前言
咋说呢,最近交接了一个XXX统计分析系统到我手上,显示页面平平无其,一看导入、导出功能的实现代码,每个小菜单目录里面都对应一个导入导出接口,看起来十分难受!(此处省略1w字内心os)正所谓前人栽树、后人乘凉,bug也是接踵而来,打了我个措手不及呀!于是想着去优化一波代码,故事的正文由此展开
解耦
解耦真的很重要!重要的事情说三遍!好的代码规范结合良好的架构,让项目日后的运营和维护都变得容易了许多,最重要的是自己看着也舒服
如何将所有的导入接口合并成一个接口?
要想实现如何将所有的导入接口合并成一个接口前,首先我们要弄清楚这些导入接口间有哪几块是可以共用的,哪几部分又是各自差异化的,下面我来简单罗列一下
共用
- 解析导入的文件这个流程是一样的,都是先读取 execel 流,然后逐行解析数据
- 接口实现的逻辑这个流程是一样的,都是先解析数据,然后过滤数据,最后对数据进行入库
差异化
- 每个导入接口,入库的时候用到的 service 是不一样的
- 每个导入接口,过滤数据的逻辑是不一样的、入库的逻辑也可能不一样,举个例子来说:可能有些需要先删除旧数据,然后插入解析到的数据。有一些是先入库后删除旧数据。
搞清楚了这几点之后,我们就可以从代码角度去扩展实现原有的功能了
导入功能、抽离同质化的逻辑实现
java 中有一个东西叫做 抽象类 ,使用抽象类即可将:差异化的东西抽象出来,同质化的东西进行复用。
以下代码为我多次调试、以及测试验证后的最终版代码,大体的逻辑就是利用 Easy Excel 中的 ExcelReader 来对文件进行解析,解析完成后,我们对数据进行一个入库操作,当然其中也实现了一些个性化操作,考虑到上文提到的差异化的部分,提供了一些扩展点给开发人员的,对数据过滤、最终数据入库要怎么去实现交给子类去实现
@Slf4j
public abstract class AbstractAnalysisEventListener<T> extends AnalysisEventListener<T> {
/**
* 应对多线程下的导入问题:每个线程解析到的导入数据都与其线程挂钩,达到副本独立的效果
*/
private ThreadLocal<List<T>> datas = new ThreadLocal<>();
private ImportVo importVo;
private final String defaultSheetName = "Sheet1";
private final Integer defaultSheetNo = 1;
private final Integer defaultHeadRowNumber = 1;
@Override
public void invoke(T source, AnalysisContext analysisContext) {
if (!whetherImport(source, importVo)) return;
if (null == datas.get()) datas.set(new ArrayList<>());
datas.get().add(formatData(source, importVo));
}
/**
* 文件解析完毕
*/
@Transactional
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
log.info("开始准备数据入库!");
try {
