目录
一、概述
1、简介
2、架构
3、使用场景
二、安装
三、基本概念
1、数据模型
列(Column)
列族
KeySpace
节点(Node)
集群(Cluster)
2、数据类型
基础类型
集合类型
自定义数据类型
四、操作
1.客户端操作
cqlsh的基本命令
CQL-查询语言
Keyspace
表操作
索引操作
CRUD操作
2.JAVA操作
一、概述
1、简介
Apache Cassandra是高度可扩展的,高性能的分布式NoSQL数据库。 提供高可用性而无需担心单点故障。具有能够处理大量数据的分布式架构。 数据放置在具有多个复制因子的不同机器上,以获得高可用性,而无需担心单点故障。

特性:
- 弹性可扩展性 - Cassandra是高度可扩展的; 它允许添加更多的硬件以适应更多的客户和更多的数据根据要求。
- 始终基于架构 - Cassandra没有单点故障,它可以连续用于不能承担故障的关键业务应用程序。
- 快速线性性能 - Cassandra是线性可扩展性的,即它为你增加集群中的节点数量增加你的吞吐量。因此,保持一个快速的响应时间。
- 灵活的数据存储 - Cassandra适应所有可能的数据格式,包括:结构化,半结构化和非结构化。它可以根据您的需要动态地适应变化的数据结构。
- 便捷的数据分发 - 可以在多个数据中心之间复制数据,可以灵活地在需要时分发数据。
- 事务支持 - Cassandra支持属性,如原子性,一致性,隔离和持久性(ACID)。
- 快速写入 - Cassandra被设计为在廉价的商品硬件上运行。 它执行快速写入,并可以存储数百TB的数据,而不牺牲读取效率。
2、架构
Cassandra中的数据分布在集群中的所有节点上,处理多个节点之间的大数据工作负载,而无需担心单点故障。各个节点是相互独立的,但同时与其他节点互连,平等地址。每个阶段都可以进行读写操作,如果其中一个节点发生故障,其他节点也可以继续提供读写请求。
在Cassandra中,集群中的节点作为给定数据片段的副本。 如果某些节点以超时值响应,Cassandra会将最新的值返回给客户端。 返回最新值后,Cassandra会在后台执行读取修复,以更新旧值。
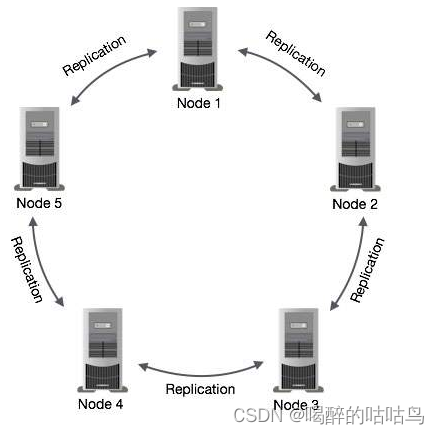
结构组成:
- 节点(Node):Cassandra节点是存储数据的地方。
- 数据中心(Data center):数据中心是相关节点的集合。
- 集群(Cluster):集群是包含一个或多个数据中心的组件。
- 提交日志(Commit log):每个写入操作都将写入提交日志,用户异常恢复数据。
- 存储表(Mem-table):内存表是内存驻留的数据结构。 提交日志后,数据将被写入内存表。 有时,对于单列系列,将有多个内容表。
- SSTable:当内容达到阈值时,它是从内存表刷新数据的磁盘文件。
- 布鲁姆过滤器(Bloom filter):这些只是快速,非确定性的,用于测试元素是否是集合成员的算法。 它是一种特殊的缓存。 每次查询后都会访问Bloom过滤器。
3、使用场景
特征
- 数据写入操作密集
- 数据修改操作很少
- 通过主键查询
- 需要对数据进行分区存储
场景举例
- 存储日志型数据
- 类似物联网的海量数据
- 对数据进行跟踪官网
官网
二、安装
docker pull cassandradocker run -d -p 9042:9042 --name cassandra cassandra:latest进入cassandra的命令行
docker exec -it cassandra bash
cqlshcassandra数据存放位置共有三处地方:
data目录:
用于存储真正的数据文件,即SSTable文件。如果服务器有多个磁盘,可以指定多个目录,每一个目录都在不同的磁盘中。这样Cassandra就可以利用更多的硬盘空间。在data目录下,Cassandra 会将每一个 Keyspace 中的数据存储在不同的文件目录下,并且 Keyspace 文件目录的名称与 Keyspace 名称相同。
commitlog目录:
用于存储未写入SSTable中的数据,每次Cassandra系统中有数据写入,都会先将数据记录在该日志文件中,以保证Cassandra在任何情况下宕机都不会丢失数据。如果服务器有足够多的磁盘,可以将本目录设置在一个与data目录和cache目录不同的磁盘中,以提升读写性能。
cache目录:
用于存储系统中的缓存数据。
配置文件cassandra.yaml进行修改配置。
cassandra.yaml说明查看
三、基本概念
1、数据模型
Cassandra的数据模型与常见的关系型数据库的数据模型有很大的不同
列(Column)
列是Cassandra的基本数据结构单元,具有三个值:名称,值、时间戳

列(Column)不需要预先定义,只需要在KeySpace里定义列族,然后就可以开始写数据了。
列族
列族相当于关系数据库的表(Table),是包含了多行(Row)的容器。
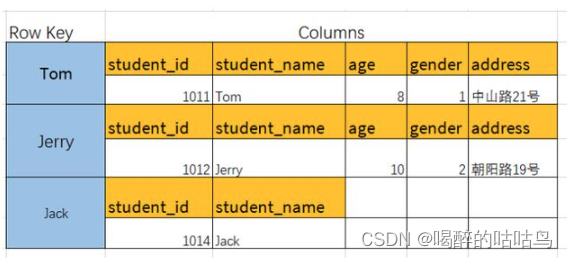
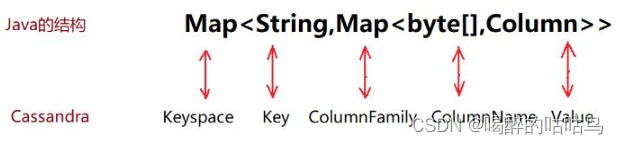
