文章目录
- 基本概念
- 启用流程
- 基本流程
- HAL层对接
- 数据流
- 计时模型
- 调试
基本概念
AAudio 是 Android 8.0 版本中引入的一种音频 API。
AAudio 提供了一个低延迟数据路径。在 EXCLUSIVE 模式下,使用该功能可将客户端应用代码直接写入与 ALSA 驱动程序共享的内存映射缓冲区。在 SHARED 模式下,MMAP 缓冲区由 AudioServer 中运行的混音器使用。在 EXCLUSIVE 模式下,由于数据会绕过混音器,延迟时间会明显缩短。
在 EXCLUSIVE 模式下,服务可从 HAL 请求 MMAP 缓冲区并管理资源。MMAP 缓冲区将在 NOIRQ 模式下运行,因此没有共享的读/写计数器来管理缓冲区的访问权限。相反,客户端会维护硬件的计时模型,并预测将在何时读取缓冲区。
- 模式
- exclusive: 独立一条通路,不跟其他音频流共享。延时最短的路径。
- shared:多个音频流共享一条路径,在AAudioService 进行混音操作。延时会相对高一点。
启用流程
-
创建AAudioService 服务
服务的实现在framework/av/media/auioserver/main_audioserver.cpp。
/** * Read system property. * @return AAUDIO_UNSPECIFIED, AAUDIO_POLICY_NEVER or AAUDIO_POLICY_AUTO or AAUDIO_POLICY_ALWAYS */ int32_t AAudioProperty_getMMapPolicy(); #define AAUDIO_PROP_MMAP_POLICY "aaudio.mmap_policy" /** * Read system property. * @return AAUDIO_UNSPECIFIED, AAUDIO_POLICY_NEVER or AAUDIO_POLICY_AUTO or AAUDIO_POLICY_ALWAYS */ int32_t AAudioProperty_getMMapExclusivePolicy(); #define AAUDIO_PROP_MMAP_EXCLUSIVE_POLICY "aaudio.mmap_exclusive_policy" // AAudioService should only be used in OC-MR1 and later. // And only enable the AAudioService if the system MMAP policy explicitly allows it. // This prevents a client from misusing AAudioService when it is not supported. aaudio_policy_t mmapPolicy = property_get_int32(AAUDIO_PROP_MMAP_POLICY, AAUDIO_POLICY_NEVER); if (mmapPolicy == AAUDIO_POLICY_AUTO || mmapPolicy == AAUDIO_POLICY_ALWAYS) { AAudioService::instantiate(); }
根据设置的属性来instantiate AAudioService,需要设置如下属性
#define AAUDIO_PROP_MMAP_POLICY "aaudio.mmap_policy"
setprop aaudio.mmap_policy 2或3(为auto或者always, 一般为2)
这一步的目的是启动AAudioService服务并会首先尝试MMap模式,失败的话重新走legacy 通过AudioTrack来写数据到audioFlinger中,可通过这个服务和hal层进行交互。
- 配置文件修改
添加mmap_no_irq_out的mixport,并将这个流的端点路由到speaker的device。这一步会在device中打开一个mmap_no_irp的流端口,数据写入到这个流端口 会写入hal中申请的mmapbuffer中。
<mixPort name="mmap_no_irq_out" role="source" flags="AUDIO_OUTPUT_FLAG_DIRECT AUDIO_OUTPUT_FLAG_MMAP_NOIRQ">
<profile name="" format="AUDIO_FORMAT_PCM_16_BIT"
samplingRates="44100 48000" channelMasks="AUDIO_CHANNEL_OUT_STEREO"/>
</mixPort>
<mixPort name="mmap_no_irq_in" role="sink" flags="AUDIO_INPUT_FLAG_MMAP_NOIRQ">
<profile name="" format="AUDIO_FORMAT_PCM_16_BIT"
samplingRates="8000 11025 12000 16000 22050 24000 32000 44100 48000"
channelMasks="AUDIO_CHANNEL_IN_MONO AUDIO_CHANNEL_IN_STEREO"/>
</mixPort>
<route type="mix" sink="Speaker"
sources="primary output,mmap_no_irq_out"/>
<route type="mix" sink="Wired Headset"
sources="primary output,mmap_no_irq_out"/>
<route type="mix" sink="Wired Headphones"
sources="primary output,mmap_no_irq_out"/>
- hal添加支持
需要实现以下的接口
start() generates (Result retval);
stop() generates (Result retval) ;
createMmapBuffer(int32_t minSizeFrames) generates (Result retval, MmapBufferInfo info);
getMmapPosition() generates (Result retval, MmapPosition position);
基本流程

-
应用端调用的流程
以原生的write_sine为例,会生成sine的波形数据并通过AAudio写入到声卡。frameworks\av\media\libaaudio\examples\write_sine\src\write_sine.cpp
- AAudio_createStreamBuilder创建stream的builder
- AAudioStreamBuilder_setBufferCapacityInFrames等等配置格式 采样率等等参数
- AAudioStreamBuilder_openStream open 获取流stream
- AAudioStream_requestStart 启动stream
- AAudioStream_write向之前打开的流中写数据
- AAudioStream_requestStop写完成关闭
AAudioStreamBuilder *builder = nullptr;
result = AAudio_createStreamBuilder(&builder);
AAudioStreamBuilder_setChannelCount(builder, mChannelCount);
if (dataCallback != nullptr) {
AAudioStreamBuilder_setDataCallback(builder, dataCallback, userContext);
}
// Open an AAudioStream using the Builder.