insertAllDate(datas.get());
log.info("数据导入完成开始 jc");
jc();
log.info("jc 结束");
} catch (Exception e) {
e.printStackTrace();
log.error("数据入库过程中出现异常:" + e.getMessage());
throw e;
}
log.info("数据入库完成!");
}
public void doExecute(ImportVo importVo, MultipartFile excelFile) throws InterruptedException {
ExcelReader reader = null;
this.importVo = importVo;
try {
reader = getReader(excelFile, this);
} catch (IOException e) {
e.printStackTrace();
log.error("初始化 ExcelReader 出现异常: " + e.getMessage() + " fileName:" + excelFile.getOriginalFilename());
throw new RuntimeException("初始化 ExcelReader 出现异常");
}
log.info("开始解析excel文件!");
ArrayList<ReadSheet> readSheets = new ArrayList<>();
ReadSheet readSheet = new ReadSheet();
if (null == importVo.getHeadRowNumber()) readSheet.setHeadRowNumber(defaultHeadRowNumber);
else readSheet.setHeadRowNumber(importVo.getHeadRowNumber());
readSheet.setClazz(aClass());
if (null == importVo.getSheetNo()) readSheet.setSheetNo(defaultSheetNo);
else readSheet.setSheetNo(importVo.getSheetNo());
if (StringUtils.isEmpty(importVo.getSheetName())) readSheet.setSheetName(defaultSheetName);
else readSheet.setSheetName(importVo.getSheetName());
readSheets.add(readSheet);
reader.read(readSheets);
log.info("excel文件解析完成!");
// 弃用的方法
//reader.read(new Sheet(sheetNo, headLineNum, rowModel));
}
private ExcelReader getReader(MultipartFile excel, AnalysisEventListener excelListener) throws IOException {
String filename = excel.getOriginalFilename();
