一、文件描述符
1、文件描述符的底层理解
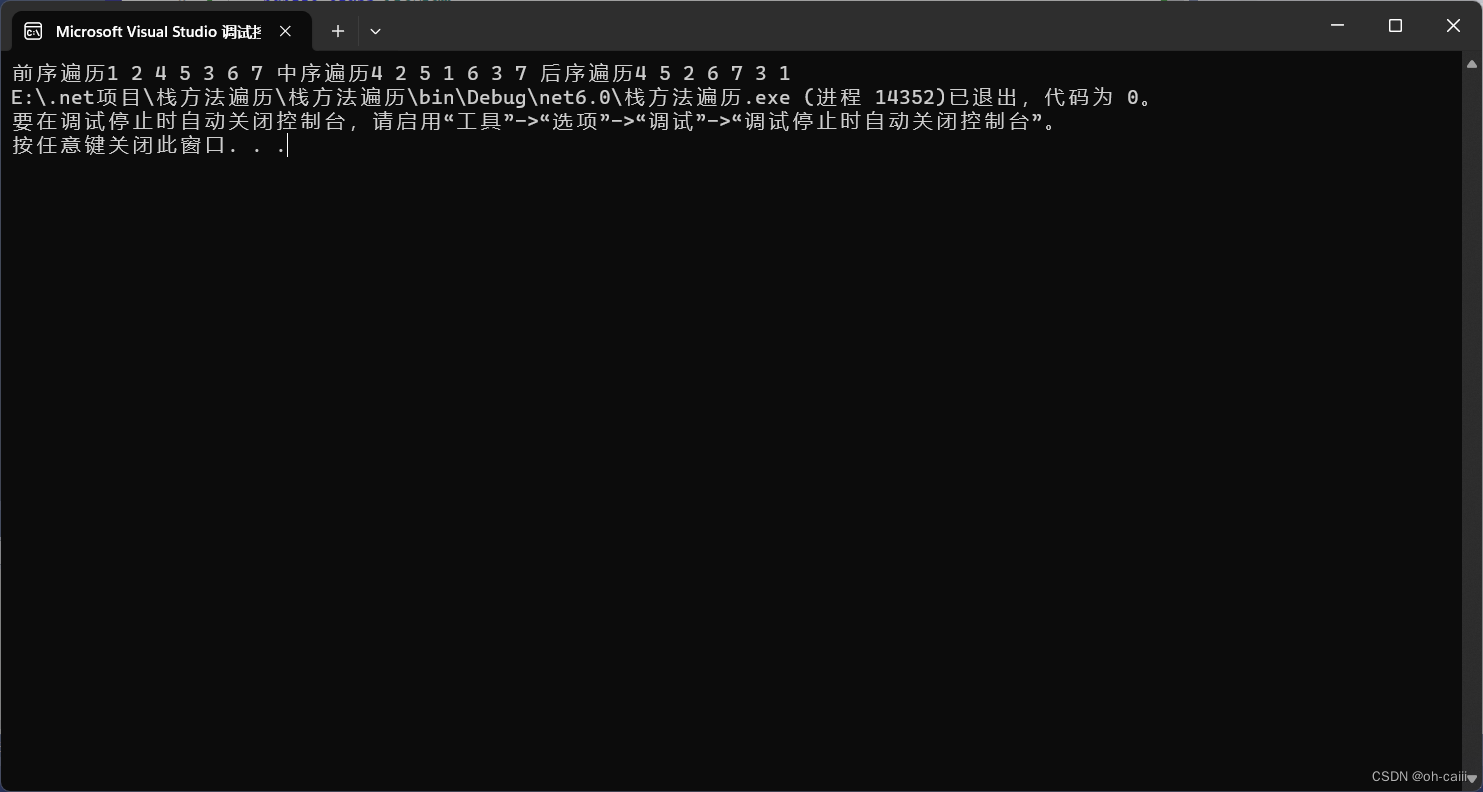
在上一章中,我们已经把 fd 的基本原理搞清楚了,知道了 fd 的值为什么是 0,1,2,3,4,5...
也知道了 fd 为什么默认从 3 开始,而不是从 0,1,2,因为其在内核中属于进程和文件的对应关系。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main(void)
{
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
} 
再看结果为3的时候,感觉不奇怪吧
接下来我们应该探索应用特征了。我们需要探索以下三个问题:
- ① 文件描述符的分配原则
- ② 重定向的本质
- ③ 理解缓冲区
2、fd 的分配原则
代码演示:默认把 0,1,2 打开,那我们直接 close(0) 关掉它们

运行结果如下:

此时,给我的文件分配的文件描述符就是0;
现在我们再把 2 关掉,close(2) 看看:![]()
运行结果:

所以,默认情况下 0,1,2 被打开,你新打开的文件默认分的就是 3 (因为 0,1,2 被占了) 。
如果把 0 关掉,给你的就是 0,如果把 2 关掉,给你的就是 2……
那是不是把 1 关掉,给你的就是 1 呢?我们来看看:
int main(void)
{
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
}结果:

发现什么都没有。
出乎意料啊,fd 居然不是 1,而是什么都没有,这是怎么回事呢?
原因很简单,1 是 stdout,printf 打印是往 stdout 打印的,你把 1 关了当然就没有显示了。
分配规则:从头遍历数组 fd_array[] ,找到一个最小的且没有被使用的下标分配给新的文件。
根据 fd 的分配规则,新的 fd 值一定是 1,所以虽然 1 不再指向对应的显示器了,但事实上已经指向了 log.txt 的底层 struct file 对象了。
但是结果没打印出来, log.txt 里也什么都没有。
二、重定向(Redirection)
1、fflush 刷新缓冲区
实际上并不是没有,而是没有刷新,用 fflush 刷新缓冲区后,log.txt 内就有内容了。
代码演示:
int main(void)
{
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
fflush(stdout);
close(fd);
}运行结果:

我们自己的代码中调用的就是 printf,printf 本来是往显示器打印的,
现在不往显示器打了,而是写到了文件里,它的 "方向" 似乎被改变了。
这不就是重定向吗?
2、dup2 函数
上面的一堆数据,都是内核数据结构,只有 OS 有权限,所以其必须提供对应接口,比如 dup。
除了 dup,还有有一个 dup2,后者更复杂一些,我们今天主要介绍 dum2 来进行重定向操作!
man dup2
dup2 可以让 newfd 拷贝 oldfd,如果需要可以将 newfd 先关闭。
newfd 是 oldfd 的一份拷贝,将后者 (newfd) 的内容写入前者 (oldfd),最后只保留 oldfd。

至于参数的传递,比如我们要输出重定向 (stdout) 到文件中:
我们要重定向时,本质是将里面的内容做改变,所以是要把 fd 的内容拷贝到 1 中的:
当我们最后进行输出重定向的时候,所有的内容都和 fd 的内容是一样的了。
所以参数在传递时,oldfd 是 fd,所以应该是 dum2(fd, 1);
dum2(fd, 1); ✅
dum2(1, fd); ❌因为要将显示器的内容显示到文件里,所以 oldfd 就是 fd,newfd 就是 1 了。
注意事项:dum2() 接口在设计时非常地反直觉,所以在理解上特比容易乱,搞清楚原理!
 代码演示:dup2()
代码演示:dup2()
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(void)
{
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 0;
}
dup2(fd, 1); // fd ← 1
fprintf(stdout, "打开文件成功,fd: %d\n", fd);
// 暂时不做讲解,后面再说
fflush(stdout);
close(fd);
return 0;
}运行结果:

3、 追加重定向
追加重定向只需要将我们 open 的方式改为 O_APPEND 就行了。
int main(void)
{
// 追加重定向只要将我们打开文件的方式改为 O_APPEND 即可
int fd = open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
if (fd < 0) {
perror("open");
return 0;
}
dup2(fd, 1);
fprintf(stdout, "打开文件成功,fd: %d\n", fd);
fflush(stdout);
close(fd);
return 0;
}运行结果如下:

4、输入重定向
之前我们是如何读取键盘上的数据的?
int main(void)
{
int fd = open("log.txt", O_RDONLY);
if (fd < 0) {
perror("open");
return 0;
}
// 读数据
char line[64];
while (fgets(line, sizeof(line),stdin) != NULL) {
printf("%s\n", line);
}
fflush(stdout);
close(fd);
return 0;
}现在我们使用输入重新的,说白了就是将 "以前从我们键盘上去读" 改为 "在文件中读"。
代码演示:所以我们将 open 改为 O_RDONLY,dup(fd, 0) :
int main(void)
{
// 输入重定向
int fd = open("log.txt", O_RDONLY);
if (fd < 0) {
perror("open");
return 0;
}
// 将本来从键盘上读 (0),改为从文件里读(3)
dup2(fd, 0);
// 读数据
char line[64];
while (fgets(line, sizeof(line),stdin) != NULL) {
printf("%s\n", line);
}
fflush(stdout);
close(fd);
return 0;
}运行结果如下:

