目录
一、Hadoop
1、文件系统
1.1、文件系统定义
1.2、传统常见的文件系统
1.3、文件系统中的重要概念
1.4、海量数据存储遇到的问题
1.5、分布式存储系统的核心属性及功能含义
2、HDFS
2.1、HDFS简介
2.2、HDFS设计目标
2.3、HDFS应用场景
2.4、HDFS重要特性
2.4.1、主从架构
2.4.2、分块存储
2.4.3、副本机制
2.4.4、元数据记录
2.4.5、namespace
2.4.6、数据块存储
2.5、HDFS存储模型
3、HDFS架构设计
3.1、角色功能
3.2、元数据持久化
3.3、安全模式
3.4、Block的副本放置策略
3.5、HDFS写流程
3.6、HDFS读流程
4、HDFS shell命令行
4.1、文件系统协议
4.2、HDFS shell命令行常用操作
4.2.1、创建文件夹
4.2.2、查看指定目录下内容
4.2.3、上传文件到HDFS指定目录下
4.2.4、查看HDFS文件内容
4.2.5、下载HDFS文件
4.2.6、拷贝HDFS文件
4.2.7、追加数据到HDFS文件中
4.2.8、HDFS数据移动操作
一、Hadoop
1、文件系统
1.1、文件系统定义
文件系统是一种存储和组织数据的方法,实现了数据的存储、分级组织、访问和获取等操作,使得用户对文件访问和查找变得容易。
文件系统使用树形目录的抽象逻辑概念代替了硬盘等物理设备使用数据块的概念,用户不必关心数据底层存在硬盘哪里,只需要记住这个文件的所属目录和文件名即可。
文件系统通常使用硬盘和光盘这样的存储设备,并维护文件在设备中的物理位置。
1.2、传统常见的文件系统
所谓传统常见的文件系统更多指的是单机的文件系统,也就是底层不会横跨多台机器实现。比如windows操作系统上的文件系统、Linux上的文件系统、FTP文件系统等等。
这些文件系统的共同特征包括:
1、带有抽象的目录树结构,树都是从/根目录开始往下蔓延
2、树中节点分为两类:目录和文件
3、从根目录开始,节点路径具有唯一性
1.3、文件系统中的重要概念
数据:指存储的内容本身,比如文件、视频、图片等,这些数据底层最终是存储在磁盘等存储介质上的,一般用户无需关心,只需要基于目录树进行增删改查即可,实际针对数据的操作由文件系统完成。
元数据:(metadata)又称之为解释性数据,记录数据的数据
文件系统元数据一般指文件大小、最后修改时间、底层存储位置、属性、所属用户、权限等信息。
思考:1、大数据时代,面对海量数据,传统的文件存储系统会面临哪些挑战呢?
1.4、海量数据存储遇到的问题
1、成本高:传统存储硬件通用性差,设备投资加上后期维护、升级扩容的成本非常高。
2、如何支撑高效率的计算分析:传统存储方式意味着数据:存储是存储,计算是计算,当需要处理数据的时候把数据移动过来。程序和数据存储是属于不同的技术厂商实现,无法有机统一整合在一起。
3、性能低:单节点I/O性能瓶颈无法逾越,难以支撑海量数据的高并发高吞吐场景。
4、可扩展性差:无法实现快速部署和弹性扩展,动态扩容,缩容成本高,技术实现难度大。
思考:
1、当遇到海量数据存储的场景,传统的文件系统如何解决海量数据的存储问题?
2、一款能够支撑海量数据存储的系统需要追求什么?吞吐量?性能?安全?效率?
3、如果让你设计一款存储系统软件来支撑海量数据存储,如何设计?
1.5、分布式存储系统的核心属性及功能含义
分布式存储系统核心属性
1、分布式存储 2、元数据记录 3、分块存储 4、副本机制
问题1:数据量大,单机存储遇到瓶颈
解决:单机纵向扩展:磁盘不够加磁盘,有上限瓶颈限制
多机横向扩展:机器不够加机器,理论上无限扩展
问题2:文件分布在不同机器上不利于寻找
解决:元数据记录下文件及其存储位置信息,快速定位文件位置
问题3:文件过大导致单机存储不下、上传下载效率低
解决:文件分块存储在不同机器,针对块并行操作提高效率
问题4:硬件故障难以避免,数据易丢失
解决:不同机器设置备份,冗余存储,保障数据安全
总结:
1、分布式存储的优点是什么?