if (filename != null && (filename.toLowerCase().endsWith(".xls") || filename.toLowerCase().endsWith(".xlsx"))) {
InputStream is = new BufferedInputStream(excel.getInputStream());
ArrayList<ReadListener> readListeners = new ArrayList<>();
readListeners.add(excelListener);
ReadWorkbook readWorkbook = new ReadWorkbook();
readWorkbook.setInputStream(is);
readWorkbook.setCustomReadListenerList(readListeners);
ExcelReader excelReader = new ExcelReader(readWorkbook);
return excelReader;
//弃用的方法
//return new ExcelReader(is, null, excelListener, false);
} else {
log.error("文件格式错误、文件名不能为空");
throw new RuntimeException("文件格式错误、文件名不能为空");
}
}
public void jc() {
importVo = null;
datas.remove();
}
public abstract Boolean whetherImport(T t, ImportVo importVo);
public abstract void insertAllDate(List<T> datas);
public abstract T formatData(T source, ImportVo importVo);
public abstract String type();
public abstract Class aClass();
}
代码设计精髓 使用Threadlocal 副本隔离
好了代码就是长上面这样了,现在来说一下代码的思想吧,可能之前积累了一些看源码的经验,竟感觉经历都是如此的类似。对 Threadlocal 不了解的可以移步 ThreadLocal还存在内存泄漏?源码级别解读
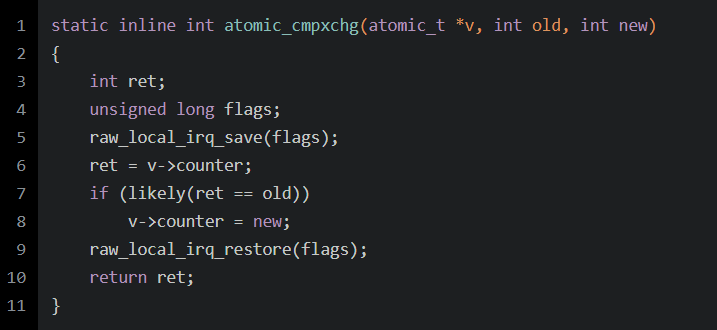
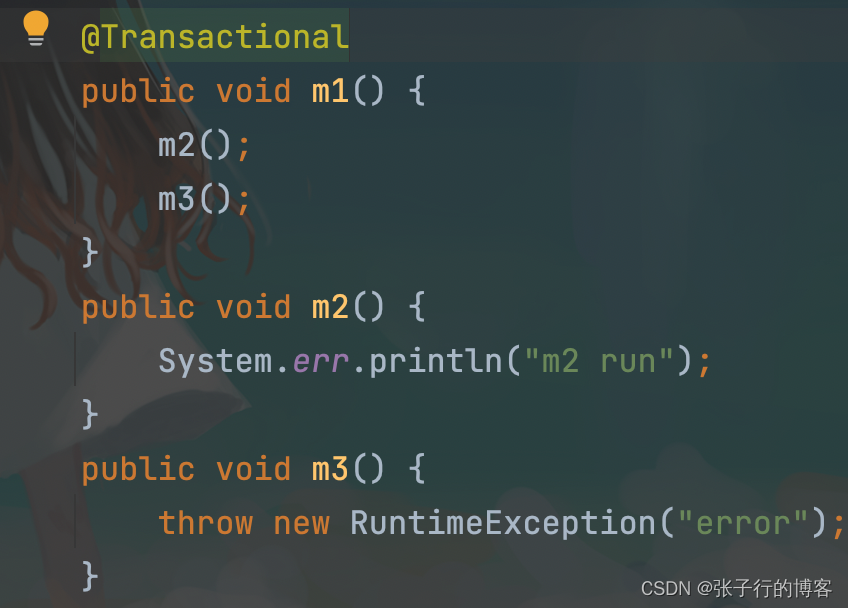
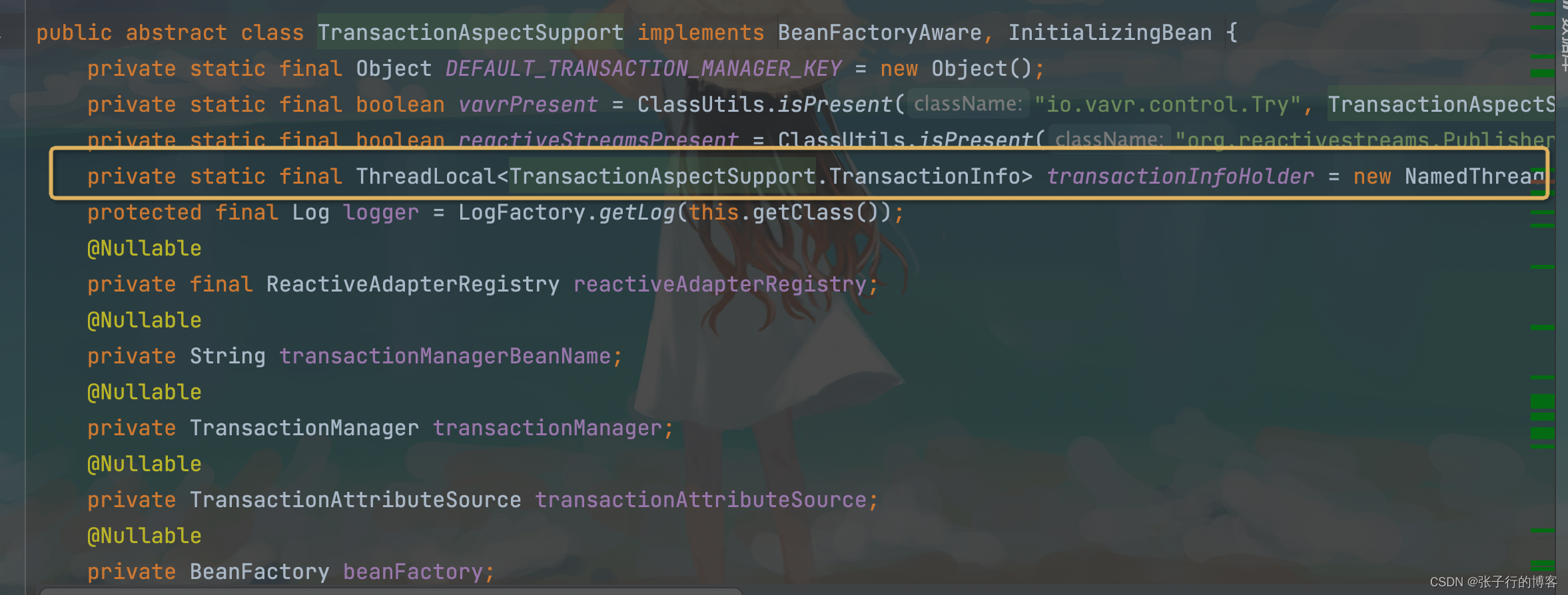
ThreadLocal 在源码中最经典的应用场景莫过于: Spring 对 Jdbc 事务的封装了,事务对象存放在 ThreadLocal 中(图二),下面来举个例子(图一),m3出现异常由于m1开启了事务,m1,m2,m3都会进行回滚,但是有一个前提就是,m1,m2,m3 使用的是同一个连接,因为回滚是根据连接来的,由于连接与线程进行了一一绑定,很容易实现 m1,m2,m3 都是用同一个连接的逻辑,因为都是在一个线程中执行(子事务的运行机制)。其次由于线程与连接绑定了,也不会出现连接污染的情况出现,一个线程中的数据回滚了,不会影响另一个线程中的数据。当然这些逻辑的实现也可以不使用 ThreadLocal ,使用一个 Map 也可以,不过需要编写一大堆的判断逻辑,还极容易出错!
