本博客主要包含了20240103新出的论文From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations论文解释及项目实现~
论文题目:20240103_From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
论文地址:2401.01885v1.pdf (arxiv.org)
项目地址:facebookresearch/audio2photoreal: Code and dataset for photorealistic Codec Avatars driven from audio (github.com)
1.论文详解
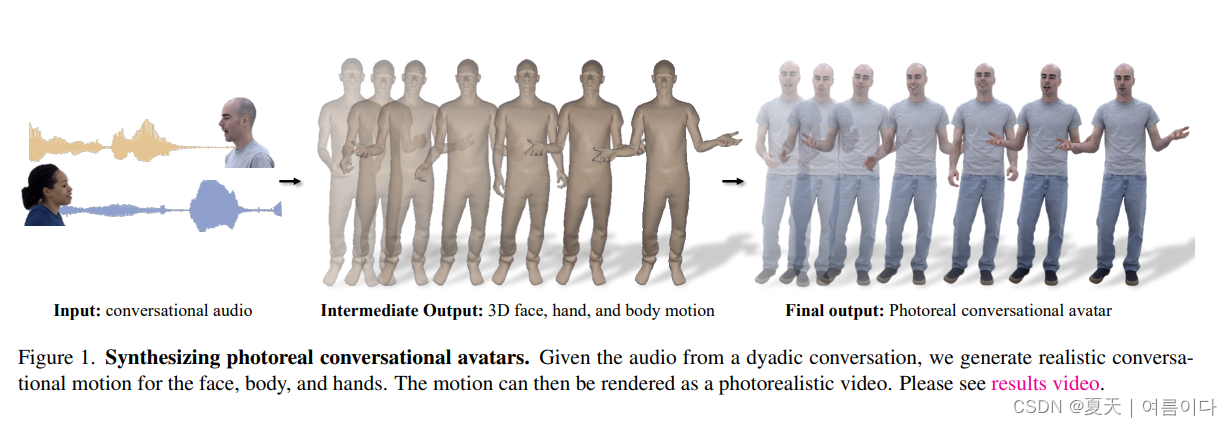
论文提出了一个框架,用于生成逼真的化身,这些化身根据二元交互的对话动态做出手势。给定语音音频,输出个人手势运动的多种可能性,包括面部、身体和手部。方法背后的关键是将矢量量化的样本多样性优势与通过扩散获得的高频细节相结合,以产生更具动态性、表现力的运动。使用高度逼真的头像来可视化生成的动作,这些头像可以表达手势中的关键细微差别(例如冷笑和傻笑)。为了促进这一研究,论文引入了一个首创的多视图对话数据集,可以进行逼真的重建。实验表明,模型可以生成适当且多样化的手势,优于仅扩散和仅VQ的方法。此外,感知评估强调了照片级真实感(相对于网格)在准确评估对话手势中微妙运动细节方面的重要性。提供代码和数据集。
论文框架

动作的生成主要包括了脸部,身体,

1.1.面部动作扩散模型
为了从语音输入中生成面部动作,提出基于语音条件的扩散模型,根据DDPM,正向噪音过程定义为
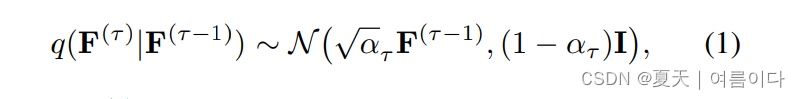
- 表示了在给定前一个时间步的情况下,当前时间步的面部动作服从于一个高斯分布(正态分布)。这个模型可以根据先前的面部动作状态来预测当前的动作状态,这样就能够根据音频输入生成连贯的面部运动序列。
F(0)近似表示清晰(无噪音)的面部表情编码序列F。在这里,τ ∈ [1, . . . , T˙] 表示正向扩散的步骤,而ατ ∈ (0, 1) 则遵循一个单调递减的噪声计划。当τ接近T˙时,采样F(T˙) ∼ N(0, I),即按照正态分布采样得到的清晰的面部动作序列。
接着,为了反向去噪,论文参考了[15, 30]的方法,定义了一个模型来从带有噪声的F(τ)中去除噪音,得到了F(0)的预测值。然后,可以通过将正向过程应用于预测的F(0)来获得反向过程的下一个步骤F(τ−1)。这种方法可以帮助还原面部动作的清晰版本,从而实现从噪声版本到清晰版本的逆向转换。

