中国图象图形学学会青年科学家会议是由中国图象图形学学会青年工作委员会发起的学术会议。本会议面向国际学术前沿与国家战略需求,致力于支持图象图形领域的优秀青年学者,为青年学者们提供学术交流与研讨的平台,促进学者之间的交流与合作。会议同时邀请工业应用部门与学会青年学者做深入交流,鼓励图象图形领域的“产学研”合作,会议中合合信息的丁凯博士为大家带来了 《文档图像大模型的思考与探索》 的分享。让我们一起走进合合信息丁凯博士的演讲,看看大模型技术的加持下,智能文档处理领域有哪些方面的进展与突破。下文内容为根据丁凯博士的分享总结而来。
文章目录
- GPT4-V在IDP领域的表现
- GPT4-V 优缺点
- 像素级OCR统一模型
- OCR大一统模型
- 文档识别分析+LLM应用
- GPT4-V的出现是挑战?机遇?
- 写在最后+福利
GPT4-V在IDP领域的表现

针对GPT4-V在IDP领域的表现,上述文章来源于微软对GPT4-V的测评报告。从报告中我们可以得知,在场景文字识别方面,GPT4-V在多种场景、语言形态和语言种类上都取得了良好的结果。同时,对于手写草稿、几何图形和文字结合的教育场景,以及公式理解等方面,GPT4-V也表现出色。相较于以往需要多个模型协同工作并在特殊场景下进行定制,GPT4-V在这些方面的表现令人印象深刻。

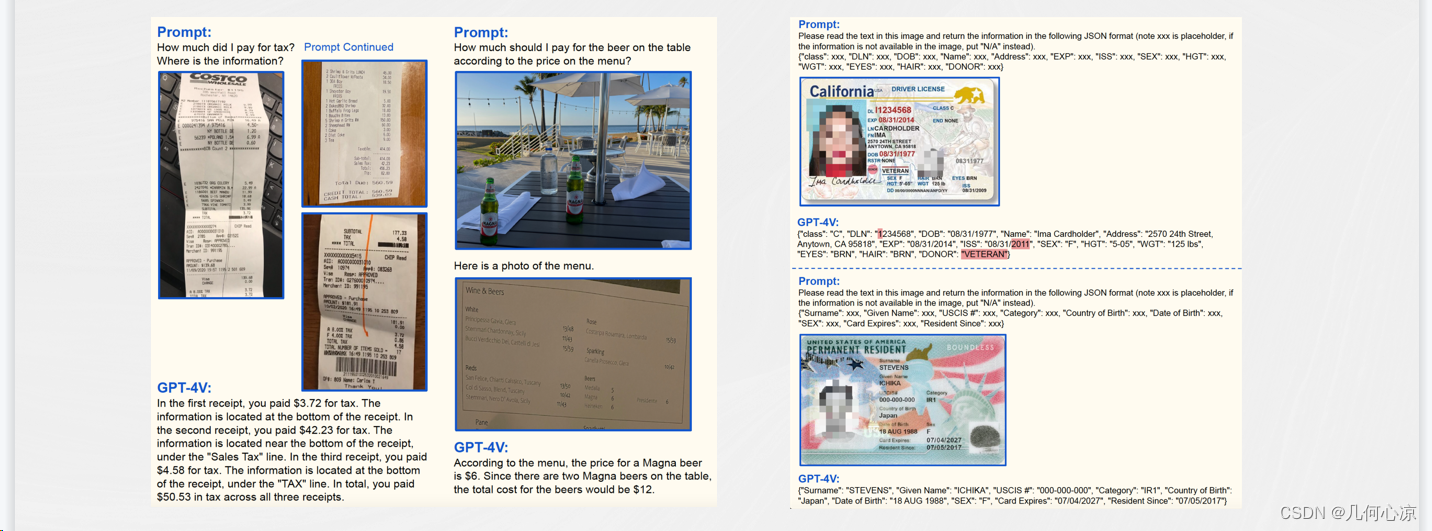