图一
图二
回到我们实现的 AbstractAnalysisEventListener 中来,由于之后的各种导入只需实现 AbstractAnalysisEventListener 类,重写一下 type()、aClass()方法就好了,各种导入的文件在对其解析的时候,数据都会存放到 datas 中,单个线程下是没有任何问题的,但是在多个线程下,datas 中的数据就会出现各种问题,比方说,线程一导入的数据解析并且入库完成了,开始清除 datas 中的数据,但是线程二的数据还在解析中,此时的 datas 由于被清空了,就会造成线程二,导入数据条数缺失的问题,等等,所以此处使用 ThreadLocal 对数据进行一个线程隔离,每个线程的数据互不影响。注:一个线程内导入多个文件还是不支持的
解析器的实现
支持的功能:判决每一条数据是否需要入库、格式化每一条需要导入的数据、导入所有符合规则的数据,详情见代码中注释
@Data
@Component
public class GoodsImportAnalysis extends AbstractAnalysisEventListener<Goods> {
@Autowired
private GoodsService goodsService;
/**
* @param goods 解析到的每一条数据
* @param importVo 前端传过来的参数
* @return true: 这条数据需要入库、false: 这条数据无需入库
*/
@Override
public Boolean whetherImport(Goods goods, ImportVo importVo) {
return true;
}
/**
* 其实这个方法也可以直接写在抽象类中,提供出来的目的在于:
* 如果日后有需求说什么,导入这个数据的同时还要删掉其他别的数据,或者先删后入库等等其他需求,提供扩展点给用户自己选择
* @param datas 经过 whetherImport 、 formatData 方法筛选最终解析得到的所有数据
*/
@Override
public void insertAllDate(List<Goods> datas) {
goodsService.saveBatch(datas);
}
/**
* @param goods 解析到的每一条数据
* @param importVo 前端传过来的参数
* @return 格式化过后的一条数据
*/
@Override
public Goods formatData(Goods goods, ImportVo importVo) {
goods.setType(Thread.currentThread().getName());
return goods;
}
/**
* 根据 type()的返回值找到对应的解析器解析文件
*/
@Override
public String type() {
return "GoodsImportAnalysis";
}
/**
* 提供解析类给予参照
*/
@Override
public Class aClass() {
return Goods.class;
}
}
导入功能统一 Service
通过实现 ApplicationContextAware 接口,获取 Spring 上下文来获取所有 AbstractAnalysisEventListener 类型的 Bean ,再根据前端传过来的参数 type 确定要用哪一个解析器来进行处理,这样一来:所有的导入接口就都统一成一个接口了。
@Slf4j
@Component
public class ImportService implements ApplicationContextAware, DisposableBean {
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
@Override
public void destroy() {
this.applicationContext = null;
}
public void execute(ImportVo importVo, MultipartFile multipartFile) {
Map<String, AbstractAnalysisEventListener> beansOfType = applicationContext.getBeansOfType(AbstractAnalysisEventListener.class);
if(beansOfType.size()==0) throw new RuntimeException("系统未提供适配器!");
boolean res = beansOfType.entrySet().stream().anyMatch(entry -> {
