报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集
20周的完整安排请点击:20周计划
每周发1个博客,共20周。
在QQ群上答疑:

文章目录
- 1. DFS剪枝概述
- 2. 剪枝例题
- 2.1 可行性剪枝:数的划分
- 2.2 最优性剪枝、可行性剪枝:生日蛋糕
- 2.3 可行性剪枝、记忆化搜索、DFS所有路径:最长距离
- 2.4 搜索顺序剪枝、可行性剪枝、排除等效冗余:小木棍
第13周: DFS剪枝
搜索必剪枝
无剪枝不搜索
1. DFS剪枝概述
DFS是暴力法的直接实现,它把所有可能的状态都搜出来,然后从中找到解。
暴力法往往比较低效,因为它把时间浪费在很多不必要的计算上。
DFS能不能优化?这就是剪枝。剪枝是DFS常用的优化手段,常常能把指数级的复杂度,优化到近似多项式的复杂度。
什么是剪枝?剪枝是一个比喻:把不会产生答案的、不必要的枝条“剪掉”。答案留在没有剪掉的枝条上,只搜索这部分枝条就可以了,从而减少搜索量,提高DFS的效率。用DFS解题时,大多数情况下都需要剪枝,以至于可以说:搜索必剪枝、无剪枝不搜索。
剪枝的关键在于剪枝的判断:剪什么枝、在哪里减。DFS的剪枝技术较多,有可行性剪枝、最优性剪枝、搜索顺序剪枝、排除等效冗余、记忆化搜索等等。
(1)可行性剪枝:对当前状态进行检查,如果当前条件不合法就不再继续,直接返回。
(2)搜索顺序剪枝:搜索树有多个层次和分支,不同的搜索顺序会产生不同的搜索树形态,复杂度也相差很大。
(3)最优性剪枝:在最优化问题的搜索过程中,如果当前花费的代价已超过前面搜索到的最优解,那么本次搜索已经没有继续进行下去的意义,此时停止对当前分支的搜索进行回溯。
(4)排除等效冗余:搜索的不同分支,最后的结果是一样的,那么只搜一个分支就够了。
(5)记忆化搜索:在递归的过程中,有许多分支被反复计算,会大大降低算法的执行效率。用记忆化搜索,将已经计算出来的结果保存起来,以后需要用到的时候直接取出结果,避免重复运算,从而提高了算法的效率。
概括剪枝的总体思想:减少搜索状态。在进一步DFS之前,用剪枝判断,若能够剪枝则直接返回,不再继续DFS。
下面用例题介绍这些剪枝方法。
2. 剪枝例题
2.1 可行性剪枝:数的划分
链接:数的划分
整数划分是经典问题,标准解法是动态规划、母函数,计算复杂度为 O ( n 2 ) O(n^2) O(n2)。当n较小时,也可以用DFS暴搜出答案。
《算法竞赛》,清华大学出版社,494页,“7.8.1 普通型母函数”介绍了整数划分的动态规划和母函数解法。
DFS求解整数划分的思路,就是模拟划分的过程。由于题目不用考虑划分数的大小顺序,为了简化划分过程,让k份数从小到大进行。
第一个数肯定是最小的数字1;
第二个数大于等于第一个数,可选1、2、…,最大不能超过(n-1)/(k-1)。设第2个数是x。
第三个数大于等于第二个数,可选x、x+1、…,最大不能超过(n-1-x)/(k-2)。这个最大值的限制就是可行性剪枝。
继续以上划分过程,当划分了k个数,且它们的和为n时,就是一个合法的划分。
C++代码。代码的计算量有多大?可以用变量num记录进入dfs()的次数,当n=200,k=6时,答案是4132096,num=147123026,计算量非常大。
C++代码
#include <bits/stdc++.h>
using namespace std;
int n,k,cnt;
void dfs(int x,int sum,int u){ //x:上次分的数; u:已经分了u个数; sum:前面u-1个数的和
if(u==k){ //已经分成了k个
if(sum==n) cnt++; //k个加起来等于n,这是一个解
return;
}
for(int i=x;sum+i*(k-u)<=n;i++) //剪枝,i的最大值不超过(n-sum)/(k-u)
dfs(i,sum+i,u+1);
}
int main(){
cin >>n>>k;
dfs(1,0,0); //第一个划分数是1
cout<<cnt;
}
Java代码
import java.util.Scanner;
public class Main {
static int n, k, cnt;
public static void dfs(int x, int sum, int u) {
if (u == k) {
if (sum == n) cnt++;
return;
}
for (int i=x; sum + i * (k - u) <= n; i++) dfs(i, sum + i, u + 1);
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
k = scanner.nextInt();
dfs(1, 0, 0);
System.out.println(cnt);
}
}
Python代码
n, k = map(int, input().split())
cnt =0