无限扩展支撑海量数据存储
2、元数据记录的功能是什么?
快速定位文件位置便于查找
3、文件分块存储好处是什么?
针对块并行操作提高效率
4、设置副本备份的作用是什么?
冗余存储保障数据安全
2、HDFS
2.1、HDFS简介
HDFS(Hadoop Distributed File System),意为:Hadoop分布式文件系统,是Apache Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。也可以说大数据首先要解决的问题就是海量数据存储问题。

HDFS主要是解决大数据如何存储问题的。分布式意味着HDFS是横跨在多台计算机上的存储系统。
HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据(比如TB和PB)
HDFS使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。

2.2、HDFS设计目标
硬件故障(Hardware Failure)是常态,HDFS可能有成百上千的服务器组成,每一个组件都有可能出现故障。因此故障检测和自我快速恢复是HDFS的核心架构目标。
HDFS上的应用主要是以流式读取数据(Streaming Data Access)。HDFS被设计成用于批处理,而不是用户交互式的。相较于数据访问的反应时间,更注重数据访问的吞吐量。
典型的HDFS文件大小是GB到TB的级别。所以,HDFS被调整成支持大文件(Large Data Sets)。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件
大部分HDFS应用对文件要求的是write-one-read-many访问模型。一个文件一旦创建、写入、关闭之后就不需要修改了。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。
移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效。将计算移动到数据附近,比之将数据移动到应用所在显然更好。
HDFS被设计为可从一个平台轻松移植到另一个平台。这有助于将HDFS广泛用作大量应用程序的首选平台。
2.3、HDFS应用场景
适合场景:大文件,数据流式访问,一次写入多次读取,低成本部署,廉价PC,高容错
不适合场景:小文件,数据交互式访问,频繁任意修改,低延迟处理
2.4、HDFS重要特性
1、主从架构 2、分块存储 3、副本机制 4、元数据记录 5、抽象统一的目录树结构(namespace)
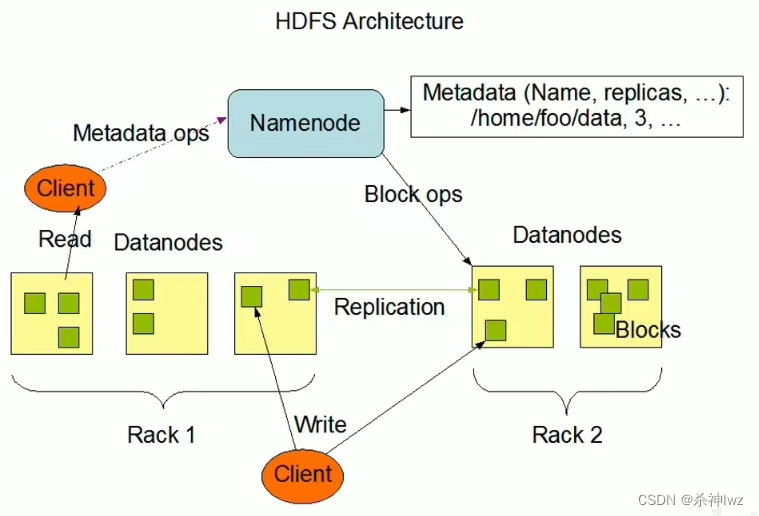
Rack:机架/机柜
2.4.1、主从架构
HDFS集群是标准的master/slave主从架构集群。
一般一个HDFS集群是有一个Namenode和一定数目的Datanode组成。
Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
上图中是一主五从模式,其中五个从角色位于两个机架(Rack)的不同服务器上。
2.4.2、分块存储
HDFS的文件在物理上是分块存储(block)的,默认大小是128M(134217728),不足128M则本身就是一块。
块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize。
2.4.3、副本机制
文件的所有block都会有副本。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
副本数由参数dfs.replication控制,默认值是3,也就是会额外再复制2份,连同本身总共3份副本。
2.4.4、元数据记录
在HDFS中,Namenode管理的元数据具有两种类型:
文件自身属性信息:文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
文件块位置映射信息:记录文件块和Datanode之间的映射信息,即哪个块位于哪个节点上。
2.4.5、namespace
HDFS支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将被Namenode记录下来。
HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/file.data。
2.4.6、数据块存储
文件的各个block的具体存储管理由DataNode节点承担。
每一个block都可以在多个DataNode上存储。
2.5、HDFS存储模型
- 文件线性按字节切割成块(block),具有offset,id
- 文件与文件的block大小可以不一样
- 一个文件除最后一个block,其他block大小一致
- block的大小依据硬件的I/O特性调整
- block被分散存放在集群的节点中,具有location
- Block具有副本(replication),没有主从概念,副本不能出现在同一个节点
- 副本是满足可靠性和性能的关键
- 文件上传可以指定block大小和副本数,上传后只能修改副本数
- 一次写入多次读取,不支持修改
- 支持追加数据
3、HDFS架构设计
- HDFS是一个主从(Master/Slaves)架构
- 由一个NameNode和一些DataNode组成
- 面向文件包含:文件数据(data)和文件元数据(metadata)
- NameNode负责存储和管理文件元数据,并维护了一个层次型的文件目录树
- DataNode负责存储文件数据(block块),并提供block的读写
- DataNode与NameNode维持心跳,并汇报自己持有的block信息
- Client和NameNode交互文件元数据和DataNode交互文件block数据
3.1、角色功能
NameNode
- 完全基于内存存储文件元数据、目录结构、文件block的映射
- 需要持久化方案保证数据可靠性