三、缓冲区的理解(Cache)
思考几个问题:
什么是缓冲区?为什么要有缓冲区?缓冲区在哪里?
对于缓冲区的概念,我们在 "进度条实现" 的插叙章节中有做探讨,但只是一个简单的讲解。
我们对缓冲区有一个共识,也知道它的存在,但我们还没有去深入理解它。
我们先来探讨第一个问题:
- 什么是缓冲区?缓冲区的本质就是一段内存。
- 为什么要有缓冲区?为了 解放使用缓冲区的进程时间。缓冲区的存在可以集中处理数据刷新,减少 IO 的次数,从而达到提高整机的效率的目的。
- 缓冲区在哪里?我们写一段代码来感受 "缓冲区" 的存在!
代码演示:用 printf 和 write 各自打印一段话
1 #include <stdio.h>
2 #include <sys/stat.h>
3 #include <sys/types.h>
4 #include <unistd.h>
5 #include<string.h>
6
7 int main(void)
8 {
9 printf("Hello printf\n"); // stdout -> 1
10 const char* msg = "Hello write\n";
11 write(1, msg, strlen(msg));
12
13 sleep(5); // 休眠五秒
14
15 return 0;
16 } 运行结果:
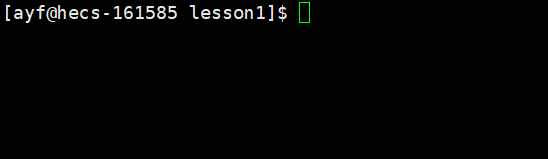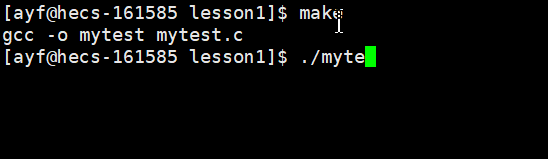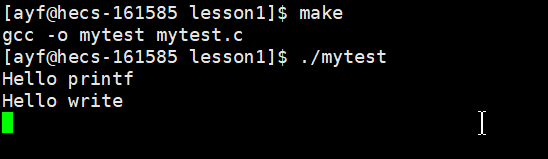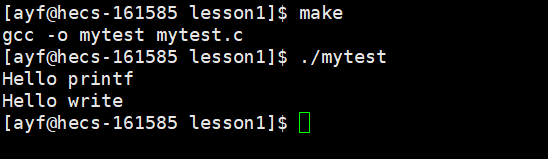
但是,如果我们去除 \n,我们就会发现 printf 的内容没有被立马打印,而 write 立马就出来了:

运行结果:
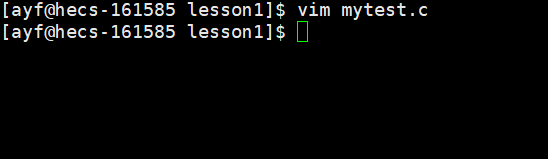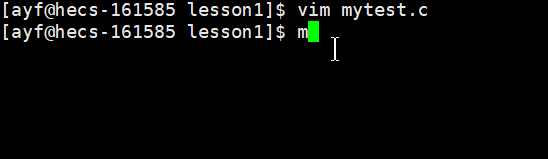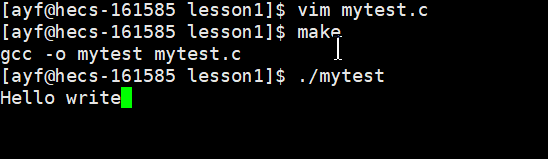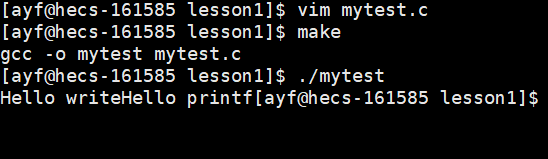
为什么sleep5s之后,才打印出hello printf????
1、语言级缓冲区
首先,我们要知道:printf 内部就是封装了 write!
printf 里打印的内容 "Hello printf" 实际上是在缓冲区里的,printf 不显示的原因是没有带 \n,数据没有被立即刷新,所以 sleep 时 printf 的内容没有被显示出来。
此时如果我们想让他刷新,可以手动加上 fflush(stdout) 刷新一下缓冲区。
至此我们说明了,printf 没有立即刷新的原因,是因为有缓冲区的存在。
可是,write 是立即刷新的!既然 printf 又封装了 write,那么缓冲区究竟在哪?
这个缓冲区一定不在 write 内部,因为如果这个缓冲区是函数内部提供的,那么直接刷新出来了。
所以这个缓冲区它只能是 C 语言提供的,该缓冲区是一个 语言级缓冲区 (语言级别的缓冲区) 。
我们再演示一次,这次选用 C 库函数 printf, fprintf 和 fputs,系统调用接口 write,观察其现象。
💬 代码演示:老样子,首先给它们都带上 \n
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
#include <string.h>
int main(void)
{
// 给它们都带上 \n
printf("Hello printf\n"); // stdout -> 1
fprintf(stdout, "Hello fprintf!\n");
fputs("Hello fputs!\n", stdout);
const char* msg = "Hello write\n";
write(1, msg, strlen(msg));
sleep(5);
return 0;
}运行结果:

代码演示:现在我们再把 \n 去掉:

运行结果:

此时结果是只有 write 内容先出,当退出时 printf, fprint, fputs 的东西才显示出来。
然而 write 无论带不带 \n 都会立马刷新,也就是说,只要 printf, fprint, fputs 调了 write 数据就一定显示。 我们继续往下深挖,stdout 的返回值是 FILE,FILE 内部有 struct,封装很多的成员属性,其中就包括 fd,还有该 FILE 对应的语言级缓冲区。
C 库函数 printf, fwrite, fputs... 都会自带缓冲区,但是 write 系统调用没有带缓冲区。
我们现在提及的缓冲区都是用户级别的缓冲区,为提高性能,OS 会提供相关的 内核级缓冲区。
库函数在系统调用的上层,是对系统调用做的封装,但是 write 没有缓冲区,这说明了:
该缓冲区是二次加上的,由 C 语言标准库提供,我们来看下 FILE 结构体:

放到缓冲区,当数据积累到一定程度时再刷。
2、fflush 是怎么运行的?
如果在刷新之前关闭了 fd,会有什么问题?
int main(void)
{
printf("Hello printf"); // stdout -> 1
fprintf(stdout, "Hello fprintf!");
fputs("Hello fprintf!", stdout);
const char* msg = "Hello write";
write(1, msg, strlen(msg));
close(1); // 直接把内部的文件关掉了,看你怎么刷
sleep(5);
return 0;
}运行结果:

之前的代码示例中,为了解决这个问题,我们用 fflush 冲刷缓冲区让数据 "变" 了出来:
int main(void)
{
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
fflush(stdout);
close(fd);
}运行结果:

重定向到文件中时不用 fflush,直接调 close 文件显示不出来的原因是:数据暂存到了缓冲区。
既然缓冲区在 FILE内部,在 C 语言中,我们每一次打开一个文件,都要有一个 FILE* 会返回。
这就意味着,每一个文件都有一个 fd 和属于它自己的语言级别缓冲区。
3、缓冲区的刷新策略
刷新策略,即什么时候刷新,刷新策略分为常规策略 和 特殊情况。
常规策略:
- 无缓冲 (立即刷新)
- 行缓冲 (逐行刷新)
- 全缓冲 (缓冲区打满,再刷新)
特殊情况:
- 进程退出
- 用户强制刷新(即调用 fflush)
下面我们运行一组代码:
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
const char* str1 = "hello printf\n";
const char* str2 = "hello fprintf\n";
const char* str3 = "hello fputs\n";
const char* str4 = "hello write\n";
// C 库函数
printf(str1);
fprintf(stdout, str2);
fputs(str3, stdout);
// 系统接口
write(1, str4, strlen(str4));
// 调用完了上面的代码,才执行的 fork
fork();
return 0;
}运行结果如下:

到目前为止还很正常,四个接口分别输出对应的字符串,打印出 4 行,没问题。
但如果我们此时重定向,比如输入 ./myfile > log.txt,怪事就发生了!log.txt 中居然有 7 条消息:
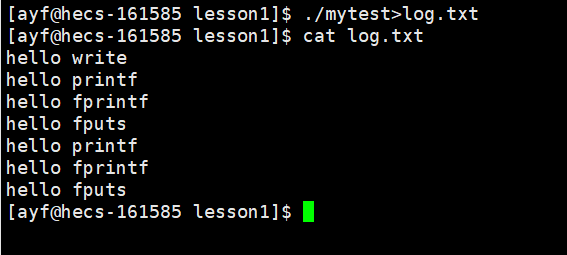
解读:当我们重定向后,本来要显示到显示器的内容经过重定向显示到了文件里,
- 如果对应的是显示器文件,刷新策略就是 行刷新
- 如果是磁盘文件,那就是 全刷新,即写满才刷新
然而这里重定向,由显示器重定向到了文件,缓冲区的刷新策略由 "行缓冲" 转变为 "全缓冲"。
文件中有 7 条,printf 出现 2 次,fprintf 出现 2 次,fputs 出现 2 次,但是 write 只有一次,
这和缓冲区有关,因为 write 压根不受缓冲区的影响。
fork 要创建子进程,之后父子进程无论谁先退出,它们都要面临的问题是:父子进程刷新缓冲区。
刷新的本质:把缓冲区的数据 write 到 OS 内部,清空缓冲区。
这里的 "缓冲区" 是自己的 FILE 内部维护的,属于父进程内部的数据区域。
所以当我们刷新时,代码和数据要发生写实拷贝,即父进程刷一份,子进程刷一份,
因而导致上面的现象,printf, fprintf, fputs 刷了 2 次到了 log.txt 中。
还有一点点,我们下次再讲,感谢阅读!!!!!!!!!