取自github开源项目:numpy100题
文章目录
- 1. 导入numpy库并简写为 np (★☆☆)
- 2. 打印numpy的版本和配置说明 (★☆☆)
- 3. 创建一个长度为10的空向量 (★☆☆)
- 4. 如何找到任何一个数组的内存大小? (★☆☆)
- 5. 如何从命令行得到numpy中add函数的说明文档? (★☆☆)
- 6. 创建一个长度为10并且除了第五个值为1的空向量 (★☆☆)
- 7. 创建一个值域范围从10到49的向量(★☆☆)
- 8. 反转一个向量(第一个元素变为最后一个) (★☆☆)¶
- 9. 创建一个 3x3 并且值从0到8的矩阵(★☆☆)
- 10. 找到数组[1,2,0,0,4,0]中非0元素的位置索引 (★☆☆)
- 11. 创建一个 3x3 的单位矩阵 (★☆☆)
- 12. 创建一个 3x3x3的随机数组 (★☆☆)
- 13. 创建一个 10x10 的随机数组并找到它的最大值和最小值 (★☆☆)
- 14. 创建一个长度为30的随机向量并找到它的平均值 (★☆☆)
- 15. 创建一个二维数组,其中边界值为1,其余值为0 (★☆☆)
- 16. 对于一个存在在数组,如何添加一个用0填充的边界? (★☆☆)
- 17. 以下表达式运行的结果分别是什么? (★☆☆)
- 18. 创建一个 5x5的矩阵,并设置值1,2,3,4落在其对角线下方位置 (★☆☆)
- 19. 创建一个8x8 的矩阵,并且设置成棋盘样式 (★☆☆)
- 20. 考虑一个 (6,7,8) 形状的数组,其第100个元素的索引(x,y,z)是什么?
- 21. 用tile函数去创建一个 8x8的棋盘样式矩阵(★☆☆)
- 22. 对一个5x5的随机矩阵做归一化(★☆☆)
- 23. 创建一个将颜色描述为(RGBA)四个无符号字节的自定义dtype?(★☆☆)
- 24. 一个5x3的矩阵与一个3x2的矩阵相乘,实矩阵乘积是什么? (★☆☆)
- 25. 给定一个一维数组,对其在3到8之间的所有元素取反 (★☆☆)
- 26. 下面脚本运行后的结果是什么? (★☆☆)
- 27. 考虑一个整数向量Z,下列表达合法的是哪个? (★☆☆)
- 28. 下列表达式的结果分别是什么?(★☆☆)
- 29. 如何从零位对浮点数组做舍入 ? (★☆☆)
- 30. 如何找到两个数组中的共同元素? (★☆☆)
- 31. 如何忽略所有的 numpy 警告(尽管不建议这么做)? (★☆☆)
- 32. 下面的表达式是正确的吗? (★☆☆)
- 33. 如何得到昨天,今天,明天的日期? (★☆☆)
- 34. 如何得到所有与2016年7月对应的日期? (★★☆)
- 35. 如何直接在位计算(A+B)\*(-A/2)(不建立副本)? (★★☆)
- 36. 用五种不同的方法去提取一个随机数组的整数部分(★★☆)
- 37. 创建一个5x5的矩阵,其中每行的数值范围从0到4 (★★☆)
- 38. 通过考虑一个可生成10个整数的函数,来构建一个数组(★☆☆)
- 39. 创建一个长度为10的随机向量,其值域范围从0到1,但是不包括0和1 (★★☆)
- 40. 创建一个长度为10的随机向量,并将其排序 (★★☆)
- 41.对于一个小数组,如何用比 np.sum更快的方式对其求和?(★★☆)
- 42. 对于两个随机数组A和B,检查它们是否相等(★★☆)
- 43. 创建一个只读数组(read-only) (★★☆)
- 44. 将笛卡尔坐标下的一个10x2的矩阵转换为极坐标形式(★★☆)
- 45. 创建一个长度为10的向量,并将向量中最大值替换为1 (★★☆)
- 46. 创建一个结构化数组,并实现 x 和 y 坐标覆盖 [0,1]x[0,1] 区域 (★★☆)
- 47. 给定两个数组X和Y,构造Cauchy矩阵C (Cij =1/(xi - yj))
- 48. 打印每个numpy标量类型的最小值和最大值? (★★☆)
- 49. 如何打印一个数组中的所有数值? (★★☆)
- 50. 给定标量时,如何找到数组中最接近标量的值?(★★☆)
- 51. 创建一个表示位置(x,y)和颜色(r,g,b)的结构化数组(★★☆)
- 52. 对一个表示坐标形状为(100,2)的随机向量,找到点与点的距离(★★☆)
- 53. 如何将32位的浮点数(float)转换为对应的整数(integer)?
- 54. 如何读取以下文件? (★★☆)
- 55. 对于numpy数组,enumerate的等价操作是什么?(★★☆)
- 56. 生成一个通用的二维Gaussian-like数组 (★★☆)
- 57. 对一个二维数组,如何在其内部随机放置p个元素? (★★☆)
- 58. 减去一个矩阵中的每一行的平均值 (★★☆)
- 59. 如何通过第n列对一个数组进行排序? (★★☆)
- 60. 如何检查一个二维数组是否有空列?(★★☆)
- 61. 从数组中的给定值中找出最近的值 (★★☆)
- 62. 如何用迭代器(iterator)计算两个分别具有形状(1,3)和(3,1)的数组? (★★☆)
- 63. 创建一个具有name属性的数组类(★★☆)
- 64. 考虑一个给定的向量,如何对由第二个向量索引的每个元素加1(小心重复的索引)? (★★★)
- 65. 根据索引列表(I),如何将向量(X)的元素累加到数组(F)? (★★★)
- 66. 考虑一个(dtype=ubyte) 的 (w,h,3)图像,计算其唯一颜色的数量(★★★)
- 67. 考虑一个四维数组,如何一次性计算出最后两个轴(axis)的和? (★★★)
- 68. 考虑一个一维向量D,如何使用相同大小的向量S来计算D子集的均值?(★★★)
- 69. 如何获得点积 dot prodcut的对角线? (★★★)
- 70. 考虑一个向量[1,2,3,4,5],如何建立一个新的向量,在这个新向量中每个值之间有3个连续的零?(★★★)
- 71. 考虑一个维度(5,5,3)的数组,如何将其与一个(5,5)的数组相乘?(★★★)
- 72.如何对一个数组中任意两行做交换? (★★★)
- 73. 考虑一个可以描述10个三角形的triplets,找到可以分割全部三角形的line segment
- 74.给定一个二进制的数组C,如何产生一个数组A满足np.bincount(A)==C(★★★)
- 75. 如何通过滑动窗口计算一个数组的平均数? (★★★)
- 76.考虑一维数组Z,构建一个二维数组,其第一行为(Z[0],Z[1],Z[2]),随后的每一行偏移1(最后一行应为(Z[-3],Z[-2],Z[-1])76. 76.考虑一维数组Z,构建一个二维数组,其第一行为(Z[0],Z[1],Z[2]),随后的每一行偏移1(最后一行应为(Z[-3],Z[-2],Z[-1])
- 77. 如何对布尔值取反,或者原位(in-place)改变浮点数的符号(sign)?(★★★)
- 78. 考虑两组点集P0和P1去描述一组线(二维)和一个点p,如何计算点p到每一条线 i (P0[i],P1[i])的距离?(★★★)
- 79.考虑两组点集P0和P1去描述一组线(二维)和一组点集P,如何计算每一个点 j(P[j]) 到每一条线 i (P0[i],P1[i])的距离?(★★★)
- 80.考虑一个任意数组,编写一个函数,提取具有固定形状并以给定元素为中心的子部分(必要时使用填充值填充)(★★★)
- 81. 考虑一个数组Z = [1,2,3,4,5,6,7,8,9,10,11,12,13,14],如何生成一个数组R = [[1,2,3,4], [2,3,4,5], [3,4,5,6], ...,[11,12,13,14]]? (★★★)
- 82. 计算一个矩阵的秩(★★★)
- 83. 如何找到一个数组中出现频率最高的值?
- 84. 从一个10x10的矩阵中提取出连续的3x3区块(★★★)
- 85. 创建一个满足 Z[i,j] == Z[j,i]的子类 (★★★)
- 86. 考虑p个 nxn 矩阵和一组形状为(n,1)的向量,如何直接计算p个矩阵的乘积(n,1)?(★★★)
- 87. 对于一个16x16的数组,如何得到一个区域(block-sum)的和(区域大小为4x4)? (★★★)
- 88. 如何利用numpy数组实现Game of Life? (★★★)
- 89. 如何找到一个数组的第n个最大值? (★★★)
- 90. 给定任意个数向量,创建笛卡尔积(每一个元素的每一种组合)(★★★)
- 91. 如何从一个正常数组创建记录数组(record array)? (★★★)
- 92. 考虑一个大向量Z, 用三种不同的方法计算它的立方(★★★)
- 93. 考虑两个形状分别为(8,3) 和(2,2)的数组A和B. 如何在数组A中找到满足包含B中元素的行?(不考虑B中每行元素顺序)? (★★★)
- 94. 考虑一个10x3的矩阵,分解出有不全相同值的行 (如 [2,2,3]) (★★★)
- 95. 将一个整数向量转换为matrix binary的表现形式 (★★★)
- 96. 给定一个二维数组,如何提取出唯一的(unique)行?(★★★)
- 97. 考虑两个向量A和B,写出用einsum等式对应的inner, outer, sum, mul函数(★★★)
- 98. 考虑一个由两个向量描述的路径(X,Y),如何用等距样例(equidistant samples)对其进行采样(sample)? (★★★)
- 99.给定整数n和2D阵列X,从X中选择可被解释为从具有n次的多项式分布中提取的行,即,仅包含整数且总和为n的行。
- 100. 对于一个一维数组X,计算它boostrapped之后的95%置信区间的平均值。
1. 导入numpy库并简写为 np (★☆☆)
import numpy as np
2. 打印numpy的版本和配置说明 (★☆☆)
print(np.__version__)
np.show_config()
1.21.5
blas_mkl_info:
NOT AVAILABLE
blis_info:
NOT AVAILABLE
openblas_info:
libraries = ['openblas', 'openblas']
library_dirs = ['/Users/gcc/opt/anaconda3/lib']
language = c
define_macros = [('HAVE_CBLAS', None)]
blas_opt_info:
libraries = ['openblas', 'openblas']
library_dirs = ['/Users/gcc/opt/anaconda3/lib']
language = c
define_macros = [('HAVE_CBLAS', None)]
lapack_mkl_info:
NOT AVAILABLE
openblas_lapack_info:
libraries = ['openblas', 'openblas']
library_dirs = ['/Users/gcc/opt/anaconda3/lib']
language = c
define_macros = [('HAVE_CBLAS', None)]
lapack_opt_info:
libraries = ['openblas', 'openblas']
library_dirs = ['/Users/gcc/opt/anaconda3/lib']
language = c
define_macros = [('HAVE_CBLAS', None)]
Supported SIMD extensions in this NumPy install:
baseline = NEON,NEON_FP16,NEON_VFPV4,ASIMD
found = ASIMDHP
not found = ASIMDDP
3. 创建一个长度为10的空向量 (★☆☆)
a=np.zeros(10)
a
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
4. 如何找到任何一个数组的内存大小? (★☆☆)
a=np.arange(10,dtype=np.int64).reshape(2,5)
print(a)
print('内存大小为%d bytes' %(a.size*a.itemsize))
[[0 1 2 3 4]
[5 6 7 8 9]]
内存大小为80 bytes
5. 如何从命令行得到numpy中add函数的说明文档? (★☆☆)
np.info(np.add)
add(x1, x2, /, out=None, *, where=True, casting='same_kind', order='K', dtype=None, subok=True[, signature, extobj])
Add arguments element-wise.
Parameters
----------
x1, x2 : array_like
The arrays to be added.
If ``x1.shape != x2.shape``, they must be broadcastable to a common
shape (which becomes the shape of the output).
out : ndarray, None, or tuple of ndarray and None, optional
A location into which the result is stored. If provided, it must have
a shape that the inputs broadcast to. If not provided or None,
a freshly-allocated array is returned. A tuple (possible only as a
keyword argument) must have length equal to the number of outputs.
where : array_like, optional
This condition is broadcast over the input. At locations where the
condition is True, the `out` array will be set to the ufunc result.
Elsewhere, the `out` array will retain its original value.
Note that if an uninitialized `out` array is created via the default
``out=None``, locations within it where the condition is False will
remain uninitialized.
**kwargs
For other keyword-only arguments, see the
:ref:`ufunc docs <ufuncs.kwargs>`.
Returns
-------
add : ndarray or scalar
The sum of `x1` and `x2`, element-wise.
This is a scalar if both `x1` and `x2` are scalars.
Notes
-----
Equivalent to `x1` + `x2` in terms of array broadcasting.
Examples
--------
>>> np.add(1.0, 4.0)
5.0
>>> x1 = np.arange(9.0).reshape((3, 3))
>>> x2 = np.arange(3.0)
>>> np.add(x1, x2)
array([[ 0., 2., 4.],
[ 3., 5., 7.],
[ 6., 8., 10.]])
The ``+`` operator can be used as a shorthand for ``np.add`` on ndarrays.
>>> x1 = np.arange(9.0).reshape((3, 3))
>>> x2 = np.arange(3.0)
>>> x1 + x2
array([[ 0., 2., 4.],
[ 3., 5., 7.],
[ 6., 8., 10.]])
6. 创建一个长度为10并且除了第五个值为1的空向量 (★☆☆)
a=np.zeros(10)
a[4]=1
a
array([0., 0., 0., 0., 1., 0., 0., 0., 0., 0.])
