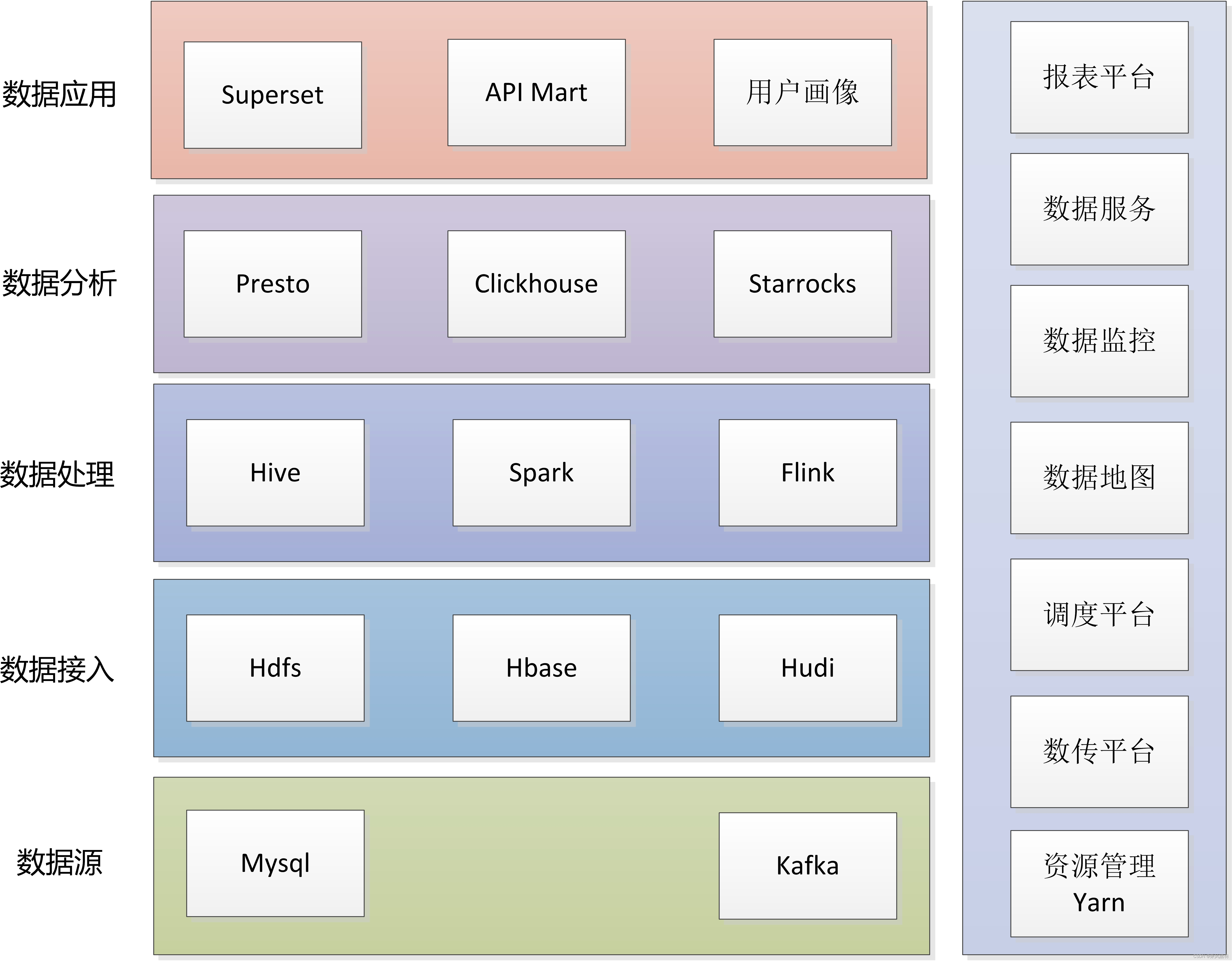
TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution )模型中文叫做“逼近理想解排序方法”,是根据评价对象与理想化目标的接近程度进行排序的方法,是一种距离综合评价方法。基本思路是通过假定正、负理想解,测算各样本与正、负理想解的距离,得到其与理想方案的相对贴近度(即距离正理想解越近同时距离负理想解越远),进行各评价对象的优劣排序。
设定理想点,比较理想点与评价对象指标的接近程度
找出最优与最最差,比较程度
常用的综合评价方法,充分利用原始数据
指标很多数据已知的评分问题
前面不适合指标太多的
前面都是主观的,没数据
指标的处理(正向化)
效益类
极小类
中间型
区间型

指标处理(标准化)

计算距离:

计算各评价对象与最优方案的贴近程度。正其中
的取值范围为[0,1],越接近1表明样本评分越好。

很容易得到上述步骤
熵权法
熵越大说明系统越混乱,携带的信息越少,权重越小;熵越小说明系统越有序,携带的信息越多,权重越大。
熵权法:原理:指标方差越少,信息量越少
由于权重不客观,因此topsis可以结合熵值法进行应用
熵权法是一种客观赋值方法,本质是指标的变异程度越小,所反映的信息就越少,所对应的权值就越低。
先给出原始数据矩阵
再归一化,标准化
再计算样本标志值比重
得到比重矩阵
再计算熵值
再计算差异程度
再定义权重









![cube生成电机库,启用了RTOS,编译报错[0xc43ed8:5050106] in osSignalWait](https://img-blog.csdnimg.cn/direct/15fe9f721670494eafb802ad51243b2a.png)