def dfs(x, sum, u):
global cnt
if u == k:
if sum == n: cnt += 1
return
for i in range(x, int((n - sum) / (k - u)) + 1):
dfs(i, sum + i, u + 1)
dfs(1, 0, 0)
print(cnt)
2.2 最优性剪枝、可行性剪枝:生日蛋糕
链接:生日蛋糕
侧面积 =
2
π
R
H
2πRH
2πRH,底面积 =
π
R
2
πR^2
πR2,体积=
π
R
2
H
πR^2H
πR2H。下面的讨论中忽略
π
π
π。
蛋糕的面积=侧面积+上表面面积。在下图中,黑色的是上表面面积之和,它等于最下面一层的底面积。设最下面一层半径是
i
i
i,则黑色的上表面面积之和
s
=
i
×
i
s=i×i
s=i×i。
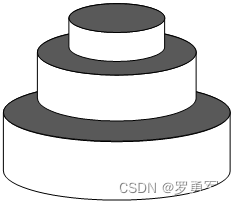
本题用DFS枚举每一层的高度和半径,并做可行性剪枝和最优性剪枝。
设最上面一层是第1层,最下面一层是第m层。从第m层开始DFS。用函数dfs(k, r, h, s, v)枚举所有层,当前处理到第k层,第k层的半径为r,高度为h,s是最底层到第k层的上表面面积,v是最底层到第k层的体积。并预处理数组sk[]、v[],sk[i]表示第1~第i层的最小侧面面积、vk[i]表示第1~第i层的最小体积。
(1)最优性剪枝1:面积。记录已经得到的最小面积ans,如果在DFS中得到的面积已经大于ans,返回。当前处理到第k层,第k层的半径是r。第k层的体积是
n
−
v
=
r
2
h
n-v=r^2h
n−v=r2h,得
h
=
(
n
−
v
)
/
r
2
h=(n-v)/r^2
h=(n−v)/r2;第k层侧面积
s
c
=
2
r
h
=
2
r
(
n
−
v
)
/
r
2
=
2
(
n
−
v
)
/
r
sc=2rh=2r(n-v)/r^2=2(n-v)/r
sc=2rh=2r(n−v)/r2=2(n−v)/r。剪枝判断:若
s
c
+
s
=
2
(
n
−
v
)
/
r
+
s
≥
a
n
s
sc + s = 2(n-v)/r + s ≥ ans
sc+s=2(n−v)/r+s≥ans,返回。
(2)可行性剪枝2:体积。如果当前已经遍历的各层的体积之和已经大于题目给定的体积n,返回。剪枝判断:若
v
+
v
k
[
k
−
1
]
>
n
v + vk[k-1] > n
v+vk[k−1]>n,返回。
(3)可行性剪枝3:半径和高度。枚举每一层的半径
i
i
i和高度
j
j
j时,应该比下面一层的半径和高度小。第k-1层的体积是
i
2
h
i^2h
i2h,它不能超过
n
−
v
−
v
k
[
k
−
1
]
n-v-vk[k-1]
n−v−vk[k−1],由
i
2
h
≤
n
−
v
−
v
k
[
k
−
1
]
i^2h≤n-v-vk[k-1]
i2h≤n−v−vk[k−1]得
h
≤
(
n
−
v
−
v
k
[
k
−
1
]
)
/
i
2
h≤(n-v-vk[k-1])/i^2
h≤(n−v−vk[k−1])/i2,剪枝判断:高度
j
j
j应该小于
(
n
−
v
−
v
k
[
k
−
1
]
)
/
i
2
(n-v-vk[k-1])/i^2
(n−v−vk[k−1])/i2。
C++代码
#include<bits/stdc++.h>
using namespace std;
const int INF=0x3f3f3f3f;
int ans=INF;
int sk[20],vk[20],n,m;
void dfs(int k,int r,int h,int s,int v) {//当前层、半径、高度、黑色上表面总面积、体积
int MAX_h = h;
if(k==0) { //蛋糕做完了
if(v==n) ans=min(ans,s); //更新表面积
return;
}
if(v+vk[k-1] > n) return; //体积>n,退出。剪枝2
if(2*(n-v)/r+s >= ans) return; //侧面积+黑色总面积 > ans,退出。剪枝1
for(int i=r-1; i>=k; i--) { //枚举k-1层的半径i,i比下一层的半径小,剪枝3
if(k==m) s = i*i; //黑色总面积
MAX_h = min(h-1, (n-vk[k-1]-v)/i/i); //第k-1层最大的高度
for(int j = MAX_h; j>=k; j--) //枚举k-1层高度j,j比下一层的高小,剪枝3
dfs(k-1,i,j,s+2*i*j,v+i*i*j);
}
}
int main() {
cin>>n>>m; //n:目标体积,m:层数
for(int i=1; i<=m; i++) { // 初始化表面积和体积为最小值
sk[i]=sk[i-1]+2*i*i; // 1~i层:侧面积最小值
vk[i]=vk[i-1]+i*i*i; // 1~i层:体积最小值