进一步观察GPT4-V在表格和信息抽取层面的表现,我们可以从两张图中看到,在这些方面GPT4-V的识别和信息抽取效果也相当不错。它不仅能够从证件等简单版式中抽取关键信息,还能处理复杂版式、多图像和自然场景结合的情况,展现了强大的抽取和推理能力。以一张包含啤酒价格推断的账单为例,GPT4-V能够分析自然场景中的啤酒,然后结合账单中的信息计算出价格。
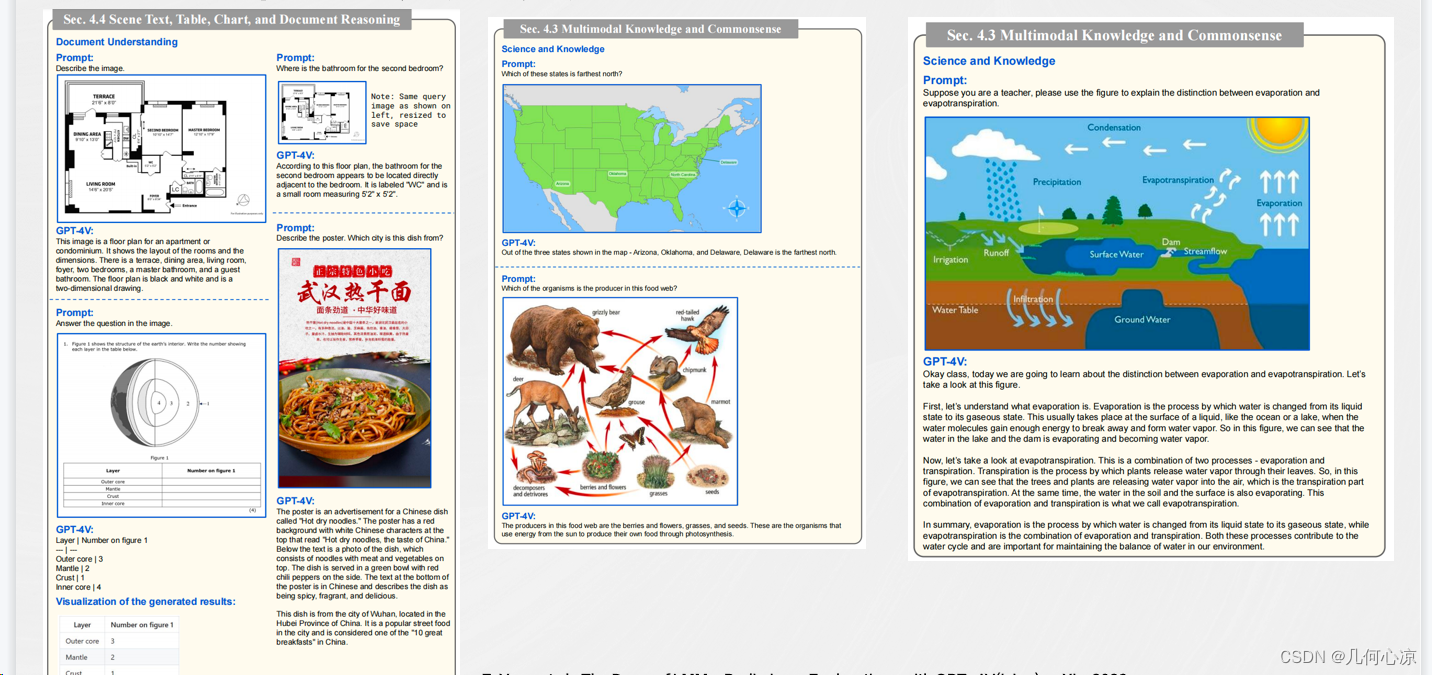
此外,GPT4-V在文档领域也有出色表现,尤其在流程图、曲线图、表格等图标的识别和理解方面展现出潜力。对于建筑设计图、生物、地理和物理等文档,GPT4-V也能够进行良好的识别和推理。相对于传统方法,特别是在泛化能力方面,GPT4-V展现出更高的水平。针对这些我们现有的一些IDP的识别、分析、理解的算法都是非常大的挑战;
上面我们详细介绍了GPT4-V在IDP领域的诸多优势和强大之处,那么有了GPT4-V后,是否能够完全解决OCR的所有问题呢?通过深入分析,我们发现GPT4-V仍然存在一些问题。首先,对于中文,无论是手写还是印刷体,GPT4-V存在严重的幻觉问题;经常会输出一些在文章中本不存在的内容,特别是在处理一些简单手写公式时,GPT4-V的效果也并不理想,常常出现错误。
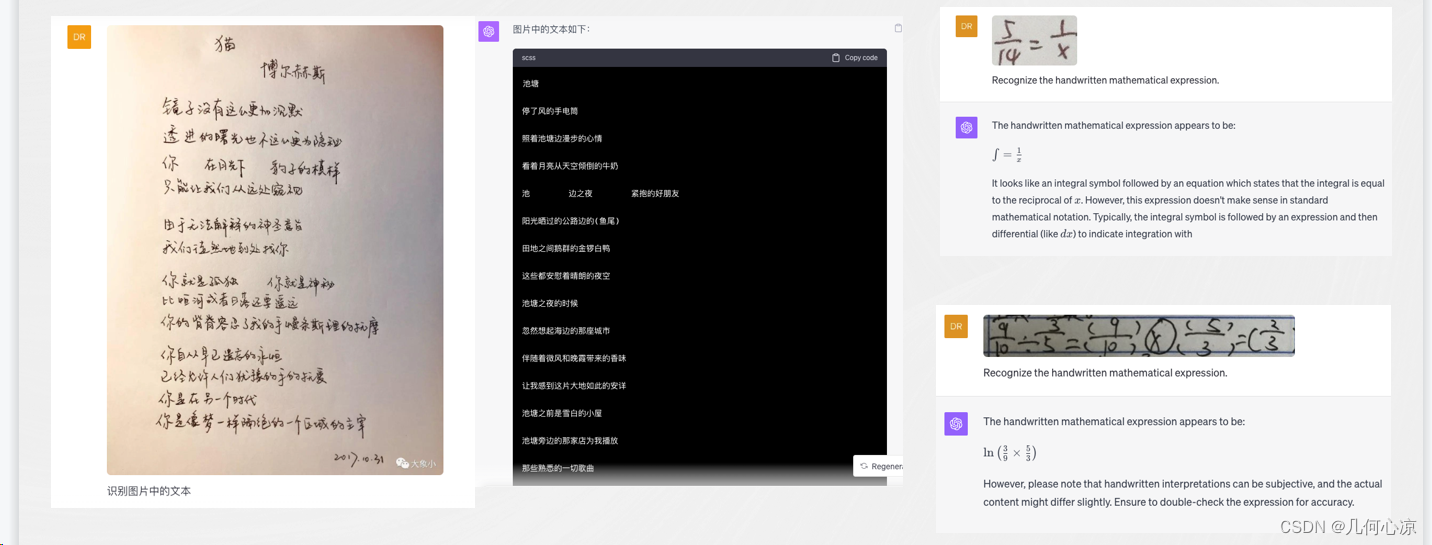
我们在前文提到了GPT4-V的优点和不足之处。为了更清晰地了解这样多模态大模型在OCR和IDP领域的表现,我们可以通过下面的量化图来将GPT4-V在OCR领域与我们的SOTA进行对比。