AbstractAnalysisEventListener abstractAnalysisEventListener = entry.getValue();
if (importVo.getType().equals(abstractAnalysisEventListener.type())) {
try {
abstractAnalysisEventListener.doExecute(importVo, multipartFile);
return true;
} catch (Exception e) {
e.printStackTrace();
log.error("导入文件时出现异常:" + e.getCause());
throw new RuntimeException(e);
}
}
return false;
});
if (!res) throw new RuntimeException("未找到合适的适配器执行!");
}
}
导入测试
goods导入模版

goods导入模版2

如果需要导入别的数据只需编写对应的 AbstractAnalysisEventListener 实现类,接口还是用如下这个接口,就可以了,如果日后解析 execel 这一步骤需要换成 poi 技术实现的话,我们只需修改 AbstractAnalysisEventListener 里面的逻辑就可以了,是不是很方便呢
@PostMapping(value = "import")
public R import2(@RequestParam("file") MultipartFile file,
@RequestParam("file2") MultipartFile file2,
@RequestPart ImportVo customParams) {
new Thread(() -> {
importService.execute(customParams, file);
}, "用户一").start();
new Thread(() -> {
importService.execute(customParams, file2);
}, "用户二").start();
return R.ok("success");
}
~~~~~~~~~~~~到此和导入有关的内容结束~~~~·~~~~~~~~
如何将所有的导出接口合并成一个接口?
老样子抽象、封装,对 EasyExcel 中的方法进行封装,支持了指定表头的数据导出,只不过动态表头是交与前端来传入的,后端解析一下就好了。里面值得注意的是,使用到了反射技术将表头与数据进行对齐
@Slf4j
public abstract class AbstractExportService implements ExecelHander {
public void execute(HttpServletResponse response, ExportVo exportVo) {
this.writeExcel(response,
dataList(list(exportVo), exportVo.getColumns().values()),
exportVo.getFileName(),
exportVo.getSheetName(),
aClass(),
head(exportVo.getColumns().keySet()));
}
/**
* 使用 linkedlist 将 db 中查出来的每一条数据字段值顺序,与前端表头传参保持一致,返回值里层list对应一行数据,外层list对应多行数据
*/
private List<List<String>> head(Set<String> list) {
List<List<String>> lists = new ArrayList<>();
list.stream().forEach(l -> {
ArrayList<String> strings = new ArrayList<>();
strings.add(l);
lists.add(strings);
});
return lists;
}
/**
* 使用 linkedlist 将 db 中查出来的每一条数据字段值顺序,与前端表头传参保持一致
*/
private List<LinkedList> dataList(List dblist, Collection<String> fileList) {
LinkedList list = new LinkedList<LinkedList>();
for (Object goods : dblist) {
List data = new LinkedList<>();
fileList.stream().forEach(heads -> {
data.add(getFieldValue(String.valueOf(heads), goods));
});
