文章目录
- 第一章 GreenPlum介绍
- 1.MPP架构介绍
- 2.GreenPlum介绍
- 3.GreenPlum数据库架构
- 4.GreenPlum数据库优缺点
GreenPlum:https://cn.greenplum.org/
第一章 GreenPlum介绍
1.MPP架构介绍
MPP是Massively Parallel Processing的缩写,也就是大规模并行处理。MPP架构是一种用于处理大规模数据的计算架构,可以通过将任务分配给多个处理单元并行执行,以提高处理速度和性能。MPP架构的由来可以追溯到对大规模数据处理需求,传统的数据库模式无法满足这些需求。MPP架构允许在大规模数据集上实现水平扩展,通过添加更多的处理单元来增加计算和存储能力。
1) 分布式存储:MPP数据库系统通常使用分布式存储架构,将数据分散存储在多个节点。每个节点都有自己的存储单元,这样可以提高数据的读取和写入速度。
2) 并行处理:MPP架构通过将任务分解为小块,并同时在多个处理单元上执行这些任务来实现并行处理。每个处理单元负责处理数据的一个子集,然后将结果合并以生成最终的输出。
3) 共享无状态架构:MPP系统通过采用共享无状态的架构,即每个节点之间没有共享的状态。这使得系统更容易水平扩展,因为可以简单的添加更多的节点,而不需要共享状态的复杂管理。
4) 负载均衡:MPP数据库通常具有负载平衡的机制,确保任务在各个节点上均匀分布,避免某些节点成为性能瓶颈。
5) 高可用性:为了提高系统的可用性,MPP架构通常设计成具有容错和故障恢复机制。如果一个节点出现故障,系统可以继续运行,而不会丢失数据或中断服务。
一些知名的MPP数据库系统,比如GreenPlum,Doris, Teradata、Netezza、Vertica等。这些MPP数据库广泛应用于企业数据仓库、商业智能和大数据分析等领域。总体而言,MPP架构通过将任务分布到多个节点并行执行,以及有效的利用分布式存储和处理方式,提高了一种高性能、可伸缩的数据处理解决方案,适用于处理大规模数据的场景。
2.GreenPlum介绍
GreenPlum数据库是一种大规模并行处理(MPP)数据库服务器,其架构特别针对管理大规模分析型数据仓库以及商业智能工作负载而设计。
MPP(也被成为shared nothing架构)指有两个或更多处理器协同执行一个操作的系统,每一个处理器都有其自己的内存、操作系统和磁盘。GreenPlum使用这种高性能系统架构来分布数据仓库负载,并且能够使用系统的所有资源并行处理一个查询。
GreenPlum数据库是基于PostgreSQL开源技术的。它本质上是多个PostgreSQL面向磁盘的数据库实例一起工作形成的一个紧密结合的数据库管理系统(DBMS)。它基于PostgreSQL开发,其SQL支持、特性、配置选项和最终用户功能在大部分情况霞和PostGreSQL非常相似。与GreenPlum数据库交互的数据库用户会感觉在使用一个常规的PostgreSQL DBMS。
GreenPlum数据库可以使用追加优化(append-optimized,AO)的存储格式来批量装载和读取数据,并且能够提供HEAP表上的性能优势。追加优化的存储为数据保护、压缩和行/列方向提供了校验和。行式或者列式追加优化的表都可以被压缩。
GreenPlum数据库和PostgreSQL的主要区别在于:
1)在基于Postgres查询规划器的常规查询规划器之外,可以利用GPORCA进行查询规划。
2)GreenPlum数据库可以使用追加优化的存储。
3)GreenPlum数据库可以选用列式存储,数据在逻辑上还是组织成一个表,单其中的行和列在物理上是存储在一种面向列的格式中,而不是存储成行。列式存储只能和追加优化表一起使用。列式存储是可压缩的。当用户只需要返回感兴趣的列时,列式存储可以提供更好的性能。所有压缩算法都可以用在行式或者列式存储的表上,但是行程编码(RLE)压缩只能用于列式存储的表。GreenPlum数据库在所有使用列式存储的追加优化表上都提供了压缩。