从对比结果可以看出,除了手写英文外,GPT4-V在场景文字识别、多语言识别、手写公式识别等其他OCR领域与SOTA相比,存在明显差距。我们可以参考右下角的Table6,这是一个手写识别场景的对比,GPT4-V在手写公式识别方面的准确率仅有百分之10几,基本可以说不够实用,而传统的SOTA在这方面可以达到60-70的水平。从这一点可以看出,GPT4-V在我们的领域中仍然与SOTA水平存在差距。

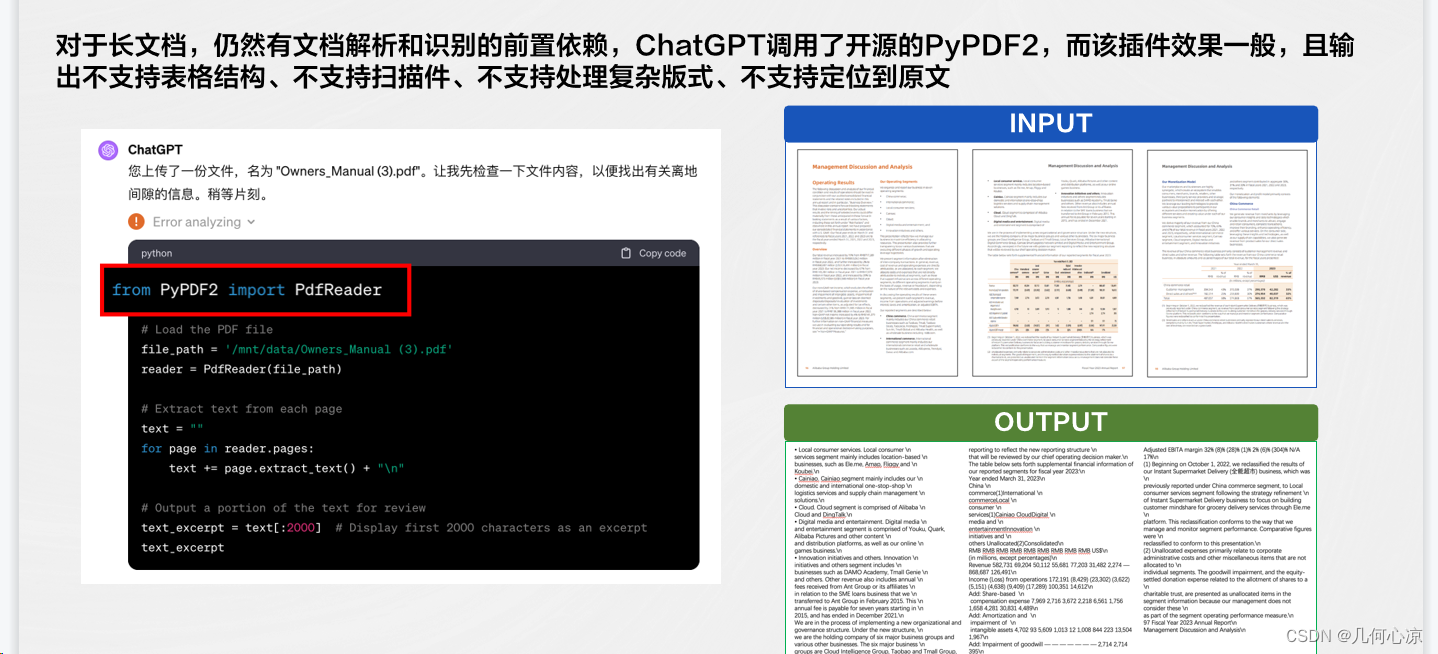
同时,可能有一个相对较少被关注的问题,那就是对于特别长的文档,虽然GPT4-V能够进行OCR文档识别,但当处理例如将200多页PDF扫描给GPT4-V用于学习和问答理解时,让它将每张图片都识别为文档,这可能超出了大模型的处理范畴。因此,对于长文档,无论是GPT4-V还是chatGPT,都依赖于前置的文档解析和文档识别。文档不仅仅是文字串,它具有结构和版式。即便是对于电子版的PDF解析而言,仍然是一个尚未解决的相当困难的问题。
在下面的图片中,我们可以看到chatGPT实际上利用了一个开源插件,但是在处理相对复杂版式时,其解析结构变得非常差。因此,如果文档解析效果较差,那么后续大模型理解文档的效果就不会太好。
GPT4-V 优缺点
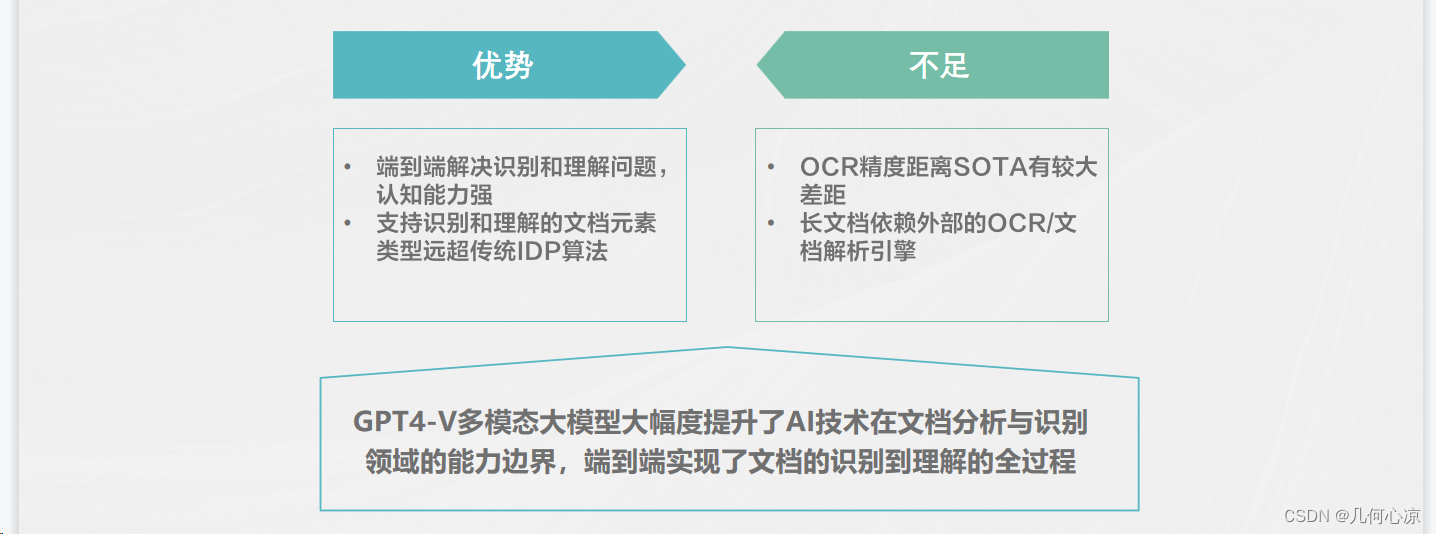
我们将上面的问题总结下:
优势:
