文章目录
- 前言
- 一、EfficientNet
- EfficientNet-B0 baseline
- MBConv
- 参数优化
- EfficientNet B0-B7 参数
- 二、EfficientDet
- BiFPN
- 复合缩放方法
- 总结
前言
EfficientDet是google在2019年11月发表的一个目标检测算法系列,其提出的背景是:之前很多研究致力于开发更高效的目标检测架构,如one-stage、anchor-free或压缩现有模型,尽管这些方法往往能获得更好的效率,但它们通常会牺牲准确性。并且这些研究并未关注工业应用上的资源约束问题。
EfficientDet精度与速度全面领先于YOLO V3, MaskRCNN, RentinaNet, NAS-FPN这些常见目标检测模型,其backbone基于EfficientNet。
ps:EfficientNet提出的背景
- 一些著名的卷积网络中(如AlexNet,VGG,ResNet等),其网络参数、层数、输入大小都是固定的,对为什么这样设置尚未有完备的解释。
- 在实际工程应用中,很多时候可能需要对网络进行一定程度的修改,但如何修改,修改哪些地方尚未有明确指导,在之前的一些论文中,基本都是通过改变输入分辨率
resolution,网络的深度depth以及Channels的宽度width(即通道数)这3个参数中的一个来提升网络的性能,而EfficientNet同时探索上述三个参数的影响。
提示:以下是本篇文章正文内容,下面内容可供参考
一、EfficientNet
EfficientNet-B0 baseline
EfficientNet一共有B0-B7个版本,EfficientNet-B0的网络框架如下图(B1-B7就是在B0的基础上修改Resolution,Depth以及Width)
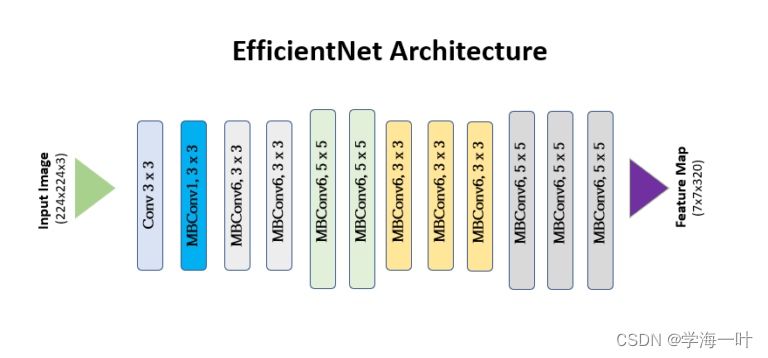
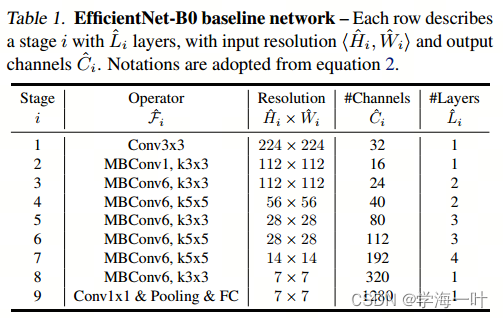
上图中可以看出EfficientNet总共分成了9段(Stage):
- Stage1就是一个卷积核大小为3x3步距为2的普通卷积层(包含BN和激活函数Swish)
- Stage2~Stage8都是在重复堆叠MBConv结构(最后一列的Layers表示该Stage重复MBConv结构多少次)