可以理解为Java结构 Map>,如图:
1)Row key
ColumnFamily 中的每一行都用Row Key(行键)来标识,这个相当于关系数据库表中的主键,并且总是被索引的。
2)主键
Cassandra可以使用PRIMARY KEY 关键字创建主键,主键分为2种
1.单键(一个字段) 2.组合键(多个字段组成)
列族具有以下属性 -
- keys_cached - 它表示每个SSTable保持缓存的位置数。
- rows_cached - 它表示其整个内容将在内存中缓存的行数。
- preload_row_cache -它指定是否要预先填充行缓存。
KeySpace
Cassandra的键空间(KeySpace)相当于数据库,我们创建一个键空间就是创建了一个数据库。键空间包含一个或多个列族(Column Family)
注意:一般将有关联的数据放到同一个 KeySpace 下面,建空间 (KeySpace) 创建的时候可以指定一些属性:副本因子,副本策略,Durable_writes(是否启用 CommitLog 机制)
副本因子:
副本就是把数据存储到多个节点,来提高容错性。副本因子决定数据有几份副本。例如:副本因子为1表示每一行只有一个副,。副本因子为2表示每一行有两个副本,每个副本位于不同的节点上。在实际应用中为了避免单点故障,会配置为3以上。
注意:副本没有主从之分。可以为每个数据中心定义副本因子。副本策略设置应大于1,但是不能超过集群中的节点数。
副本策略:
描述的是副本放在集群中的策略,目前有2种策略,内容如下:
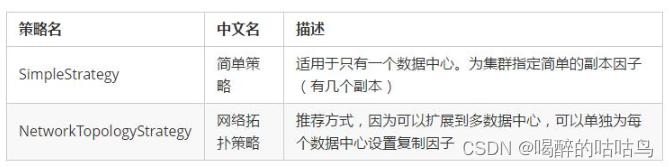
Durable_writes:
是否启用 CommitLog 机制,默认为true
节点(Node)
存储数据的机器
集群(Cluster)
Cassandra数据库是为跨越多条主机共同工作,对用户呈现为一个整体的分布式系统设计的。Cassandra最外层容器被称为群集。Cassandra将集群中的节点组织成一个环(ring),然后把数据分配到集群中的节点(Node)上。
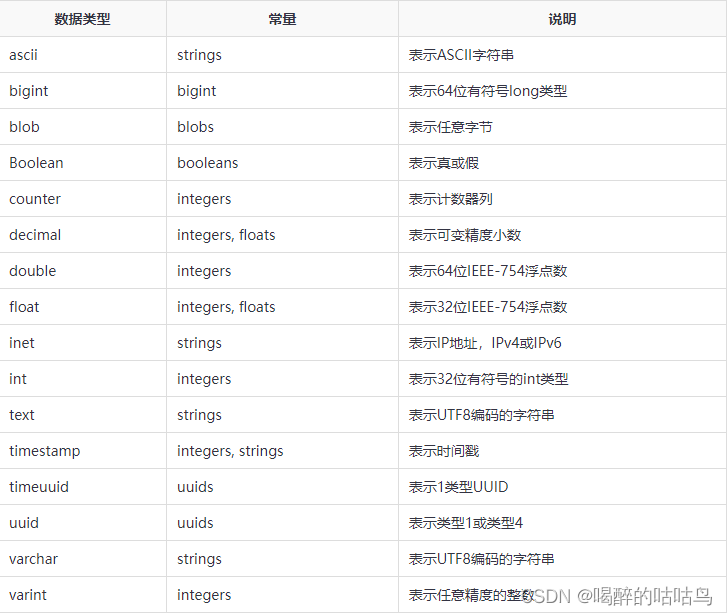
2、数据类型
基础类型
集合类型

Map:
1、集合的每一项最大是64K。 2、保持集合内的数据不要太大,免得Cassandra 查询延时过长,Cassandra 查询时会读出整个集合内的数据,集合在内部不会进行分页,集合的目的是存储小量数据。 3、不要向集合插入大于64K的数据,否则只有查询到前64K数据,其它部分会丢失。
自定义数据类型
Cqlsh为用户提供了创建自己的数据类型的功能。 下面给出了处理用户定义的数据类型时使用的命令。
- CREATE TYPE - 创建用户定义的数据类型。
- ALTER TYPE - 修改用户定义的数据类型。
- DROP TYPE - 删除用户定义的数据类型。
- DESCRIBE TYPE - 描述用户定义的数据类型。
- DESCRIBE TYPES - 描述用户定义的数据类型。
四、操作
操作类型:
1.客户端操作
docker exec -it my_cassandra /bin/bash
cd bin
cqlshcqlsh的基本命令
| 选项 | 使用/作用 |
| help | 此命令用于显示有关CQLsh命令选项的帮助主题。 |
| version | 它用于查看您正在使用的CQLsh的版本。 |
| color | 它用于彩色输出。 |
| debug | 它显示其他调试信息。 |
| execute | 它用于引导shell接受并执行CQL命令。 |
| show | 显示当前会话详情 |
help 可以查看cqlsh 支持的命令
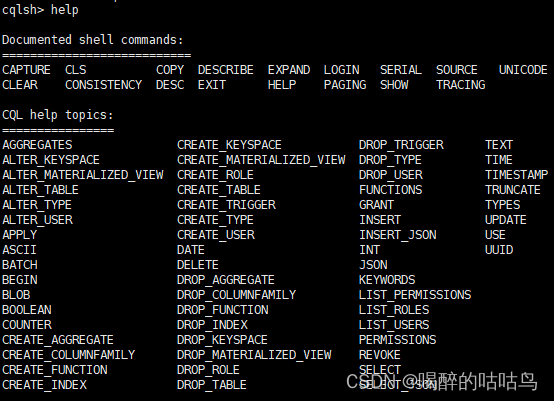
Describe cluster 提供有关集群的信息
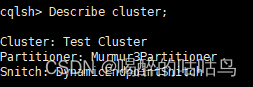
Describe Keyspaces:显示当前Cassandra里的所有键空间

Describe tables 列出键空间的所有表
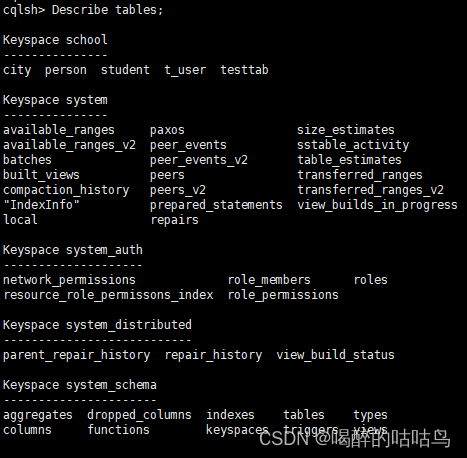
CQL-查询语言
数据定义命令
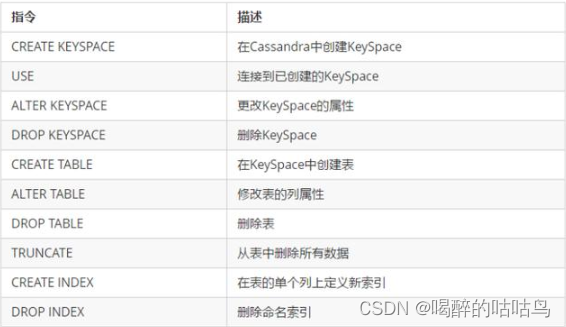
Keyspace
1、创建
语法:
CREATE KEYSPACE <identifier> WITH <properties>
具体语法:
Create keyspace KeyspaceName with replicaton={'class':strategy name,
'replication_factor': No of replications on different nodes}
- KeyspaceName 代表键空间的名字
- strategy name 代表副本放置策略,内容包括:简单策略、网络拓扑策略,选择其中的一个。
- No of replications on different nodes 代表 复制因子,放置在不同节点上的数据的副本数。
