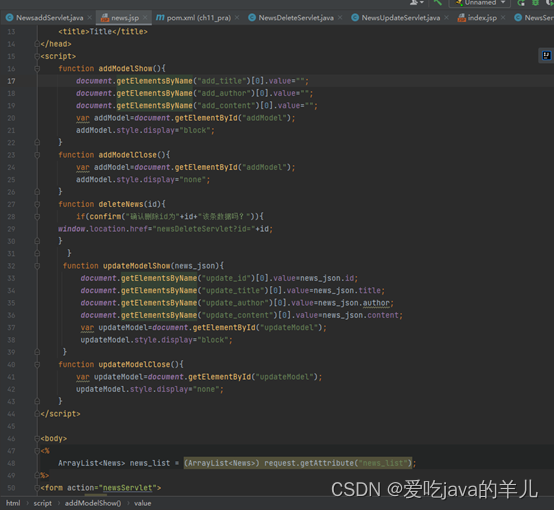
CUDA设备包含几种类型的内存,可以帮助程序员提高计算到全局内存的访问率,从而实现高执行速度。图4.6显示了这些CUDA设备内存。全局内存和恒定内存出现在图片的底部。主机可以通过调用API函数来写入(W)和读取(R)这些类型的内存。我们已经在第2章中引入了全局内存,数据并行计算。设备可以写入和读取全局内存。恒定内存支持设备短延迟、高带宽只读访问。
寄存器和共享内存,如图4.6所示,是片上内存。驻留在这些类型内存中的变量可以以高度并行的方式以非常高速的方式访问。寄存器分配给单个线程;每个线程只能访问自己的寄存器。内核函数通常使用寄存器来保存对每个线程都是私有的经常访问的变量。共享内存位置分配给线程块;块中的所有线程都可以访问分配给该块的共享内存变量。共享内存是线程的一种通过共享他们的输入数据和中间结果进行合作的有效手段。通过在CUDA内存类型之一中声明CUDA变量,CUDA程序员决定了变量的可见性和访问速度。
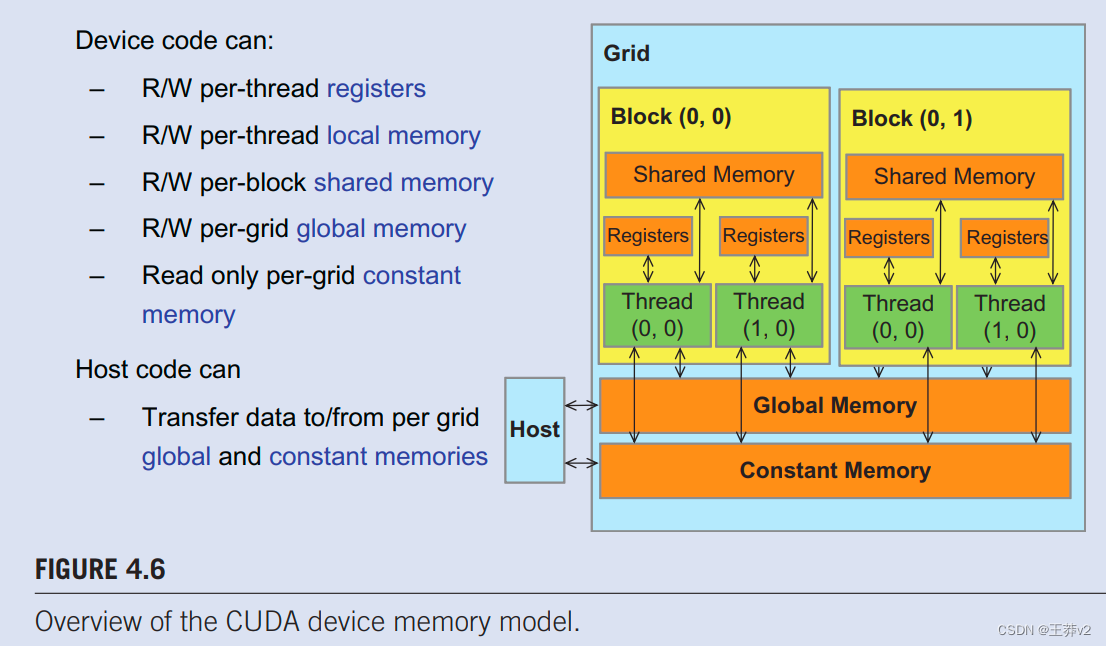
为了充分理解寄存器、共享内存和全局内存之间的区别,我们需要更详细地了解这些不同的内存类型如何在现代处理器中实现和使用。几乎所有现代处理器都从约翰·冯·诺伊曼在1945年提出的模型中找到其根源,如图4.7.所示,CUDA设备也不例外。CUDA设备中的全局内存映射到图4.7.中的内存盒。处理器盒对应于我们今天通常看到的处理器芯片边界。全局内存从处理器芯片上脱机,使用DRAM技术实现,这意味着长访问延迟和相对较低的访问带宽。寄存器对应于冯·诺伊曼模型的寄存器文件。寄存器文件位于处理器芯片上,这意味着与全局内存相比,访问延迟非常短,访问带宽高得多。在典型的设备中,寄存器文件的聚合访问带宽至少比全局内存高出两个数量级。此外,当变量存储在寄存器中时,其访问不再消耗片外全局内存带宽。这种带宽消耗的减少将反映为计算与全局内存访问比的增加。
更微妙的一点是,与对全局内存的访问相比,每次访问寄存器涉及的指令更少。大多数现代处理器中的算术指令都有“内置”寄存器操作数。例如,foating-point加法指令可能具有以下形式
fadd r1, r2, r3
其中r2和r3是寄存器编号,用于指定寄存器文件中可以找到输入操作数值的位置。存储Foating-point加法结果的位置值由 r1 指定。因此,当算术指令的操作数在寄存器中时,不需要额外的指令来使操作数值可用于执行算术计算的算术和逻辑单元(ALU)。
冯·诺曼模型
约翰·冯·诺伊曼(John von Neumann)在1945年的开创性报告中描述了一种建造电子计算机的模型,该模型基于开创性的电子离散可变自动计算机(EDVAC)计算机的设计。这个模型现在通常被称为冯·诺伊曼模型,是几乎所有现代计算机的基础蓝图。
冯·诺伊曼模型如图4.7.所示,计算机具有输入/输出功能,允许向系统提供和生成程序和数据。要执行程序,计算机首先将程序及其数据输入内存。