list.add(data);
}
return list;
}
/**
* 通过反射获取对应的值
*/
private static Object getFieldValue(String fieldName, Object person) {
try {
String firstLetter = fieldName.substring(0, 1).toUpperCase();
String getter = "get" + firstLetter + fieldName.substring(1);
Method method = person.getClass().getMethod(getter);
return method.invoke(person);
} catch (Exception e) {
e.printStackTrace();
log.error("使用反射获取对象属性值失败", e);
return "使用反射获取对象属性值失败,请检查参数 columns:[" + fieldName + "] 是否正确";
}
}
public abstract String type();
public abstract List list(ExportVo exportVo);
public abstract Class aClass();
}
对应的 ExecelHander,里面主要还是传统的导出代码,没啥好看的
public interface ExecelHander {
/**
* 导出单个sheet
* @param data 导出数据List
* @param fileName 文件名
* @param sheetName sheet名
* @param model 映射实体
*/
default void writeExcel(HttpServletResponse response, List<? extends Object> data, String fileName, String sheetName,
Class model, List<List<String>> heads) {
try {
// 表头样式策略
WriteCellStyle headWriteCellStyle = new WriteCellStyle();
// 设置数据格式
headWriteCellStyle.setDataFormat((short) BuiltinFormats.getBuiltinFormat("m/d/yy h:mm"));
// 是否换行
headWriteCellStyle.setWrapped(false);
// 水平对齐方式
headWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.LEFT);
// 垂直对齐方式
headWriteCellStyle.setVerticalAlignment(VerticalAlignment.CENTER);
// 前景色
headWriteCellStyle.setFillForegroundColor(IndexedColors.WHITE.getIndex());
// 背景色
headWriteCellStyle.setFillBackgroundColor(IndexedColors.WHITE.getIndex());
// 设置为1时,单元格将被前景色填充
headWriteCellStyle.setFillPatternType(FillPatternType.NO_FILL);
// 控制单元格是否应自动调整大小以适应文本过长时的大小
headWriteCellStyle.setShrinkToFit(false);
// 单元格边框类型
headWriteCellStyle.setBorderBottom(BorderStyle.NONE);
headWriteCellStyle.setBorderLeft(BorderStyle.NONE);
headWriteCellStyle.setBorderRight(BorderStyle.NONE);
headWriteCellStyle.setBorderTop(BorderStyle.NONE);
// 单元格边框颜色
headWriteCellStyle.setLeftBorderColor(IndexedColors.BLACK.index);
headWriteCellStyle.setRightBorderColor(IndexedColors.BLACK.index);
headWriteCellStyle.setTopBorderColor(IndexedColors.BLACK.index);
headWriteCellStyle.setBottomBorderColor(IndexedColors.BLACK.index);
