线程调度严格来说是一个实现概念。因此,它必须在特定硬件实现的背景下进行讨论。在迄今为止的大多数实现中,分配给SM的块被进一步分为32个称为warps的线程单元。warps的大小是特定于实现的。warps不是CUDA规范的一部分;然而,了解warps有助于理解和优化特定代CUDA设备上CUDA应用程序的性能。warps的大小是CUDA设备的属性,位于设备查询变量(在本例中为dev_prop)的warpSize字段中。
warp是SM中线程调度的单位。图3.13显示了在实现中将块划分为warp。每个warp经由32个连续的线程ldx值组成:线程0到31形成第一个warp,32到63第二个warp等。在本例中,三个块——第1块、第2块和第3块被分配给一个SM。出于调度目的,这三个区块中的每一个都进一步分为warp。
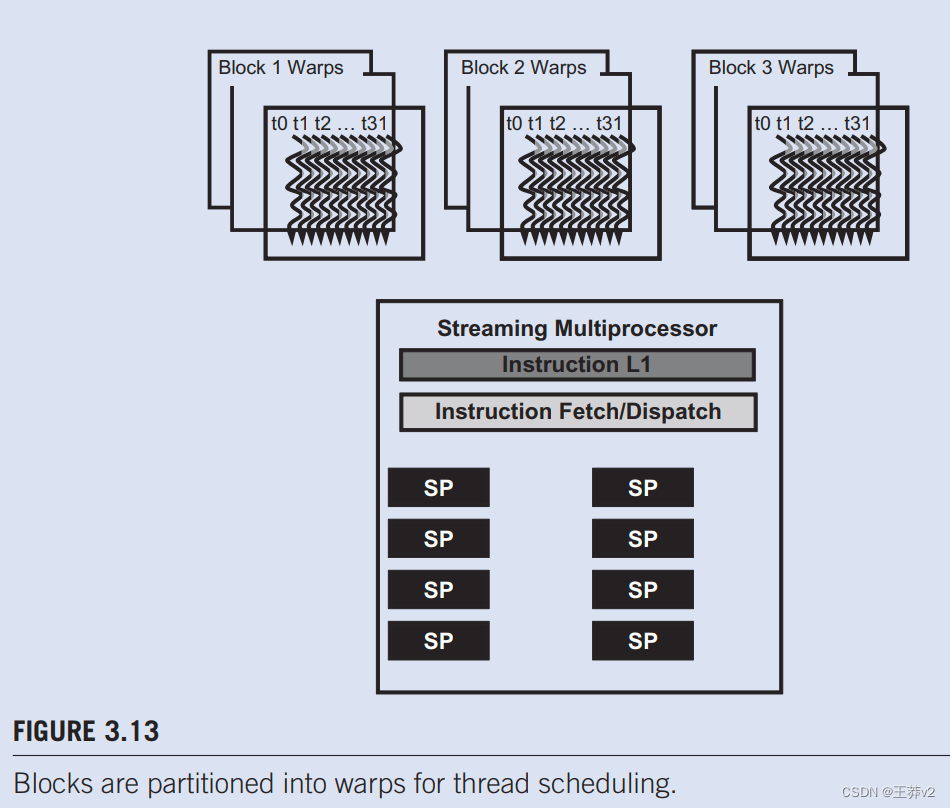
我们可以计算给定块大小和分配给每个SM的给定块数的驻留在SM中的warps。在图3.13中,如果每个块有256个线程,我们可以确定每个块有256/32或8个warps。每个SM有三个块,每个SM有8×3=24个warps。
SM旨在按照单指令、多数据(SIMD)模型执行warp中的所有线程,即在任何时候,都会为warp中的所有线程获取并执行一条指令。这种情况如图3.13所示,在SM中的执行单元(SP)之间共享单个指令获取/调度。这些线程将对数据的不同部分应用相同的指令。因此,warp中的所有线程将始终具有相同的执行时间。
图3.13还显示了一些实际执行指令的硬件流处理器(SP)。一般来说,SP比分配给每个SM的线程少;即每个SM只有足够的硬件来执行在任何时间点分配给SM的所有线程的小子集的指令。在早期的GPU设计中,每个SM在任何瞬间只能为单个warp执行一个指令。在最近的设计中,每个SM可以在任何时间点执行少量warp的指令。无论哪种情况,硬件都可以为SM中所有warp的一小部分执行指令。一个合理的问题是,如果一个SM在任何时候都只能执行一小部分,那么为什么我们需要在SM中有这么多的warp。答案是,这就是CUDA处理器如何有效地执行长延迟操作,例如全局内存访问。
当要由warp执行的指令需要等待之前启动的长延迟操作的结果时,不会选择这个warp执行。相反,将选择另一个不再等待结果的常驻warp进行执行。如果多个warp已准备好执行,则使用优先级机制来选择一个执行。这种用其他线程的工作填充操作延迟时间的机制通常被称为“延迟容忍度”或“latency隐藏”(见“延迟容忍度”边栏)。
warp调度也用于容忍其他类型的操作延迟,例如管道化的浮点算术和分支指令。给定足够数量的warp,硬件可能会在任何时间点找到要执行的warp,因此尽管有这些长延迟操作,但仍能充分利用执行硬件。选择执行的就绪warp避免了在执行时间线中引入空闲或浪费的时间,这被称为零开销线程调度。通过warp调度,warp指令的长等待时间通过执行其他warp指令被“隐藏”。这种容忍长延迟操作的能力是GPU不像CPU那样将几乎那么多的芯片区域用于缓存存储器和分支预测机制的主要原因。因此,GPU可以将其更多的芯片区域用于浮点执行资源。
延迟容忍
在各种日常情况下也需要延迟容忍。例如,在邮局,每个试图运送包裹的人最好在去服务柜台之前填写所有必要的表格和标签。相反,有些人等待服务台办事员告诉他们要填写哪种表格以及如何填写表格。