该程序由一系列指令组成。控制单元维护一个程序计数器(PC),其中包含要执行的下一个指令的内存地址。**在每个“指令周期”中,控制单元使用PC将指令获取到指令寄存器(IR)。然后,指令位用于确定计算机所有组件要采取的操作,这就是为什么该模型也被称为“存储程序”模型。**该术语意味着用户可以通过将不同的程序存储在内存中来改变计算机的行为。
同时,如果操作数值在全局内存中,处理器需要执行内存load操作,以使操作数值可用于ALU。例如,如果浮点加法指令的第一个操作数在全局内存中,则所涉及的指令可能会
load r2, r4, offset
fadd r1, r2, r3
其中,load指令将偏移值添加到r4的内容中,以形成操作数值的地址。然后,它访问全局内存,并将值放入寄存器r2中。一旦操作数值在r2中,tadd指令通过使用r2和r3中的值执行浮点加法,然后将结果放入r1。由于处理器每个时钟周期只能获取和执行数量有限的指令,因此与没有额外负载的版本相比,具有额外负载的版本可能需要更多的时间来处理。因此,将操作数放在寄存器中可以提高执行速度。
最后,在寄存器中放置操作数值还有另一个微妙的原因。在现代计算机中,从寄存器文件中访问值所消耗的能量至少比从全局内存中访问值的能量低一个数量级。我们将研究现代计算机中访问这两种硬件结构的速度和能量差异。然而,正如我们很快就会了解到的那样,每个线程可用的寄存器数量(请参阅“处理单元和线程”边栏)在今天的GPU中相当有限。我们需要小心,不要过度订阅这种有限的资源。
图4.8显示CUDA设备中的共享内存和寄存器。虽然两者都是片上存储器,但它们在功能和访问成本方面存在显著差异。共享内存被设计为驻留在处理器芯片上的内存空间的一部分。当处理器访问驻留在共享内存中的数据时,它需要执行内存 加载操作,类似于访问全局内存中的数据。**然而,由于共享内存驻留在芯片上,因此可以以比全局内存更低的延迟和更高的吞吐量访问它。**由于需要执行负载操作,共享内存的延迟比寄存器更长,带宽更低。在计算机架构术语中,共享内存是scratchpad memory的一种形式。
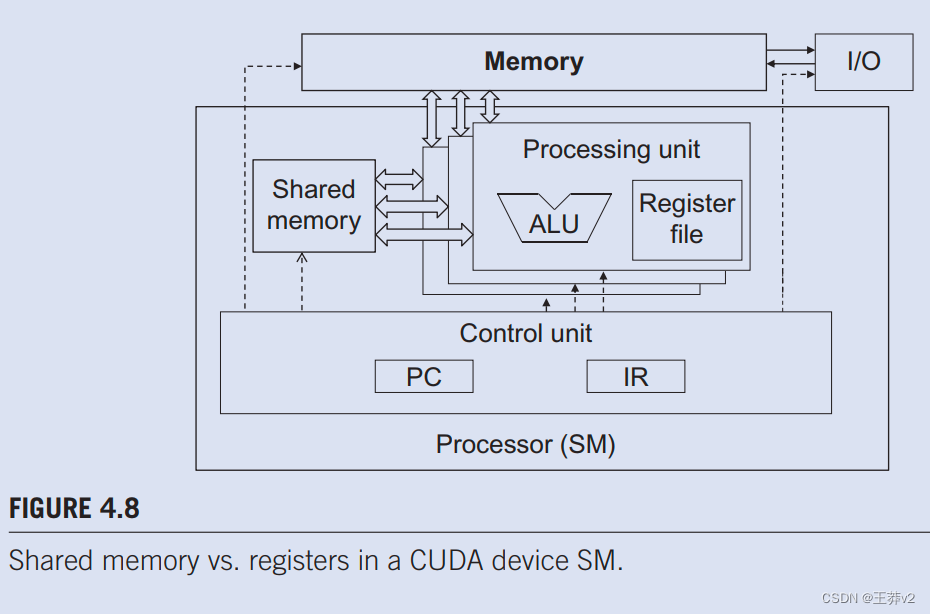
CUDA中共享内存和寄存器的一个重要区别是,驻留在共享内存中的变量可以被块中的所有线程访问,而寄存器数据对线程是私有的。共享内存旨在支持块中线程之间高效、高带宽的数据共享。如图4.8所示,CUDA设备SM通常使用多个处理单元,以允许多个线程同时进行(请参阅处理单元和线程边栏)。块中的线程可以分布在这些处理单元中。因此,这些CUDA设备中共享内存的硬件实现通常旨在允许多个处理单元同时访问其内容,以支持块中线程之间的高效数据共享。我们将学习几种重要类型的并行算法,这些算法可以从线程之间的这种高效数据共享中受益匪浅。
处理单元和线程