result = AAudioStreamBuilder_openStream(builder, &mStream);
aaudio_result_t result = AAudioStream_requestStart(mStream);
myData.sampleRate = actualSampleRate;
myData.setupSineSweeps();
myData.sineOscillators[i].render(&floatData[i], actualChannelCount,
framesPerWrite);
actual = AAudioStream_write(aaudioStream, floatData, minFrames, timeoutNanos);
aaudio_result_t result = AAudioStream_requestStop(mStream)
-
内部流程
-
服务端通过hal创建共享内存
AAudioBinderClient通过service open, open后获取stream、 open调用到audioFlinger的openStream。
audioflinger中根据配置的信息 获取open的handle,然后使用返回的流调用createMmapBuffer。
这个buffer 是调用到hal层 通过alsa或者tinyalsa 来创建buffer。buffer创建成功后返回给AAudio。
std::shared_ptr<AAudioServiceInterface> service = getAAudioService(); if (service.get() == nullptr) return AAUDIO_ERROR_NO_SERVICE; stream = service->openStream(request, configuration); status = mMmapStream->createMmapBuffer(minSizeFrames, &mMmapBufferinfo);-
共享内存传递到客户端
这块由hal创建的buffer 通过shared_memory_fd封装在mAudioDataFileDescriptor里面
这个fd如何传递到客户端,通过封装在AudioEndpointParcelable进行传递。 -
客户端获取共享内存
service的getStreamDescription接口 来获取共享内存的fd。 这个流程也是在open之后就立马进行的,clinet取到这个parcelable信息后,重新读出来并初始化在FifoBufferIndirect中。open流程总结: mmap模式 clinet会通过AAudioService申请内存,AAudioService 调用到hal,由hal创建一块共享的内存 并将fd返回给client, clinet端使用系统调用mmap从fd中map出一段内存进行数据的读写等操作。
aaudio_result_t SharedMemoryParcelable::resolveSharedMemory(const unique_fd& fd) { mResolvedAddress = (uint8_t *) mmap(0, mSizeInBytes, PROT_READ | PROT_WRITE, MAP_SHARED, fd.get(), 0); ALOGE("mmap() for fd = %d, address:%p, nBytes = %" PRId64 ", errno = %s", fd.get(), mResolvedAddress, mSizeInBytes, strerror(errno)); if (mResolvedAddress == MMAP_UNRESOLVED_ADDRESS) { ALOGE("mmap() failed for fd = %d, nBytes = %" PRId64 ", errno = %s", fd.get(), mSizeInBytes, strerror(errno)); return AAUDIO_ERROR_INTERNAL; } return AAUDIO_OK; } -
start流程
会通过aaudioService 一路调用到hal 的start -
write流程
