文章目录
- 前言
- 一、均方误差
- 二、交叉熵损失
- 三、二元交叉熵损失
- 四、Smooth L1 Loss
- 五、IOU系列的loss
前言
损失函数是度量模型的预测输出与真实标签之间的差异或误差,在深度学习算法中起着重要作用。具体作用:
1、目标优化:损失函数是优化算法的目标函数,通过最小化损失函数,模型的参数可以使得预测值接近真实值。训练过程的目标就是找到使损失函数最小化的参数。
2、模型评估:损失函数也可用于评估模型的性能。
3、指导学习过程:通过损失函数,模型可以学习如何调整权重和偏置以最小化预测实际标签之间的差异。这是通过梯度下降等优化算法来实现,这些算法使用损失函数的梯度来指导参数的更新。
深度学习损失函数在训练和评估深度学习模型中发挥关键作用,直接影响模型的性能和泛化能力。选择合适的损失函数是深度学习模型设计中的一个重要决策。
一、均方误差
均方误差(Mean Squared Error,MSE)是一种用于回归问题的损失函数,它度量模型的预测值与实际标签之间的平方差的平均值。通常用在具有连续输出的回归问题中使用,结合梯度下降等优化算法,最小化模型的预测误差。
优点:由于平方的存在,能对大误差给予更大的惩罚。缺点:对离群值(异常值)非常敏感,单个异常值可能对整体损失较大影响。
在pytroch的API:参考文档
torch.nn.MSELoss(reduction=‘mean’)
reduction (str, optional) – Specifies the reduction to apply to the output: ‘none’ | ‘mean’ | ‘sum’. ‘none’: no reduction will be applied, ‘mean’: the sum of the output will be divided by the number of elements in the output, ‘sum’: the output will be summed. Note: size_average and reduce are in the process of being deprecated, and in the meantime, specifying either of those two args will override reduction. Default: ‘mean’
代码示例:
import torch
import torch.nn as nn
torch.random.manual_seed(0)
if __name__ == '__main__':
mse = nn.MSELoss(reduction='sum')
inputs = torch.randn(3, 5, requires_grad=True)
outputs = torch.randn(3, 5)
loss = mse(inputs, outputs)
在cv中,常用在以下几个领域:
- 图像配准(模板匹配):MSE用于衡量两个图像之间的差异。通过比较配准后的图像与目标之间的像素,评估二者之间的差异。
- 回归任务:在图像属性预测等任务中,MSE是一种常见的损失函数。
- 目标检测:在目标检测中,当模型需要回归目标边界框的坐标时,MSE度量预测框与真实框之间的位置差异。如yolov1等。
- 自监督学习:生成的目标通常是通过对原始数据应用某种变换而获得的。MSE可以用于度量模型生成的结果与变换后的原始数据之间的差异。
- 生成对抗网络(GAN): 在 GAN 中,生成器的输出与真实图像之间的差异通常可以通过 MSE 来度量。然而,对抗性损失(例如二元交叉熵)通常更为常见,因为它更好地促使生成器生成逼真的图像。
二、交叉熵损失
CrossEntropyLoss(交叉熵损失)是在多分类问题中常用的损失函数,用于衡量模型输出的概率分布与真实标签的差异。
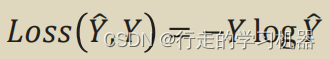
Y代表真实值, Y-head表示预测值
交叉熵损失通过比较模型对每个类别的预测概率与真实标签的概率分布,惩罚模型对正确类别的不确定性越大的情况。在优化过程中,模型的目标是最小化交叉熵损失,以使得模型对每个样本的预测更接近真实的标签分布。参考文档
在PyTorch等深度学习框架中,CrossEntropyLoss通常与Softmax激活函数结合使用。Softmax函数能够将模型的原始输出转换成表示概率分布的形式,而CrossEntropyLoss则基于这些概率计算损失。
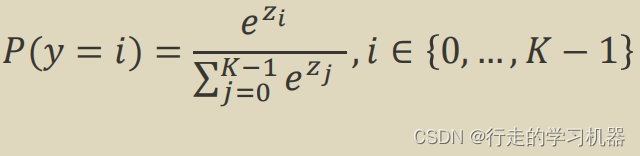
代码示例:
import torch
import torch.nn as nn
# Example of target with class indices
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
output.backward()
# Example of target with class probabilities
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5).softmax(dim=1)
output = loss(input, target)
output.backward()
在cv领域,交叉熵损失常用在图像多分类的场景中。