新建:
CREATE KEYSPACE company WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
CREATE KEYSPACE test_keyspace WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 } AND DURABLE_WRITES = false;
验证:
DESCRIBE keyspaces ;
DESCRIBE company ;
2、使用键空间
USE <identifier>USE company;
3、修改键空间
语法:
ALTER KEYSPACE <identifier> WITH <properties>
或者 -
ALTER KEYSPACE "KeySpace Name" WITH replication = {'class': 'Strategy name',
'replication_factor' : 'No.Of replicas'};
又或者 -
Alter Keyspace KeyspaceName with replication={'class':'StrategyName',
'replication_factor': no of replications on different nodes}
with DURABLE_WRITES=true/false
注意:
- Keyspace Name: Cassandra中的键名称不能更改。
- Strategy Name: 可以通过使用新的策略名称来更改战略名称。
- Replication Factor : 可以通过使用新的复制因子来更改复制因子。
- DURABLE_WRITES:可以通过指定其值true / false来更改。 默认情况下为true。 如果设置为false,则不会将更新写入提交日志,反之亦然。
修改:
alter KEYSPACE company WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 1};
验证:
DESCRIBE company ;
4、删除键空间
DROP KEYSPACE <identifier>DROP KEYSPACE company;
表操作
注意:操作前,先把键空间company键空间创建,并使用company键空间.
CREATE KEYSPACE company WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 1};
use company;
1、查看所有的表
DESCRIBE TABLES;
2、创建表
CREATE (TABLE | COLUMNFAMILY) <tablename>
('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)
CREATE TABLE t_user(
id int PRIMARY KEY,
name text,
age int,
gender tinyint,
address text ,
interest set<text>,
phone list<text>,
education map<text, text>
);验证
DESCRIBE TABLE t_user;
主键有两种类型:
- 单个主键:对单个主键使用以下语法。
Primary key (ColumnName) - 复合主键:对复合主键可使用以下语法。
Primary key(ColumnName1,ColumnName2 . . .) 或- Primary key((key_part_one,key_part_two),ColumnName2 . . .) key_part_one:称作Partition Key,Cassandra会对其做一个hash计算,决定放在哪个节点。 key_part_two:CLUSTERING KEY
3、修改表结构
语法,可以添加列,删除列
添加一列:
ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>
删除一列:
ALTER table name DROP name;
ALTER TABLE t_user ADD email text;
ALTER table t_user DROP email;
4、删除表
DROP TABLE <tablename>5、清空表
TRUNCATE <tablename>索引操作
1、普通列创建索引
CREATE INDEX <identifier> ON <tablename>创建索引的规则
- 由于主键已编入索引,因此无法在主键上创建索引。
- 在Cassandra中,不支持集合索引。
- 没有对列进行索引,Cassandra无法过滤该列,除非它是主键。
CREATE INDEX sname ON t_user(name);
索引原理:
Cassandra自动新创建了一张表格,同时将原始表格之中的索引字段作为新索引表的Primary Key!并且存储的值为原始数据的Primary Key.