现在我们已经引入了冯·诺伊曼模型,我们准备讨论线程的实现方式。现代计算机中的线程是在冯·诺伊曼处理器上执行程序的状态。回想一下,线程由程序的代码、正在执行的代码中的特定点以及其变量和数据结构的值组成。
在基于冯·诺伊曼模型的计算机中,程序的代码存储在内存中。PC跟踪正在执行的程序的特定点。IR保存从点执行中获取的指令。寄存器和内存保存变量和数据结构的值。
现代处理器旨在允许上下文切换,其中多个线程可以通过轮流取得processor来分时共享处理器。通过仔细保存和恢复PC值以及寄存器和内存的内容,我们可以暂停线程的执行,然后稍后正确地恢复线程的执行。
一些处理器提供多个处理单元,允许多个线程同时进行。图4.8显示了单指令、多数据设计风格,其中多个处理单元共享PC和IR。在此设计下,所有线程都通过在程序中执行相同的指令来同时进行。
现在应该很清楚,寄存器、共享内存和全局内存具有不同的功能、延迟和带宽。因此,必须理解声明变量的过程,以便它驻留在预期的内存类型中。表4.1展示了将程序变量声明为各种内存类型的CUDA语法。每个这样的声明还给其声明的CUDA变量一个范围和生命周期。范围标识了可以访问变量的线程范围:仅单个线程、块的所有线程或所有网格的所有线程。如果变量的范围是单个线程,则将为每个线程创建变量的私有版本;每个线程只能访问其变量的私有版本。为了说明,如果一个内核声明一个范围为线程的变量,并且它以一百万个线程启动,则将创建该变量的一百万个版本,以便每个线程初始化并使用自己的变量版本。
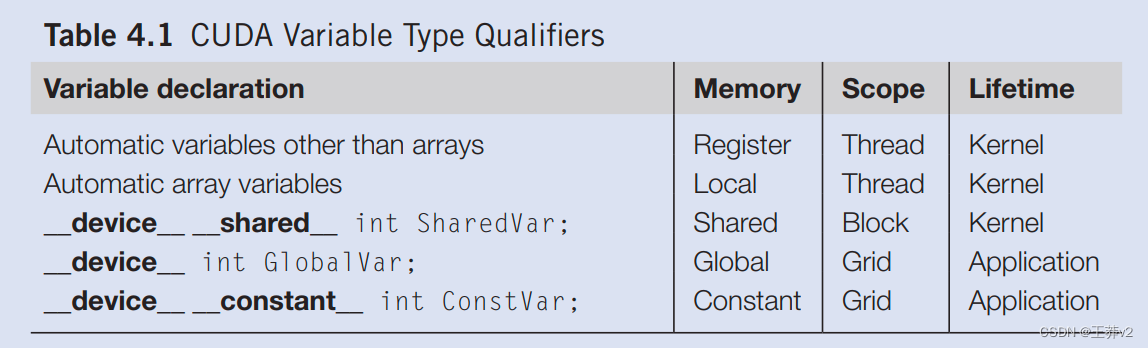
Lifetime表示变量可供使用时程序执行持续时间的部分:在内核执行内或整个应用程序中。如果变量的生命周期在内核执行范围内,则必须在内核函数主体中声明,并且只能由内核代码使用。如果内核被多次调用,则这些调用中不会保持变量的值。每次调用都必须初始化变量才能使用它们。同时,如果变量的生命周期持续到整个应用程序中,则必须在任何函数体之外声明。这些变量的内容在整个应用程序执行过程中保持不变,并可供所有内核使用。
我们将不是数组或矩阵的变量称为标量变量。如表4.1所示,内核和设备函数中声明的所有自动标量变量都被放入寄存器中。这些自动变量的范围在单个线程中。当内核函数声明自动变量时,为执行内核函数的每个线程生成该变量的私有副本。当线程终止时,其所有自动变量也不再存在。在图4.1中,变量blurRow、blurcol、curRow、curCol、像素和pixval是自动变量,属于此类别。请注意,访问这些变量的速度非常快且并行;但是,在硬件实现中,必须小心不要超过寄存器存储的有限容量。使用大量寄存器可能会对分配给每个SM的活动线程数量产生负面影响。我们将在第5章,性能考虑中讨论这一点。