}
dfs(m,n,n,0,0); //从最下面一层(第m层)开始
if(ans==INF) cout<<0;
else cout<<ans;
return 0;
}
Java代码
import java.util.*;
public class Main {
static final int INF = 0x3f3f3f3f;
static int ans = INF;
static int[] sk;
static int[] vk;
static int n, m;
public static void dfs(int k, int r, int h, int s, int v) {
int MAX_h = h;
if (k == 0) {
if (v == n) ans = Math.min(ans, s);
return;
}
if (v + vk[k - 1] > n) return;
if (2 * (n - v) / r + s >= ans) return;
for (int i = r - 1; i >= k; i--) {
if (k == m) s = i * i;
MAX_h = Math.min(h - 1, (n - vk[k - 1] - v) / i / i);
for (int j = MAX_h; j >= k; j--)
dfs(k - 1, i, j, s + 2 * i * j, v + i * i * j);
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
sk = new int[m + 1];
vk = new int[m + 1];
sk[0] = 0;
vk[0] = 0;
for (int i = 1; i <= m; i++) {
sk[i] = sk[i - 1] + 2 * i * i;
vk[i] = vk[i - 1] + i * i * i;
}
dfs(m, n, n, 0, 0);
if (ans == INF) System.out.println(0);
else System.out.println(ans);
scanner.close();
}
}
Python代码
INF = 0x3f3f3f3f
ans = INF
sk = []
vk = []
def dfs(k, r, h, s, v):
global ans
MAX_h = h
if k == 0:
if v == n: ans = min(ans, s)
return
if v + vk[k - 1] > n: return
if 2 * (n - v) / r + s >= ans: return
for i in range(r - 1, k - 1, -1):
if k == m: s = i * i
MAX_h = min(h - 1, (n - vk[k - 1] - v) // (i * i))
for j in range(MAX_h, k - 1, -1):
dfs(k - 1, i, j, s + 2 * i * j, v + i * i * j)
n = int(input())
m = int(input())
sk = [0] * (m + 1)
vk = [0] * (m + 1)
for i in range(1, m + 1):
sk[i] = sk[i - 1] + 2 * i * i
vk[i] = vk[i - 1] + i * i * i
dfs(m, n, n, 0, 0)
if ans == inf: print(0)
else: print(ans)
2.3 可行性剪枝、记忆化搜索、DFS所有路径:最长距离
链接:最长距离
样例中,移走最下面的1后,最远的距离是左上角和右下角的距离,等于
2
2
+
2
2
=
2.828427
\sqrt{2^2+2^2}=2.828427
22+22=2.828427。
用这道例题讲解如何用DFS搜索所有的路径。
本题的解法是图论的最短路。两个格子之间的最少障碍数量cnt,就是这两个格子之间的最短路径长度。如果这条最短路径的长度满足cnt≤T,那么它是一个符合题意的合法路径,可以计算出这两个格子的欧氏距离。计算出任意两点的欧氏距离,取最大值就是答案。
计算最短路一般用Dijkstra、SPFA这样的高级最短路算法,可用于多达百万个点的图。本题的图很小,也可以用DFS计算最短路,虽然效率低下,但是代码简单。
DFS如何计算起点s和终点t之间的最短路?从s出发,在每一步都向上、下、左、右四个方向继续走,暴力搜索出所有到t的路径,并比较得到其中最短的那条路径长度,就是s、t之间的最短路。
《程序设计竞赛专题挑战教程》,人民邮电出版社,137页,“5.1.3 DFS搜索所有路径”详细说明了如何用DFS搜索从一个起点到一个终点之间的所有路径。