- Stage9由一个普通的1x1的卷积层(包含BN和激活函数Swish)一个平均池化层和一个全连接层组成。
ps: 表格中每个MBConv后会跟一个数字1或6,这里的1或6就是倍率因子n即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中逐通道卷积层DW(Depthwise Conv)所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channel
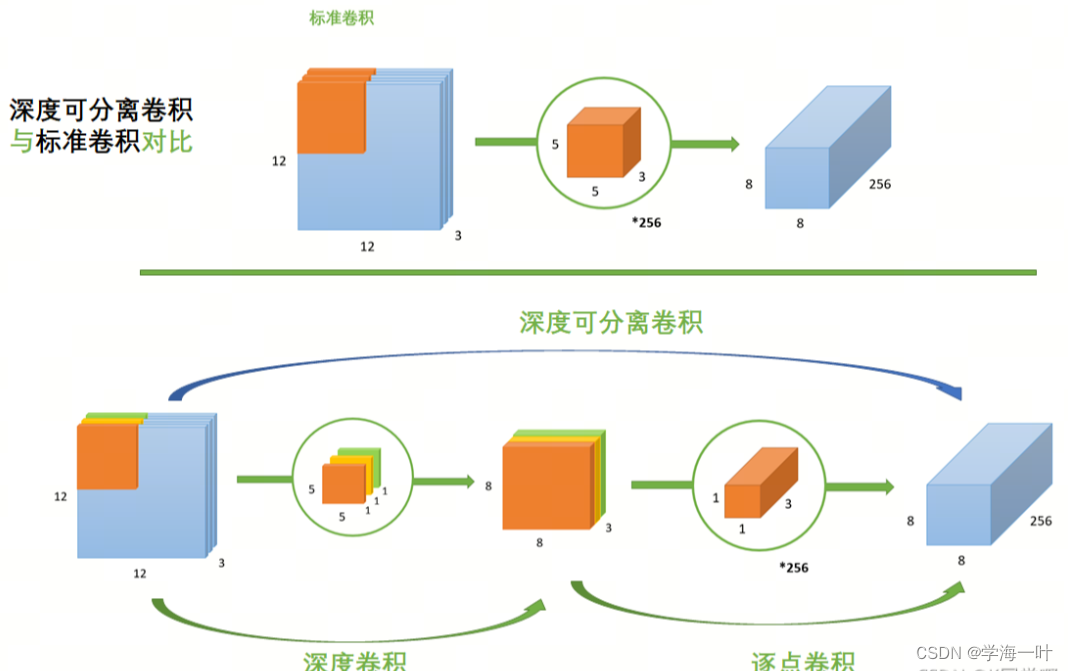
ps:逐通道卷积层DW(Depthwise Conv)是深度可分离卷积的组成部分,深度可分离卷积(depthwise separable convolution)由逐通道卷积depthwise(DW)和逐点卷积pointwise(PW)两个部分组成,相比于普通卷积,通过将乘法运算变为加法运算, 在能够保证同样卷积精度的情况下, 极大的降低计算成本。
- 如下图所示,参数量由5 * 5 * 3 * 256=19,200极显著下降至5 * 5 * 1 + 1 * 1 * 3 * 256=793
MBConv
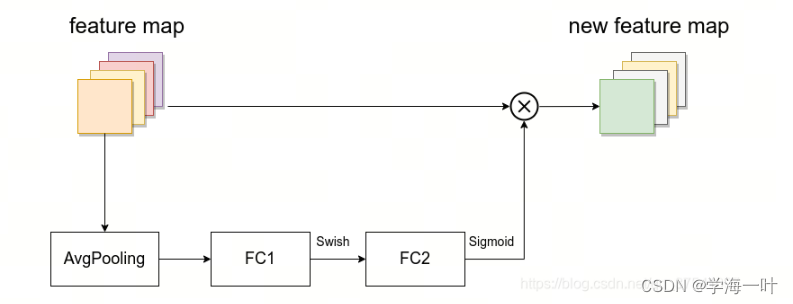
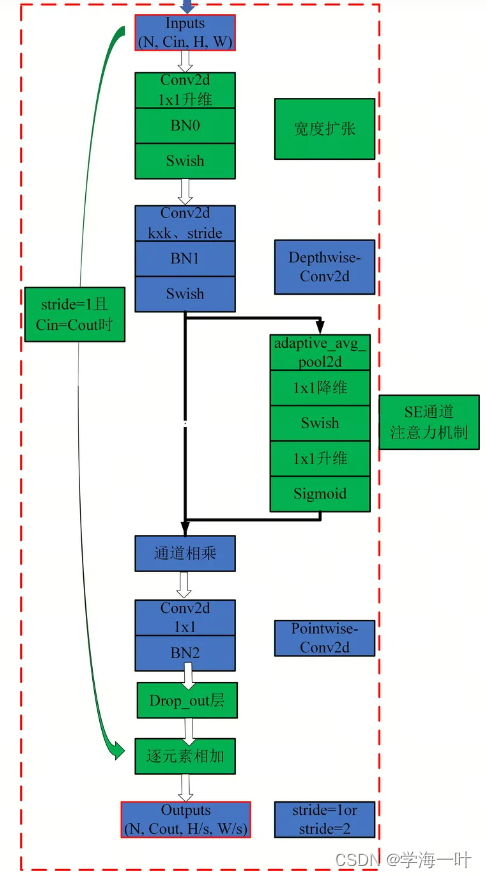
MBConv结构如下图,包含一个用于升维的1x1的普通卷积层(包含BN和Swish激活),逐通道卷积层DW(包含BN和Swish激活),压缩和激励模块SE,一个用于降维的1x1的普通卷积层(包含BN)以及Dropout层

ps:压缩和激励(Squeeze-and-Excitation, SE)模块用于发掘并刻画feature map中channel-wise feature间的关系,并显式地进行特征重标定,以提升有用的特征、抑制作用不太大的特征。SE block以微小的计算成本为现有的先进的神经网络架构带来了性能改进。SE Nets在ILSVRC 2017竞赛中赢得了第一名,并将top-5错误率显著减少到2.251%,相对2016年的第一名取得了∼25%的改进。