// 字体策略
WriteFont writeFont = new WriteFont();
writeFont.setBold(false);
// 字体颜色
writeFont.setColor(Font.COLOR_NORMAL);
// 字体名称
writeFont.setFontName("宋体");
// 字体大小
writeFont.setFontHeightInPoints((short) 11);
// 是否使用斜体
writeFont.setItalic(false);
// 是否在文本中使用横线删除
writeFont.setStrikeout(false);
// 设置要使用的文本下划线的类型
writeFont.setUnderline(Font.U_NONE);
// 设置要使用的字符集
writeFont.setCharset(FontCharset.DEFAULT.getNativeId());
headWriteCellStyle.setWriteFont(writeFont);
// 内容样式策略策略
WriteCellStyle contentWriteCellStyle = new WriteCellStyle();
contentWriteCellStyle.setFillForegroundColor(IndexedColors.WHITE.getIndex());
contentWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.GENERAL);
contentWriteCellStyle.setBorderBottom(BorderStyle.NONE);
contentWriteCellStyle.setBorderLeft(BorderStyle.NONE);
contentWriteCellStyle.setBorderRight(BorderStyle.NONE);
contentWriteCellStyle.setBorderTop(BorderStyle.NONE);
contentWriteCellStyle.setFillPatternType(FillPatternType.NO_FILL);
contentWriteCellStyle.setWrapped(false);
EasyExcel.write(getOutputStream(fileName, response), model)
.head(heads)
.registerWriteHandler(new HorizontalCellStyleStrategy(headWriteCellStyle, contentWriteCellStyle))
.registerWriteHandler(new SimpleColumnWidthStyleStrategy(16))
.excelType(ExcelTypeEnum.XLSX)
.sheet(sheetName)
.doWrite(data);
} catch (Exception e) {
e.printStackTrace();
}
}
default OutputStream getOutputStream(String fileName, HttpServletResponse response) throws Exception {
try {
fileName = URLEncoder.encode(fileName, "utf-8");
response.setContentType("application/json");
response.setCharacterEncoding("utf-8");
response.setHeader("Content-Disposition", "attachment; filename=" + fileName + ".xlsx");
response.setHeader("Pragma", "public");
response.setHeader("Cache-Control", "no-store");
response.addHeader("Cache-Control", "max-age=0");
return response.getOutputStream();
} catch (IOException e) {
throw new Exception("导出excel表格失败!", e);
}
}
}
导出功能统一 Service
套路和导入一样,~不多bb
@Component
public class ExportService implements ApplicationContextAware, DisposableBean {
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