2、集合列创建索引
CREATE INDEX ON t_user(interest); -- set集合添加索引
CREATE INDEX mymap ON t_user(KEYS(education)); -- map结合添加索引
3、删除索引
DROP INDEX <identifier>
CRUD操作
数据操作指令
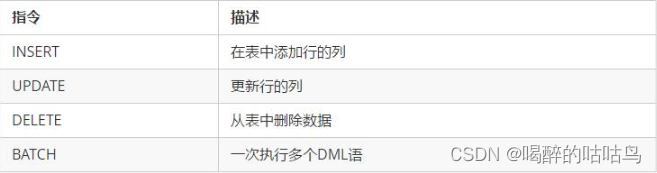
查询指令
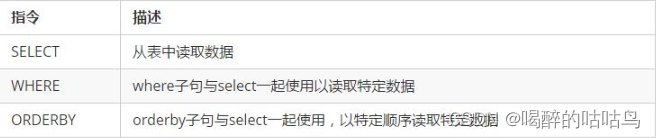
1、插入数据
INSERT INTO <tablename>
(<column1 name>, <column2 name>....)
VALUES (<value1>, <value2>....)
USING <option>
INSERT INTO t_user(id, address, age, education, gender, interest, name, phone)
VALUES (1,'dizhi',12,{'code':'12'},1,{'yestouu@gmail.com'},'zs',['123456','1234']);
INSERT INTO t_user(id, address, age, education, gender, interest, name, phone)
VALUES (2,'dizhi',12,{'code':'12'},1,{'yestouu@gmail.com'},'zs',['123456','1234']);
INSERT INTO t_user(id, address, age, education, gender, interest, name, phone)
VALUES (3,'dizhi',12,{'code':'12'},1,{'yestouu@gmail.com'},'zs',['123456','1234']);
2、更新数据
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>
又或者 -
Update KeyspaceName.TableName
Set ColumnName1=new Column1Value,
ColumnName2=new Column2Value,
ColumnName3=new Column3Value,
.
.
.
Where ColumnName=ColumnValue
update t_user set age=2,phone=['1'] where id =1;
#更新set类型数据
update t_user set interest= interest + {'aa'} where id = 1;
update t_user set interest = interest - {'aa'} where id = 1;
update t_user set interest = {} WHERE id = 1;
#更新list类型数据
update t_user set phone = [ '030-55555555' ] + phone where id= 1;
update t_user set phone = phone + [ '040-33333333' ] where id= 1;
update t_user set phone[2] = '050-22222222' where id= 1;
update t_user set phone = phone - ['020-66666666'] where id= 1;
update t_user set phone =[] where id= 1;
#更新map类型数据update t_user set education={'e': 'f'} where id= 1;
#UPDATE命令设置指定元素的value
update t_user set education['e']='g' where id= 1;
update t_user set education = education + {'a':'b','c':'d'} where id= 1;
update t_user set education=education - {'a','c'} WHERE id = 1;
UPDATE t_user SET education={} WHERE id = 1;
3、删除数据
DELETE FROM <identifier> WHERE <condition>;
delete from t_user where id=1;
#删除某个字段
delete interest FROM t_user WHERE id= 1;
4、查询数据
使用 SELECT 、WHERE、LIKE、GROUP BY 、ORDER BY等关键词
SELECT FROM <tablename>
SELECT FROM <table name> WHERE <condition>;
查询所有数据
select * from t_user;
根据主键查询
select * from t_user where id =1;
查询时使用索引
注意事项:
- Primary Key 只能用 = 号查询
- 第二主键 支持= > < >= <=
- 索引列 只支持 = 号
- 非索引非主键字段过滤可以使用ALLOW FILTERING
create table student (
key_one int,
key_two int,
name text,
age int,
PRIMARY KEY(key_one, key_two)
);
create INDEX tage ON student (age);key_one 是第一主键,key_two是第二主键,age是索引列,name是普通列
insert into student(key_one,key_two,name,age) values(1,2,'a',2);
insert into student(key_one,key_two,name,age) values(2,3,'b',2);
insert into student(key_one,key_two,name,age) values(3,4,'c',2);
insert into student(key_one,key_two,name,age) values(4,5,'d',2);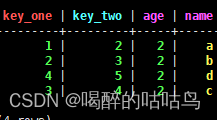
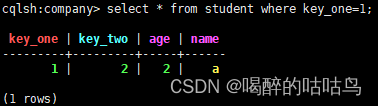
第一主键 只能用=号查询
select * from student where key_one=1;
select * from student where key_one>1;

如果需要完成这个查询,可以使用 ALLOW FILTERING
select * from student where key_one>1 ALLOW FILTERING;
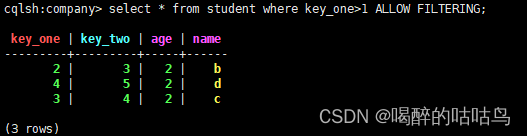
注意:加上ALLOW FILTERING 后确实可以查询出数据,但是不建议这么做