用DFS计算最短路,效率很低下。因为它要搜索所有路径,而路径非常多,其数量是指数级的。即使是很小的图,只有十几个点,几十条边,两个点之间的路径数量也可能多达数千条。本题N和M最大等于30,两点之间的路径数量可能多达百万。即使是这样小的图,计算量也还是太大,需要在DFS中剪枝,把不可能产生答案的路径剪去。
用到两种剪枝:
(1)可行性剪枝。从起点s出发,到一个点t时,如果路径上的障碍数量已经超过T个,后面就不用继续了。
(2)记忆化搜索。从起点s出发到t的路径有很多条,设第一次得到的路径长度为cnt1,第二次得到的路径长度是cnt2,如果cnt1<cnt2,那么保留cnt1就可以了,第二次的路径计算的结果应该丢弃,并不再从这个点继续搜索路径。
C++代码。dfs(x,y,cnt)搜索和计算从起点[i, j]到任意坐标[x, y]的路径长度,把最短路径长度(本题中就是最少障碍数量)记录在dis[x][y]中。第8行是可行性剪枝,第9行是记忆化搜索。
#include <bits/stdc++.h>
using namespace std;
int n,m,t,a[35][35];
int dis[35][35]; //dis[x,y]是起点到[x,y]的最短路(就是最少障碍数)
int vis[35][35]; //vis[x][y]=1: 坐标[x,y]已经走过,不用再走
int dx[4]={-1,1,0,0}, dy[4]={0,0,-1,1};//四个方向
void dfs(int x,int y,int cnt){ //走到坐标[x,y], 已走过的路径长度是cnt(cnt个障碍)
if(cnt>t) return; //可行性剪枝。已经移走了t个障碍,不能再移了
if(cnt>=dis[x][y]) return; //记忆化搜索,前面计算过到[x,y]的最短路
dis[x][y] = cnt;
for(int i=0;i<4;i++) { //向四个方向走一步
int nx=x+dx[i], ny=y+dy[i];
if(nx>n || nx<1 || ny>m || ny<1) continue; //判断越界
if(vis[nx][ny]) continue; //这个点已经走过
vis[nx][ny]=1; //保存现场
dfs(nx, ny, cnt+a[nx][ny]); //继续走一步
vis[nx][ny]=0; //恢复现场
}
}
int main(){
cin>>n>>m>>t;
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++){ //输入网格图,左上角坐标(1,1),右下角坐标(n,m)
char ch; cin>>ch; a[i][j] = ch-'0';
}
int ans=0;
for(int i=1;i<=n;i++) //枚举任意起点[i,j]
for(int j=1;j<=m;j++){
memset(dis,0x3f,sizeof(dis)); //最短路长度的初值是无穷大
memset(vis,0,sizeof(vis));
int cnt = a[i][j]==1?1:0; //以[i,j]为起点
dfs(i,j,cnt); //计算从起点[i,j]到任意一个点的最短路长度(障碍数量)
for(int x=1;x<=n;x++) //计算[i,j]到任意点[x,y]的欧式距离
for(int y=1;y<=m;y++)
if(dis[x][y]<=t)
ans = max(ans,(x-i)*(x-i)+(y-j)*(y-j)); //先不开方,保证精度
}
printf("%.6f",sqrt(ans));
}
Java代码
import java.util.*;
public class Main {
static int n, m, t;
static int[][] a;
static int[][] dis; //dis[x,y]是起点到[x,y]的最短路(就是最少障碍数)
static int[][] vis; //vis[x][y]=1: 坐标[x,y]已经走过,不用再走
static int[] dx = {-1, 1, 0, 0}; //四个方向
static int[] dy = {0, 0, -1, 1};
public static void dfs(int x,int y,int cnt){ //走到[x,y], 已走过的路径长度是cnt(cnt个障碍)
if (cnt > t) return; //可行性剪枝。已经移走了t个障碍,不能再移了
if (cnt >= dis[x][y]) return; //记忆化搜索,前面计算过到[x,y]的最短路
dis[x][y] = cnt;
for (int i = 0; i < 4; i++) { //向四个方向走一步
int nx = x + dx[i];
int ny = y + dy[i];
if (nx > n || nx < 1 || ny > m || ny < 1) continue; //判断越界
if (vis[nx][ny] == 1) continue; //这个点已经走过