7. 创建一个值域范围从10到49的向量(★☆☆)
a=np.arange(10,50)
a
array([10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43,
44, 45, 46, 47, 48, 49])
8. 反转一个向量(第一个元素变为最后一个) (★☆☆)¶
a=np.arange(10)
a=a[::-1]
a
array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
9. 创建一个 3x3 并且值从0到8的矩阵(★☆☆)
a=np.arange(9).reshape(3,3)
a
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
10. 找到数组[1,2,0,0,4,0]中非0元素的位置索引 (★☆☆)
- numpy.nonzero 函数用于返回数组中非零元素的索引。具体而言,它返回一个包含每个维度非零元素索引数组的元组。这在寻找数组中非零元素的位置时非常有用。
a=np.array([1,2,0,0,4,0])
a=np.nonzero(a)
a
(array([0, 1, 4]),)
11. 创建一个 3x3 的单位矩阵 (★☆☆)
numpy.eye 函数用于创建一个二维的单位矩阵(identity matrix)。单位矩阵是一个方阵,其主对角线上的元素均为 1,而其它元素均为 0。单位矩阵的大小由输入的参数确定。
语法如下:
numpy.eye(N, M=None, k=0, dtype=<class 'float'>, order='C')参数说明:
N: 返回的矩阵的行数。
M: (可选)返回的矩阵的列数。默认为 N。
k: (可选)对角线的偏移。正值表示上对角线,负值表示下对角线。默认为 0,表示主对角线。
dtype: (可选)返回的数组的数据类型。
order: (可选)‘C’ 表示按行的 C 风格顺序存储,‘F’ 表示按列的 Fortran 风格顺序存储。
a=np.eye(3)
a
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
12. 创建一个 3x3x3的随机数组 (★☆☆)
- np.random.random 是 NumPy 中用于生成服从均匀分布的随机样本的函数,其语法如下:
*-numpy.random.random(size=None)
** size: 用于指定生成随机样本的数组形状。如果不提供,返回单个随机样本。
** 其中的元素是在半开区间 [0.0, 1.0) 内均匀分布的随机数。
a=np.random.random((3,3,3))
a
array([[[0.86000081, 0.01487458, 0.31168853],
[0.27519871, 0.81353068, 0.02458331],
[0.01194352, 0.70810269, 0.08797808]],
[[0.33990574, 0.19674185, 0.41844523],
[0.27472389, 0.42284069, 0.56331295],
[0.48208164, 0.60311039, 0.21530906]],
[[0.61734285, 0.78914963, 0.80817949],
[0.76459779, 0.84338892, 0.47303578],
[0.78238981, 0.39022624, 0.81661391]]])
13. 创建一个 10x10 的随机数组并找到它的最大值和最小值 (★☆☆)
a=np.random.random((10,10))
print(a)
a_max,a_min=a.max(),a.min()
print(f"最大值为:{a_max},最小值为:{a_min}")
[[0.87251655 0.95812965 0.22268919 0.05895868 0.55534781 0.2563167
0.3238934 0.01794027 0.51791528 0.03771506]
[0.18937527 0.84846026 0.19459408 0.38394758 0.83798346 0.49055697
0.84641044 0.25846426 0.98740434 0.62777417]
[0.16684204 0.5252425 0.6545476 0.19166555 0.97259195 0.54890975
0.78865651 0.20655217 0.88125307 0.52247264]
[0.65032956 0.98949575 0.09406112 0.02332834 0.55567587 0.63526981
0.88468495 0.090315 0.83148095 0.18433676]
[0.06689589 0.22161316 0.35887156 0.53759654 0.70735222 0.42831714
0.87177597 0.30566855 0.92648477 0.87179382]
[0.38734611 0.75588521 0.63223681 0.18156126 0.20046393 0.11143773
0.44299678 0.57020412 0.84370792 0.23172209]
[0.96854648 0.86519475 0.57233523 0.87026014 0.03149531 0.71635881
0.55320902 0.19898275 0.14742436 0.8431734 ]
[0.39432292 0.15567199 0.31174198 0.37321367 0.65442364 0.02340556
0.1310459 0.81403028 0.19408367 0.36864657]
[0.77901981 0.11500564 0.85799836 0.15221063 0.4486416 0.71949732
0.1457204 0.67316866 0.20111885 0.63329934]
[0.76199289 0.36808286 0.56829539 0.21172502 0.46989318 0.88160521
0.5031623 0.05154334 0.45452765 0.81610687]]
最大值为:0.9894957515766177,最小值为:0.01794027469745807
14. 创建一个长度为30的随机向量并找到它的平均值 (★☆☆)
a=np.random.random(30)
a_mean=a.mean()
a_mean
0.5259837622291507
15. 创建一个二维数组,其中边界值为1,其余值为0 (★☆☆)
a=np.ones((10,10))
#a[1:9,1:9]=0
a[1:-1,:-1]=0
a
array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])
16. 对于一个存在在数组,如何添加一个用0填充的边界? (★☆☆)
np.pad 函数是 NumPy 中用于在数组周围添加边缘或填充值的函数。它的语法如下:
numpy.pad(array, pad_width, mode='constant', **kwargs)参数说明:
array: 输入的数组。
pad_width: 每个轴(维度)上要添加的边缘宽度。可以是单个整数,表示在所有轴上添加相同宽度的边缘,也可以是长度为 (before, after) 的元组,表示在每个轴上添加不同宽度的前置和后置边缘。
mode: 填充模式,用于指定如何填充边缘。默认为 ‘constant’。
constant_values:填充的元素,默认为0**kwargs: 其他可选参数,具体取决于填充模式。
a=np.arange(9).reshape(3,3)
a=np.pad(a,pad_width=1)
a
array([[0, 0, 0, 0, 0],
[0, 0, 1, 2, 0],
[0, 3, 4, 5, 0],
[0, 6, 7, 8, 0],
[0, 0, 0, 0, 0]])
17. 以下表达式运行的结果分别是什么? (★☆☆)
- 提示: NaN = not a number, inf = infinity)
- 任何数乘以 NaN 都会得到 NaN。
- 在 NumPy 中,NaN 不等于自身。这是因为 NaN 通常表示不确定的或未定义的值,因此无法简单地与另一个 NaN 进行相等比较。
- 正无穷是大于任何有限数和 NaN 的,但 NaN 无法被比较。因此,这个表达式的结果是 False。
- 任何数减去 NaN 都会得到 NaN
- 这是由于浮点数表示误差。在计算机中,某些十进制小数不能精确地表示为二进制浮点数,导致小数计算时的精度问题。在这个例子中,0.3 无法精确表示为二进制浮点数,因此与 3 * 0.1 比较时会产生小数位的差异,结果为 False。在浮点数比较中,通常应该使用某个小的容忍度(例如,使用 numpy.isclose 函数)。
print(0*np.nan)
print(np.nan==np.nan)
print(np.inf>np.nan)
print(np.nan-np.nan)
print(0.3==3*0.1)
nan
False
False
nan
False
18. 创建一个 5x5的矩阵,并设置值1,2,3,4落在其对角线下方位置 (★☆☆)
np.diag 函数用于提取对角线元素或构造对角矩阵,具体操作取决于传递给函数的参数。
提取对角线元素
- 当你给 np.diag 传递一个二维数组时,它会返回数组的主对角线上的元素。语法如下:
numpy.diag(v, k=0)
v: 输入的数组。
k: 对角线的偏移量。主对角线为0,正值表示上对角线,负值表示下对角线。构造对角矩阵
当你给 np.diag 传递一个一维数组时,它会返回一个以该数组为主对角线元素的对角矩阵。
a=np.zeros((5,5))
np.fill_diagonal(a[1:, :-1], [1, 2, 3, 4])
a
# 或者更简单的方法
# a = np.diag(1+np.arange(4),k=-1)
array([[0., 0., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 2., 0., 0., 0.],
[0., 0., 3., 0., 0.],
[0., 0., 0., 4., 0.]])
19. 创建一个8x8 的矩阵,并且设置成棋盘样式 (★☆☆)
Z = np.zeros((8,8),dtype=int)
print(Z)
Z[1::2,::2] = 1
Z[::2,1::2] = 1
print(Z)
[[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]]
[[0 1 0 1 0 1 0 1]
[1 0 1 0 1 0 1 0]
[0 1 0 1 0 1 0 1]
[1 0 1 0 1 0 1 0]
[0 1 0 1 0 1 0 1]
[1 0 1 0 1 0 1 0]
[0 1 0 1 0 1 0 1]
[1 0 1 0 1 0 1 0]]
20. 考虑一个 (6,7,8) 形状的数组,其第100个元素的索引(x,y,z)是什么?
np.unravel_index 函数的作用是将扁平索引(在一维数组中的索引)转换为多维数组的索引。具体而言,给定一个扁平索引,该函数返回该索引在多维数组中的对应位置的索引值。
- numpy.unravel_index(indices, shape, order=‘C’)
参数说明:
indices: 扁平索引或包含多个扁平索引的数组。
shape: 多维数组的形状。
order: {‘C’, ‘F’},用于指定多维数组的索引顺序,‘C’ 表示按行的 C 风格顺序,‘F’ 表示按列的 Fortran 风格顺序。
a=np.arange(336).reshape((6,7,8))
index=np.unravel_index(100,a.shape)
print(index)
print(a[index])
(1, 5, 4)
100
21. 用tile函数去创建一个 8x8的棋盘样式矩阵(★☆☆)
numpy.tile 的作用是通过沿指定轴复制数组来构造新的数组。
以下是 numpy.tile 函数的基本语法:
numpy.tile(A, reps)
参数说明:
A:要复制的数组。
reps:沿各个维度重复的次数。
a=np.tile(np.array([[0,1],[1,0]]),(4,4))
a
array([[0, 1, 0, 1, 0, 1, 0, 1],
[1, 0, 1, 0, 1, 0, 1, 0],
[0, 1, 0, 1, 0, 1, 0, 1],
[1, 0, 1, 0, 1, 0, 1, 0],
[0, 1, 0, 1, 0, 1, 0, 1],
[1, 0, 1, 0, 1, 0, 1, 0],
[0, 1, 0, 1, 0, 1, 0, 1],
[1, 0, 1, 0, 1, 0, 1, 0]])
22. 对一个5x5的随机矩阵做归一化(★☆☆)
a=np.random.random((5,5))*100
print(a)
a_max,a_min=a.max(),a.min()
a=(a-a_min)/(a_max-a_min)
print('归一化后')
print(a)
[[35.73584401 73.66360488 34.99665744 92.65552426 36.99521764]
[52.02687978 46.5001102 34.8487469 33.44784381 67.22239537]
[27.19007355 31.7241669 28.4116792 11.36360295 83.53285565]
[43.57793044 63.54621665 83.57473101 49.14157272 44.65001753]
[25.07461979 1.35842603 82.17381887 24.41805833 40.07717417]]
归一化后
[[0.37654448 0.79197675 0.36844798 1. 0.39033871]
[0.55498427 0.49444818 0.36682788 0.35148344 0.72142456]
[0.28294051 0.33260357 0.29632106 0.10958921 0.90007712]
[0.46244081 0.68115846 0.9005358 0.52338078 0.47418365]
[0.25976941 0. 0.88519125 0.25257793 0.42409615]]
23. 创建一个将颜色描述为(RGBA)四个无符号字节的自定义dtype?(★☆☆)
np.dtype自定义数据类型,可以规定数据的字段类型,以及每个字段的大小,
color=np.dtype([("r",np.ubyte,1),
("g",np.ubyte,1),
("b",np.ubyte,1),
("a",np.ubyte,1)])
color
/var/folders/cr/2fpn8__12377w89ml3mv5ksw0000gn/T/ipykernel_90434/2580298444.py:1: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
color=np.dtype([("r",np.ubyte,1),
dtype([('r', 'u1'), ('g', 'u1'), ('b', 'u1'), ('a', 'u1')])
24. 一个5x3的矩阵与一个3x2的矩阵相乘,实矩阵乘积是什么? (★☆☆)
a=np.arange(15).reshape((5,3))
print(a)
print('\n')
b=np.ones((3,2))
print(b)
print('\n')
print(np.dot(a,b))
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]
[12 13 14]
[[1. 1.]
[1. 1.]
[1. 1.]]
[[ 3. 3.]
[12. 12.]
[21. 21.]
[30. 30.]
[39. 39.]]
25. 给定一个一维数组,对其在3到8之间的所有元素取反 (★☆☆)
a=np.arange(12)
print(a)
a[(a>3) &(a<=8)]*=-1
print(a)
[ 0 1 2 3 4 5 6 7 8 9 10 11]
[ 0 1 2 3 -4 -5 -6 -7 -8 9 10 11]
26. 下面脚本运行后的结果是什么? (★☆☆)
1.print(sum(range(5),-1))
2.from numpy import *
print(sum(range(5),-1))解释:
- 1.这会输出 9。这是因为 sum(range(5), -1) 的含义是,将 range(5) 中的所有元素加起来,并将结果与 -1 相加。
- 这会输出 10。在 NumPy 中,sum 函数的用法与内建的 sum 函数略有不同,其中的第二个参数是指定求和的轴。在这里,-1 表示沿着数组的最后一个轴进行求和,因此会将一维数组 [0, 1, 2, 3, 4] 中的所有元素相加,结果为 10。
print(sum(range(5),-1))
9
from numpy import *
print(sum(range(5),-1))
10
27. 考虑一个整数向量Z,下列表达合法的是哪个? (★☆☆)
- Z**Z
- 2 << Z >> 2
- Z <- Z
- 1j*Z
- Z/1/1
- ZZ
回答:
- 合法的有:1,2,3,4,5,
- 不合法的有:6
a=np.arange(5)
print(a)
print(a**a)
print(2<<a >>2)
print(a< -a)
print(1j*a)
print(a/1/1)
[0 1 2 3 4]
[ 1 1 4 27 256]
[0 1 2 4 8]
[False False False False False]
[0.+0.j 0.+1.j 0.+2.j 0.+3.j 0.+4.j]
[0. 1. 2. 3. 4.]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [96], in <cell line: 8>()
6 print(1j*a)
7 print(a/1/1)
----> 8 print(a<a>a)
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
28. 下列表达式的结果分别是什么?(★☆☆)
- np.array(0) / np.array(0):在NumPy中,对零除以零会得到 NaN (Not a Number)。在这个具体的例子中,它会引发警告,结果是 nan。
- np.array(0) // np.array(0):在NumPy中,整数除法中的零除以零不会引发运行时错误,而是会得到0。这是NumPy中的一种特殊情况,与Python中的整数除法不同,Python中的整数除法会引发 ZeroDivisionError。在NumPy中,整数除法的规则稍有不同,它会在遇到零除以零的情况时得到0。
- np.array([np.nan]).astype(int).astype(float):NaN首先被转换为整数类型的特殊值,然后再转换为浮点数时,特殊的整数值会被解释为浮点数的 0.0
print(np.array(0) / np.array(0))
print(np.array(0) // np.array(0))
print(np.array([np.nan]).astype(int).astype(float))
nan
0
[0.]
/var/folders/cr/2fpn8__12377w89ml3mv5ksw0000gn/T/ipykernel_90434/1342500386.py:1: RuntimeWarning: invalid value encountered in true_divide
print(np.array(0) / np.array(0))
/var/folders/cr/2fpn8__12377w89ml3mv5ksw0000gn/T/ipykernel_90434/1342500386.py:2: RuntimeWarning: divide by zero encountered in floor_divide
print(np.array(0) // np.array(0))
29. 如何从零位对浮点数组做舍入 ? (★☆☆)
np.random.uniform函数用于从一个均匀分布中生成随机样本。其基本语法如下:
numpy.random.uniform(low=0.0, high=1.0, size=None)
参数说明:
low:分布的下限(包含)。
high:分布的上限(不包含)。
size:生成随机样本的数量,可以是整数,元组或None。如果为None,则返回单个随机样本;如果是整数,则返回一个包含指定数量元素的数组;如果是元组,则返回一个包含指定形状的数组。
np.abs(Z):计算数组中每个元素的绝对值
np.ceil():
np.copysign 函数用于将一个数组中的元素的绝对值与另一个数组中的元素的符号相结合,产生一个新的数组。其基本语法如下:
numpy.copysign(x1, x2)
参数说明:
x1:表示绝对值的数组。
x2:表示符号的数组。
返回值:一个新的数组,其元素的绝对值来自于 x1,而符号来自于 x2。
a = np.random.uniform(-10,+10,10)
print (np.ceil(a))
# Z = np.random.uniform(-10,+10,10)
# print (np.copysign(np.ceil(np.abs(Z)), Z))
[ 1.43329194 -4.8720988 -4.00263312 6.7592907 -4.04200198 -6.07420686
8.19706659 9.95742957 3.71356199 -7.28792244]
[ 2. -4. -4. 7. -4. -6. 9. 10. 4. -7.]
30. 如何找到两个数组中的共同元素? (★☆☆)
np.intersect1d 函数用于找到两个数组的交集,返回一个包含交集元素的新数组,该数组中的元素是唯一的。它会将输入数组中的元素进行排序,并返回排序后的交集数组。其基本语法如下:
numpy.intersect1d(ar1, ar2, assume_unique=False, return_indices=False)
参数说明:
ar1:第一个输入数组。
ar2:第二个输入数组。
assume_unique:如果为 True,表示输入数组已经是唯一的(已排序且没有重复)。默认为 False。
return_indices:如果为 True,则返回一个元组 (intersect, indices_ar1, indices_ar2),其中 indices_ar1 和 indices_ar2 是相应于 ar1 和 ar2 中的元素的索引。
a1=np.arange(10)
a2=np.arange(2,8,1)
print(np.intersect1d(a1,a2))
[2 3 4 5 6 7]
31. 如何忽略所有的 numpy 警告(尽管不建议这么做)? (★☆☆)
# 忽略所有警告
defaults = np.seterr(all="ignore")
Z = np.ones(1) / 0
# 恢复原始错误状态
_ = np.seterr(**defaults)
An equivalent way, with a context manager:
#使用上下文管理器(context manager)忽略警告
with np.errstate(divide='ignore'):
Z = np.ones(1) / 0
32. 下面的表达式是正确的吗? (★☆☆)
np.sqrt(-1) == np.emath.sqrt(-1)
解释:在NumPy中,np.sqrt(-1) 返回NaN,而np.emath.sqrt(-1) 返回1j,因为np.emath.sqrt 是扩展数学模块,用于提供更广泛的数学支持,包括处理复数。
print(np.sqrt(-1))
print(np.emath.sqrt(-1))
print(np.sqrt(-1) == np.emath.sqrt(-1))
nan
1j
False
/var/folders/cr/2fpn8__12377w89ml3mv5ksw0000gn/T/ipykernel_90434/1251884223.py:1: RuntimeWarning: invalid value encountered in sqrt
print(np.sqrt(-1))
/var/folders/cr/2fpn8__12377w89ml3mv5ksw0000gn/T/ipykernel_90434/1251884223.py:3: RuntimeWarning: invalid value encountered in sqrt
print(np.sqrt(-1) == np.emath.sqrt(-1))
33. 如何得到昨天,今天,明天的日期? (★☆☆)
np.datetime64:
用于表示日期时间。
它基于固定的时间单位,如年、月、日、小时、分钟、秒等,具体的单位可以通过字符串指定,例如 np.datetime64(‘2022-01-01’)。
还可以使用时间单位的倍数,例如 np.datetime64(10, ‘D’) 表示10天后的日期时间。np.timedelta64:
用于表示时间差,即两个日期时间之间的时间间隔。
类似于 np.datetime64,可以指定时间差的单位,例如 np.timedelta64(5, ‘D’) 表示5天的时间差。
可以进行时间差的运算,例如将一个日期时间加上一个时间差,得到新的日期时间。
yesterday=np.datetime64('today','D')-np.timedelta64(1,'D')
today=np.datetime64('today','D')
tomorrow=today+np.timedelta64(1,'D')
print(yesterday)
print(today)
print(tomorrow)
2024-01-04
2024-01-05
2024-01-06
34. 如何得到所有与2016年7月对应的日期? (★★☆)
np.arange(dtype=‘datetime64[D]’)这样的操作在处理时间序列数据时很有用,例如创建一系列日期以用于时间索引。
print(np.arange('2016-07-01','2016-08-01',dtype='datetime64[D]'))
['2016-07-01' '2016-07-02' '2016-07-03' '2016-07-04' '2016-07-05'
'2016-07-06' '2016-07-07' '2016-07-08' '2016-07-09' '2016-07-10'
'2016-07-11' '2016-07-12' '2016-07-13' '2016-07-14' '2016-07-15'
'2016-07-16' '2016-07-17' '2016-07-18' '2016-07-19' '2016-07-20'
'2016-07-21' '2016-07-22' '2016-07-23' '2016-07-24' '2016-07-25'
'2016-07-26' '2016-07-27' '2016-07-28' '2016-07-29' '2016-07-30'
'2016-07-31']
35. 如何直接在位计算(A+B)*(-A/2)(不建立副本)? (★★☆)
- np.add(out=):
作用:将两个数组的对应元素进行加法运算。
out 参数:指定计算结果的输出数组,即将计算结果存储在指定的数组中。- np.negative(out=):
作用:对数组中的每个元素进行取负操作。
out 参数:指定计算结果的输出数组,即将计算结果存储在指定的数组中。- np.multiply(out=):
作用:将两个数组的对应元素进行乘法运算。
out 参数:指定计算结果的输出数组,即将计算结果存储在指定的数组中。- np.divide(out=):
作用:将两个数组的对应元素进行除法运算。
out 参数:指定计算结果的输出数组,即将计算结果存储在指定的数组中。
a=np.ones(3)*1
b=np.ones(3)*2
print(a)
print(b)
np.add(a,b,out=b)
np.divide(a,2,out=a)
np.negative(a,out=a)
np.multiply(a,b,out=a)
[1. 1. 1.]