SE模块由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的
1
4
\frac{1}{4}
41 ,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数。
MBConv的具体网络拓扑图如下:
参数优化
根据以往的经验:
- 增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
- 增加网络的width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征
- 增加输入网络的图像分辨率resolution能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小。并且大分辨率图像会增加计算量
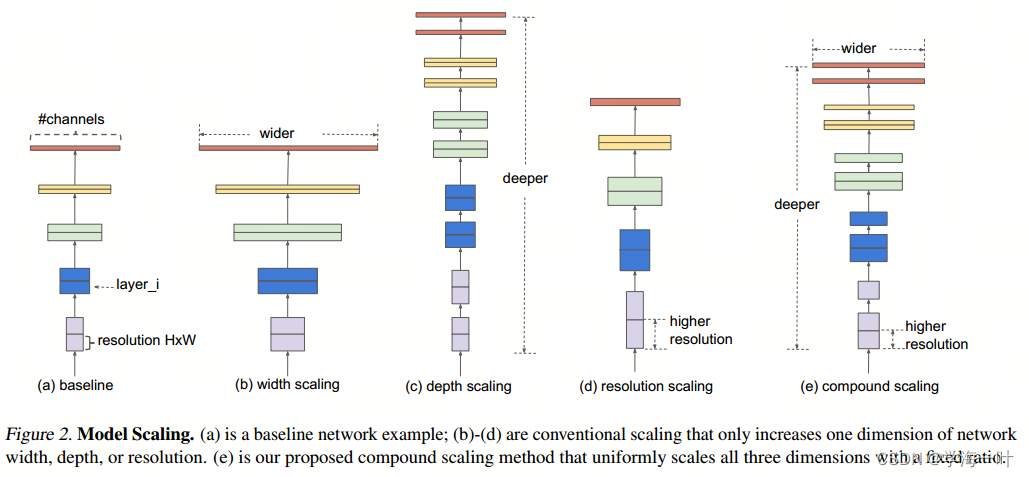
论文的目标是:给定资源约束(计算力FLOPS、内存Memory)下,最大限度地提高模型精度(其实就是通过搜索手段进行参数优化 ( d , w , r ) (d,w,r) (d,w,r)),公式如下:
ps:
- 要优化参数首先要有一个baseline模型,论文通过神经结构搜索(Neural Architecture Search,NAS)创建了EffcientNet B0 baseline模型,当然也可使用其他现有的模型进行,如MobileNets、ResNets等。
- 关于NAS,是一种神经架构搜索技术,对比传统网络的超参搜索,NAS主要的区别是深度网络结构搜索的重点在于如何拼接不同的结构模块和操作,以及如何降低模型评估的计算消耗,具体相关原理参见原文及相关论文,这里不做具体描述。
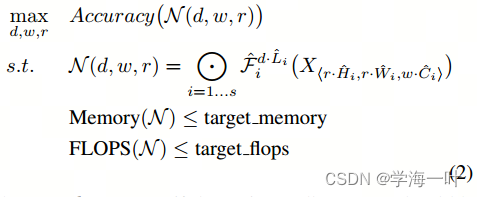
其中,
- ⊙ i = 1... s ⊙_{i=1...s} ⊙i=1...s表示连乘运算
- d用来缩放深度 L ^ i \widehat{L}_i L i,i对应的是上表中的stage
- r用来缩放分辨率即影响 H ^ i \widehat{H}_i H i和 W ^ i \widehat{W}_i W i
- w就是用来缩放特征矩阵的channel即 C ^ i \widehat{C}_i C i