write会调用到AudioStreamInternalPlay::write 其中buffer 外部要写入进行播放的数据。
也就是从之前FifoBufferIndirect中获取一块内存设置为AAduioFlowGraph的输出,要写入的数据设置为
AAduioFlowGraph的输入, 通过AAduioFlowGraph的process,输入数据可能有格式转换等等的操作。然后写入到hal的内存中。如何是exclusive的模式,应用端的数据直接写到hal申请的内存中。hal在送入硬件进行播放。
-
HAL层对接
-
基础知识
-
buffer size period size概念的理解
const struct pcm_config config = { .channels = 2, .rate = 48000, .format = PCM_FORMAT_S32_LE, .period_size = 1024, .period_count = 2, .start_threshold = 1024, .silence_threshold = 1024 * 2, .stop_threshold = 1024 * 2pcm_config中的内容,包括声道数、采样数、数据格式等内容。
period_size表示的内核中DMA块的大小。
period_count表示这样的块有几个。period_count的大小应该大于2,这样才能保证音频播放过程中无卡顿。
start_threshold用来表示有多少帧数据的时候,才开始播放声音。
silence_threshold和stop_threshold表示静音和停止播放时候需要的帧数,帧数太少的时候进行操作,可能导致破音的产生。
buffer size 为period_count * period_count, 表示硬件中的缓存的buffer 的大小。
buffer size/sample rate: 硬件缓冲全部播放完成需要的时间,也是hal写完数据后,等硬件播放完成需要的理论时间。
-
alsa驱动中的ringbuffer的管理
驱动ringbuffer 中 硬件读的位置, 间隔的是可写的空间, 然后是应用写buffer的位置。
一个往驱动ringbuffer 写数据的流程:

首先上面设置了buffer size。 为period size * period count。 底下的ringbuffer是由很多个
buffer size大小的HW buffer 组成的。avail的size 是hw_prt + buffer size - appl_ptr,理解为起始地址为硬件读取的指针的在一个buffer size的空间内减去当前应用已经写的数据。
-
-
hal层封装内存的数据结构(基于tinyalsa)
struct audio_mmap_buffer_info { void* shared_memory_address; /**< base address of mmap memory buffer. For use by local process only */ int32_t shared_memory_fd; /**< FD for mmap memory buffer */ int32_t buffer_size_frames; /**< total buffer size in frames */ int32_t burst_size_frames; /**< transfer size granularity in frames */ audio_mmap_buffer_flag flags; /**< Attributes describing the buffer. */ }; status = mMmapStream->createMmapBuffer(minSizeFrames, &mMmapBufferinfo);-
通过hal层的createMmapBuffer获取到的结构体
-
shared_memory_fd:打开声卡, 获取操作的指针,打开的时候需要设置low_latency的config。打开之后通过pcm_get_poll_fd获取fd。
-
shared_memory_address:通过pcm_mmap_begin 获取虚拟地址
-
bufffer_size_frames:是alsa中buffer的帧数,一般配置为period_count* period size。alsa buffer中能够存储几个中断周期内处理完成的帧数。 也是以帧为单位的。