@Override
public void destroy() {
this.applicationContext = null;
}
public void execute(ExportVo exportVo, HttpServletResponse response) {
Map<String, AbstractExportService> beansOfType = applicationContext.getBeansOfType(AbstractExportService.class);
beansOfType.entrySet().stream().forEach(entry -> {
AbstractExportService abstractExportService = entry.getValue();
if (null != abstractExportService.type() && abstractExportService.type().equals(exportVo.getType())) {
abstractExportService.execute(response,exportVo);
}
});
}
}
Goods导出
只需实现一下我们的 AbstractExportService ,重写一下 list 方法就行了
@Component
public class GoodsExportService extends AbstractExportService {
@Autowired
private GoodsService goodsService;
/**
* @param exportVo 导出条件
* @return 导出文件中的数据来源
*/
@Override
public List list(ExportVo exportVo) {
List ids = (List) exportVo.getCustomParams().get("id");
LambdaQueryWrapper<Goods> wrapper = new LambdaQueryWrapper<Goods>()
.in(Goods::getId, ids);
List<Goods> list = goodsService.list(wrapper);
return list;
}
@Override
public Class aClass() {
return Goods.class;
}
@Override
public String type() {
return "GoodsExportService";
}
}
Student导出
@Component
public class StudentExportService extends AbstractExportService {
@Autowired
private StudentService studentService;
@Override
public String type() {
return "StudentExportService";
}
@Override
public List list(ExportVo exportVo) {
List<Student> list = studentService.list();
return list;
}
@Override
public Class aClass() {
return Student.class;
}
}
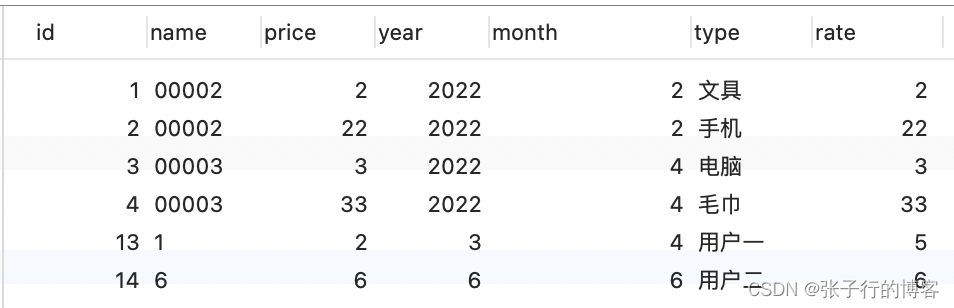
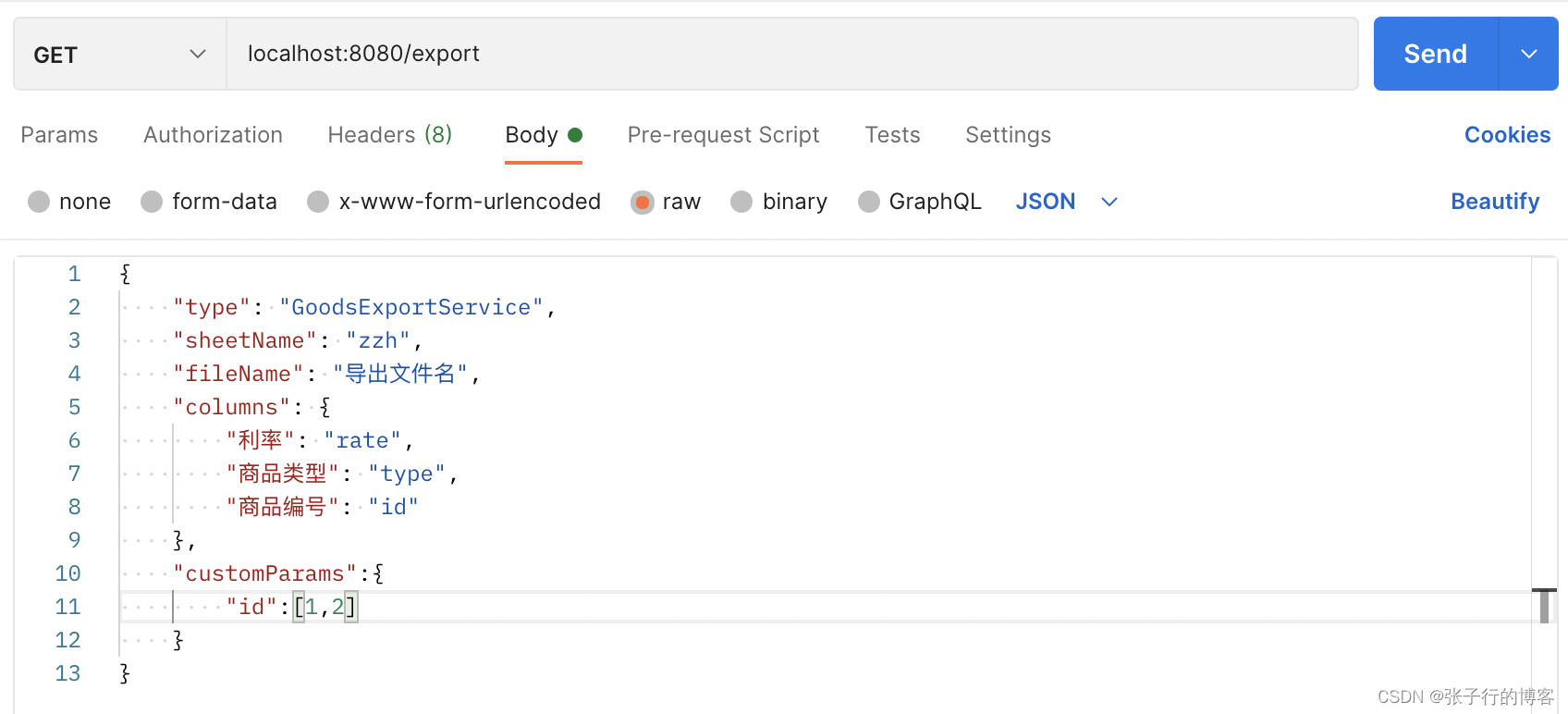
导出效果
可以看到,实现了自定义表头列的功能,且顺序和传参的顺序一致,真不错,而且由于指定了导出条件,只导出id为1、2的数据

附页(导入文件解析成功、但是映射不上)
由于本文的基础代码是用 Mybatis Plus 生成的,对应的 Entity 类上面加了 @Accessors(chain = true) 这个注解,导致 Easy Excel 在做数据解析映射的时候,映射不上去,对应源码中 ModelBuildEventListener 类下面的 buildUserModel 方法,感兴趣的小伙伴可以在此处打一个断点,自行去 debug ,本文碍于篇幅不展开叙述了。解决办法去掉 @Accessors 。
~~~~~~~~~~~到此全文结束~~~~~~~~~~
题外话
如果读者追求极致的性能可以结合 ThreadPoolTaskExecutor 实现多线程批量导入,在对应入库逻辑里面改造即可



![[附源码]java毕业设计龙虎时代健身房管理系统](https://img-blog.csdnimg.cn/74247381268e4106951e8188ab6ee280.png)