vis[nx][ny] = 1; //保存现场
dfs(nx, ny, cnt + a[nx][ny]); //继续走一步
vis[nx][ny] = 0; //恢复现场
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
t = scanner.nextInt();
scanner.nextLine(); //读末尾的回车
a = new int[n + 1][m + 1];
dis = new int[n + 1][m + 1];
vis = new int[n + 1][m + 1];
for (int i = 1; i <= n; i++){ //输入网格图,左上角坐标(1,1),右下角坐标(n,m)
String line = scanner.nextLine();
for (int j = 1; j <= m; j++) {
char ch = line.charAt(j-1);
a[i][j] = ch - '0';
}
}
int ans = 0;
for (int i = 1; i <= n; i++) //枚举任意起点[i,j]
for (int j = 1; j <= m; j++) {
for (int[] row : dis) Arrays.fill(row, Integer.MAX_VALUE); //最短路初值是无穷大
for (int[] row : vis) Arrays.fill(row, 0);
int cnt = a[i][j] == 1 ? 1 : 0; //以[i,j]为起点
dfs(i, j, cnt); //计算从起点[i,j]到任意一个点的最短路长度(障碍数量)
for (int x = 1; x <= n; x++) //计算[i,j]到任意点[x,y]的欧式距离
for (int y = 1; y <= m; y++)
if (dis[x][y] <= t)
ans = Math.max(ans, (x-i)*(x-i)+(y-j)*(y-j)); //先不开方,保证精度
}
System.out.printf("%.6f", Math.sqrt(ans));
}
}
Python代码
n, m, t = map(int, input().split())
a = [[0] * (m+1) for _ in range(n+1)]
for i in range(1,n+1): #输入网格图,左上角坐标(1,1),右下角坐标(n,m)
line = input()
for j in range(1,m+1): a[i][j]=int(line[j-1])
dis = [[float('inf')] * (m+1) for _ in range(n+1)] #dis[x,y]是起点到[x,y]的最短路(最少障碍数)
vis = [[0] * (m+1) for _ in range(n + 1)] #vis[x][y]=1: 坐标[x,y]已经走过,不用再走
dx = [-1, 1, 0, 0] #四个方向
dy = [0, 0, -1, 1]
def dfs(x, y, cnt): #走到坐标[x,y], 已走过的路径长度是cnt(cnt个障碍)
if cnt > t: return #可行性剪枝。已经移走了t个障碍,不能再移了
if cnt >= dis[x][y]: return #记忆化搜索,前面计算过到[x,y]的最短路
dis[x][y] = cnt
for i in range(4): #向四个方向走一步
nx = x + dx[i]
ny = y + dy[i]
if nx>n or nx<1 or ny>m or ny<1: continue #判断越界
if vis[nx][ny] == 1: continue #这个点已经走过
vis[nx][ny] = 1 #保存现场
dfs(nx, ny, cnt + a[nx][ny]) #继续走一步
vis[nx][ny] = 0 #恢复现场
ans = 0
for i in range(1, n+1): #枚举任意起点[i,j]
for j in range(1, m+1):
dis = [[float('inf')] * (m+1) for _ in range(n+1)]
vis = [[0] * (m+1) for _ in range(n+1)]
cnt = 1 if a[i][j] == 1 else 0 #以[i,j]为起点
dfs(i, j, cnt) #计算从起点[i,j]到任意一个点的最短路长度(障碍数量)
for x in range(1, n+ ): #计算[i,j]到任意点[x,y]的欧式距离
for y in range(1, m+1):
if dis[x][y] <= t: ans = max(ans,(x-i)**2 + (y-j)**2) #先不开方,保证精度
print('%.6f'%(ans**0.5))
