一、模型容器——Containers
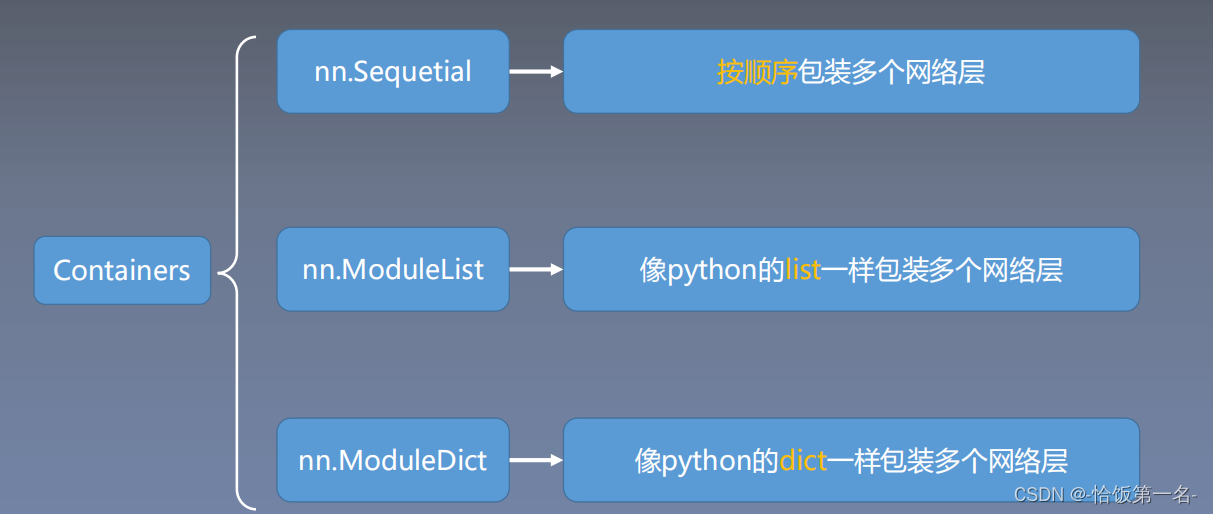
nn.Sequential 是 nn.module的容器,用于按顺序包装一组网络层

Sequential 容器
nn.Sequential 是 nn.module的容器,用于按顺序包装一组网络层
• 顺序性:各网络层之间严格按照顺序构建
• 自带forward():自带的forward里,通过for循环依次执行前向传播运算
Sequential 是 PyTorch 中的一个容器类,用于将多个模块按照顺序组合在一起形成一个模型。Sequential 容器允许我们按照顺序添加不同的层或模块,以构建神经网络模型。
使用 Sequential 容器,可以通过简单的方式定义一个模型,无需手动编写 forward() 函数。只需要按照顺序将模块添加到 Sequential 容器中,输入数据会按照添加的顺序依次经过每个模块进行计算。
下面是使用 Sequential 容器构建一个简单的神经网络模型的示例:
import torch
import torch.nn as nn
# 创建一个Sequential容器,并按顺序添加模块
model = nn.Sequential(
nn.Linear(in_features=100, out_features=64), # 添加一个线性层,输入维度为100,输出维度为64
nn.ReLU(), # 添加ReLU激活函数
nn.Linear(in_features=64, out_features=10), # 添加一个线性层,输入维度为64,输出维度为10
nn.Softmax(dim=1) # 添加Softmax函数,dim=1表示按行计算Softmax
)
在上面的示例中,我们首先创建了一个 Sequential 容器 model,然后按照顺序添加了四个模块:一个线性层、一个ReLU激活函数、另一个线性层和一个Softmax函数。这样就构建了一个简单的神经网络模型。
使用 Sequential 容器可以简化模型的定义和使用,特别适用于简单的线性堆叠结构。但对于一些复杂的网络结构,可能需要使用其他的容器或自定义模型来更灵活地组织模块。
nn.ModuleList
nn.ModuleList 是 nn.Module 的容器,用于包装一组网络层,并以迭代方式调用这些网络层。与 nn.Sequential 不同,nn.ModuleList 可以更灵活地管理和操作网络层。
下面是 nn.ModuleList 的几个主要方法:
append(module):在ModuleList的末尾添加一个网络层。extend(module_list):将另一个ModuleList中的网络层拼接到当前ModuleList的末尾。insert(index, module):在指定的位置index插入一个网络层。remove(module):从ModuleList中移除指定的网络层。pop(index):移除并返回指定位置index的网络层。forward(*inputs):重写nn.Module的forward方法,以便迭代调用ModuleList中的网络层。
下面是一个示例,展示如何使用nn.ModuleList:
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.layers = nn.ModuleList([
nn.Linear(10, 20),
nn.ReLU(),
nn.Linear(20, 30),
nn.ReLU()
])
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
model = MyModule()
input_tensor = torch.randn(32, 10)
output = model(input_tensor)