-
burst_size_frames: 每次传输的帧数。一般配置为period size 为一个中断周期内处理的帧数大小 是以frame 为单位的。
-
-
hal获取硬件的更新位置和时间戳
/** * Mmap buffer read/write position returned by audio_stream->get_mmap_position(). * note\ Used by streams opened in mmap mode. */ struct audio_mmap_position { int64_t time_nanoseconds; /**< timestamp in ns, CLOCK_MONOTONIC */ int32_t position_frames; /**< increasing 32 bit frame count reset when stream->stop() is called */ };通过pcm_mmap_get_hw_ptr的函数获取当前 alsa的hw_ptr值也就是上面结构体中的position_frames,以及相对时间(以1970年为基准的时间戳对应time_nanoseconds)。
这些时间和ptr位置的信息返回给AAudio 更新计时模型。 -
hal层流程的控制start、stop
-
out_start
调用pcm_start将pcm进行start。如果没有start就调用pcm_mmap_get_hw_ptr
EBADFD: 未start会出现 fd in bad status的错误。
EPIPE( Broken pipe): 而fd被关闭的会出现bad FIFO的错误。 -
out_stop
stop 并close 掉pcm的fd。
-
数据流
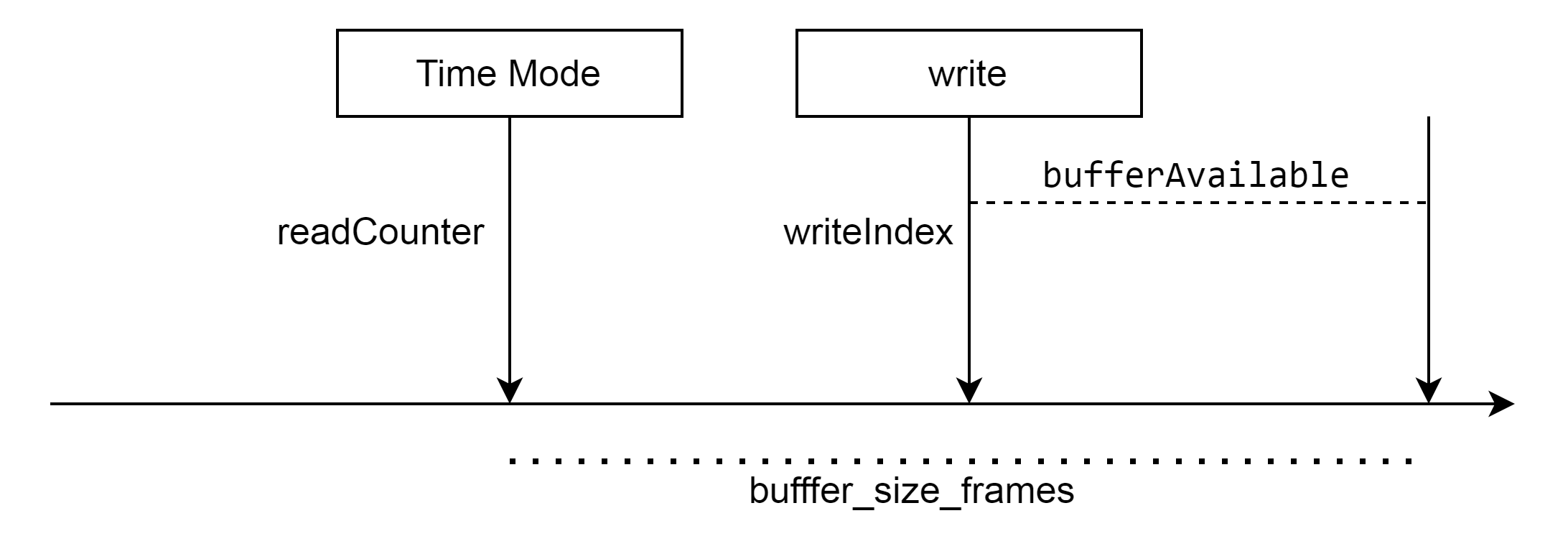
- 首先从声卡mmap出来的这一段内存,对于播放,上层维护着一个writeIndex, 这个index 不受任何其他的影响。只要数据往buffer里面写了多少,那么这个index就会往前移动多少。
- 而从hal层 get_mmap_position返回的时间 和 position。其中时间表示从1970为基准,播放了多少的时间,以及当前硬件从mmap buffer读取的指针的位置hw_ptr。上层依靠这个来更新硬件读的位置, 这个影响到 上层判断一次可以写入多少的数据。 但不会影响连续的往硬件buffer 上面写数据。
- 在写的时候 需要获取一下当前的时间, 将当前时间减掉上一次get_mmap_position获取到的时间,转换为postion(实际就是距离上一次更新 硬件又已经播放了多少帧)将这个readCounter 更新到新的位置。
然后根据这个新的位置和 已经写的位置 以及hw_buffer 来判断有多少空间可以写。如果这个position错的话, 偏大 可写的数据空间更多,变小可写数据空间少。
计时模型
-
所谓的计时模型就是播放时间和位置一个转换关系。 根据hal层上报的播放时间 和 播放位置 会更新两者之间的对应关系。目的是为了 比较精确 合理的获取硬件读取的位置。 当要把数据写入到mmap
的buffer 前 ,确认当前硬件读的位置并更新,然后根据读位置和写位置 获取可以写的buffer的大小。
根据这个大小写入这么多的数据。 -
mmap 模式的时候。内核并不知道用户空间何时完成写入了, 因此用户空间完成写入时需要通过某种方式告知内核. alsa提供了ioctl SNDRV_PCM_IOCTL_SYNC_PTR, 供用户空间通知内核更新appl_ptr, 例如tinyalsa中的pcm_sync_ptr采用的就是这种方式对应的接口是pcm_mmap_get_hw_ptr. 在内核层, snd_pcm_common_ioctl1 -> snd_pcm_sync_ptr 会最终更新该参数。这个调用是在get_out_position的时候同步完成的。
-
下面的函数会将上面获取mmap的postion mmap的position 更新到
mFramesTransferred中。最后的累加值会返回出去到positionFrames 和 timeNanos 中。
// Get free-running DSP or DMA hardware position from the HAL.