2.4 搜索顺序剪枝、可行性剪枝、排除等效冗余:小木棍
链接:小木棍
本题是一道“DFS求全排列+剪枝”的经典题。
直接的思路是猜原始木棍的长度是L,然后测试n个小木棍能否拼出k=sum/L根原始木棍,sum是所有小木棍的总长度。可以用二分法猜这个L,L的最小值是最大的ai;L的最大值是65×50。由于L的范围不大,也许不用二分也行。
给定一个长度L,如何判断能不能拼出来?下面模拟拼的过程。
在n个小木棍中选几个,拼第一个L。可以用DFS求全排列的方法选小木棍。有两种可能:
(1)在DFS求排列的过程中,用几根小木棍拼出了一根L。把这几个小木棍置为已用,然后对其他的小木棍继续用DFS开始新一轮的拼一根L。如果一直能拼出L,而且拼出了k=sum/L根,那么L是一个合法的长度。
(2)如果在一次拼L时,能用的小木棍的所有排列,只能拼出一部分L,失败退出,下一次测试L+1。
但是,DFS对n个数求全排列,一共有n!个全排列,本题n≤65,计算量极大,显然会超时。如果坚持使用DFS,必须剪枝。
设计以下剪枝方案。
剪枝1:搜索顺序剪枝。先把小木棍从大到小排序,求全排列时,先选长木棍再选短木棍,因为用长木棍拼比用短木棍拼更快,用的木棍更少,能减少枚举数,这是贪心的思想。排序可以用sort()函数,不过本题的ai值范围很小,可以用桶排,而且本题情况简单,用哈希实现最简单的桶排就行,优点是常数小、操作简便。
剪枝2:可行性剪枝。在做某个排列时,若加入某个小木棍,导致长度大于L,那么这个小木棍不合适。
剪枝3:排除等效冗余。上面优化搜索顺序中,是用贪心的策略进行搜索,为什么可以用贪心?因为不同顺序的拼接是等效的,先拼长的x再拼短的y,和先拼短y再拼长x是一样的。根据这个原理,可以做进一步的剪枝,这是本题最重要的剪枝。下面详细说明。
对排序后的{a1, a2, …, an}做全排列,a1≥a2≥…≥an,根据“DFS与排列”中给出的编码方法,能够按顺序输出全排列。以{3, 2, 1}为例:
第一轮的全排列:a1=3在第一个位置,得到全排列:321、312。
第二轮的全排列:a2=2在第一个位置:231、213。
第三轮的全排列:a3=1在第一个位置:132、123。
回到小木棍这道题:
第一轮,a1位于第一个位置,后面的{a2, …, an}有(n-1)!个排列。如果在这一轮的(n-1)!个排列中,拼不成k个L,那么不用再做第二轮、第三轮…的全排列了,因为第一轮的a1和其他木棍的组合情况在第二轮、第三轮…中也会出现,重复了。请读者自己证明为什么重复。
经过这个剪枝,原来需要对n个数做n!次全排列,现在只需要做(n-1)!次,优化了n倍。
这个剪枝还可以扩展。若某个全排列的前i个拼出了L,而第i-1个到第n个的排列拼不出,那么对这第i-1个到第n个的排列的处理,和前面讨论的一样。
剪枝4:可行性剪枝。所有小木棍的sum应该是原始小木棍长度L的倍数,或者说sum能整除L。
C++代码
#include<bits/stdc++.h>
using namespace std;
const int N = 70 ;
int maxn=0, minn=N, Hash[N]; //Hash[i]:长度为i的小木棍的数量
void dfs(int k, int len, int L, int p ) { //尝试拼出k根长度都为L的小木棍
if(k == 0 ) { cout << L; exit(0); } //已拼出k根L,输出结果,结束程序
if(len == L ) { //拼出了一根长度为L的木棍
dfs(k-1, 0, L, maxn); //继续,用剩下的小木棍拼长L的原始木棍,应该再拼K-1根
return;
}
for(int i=p; i >= minn; i-- ) { //遍历每个小木棍,生成排列。剪枝1
if( Hash[i] && i + len <= L ) { //Hash[i]>0:存在长度i的小木棍;i+len<=L:剪枝2
Hash[i]-- ; //若Hash[i]减到0,表示长度i的小木棍用完了
dfs(k, len+i, L, i); //继续搜下一个小木棍
Hash[i]++; //恢复现场,这根木棍可以再用
if(len == 0) break; //剪枝3,排除等效冗余剪枝
if(len+i == L ) break; //剪枝3的扩展
}
}
return;
}
int main() {
int n; cin >> n;
int sum=0;
while(n--) {
int a; cin >> a;
Hash[a]++; //长度为a的小木棍的数量是Hash[a]
sum += a; //长度之和
maxn = max(maxn,a); //最长小木棍
minn = min(minn,a); //最短小木棍
}
for(int L=maxn ; L<= sum/2 ; L++ ) //拼长度为L的原始木棍。枚举L
if( sum % L == 0 ) //总长度能整除L,说明L是一个可能的长度
dfs(sum/L, 0, L, maxn); //拼长度为L的原始木棍,应该有k=sum/L根