第二主键 支持 = 、>、 <、 >= 、 <=
key_two是第二主键,不要单独对key_two 进行 查询,
select * from student where key_two = 2;

如果需要完成这个查询,可以使用 ALLOW FILTERING
select * from student where key_two = 2 ALLOW FILTERING;

注意:加上ALLOW FILTERING 后确实可以查询出数据,但是不建议这么做
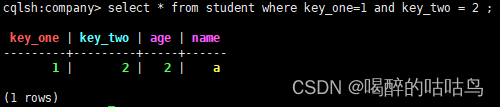
正确用法:
select * from student where key_one=1 and key_two = 2 ;
索引列 只支持=号
select * from student where age = 2;
普通列,非索引非主键字段
普通列,在查询时需要使用ALLOW FILTERING
select * from student where key_one =1 and name='a';

select * from student where key_one =1 and name='a' ALLOW FILTERING;

集合列
ALTER TABLE student ADD email set<text>;
ALTER TABLE student ADD phone list<text>;
ALTER TABLE student ADD education map<text, text>;
create INDEX temail ON student (email);
create INDEX tphone ON student (phone);
create INDEX teducation ON student (education);
insert into student(key_one,key_two,name,age,email,phone,education) values(6,7,'d',2,{'1234'},['1'],{'info':'张三'});
insert into student(key_one,key_two,name,age,email,phone,education) values(7,8,'d',2,{'1234'},['1'],{'info':'张四'});
使用where子句的CONTAINS条件按照给定的值进行过滤。
select * from student where email CONTAINS '1234'; -- 查询set集合
select * from student where education CONTAINS key 'info' allow filtering; --查询map集合的key值
select * from student where education CONTAINS '张四'; --查询map的value值
ALLOW FILTERING
ALLOW FILTERING是一种非常消耗计算机资源的查询方式。 如果表包含例如100万行,并且其中95%具有满足查询条件的值,则查询仍然相对有效,这时应该使用ALLOW FILTERING。
如果表包含100万行,并且只有2行包含满足查询条件值,则查询效率极低。Cassandra将无需加载999,998行。如果经常使用查询,则最好在列上添加索引。
ALLOW FILTERING在表数据量小的时候没有什么问题,但是数据量过大就会使查询变得缓慢。
查询时排序
cassandra也是支持排序的,order by。 排序也是有条件的
1.必须有第一主键的=号查询
cassandra的第一主键是决定记录分布在哪台机器上,cassandra只支持单台机器上的记录排序。
2.只能根据第二、三、四…主键进行有序的,相同的排序。
3.不能有索引查询
cassandra的任何查询,最后的结果都是有序的,内部就是这样存储的。
select * from student where key_one = 1 order by key_two;
select * from student where key_one = 1 and age =2 order by key_two; --错误,不能有索引查询
分页查询
使用limit 关键字来限制查询结果的条数 进行分页
select * from student where key_one = 1 order by key_two limit 1;
批量操作
多次更新操作合并为一次请求,减少客户端和服务端的网络交互。 batch中同一个partition key的操作具有隔离性.
使用BATCH,可以同时执行多个修改语句(插入,更新,删除)
BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCH 
BEGIN BATCH
INSERT INTO t_user(id, address, age, education, gender, interest, name, phone) VALUES (5,'dizhi',12,{'code':'12'},1,{'yestouu@gmail.com'},'zs',['123456','1234']);
UPDATE t_user set age = 11 where id= 1;
DELETE FROM t_user WHERE id=2;
APPLY BATCH;
2.JAVA操作
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-cassandra</artifactId>
</dependency># 应用名称
spring:
application:
name: spring-lean-cassandra
data:
cassandra:
contact-points: 192.168.56.1
port: 9042
local-datacenter: datacenter1
session-name: cassandraCluster
username:
password:
keyspace-name: company
# 应用服务 WEB 访问端口
server:
port: 9088
手动创建 keyspace和表。
CREATE TABLE person
(
id int,
name text,
name_cn text,
age int,
PRIMARY KEY (id)
);
CREATE TABLE city
(
id int,
name text,
persons list<text>,
PRIMARY KEY (id)
);
CREATE TABLE t_user
(
id int,
name text,
age int,
books list<text>,
PRIMARY KEY (id)
);
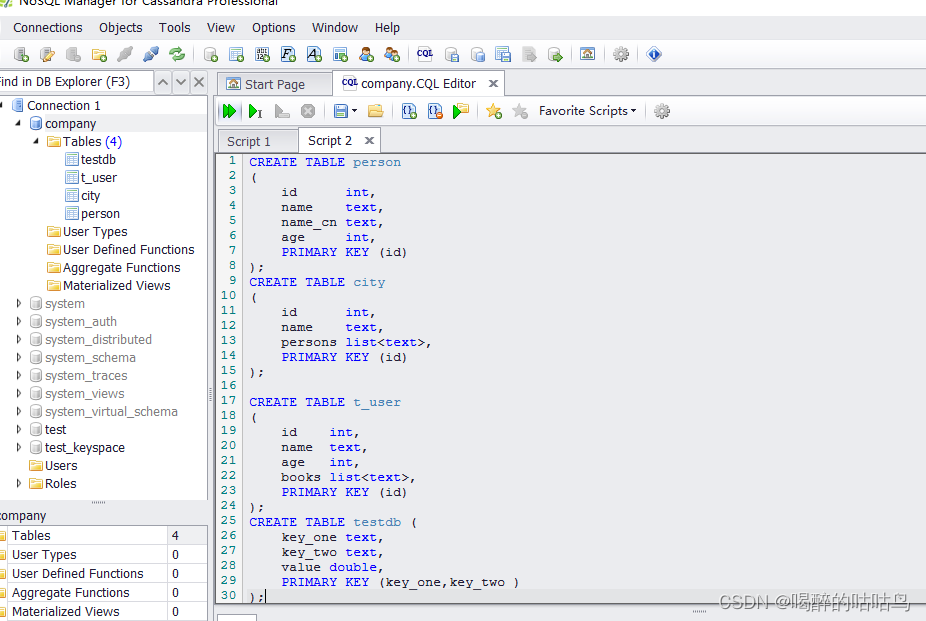
CREATE TABLE testdb (
key_one text,
key_two text,
value double,
PRIMARY KEY (key_one,key_two )
);
import lombok.Data;