当服务台前排长队时,必须最大限度地提高服务人员的生产力。当每个人都在等待时,让一个人在办事员面前填写表格不是一种有效的方法。在人员填写表格时,办事员应该协助排队等候的其他客户。这些其他客户已经“准备就绪”,不应该被需要更多时间填写表格的客户阻止。
因此,一个好的办事员会礼貌地要求第一个客户靠边站来填写表格,同时他/她可以为其他客户服务。在大多数情况下,一旦该客户完成表格,并且办事员完成为当前客户提供服务,而不是该客户到行尾,就会为第一个客户提供服务。
我们可以将这些邮局客户视为warp,将办事员视为硬件执行单元。需要填写表格的客户对应于一个warp,其持续执行取决于长延迟操作。
我们现在准备好进行一个简单的练习了。假设CUDA设备每个SM最多允许8个块和1024个线程,以先成为限制者为准。此外,它允许每个块中多达512个线程。对于图像模糊,我们应该使用8×8、16×16还是32×32线程块?为了回答这个问题,我们可以分析每个选择的利弊。如果我们使用8 x 8块,每个块只有64个线程。我们需要1024/64 = 12个区块才能完全占据一个SM。然而,每个SM最多只能允许8个块;因此,我们最终每个SM中只有64×8=512个线程。这个有限的数量意味着SM执行资源可能没有得到充分利用,因为可以围绕长延迟操作安排的warp更少。
请注意,这是一个过于简化的练习。正如我们将在第4章“内存和数据局部性”中解释的那样,在确定最合适的块尺寸时,还必须考虑寄存器和共享内存等其他资源的使用。本练习强调了块数量限制和可以分配给每个SM的线程数量限制之间的相互作用。
16×16块导致每个块256个线程,这意味着每个SM可以采取1024/256 = 4个块。这个数字在8块限制范围内,是一个很好的配置,因为它将允许我们在每个SM中拥有完整的线程容量,并允许围绕长延迟操作调度最大数量的warp。32 x 32块将在每个块中提供1024个线程,这超过了该设备每个块的512个线程限制。只有16 x 16块允许为每个SM分配最大线程数。Kerel执行配置参数定义了grid及其块的尺寸。blockIdx和threadidx中的唯一坐标允许网格的线程识别自己及其数据域。程序员有责任在内核函数中使用这些变量,以便线程能够正确识别要处理的数据部分。这种编程模式迫使程序员将线程及其数据组织到分层和多维组织中。
一旦启动网格,其块可以按任意顺序分配给SM,从而实现CUDA应用程序的透明可扩展性。透明的可扩展性有一个限制:不同块中的线程不能相互同步。为了使内核保持透明的可扩展性,不同块中的线程相互同步的简单方法是终止内核,并在同步点后为活动启动一个新的内核。
线程被分配给SM,以便逐个块执行。每个CUDA设备对每个SM的可用资源量施加了潜在的不同限制。每个CUDA设备对每个SM可以容纳的块数量和线程数量设置限制,以先成为限制者为准。对于每个内核,其中一个或多个资源限制可以成为同时驻留在CUDA设备中的线程数量的限制因素。
一旦一个块被分配给一个SM,它就会被进一步分割成warp。warp中的所有线程都具有相同的执行时间。在任何时候,SM只执行其常驻warp的一小部分的指令。这个条件允许其他warp等待长延迟操作,而不会减慢大量执行单元的整体执行吞吐量。


![[De1ctf 2019]SSRF Me](https://img-blog.csdnimg.cn/direct/3e624bf6ccfc408e98152489309694e6.png)