[2. 2. 2.]
array([-1.5, -1.5, -1.5])
36. 用五种不同的方法去提取一个随机数组的整数部分(★★☆)
np.floor:
作用:向下取整,将数组中的每个元素取其不大于自身的最大整数。
np.ceil:
作用:向上取整,将数组中的每个元素取其不小于自身的最小整数。
astype:
作用:将数组的数据类型转换为指定的数据类型。
np.trunc:
作用:截断为整数,将数组中的每个元素取其整数部分,即去掉小数部分。
a=np.random.uniform(0,10,10)
print(a)
print('1. 数字减去小数部分')
print(a-a%1)
print('2. np.floor 向下取整')
print(np.floor(a))
print('3. np.ceil 向上取整')
print(np.ceil(a)-1)
print('4. astype 转int')
print(a.astype(int))
print('5. np.trunc 截取整数')
print(np.trunc(a))
[2.28635616e+00 3.26209728e-04 3.77724935e+00 1.75988362e-01
1.55430132e+00 5.93855631e+00 4.66369985e-01 7.18598770e+00
8.72049252e+00 6.29051024e+00]
1. 数字减去小数部分
[2. 0. 3. 0. 1. 5. 0. 7. 8. 6.]
2. np.floor 向下取整
[2. 0. 3. 0. 1. 5. 0. 7. 8. 6.]
3. np.ceil 向上取整
[2. 0. 3. 0. 1. 5. 0. 7. 8. 6.]
4. astype 转int
[2 0 3 0 1 5 0 7 8 6]
5. np.trunc 截取整数
[2. 0. 3. 0. 1. 5. 0. 7. 8. 6.]
37. 创建一个5x5的矩阵,其中每行的数值范围从0到4 (★★☆)
a=np.zeros((5,5))
a+=np.arange(5)
a
array([[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]])
38. 通过考虑一个可生成10个整数的函数,来构建一个数组(★☆☆)
np.fromiter 是 NumPy 中的一个函数,用于从可迭代对象创建一个数组。其基本语法如下:
numpy.fromiter(iterable, dtype, count=-1)
参数说明:
iterable:可迭代对象,例如列表、元组等。
dtype:返回数组的数据类型。
count(可选):要从可迭代对象中读取的元素数量。如果未指定或为负数,则从可迭代对象中读取所有元素。yield 语句在 Python 中用于定义生成器函数。生成器函数是一种特殊类型的函数,它使用 yield 语句来产生一个序列的值,而不是一次性生成所有值。当生成器函数被调用时,它返回一个生成器对象,该对象可以用于迭代产生值。
def generate():
for x in range(10):
yield x
a=np.fromiter(generate(),dtype=float,count=-1)
print(a)
[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
39. 创建一个长度为10的随机向量,其值域范围从0到1,但是不包括0和1 (★★☆)
np.linspace 是 NumPy 中用于创建等间隔的一维数组的函数。其作用是在指定的起始值和结束值之间生成指定数量的均匀间隔的数字序列。
其基本语法如下:
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
参数说明:
start:序列的起始值。
stop:序列的结束值。
num:生成的等间隔样本数量,默认为50。
endpoint:如果为 True,则包括 stop 值;如果为 False,则不包括 stop 值。默认为 True。
retstep:如果为 True,返回 (数组, 步长) 的元组,其中步长为样本之间的间隔。默认为 False。
dtype:返回数组的数据类型,如果未提供,则从其他输入参数中推断数据类型。
axis:指定数组的轴。默认为0。
a=np.linspace(0,1,11,endpoint=False)[1:]
a
array([0.09090909, 0.18181818, 0.27272727, 0.36363636, 0.45454545,
0.54545455, 0.63636364, 0.72727273, 0.81818182, 0.90909091])
40. 创建一个长度为10的随机向量,并将其排序 (★★☆)
a=np.random.random(10)
print(a)
print('排序后')
a.sort()
print(a)
[0.2883271 0.51049073 0.36081688 0.78530535 0.44906228 0.679871
0.44265599 0.74763199 0.0863876 0.55867067]
排序后
[0.0863876 0.2883271 0.36081688 0.44265599 0.44906228 0.51049073
0.55867067 0.679871 0.74763199 0.78530535]
41.对于一个小数组,如何用比 np.sum更快的方式对其求和?(★★☆)
np.add.reduce 是 NumPy 中的一个函数,用于对数组中的元素进行加法操作并返回一个最终的累加结果。其作用类似于调用 np.add.reduceat,但是只返回一个结果。其基本语法如下:
numpy.add.reduce(a, axis=None, dtype=None, out=None, keepdims=False, initial=None, where=True)
参数说明:
a:输入数组。
axis:指定沿哪个轴进行累加操作。如果为 None,则对整个数组进行累加。默认为 None。
dtype:返回数组的数据类型。如果未提供,则从其他输入参数中推断数据类型。
out:指定用于存储结果的输出数组。
keepdims:如果为 True,则保持输出数组的维度,使其与输入数组具有相同的维度。默认为 False。
initial:累加的初始值,如果未提供,则使用数组的第一个元素作为初始值。
where:一个布尔数组,指示在哪里参与累加。默认为 True。
- 在小数组上,np.add.reduce 比 np.sum 快的原因主要与内部实现有关。虽然两者的目标都是对数组进行求和操作,但它们的内部细节和实现方式有所不同。
- np.sum 是一个通用的求和函数,它可以处理各种情况,包括多维数组、轴的指定等。由于其通用性,np.sum 的实现可能包含了一些额外的逻辑,以应对更复杂的使用情形。这可能使得在小数组上的性能相对较低。
- 而 np.add.reduce 是一个专门用于在单轴上对数组进行累加的函数。由于它的目标更为特定,它可能在实现中采用了一些针对这种特定情况的优化,以提高性能。对于小数组而言,这种专门优化的实现可能更为高效。
a=np.arange(10)
print(np.add.reduce(a))
45
42. 对于两个随机数组A和B,检查它们是否相等(★★☆)
p.allclose:
作用:用于检查两个数组是否在数值上相等,或者是否在指定的容差范围内相等。
语法:numpy.allclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False)
参数:
a,b:要比较的两个数组。
rtol:相对容差(相对差异的容忍度),默认为 1e-05。
atol:绝对容差(绝对差异的容忍度),默认为 1e-08。
equal_nan:是否将 NaN 视为相等,如果为 True,则 NaN 在两个数组中都视为相等。默认为 False。np.array_equal:
作用:检查两个数组的形状和元素是否完全相同。
语法:numpy.array_equal(a1, a2).
参数:
a1,a2:要比较的两个数组。总体来说,np.allclose 用于处理浮点数数组的相等性检查,而 np.array_equal 用于检查两个数组的完全相等性。选择使用哪个函数取决于你的需求和数据的类型。
a=np.linspace(0,1,6)
print(a)
b=np.linspace(0,1+1e-6,6)
print(b)
print(np.allclose(a,b))
print(np.array_equal(a,b))
[0. 0.2 0.4 0.6 0.8 1. ]
[0. 0.2000002 0.4000004 0.6000006 0.8000008 1.000001 ]
True
False
43. 创建一个只读数组(read-only) (★★☆)
flags.writeable
flags.writeable 是 NumPy 中数组对象的一个属性,用于检查数组是否可写。这个属性是一个布尔值,如果为 True,表示数组可以被修改;如果为 False,表示数组是只读的,不能被修改。
a=np.zeros(10)
a.flags.writeable=False
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [158], in <cell line: 3>()
1 a=np.zeros(10)
2 a.flags.writeable=False
----> 3 a[0]=1
ValueError: assignment destination is read-only
44. 将笛卡尔坐标下的一个10x2的矩阵转换为极坐标形式(★★☆)
a=np.random.random((10,2))
print(a)
x,y=a[:,0],a[:,1]
r=np.sqrt(x**2+y**2)
t=np.arctan2(y,x)
print(r)
print(t)
[[0.06876082 0.349651 ]
[0.111768 0.37010542]
[0.39339445 0.94132646]
[0.54373538 0.72031854]
[0.28643554 0.28288794]
[0.28045391 0.35135182]
[0.39958232 0.65813373]
[0.07031631 0.83874089]
[0.55598324 0.89324979]
[0.42997453 0.51125225]]
[0.35634797 0.38661364 1.02022287 0.9025004 0.40258031 0.44955812
0.76993899 0.84168323 1.05214664 0.66802467]
[1.37661861 1.27751519 1.17494201 0.92419584 0.77916697 0.89714541
1.02514002 1.48715635 1.01404903 0.87153744]
45. 创建一个长度为10的向量,并将向量中最大值替换为1 (★★☆)
np.argmax 和 np.argmin 是 NumPy 中用于获取数组中最大值和最小值的索引的函数。
np.argmax:
作用:返回数组中最大值的索引。
语法:numpy.argmax(a, axis=None, out=None)
参数:
a:输入的数组。
axis:指定在哪个轴上查找最大值,默认为 None,表示在整个数组中查找。
out:指定用于存储结果的输出数组。
np.argmin:
作用:返回数组中最小值的索引。
语法:numpy.argmin(a, axis=None, out=None)
参数:
a:输入的数组。
axis:指定在哪个轴上查找最小值,默认为 None,表示在整个数组中查找。
out:指定用于存储结果的输出数组。这两个函数在数据分析和处理中经常用于找到数组中的最大值和最小值的位置。需要注意的是,如果数组中存在多个最大值或最小值,这些函数只返回第一个找到的索引。
a=np.arange(10)
a[a.argmax()]=1
print(a)
[0 1 2 3 4 5 6 7 8 1]
46. 创建一个结构化数组,并实现 x 和 y 坐标覆盖 [0,1]x[0,1] 区域 (★★☆)
np.meshgrid 是 NumPy 中用于生成网格坐标矩阵的函数。它接受两个或多个一维数组,返回两个二维数组(或多维数组),这两个数组分别包含了所有输入数组中可能的组合。
具体来说,如果有两个输入数组 x 和 y,np.meshgrid(x, y) 的输出将是两个二维数组,其中一个数组的每一行都是 x 中的一个元素,而另一个数组的每一列都是 y 中的一个元素。
基本语法如下:
X, Y = np.meshgrid(x, y, indexing=‘xy’, sparse=False, copy=True)
参数说明:
x,y:输入的一维数组,用于生成网格。
indexing:指定输出数组的索引方式,可选值为 ‘xy’ 或 ‘ij’。
sparse:如果为 True,则返回稀疏矩阵(只有非零元素的坐标),如果为 False,则返回完整矩阵。默认为 False。
copy:如果为 True,则复制输入数组,如果为 False,则直接使用输入数组。默认为 True。
a=np.zeros((5,5),[('x','float'),('y','float')])
a['x'],a['y']=np.meshgrid(np.linspace(0,1,5),np.linspace(0,1,5))
print(a)
x=a['x']
y=a['y']
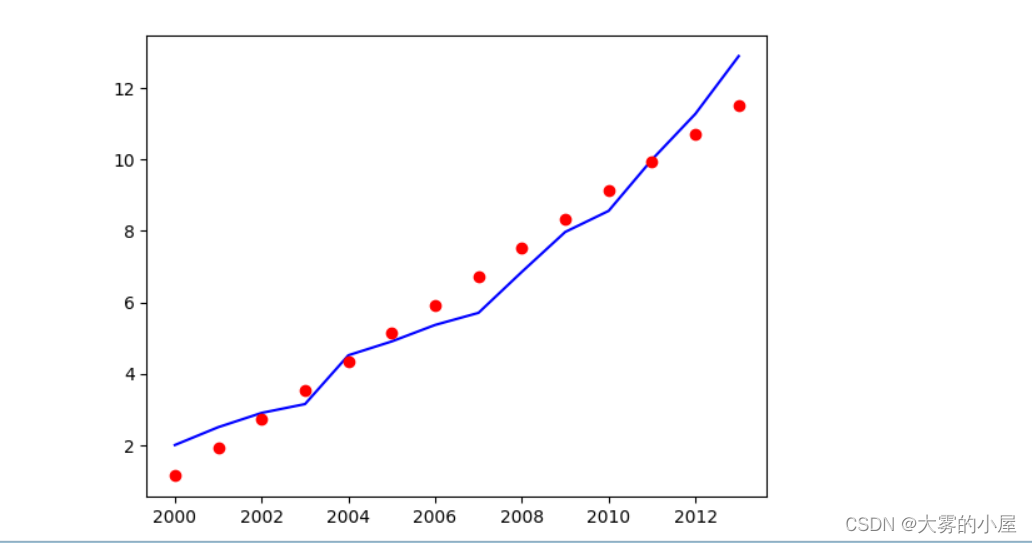
plt.scatter(x,y,marker='o')
plt.show()
[[(0. , 0. ) (0.25, 0. ) (0.5 , 0. ) (0.75, 0. ) (1. , 0. )]
[(0. , 0.25) (0.25, 0.25) (0.5 , 0.25) (0.75, 0.25) (1. , 0.25)]
[(0. , 0.5 ) (0.25, 0.5 ) (0.5 , 0.5 ) (0.75, 0.5 ) (1. , 0.5 )]
[(0. , 0.75) (0.25, 0.75) (0.5 , 0.75) (0.75, 0.75) (1. , 0.75)]
[(0. , 1. ) (0.25, 1. ) (0.5 , 1. ) (0.75, 1. ) (1. , 1. )]]

47. 给定两个数组X和Y,构造Cauchy矩阵C (Cij =1/(xi - yj))
np.subtract.outer 是 NumPy 中用于计算两个数组之间的外部差(outer difference)的函数。它接受两个一维数组作为输入,返回一个二维数组,其中包含了两个输入数组的所有元素之间的差。
基本语法如下:
numpy.subtract.outer(A, B)
参数说明:
A:输入的一维数组。
B:输入的另一个一维数组。
这种操作在某些数学计算和数据处理任务中很有用,例如在创建二维网格时或进行多项式运算时。
np.linalg.det 是 NumPy 中用于计算矩阵的行列式的函数。行列式是一个与方阵相关的标量值,对于 2x2 和 3x3 的矩阵,行列式的计算相对简单。对于更高维的矩阵,行列式的计算涉及到更多的代数和线性代数的概念。
基本语法如下:
numpy.linalg.det(a)
参数说明:
a:输入的方阵。行列式的值对于方阵的性质和变换有着重要的数学意义。如果行列式为零,表示矩阵不可逆;如果行列式为非零,则表示矩阵可逆。在线性代数和数值计算中,行列式是一个重要的概念。
x=np.arange(5)
y=x+0.5
c=1.0/np.subtract.outer(x,y)
print(c)
print(np.linalg.det(c))
[[-2. -0.66666667 -0.4 -0.28571429 -0.22222222]
[ 2. -2. -0.66666667 -0.4 -0.28571429]
[ 0.66666667 2. -2. -0.66666667 -0.4 ]
[ 0.4 0.66666667 2. -2. -0.66666667]
[ 0.28571429 0.4 0.66666667 2. -2. ]]
-131.91659501325745
48. 打印每个numpy标量类型的最小值和最大值? (★★☆)
np.iinfo、np.finfo 和 eps 是 NumPy 中用于获取整数和浮点数的信息的函数。它们的作用如下:
np.iinfo:
作用:返回整数数据类型的信息。
语法:numpy.iinfo(type)
参数:
type:整数数据类型,如 np.int32、np.int64 等。
np.finfo:
作用:返回浮点数数据类型的信息。
语法:numpy.finfo(type)
参数:
type:浮点数数据类型,如 np.float32、np.float64 等。
np.finfo(dtype).eps返回给定浮点数类型的相邻可表示值之间的差异(spacing)。这个值通常被称为机器精度(machine epsilon),表示在给定浮点数类型下,离 1 最近的可表示浮点数与 1 之间的最小正差值。- 具体来说,对于浮点数类型 dtype,np.finfo(dtype).eps 给出了与 1 最近的可表示浮点数与 1 之间的最小正差值。这个值是一个非常小的正数,表示在该浮点数类型下,两个相邻的可表示浮点数之间的最小距离。
for dtype in [np.int8,np.int16,np.int32,np.int64]:
print(np.iinfo(dtype).min)
print(np.iinfo(dtype).max)
print('-----------------')
print('float')
for dtype in [np.float16,np.float32,np.float64]:
print(np.finfo(dtype).min)
print(np.finfo(dtype).max)
print(np.finfo(dtype).eps)
print('-----------------')
-128
127
-----------------
-32768
32767
-----------------
-2147483648
2147483647
-----------------
-9223372036854775808
9223372036854775807
-----------------
float
-65500.0
65500.0
0.000977
-----------------
-3.4028235e+38
3.4028235e+38
1.1920929e-07
-----------------
-1.7976931348623157e+308
1.7976931348623157e+308
2.220446049250313e-16
-----------------
49. 如何打印一个数组中的所有数值? (★★☆)
np.set_printoptions 是 NumPy 中用于设置打印选项的函数。通过这个函数,你可以定制输出的格式,例如设置小数点后的位数、打印数组的阈值、打印数组的形状等。
基本语法如下:
numpy.set_printoptions(precision=None, threshold=None, edgeitems=None, linewidth=None, suppress=None, nanstr=None, infstr=None, formatter=None, sign=None, floatmode=None, **kwarg)
一些常用的参数说明如下:
precision:设置浮点数的小数点后的位数。
threshold:设置打印数组时的阈值,超过阈值的部分将以省略号表示。
edgeitems:设置打印数组时显示的边缘元素的数量。
linewidth:设置打印数组时每行的字符数。
suppress:控制小数的显示,如果为 True,则小数位数多于 precision 时使用科学计数法。
nanstr 和 infstr:分别设置打印数组中 NaN 和无穷大的字符串表示。
formatter:指定一个格式化函数来自定义数组元素的打印格式。
sign:设置是否在正数前显示符号。
floatmode:控制浮点数的显示格式。
a=np.random.random(10).reshape(2,5)
np.set_printoptions(precision=2)
print(a)
[[0.47 0.09 0.38 0.88 0.68]
[0.75 0.35 0.25 0.7 0.7 ]]
50. 给定标量时,如何找到数组中最接近标量的值?(★★☆)
a=np.arange(100)
v=np.random.uniform(0,100)
print(v)
i=(np.abs(a-v)).argmin()
print(a[i])
89.90785830083318
90
51. 创建一个表示位置(x,y)和颜色(r,g,b)的结构化数组(★★☆)
a=np.zeros(10,[('position',[('x',float,1),('y',float,1)]),
('color',[('r',float,1),('g',float,1),('b',float,1)])
])
print(a)
[((0., 0.), (0., 0., 0.)) ((0., 0.), (0., 0., 0.))