**自动数组变量不存储在寄存器中。相反,它们存储在全局内存中,可能会产生长时间的访问延迟和潜在的访问拥塞。****与自动标量变量类似,这些数组的范围仅限于单个线程;即为每个线程创建并使用每个自动数组的私有版本。一旦线程终止其执行,其自动数组变量的内容也不复存在。**根据我们的经验,自动数组变量很少用于内核函数和设备函数。
如果变量声明前面有“Shared”(每个”由两个“”字符组成)关键字,则在CUDA中声明一个共享变量。也可以在声明中添加__shared__”关键字前面的可选的__device",以实现相同的效果。此类声明通常位于内核函数或设备函数中。**共享变量驻留在共享内存中。共享变量的范围位于线程块内;即块中的所有线程都看到共享变量的相同版本。**在内核执行期间,为每个线程块创建并使用共享变量的私有版本。共享变量的生命周期在内核的持续时间内。当内核终止其执行时,其共享变量的内容将不复存在。如前所述,共享变量是块内线程相互协作的有效手段。从共享内存中访问共享变量的速度非常快且高度并行。CUDA程序员经常使用共享变量来保存在内核执行阶段大量使用的gobal内存数据部分。可能需要调整算法,以创建严重关注全局内存数据的一小部分的执行阶段,正如我们将在第4.4节中用矩阵乘法演示的那样。
如果变量声明前面有关键字“constant”(每个由两个“_”字符组成),则它在CUDA中声明一个常量变量。可选的 _device“关键字也可以在“constant”前面添加,以实现相同的效果。常量变量的声明必须在任何函数体之外。常量变量的范围跨越所有grids,这意味着所有网格中的所有线程都看到常量变量的相同版本。常量变量的生命周期是整个应用程序的执行时间。常量变量通常用于为内核函数提供输入值的变量。常量变量存储在全局内存中,但为了高效访问而缓存。有了适当的访问模式,访问恒定内存是极其快速和并行的。目前,应用程序中常量变量的总大小限制为65,536字节。输入数据量可能需要划分以适应此限制,正如我们将在第7章《并行模式:卷积》中说明的那样。
声明前面只有关键字“device(每个”“由两个”字符组成)的变量是一个全局变量,将放置在全局内存中。对全局变量的访问很慢。通过相对较新的设备中的缓存,访问全局变量的延迟和吞吐量得到了改善。全局变量的一个重要优势是,它们对所有内核的所有线程都是可见的。它们的内容也在整个执行过程中持续存在。因此,全局变量可以用作线程跨块协作的手段。然而,在访问全局内存时,在来自不同线程块的线程之间同步或确保跨线程的数据一致性的唯一简单方法是终止当前内核执行。因此,全局变量通常用于将信息从一个内核调用传递到另一个内核调用。
在CUDA中,指针用于指向全局内存中的数据对象。指针使用在内核和设备函数中以两种方式出现:(1)如果对象由主机函数分配,则指向对象的指针由cudaMalloc初始化,并可以作为参数传递给内核函数(例如,图4.3中的参数M、N和P)和(2)全局内存中声明的变量的地址分配给指针变量。为了说明,内核函数中的语句{float* ptr= &GlobalVar;}将GlobalVar的地址分配到自动指针变量ptr中。读者应参考CUDA编程指南,了解在其他内存类型中使用指针。