GPT4-V的独特之处在于它实现了对文档的端到端识别和理解,与传统方法先感知再理解的流程不同。它在理解和认知方面展现出强大的能力,借助大型语言模型的支持,同时支持对文档元素的识别和理解。除了传统的文字、表格、公式等识别理解外,GPT4-V在处理流程图、图表、建筑物理化学图文等方面的识别能力超越了传统的IDP算法。
不足:
然而,GPT4-V仍存在一些不足之处。首先,其当前的OCR精度与SOTA水平相比仍存在较大差距。其次,它对于长文档的解析依赖于外部文档解析引擎,外部解析性能会影响整体性能。总体而言,GPT4-V多模态大模型显著提升了AI技术在在线文档分析与识别领域的能力,解决了以前难以处理或无法处理的问题。同时,GPT4-V和chatGPT为我们提供了一种新的范式,即大数据、大算力、多任务、端到端。
通过上述分析,我们回顾了文档分析识别的主题,发现GPT4-V在像篡改监测、文本分割擦除等像素级任务方面处理并不理想,也未能达到SOTA水平的性能。然而,GPT4-V的强项在于信息抽取和理解认知层面,为该领域提供了显著的提升。
GPT4-V虽然没有明确执行版面还原,但在文档识别和理解过程中进行了内部相应的工作。基于以上现状的分析,我们可以延伸到以下几个问题:
-
GPT4-V难以处理像素级的OCR任务,如篡改监测、文本分割、文本擦除等。这与传统模型采用一个模型解决一个问题的方式有所不同。大模型给我们的范式是能否创建一个多任务的模型来统一解决OCR任务,通过更大的数据和算力,使整体效果优于传统方法。
-