在上述示例中,我们定义了一个自定义的模型 MyModule,其中使用了 nn.ModuleList 来包装了一组网络层。在 forward 方法中,我们使用迭代方式调用了 ModuleList 中的每个网络层,将输入 x 逐层传递,并最终返回输出结果。
nn.ModuleDict
nn.ModuleDict是nn.Module的容器,用于包装一组网络层,并以索引方式调用网络层。下面是对主要方法的解释:
- clear(): 清空ModuleDict中的所有网络层。
- items(): 返回一个可迭代的键值对(key-value pairs)的视图,可以用于遍历ModuleDict中的所有网络层。
- keys(): 返回一个可迭代的键(key)的视图,可以用于遍历ModuleDict中的所有键。
- values(): 返回一个可迭代的值(value)的视图,可以用于遍历ModuleDict中的所有值。
- pop(key): 返回指定键(key)对应的值(value),并从ModuleDict中删除该键值对。
使用nn.ModuleDict可以方便地管理和调用一组网络层,例如:
import torch
import torch.nn as nn
# 定义自定义模型类 MyModule
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
# 使用 nn.ModuleDict 包装一组网络层
self.layers = nn.ModuleDict({
'linear1': nn.Linear(10, 20), # 第一个线性层,输入维度为10,输出维度为20
'relu1': nn.ReLU(), # ReLU激活函数层
'linear2': nn.Linear(20, 30), # 第二个线性层,输入维度为20,输出维度为30
'relu2': nn.ReLU() # ReLU激活函数层
})
def forward(self, x):
x = self.layers['linear1'](x) # 调用第一个线性层
x = self.layers['relu1'](x) # 调用ReLU激活函数层
x = self.layers['linear2'](x) # 调用第二个线性层
x = self.layers['relu2'](x) # 调用ReLU激活函数层
return x
# 实例化自定义模型
model = MyModule()
# 创建输入张量
input_tensor = torch.randn(32, 10) # 创建一个大小为32x10的随机张量作为输入
# 前向传播
output = model(input_tensor) # 将输入张量传入模型进行前向传播
在上述代码中,我们使用nn.ModuleDict包装了一组网络层,并使用键(key)来索引调用网络层。在模型的forward方法中,我们通过self.layers[key]的方式来调用具体的网络层,实现了前向传播过程。
容器总结
• nn.Sequential:顺序性,各网络层之间严格按顺序执行,常用于block构建
• nn.ModuleList:迭代性,常用于大量重复网构建,通过for循环实现重复构建
• nn.ModuleDict:索引性,常用于可选择的网络层
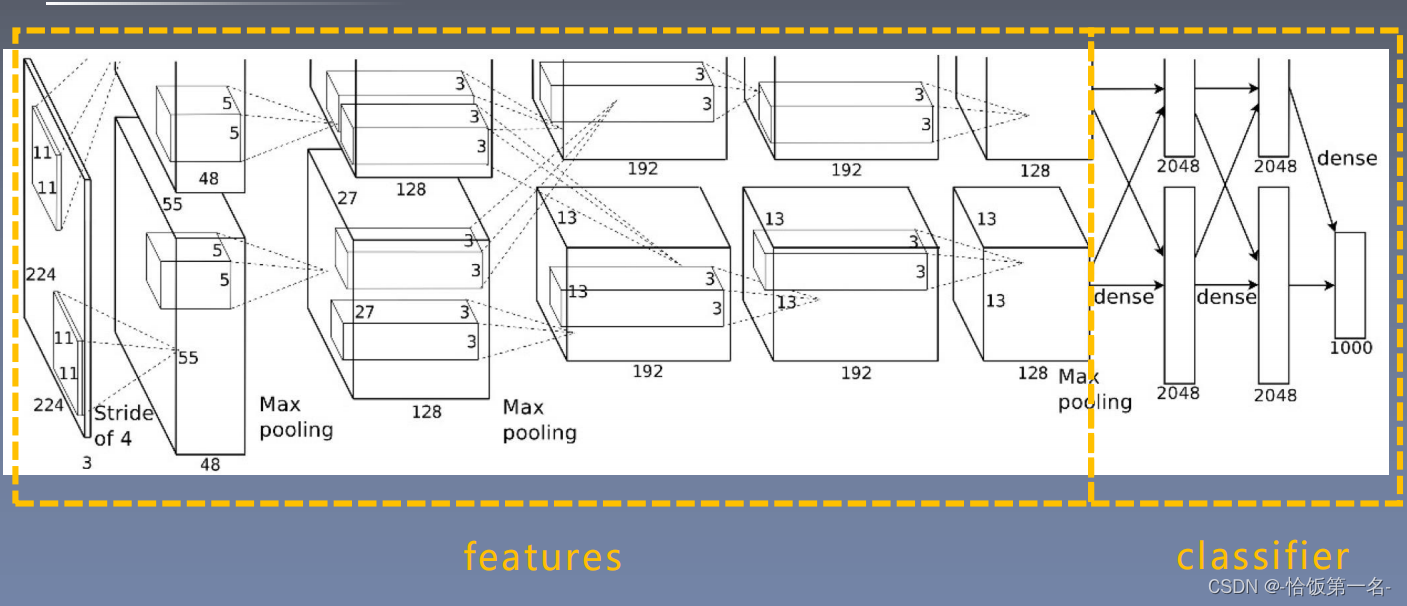
AlexNet构建
AlexNet:2012年以高出第二名10多个百分点的准确率获得ImageNet分类任务冠
军,开创了卷积神经网络的新时代
AlexNet特点如下:
- 采用ReLU:替换饱和激活函数,减轻梯度消失
- 采用LRN(Local Response Normalization):对数据归一化,减轻梯度消失
- Dropout:提高全连接层的鲁棒性,增加网络的泛化能力
- Data Augmentation:TenCrop,色彩修改