- 提供副本放置策略
DataNode
- 基于本地磁盘存储block(文件的形式)
- 并保存block的校验和数据保证block的可靠性
- 与NameNode保持心跳,汇报block列表状态
SecondaryNameNode(SNN)
- 在非Ha模式下,SNN一般是独立的节点,周期完成对NN的EditLog向FsImage合并,减少EditLog大小,减少NN启动时间
- 根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
- 根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB
3.2、元数据持久化
- 任何对文件系统元数据产生修改的操作,Namenode都会使用一种称为EditLog的事务日志记录下来
- 使用FsImage存储内存所有的元数据状态
- 使用本地磁盘保存EditLog和FsImage
- EditLog具有完整性,数据丢失少,但恢复速度慢,并有体积膨胀风险
- FsImage具有恢复速度快,体积与内存数据相当,但不能实时保存,数据丢失多
- NameNode使用了FsImage+EditLog整合的方案:
- 滚动将增量的EditLog更新到FsImage,以保证更近时点的FsImage和更小的EditLog体积
3.3、安全模式
- HDFS搭建时会格式化,格式化操作会产生一个空的FsImage
- 当Namenode启动时,它从硬盘中读取Editlog和FsImage
- 将所有Editlog中的事务作用在内存中的FsImage上
- 并将这个新版本的FsImage从内存中保存到本地磁盘上
- 然后删除旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了
- Namenode启动后会进入一个称为安全模式的特殊状态。
- 处于安全模式的Namenode是不会进行数据块的复制的。
- Namenode从所有的 Datanode接收心跳信号和块状态报告。
- 每当Namenode检测确认某个数据块的副本数目达到这个最小值,那么该数据块就会被认为是副本安全(safely replicated)的。
- 在一定百分比(这个参数可配置)的数据块被Namenode检测确认是安全之后(加上一个额外的30秒等待时间),Namenode将退出安全模式状态。
- 接下来它会确定还有哪些数据块的副本没有达到指定数目,并将这些数据块复制到其他Datanode上。
3.4、Block的副本放置策略
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的 机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点。
3.5、HDFS写流程
- Client和NN连接创建文件元数据
- NN判定元数据是否有效
- NN处发副本放置策略,返回一个有序的DN列表
- Client和DN建立Pipeline连接
- Client将块切分成packet(64KB),并使用chunk(512B)+chucksum(4B)填充
- Client将packet放入发送队列dataqueue中,并向第一个DN发送
- 第一个DN收到packet后本地保存并发送给第二个DN
- 第二个DN收到packet后本地保存并发送给第三个DN
- 这一个过程中,上游节点同时发送下一个packet
- 生活中类比工厂的流水线:结论:流式其实也是变种的并行计算
- Hdfs使用这种传输方式,副本数对于client是透明的
- 当block传输完成,DN们各自向NN汇报,同时client继续传输下一个block
- 所以,client的传输和block的汇报也是并行的
3.6、HDFS读流程
- 为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。
- 如果在读取程序的同一个机架上有一个副本,那么就读取该副本。
- 如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。
- 语义:下载一个文件:
- Client和NN交互文件元数据获取fileBlockLocation
- NN会按距离策略排序返回
- Client尝试下载block并校验数据完整性
- 语义:下载一个文件其实是获取文件的所有的block元数据,那么子集获取某些block应该成立
- Hdfs支持client给出文件的offset自定义连接哪些block的DN,自定义获取数据
- 这个是支持计算层的分治、并行计算的核心
4、HDFS shell命令行
命令行界面(英语:command-line interface,缩写:CLI),是指用户通过键盘输入指令,计算机接收到指令后,予以执行一种人际交互方式。
Hadoop提供了文件系统的shell命令行客户端:hadoop fs [generic options]
[root@node1 ~]# hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile [-n] <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum [-v] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-concat <target path> <src path> <src path> ...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-crc] [-ignoreCrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] [-s] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] [-t <thread count>] [-q <thread pool queue size>] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