aaudio_result_t AAudioServiceEndpointMMAP::getFreeRunningPosition(int64_t *positionFrames,
int64_t *timeNanos) {
struct audio_mmap_position position;
if (mMmapStream == nullptr) {
return AAUDIO_ERROR_NULL;
}
status_t status = mMmapStream->getMmapPosition(&position);
ALOGE("%s() status= %d, pos = %d, nanos = %lld\n",
__func__, status, position.position_frames, (long long) position.time_nanoseconds);
aaudio_result_t result = AAudioConvert_androidToAAudioResult(status);
if (result == AAUDIO_ERROR_UNAVAILABLE) {
ALOGW("%s(): getMmapPosition() has no position data available", __func__);
} else if (result != AAUDIO_OK) {
ALOGE("%s(): getMmapPosition() returned status %d", __func__, status);
} else {
// Convert 32-bit position to 64-bit position.
mFramesTransferred.update32(position.position_frames);
*positionFrames = mFramesTransferred.get();
*timeNanos = position.time_nanoseconds;
}
return result;
}
在service 有一个线程是专门发送timestamp给client端
获取timestamp调度的周期开始的时候 是1ms。 而后是3ms, 10ms最后是50ms。同时也会加上一个0-1ms之间的随机数
void AAudioServiceStreamBase::run() {
aaudio_result_t result = AAUDIO_OK;
while(mThreadEnabled.load()) {
loopCount++;
if (AudioClock::getNanoseconds() >= nextTime) {
result = sendCurrentTimestamp();
if (result != AAUDIO_OK) {
ALOGE("%s() timestamp thread got result = %d", __func__, result);
break;
}
nextTime = timestampScheduler.nextAbsoluteTime();
} else {
// Sleep until it is time to send the next timestamp.
// TODO Wait for a signal with a timeout so that we can stop more quickly.
AudioClock::sleepUntilNanoTime(nextTime);
}
}
// This was moved from the calls in stop_l() and pause_l(), which could cause a deadlock
// if it resulted in a call to disconnect.
if (result == AAUDIO_OK) {
(void) sendCurrentTimestamp();
}
ALOGD("%s() %s exiting after %d loops <<<<<<<<<<<<<< TIMESTAMPS",
__func__, getTypeText(), loopCount);
}
发送消息到client端, 在外部write的时候 会先处理service端发送的消息。调用processTimestamp进行处理。
// Write the data, block if needed and timeoutMillis > 0
aaudio_result_t AudioStreamInternalPlay::write(const void *buffer, int32_t numFrames,
int64_t timeoutNanoseconds) {
return processData((void *)buffer, numFrames, timeoutNanoseconds);
}
aaudio_result_t result = processCommands();
aaudio_result_t AudioStreamInternal::onTimestampService(AAudioServiceMessage *message) {
#if LOG_TIMESTAMPS
logTimestamp(*message);
#endif
processTimestamp(message->timestamp.position,
message->timestamp.timestamp + mTimeOffsetNanos);
return AAUDIO_OK;
}
调试
tinyalsa 上面流程跑通, 但是没有声音。 查看声卡的状态是XRUN。但是有往mmap出来的地址上面写数据。怎么调试这个问题?
-
确认fd是不是正确
可以通过正常播放的时候, 打印一下这个fd的路径看看是不是对的。
-
确认mmap是不是成功
AAudio mmap的时候 是成功的, 如果失败上面会报错。
-
数据是不是真正的写入
通过查看声卡的状态和信息来确认
cat /proc/asound/card2/pcm0p/sub0/status
state: RUNNING
owner_pid : 30897
trigger_time: 152475.615823722
tstamp : 152487.360496736
delay : 1696
avail : 224
avail_max : 480
hw_ptr : 563760
appl_ptr : 565680
运行的时候 hw_ptr 和 appl_ptr 是变化的
state: 当前输出运行状态
owner_pid:调用者的线程号
delay: 当前buffer中可用数据大小(单位为:帧)
avail:当前buffer中空闲空间大小(单位为:帧)[为pcmc录音时,该值为可用数据大小]
hw_ptr: alsa驱动读取指针位置 [为pcmc录音时,该值为 alsa驱动写入指针位置]
appl_ptr:alsa写入数据者的指针位置 [为pcmc录音时,该值为alsa读取数据者的指针位置]。