((0., 0.), (0., 0., 0.)) ((0., 0.), (0., 0., 0.))
((0., 0.), (0., 0., 0.)) ((0., 0.), (0., 0., 0.))
((0., 0.), (0., 0., 0.)) ((0., 0.), (0., 0., 0.))
((0., 0.), (0., 0., 0.)) ((0., 0.), (0., 0., 0.))]
/var/folders/cr/2fpn8__12377w89ml3mv5ksw0000gn/T/ipykernel_90434/344946253.py:1: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
a=np.zeros(10,[('position',[('x',float,1),('y',float,1)]),
52. 对一个表示坐标形状为(100,2)的随机向量,找到点与点的距离(★★☆)
atleast_2d 是 NumPy 中的函数,用于将输入数据至少转换为二维数组。基本语法如下:
numpy.atleast_2d(*arys)
参数说明:
*arys:可变数量的输入数组。 np
该函数会对输入的数组进行判断:
如果输入是 0 维数组,将其转换为 1 维数组。
如果输入是 1 维数组,将其保持不变。
如果输入是 2 维或更高维数组,将其保持不变。
返回值是至少包含两维的数组,即使输入本身是一维数组也会被转换为形状为 (1, N) 或 (N, 1) 的二维数组。
在这个例子中,np.atleast_2d 将一维数组 arr_1d 转换为二维数组 arr_2d,确保数组至少有两维。这对于某些函数要求输入至少是二维数组的情况很有用。
scipy.spatial.distance.cdist(Z, Z) 函数用于计算两个集合之间的距离。这个函数通常用于计算两个集合中每对点之间的距离。
基本语法如下:
scipy.spatial.distance.cdist(XA, XB, metric='euclidean', *args, **kwargs)
参数说明:
XA:表示第一个集合的数组。
XB:表示第二个集合的数组。
metric:指定计算距离的度量方式,可以是字符串(如 ‘euclidean’、‘manhattan’ 等)或自定义的距离函数。
返回值是一个二维数组,其中第 i 行和第 j 列的元素表示第一个集合中的第 i 个点与第二个集合中的第 j 个点之间的距离。
a=np.arange(20).reshape(10,2)
print(a)
x,y=np.atleast_2d(a[:,0],a[:,1])
print(x)
print(x.T)
print(np.sqrt((x-x.T)**2+(y-y.T)**2))
[[ 0 1]
[ 2 3]
[ 4 5]
[ 6 7]
[ 8 9]
[10 11]
[12 13]
[14 15]
[16 17]
[18 19]]
[[ 0 2 4 6 8 10 12 14 16 18]]
[[ 0]
[ 2]
[ 4]
[ 6]
[ 8]
[10]
[12]
[14]
[16]
[18]]
[[ 0. 2.83 5.66 8.49 11.31 14.14 16.97 19.8 22.63 25.46]
[ 2.83 0. 2.83 5.66 8.49 11.31 14.14 16.97 19.8 22.63]
[ 5.66 2.83 0. 2.83 5.66 8.49 11.31 14.14 16.97 19.8 ]
[ 8.49 5.66 2.83 0. 2.83 5.66 8.49 11.31 14.14 16.97]
[11.31 8.49 5.66 2.83 0. 2.83 5.66 8.49 11.31 14.14]
[14.14 11.31 8.49 5.66 2.83 0. 2.83 5.66 8.49 11.31]
[16.97 14.14 11.31 8.49 5.66 2.83 0. 2.83 5.66 8.49]
[19.8 16.97 14.14 11.31 8.49 5.66 2.83 0. 2.83 5.66]
[22.63 19.8 16.97 14.14 11.31 8.49 5.66 2.83 0. 2.83]
[25.46 22.63 19.8 16.97 14.14 11.31 8.49 5.66 2.83 0. ]]
a=np.arange(20).reshape(10,2)
from scipy.spatial.distance import cdist
print(cdist(a,a))
[[ 0. 2.83 5.66 8.49 11.31 14.14 16.97 19.8 22.63 25.46]
[ 2.83 0. 2.83 5.66 8.49 11.31 14.14 16.97 19.8 22.63]
[ 5.66 2.83 0. 2.83 5.66 8.49 11.31 14.14 16.97 19.8 ]
[ 8.49 5.66 2.83 0. 2.83 5.66 8.49 11.31 14.14 16.97]
[11.31 8.49 5.66 2.83 0. 2.83 5.66 8.49 11.31 14.14]
[14.14 11.31 8.49 5.66 2.83 0. 2.83 5.66 8.49 11.31]
[16.97 14.14 11.31 8.49 5.66 2.83 0. 2.83 5.66 8.49]
[19.8 16.97 14.14 11.31 8.49 5.66 2.83 0. 2.83 5.66]
[22.63 19.8 16.97 14.14 11.31 8.49 5.66 2.83 0. 2.83]
[25.46 22.63 19.8 16.97 14.14 11.31 8.49 5.66 2.83 0. ]]
53. 如何将32位的浮点数(float)转换为对应的整数(integer)?
a=np.random.random(10).astype(np.float32)*100
print(a)
a=a.astype(np.int32)
print(a)
[64.23 53.86 55.6 11.44 14.85 38.45 15.28 73.6 73.3 27.12]
[64 53 55 11 14 38 15 73 73 27]
54. 如何读取以下文件? (★★☆)
1, 2, 3, 4, 5
6, , , 7, 8
, , 9,10,11np.genfromtxt 是 NumPy 中用于从文本文件加载数据的函数。它支持读取各种格式的文本数据,并返回一个 NumPy 数组。该函数的主要作用包括:
从文本文件加载数据: np.genfromtxt 可以从文本文件中读取数据,支持多种文本文件格式,包括逗号分隔值 (CSV)、空格分隔值等。
处理缺失数据: 该函数允许在加载数据时处理缺失值,你可以指定缺失值的表示方式。
指定数据类型: 你可以通过参数指定加载后的数组的数据类型,以确保正确地解释和存储数据。
指定列: 你可以选择加载文件中的特定列,而不是加载整个文件的所有列。
相关参数:fname: 文件名,要加载的文本文件的路径。
delimiter: 分隔符,指定文本文件中的字段分隔符,例如逗号、空格等。
dtype: 数据类型,指定返回数组的数据类型。默认为 float。
comments: 注释字符,指定在文件中表示注释的字符。默认是 #。
skip_header: 跳过头部行数,指定要跳过的文件头部行数。
skip_footer: 跳过尾部行数,指定要跳过的文件尾部行数。
usecols: 选择加载的列,指定要加载的列的索引或列名。
unpack: 是否拆分列,如果为 True,返回每列作为数组的一个元素。
missing_values: 缺失值表示方式,指定文件中表示缺失值的字符串。
filling_values: 填充缺失值,用指定的值填充缺失值。
autostrip: 自动去除空格,如果为 True,去除字段两侧的空格。
delimiter: 指定分隔符,默认为 None,表示自动检测。
这只是一小部分可用参数的列表。你可以查阅 NumPy 文档以获取完整的参数列表和详细的说明:https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.genfromtxt.html
data=np.genfromtxt('data.txt',delimiter=',',dtype=int,missing_values=' ',filling_values=0)
print(data)
[[ 1 2 3 4 5]
[ 6 0 0 7 8]
[ 0 0 9 10 11]]
55. 对于numpy数组,enumerate的等价操作是什么?(★★☆)
np.ndenumerate 和 np.ndindex 是 NumPy 中用于迭代多维数组的两个函数。
np.ndenumerate:
作用: np.ndenumerate 返回数组的索引和对应的值的迭代器。可以用于同时遍历数组的索引和对应的元素值。
语法:numpy.ndenumerate(arr)np.ndindex:
作用: np.ndindex 生成多维数组的索引的迭代器。可以用于在嵌套的循环中遍历数组的所有索引。
语法:numpy.ndindex(*shape)
这两个函数在处理多维数组时非常有用,允许你以不同的方式迭代数组的元素。np.ndenumerate 提供了索引和值的同时访问,而 np.ndindex 则生成索引的迭代器,可以用于嵌套的循环。
a=np.arange(10).reshape(5,2)
for index,value in np.ndenumerate(a):
print(index,value)
print('---------------')
for index in np.ndindex(a.shape):
print(index,a[index])
(0, 0) 0
(0, 1) 1
(1, 0) 2
(1, 1) 3
(2, 0) 4
(2, 1) 5
(3, 0) 6
(3, 1) 7
(4, 0) 8
(4, 1) 9
---------------
(0, 0) 0
(0, 1) 1
(1, 0) 2
(1, 1) 3
(2, 0) 4
(2, 1) 5
(3, 0) 6
(3, 1) 7
(4, 0) 8
(4, 1) 9
56. 生成一个通用的二维Gaussian-like数组 (★★☆)
def gaussian_like_2d(shape,A=1.0,mu=None, sigma=None):
if mu is None:
mu=[s//2 for s in shape]
if sigma is None:
sigma=[s/5 for s in shape]
x,y=np.meshgrid(np.arange(shape[0]),np.arange(shape[1]))
exponent=-((x-mu[0])**2/(2*sigma[0]**2)+(y-mu[1])**2/(2*sigma[1]**2))
result=A*np.exp(exponent)
return result
shape=(100,100)
a=1.0
mu=(shape[0]//2,shape[1]//2)
sigma=(20,10)
gaussian_array=gaussian_like_2d(shape,a,mu,sigma)
#显示数组
plt.imshow(gaussian_array, cmap='viridis', extent=(0, shape[1], shape[0], 0))
plt.colorbar()
plt.title('2D Gaussian-like Array')
plt.show()

57. 对一个二维数组,如何在其内部随机放置p个元素? (★★☆)
np.put 和 np.random.choice 是 NumPy 中用于数组操作的两个函数。
np.put 函数:
作用: np.put 函数用于按照指定索引将值放入数组中。它根据给定的索引将数组的元素替换为指定的值。
numpy.put(a, ind, v, mode='raise')
a: 要操作的数组。
ind: 用于指定替换值的索引数组,可以是整数索引,也可以是布尔数组。
v: 要放入数组的值,可以是单个值或与 ind 形状相同的数组。
mode: 替换模式,表示处理索引超出数组范围的方式。可选值有:
‘raise’:如果有索引超出范围,抛出 IndexError(默认值)。
‘wrap’:在数组两端循环使用索引。
‘clip’:将超出范围的索引截断为最接近的边界索引。
np.random.choice 函数:
作用: np.random.choice 函数用于从给定的一维数组中随机抽取元素。它可以用于生成随机的样本或者进行随机抽样。
numpy.random.choice(a, size=None, replace=True, p=None)
a: 一维数组或整数,表示抽样空间。如果是数组,表示从该数组中进行抽样;如果是整数,表示从 range(a) 中进行抽样。
size: 抽样结果的形状。如果为 None,则返回单个值;如果为整数或元组,表示抽样结果的形状。
replace: 是否有放回抽样。如果为 True,允许重复抽取同一个元素;如果为 False,不允许有放回抽样。
p: 用于指定每个元素被抽中的概率。如果为 None,所有元素被选择的概率相等;如果为数组,表示每个元素对应的抽中概率。这两个函数都提供了在数组上进行操作的便捷方法,可以根据具体的需求选择使用。np.put 用于直接修改数组的指定位置的元素值,而 np.random.choice 用于从给定数组中进行随机抽样。
n=10
p=5
a=np.zeros((n,n))
np.put(a,np.random.choice(range(n*n),p,replace=False),1)
a
array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
58. 减去一个矩阵中的每一行的平均值 (★★☆)
numpy.mean 函数用于计算数组中元素的平均值。它可以应用于一维或多维数组,并返回沿指定轴的平均值。以下是 numpy.mean 函数的基本用法:
numpy.mean(a, axis=None, dtype=None, keepdims=False)
a: 要计算平均值的数组。
axis: 沿着哪个轴计算平均值。默认是对整个数组进行计算,可以是一个整数(表示轴的索引)或一个元组(表示多个轴)。
dtype: 返回数组的数据类型,如果未提供,则使用数组的数据类型。
keepdims: 如果为 True,则保持输出的维度与输入的维度相同,否则将缩小维度。
a=np.arange(20).reshape(5,4)
print(a)
print(a-a.mean(axis=1,keepdims=True))
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]]
[[-1.5 -0.5 0.5 1.5]
[-1.5 -0.5 0.5 1.5]
[-1.5 -0.5 0.5 1.5]
[-1.5 -0.5 0.5 1.5]
[-1.5 -0.5 0.5 1.5]]
59. 如何通过第n列对一个数组进行排序? (★★☆)
numpy.argsort 函数用于返回数组排序后的索引。具体来说,它返回的是数组元素从小到大排序后的索引数组。
以下是 numpy.argsort 函数的基本用法:
numpy.argsort(a, axis=-1, kind='quicksort', order=None)
a: 要排序的数组。
axis: 沿着哪个轴进行排序。默认为最后一个轴。
kind: 排序算法的种类,可选值有 ‘quicksort’、‘mergesort’、‘heapsort’ 等。默认为 ‘quicksort’。
order: 如果数组是结构化数组,则可以指定一个字段用于排序。
a=np.random.randint(0,10,(3,3))
print(a)
print (a[argsort(a[:,-1])])
[[3 1 8]
[7 1 6]
[1 8 3]]
[[1 8 3]
[7 1 6]
[3 1 8]]
60. 如何检查一个二维数组是否有空列?(★★☆)
numpy.any 函数用于测试数组中的任意元素是否为 True。它沿指定的轴检查数组中的元素,如果任意元素满足条件,则返回 True,否则返回 False。
以下是 numpy.any 函数的基本用法:
numpy.any(a, axis=None, out=None, keepdims=False)
a: 输入数组,可以是任意形状和维度。
axis: 沿着哪个轴检查元素。默认为 None,表示在整个数组上检查。
out: 输出数组,用于存储结果。如果未提供,则会创建一个新数组。
keepdims: 如果为 True,则在输出中保持输入数组的轴的尺寸。默认为 False。
a=np.array([[0,1,2],[0,3,4],[0,4,5]])
print(a)
print(np.any(np.all(a==0,axis=0)))
[[0 1 2]
[0 3 4]
[0 4 5]]
True
61. 从数组中的给定值中找出最近的值 (★★☆)
在NumPy中,flat 是数组对象的一个属性,它是一个扁平迭代器(flat iterator)。flat 属性允许你在多维数组上进行迭代,返回数组中的所有元素,按照它们在内存中的存储顺序进行迭代。
作用:
扁平迭代: 使用 flat 属性可以将多维数组扁平化,使得你可以在一个循环中依次访问所有元素。
获取扁平迭代器: flat 返回一个迭代器对象,可以用于遍历数组的所有元素。
a=np.random.uniform(0,1,10)
print(a)
b=0.5
m=a.flat[np.abs(a-b).argmin()]
print(m)