...4.1、文件系统协议
HDFS Shell CLI支持操作多种文件系统,包括本地文件系统(file:///)、分布式文件系统(hdfs://nn:8020)等
具体操作的是什么文件系统取决于命令中文件路径URL中的前缀协议。
如果没有指定前缀,则将会读取环境变量中的fs.defaultFS属性,以该属性值作为默认文件系统。(cat /export/server/hadoop-3.3.6/etc/hadoop/core-site.xml)
hadoop fs -ls file:/// #操作本地文件系统
hadoop fs -ls hdfs://node1:8020/ #操作HDFS分布式文件系统
hadoop fs -ls / #直接根目录,没有指定协议 将加载读取fs.defaultFS值
#演示
[root@node1 ~]# hadoop fs -ls file:///
Found 20 items
dr-xr-xr-x - root root 20480 2023-12-24 23:37 file:///bin
dr-xr-xr-x - root root 4096 2023-12-24 23:42 file:///boot
drwxr-xr-x - root root 3100 2024-01-06 23:22 file:///dev
drwxr-xr-x - root root 8192 2024-01-06 23:22 file:///etc
drwxr-xr-x - root root 48 2023-12-25 23:59 file:///export
drwxr-xr-x - root root 6 2018-04-11 12:59 file:///home
dr-xr-xr-x - root root 4096 2023-12-24 23:37 file:///lib
dr-xr-xr-x - root root 20480 2023-12-24 23:37 file:///lib64
drwxr-xr-x - root root 6 2018-04-11 12:59 file:///media
drwxr-xr-x - root root 6 2018-04-11 12:59 file:///mnt
drwxr-xr-x - root root 6 2018-04-11 12:59 file:///opt
dr-xr-xr-x - root root 0 2024-01-06 23:22 file:///proc
dr-xr-x--- - root root 183 2024-01-02 23:51 file:///root
drwxr-xr-x - root root 620 2024-01-06 23:22 file:///run
dr-xr-xr-x - root root 12288 2023-12-25 23:35 file:///sbin
drwxr-xr-x - root root 6 2018-04-11 12:59 file:///srv
dr-xr-xr-x - root root 0 2024-01-06 23:22 file:///sys
drwxrwxrwt - root root 4096 2024-01-06 23:27 file:///tmp
drwxr-xr-x - root root 155 2023-12-24 23:35 file:///usr
drwxr-xr-x - root root 267 2023-12-24 23:41 file:///var
[root@node1 ~]#
[root@node1 ~]# hadoop fs -ls hdfs://node1:8020/
Found 4 items
drwxr-xr-x - root supergroup 0 2024-01-02 23:52 hdfs://node1:8020/lwztest
drwxr-xr-x - root supergroup 0 2024-01-03 00:05 hdfs://node1:8020/tmp
drwxr-xr-x - root supergroup 0 2024-01-03 00:05 hdfs://node1:8020/user
drwxr-xr-x - root supergroup 0 2024-01-03 00:19 hdfs://node1:8020/wordcount
[root@node1 ~]#
[root@node1 ~]# hadoop fs -ls /
Found 4 items
drwxr-xr-x - root supergroup 0 2024-01-02 23:52 /lwztest
drwxr-xr-x - root supergroup 0 2024-01-03 00:05 /tmp
drwxr-xr-x - root supergroup 0 2024-01-03 00:05 /user
drwxr-xr-x - root supergroup 0 2024-01-03 00:19 /wordcount
[root@node1 ~]#
[root@node1 ~]# cat /export/server/hadoop-3.3.6/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 设置默认使用的文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
...区别
hadoop dfs 只能操作HDFS文件系统(包括Local FS间的操作),不过已经Deprecated;
hdfs dfs 只能操作HDFS文件系统相关(包括与Local FS间的操作),常用;
hadoop fs 可操作任意文件系统,不仅仅是hdfs文件系统,使用范围更广;