import org.springframework.data.cassandra.core.mapping.*;
import java.util.List;
@Data
@Table
public class City {
@PrimaryKey
private int id;
private String name;
private List<String> persons;
}
import lombok.Data;
import org.springframework.data.cassandra.core.mapping.Column;
import org.springframework.data.cassandra.core.mapping.PrimaryKey;
import org.springframework.data.cassandra.core.mapping.Table;
@Data
@Table
public class Person {
@PrimaryKey
private Integer id;
private String name;
@Column(value = "name_cn")
private String nameCn;
private Integer age;
}
import lombok.Data;
import org.springframework.data.cassandra.core.mapping.PrimaryKey;
import org.springframework.data.cassandra.core.mapping.Table;
import java.io.Serializable;
import java.util.List;
@Data
@Table("t_user")
public class User implements Serializable {
@PrimaryKey
private int id;
private String name;
private int age;
private List<String> books;
}
import lombok.Data;
import org.springframework.data.cassandra.core.cql.PrimaryKeyType;
import org.springframework.data.cassandra.core.mapping.Column;
import org.springframework.data.cassandra.core.mapping.PrimaryKeyColumn;
import org.springframework.data.cassandra.core.mapping.Table;
@Data
@Table("testdb")
public class TestDb {
@PrimaryKeyColumn(value = "key_one",type = PrimaryKeyType.PARTITIONED)
private String keyOne;
@PrimaryKeyColumn(value = "key_two",type = PrimaryKeyType.CLUSTERED)
private String keyTwo;
@Column("value")
private double value;
}import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.cassandra.repository.config.EnableCassandraRepositories;
@EnableCassandraRepositories
@SpringBootApplication
public class SpringLeanCassandraApplication {
public static void main(String[] args) {
SpringApplication.run(SpringLeanCassandraApplication.class, args);
}
}第一种方式:集成CassandraRepository对象。
import com.lean.cassandra.entity.City;
import org.springframework.data.cassandra.repository.CassandraRepository;
public interface CityRepository extends CassandraRepository<City, Integer> {
}
import com.lean.cassandra.entity.Person;
import org.springframework.data.cassandra.repository.AllowFiltering;
import org.springframework.data.cassandra.repository.CassandraRepository;
public interface PersonRepository extends CassandraRepository<Person, Integer> {
/**
* 根据名字查询
*
* @param name 名字
* @return Person
*/
@AllowFiltering
Person findByName(String name);
}第二种方式:使用CassandraTemplate进行操作。
import com.lean.cassandra.entity.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.cassandra.core.CassandraTemplate;
import org.springframework.data.cassandra.core.query.Query;
import org.springframework.stereotype.Service;
import java.io.Serializable;
import java.util.List;
@Service
public class UserService {
@Autowired
private CassandraTemplate cassandraTemplate;
public void saveUser(User user){
cassandraTemplate.insert(user);
}
public void batchSaveUser(List<User> userList){
cassandraTemplate.batchOps().insert(userList);
}
public void updateUser(User user){
cassandraTemplate.update(user);
}
public User getById(Serializable id) {
return cassandraTemplate.selectOneById(id, User.class);
}