[0.46 0.19 0.37 0.96 0.19 0.94 0.58 0.25 0.43 0.89]
0.45509006392213425
62. 如何用迭代器(iterator)计算两个分别具有形状(1,3)和(3,1)的数组? (★★☆)
numpy.nditer 函数是 NumPy 中用于多维数组迭代的强大工具。它可以在不同的迭代模式下,按照指定的顺序访问数组的元素。nditer 的灵活性使得在遍历数组时可以轻松地执行各种操作。
作用:
多维数组迭代: nditer 主要用于在多维数组上进行迭代,可以方便地遍历数组的每个元素。
指定迭代顺序: 提供了多种迭代模式,可以按照不同的顺序遍历数组,例如正序、逆序、以及指定轴的迭代等。
可同时迭代多个数组: 允许同时迭代多个数组,使得在进行数组操作时更加灵活。
numpy.nditer(arr, op_flags=None, flags=None, op_dtypes=None, order='K', casting='safe', op_axes=None, itershape=None, buffersize=0)arr: 要迭代的数组。
op_flags: 操作标志,可以用于指定每个迭代的操作。
flags: 控制迭代的行为,如是否要求写入、是否使用多线程等。
op_dtypes: 操作数据类型,可以指定每个迭代的数据类型。
order: 迭代顺序,可选值有 ‘C’、‘F’、‘A’、‘K’ 等。
casting: 强制类型转换的规则。
op_axes: 操作的轴,用于在多数组情况下指定各个数组的迭代轴。
itershape: 迭代器的形状。
buffersize: 缓冲区大小,用于指定迭代时的缓冲区大小。创建形状为 (3, 1) 的一维数组 a,其元素为 [0, 1, 2]。
创建形状为 (1, 3) 的一维数组 b,其元素为 [0, 1, 2]。
使用 numpy.nditer 迭代器迭代数组 a、b 以及一个新创建的数组(初始化为 None)。
在迭代的过程中,对应位置的 a 和 b 的元素相加,结果存储在新创建的数组中。
打印最终存储结果的新数组。
a=np.arange(3).reshape(3,1)
b=np.arange(3).reshape(1,3)
it=np.nditer([a,b,None])
for x,y,z in it:
z[...]=x+y
print(it.operands[2])
[[0 1 2]
[1 2 3]
[2 3 4]]
63. 创建一个具有name属性的数组类(★★☆)
new: 该方法用于创建一个新的 NamedArray 实例。它接受一个数组和一个名称参数,将数组转换为 NamedArray 类的实例,并设置实例的 name 属性。
array_finalize: 当通过某个类的构造器(比如‘new’方法)创建一个数组时,如果这个数组是该类的实例的视图,则会调用这个方法。该方法在数组的视图被创建时调用,用于执行一些额外的操作。在这里,它从原始数组对象中获取名称属性,并将其存储在新创建的数组中。
在Python中,cls 是一个约定俗成的命名,用于表示类(class)本身。它在类的方法中作为第一个参数传递,用于引用该类的实例或类属性。在类的构造器 new 中,cls 通常用于引用类本身,用来创建类的实例。
- 关于NumPy中的视图和类的关系:
NumPy中的数组视图是指在原始数据的基础上创建的新数组,它与原始数据共享相同的内存块。数组视图不会复制原始数据,而是提供了一个不同的方式来查看相同的数据。在NumPy中,使用 .view() 方法可以创建一个数组的视图。
创建一个 NamedArray 类时,它继承自 numpy.ndarray,并通过 view(cls) 方法创建了一个数组的视图。通过 view 方法, NamedArray 类能够使用 NumPy 数组的许多特性,并在此基础上添加了额外的属性(如 name 属性)。这个类的实例不仅具有数组的功能,还有额外的自定义属性。
class NamedArray(np.ndarray):
def __new__(cls, arr, name="none"):
obj = np.asarray(arr).view(cls)
obj.name = name
return obj
def __array_finalize__(self, obj):
if obj is None:
return
self.flag = True
a=NameArray(np.arange(10),"range_10")
print(a.name)
b=a
b.flag=False
print(b.flag)
print(a.flag)
range_10
False
False
64. 考虑一个给定的向量,如何对由第二个向量索引的每个元素加1(小心重复的索引)? (★★★)
np.bincount 函数是 NumPy 中用于计算非负整数数组中每个元素出现次数的函数。该函数返回一个一维数组,其中的元素是对应索引出现的次数。
语法:
numpy.bincount(x, weights=None, minlength=0)
x: 输入的非负整数数组。
weights: 可选参数,与输入数组 x 具有相同长度的数组,用于指定每个元素的权重。
minlength: 可选参数,输出数组的最小长度,可用于指定输出数组的长度。np.add.at 函数是 NumPy 中用于按照指定的索引位置将值相加的函数。它允许在数组的特定位置进行原地操作,而不是创建新的数组。
numpy.add.at(arr, indices, values)
arr: 输入数组。
indices: 用于指定要增加值的索引的数组。
values: 要增加的值,可以是标量或与 indices 数组长度相同的数组。
a=np.ones(10)
#生成需要相加的向量索引
i=np.random.randint(0,len(a),20)
print(i)
#使用bincount记录每个索引出现的次数,如1出现了两次,索引1位置的个数需要加2
a+=np.bincount(i,minlength=len(a))
print(a)
#或者
# np.add.at(a,i,1)
# print(a)
[9 3 0 1 3 8 6 9 3 2 1 5 4 4 1 8 6 2 7 4]
[2. 4. 3. 4. 4. 2. 3. 2. 3. 3.]
65. 根据索引列表(I),如何将向量(X)的元素累加到数组(F)? (★★★)
X=np.arange(5)
print(X)
#即利用bincount进行相加,如索引1和1出现两次,即对应的将第一个1在X中的元素2和第二个1在X中的元素4相加得到6;
I=np.array([2,3,1,2,1])
F=np.bincount(I,weights=X)
print(F)
##或者
F2=np.zeros(5)
np.add.at(F2,I,X)
print(F2)
[0 1 2 3 4]
[0. 6. 3. 1.]
[0. 6. 3. 1. 0.]
66. 考虑一个(dtype=ubyte) 的 (w,h,3)图像,计算其唯一颜色的数量(★★★)
numpy.unique 函数用于找到数组中的唯一元素,并返回按升序排列的唯一值数组。该函数有几个重要的参数:
numpy.unique(ar, return_index=False, return_inverse=False, return_counts=False, axis=None)
ar: 输入数组。
return_index: 如果为 True,则返回输入数组中唯一元素的索引数组。
return_inverse: 如果为 True,则返回一个与输入数组形状相同的整数数组,其中包含输入数组中的元素的索引,用于重构输入数组。
return_counts: 如果为 True,则返回一个数组,其中包含输入数组中每个唯一元素的出现次数。
axis: 沿着指定轴查找唯一值。默认为 None,表示在整个数组中查找。
w,h=16,16
i=np.random.randint(0,2,(h,w,3)).astype(np.ubyte)
print(i.shape)
F=i[...,0]*(256*256)+i[...,1]*(256*256)+i[...,2]
print(F.shape)
print(F)
n=len(np.unique(F))
print(n)
(16, 16, 3)
(16, 16)
[[131072 65536 1 131073 1 0 65537 0 65537 1
65537 65537 131073 131072 0 1]
[ 0 131072 65537 0 0 131073 0 131072 65537 0
131073 65536 65536 131072 1 1]
[131073 65536 1 65536 131073 65536 131072 1 131073 131073
65536 65537 0 65537 131073 65537]
[ 0 65537 1 65536 131072 131072 65536 1 131073 0
0 65536 65536 131072 65537 65536]
[ 65537 65536 65536 1 131073 65537 65536 1 65536 65536
65537 0 65536 0 131072 1]
[ 0 0 131073 65537 65537 65536 1 1 65537 65536
0 131073 0 65536 1 131072]
[131073 65537 131073 1 1 65537 65536 0 65537 131072
131072 65536 131073 1 131073 1]
[ 0 65536 65536 65537 131072 0 0 0 65536 65537
1 65536 0 65536 65537 65537]
[131073 65537 65536 131073 0 65537 0 65536 65536 1
65537 65537 1 65536 131073 131073]
[ 65536 65537 131073 65537 0 0 1 65537 65537 1
131073 65536 0 131073 131073 65536]
[ 65536 65536 65537 1 65536 1 1 131072 65536 65537
131072 131073 0 1 65537 1]
[ 1 131073 65536 131073 131072 65536 0 1 65537 131073
131073 131072 131072 65537 0 1]
[ 1 65537 65537 1 65537 131073 1 65537 1 1
0 131073 65536 65536 65537 131073]
[ 65537 65537 131072 65537 0 65536 1 1 65537 0
0 65536 65536 131072 0 65537]
[131073 0 65537 65537 0 131072 65536 65537 65537 131073
131073 131072 65537 65536 65537 0]
[ 65537 65537 65536 131073 65537 65537 65537 1 1 65537
65537 65537 0 0 0 0]]
6
67. 考虑一个四维数组,如何一次性计算出最后两个轴(axis)的和? (★★★)
numpy.sum 函数用于计算数组元素的和。它有以下语法:
numpy.sum(a, axis=None, dtype=None, keepdims=False, initial=0, where=True)
a: 要求和的输入数组。
axis: 指定在哪个轴上进行求和操作。默认为 None,表示对整个数组进行求和。
dtype: 返回数组的数据类型。如果未提供,则使用输入数组的数据类型。
keepdims: 如果为 True,则保持输出的维度与输入相同。
initial: 对数组元素进行求和之前要添加到和的初始值。默认为 0。
where: 指定进行求和操作的条件。默认为 True,表示对所有元素进行求和。
a=np.random.randint(0,10,(2,2,2,2))
print(a)
sum=a.sum(axis=(-2,-1))
print(sum)
[[[[2 9]
[4 2]]
[[2 1]
[1 8]]]
[[[5 7]
[5 4]]
[[0 5]
[1 9]]]]
[[17 12]
[21 15]]
68. 考虑一个一维向量D,如何使用相同大小的向量S来计算D子集的均值?(★★★)
D=np.random.uniform(0,1,100)
print(D)
S=np.random.randint(0,10,100)
print(S)
D_sums=np.bincount(S,D)
print(D_sums)
D_counts=np.bincount(S)
print(D_counts)
D_means=D_sums/D_counts
print(D_means)
##或者方法2
import pandas as pd
print(pd.Series(D).groupby(S).mean())
[0.03 0.78 0.69 0.07 0.72 0.38 0.88 0.86 0.37 0.35 0.53 0.03 0.7 0.89
0.51 0.42 0.19 0.45 0.58 0.26 0.86 0.5 0.64 0.77 0.07 0.03 0.9 0.48
0.52 0.49 0.64 0.72 0.68 0.23 0.88 0.82 0.97 0.36 0.19 0.02 0.63 0.72
0.57 0.55 0.82 0.78 0.55 0.69 0.95 0.12 0.19 0.27 0.82 0.64 0.45 0.38
0.53 0.85 0.68 0.2 0.65 0.99 0.96 0.1 0.76 0.8 0.79 0.1 0.89 0.15
0.55 0.87 0.11 0.81 0.68 0.03 0.99 0.34 0.34 0.82 0.81 0.39 0.55 0.9
1. 0.95 0.89 0.75 0.83 0.01 0.34 0.93 0.91 0.1 0.74 0.22 0.83 0.94
0.41 0.82]
[4 4 1 5 4 2 3 4 0 8 0 9 9 9 8 5 0 7 0 1 6 0 1 7 2 2 4 0 9 0 9 0 8 9 0 9 0
9 0 2 0 5 9 5 6 9 1 7 8 4 6 0 0 7 0 7 5 9 9 8 8 7 4 0 6 4 4 6 4 2 6 5 4 9
3 4 4 9 3 3 3 1 5 9 2 4 9 7 6 5 2 3 9 6 8 9 2 9 1 8]
[ 8.18 2.95 2.83 4.46 8.93 3.73 4.23 4.66 4.89 12.08]
[16 6 8 6 14 8 8 7 8 19]
[0.51 0.49 0.35 0.74 0.64 0.47 0.53 0.67 0.61 0.64]
0 0.510982
1 0.491211
2 0.353272
3 0.743376
4 0.637604
5 0.466660
6 0.528168
7 0.666266
8 0.611535
9 0.635642
dtype: float64
69. 如何获得点积 dot prodcut的对角线? (★★★)
np.einsum 函数用于执行爱因斯坦求和约定(Einstein summation convention)。这是一种用于表示多维数组之间的操作的紧凑且强大的语法。通过指定操作的输入和输出的索引标记,np.einsum 允许执行各种线性代数和张量运算,如矩阵乘法、矩阵转置、内积、外积等。
语法:
numpy.einsum(subscripts, *operands, out=None, dtype=None, order='K', casting='safe', optimize=False)
subscripts: 表示操作的索引标记的字符串。
operands: 要操作的输入数组。
out: 结果存储的数组。如果未提供,则创建一个新数组。
dtype: 结果数组的数据类型。
order: 输入数组的存储顺序(C-顺序或者 F-顺序)。
casting: 在类型转换时允许的策略。
optimize: 是否进行优化。
np.einsum 根据指定的索引标记执行不同的操作,包括矩阵乘法、内积、对角元素求和等。‘ij,jk->ik’ 表示进行矩阵乘法,‘i,i->’ 表示进行内积,‘ii->’ 表示对角元素求和。
a=np.arange(16).reshape(4,4)
print(a)
b=np.arange(16).reshape(4,4)
print(b)
print(np.dot(a,b))
print(np.diag(np.dot(a,b)))
## 方法2
print(np.sum(a*b.T,axis=1))
##方法3 简洁方法
np.einsum("ij,ji->i",a,b)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
[[ 56 62 68 74]
[152 174 196 218]
[248 286 324 362]
[344 398 452 506]]
[ 56 174 324 506]
[ 56 174 324 506]
array([ 56, 174, 324, 506])
70. 考虑一个向量[1,2,3,4,5],如何建立一个新的向量,在这个新向量中每个值之间有3个连续的零?(★★★)
a=np.array([1,2,3,4,5])
na=3
a1=np.zeros(len(a)+(len(a)-1)*3)
a1[::na+1]=a
print(a1)
[1. 0. 0. 0. 2. 0. 0. 0. 3. 0. 0. 0. 4. 0. 0. 0. 5.]
