在实际应用大模型的过程中,尤其是处理长文本的上下文信息时,如何高效灵活地调度计算资源成为一个学术界与工业界共同关注的问题。
大语言模型所能容纳的上下文长度直接影响了诸如 ChatGPT 等高级应用与用户交互体验的优劣程度,这给云环境下的 LLM 服务系统提出了严峻挑战:不合理的资源配置不仅可能导致性能瓶颈,还可能造成宝贵的计算资源浪费。
最近,上海交通大学携手阿里研究团队针对这个问题开展了一项研究。
他们提出一个名为 DistAttention 的新颖注意力机制以及一套名为 DistKV-LLM 的分布式 LLM 服务架构,针对长文本语言任务处理中的计算难题提出了新解法,或是对行业的启示。

论文链接:https://arxiv.org/pdf/2401.02669.pdf
长文本处理
LLM云服务是指通过云计算平台提供的,基于大型语言模型的各项服务。各家在LLM云服务之上也下足了马力。目前市场上主要的 LLM 云服务提供商包括但不限于亚马逊的 SageMaker、谷歌的 Cloud AI Platform、微软的 Azure Machine Learning 以及国内的阿里云等。这些平台通常提供了从模型开发到部署的一站式服务,包括计算资源、数据存储、模型训练和部署等。
上个月,一则关于阿里云 OpenSearch-LLM 服务出现故障的消息在技术人员之间传播开来。然而,由于 LLM 云服务这一概念尚未普及至大众认知层面,因此该事件在持续了一天后,便鲜有人再提起。
但这样一个不起眼的故障事件,为我们带来了一个新的思考,基于大型预训练语言模型的在线LLM云服务虽然拥有巨大的超能力,能够为用户提供高效、实时的语言理解和生成能力,但而与之而来的是其对于算力资源的巨大挑战。
拿阿里云 OpenSearch-LLM 智能问答服务为例,公开资料显示,该服务利用了先进的LLM技术,在云端提供强大的自然语言处理功能。由于模型运行所需的计算资源波动较大,特别是在处理长上下文场景时对内存和计算力的需求激增导致的。这种情况下,传统的资源分配策略可能无法有效应对动态变化的需求,从而引发服务不稳定甚至中断。
可以看出即使强大如阿里云也会受制于 LLM 长文本处理的难题。在 Infinite-LLM 的研究中,揭示了这样一个现象:LLM服务的核心运作往往倚赖于多张 GPU 卡的协同工作以完成复杂的文本任务,然而其内在的动态自回归生成机制犹如一道待解的计算难题。
在模型自回归过程中,文本如同一幅逐步渲染的画卷,每一步都根据前序内容迭代地生成新的词语或token,并将它们融合到当前上下文中作为后续生成的基础输入。这种高度动态且连续的过程使得提前精确规划资源分配成为一项不可预知的任务,从而对设计和优化云端 LLM 服务架构构成了实质性挑战。
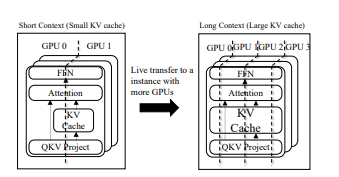
图注:在采用传统模型并行策略将网络分布在更多GPU上时,这些不随上下文扩展的层会被过度细粒度地分割
打个比方,这就类似于一位顶级厨师运用最先进的智能厨房设备,尝试烹饪一道工序繁复且需灵活调整口味的创新菜品。每当加入一种新鲜食材时,都必须依据现有的风味组合重新调配调料,而且无法预见究竟需要多少种类的食材才能成就这道完美的佳肴。
面对这一亟待解决的问题,业界各方表现出共同的关注与期待。众多研发团队积极投入研究,其中 PagedAttention等方案试图通过改进 GPU 与 CPU 之间的数据交换策略,有效地管理和调度内存资源,以期化解上述困扰LLM服务效率提升的棘手问题。
但这种方法存在几个局限性:
首先,PagedAttention的内存置换范围局限于单一节点内的GPU和CPU内存,因此对极长上下文长度的支持能力受限;
其次,尽管其分页策略旨在最小化内存碎片,但基于请求级别整体交换KV缓存(Key-Value,键值缓存,是一种计算机存储技术),错失了在分布式云环境中实现更为灵活、精细化调度的机会;
此外,对于被置换出的请求所造成的计算中断可能会导致运行任务性能抖动,从而可能违反对云服务至关重要的服务协议(SLAs)。
为了解决业界长期面临的大规模语言模型(LLM)服务中的内存管理与资源分配难题,阿里与上海交大的团队提出了一种名为 DistAttention 的新型注意力算法。
DistAttention将 KV 缓存划分为rBlocks——统一的子块,以便为具有长上下文长度的LLM服务分布式计算和内存管理注意力模块。与主要利用单个节点内的GPU或CPU内存的传统方法不同,DistAttention允许优化分布式数据中心中所有可访问的GPU或CPU内存资源,特别是那些现在利用率不高的资源。这不仅支持更长的上下文长度,还避免了与数据交换或实时迁移过程相关的性能波动。
