
不过,IEEE 754 标准的出现晚于C语言标准(最早的 ANSI C 标准于 1983 年发布),C语言标准并没有强制编译器采用 IEEE 754 格式,只是说要使用科学计数法的形式来表示浮点数,但是编译器在实现浮点数时,都采用了 IEEE 754 格式,这既符合C语言标准,又符合 IEEE 标准,何乐而不为。
8、特殊值
IEEE 754 标准规定,当指数 exp 的所有位都为 1 时,不再作为“正常”的浮点数对待,而是作为特殊值处理:
- 如果此时尾数 mant 的二进制位都为 0,则表示无穷大:
- 如果符号 sign 为 1,则表示负无穷大;
- 如果符号 sign 为 0,则表示正无穷大。
- 如果此时尾数 mant 的二进制位不全为 0,则表示 NaN(Not a Number),也即这是一个无效的数字,或者该数字未经初始化。
9、非规格化浮点数
当指数 exp 的所有二进制位都为 0 时,情况也比较特殊。
对于“正常”的浮点数,尾数 mant 隐含的整数部分为 1,并且在读取浮点数时,内存中的指数 exp 要减去中间值 median 才能还原真实的指数 exponent,也即:
mantissa = 1.mant
exponent = exp - median
但是当指数 exp 的所有二进制位都为 0 时,一切都变了!尾数 mant 隐含的整数部分变成了 0,并且用 1 减去中间值 median 才能还原真实的指数 exponent,也即:
mantissa = 0.mant
exponent = 1 - median
对于 float,exponent = 1 - 127 = -126,指数 exponent 的值恒为 -126;对于 double,exponent = 1 - 1023 = -1022,指数 exponent 的值恒为 -1022。
当指数 exp 的所有二进制位都是 0 时,我们将这样的浮点数称为“非规格化浮点数”;当指数 exp 的所有二进制位既不全为 0 也不全为 1 时,我们称之为“规格化浮点数”;当指数 exp 的所有二进制位都是 1 时,作为特殊值对待。 也就是说,究竟是规格化浮点数,还是非规格化浮点数,还是特殊值,完全看指数 exp。
(1)+0 和 -0 的表示
对于非规格化浮点数,当尾数 mant 的所有二进制位都为 0 时,整个浮点数的值就为 0:
- 如果符号 sign 为 0,则表示 +0;
- 如果符号 sign 为 1,则表示 -0。
10、IEEE 754 为什么增加非规格化浮点数
我们以 float 类型为例来说明。
对于规格化浮点数,当尾数 mant 的所有位都为 0、指数 exp 的最低位为 1 时,浮点数的绝对值最小(符号 sign 的取值不影响绝对值),为 1.0 × ,也即
。
对于一般的计算,这个值已经很小了,非常接近 0 值了,但是对于科学计算,它或许还不够小,距离 0 值还不够近,非规格化浮点数就是来弥补这一缺点的:非规格化浮点数可以让最小值更小,更加接近 0 值。
对于非规格化浮点数,当尾数的最低位为 1 时,浮点数的绝对值最小,为 ×
=
,这个值比
小了 23 个数量级,更加即接近 0 值。
让我更加惊讶的是,规格化浮点数能够很平滑地过度到非规格化浮点数,它们之间不存在“断层”,下表能够让读者看得更加直观。
| 说明 | float 内存 | exp | exponent | mant | mantissa | 浮点数的值 flt |
|---|---|---|---|---|---|---|
| 0值 最小非规格化数 最大非规格化数 | 0 - 00...00 - 00...00 0 - 00...00 - 00...01 0 - 00...00 - 00...10 0 - 00...00 - 00...11 …… 0 - 00...00 - 11...10 0 - 00...00 - 11...11 | 0 0 0 0 …… 0 0 | -126 -126 -126 -126 …… -126 -126 | 0 2^-23 2^-22 1.1 × 2^-22 …… 0.11...10 0.11...11 | 0 2^-23 2^-22 1.1 × 2^-22 …… 0.11...10 0.11...11 | +0 2^-149 2^-148 1.1 × 2^-148 …… 1.11...10 × 2^-127 1.11...11 × 2^-127 |