GPT4-V具有更强的泛化能力,支持更多文档种类,但精度不足。在这一点上,是否能够在OCR领域创建一个大一统模型,将GPT4-V的泛化能力和传统方法的精度结合起来,通过更大的数据训练和更大的算力,使其在精度上超过SOTA水平,同时拓展泛化能力,成为OCR领域的奇迹。
-
考虑应用层面,对于长文档,大模型依赖于前置的文档识别分析引擎。如何更好地将识别分析引擎与大语言模型结合,以解决领域内的问题。

基于上面的三个问题来看下合合信息-华南理工大学文档图像分析识别与理解联合实验室所作的一些工作:
像素级OCR统一模型
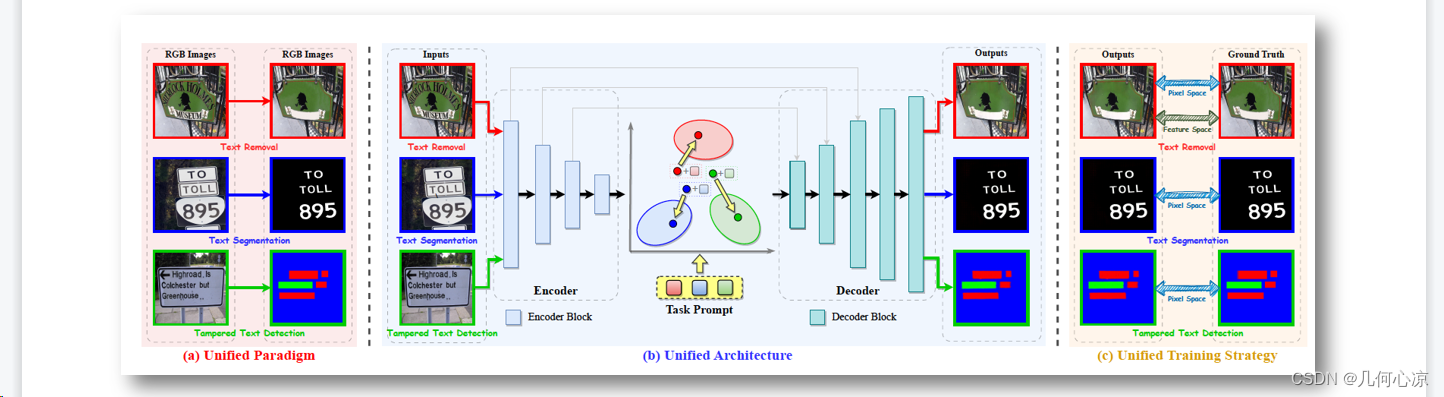
UPOCR实际上是一个像素级通用模型,通过统一文本擦除、文本分割和篡改文本监测等像素级OCR任务的任务范式、架构和训练策略。
通过引入科学系的任务示例来指导基于Vit的编码器和解释器架构,从效果上看,它优于现有专业性模型。整个模型的主干网络是VITEraser,然后我们结合文本擦除、文本分割和篡改监测等三个任务提示词进行统一训练。训练完成后,该模型可以直接用于下游任务,无需专门的精细调整。
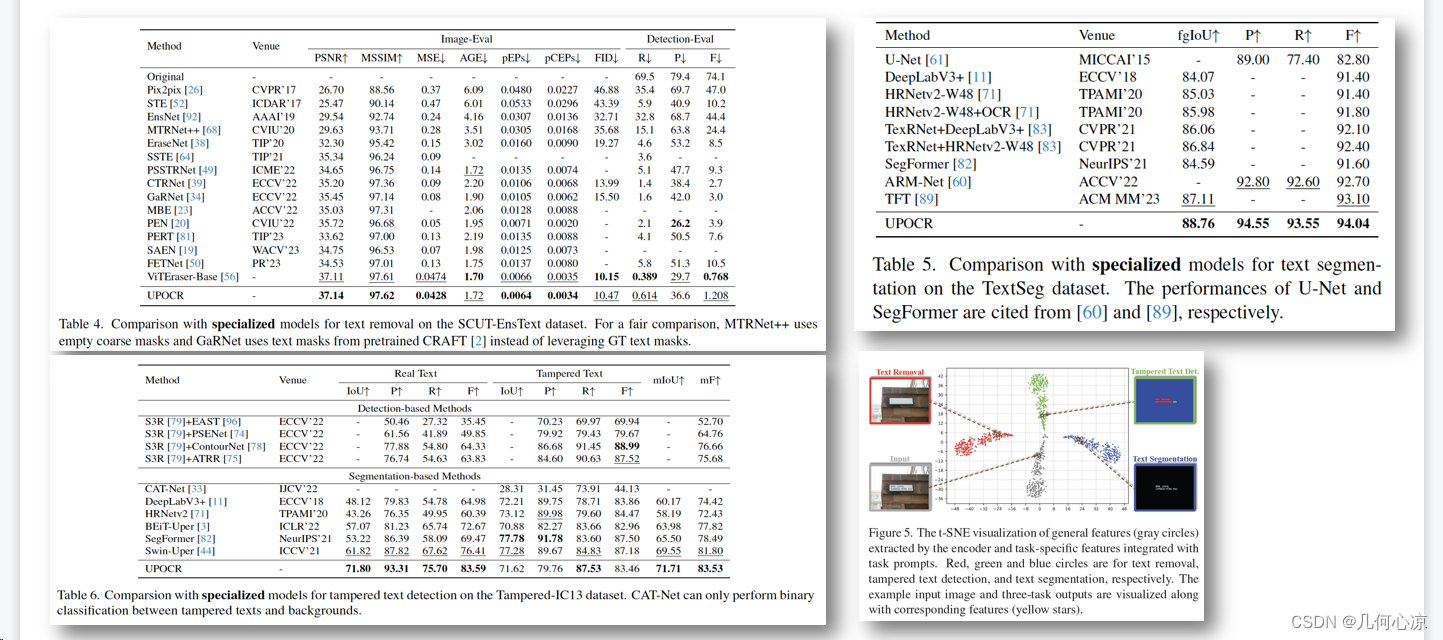
在实验结果中,左上角展示了文本擦除的实验,实验室的方法在文本擦除的绝大部分指标上优于SOTA水平。右上角是文本分割任务的数据,我们的各项指标也优于SOTA水平。在篡改监测方面,我们的大部分指标接近或超过SOTA模型的专业效果。通过右下角的可视化图,更清晰地展示了通过提示词将不同任务分割开来的效果。
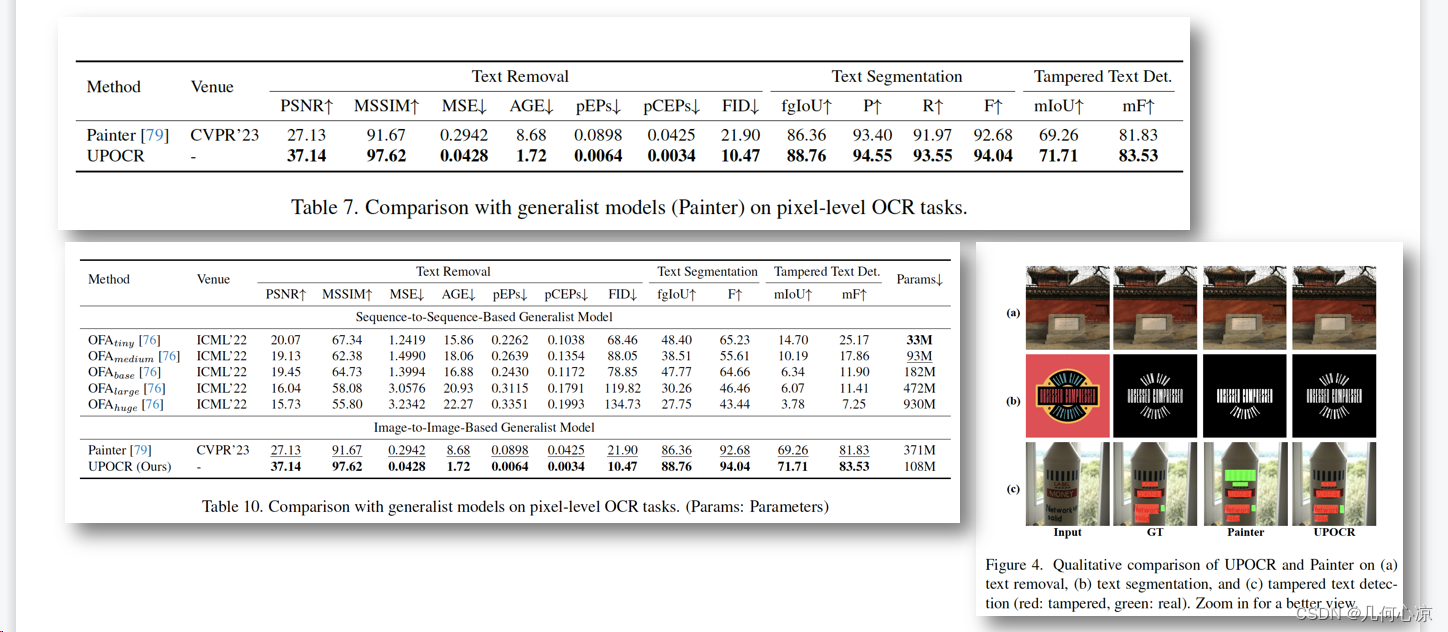