cout << sum; //所有L都拼不出来,说明原始木棍只有一根,长度sum
return 0;
}
第32行从小到大枚举长度L,看能否拼出长度为L的原始木棍。L的最小值是小木棍的最大值maxn,最大值是sum/2,表示拼2个原始木棍。第35行,如果所有的L都不对,那么这些小木棍只能合在一起成为一根木棍,长度就是所有木棍的和sum。
函数dfs(k, len, L, p)拼k根长度为L的原始木棍,如果成功,就输出L,并直接退出程序。参数len是拼一个L的过程中已经拼出的长度,例如L=7,已经使用了长2、3的两根木棍,此时len=5,还有7-5=2没有拼。p是现在可以用的最长小木棍。
(1)用桶排序对ai排序。第27行Hash[a]++,把a存到Hash[a],表示长度为a的小木棍的数量是Hash[a]。若Hash[i]=0,说明不存在长度i的小木棍。由于1≤ai≤50,只需要使用Hash[1]~Hash[50]即可,所以本题用桶排序非常合适。第11行i从大到小遍历Hash[i],就是对长度i从大到小排序。第11行是剪枝1。
(2)剪枝2,可行性剪枝,第12行,如果i + len > L,说明用长度i的小木棍拼,会使得总长超过L,不合适。
(3)剪枝3,排除等效冗余,第16行是剪枝3,第17行是剪枝3的扩展,这里详细解释。11行的for循环是对n个a做全排列,原理见“DFS与排列”的说明。一共做n轮全排列,第1轮把a1放在第一个位置、第2轮把a2放在第一个位置、…。第16行是某一轮全排列结束,如果在这一轮全排列过程中得到了k个L,在6行就会输出L并结束程序。如果程序能执行到第16行,说明这一轮的全排列没有成功,第16行就执行剪枝3并退出,不再做后续轮次的全排列。如果能执行到第17行,表示在某一轮的中间,前面能拼出L,后面拼不出,此时也不再做后续轮次的全排列。
(4)剪枝4,第33行。如果sum不能整除L,表示拼不出长度为L的原始木棍。
Java代码
import java.util.*;
public class Main {
static int N = 70;
static int maxn=0, minn=N;
static int[] Hash = new int[N];
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int sum = 0;
while(n-- > 0) {
int a = sc.nextInt();
Hash[a]++;
sum += a;
maxn = Math.max(maxn, a);
minn = Math.min(minn, a);
}
for(int L = maxn; L <= sum / 2; L++)
if(sum % L == 0) dfs(sum / L, 0, L, maxn);
System.out.println(sum);
sc.close();
}
public static void dfs(int k, int len, int L, int p) {
if(k == 0) { System.out.println(L); System.exit(0); }
if(len == L) {
dfs(k-1, 0, L, maxn);
return;
}
for(int i = p; i >= minn; i--) {
if(Hash[i] > 0 && i + len <= L) {
Hash[i]--;
dfs(k, len + i, L, i);
Hash[i]++;
if(len == 0) break;
if(len + i == L) break;
}
}
return;
}
}
Python代码
N = 70
maxn,minn = 0, N
Hash = [0] * N
def dfs(k, length, L, p):
if k == 0:
print(L)
exit(0)
if length == L:
dfs(k-1, 0, L, maxn)
return
for i in range(p, minn-1, -1):
if Hash[i] > 0 and i + length <= L:
Hash[i] -= 1
dfs(k, length + i, L, i)
Hash[i] += 1
if length == 0: break
if length + i == L: break
n = int(input())
sum = 0
A = list(map(int, input().split()))
for i in range(n):
a = A[i]
Hash[a] += 1
sum += a
maxn = max(maxn, a)
minn = min(minn, a)
for L in range(maxn, sum // 2 + 1):
if sum % L == 0: dfs(sum // L, 0, L, maxn)
print(sum)