3.GreenPlum数据库架构

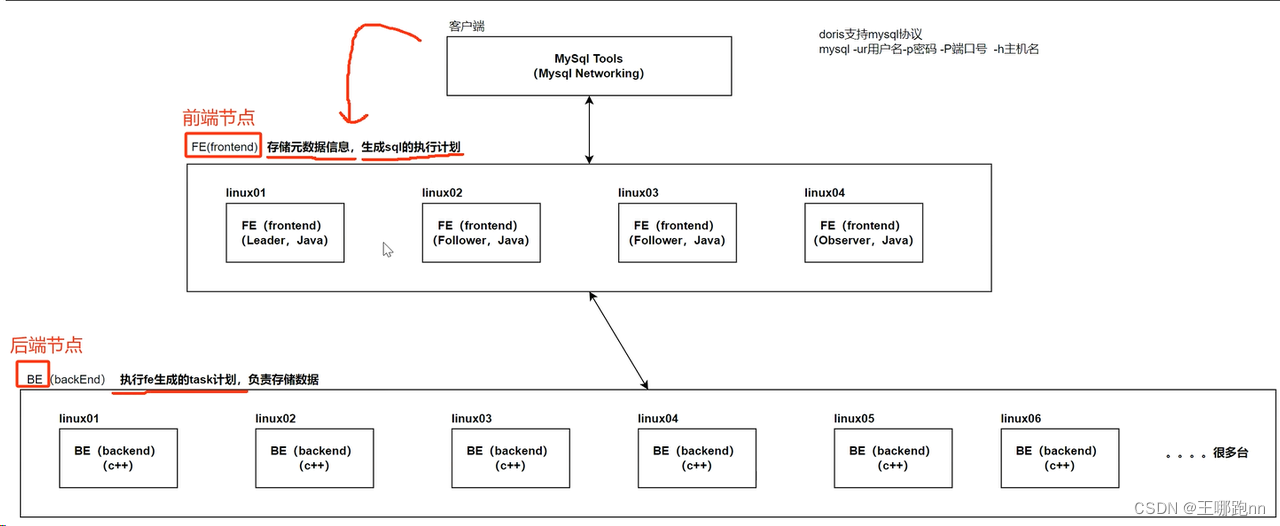
GreenPlum数据库是由Master Server、Segment Server和Interconnect三部分组成,Interconnect在Master和Segment之间起到了桥梁的作用。
GreenPlum是一个关系型数据库,由数个独立的数据服务组成的逻辑数据库,整个集群由多个数据节点(Segment)和控制节点(Master)组成。在典型的Shared-Nothing中,每个节点上所有的资源的CPU、内存、磁盘都是独立的,每个节点都只有全部数据的一部分,也只能使用本节点的数据资源。在GreenPlum中,需要存储的数据在进入到表时,将先进行数据分布的处理工作,将一个表中的数据平均分布到每个节点上,并未每个表指定一个分布列(Distribute Column),之后便根据Hash来分布数据,基于Shared-Nothing的原则,GreenPlum这样处理可以充分发挥每个节点处IO的处理能力。
1)Master节点:Master是整个系统的控制中心和堆外的服务接入点,它负责接收用户SQL请求,将SQL生成查询计划并进行处理优化,然后将查询计划分配到所有Segment节点并进行处理,协调组织各Segment节点按照查询计划一步一步的进行并行处理,最后获取到Segment的计算结果,再返回给客户端。从用户的角度看GreenPlum集群,看到的只是Master节点,无需关心集群内部的机制,所有的并行处理都是在Master控制下自动完成的。Master节点一般配备一个Standby节点。
2)Segment节点:Segment是GreenPlum执行并行任务的并行计算节点,它接收Master指令进行MPP并行计算,因此所有Segment节点的计算性能总和就是整个集群的性能,通过增加Segment节点,可以线性化的增加集群处理性能和存储容量,Segment节点可以是1-10000个节点。
3)InterConnect:InterConnect是Master节点和Segment节点、Segment节点之间进行数据传输的组件,基于千兆交换机或者万兆交换机实现数据在节点之间的高速传输。
外部数据在加载到Segment时,采用并行数据流进行加载,直接加载到Segment节点,这项独特的技术是GreenPlum的专有技术,保证数据在最短时间内加载到数据库中。
4.GreenPlum数据库优缺点
1)优点
1.1)数据存储:数据激增,采用MPP架构的数据库系统可以对海量数据进行管理。
1.2)高并发:拥有强大并行处理能力提供并发支持。
1.3)线性扩展:线性扩展为数据分析系统的扩展提供技术上的保证,用户可根据实际实施需要进行容量和性能的扩展。
1.4)高性价比:基于业界开放式硬件平台,在普通的x86 server上就能达到很高的性能,因此性价比很高。
1.5)处理速度:GreenPlum通过准实时、实时的数据加载方式,实现数据仓库的实时更新,进而实现动态数据仓库。
1.6)高可用性:对于主节点,GreenPlum提供Master/Standby机制进行主节点容错,当主节点发生错误时,可以切换到Standby节点继续服务。
1.7)系统易用:GreenPlum产品是基于流行的PostgreSQL之上开发,几乎所有的PostgreSQL客户端工具及PostgreSQL应用都能运行在GreenPlum平台上,在Internet上有丰富的资源支持。
2)缺点
2.1):主从双层架构,并非真正的扁平架构,存在性能瓶颈和SPOF单点故障。
2.2):无法支持数据压缩态下的DML操作,不易于数据的维护和更新。
2.3):单个节点上的数据库没有并行和大内存实用能力,必须通过部署多个实例(segmenr server)来充分利用系统资源,造成使用和部署很复杂。