OCR大一统模型
在这个领域,许多工作都为我们提供了有益的启示。首先是Donut模型,这是一个无需OCR的文档理解Transformer模型,通过文本序列统一了不同的任务,例如分类、问答以及文档的识别和解析,如下图所示。
另一个方面是Meta的工作,其目标是在语言模型训练过程中获取大量语料,尤其是学术界的扫描文件。他们通过SwinTransformer和Transformer Decoder实现了从文档图像到文档序列的输出,以便将文档传递给大模型进行训练。
还有微软的KOSMOS2.5工作,基于Pix2Seq框架,输入图像并输出文本块识别结果,以及端到端Markdown 3.2亿和Resampler减少图像嵌入数量,性能较NOUGAT要好得多。
我们还在思考以下几个方面:
1、将文档图像识别分析的各种任务定义为序列预测的形式,包括文本、段落、版面分析、表格、公式等。
2、通过不同的提示词引导模型完成不同的OCR任务。
3、支持篇章级的文档图像识别分析,输出标准格式的Markdown、HTML、Text等。
4、将文档理解相关的任务交给大语言模型(LLM)来完成。

总体而言,我们希望在感知层面取得足够好的性能,然后将认知任务交给大语言模型,因为我们认识到在感知层面,GPT4-V距离SOTA水平还存在较大差距,因此我们希望更好地解决这一领域的问题。
基于SPTS的进一步优化和迭代,我们提出了SPTSV3模型,具有以下特点:
1、多种OCR任务定义为序列预测的形式。