使用神经网络F来预测F(0)。公式中的F(F(τ); τ, A, L)表明F(0)的近似值,其中A是输入的音频特征,而L = (l1, . . . , lT)是根据[9]的预先训练的音频到唇部回归器的输出,但这里限制在唇部顶点而不是整个面部网格上。研究人员在30小时的内部三维网格数据上对唇部回归器进行了训练。每个lt ∈ Rdl×3表示给定音频A时在帧t上预测的dl个唇部顶点的集合。表2显示,在同时考虑唇部回归器输出和音频时,与仅考虑音频相比,显著提高了唇同步质量。扩散模型则是使用简化的ELBO(Evidence Lower Bound)目标进行训练,
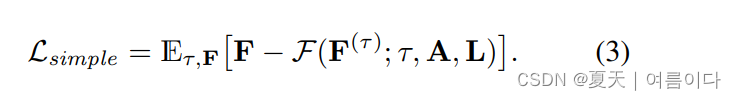
训练过程中采用了一种无分类器指导的模型训练方法。他们通过在训练过程中以低概率随机地替换条件部分(A = ∅ 和 L = ∅)来实现这一点。为了结合音频和唇部顶点信息,他们使用了一个交叉注意力层。同时,时间步信息则通过一个特征逐层线性调制(FiLM)层来整合,具体示意如图4a所示。这种方法允许模型在训练过程中部分时间不使用音频和唇部顶点信息,从而更好地适应不完整的条件输入。
2.项目实现
2.1.环境配置
git clone https://github.com/facebookresearch/audio2photoreal
cd audio2photoreal
pip install -r scripts/requirements.txt
sh demo/install.sh
sh scripts/download_prereq.sh
apt install ffmpeg
# demo
python -m demo.demo
2.2.数据集下载
论文中提出的模型中共包含四个人,PXB184, RLW104, TXB805, 和 GQS883,这里只下载一个
一个人的数据是1.1G.(地址)
# RLW104 数据集人ID
wget https://github.com/facebookresearch/audio2photoreal/releases/download/v1.0/RLW104.zip
unzip RLW104.zip -d dataset/
rm RLW104.zip
包含了语音文件,身体动作numpy文件,人脸numpy文件,
- audio.wav:包含 48kHz 原始音频(两个通道,1600*T 个采样点)的波形文件;通道 0 是与当前人相关的音频,通道 1 是与对话伙伴相关的音频。
- body_pose.npy:运动骨架中关节角度的(T x 104)数组。并非所有关节都用 3DoF 表示。每个 104-d 向量可用于重建全身骨架。
- face_expression.npy:(T x 256)面部编码数组,其中每个 256-d 向量可重建一个面部网格。
- missing_face_frames.npy: 面部代码丢失或损坏的索引列表(t)。
- data_stats.pth:每个人每种模式的均值和 std。
下载动作生成
每个人1.3G (地址)
wget http://audio2photoreal_models.berkeleyvision.org/RLW104_models.tar
tar xvf RLW104_models.tar
rm RLW104_models.tar
要运行实际模型,您需要运行预训练模型并生成关联的结果文件,然后再对其进行可视化。
2.3.预训练模型
我们训练特定于人员的模型,因此每个人都应该有一个关联的目录。例如,对于 ,它们的完整模型应解压缩为以下结构。
每个人有 4 个模型,每个模型都有一个相关的 .args.json
- 输出 256 个基于音频的面部代码的人脸扩散模型
- 一种姿态扩散模型,可输出 104 次关节旋转,以音频和引导姿势为条件
- 以 1 fps 的音频为条件输出 VQ 令牌的引导 VQ 姿势模型
- 一个 VQ 编码器-解码器模型,用于矢量量化连续的 104 维姿态空间。
2.4.运行预训练模型
2.4.1.人脸生成
生成语法
python -m sample.generate
--model_path <path/to/model>
--num_samples <xsamples>
--num_repetitions <xreps>
--timestep_respacing ddim500
--guidance_param 10.0参数说明
- model_path :
- num_samples:要生成的样本数。要对整个数据集进行采样,请使用 56(TXB805 除外,该数据集使用 58)。
- num_repetitions:重复采样次数,即生成的序列总数为(num_samples * num_repetitions)。
- timestep_respacing:扩散步长。格式始终为 ddim<number>。
- guidance_param:条件对结果的影响程度。我通常使用的范围是 2.0-10.0,脸部倾向于更高。
# 实例
python -m sample.generate --model_path RLW104 --num_samples 56 --timestep_respacing ddim500 --guidance_param 10.0使用提供的预训练模型生成人脸