71. 考虑一个维度(5,5,3)的数组,如何将其与一个(5,5)的数组相乘?(★★★)
a=np.ones((5,5,3))
b=2*np.ones((5,5))
print(a*b[:,:,None])
[[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]
[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]
[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]
[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]
[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]]
72.如何对一个数组中任意两行做交换? (★★★)
a=np.arange(25).reshape(5,5)
print(a)
a[[0,1]]=a[[1,0]]
print(a)
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]]
[[ 5 6 7 8 9]
[ 0 1 2 3 4]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]]
73. 考虑一个可以描述10个三角形的triplets,找到可以分割全部三角形的line segment
numpy.repeat 函数用于沿指定轴重复数组中的元素。这对于构建具有重复元素的新数组非常有用。
语法:
numpy.repeat(a, repeats, axis=None)
a: 输入数组。
repeats: 一个整数,数组或者包含整数的数组。指定每个元素重复的次数。如果是整数,则所有元素都重复相同的次数;如果是数组,则表示每个元素重复的次数。
axis: 沿着哪个轴重复,默认为 None,表示在展平的数组中重复。numpy.roll 函数用于沿指定轴滚动数组的元素。具体来说,它将数组中的元素沿指定轴向前或向后滚动指定的数量。这对于创建循环效果或者在数组中循环移动元素非常有用。
numpy.roll(a, shift, axis=None)
a: 输入数组。
shift: 沿指定轴滚动的元素数量,可以为负值(向后滚动)或正值(向前滚动)。
axis: 指定沿其滚动的轴,默认为 None,表示在展平的数组中滚动。
#创建是个三角形的顶点索引
faces=np.random.randint(0,100,(10,3))
print(faces)
#将每个三角形的边重复一次,然后向后滚动一个位置
F=np.roll(faces.repeat(2,axis=1),-1,axis=1)
print(F)
#通过将重复的边展开,得到30*2数组,每行都是一条边
F=F.reshape(len(F)*3,2)
F=np.sort(F,axis=1)
G=F.view(dtype=[('p0',F.dtype),('p1',F.dtype)])
print(G)
G=np.unique(G)
print(G)
[[92 83 21]
[44 70 3]
[35 90 86]
[30 30 82]
[83 58 68]
[40 84 17]
[25 38 23]
[66 80 53]
[ 5 51 30]
[17 58 49]]
[[92 83 83 21 21 92]
[44 70 70 3 3 44]
[35 90 90 86 86 35]
[30 30 30 82 82 30]
[83 58 58 68 68 83]
[40 84 84 17 17 40]
[25 38 38 23 23 25]
[66 80 80 53 53 66]
[ 5 51 51 30 30 5]
[17 58 58 49 49 17]]
[[(83, 92)]
[(21, 83)]
[(21, 92)]
[(44, 70)]
[( 3, 70)]
[( 3, 44)]
[(35, 90)]
[(86, 90)]
[(35, 86)]
[(30, 30)]
[(30, 82)]
[(30, 82)]
[(58, 83)]
[(58, 68)]
[(68, 83)]
[(40, 84)]
[(17, 84)]
[(17, 40)]
[(25, 38)]
[(23, 38)]
[(23, 25)]
[(66, 80)]
[(53, 80)]
[(53, 66)]
[( 5, 51)]
[(30, 51)]
[( 5, 30)]
[(17, 58)]
[(49, 58)]
[(17, 49)]]
[( 3, 44) ( 3, 70) ( 5, 30) ( 5, 51) (17, 40) (17, 49) (17, 58) (17, 84)
(21, 83) (21, 92) (23, 25) (23, 38) (25, 38) (30, 30) (30, 51) (30, 82)
(35, 86) (35, 90) (40, 84) (44, 70) (49, 58) (53, 66) (53, 80) (58, 68)
(58, 83) (66, 80) (68, 83) (83, 92) (86, 90)]
74.给定一个二进制的数组C,如何产生一个数组A满足np.bincount(A)==C(★★★)
C=np.array([0,1,0,1,0,0,1])
A=np.repeat(np.arange(len(C)),C)
print(A)
print(np.bincount(A))
[1 3 6]
[0 1 0 1 0 0 1]
75. 如何通过滑动窗口计算一个数组的平均数? (★★★)
np.cumsum 函数用于计算数组元素的累积和。具体来说,返回一个具有相同形状的数组,其中每个元素是原始数组对应位置之前所有元素的和。
语法:
numpy.cumsum(a, axis=None, dtype=None, out=None)
a: 输入数组。
axis: 指定沿着哪个轴计算累积和,默认为 None,表示在展平的数组中计算。
dtype: 指定输出数组的数据类型。
out: 可选,用于指定输出数组的位置。在这个示例中,moving_average 函数计算了输入数据 data 的窗口大小为 3 的移动平均值。输出结果是一个新的数组,其长度比原始数组少 n - 1,因为在计算移动平均时,需要考虑窗口的大小。
def moving_average(a,n=3):
ret = np.cumsum(a, dtype=float)
print(f'cumsum:{ret}')
ret[n:] = ret[n:] - ret[:-n]
print(f'cafter:{ret}')
return ret[n - 1:] / n
Z=np.arange(10)
print(Z)
ret=moving_average(Z,n=3)
print(ret)
[0 1 2 3 4 5 6 7 8 9]
cumsum:[ 0. 1. 3. 6. 10. 15. 21. 28. 36. 45.]
cafter:[ 0. 1. 3. 6. 9. 12. 15. 18. 21. 24.]
[1. 2. 3. 4. 5. 6. 7. 8.]
76.考虑一维数组Z,构建一个二维数组,其第一行为(Z[0],Z[1],Z[2]),随后的每一行偏移1(最后一行应为(Z[-3],Z[-2],Z[-1])76. 76.考虑一维数组Z,构建一个二维数组,其第一行为(Z[0],Z[1],Z[2]),随后的每一行偏移1(最后一行应为(Z[-3],Z[-2],Z[-1])
numpy.lib.stride_tricks.as_strided 函数用于创建一个共享内存的视图,从而可以按照指定的形状和步幅访问数组的元素,而无需复制数组数据。这样可以在不占用额外内存的情况下,灵活地改变数组的形状和步幅。
语法:
numpy.lib.stride_tricks.as_strided(x, shape=None, strides=None, subok=False, writeable=True)
x: 输入数组。
shape: 返回数组的形状。
strides: 返回数组的步幅。
subok: 如果为 True,则返回的数组是输入数组的子类;如果为 False,则返回的数组是基类 np.ndarray 的实例。
writeable: 如果为 False,返回的数组为只读。
from numpy.lib import stride_tricks
def rolling(a,windows):
shape=(a.size-windows+1,windows)
strides=(a.itemsize,a.itemsize)
return stride_tricks.as_strided(a,shape=shape,strides=strides)
a=np.arange(10)
z=rolling(a,3)
print("原始数据:",a)
print("滑动窗口数据:")
print(z)
原始数据: [0 1 2 3 4 5 6 7 8 9]
滑动窗口数据:
[[0 1 2]
[1 2 3]
[2 3 4]
[3 4 5]
[4 5 6]
[5 6 7]
[6 7 8]
[7 8 9]]
77. 如何对布尔值取反,或者原位(in-place)改变浮点数的符号(sign)?(★★★)
np.logical_not 是 NumPy 中的逻辑运算函数,用于对数组中的元素进行逻辑非(取反)操作。它返回一个新的数组,新数组的每个元素都是原始数组中对应位置元素的逻辑非结果。
语法:
numpy.logical_not(x, /, out=None, *, where=True, casting='same_kind', order='K', dtype=None, subok=True[, signature, extobj])
x: 输入数组。
out: 可选,用于指定输出数组的位置。
where: 可选,用于指定在哪些位置进行逻辑非操作。
dtype: 可选,指定输出数组的数据类型。注意np.logical_not用于逻辑非操作,即对布尔数组中的每个元素取反。它是逐元素的逻辑非操作,返回一个布尔数组,输出数组的每个元素是输入数组中对应位置元素的逻辑非结果。
总的来说,np.logical_not 主要用于处理布尔数组的逻辑非操作,而 np.negative 主要用于对数值数组的数值取反操作。它们的应用场景和操作对象不同。
a=np.random.uniform(-1,1,100)
print("取反前:",a)
np.negative(a,out=a)
print(a)
##方法2
a=np.zeros(10)
print("取反前:",a)
np.logical_not(a,out=a)
print(a)
取反前: [ 0.85 -0. 0.76 0.89 0.61 0.87 -0.02 0.07 0.04 -0.33 -0.77 -0.3
0.62 -0.18 -0.88 -0.59 -0.49 -0.64 -0.52 -0.82 -0.46 -0.52 0.4 0.12
-0.67 -0.03 0.51 -0.64 0.1 0.24 0.49 0.48 0.41 0.82 0.44 -0.29
-0.17 0.92 -0.18 0.74 -0.57 0.48 -0.25 0.94 -0.53 -0.21 0.79 0.87
-0.9 0.68 0.95 0.69 0.72 0.89 -0.84 -0.08 -0.31 0.84 0.78 0.52
-0.75 0.92 -0.29 0.07 0.75 0.04 0.58 -0.06 0.98 -0.19 -0.37 0.89
0.68 -0.49 0.6 -0.48 0.88 0.79 -0.59 0.6 -0.21 0.46 0.2 -0.31
0.82 0.16 0.73 0.69 -0.49 -0.07 0.8 0.47 -0.23 0.17 -0.7 0.69
-0.21 -0.72 -0.97 0.02]
[-0.85 0. -0.76 -0.89 -0.61 -0.87 0.02 -0.07 -0.04 0.33 0.77 0.3
-0.62 0.18 0.88 0.59 0.49 0.64 0.52 0.82 0.46 0.52 -0.4 -0.12
0.67 0.03 -0.51 0.64 -0.1 -0.24 -0.49 -0.48 -0.41 -0.82 -0.44 0.29
0.17 -0.92 0.18 -0.74 0.57 -0.48 0.25 -0.94 0.53 0.21 -0.79 -0.87
0.9 -0.68 -0.95 -0.69 -0.72 -0.89 0.84 0.08 0.31 -0.84 -0.78 -0.52
0.75 -0.92 0.29 -0.07 -0.75 -0.04 -0.58 0.06 -0.98 0.19 0.37 -0.89
-0.68 0.49 -0.6 0.48 -0.88 -0.79 0.59 -0.6 0.21 -0.46 -0.2 0.31
-0.82 -0.16 -0.73 -0.69 0.49 0.07 -0.8 -0.47 0.23 -0.17 0.7 -0.69
0.21 0.72 0.97 -0.02]
取反前: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
78. 考虑两组点集P0和P1去描述一组线(二维)和一个点p,如何计算点p到每一条线 i (P0[i],P1[i])的距离?(★★★)
def distance(P0,P1,p):
T=P1-P0
L=(T**2).sum(axis=1)
#计算点p在直线上的投影位置,利用的是点到直线的投影公式
U=-((P0[:,0]-p[...,0]*T[:,0]+P1[:,1]-p[...,1]*T[:,1]))/L
U=U.reshape(len(U),1)
D=P0+U*T-p
print(D)
return np.sqrt((D**2).sum(axis=1))
p0=np.random.uniform(-10,10,(10,2))
p1=np.random.uniform(-10,10,(10,2))
p=np.random.uniform(-10,10,(1,2))
print(distance(p0,p1,p))
[[ 10.06 2.68]
[ 17.95 2.94]
[ -5.87 -9.21]
[ 13.73 0.27]
[ 8.22 2.12]
[ 17.22 4.31]
[ 11.61 2.95]
[ -2.64 4.05]
[ 4.97 -13.43]
[ 10.69 -5.65]]
[10.41 18.19 10.92 13.74 8.48 17.76 11.98 4.84 14.32 12.09]
79.考虑两组点集P0和P1去描述一组线(二维)和一组点集P,如何计算每一个点 j(P[j]) 到每一条线 i (P0[i],P1[i])的距离?(★★★)
## 参考问题78
p0=np.random.uniform(-10,10,(10,2))
p1=np.random.uniform(-10,10,(10,2))
p=np.random.uniform(-10,10,(10,2))
print(np.array([distance(p0,p1,p_i) for p_i in p]))
[[ 3.78 12.51]
[ -7.4 2.95]
[ 1.16 -8.01]
[-14.63 0.99]
[ -3.97 3.02]
[ -0.75 -9.72]
[ 4.06 0.23]
[-10.91 -0.55]
[ -5.92 -3.25]
[ -8.72 7.92]]
[[ 9.49 7.06]
[-5.35 -1.21]
[11.45 -4.69]
[-3.43 1.9 ]
[-3.35 0.64]
[-0.65 -8.49]
[ 4.28 1.99]
[-6.66 -5.83]
[ 5.28 -3.8 ]
[-8.64 9.03]]
[[ 8.86 7.67]
[-5.4 -1.13]
[ 9.28 -5.39]
[-5.6 1.72]
[-3.26 0.28]
[-0.74 -9.58]
[ 4.13 0.81]
[-7.03 -5.37]
[ 3.23 -3.7 ]
[-8.71 7.96]]
[[ 4.45 11.87]
[ -7.42 3. ]
[ 3.82 -7.15]
[-12.03 1.2 ]
[ -4.12 3.63]
[ -0.63 -8.24]
[ 4.26 1.82]
[-10.55 -1. ]
[ -3.48 -3.37]
[ -8.62 9.38]]
[[ 15.93 0.92]
[ -1.27 -9.54]
[ 13.24 -4.12]
[ 0.47 2.21]
[ -1.12 -8.05]
[ -1.25 -16.18]
[ 3.35 -5.4 ]
[ -0.9 -12.97]
[ 10.24 -4.04]
[ -9.16 1.28]]
[[ 15.27 1.56]
[ -1.61 -8.84]
[ 12.64 -4.31]
[ -0.31 2.15]
[ -1.28 -7.41]
[ -1.22 -15.77]
[ 3.39 -5.04]
[ -1.46 -12.29]
[ 9.41 -4. ]
[ -9.13 1.69]]
[[ 8.32 8.18]
[ -3.84 -4.3 ]
[ -1.29 -8.8 ]
[-15.18 0.95]
[ -1.81 -5.38]
[ -1.44 -18.57]
[ 2.95 -8.52]
[ -6.49 -6.04]
[ -5.31 -3.28]
[ -9.31 -0.94]]
[[ 11.18 5.45]
[ -3.77 -4.43]
[ 9.14 -5.44]
[ -4.88 1.78]
[ -2.33 -3.34]
[ -1.01 -13.08]
[ 3.7 -2.61]
[ -4.87 -8.05]
[ 4.42 -3.76]
[ -8.95 4.44]]
[[ 0.63 15.51]
[-10.13 8.52]
[ 4.33 -6.99]
[-12.94 1.13]
[ -5.7 9.75]
[ -0.16 -2.23]
[ 5.01 7.7 ]
[-14.12 3.43]
[ -5.19 -3.28]
[ -8.21 15.42]]
[[ 0.76 15.39]
[ -9.67 7.59]
[ 2.27 -7.65]
[-14.73 0.99]
[ -5.32 8.3 ]
[ -0.32 -4.31]
[ 4.74 5.57]
[-13.8 3.04]
[ -6.73 -3.21]
[ -8.35 13.35]]
[[13.07 7.96 8.09 14.66 4.99 9.75 4.07 10.92 6.75 11.78]
[11.83 5.49 12.38 3.92 3.42 8.52 4.72 8.85 6.5 12.5 ]
[11.72 5.51 10.73 5.86 3.27 9.61 4.21 8.85 4.91 11.8 ]
[12.68 8. 8.11 12.09 5.49 8.26 4.64 10.6 4.84 12.74]
[15.96 9.63 13.86 2.26 8.13 16.23 6.35 13.01 11.01 9.25]
[15.35 8.98 13.35 2.17 7.52 15.82 6.07 12.37 10.22 9.29]
[11.67 5.77 8.89 15.21 5.67 18.62 9.02 8.86 6.24 9.36]
[12.44 5.82 10.64 5.19 4.07 13.12 4.53 9.41 5.8 9.99]
[15.52 13.24 8.22 12.99 11.29 2.23 9.19 14.53 6.14 17.47]
[15.41 12.29 7.98 14.76 9.86 4.32 7.31 14.13 7.45 15.75]]
80.考虑一个任意数组,编写一个函数,提取具有固定形状并以给定元素为中心的子部分(必要时使用填充值填充)(★★★)
Z = np.random.randint(0,10,(10,10))
shape = (5,5)
fill = 0
position = (1,1)
R = np.ones(shape, dtype=Z.dtype)*fill
P = np.array(list(position)).astype(int)
Rs = np.array(list(R.shape)).astype(int)
Zs = np.array(list(Z.shape)).astype(int)
R_start = np.zeros((len(shape),)).astype(int)
R_stop = np.array(list(shape)).astype(int)
Z_start = (P-Rs//2)
Z_stop = (P+Rs//2)+Rs%2
R_start = (R_start - np.minimum(Z_start,0)).tolist()
Z_start = (np.maximum(Z_start,0)).tolist()
R_stop = np.maximum(R_start, (R_stop - np.maximum(Z_stop-Zs,0))).tolist()
Z_stop = (np.minimum(Z_stop,Zs)).tolist()
r = [slice(start,stop) for start,stop in zip(R_start,R_stop)]
z = [slice(start,stop) for start,stop in zip(Z_start,Z_stop)]
R[r] = Z[z]
print (Z)
print (R)
[[0 8 7 5 7 4 0 1 1 3]
[3 3 7 5 3 4 9 8 6 4]
[2 7 6 6 0 6 9 3 9 3]
[8 5 5 3 3 3 5 1 4 7]
[8 3 8 5 5 8 1 8 6 6]
[4 5 9 0 9 6 3 4 3 3]
[3 8 5 3 6 5 1 5 4 5]
[7 2 2 8 5 4 2 9 4 9]
[4 1 1 6 6 0 5 5 7 0]
[4 2 0 1 5 5 8 9 8 9]]
[[0 0 0 0 0]
[0 0 8 7 5]
[0 3 3 7 5]
[0 2 7 6 6]
[0 8 5 5 3]]
/var/folders/cr/2fpn8__12377w89ml3mv5ksw0000gn/T/ipykernel_90434/2871744890.py:23: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
R[r] = Z[z]
81. 考虑一个数组Z = [1,2,3,4,5,6,7,8,9,10,11,12,13,14],如何生成一个数组R = [[1,2,3,4], [2,3,4,5], [3,4,5,6], …,[11,12,13,14]]? (★★★)
Z=np.arange(1,15,dtype=np.uint32)
print(Z)
R=stride_tricks.as_strided(Z,(len(Z)-3,4),(Z.itemsize,Z.itemsize))
print(R)
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
[[ 1 2 3 4]
[ 2 3 4 5]
[ 3 4 5 6]
[ 4 5 6 7]
[ 5 6 7 8]
[ 6 7 8 9]
[ 7 8 9 10]
[ 8 9 10 11]
[ 9 10 11 12]
[10 11 12 13]
[11 12 13 14]]
82. 计算一个矩阵的秩(★★★)
np.linalg.svd 是 NumPy 中用于计算奇异值分解(SVD)的函数。奇异值分解是矩阵分解的一种形式,将一个矩阵分解为三个矩阵的乘积
语法:
numpy.linalg.svd(a, full_matrices=True, compute_uv=True, hermitian=False)
参数 a:要进行奇异值分解的矩阵。
参数 full_matrices:可选,如果为 True,则返回完整的 U , ∑ , V T U,\sum,V^T U,∑,VT
如果为 False,则返回缩减的形式,其中U和 V T V^T VT的列数等于 a 的秩。
参数 compute_uv:可选,如果为 True,则计算U和 V T V^T VT;如果为 False,则只计算奇异值。
参数 hermitian:可选,如果为 True,表示输入矩阵 a 是 Hermitian 矩阵(共轭对称矩阵)。
返回值:
返回值是一个元组 (U, s, Vh),其中 U 是左奇异矩阵,s 是奇异值的一维数组,Vh 是右奇异矩阵的共轭转置。在 NumPy 中,你可以使用 numpy.linalg.matrix_rank 函数来计算一个矩阵的秩。以下是该函数的语法:
numpy.linalg.matrix_rank(M, tol=None, hermitian=False)
参数 M:要计算秩的输入矩阵。
参数 tol:可选,容忍度。在数值计算中,可能存在小的数值误差。如果提供了容忍度,则小于该容忍度的奇异值将被视为零。
参数 hermitian:可选,如果为 True,则输入矩阵被视为 Hermitian 矩阵(共轭对称矩阵)。
a=np.arange(100).reshape(10,10)
print(a)
u,s,v=np.linalg.svd(a)
rank=np.sum(s>1e-10)
print(rank)
#方法2
a=np.arange(100).reshape(10,10)
print(np.linalg.matrix_rank(a))
[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]
[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]
2
2
83. 如何找到一个数组中出现频率最高的值?
