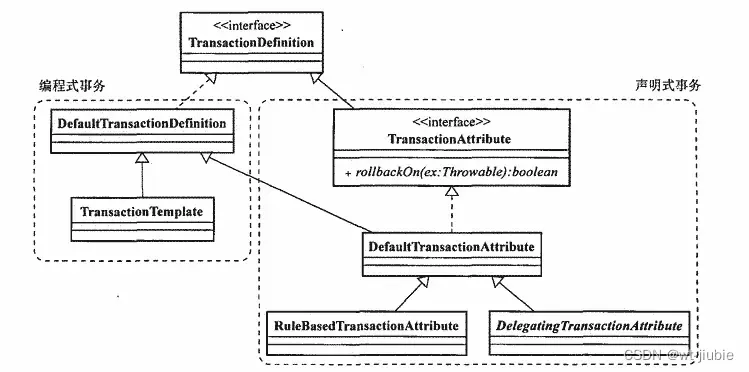
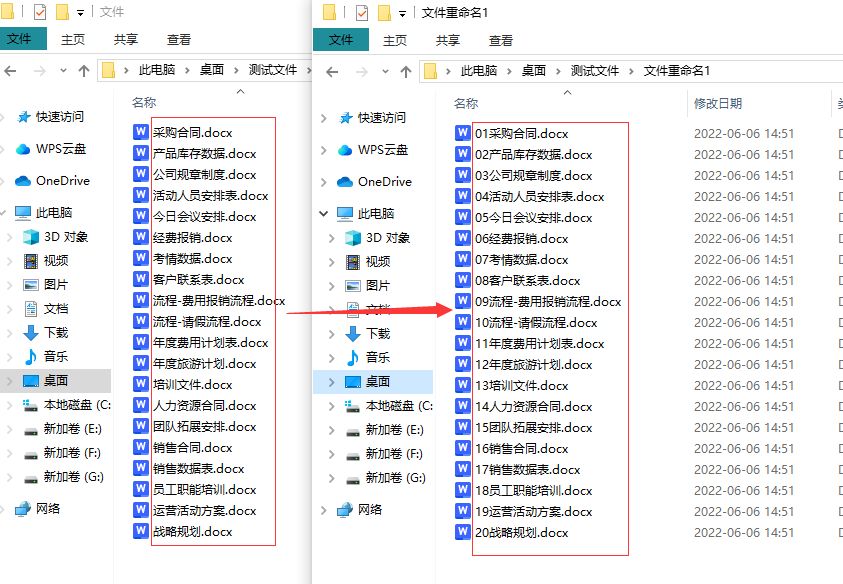
txt文档里筛选出重复数据,并保存到新的txt文档
input_file = r'D:\pythonXangmu\quchong\input_file.txt' #原始文档
#output_file = 'output.txt'#重复内容记录文档
output_file = r'D:\pythonXangmu\quchong\output.txt'#绝对路径,解决报错找不到文件或文件夹
with open(input_file, 'r', encoding='utf-8') as file:
content = file.readlines()
print('content',content)
unique_lines = set()#存储唯一的行数据,是列表
duplicate_lines = []#存储重复的行,是列表
#筛选出每行重复数据
for line in content:
if line in unique_lines:
duplicate_lines.append(line)
else:
unique_lines.add(line)
with open(output_file, 'w', encoding='utf-8') as file:
for line in duplicate_lines:
file.write(line)
for line2 in duplicate_lines:
line2 =line2
print('line2',line2)
print('unique_lines',unique_lines)
print('duplicate_lines',duplicate_lines)
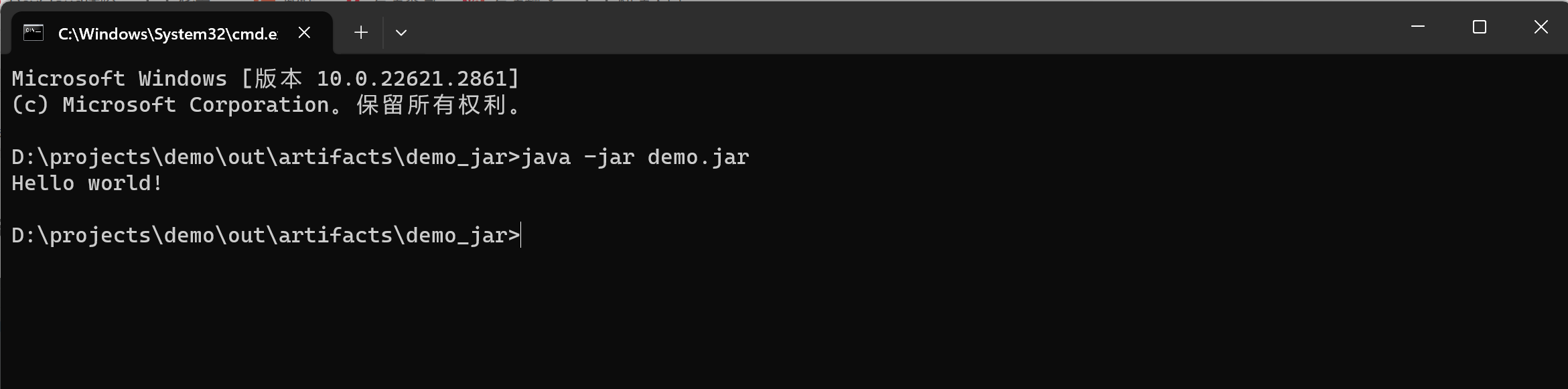
打印:
content [‘1200001\n’, ‘1233331\n’, ‘1244441\n’, ‘0000121\n’, ‘1200001\n’, ‘1233331\n’, ‘1233331\n’]
line2 1200001
line2 1233331
line2 1233331
unique_lines {‘1233331\n’, ‘1244441\n’, ‘0000121\n’, ‘1200001\n’}
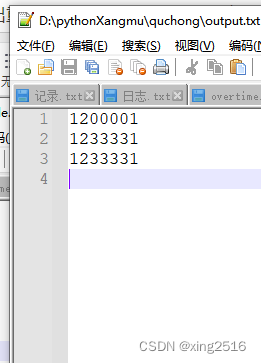
duplicate_lines [‘1200001\n’, ‘1233331\n’, ‘1233331\n’]
input_file.txt
output.txt