public User getObj(Query query) {
return cassandraTemplate.selectOne(query, User.class);
}
public List<User> listObjs(Query query) {
return cassandraTemplate.select(query, User.class);
}
}
package com.lean.cassandra.service;
import com.lean.cassandra.entity.TestDb;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.cassandra.core.CassandraTemplate;
import org.springframework.data.cassandra.core.query.Criteria;
import org.springframework.data.cassandra.core.query.Query;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class TestDbService {
@Autowired
private CassandraTemplate cassandraTemplate;
public TestDb save(TestDb testDb) {
return cassandraTemplate.insert(testDb);
}
public List<TestDb> query(TestDb testDb) {
return cassandraTemplate.select("select * from testdb where key_one = '"+testDb.getKeyOne()+"';", TestDb.class);
}
public boolean delete(TestDb testDb) {
return cassandraTemplate.delete(Query.query(Criteria.where("key_one").is(testDb.getKeyOne())).and(Criteria.where("key_two").lte(testDb.getKeyTwo())), TestDb.class);
}
}
测试:
第一种:
import com.lean.cassandra.entity.City;
import com.lean.cassandra.entity.Person;
import com.lean.cassandra.repository.CityRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.LinkedList;
import java.util.List;
@SpringBootTest
public class CityRepositoryTest {
@Autowired
private CityRepository cityRepository;
@Test
public void save() {
List<String> list = new LinkedList<>();
for (int i = 0; i < 20; i++) {
Person person = new Person();
person.setId(i + 1);
person.setAge(18 + i);
person.setName("test" + (i + 1));
person.setNameCn("测试" + (i + 1));
list.add(person.toString());
}
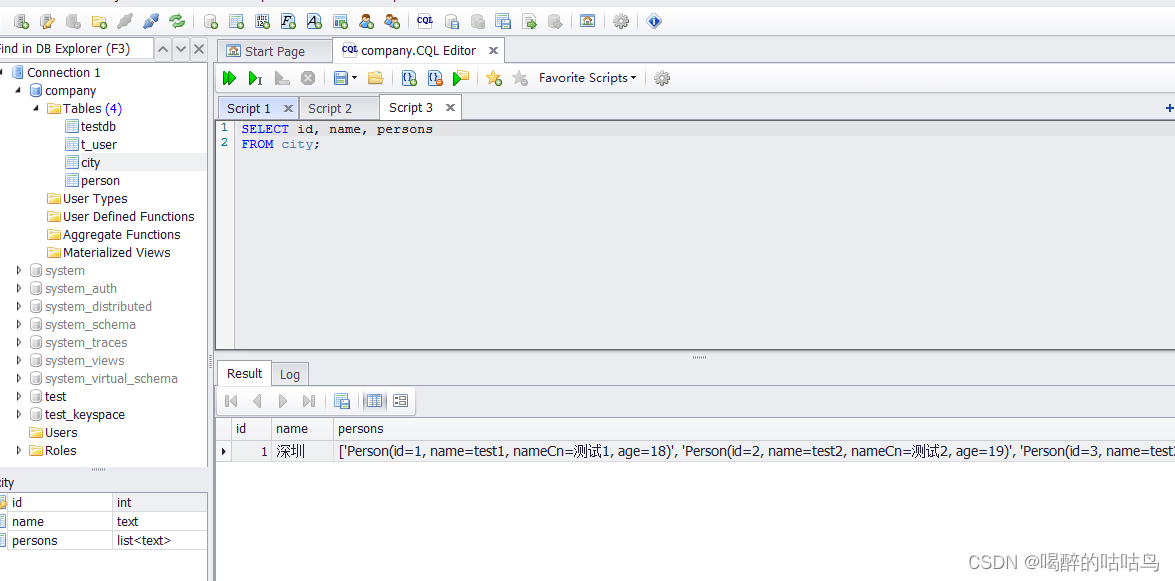
City city = new City();
city.setId(1);
city.setName("深圳");
city.setPersons(list);
cityRepository.save(city);
}
}
package com.lean.cassandra;
import com.lean.cassandra.entity.Person;
import com.lean.cassandra.repository.PersonRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.cassandra.core.query.CassandraPageRequest;
import org.springframework.data.domain.Pageable;
import java.util.LinkedList;
import java.util.List;
@SpringBootTest
public class PersonRepositoryTest {
@Autowired
private PersonRepository repository;
@Test
public void save() {
Person person = new Person();
person.setId(1);
person.setName("xxb");
person.setAge(18);
repository.save(person);
}
@Test
public void saveAll() {
List<Person> list = new LinkedList<>();
for (int i = 1; i < 20; i++) {
Person person = new Person();
person.setId(i + 1);
person.setAge(18 + i);
person.setName("test" + (i + 1));
person.setNameCn("测试" + (i + 1));
list.add(person);
}
repository.saveAll(list);
}
@Test
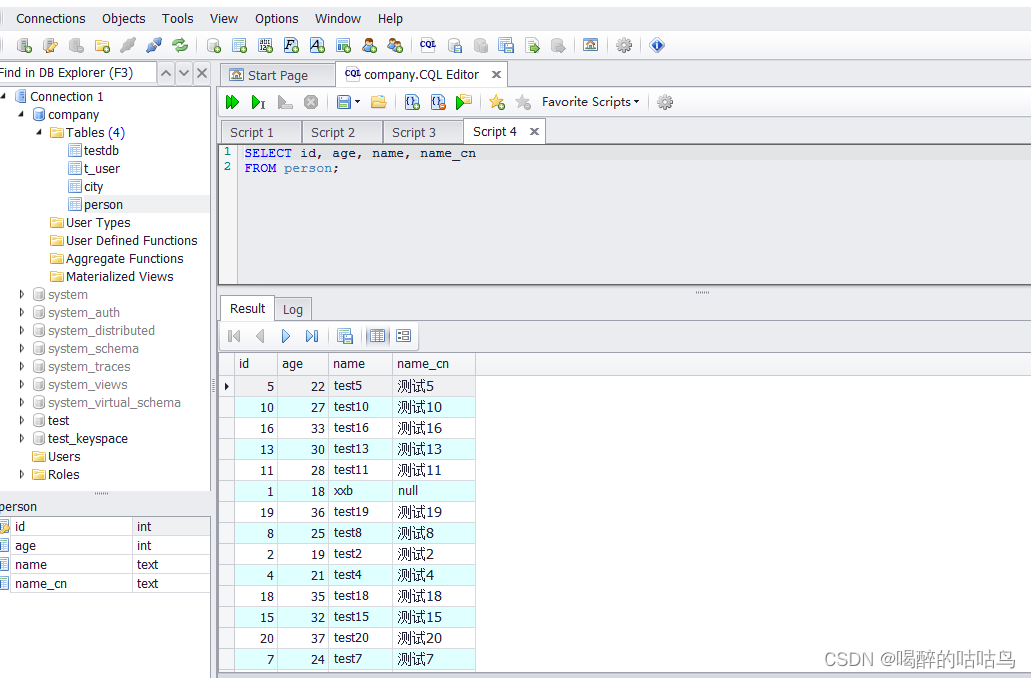
public void findById() {
Person person = repository.findById(1).orElse(null);
System.out.println(person);
}
@Test
public void findByName() {
Person person = repository.findByName("xxb");
System.out.println(person);
}
@Test
public void update() {
Person person = repository.findById(1).orElse(null);
person.setAge(20);
repository.save(person);
System.out.println(person);
}
@Test
public void all() {
List<Person> personList = repository.findAll();
System.out.println(personList);