a=np.random.randint(0,10,50)
print(a)
count=np.bincount(a)
print(count[count.argmax()])
[1 7 2 7 7 8 9 2 8 3 4 9 0 5 1 3 3 7 0 9 0 1 4 3 8 0 5 5 1 4 0 6 6 6 7 7 5
5 6 2 1 8 4 0 6 2 9 7 6 2]
7
84. 从一个10x10的矩阵中提取出连续的3x3区块(★★★)
a=np.random.randint(0,10,(10,10))
print(a)
n=3
shape=(a.shape[0]-3+1,a.shape[1]-3+1,n,n)
print(shape)
print(a.strides)
b=stride_tricks.as_strided(a,shape,strides=a.strides+a.strides)
print(b)
[[0 3 7 0 9 7 5 1 5 4]
[1 9 7 6 3 2 5 8 3 0]
[4 7 4 1 9 3 1 1 9 8]
[5 8 2 8 3 8 4 9 5 9]
[0 8 6 2 8 1 8 4 9 5]
[2 9 8 2 0 4 1 8 5 9]
[5 8 8 5 7 3 4 6 8 0]
[5 3 4 7 7 7 3 3 8 5]
[5 9 9 0 1 3 7 1 3 7]
[3 6 7 8 5 7 4 2 0 8]]
(8, 8, 3, 3)
(80, 8)
[[[[0 3 7]
[1 9 7]
[4 7 4]]
[[3 7 0]
[9 7 6]
[7 4 1]]
[[7 0 9]
[7 6 3]
[4 1 9]]
[[0 9 7]
[6 3 2]
[1 9 3]]
[[9 7 5]
[3 2 5]
[9 3 1]]
[[7 5 1]
[2 5 8]
[3 1 1]]
[[5 1 5]
[5 8 3]
[1 1 9]]
[[1 5 4]
[8 3 0]
[1 9 8]]]
[[[1 9 7]
[4 7 4]
[5 8 2]]
[[9 7 6]
[7 4 1]
[8 2 8]]
[[7 6 3]
[4 1 9]
[2 8 3]]
[[6 3 2]
[1 9 3]
[8 3 8]]
[[3 2 5]
[9 3 1]
[3 8 4]]
[[2 5 8]
[3 1 1]
[8 4 9]]
[[5 8 3]
[1 1 9]
[4 9 5]]
[[8 3 0]
[1 9 8]
[9 5 9]]]
[[[4 7 4]
[5 8 2]
[0 8 6]]
[[7 4 1]
[8 2 8]
[8 6 2]]
[[4 1 9]
[2 8 3]
[6 2 8]]
[[1 9 3]
[8 3 8]
[2 8 1]]
[[9 3 1]
[3 8 4]
[8 1 8]]
[[3 1 1]
[8 4 9]
[1 8 4]]
[[1 1 9]
[4 9 5]
[8 4 9]]
[[1 9 8]
[9 5 9]
[4 9 5]]]
[[[5 8 2]
[0 8 6]
[2 9 8]]
[[8 2 8]
[8 6 2]
[9 8 2]]
[[2 8 3]
[6 2 8]
[8 2 0]]
[[8 3 8]
[2 8 1]
[2 0 4]]
[[3 8 4]
[8 1 8]
[0 4 1]]
[[8 4 9]
[1 8 4]
[4 1 8]]
[[4 9 5]
[8 4 9]
[1 8 5]]
[[9 5 9]
[4 9 5]
[8 5 9]]]
[[[0 8 6]
[2 9 8]
[5 8 8]]
[[8 6 2]
[9 8 2]
[8 8 5]]
[[6 2 8]
[8 2 0]
[8 5 7]]
[[2 8 1]
[2 0 4]
[5 7 3]]
[[8 1 8]
[0 4 1]
[7 3 4]]
[[1 8 4]
[4 1 8]
[3 4 6]]
[[8 4 9]
[1 8 5]
[4 6 8]]
[[4 9 5]
[8 5 9]
[6 8 0]]]
[[[2 9 8]
[5 8 8]
[5 3 4]]
[[9 8 2]
[8 8 5]
[3 4 7]]
[[8 2 0]
[8 5 7]
[4 7 7]]
[[2 0 4]
[5 7 3]
[7 7 7]]
[[0 4 1]
[7 3 4]
[7 7 3]]
[[4 1 8]
[3 4 6]
[7 3 3]]
[[1 8 5]
[4 6 8]
[3 3 8]]
[[8 5 9]
[6 8 0]
[3 8 5]]]
[[[5 8 8]
[5 3 4]
[5 9 9]]
[[8 8 5]
[3 4 7]
[9 9 0]]
[[8 5 7]
[4 7 7]
[9 0 1]]
[[5 7 3]
[7 7 7]
[0 1 3]]
[[7 3 4]
[7 7 3]
[1 3 7]]
[[3 4 6]
[7 3 3]
[3 7 1]]
[[4 6 8]
[3 3 8]
[7 1 3]]
[[6 8 0]
[3 8 5]
[1 3 7]]]
[[[5 3 4]
[5 9 9]
[3 6 7]]
[[3 4 7]
[9 9 0]
[6 7 8]]
[[4 7 7]
[9 0 1]
[7 8 5]]
[[7 7 7]
[0 1 3]
[8 5 7]]
[[7 7 3]
[1 3 7]
[5 7 4]]
[[7 3 3]
[3 7 1]
[7 4 2]]
[[3 3 8]
[7 1 3]
[4 2 0]]
[[3 8 5]
[1 3 7]
[2 0 8]]]]
85. 创建一个满足 Z[i,j] == Z[j,i]的子类 (★★★)
class Symetric(np.ndarray):
def __setitem__(self,index,value):
i,j=index
super(Symetric,self).__setitem__((i,j),value)
super(Symetric,self).__setitem__((j,i),value)
def symetric(Z):
# print("1",Z+Z.T)
# print("2",Z+Z.T-np.diag(Z.diagonal()))
return np.asarray(Z+Z.T-np.diag(Z.diagonal())).view(Symetric)
a=np.random.randint(0,10,(5,5))
print(a)
S=symetric(a)
# S[2,3]=42
print(S)
[[1 1 7 7 5]
[4 5 0 8 7]
[7 4 0 9 5]
[3 2 9 1 5]
[4 8 0 1 2]]
[[ 1 5 14 10 9]
[ 5 5 4 10 15]
[14 4 0 18 5]
[10 10 18 1 6]
[ 9 15 5 6 2]]
86. 考虑p个 nxn 矩阵和一组形状为(n,1)的向量,如何直接计算p个矩阵的乘积(n,1)?(★★★)
numpy.tensordot 函数用于计算张量的张量积。张量积是一种在多维数组之间执行的操作,它可以看作是数组的乘法的一般化形式。numpy.tensordot 函数的语法如下:
numpy.tensordot(a, b, axes=2)
其中,a 和 b 是要计算张量积的输入数组,axes 参数是指定求和的轴的参数。
具体来说,numpy.tensordot 的作用是将两个张量进行张量积运算。这个过程可以用以下步骤来理解:
指定张量积的轴(axes)。
在指定的轴上,将两个张量相乘。
对相乘的结果进行求和,得到最终的输出张量。
这个函数的用途非常广泛,特别是在线性代数和深度学习等领域。通过调整 axes 参数,可以灵活地控制张量积的计算方式。在一些复杂的张量运算中,numpy.tensordot 可以帮助简化代码并提高执行效率。
p,n=2,3
M=np.ones((p,n,n))
print(M)
V=np.ones((p,n,1))
print(V)
s=np.tensordot(M,V,axes=[[0,2],[0,1]])
print(s)
[[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]]
[[[1.]
[1.]
[1.]]
[[1.]
[1.]
[1.]]]
[[6.]
[6.]
[6.]]
87. 对于一个16x16的数组,如何得到一个区域(block-sum)的和(区域大小为4x4)? (★★★)
np.add.reduceat 函数是 NumPy 中用于执行分段求和(segmented reduction)的函数。这个函数提供了一种对数组的指定片段进行求和的方式。它的语法如下:
numpy.add.reduceat(a, indices, axis=None)
其中:
a 是输入的数组。
indices 是一个整数数组,指定了在哪些位置进行分段求和。
axis 是指定沿着哪个轴进行操作的参数(可选,默认为 None,表示对整个数组进行操作)。
np.add.reduceat 返回一个与输入数组形状相同的数组,包含了分段求和的结果。
a=np.random.randint(0,5,(16,16))
k=4
print(a)
s1=np.add.reduceat(a,np.arange(0,a.shape[0],k),axis=0)
print(s)
s2=np.add.reduceat(s,np.arange(0,s1.shape[1],k),axis=1)
print(s2)
[[0 4 1 3 1 3 0 0 1 2 3 1 4 2 2 0]
[3 4 3 4 3 3 1 3 1 0 1 2 4 1 1 3]
[3 2 2 3 3 1 3 0 3 4 1 1 4 1 3 2]
[4 0 2 2 1 3 0 4 1 3 4 1 1 0 2 1]
[1 0 1 1 0 2 3 1 2 2 0 3 1 2 1 3]
[3 3 4 4 0 0 0 3 4 1 1 4 3 2 1 4]
[0 2 3 1 1 3 2 0 4 0 0 3 3 2 1 4]
[0 3 3 0 1 0 4 0 0 1 1 4 1 0 0 1]
[3 0 4 2 2 4 3 2 4 1 3 4 1 2 4 3]
[3 2 1 2 0 0 4 1 2 1 3 2 4 0 1 1]
[1 3 3 0 2 1 0 1 4 2 1 4 2 3 1 0]
[1 2 3 0 3 4 4 0 1 3 3 2 4 1 3 2]
[1 3 1 4 1 0 0 0 0 4 0 4 0 2 0 4]
[4 1 4 0 1 2 0 0 2 3 0 1 0 2 2 0]
[4 4 3 3 1 3 1 4 4 2 2 2 4 3 0 0]
[3 1 4 4 3 0 1 1 3 3 1 0 4 3 2 2]]
[[ 8 10 3 13 4 12 12 9 4 8 13 7 11 11 9 7]
[11 12 10 1 2 2 9 6 6 4 8 6 7 11 10 6]
[ 8 7 11 7 12 9 3 8 7 9 7 8 8 3 6 15]
[ 7 10 12 10 15 9 9 11 6 8 11 12 11 4 8 5]]
[[34 37 32 38]
[34 19 24 34]
[33 32 31 32]
[39 44 37 28]]
88. 如何利用numpy数组实现Game of Life? (★★★)
生命的游戏,也被简称为生命,是英国数学家John Horton Conway于1970年设计的一种元胞自动机。[1]它是一个零玩家游戏,[2][3]意味着它的进化是由其初始状态决定的,不需要进一步的输入。一个人通过创建初始配置并观察其如何演变来与生命游戏互动。它是图灵完备的,可以模拟通用构造函数或任何其他图灵机。
生命游戏的宇宙是一个由正方形细胞组成的无限二维正交网格,每个细胞都处于两种可能的状态之一,活的或死的(或有人居住和无人居住)。每个细胞与其八个相邻细胞相互作用,即水平、垂直或对角相邻的细胞。在时间的每一步,都会发生以下转变:
- 任何相邻活细胞少于两个的活细胞都会死亡,就好像是由于人口不足。
- 任何有两个或三个活邻居的活细胞都会存活到下一代。
- 任何有三个以上邻居的活细胞都会死亡,就好像是由于人口过多。
- 任何一个只有三个活邻居的死细胞都会变成活细胞,就像是通过繁殖一样。
最初的模式构成了系统的种子。第一代是通过将上述规则同时应用于种子中的每个细胞而产生的,无论是活的还是死的;出生和死亡同时发生,这种情况发生的离散时刻有时被称为滴答声。每一代都是前一代的纯函数。这些规则将继续重复应用,以创建下一代。
def iterate(Z):
# Count neighbours
N = (Z[0:-2,0:-2] + Z[0:-2,1:-1] + Z[0:-2,2:] +
Z[1:-1,0:-2] + Z[1:-1,2:] +
Z[2: ,0:-2] + Z[2: ,1:-1] + Z[2: ,2:])
# Apply rules
birth = (N==3) & (Z[1:-1,1:-1]==0)
survive = ((N==2) | (N==3)) & (Z[1:-1,1:-1]==1)
Z[...] = 0
Z[1:-1,1:-1][birth | survive] = 1
return Z
Z = np.random.randint(0,2,(10,10))
print(Z)
for i in range(100): Z = iterate(Z)
print (Z)
[[0 1 0 0 0 0 0 1 0 1]
[0 0 0 1 1 0 1 1 1 0]
[1 0 0 1 0 0 0 1 0 1]
[1 0 0 0 0 1 0 1 1 0]
[0 1 0 1 1 1 1 0 1 0]
[0 0 1 0 1 1 1 0 0 0]
[1 0 0 1 1 1 0 0 0 0]
[1 1 1 0 0 1 1 0 1 0]
[0 0 1 0 1 0 0 0 0 0]
[0 1 0 1 1 0 1 0 1 0]]
[[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]]
89. 如何找到一个数组的第n个最大值? (★★★)
np.argsort 函数是 NumPy 中用于返回数组排序后元素的索引的函数。它返回的是原数组中元素按升序排序后的索引数组。具体来说,np.argsort 的语法是:
numpy.argsort(a, axis=-1, kind='quicksort', order=None)
其中:
a 是要排序的数组。
axis 是沿着哪个轴进行排序的参数(默认为最后一个轴)。
kind 是排序算法的选择参数,可以是 ‘quicksort’、‘mergesort’ 或 ‘heapsort’ 中的一个(默认为 ‘quicksort’)。
order 是指定排序时要使用的字段的参数(如果数组是结构化数组)。
np.argpartition 函数是 NumPy 中用于返回数组局部排序后元素的索引的函数。它在排序的过程中并不会对整个数组进行排序,而是在每个元素的正确位置之前,将它们放置在合适的位置。这样,我们就可以获取局部最小值或局部最大值的索引而无需对整个数组进行排序。
具体来说,np.argpartition 的语法如下:
numpy.argpartition(a, kth, axis=-1, kind='introselect', order=None)
其中:
a 是要进行局部排序的数组。
kth 是要选择的排序位置或选择的元素个数。
axis 是沿着哪个轴进行排序的参数(默认为最后一个轴)。
kind 是排序算法的选择参数,可以是 ‘introselect’ 或 ‘heapsort’ 中的一个(默认为 ‘introselect’)。
order 是指定排序时要使用的字段的参数(如果数组是结构化数组)。np.argpartition 的实际应用场景包括在大数据集中查找最小或最大的 k 个元素的索引,而无需对整个数据集进行完全排序。
a=np.arange(1000000)
np.random.shuffle(a)
n=5
#方法1 速度较慢
print(a[np.argsort(a)[-n]])
999995
a=np.arange(1000000)
np.random.shuffle(a)
n=5
#方法2 速度较快 第n-1位,为第n小或
print(a[np.argpartition(-a,n-1)[n-1]])
999995
90. 给定任意个数向量,创建笛卡尔积(每一个元素的每一种组合)(★★★)
np.indices 函数是 NumPy 中用于生成多维索引数组的函数。具体来说,np.indices 用于创建一个数组,其中包含了所有可能的索引值。这在一些需要生成多维网格或用索引进行矩阵操作时非常有用。
np.indices 的语法如下:
numpy.indices(dimensions, dtype=<class 'int'>)
其中:
dimensions 是一个表示生成的索引数组的形状的元组。
dtype 是生成的索引数组的数据类型(默认为整数类型)。
def cartesian(arrays):
arrays = [np.asarray(a) for a in arrays]
shape = (len(x) for x in arrays)
ix = np.indices(shape, dtype=int)
print(ix.shape)
ix = ix.reshape(len(arrays), -1).T
print(ix)
for n, arr in enumerate(arrays):
ix[:, n] = arrays[n][ix[:, n]]
return ix
print(cartesian(([1, 2, 3], [4, 5], [6, 7])))
(3, 3, 2, 2)
[[0 0 0]
[0 0 1]
[0 1 0]
[0 1 1]
[1 0 0]
[1 0 1]
[1 1 0]
[1 1 1]
[2 0 0]
[2 0 1]
[2 1 0]
[2 1 1]]
[[1 4 6]
[1 4 7]
[1 5 6]
[1 5 7]
[2 4 6]
[2 4 7]
[2 5 6]
[2 5 7]
[3 4 6]
[3 4 7]
[3 5 6]
[3 5 7]]
91. 如何从一个正常数组创建记录数组(record array)? (★★★)
np.core.records.fromarrays 函数用于创建结构化数组(structured array)或记录数组(record array)。
结构化数组是一种 NumPy 数组,其中每个元素可以包含不同的数据类型,并且每个元素的字段(field)都有一个名称和相应的数据类型。结构化数组在处理表格形式的数据时非常有用,类似于数据库中的表格.