三、二元交叉熵损失
BCELoss是交叉熵损失在二分类问题上的一个特例。在深度学习中,会使用二元交叉熵损失函数来衡量二分类模型的性能。与一般的交叉熵损失相比,二元交叉熵只涉及两个类别,因此简化了损失函数的形式。优化算法(如梯度下降)通过最小化BCELoss来调整模型参数,使得模型在二分类任务中更准确。
表达式如下:
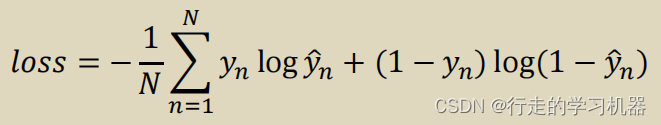
在pytorch的API:
torch.nn.BCELoss(weight=None, reduction=‘mean’)
reduction (str, optional) – Specifies the reduction to apply to the output: ‘none’ | ‘mean’ | ‘sum’. ‘none’: no reduction will be applied, ‘mean’: the sum of the output will be divided by the number of elements in the output, ‘sum’: the output will be summed. Note: size_average and reduce are in the process of being deprecated, and in the meantime, specifying either of those two args will override reduction. Default: ‘mean’
在PyTorch等深度学习框架中,BCELoss通常与Sigmoid激活函数一起使用,因为Sigmoid函数可以将模型输出映射到[0, 1]范围内的概率值。这两者的结合通常用于最后一层的模型输出。
代码示例:
import torch
import torch.nn as nn
m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, 2, requires_grad=True)
target = torch.rand(3, 2, requires_grad=False)
output = loss(m(input), target)
output.backward()
四、Smooth L1 Loss
Smooth L1 Loss,也称为 Huber Loss,是一种损失函数,通常用于回归问题。它的特点是相对于均方误差(MSE),在预测接近目标值时损失函数的增长更缓慢,这使得它对离群值(outliers)更加鲁棒。

beta一般等于1。
优点:
- 鲁棒性:Smooth L1 Loss相对于均方误差(MSE)对离群值更具鲁棒性。这使得它在处理包含噪声或异常值的数据时表现更好,尤其在回归任务中,其中存在离群值的可能性较大。
- 平滑性: 在 (|x| < 1) 的情况下,Smooth L1 Loss使用平方项,使得损失在预测接近目标值时增长缓慢。这种平滑性有助于训练过程的稳定性。
- 对于大误差的抑制效果: 对于大误差,Smooth L1 Loss的增长速率较慢,相对于MSE,它在对大误差的处理上更加温和。
缺点: - 对小误差不敏感: 对于小误差,Smooth L1 Loss的损失增长速率较快,这可能使得在某些情况下对小误差不够敏感。这也可能导致模型对于较小的误差调整得过于激烈。
- 非唯一性: 对于某些相同的误差,Smooth L1 Loss可能有多个最小值。这使得损失函数的形状在某些情况下变得复杂,可能对优化过程产生一定的影响。
在pytorch中的API:
torch.nn.SmoothL1Loss(reduction=‘mean’, beta=1.0)
在cv领域中,smooth L1 loss常用来代替MSE,用于边界框回归,相比较MSE,smooth L1 loss更抗干扰。
五、IOU系列的loss
IOU Loss用于衡量目标检测模型性能的损失函数。用于监督模型在生成边界框预测时与真实边界框之间的重叠程度。
总共有四种IOU相关的Loss:IOU Loss、GIOU Loss、DIOU Loss、CIOU Loss
(1)IOU Loss:衡量预测框与真实框的IOU的大小,IOU越大,损失越少。
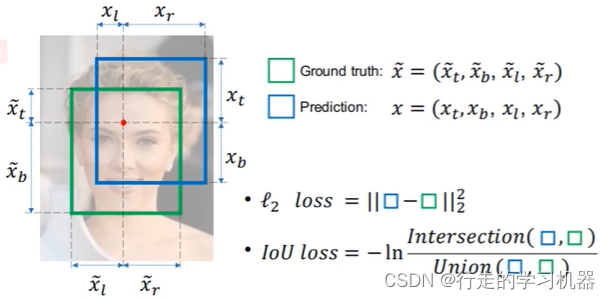
优点:能够更好反应重合程度,具有尺度不变性;
缺点:当二者不相交时,Loss为0,导致损失没办法继续传播。
(2)、GIOU Loss
GIOULoss针对IOULoss的缺点,引入了Ac和u,改善了部分IOULoss的缺陷。
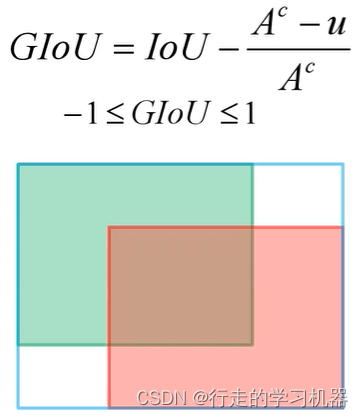
Ac表示蓝色矩形框的面积,u表示预测框与真实框的并集。
GIOULoss表达式:
GIOU Loss = 1 - GIOU
缺点是:两个边界框在同一水平线上时(Ac等于u),退化成IOU。收敛慢,收敛精度低。
(3)DIOU Loss
DIOU Loss在IOU的基础上,考虑了预测框与边界框中心的距离及最大矩形框的对角线距离。
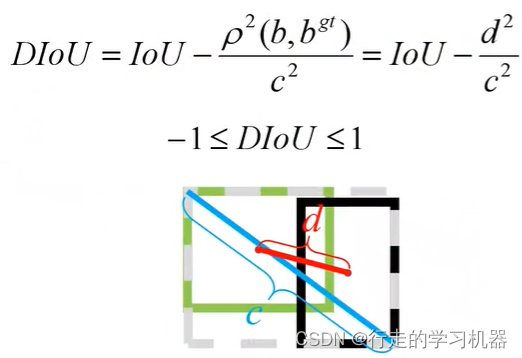
DIOULoss = 1 - DIou
DIOULoss极大加快了收敛速度和收敛精度。
(4)CIOU Loss
CIOU Loss在DIOU Loss的基础上,还考虑长宽比。