}
@Test
public void count() {
long count = repository.count();
System.out.println(count);
}
@Test
public void delete() {
repository.deleteById(1);
Person person = repository.findById(1).orElse(null);
System.out.println(person);
}
@Test
public void deleteAll() {
repository.deleteAll();
long count = repository.count();
System.out.println(count);
}
@Test
public void page() {
Pageable pageable = CassandraPageRequest.of(0, 5);
List<Person> list = repository.findAll(pageable).getContent();
System.out.println(list);
}
}
第二种:
package com.lean.cassandra;
import com.alibaba.fastjson.JSON;
import com.datastax.oss.driver.api.querybuilder.QueryBuilder;
import com.google.common.collect.Lists;
import com.lean.cassandra.entity.User;
import com.lean.cassandra.service.UserService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.cassandra.core.query.Query;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class UserServiceTest {
@Autowired
private UserService userService;
@Test
public void saveUser() {
User user = new User();
user.setId(1);
user.setName("aa");
user.setAge(10);
user.setBooks(Lists.newArrayList());
userService.saveUser(user);
}
@Test
public void batchSaveUser() {
List<User> userList = new ArrayList<>();
for (int i = 2; i < 100; i++) {
User user = new User();
user.setId(0);
user.setName("aa");
user.setAge(10);
user.setBooks(Lists.newArrayList());
userList.add(user);
}
userService.batchSaveUser(userList);
}
@Test
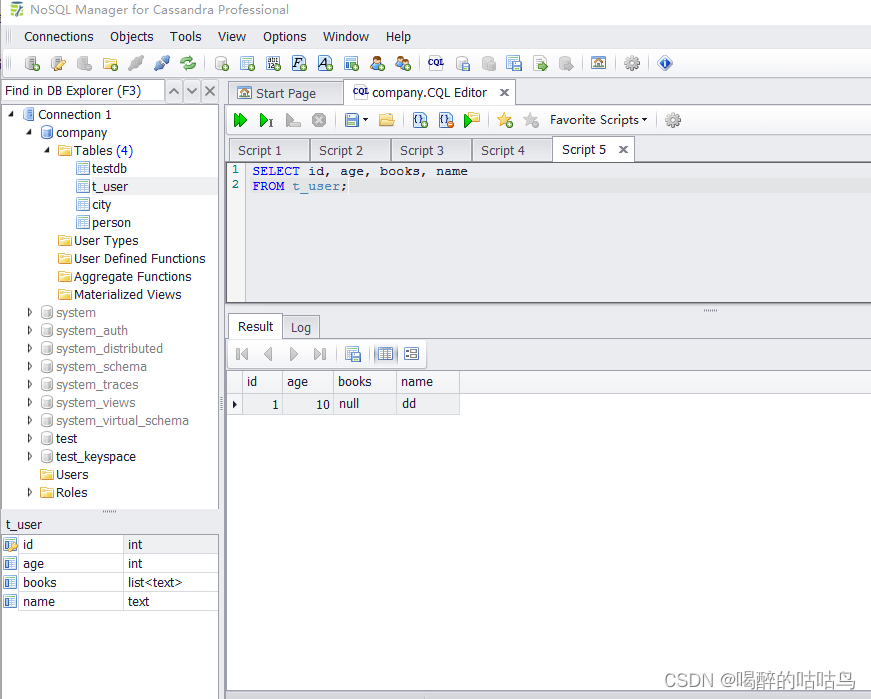
public void updateUser() {
User user = new User();
user.setId(1);
user.setName("dd");
user.setAge(10);
user.setBooks(Lists.newArrayList());
userService.updateUser(user);
}
@Test
public void getById() {
Integer id = 1;
User user = userService.getById(id);
System.out.println(JSON.toJSONString(user));
}
@Test
public void getUserDetail() {
Query query = Query.empty();
// query = query.withAllowFiltering();
User user = userService.getObj(query);
System.out.println(JSON.toJSONString(user));
}
@Test
public void findUserList() {
Query query = Query.empty();
// query = query.withAllowFiltering();
List<User> userList = userService.listObjs(query);
System.out.println(JSON.toJSONString(userList));
}
}
package com.lean.cassandra;
import com.alibaba.fastjson.JSON;
import com.lean.cassandra.entity.TestDb;
import com.lean.cassandra.service.TestDbService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class TestDbTest {
@Autowired
private TestDbService testDbService;
@Test
public void save() {
for (int i = 0; i < 100; i++) {
TestDb testDb=new TestDb();
if(i%2==0){
testDb.setKeyOne("1");
}else {
testDb.setKeyOne("2");
}
testDb.setKeyTwo((i+2)+"");
testDb.setValue(1.0D);
testDbService.save(testDb);
}
}
@Test
public void query() {
TestDb testDb=new TestDb();
testDb.setKeyOne("1");
List<TestDb> query = testDbService.query(testDb);
System.out.println(JSON.toJSONString(query));
}
@Test
public void delete() {
TestDb testDb=new TestDb();
testDb.setKeyOne("1");
testDb.setKeyTwo("2");
testDbService.delete(testDb);
}
}
官方网址
cassandra可视化客户端
分布式算法实用指南
Cassandra数据库




![[附源码]java毕业设计龙虎时代健身房管理系统](https://img-blog.csdnimg.cn/74247381268e4106951e8188ab6ee280.png)