2、通过不同的提示词引导模型完成不同的OCR任务。
3、模型沿用SPTS的CNN+Transformer Encoder+Transformer Decoder的图片到序列的结构。

我们目前定义了一些任务,如场景文字识别、表格识别分析、公式识别、手写文档识别等,初步结果显示在文本方面,实验室的指标在许多方面优于SOTA水平。
当然,我们还有许多工作要做。当前的任务还不够多,与GPT4-V的泛化能力相比,我们仍存在差距。包括模型训练数据、模型参数量等方面,我们仍有很大的可扩展空间,需要进一步提升性能,并不断扩大泛化能力。
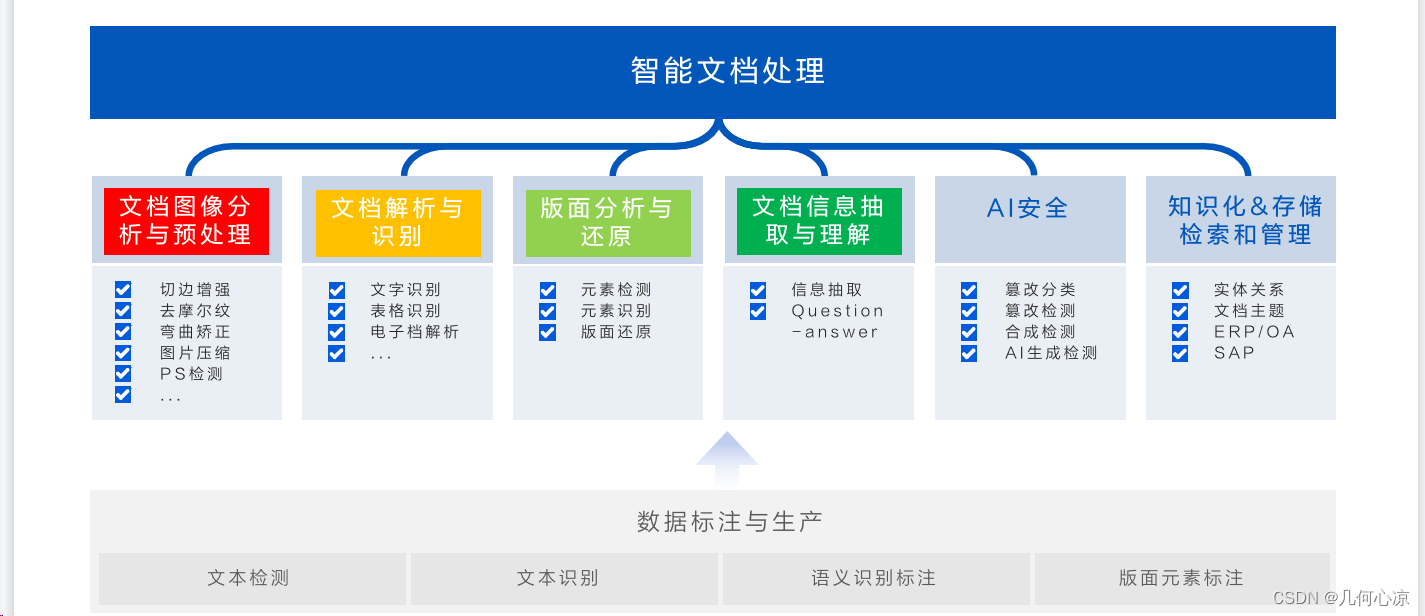
文档识别分析+LLM应用
在这个领域的研究中,众所周知,随着大语言模型的发展,文档层面的应用也逐渐出现。然而,文档是有结构和逻辑的,例如版面和格式对内容的影响非常大。为了解决这个问题,我们提出了一套技术框架,如下图所示。在获得初步数据后,我们对文档进行识别和版面分析,包括段落、表格、公式、图表等结构,然后进行切分和召回。

基于这一框架,实验室进行了实验,对自己的文档以及财报和研报进行了分析。之所以选择这两种类型进行实验是因为它们具备以下特点:文档内容长、图表多、版式复杂、专业性强、数据多、相似概念多。考虑到这些特点,对我们的召回提出了很大的挑战。同时,我们比较了传统方式和实验室的框架下两种模式的检索召回率。在实验室的框架下,召回率达到了80多,当然,我们仍有许多优化的空间。
GPT4-V的出现是挑战?机遇?