np.core.records.fromarrays 的语法如下:
numpy.core.records.fromarrays(arrayList, dtype=None, shape=None, formats=None, names=None, titles=None, aligned=False, byteorder=None)
其中参数的含义如下:
arrayList:包含了输入数组的列表。
dtype:结构化数组的数据类型。如果未提供,将根据输入数组自动推断。
shape:结构化数组的形状。如果未提供,将根据输入数组自动推断。
formats:指定每个字段的数据类型的字符串列表。
names:指定每个字段的名称的字符串列表。
titles:用于指定字段的标题的字符串列表。
aligned:是否对齐结构化数组的字段。
byteorder:指定字节顺序的字符串。
a=np.array([("Hello",2.5,3),("World",3.6,2)])
r=np.core.records.fromarrays(a.T,names='col1,col2,col3',formats='S8,f8,i8')
print(r)
[(b'Hello', 2.5, 3) (b'World', 3.6, 2)]
92. 考虑一个大向量Z, 用三种不同的方法计算它的立方(★★★)
x = np.arange(9).reshape(3,3)
print(x)
print("方法1:",np.power(x,3))
print("方法2:",x*x*x)
print("方法3:",np.einsum('ij,ij,ij->ij',x,x,x))
[[0 1 2]
[3 4 5]
[6 7 8]]
方法1: [[ 0 1 8]
[ 27 64 125]
[216 343 512]]
方法2: [[ 0 1 8]
[ 27 64 125]
[216 343 512]]
方法3: [[ 0 1 8]
[ 27 64 125]
[216 343 512]]
93. 考虑两个形状分别为(8,3) 和(2,2)的数组A和B. 如何在数组A中找到满足包含B中元素的行?(不考虑B中每行元素顺序)? (★★★)
a=np.random.randint(0,5,(8,3))
print("a",a)
b=np.random.randint(0,5,(2,2))
print("b",b)
#生成8*3*1*1维度的数据,便于进行广播运算
c=(a[...,np.newaxis,np.newaxis]==b)
#即判断每个元素是否存在于b中
print(c.shape)
print("c",c)
print(np.where(c.any((3,1))))
row=np.where(c.any((3,1)).all(1))[0]
print(row)
a [[0 3 2]
[0 4 4]
[2 2 3]
[0 1 3]
[4 4 1]
[1 2 2]
[4 1 0]
[4 2 4]]
b [[0 0]
[4 1]]
(8, 3, 2, 2)
c [[[[ True True]
[False False]]
[[False False]
[False False]]
[[False False]
[False False]]]
[[[ True True]
[False False]]
[[False False]
[ True False]]
[[False False]
[ True False]]]
[[[False False]
[False False]]
[[False False]
[False False]]
[[False False]
[False False]]]
[[[ True True]
[False False]]
[[False False]
[False True]]
[[False False]
[False False]]]
[[[False False]
[ True False]]
[[False False]
[ True False]]
[[False False]
[False True]]]
[[[False False]
[False True]]
[[False False]
[False False]]
[[False False]
[False False]]]
[[[False False]
[ True False]]
[[False False]
[False True]]
[[ True True]
[False False]]]
[[[False False]
[ True False]]
[[False False]
[False False]]
[[False False]
[ True False]]]]
(array([0, 1, 1, 3, 3, 4, 5, 6, 6, 7]), array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1]))
[1 3 6]
94. 考虑一个10x3的矩阵,分解出有不全相同值的行 (如 [2,2,3]) (★★★)
Z = np.random.randint(0,5,(10,3))
print (Z)
#比较每行的元素是否都相同
E = np.all(Z[:,1:] == Z[:,:-1], axis=1)
print(E)
#抽取每行元素不相同,若行元素相同则省略
U = Z[~E]
print (U)
#方法2
U = Z[Z.max(axis=1) != Z.min(axis=1),:]
print (U)
[[2 1 3]
[2 0 0]
[1 0 2]
[1 3 1]
[4 1 1]
[4 4 1]
[0 1 0]
[4 2 3]
[0 4 2]
[3 2 3]]
[False False False False False False False False False False]
[[2 1 3]
[2 0 0]
[1 0 2]
[1 3 1]
[4 1 1]
[4 4 1]
[0 1 0]
[4 2 3]
[0 4 2]
[3 2 3]]
[[2 1 3]
[2 0 0]
[1 0 2]
[1 3 1]
[4 1 1]
[4 4 1]
[0 1 0]
[4 2 3]
[0 4 2]
[3 2 3]]
95. 将一个整数向量转换为matrix binary的表现形式 (★★★)
np.unpackbits 函数用于将整数数组中的每个整数解压为对应的二进制表示形式。它将整数的二进制表示拆分为每一位,返回一个包含二进制位的数组。
以下是 np.unpackbits 函数的基本语法:
numpy.unpackbits(array, axis=None)
array:输入的整数数组。
axis:指定在哪个轴上进行解压。默认为 None,表示在扁平化的数组上解压。
I = np.array([0, 1, 2, 3, 15, 16, 32, 64, 128],dtype=np.uint8)
B = ((I.reshape(-1,1) & (2**np.arange(8))) != 0).astype(int)
print(B[:,::-1])
print(np.unpackbits(I[:,np.newaxis],axis=1))
[[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 1]
[0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 1 1]
[0 0 0 0 1 1 1 1]
[0 0 0 1 0 0 0 0]
[0 0 1 0 0 0 0 0]
[0 1 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]]
[[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 1]
[0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 1 1]
[0 0 0 0 1 1 1 1]
[0 0 0 1 0 0 0 0]
[0 0 1 0 0 0 0 0]
[0 1 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]]
96. 给定一个二维数组,如何提取出唯一的(unique)行?(★★★)
np.ascontiguousarray 函数的作用是返回一个在内存中是连续存储的(即是"按行"连续存储的)数组的副本。如果输入数组本身已经是连续存储的,那么该函数会返回原始数组的视图(view)而不创建副本。
语法如下:
numpy.ascontiguousarray(a, dtype=None)
a:输入数组。
dtype:可选参数,指定返回数组的数据类型。如果不指定,将使用输入数组的数据类型。
这个函数通常在需要保证数组是连续存储的情况下使用,因为一些 NumPy 函数对于连续存储的数组有更好的性能。
a=np.random.randint(0,2,(6,3))
print(a)
t=np.ascontiguousarray(a).view(np.dtype(np.void,a.dtype.itemsize*a.shape[1]))
_,idx=np.unique(t,return_index=True)
ua=a[idx]
print(ua)
[[0 0 1]
[1 0 0]
[1 0 0]
[0 1 1]
[1 1 1]
[1 0 1]]
[[0 0 1]
[1 0 0]]
97. 考虑两个向量A和B,写出用einsum等式对应的inner, outer, sum, mul函数(★★★)
A = np.arange(0,5)
print(A)
B = np.arange(0,5)
print ('sum')
print (np.einsum('i->', A))# np.sum(A)
[0 1 2 3 4]
sum
10
print(A*B)
print(np.einsum('i,i->i',A,B))
[ 0 1 4 9 16]
[ 0 1 4 9 16]
print ('inner')
print(np.inner(A,B))
print (np.einsum('i,i', A, B)) # np.inner(A, B)
inner
30
30
print ('outer')
print(np.outer(A,B))
print (np.einsum('i,j->ij', A, B)) # np.outer(A, B)
outer
[[ 0 0 0 0 0]
[ 0 1 2 3 4]
[ 0 2 4 6 8]
[ 0 3 6 9 12]
[ 0 4 8 12 16]]
[[ 0 0 0 0 0]
[ 0 1 2 3 4]
[ 0 2 4 6 8]
[ 0 3 6 9 12]
[ 0 4 8 12 16]]
98. 考虑一个由两个向量描述的路径(X,Y),如何用等距样例(equidistant samples)对其进行采样(sample)? (★★★)
np.interp 函数用于一维线性插值。它在两个点之间进行线性插值,计算在给定点上的插值值。该函数的基本语法如下:
numpy.interp(x, xp, fp, left=None, right=None, period=None)
x:要插值的点的横坐标数组。
xp:已知数据点的横坐标数组。
fp:已知数据点的纵坐标数组。
left(可选):对于 x 小于 xp 中的最小值时的插值方式。
right(可选):对于 x 大于 xp 中的最大值时的插值方式。
period(可选):如果给定,表示数据是周期性的,可以指定一个周期,用于处理超出 xp 范围的插值。
#创建角度数组,范围0-10pi
phi=np.arange(0,10*np.pi,0.1)
#设置参数a的值为1
a=1
#计算每个角度对应的x和y坐标
x=a*phi*np.cos(phi)
y=a*phi*np.sin(phi)
#计算路径上相邻点的线段长度
dr=((np.diff(x)**2+np.diff(y)**2)**.5)
#创建一个与x相同形状的数组,用于存储累积路径长度
r=np.zeros_like(x)
#通过累积线段长度,计算路径每个点对应的累积路径长度
r[1:]=np.cumsum(dr)
#创建等间隔路径长度并进行插值
r_int=np.linspace(0,r.max(),200)
x_int=np.interp(r_int,r,x)
y_int=np.interp(r_int,r,y)
plt.plot(x, y, 'o', label='alredy know')
plt.plot(x_int, y_int, 'x-', label='after insert')
plt.legend()
plt.show()

99.给定整数n和2D阵列X,从X中选择可被解释为从具有n次的多项式分布中提取的行,即,仅包含整数且总和为n的行。
np.logical_and.reduce 函数是 NumPy 中用于逻辑 AND 操作的函数,它对给定的布尔数组进行逐元素的逻辑 AND 操作,并返回一个单一的布尔值。
numpy.logical_and.reduce(array, axis=None, dtype=None, keepdims=False, out=None).
array:输入的布尔数组。
axis:可选参数,指定沿着哪个轴进行逻辑 AND 操作。默认是对整个数组进行操作。
dtype:可选参数,指定输出数组的数据类型。
keepdims:可选参数,如果为 True,保持输出数组的维度;如果为 False,结果数组的维度将被压缩。
out:可选参数,用于指定输出数组的位置,如果指定,结果将被写入该数组。
np.mod 函数是 NumPy 中用于计算取模运算(求余数)的函数。它对数组中的元素进行逐元素的取模运算,并返回结果数组。np.mod 函数的基本语法如下:
numpy.mod(x1, x2, out=None, where=True, casting='same_kind', order='K', dtype=None, subok=True[, signature, extobj])
x1:除数数组。
x2:被除数数组。
out:可选参数,指定结果存储的位置。
where:可选参数,用于指定计算条件。
casting:可选参数,指定类型转换规则。
order:可选参数,指定数组在内存中的存储顺序。
dtype:可选参数,指定输出数组的数据类型。
subok:可选参数,如果为 True,则子类将被传递;如果为 False,则返回基类数组。
X = np.asarray([[1.0,0.0,3.0,8.0],[2.0,0.0,1.0,1.0],[1.5,2.5,1.0,0.0]])
print(X.shape)
n=4
M=np.logical_and.reduce(np.mod(X,1)==0,axis=-1)
M&=(X.sum(axis=-1)==n)
print(X[M])
(3, 4)
[[2. 0. 1. 1.]]
100. 对于一个一维数组X,计算它boostrapped之后的95%置信区间的平均值。
np.percentile 函数是 NumPy 中用于计算百分位数的函数。它对给定的数据进行百分位数的计算,并返回指定百分位数的值。百分位数表示在一组数据中某个百分比的位置,例如,中位数是50%百分位数。
numpy.percentile(a, q, axis=None, out=None, overwrite_input=False, interpolation='linear', keepdims=False)
a:输入的数组。
q:要计算的百分位数,可以是一个百分比或一组百分位数。
axis:可选参数,指定在哪个轴上进行计算。默认是对整个数组进行计算。
out:可选参数,指定输出数组的位置。
overwrite_input:可选参数,如果为 True,则允许在计算过程中覆盖输入数组。默认为 False。
interpolation:可选参数,指定在计算过程中的插值方式,默认是 ‘linear’。
keepdims:可选参数,如果为 True,保持输出数组的维度;如果为 False,结果数组的维度将被压缩。
#生成标准正态分布的一维数组
X = np.random.randn(100)
N = 1000 #采样次数
print(X.size)
#对 X 进行 bootstrap 采样,生成 N 个样本,每个样本的大小与原始数据 X 相同。idx 是一个包含采样索引的二维数组。
idx = np.random.randint(0, X.size, (N, X.size))
print(idx)
means = X[idx].mean(axis=1)
#计算 bootstrap 样本均值的置信区间,即计算均值的2.5%和97.5%百分位数。这个置信区间用于估计样本均值的不确定性范围。
confint = np.percentile(means, [2.5, 97.5])
print (confint)
100
[[70 17 15 ... 36 73 98]
[78 39 48 ... 49 11 80]
[85 76 3 ... 18 94 42]
...
[80 5 55 ... 93 4 98]
[54 45 17 ... 58 8 45]
[55 34 33 ... 88 22 34]]
[-0.03454481 0.35980388]