目前版本来看,官方最终推荐使用的是hadoop fs。当然hdfs dfs 在市面上的使用也比较多。
[root@node1 ~]# hadoop dfs
WARNING: Use of this script to execute dfs is deprecated.
WARNING: Attempting to execute replacement "hdfs dfs" instead.
Usage: hadoop fs [generic options]
[-appendToFile [-n] <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum [-v] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
...
[root@node1 ~]# hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile [-n] <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum [-v] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-concat <target path> <src path> <src path> ...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-crc] [-ignoreCrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] [-s] <path> ...]
...参数说明
HDFS文件系统的操作命令很多和Linux类似,因此学习成本相对较低。
可以通过hadoop fs -help命令来查看每个命令的详细用法
[root@node1 ~]# hadoop fs -help
Usage: hadoop fs [generic options]
[-appendToFile [-n] <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum [-v] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-concat <target path> <src path> <src path> ...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-crc] [-ignoreCrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] [-s] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] [-t <thread count>] [-q <thread pool queue size>] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate] [-fs <path>]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-crc] [-ignoreCrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
...4.2、HDFS shell命令行常用操作
4.2.1、创建文件夹
hadoop fs -mkdir [-p] <path> ...
path 为待创建的目录
-p选项的行为与Unix mkdir -p非常相似,它会沿着路径创建父目录。
hadoop fs -mkdir -p /lwz4.2.2、查看指定目录下内容
hadoop fs -ls [-h] [-R] [<path> ...]
path 指定目录路径
-h 人性化显示文件size
-R 递归查看指定目录及其子目录
[root@node1 ~]# hadoop fs -ls /
Found 5 items
drwxr-xr-x - root supergroup 0 2024-01-06 23:50 /lwz
drwxr-xr-x - root supergroup 0 2024-01-02 23:52 /lwztest
drwxr-xr-x - root supergroup 0 2024-01-03 00:05 /tmp
drwxr-xr-x - root supergroup 0 2024-01-03 00:05 /user
drwxr-xr-x - root supergroup 0 2024-01-03 00:19 /wordcount
4.2.3、上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
-f 覆盖目标文件(已经存在下)
-p 保留访问和修改时间,所有权和权限
localsrc 本地文件系统(客户端所在机器)
dst 目标文件系统(HDFS)
[root@node1 ~]# hadoop fs -mkdir /lwztest
[root@node1 ~]# echo 123456adf > 1.txt
[root@node1 ~]# cat 1.txt
123456adf
#方式一
[root@node1 ~]# hadoop fs -put 1.txt /lwztest
[root@node1 ~]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2024-01-02 23:52 /lwztest
#方式二
[root@node1 ~]# hadoop fs -put file:///root/1.txt hdfs://node1:8020/lwz
4.2.4、查看HDFS文件内容
hadoop fs -cat <src> ...