# 可以打开audio2photoreal/checkpoints/diffusion/c2_face查看权重名称
python -m sample.generate --model_path checkpoints/diffusion/c2_face/model000190000.pt --num_samples 10 --num_repetitions 5 --timestep_respacing ddim500 --guidance_param 10.0 
生成一个结果的numpy文件
2.4.2.身体生成
与人脸生成相似,这里输入模型来生成引导姿势。
身体生成语法
python -m sample.generate
--model_path <path/to/model>
--resume_trans <path/to/guide/model>
--num_samples <xsamples>
--num_repetitions <xreps>
--timestep_respacing ddim500
--guidance_param 10.0实例:
#确认路径 audio2photoreal/checkpoints/diffusion/下 和 /checkpoints/guide/c2_pose/checkpoints下参数 名称
python -m sample.generate --model_path checkpoints/diffusion/c2_pose/model000190000.pt --resume_trans checkpoints/guide/c2_pose/checkpoints/iter-0135000.pt --num_samples 10 --num_repetitions 5 --timestep_respacing ddim500 --guidance_param 10.0
同样,输出将保存到
查看结果
# 注意路径
python -m sample.generate --model_path checkpoints/diffusion/c2_pose/model000190000.pt --resume_trans checkpoints/guide/c2_pose/checkpoints/iter-0135000.pt --num_samples 10 --num_repetitions 5 --timestep_respacing ddim500 --guidance_param 10.0 --face_codes checkpoints/diffusion/c2_face/samples_c2_face_000190000_seed10_/results.npy --pose_codes checkpoints/diffusion/c2_pose/samples_c2_pose_000190000_seed10_guide_iter-0135000.pt/results.npy --plot如果出错,参考【PS2】
2.5.可视化
如果环境配置完成,可是实话完整数据集~
python -m visualize.render_anno --save_dir visualize/ --data_root dataset/RLW104 --max_seq_length 6002.6.训练
训练四种可能的模型:
- 1) 面部扩散模型,
- 2) 身体扩散模型
- 3) 身体 vq vae,
- 4) 身体导向变压器。 唯一的依赖关系是
3) 是 4) 所必需的。所有其他模型都可以并行训练。
训练完这 4 个模型后,现在可以按照“运行预训练模型”部分生成样本并可视化结果。
通过传入标志来可视化相应的地面实况序列。--render_gt
PS
【PS1】 AttributeError: module 'cv2.dnn' has no attribute 'DictValue'
查看库pip list 中是否有

因为我的环境是在docker容器内 ,所以要下载opencv-contrib-python,没有的话
# 如果没有就下载 pip install opencv-python-headless
pip install opencv-contrib-python如果有以上库,依旧出现同样错误,那么就是opencv配置库不全
apt-get install build-essential cmake
apt-get install libgtk-3-dev
apt-get install libboost-all-dev
pip install dlib最终解决:是因为版本问题,修改为
pip install opencv-python==4.8.0.74
【PS2】FileNotFoundError: [Errno 2] No such file or directory: 'audio2photoreal/checkpoints/ca_body/data/RLW104/config.yml'
在/audio2photoreal/sample/generate.py文件中170行
指定了配置文件位置,但是文件夹下并没有此文件
下载预训练文件没有下载完全,尝试
sh demo/install.sh
【PS3】ModuleNotFoundError: No module named 'tkinter'
解决:
apt-get install tcl-dev tk-dev python3-tk
【PS4】ing






![[Vulnhub靶机] DriftingBlues: 5](https://img-blog.csdnimg.cn/9f55a5f7fdc14d9fbf46c23376805cd1.png)