这就像一位技艺高超的仓储大师,巧妙地将一个不断扩展的、宛如巨大食材仓库的KV缓存分割成大小适中的rBlocks储物箱,使得在面对一道配料繁多、制作复杂的超长菜单(相当于处理长上下文任务)时,每一种“食材”(数据)都能迅速而准确地送达各自的烹饪台(分布式计算节点)。
与那些只在单一厨房(单个GPU或CPU内存节点)内调配食材的传统方法相比,这位“仓储大师”更擅长调动整个美食广场(即数据中心内的所有可用GPU和CPU内存资源),特别是那些闲置或使用率低的空间,使制作超长菜单变得可行且高效,避免了因频繁搬运食材造成的混乱和效率波动。
换言之,DistAttention能够灵活调度跨数据中心的所有可访问GPU或CPU内存资源,特别是那些利用率较低的部分,从而不仅支持更长的上下文处理,还能有效降低由于数据交换或实时迁移带来的性能起伏。
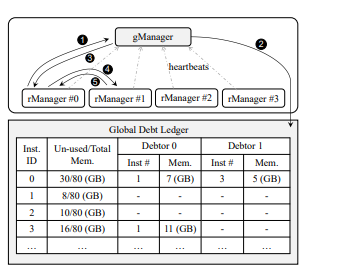
图注:展示了DistKV-LLM如何解决内存碎片化问题
基于此,Infinite-LLM团队进一步开发了集成 DistAttention 技术的 DistKV-LLM 分布式LLM服务引擎。
DistKV-LLM 是一个与 DistAttention 无缝集成的分布式LLM服务引擎。DistKV-LLM 擅长管理KV缓存,有效地在数据中心内的分布式 GPU 和 CPU 之间协调内存使用。当一个LLM服务实例由于 KV 缓存扩展而面临内存不足时,DistKV-LLM主动从负担较轻的实例寻求补充内存。
相比起 DistAttention,DistKV-LLM更像一位精明的协调员,在数据中心内部妥善管理和优化分布式GPU和CPU之间的KV缓存使用。当一个LLM服务实例因为KV缓存扩大而导致内存不足时,它会主动从负载较小的实例借用额外内存。
同时,DistKV-LLM还引入了一套精细的通信协议,促进云端运行的多个LLM服务实例之间进行高效、扩展性强且一致的互动协作。这套协议的核心目标是高效管理和平衡庞大的内存资源,并优先关注数据存储位置就近性和通信效率提升,这对于解决与KV缓存分布存储相关的性能瓶颈至关重要。
这意味着DistKV-LLM能够更好地驾驭大型语言模型在众多GPU和CPU上的并行运算。当LLM服务因需处理海量信息而面临内存压力时,DistKV-LLM能智慧地从负载较轻的区域获取额外内存,并制定一套高级协同规则,确保不同云上LLM实例间能够高效有序、步调一致地完成工作。这一系列设计的关键在于优化内存使用、确保数据快速存取以及减少各部分间的通信成本,即使面临复杂的分布式存储挑战,也能保障系统的整体高性能表现。
DistAttention与DistKV-LLM双管齐下,为分布式环境下LLM服务所面临的资源分配与优化挑战提供了一个切实有效的解决方案。
在具体的实验测评之中,DistAttention与DistKV-LLM在资源管理方面也有卓越的表现。
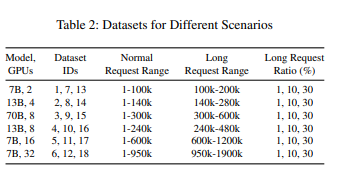
研究人员在一个包含4个节点和32块GPU的集群上部署了DistKV-LLM系统。每个节点配备了8块NVIDIA A100(80GB)GPU。模型方面则选择了一个具有代表性的模型LLaMA2 进行评估(LLaMA2系列包含了三个不同规模的模型:7B、13B和70B。)。
团队对分布式系统配置进行了广泛测试,涵盖了从2个到32个实例的多种规模。在评测过程中,采用了包含上下文长度最高达1,900K字节的18个代表性基准数据集进行严格检验。结果显示,相较于当前最尖端的技术,系统成功实现了1.03至2.4倍的显著端到端性能飞跃,并且在处理更长上下文信息方面表现出色,支持的上下文长度可扩展至原先的2至19倍之多。同时,在处理标准长度上下文任务场景下,系统的吞吐量也取得了令人瞩目的提升,增长幅度在1.4至5.3倍之间。
结语
随着深度学习技术在自然语言处理领域的广泛应用与深化,端到端性能的研究受到了广泛关注。在应对长文本时,这种性能飞跃的重要性尤为凸显,因为它直接影响了我们能否高效而准确地驾驭海量文本数据,并从中抽丝剥茧般提取出有价值的信息。
DistAttention与DistKV-LLM的结合,通过智能管理内存资源、优化分布式计算策略,成功解决了大规模语言模型服务在长上下文处理中的难题,使系统能够从容应对超长文本序列,同时保持端到端性能提升以及上下文长度扩展能力。未来云端自然语言处理应用有望迎来全新的突破与变革。








![[VUE]4-状态管理vuex](https://img-blog.csdnimg.cn/direct/e05d375daad048ec91942c6b376dea13.png)