GPT4-V等多模态大模型技术对文档识别与分析领域带来了巨大的推动,同时也给传统的IDP技术提出了挑战。尽管大模型并没有完全解决IDP领域的所有问题,但它为我们提供了很多机会和挑战,如何更好地结合大模型的能力来解决IDP问题是值得深入研究和探索的方向。
GPT4-V在领域中的引入确实带来了很大的挑战,但同时也为我们创造了许多机会。大模型与OCR或IDP并不是互斥的,而是可以有很多结合的机会,使领域能够取得更好的发展。
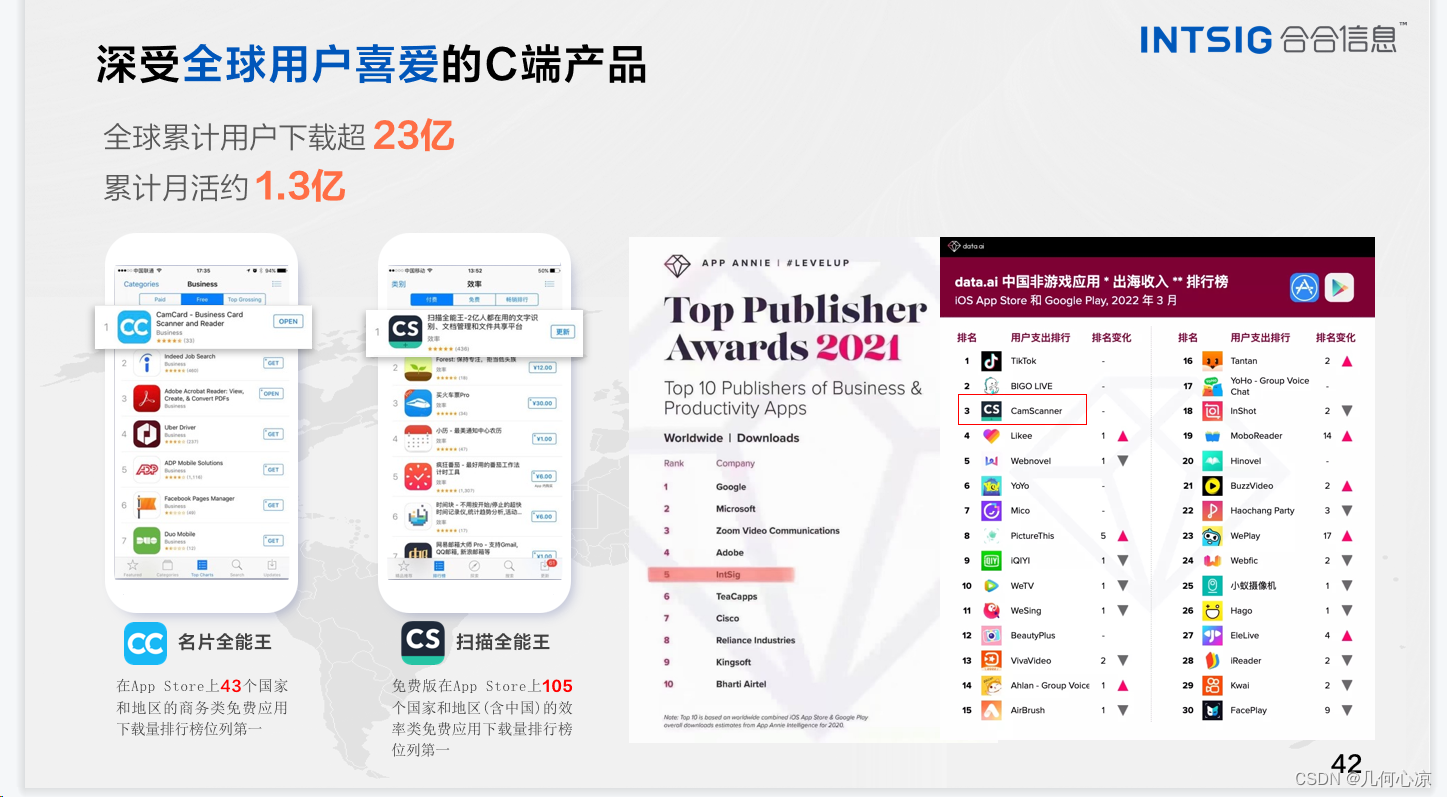
合合信息为何一直关注大模型和文档识别?自公司成立以来,合合信息一直在围绕文档领域进行技术研究和产品开发,涉及TOB、TOC等多个方面。公司将这些技术内容产品化商业化,在出海方面,合合信息的工具化产品也名列前茅。最后丁凯博士呼吁在OCR领域,不论是在技术、应用还是商业化方面,都存在着巨大的机会和价值,值得深入挖掘。
写在最后+福利
听完丁凯博士的分享后,深感大模型时代对文档识别的冲击与颠覆。GPT4-V等多模态大模型的崭新范式让我们见识到了AI在文档处理领域的卓越表现,给传统IDP技术带来了巨大挑战。尤其是端到端的文档理解能力,实在让人感叹不已。
当然分享中丁凯博士也提出目前大模型在中文处理和OCR精度等方面还有一定提升空间。也给了该领域的开发者们一些启示,在探索大模型能力的同时,仍需深入研究和拓展,以更好地解决领域内的实际问题。在这个技术变革的过程中,我们需要在创新中持续前行,以迎接未知的挑战。
最后的最后,合合信息为大家准备了一波抽奖;填写问卷即可参与,12号开奖;中奖者可以获得 50元京东卡,共抽取10名; 快来参与吧
问卷地址👉 https://qywx.wjx.cn/vm/exOhu6f.aspx