| 最小规格化数 最大规格化数 | 0 - 00...01 - 00...00 0 - 00...01 - 00...01 …… 0 - 00...10 - 00...00 0 - 00...10 - 00...01 …… 0 - 11...10 - 11...10 0 - 11...10 - 11...11 | 1 1 …… 2 2 …… 254 254 | -126 -126 …… -125 -125 127 127 | 0.0 0.00...01 …… 0.0 0.00...01 …… 0.11...10 0.11...11 | 1.0 1.00...01 …… 1.0 1.00...01 …… 1.11...10 1.11...11 | 1.0 × 2^-126 1.00...01 × 2^-126 …… 1.0 × 2^-125 1.00...01 × 2^-125 …… 1.11...10 × 2^127 1.11...11 × 2^127 |
| 0 - 11...11 - 00...00 | - | - | - | - | +∞ | |
| 0 - 11...11 - 00...01 …… 0 - 11...11 - 11...11 | - | - | - | - | NaN |
^ 表示次方,例如 2^10 表示 2 的 10 次方。
上表演示了正数时的情形,负数与此类似。请读者注意观察最大非规格化数和最小规格化数,它们是连在一起的,是平滑过渡的。
11、舍入模式
浮点数的尾数部分 mant 所包含的二进制位有限,不可能表示太长的数字,如果尾数部分过长,在放入内存时就必须将多余的位丢掉,取一个近似值。究竟该如何来取这个近似值,IEEE 754 列出了四种不同的舍入模式。
(1)舍入到最接近的值
就是将结果舍入为最接近且可以表示的值,这是默认的舍入模式。最近舍入模式和我们平时所见的“四舍五入”非常类似,但有一个细节不同。
对于最近舍入模式,IEEE 754 规定,当有两个最接近的可表示的值时首选“偶数”值;而对于四舍五入模式,当有两个最接近的可表示的值时要选较大的值。以十进制为例,就是对.5的舍入上采用偶数的方式,请看下面的例子。
最近舍入模式:Round(0.5) = 0、Round(1.5) = 2、Round(2.5) = 2
四舍五入模式:Round(0.5) = 1、Round(1.5) = 2、Round(2.5) = 3
(2) 向 +∞ 方向舍入(向上舍入)
会将结果朝正无穷大的方向舍入。标准库函数 ceil() 使用的就是这种舍入模式,例如,ceil(1.324) = 2,Ceil(-1.324) = -1。
(3)向 -∞ 方向舍入(向下舍入)
会将结果朝负无穷大的方向舍入。标准库函数 floor() 使用的就是这种舍入模式,例如,floor(1.324) = 1,floor(-1.324) = -2。
(4) 向 0 舍入(直接截断)
会将结果朝接近 0 的方向舍入,也就是将多余的位数直接丢掉。C语言中的类型转换使用的就是这种舍入模式,例如,(int)1.324 = 1,(int) -1.324 = -1。
12、总结
与定点数相比,浮点数在精度方面损失不小,但是在取值范围方面增大很多。牺牲精度,换来取值范围,这就是浮点数的整体思想。
IEEE 754 标准其实还规定了浮点数的加减乘除运算,不过本文的重点是讲解浮点数的存储,所以对于浮点数的运算不再展开讨论。
13、答疑解惑
上节我们还留下了一个疑问,就是用 %f 输出 128.101 时得到的是一个近似值,而不是一个精确值,这是因为,128.101 转换为浮点格式后,尾数部分过长,被丢掉了,不能“真实”地存储了。
128.101 转换成二进制为:
10000000.0001100111011011001000101101……(无限循环)
向左移动 7 位后为:
1.00000000001100111011011001000101101……
由此可见,尾数部分为:
000 0000 0001 1001 1101 1011 001000101101……
将多出的二进制丢掉后为:
000 0000 0001 1001 1101 1011
使用 printf 输出时,还需要进行还原,还原后的二进制为:
10000000.0001100111011011
转换成十进制为 128.1009979248046875,按照四舍五入的原则取 6 位小数,就是128.100998。