读取指定文件全部内容,显示在标准输出控制台。
注意:对于大文件内容读取,慎重。
[root@node1 ~]# hadoop fs -cat /lwz/1.txt
123456adf
[root@node1 ~]# hadoop fs -tail /lwz/1.txt
123456adf
[root@node1 ~]#
4.2.5、下载HDFS文件
hadoop fs -get [-f] [-p] <src> ...<localdst>
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已经存在下)
-p 保留访问和修改时间,所有权和权限
[root@node1 ~]# mkdir test
[root@node1 ~]# cd test
[root@node1 test]# ll
total 0
[root@node1 test]# hadoop fs -get /lwz/1.txt ./
[root@node1 test]# ll
total 4
-rw-r--r--. 1 root root 10 Jan 7 00:16 1.txt
#下载下来后,并修改文件名为11.txt
[root@node1 test]# hadoop fs -get /lwz/1.txt ./11.txt
[root@node1 test]# ll
total 8
-rw-r--r--. 1 root root 10 Jan 7 00:19 11.txt
-rw-r--r--. 1 root root 10 Jan 7 00:16 1.txt
[root@node1 test]# cat 11.txt
123456adf
[root@node1 test]#
4.2.6、拷贝HDFS文件
hadoop fs -cp [-f] <src> ...<dst>
-f 覆盖目标文件(已经存在下)
[root@node1 ~]# hadoop fs -cp /lwz/1.txt /lwz/11.txt #重命名
[root@node1 ~]# hadoop fs -ls /lwz
Found 2 items
-rw-r--r-- 3 root supergroup 10 2024-01-07 00:05 /lwz/1.txt
-rw-r--r-- 3 root supergroup 10 2024-01-07 00:24 /lwz/11.txt
[root@node1 ~]#
4.2.7、追加数据到HDFS文件中
hadoop fs -appendToFile <localsrc> ... <dst>
将所有给定本地文件的内容追加到给定dst文件。
dst如果文件不存在,将创建该文件。
如果<localsrc>为-,则输入为从标准输入中读取。
#追加内容到文件尾部appendToFile
[root@node1 ~]# echo a > a.txt
[root@node1 ~]# echo b > b.txt
[root@node1 ~]# echo c > c.txt
[root@node1 ~]# cat a.txt
a
[root@node1 ~]# hadoop fs -put a.txt /
[root@node1 ~]# hadoop fs -cat /a.txt
a
[root@node1 ~]# hadoop fs -appendToFile b.txt c.txt /a.txt
[root@node1 ~]# hadoop fs -cat /a.txt
a
b
c
[root@node1 ~]#
应用场景:小文件合并
4.2.8、HDFS数据移动操作
hadoop fs -mv <src> ... <dst>
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称
[root@node1 ~]# hadoop fs -mv /a.txt /lwz/
[root@node1 ~]# hadoop fs -ls /lwz
Found 3 items
-rw-r--r-- 3 root supergroup 10 2024-01-07 00:05 /lwz/1.txt
-rw-r--r-- 3 root supergroup 10 2024-01-07 00:24 /lwz/11.txt
-rw-r--r-- 3 root supergroup 6 2024-01-07 00:33 /lwz/a.txt
HDFS shell其他命令
HDFS shell命令官方指导文档
命令属于多用多会,孰能生巧,不用就忘。
Hadoop分布式文件系统(一)
再小的努力,乘以365都很明显!
一个程序员最重要的能力是:写出高质量的代码!!
有道无术,术尚可求也,有术无道,止于术。
无论你是年轻还是年长,所有程序员都需要记住:时刻努力学习新技术,否则就会被时代抛弃!








![[Excel]如何找到非固定空白格數列的條件數據? 以月份報價表單為例](https://img-blog.csdnimg.cn/direct/e6ad96bcc1e8406c90f877bd2b0cf567.png)