ps:
- FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
- FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
接着作者又提出了一个复合缩放方法 ( compound scaling method) ,在这个方法中使用了一个混合因子
ϕ
\phi
ϕ去统一的缩放width,depth,resolution参数,具体的公式如下:
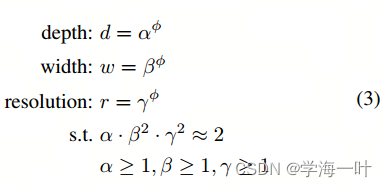
因此
(
d
,
w
,
r
)
(d,w,r)
(d,w,r)搜索问题变为
α
,
β
,
γ
\alpha, \beta, \gamma
α,β,γ搜索问题,具体步骤如下:
- 固定 ϕ = 1 \phi=1 ϕ=1,并基于上面给出的公式(2)和(3)进行grid search,得到EfficientNet-B0最佳参数为 α = 1.2 , β = 1.1 , γ = 1.15 \alpha=1.2, \beta=1.1, \gamma=1.15 α=1.2,β=1.1,γ=1.15
- 固定 α = 1.2 , β = 1.1 , γ = 1.15 \alpha=1.2, \beta=1.1, \gamma=1.15 α=1.2,β=1.1,γ=1.15,在EfficientNet-B0的基础上使用不同的 ϕ \phi ϕ分别得到EfficientNetB-1至EfficientNetB-7
ps:因为考虑到提升网络的深度是最有效的策略,因此将其他两个维度的缩放进行了平方操作。当一个网络缩放完毕后,它的FLOPS提升的倍数为 α ⋅ β 2 ⋅ γ 2 \alpha \cdot \beta^2 \cdot \gamma^2 α⋅β2⋅γ2,约束 α ⋅ β 2 ⋅ γ 2 ≈ 2 \alpha \cdot \beta^2 \cdot \gamma^2 ≈ 2 α⋅β2⋅γ2≈2,则将FLOPS的增长范围控制到了 2 ϕ 2^\phi 2ϕ
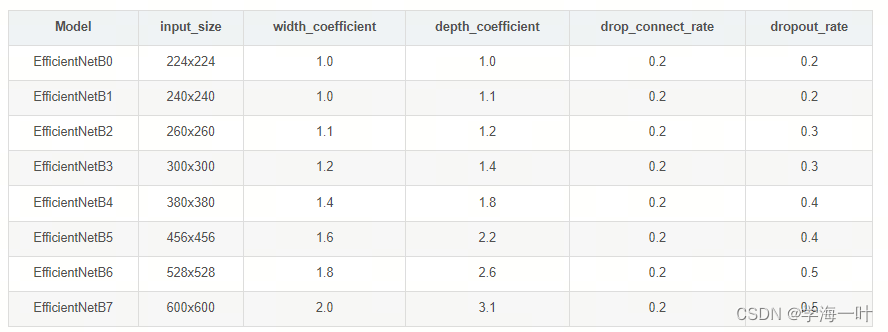
EfficientNet B0-B7 参数
通过搜索得到的 EfficientNet B0-B7 的参数如下:
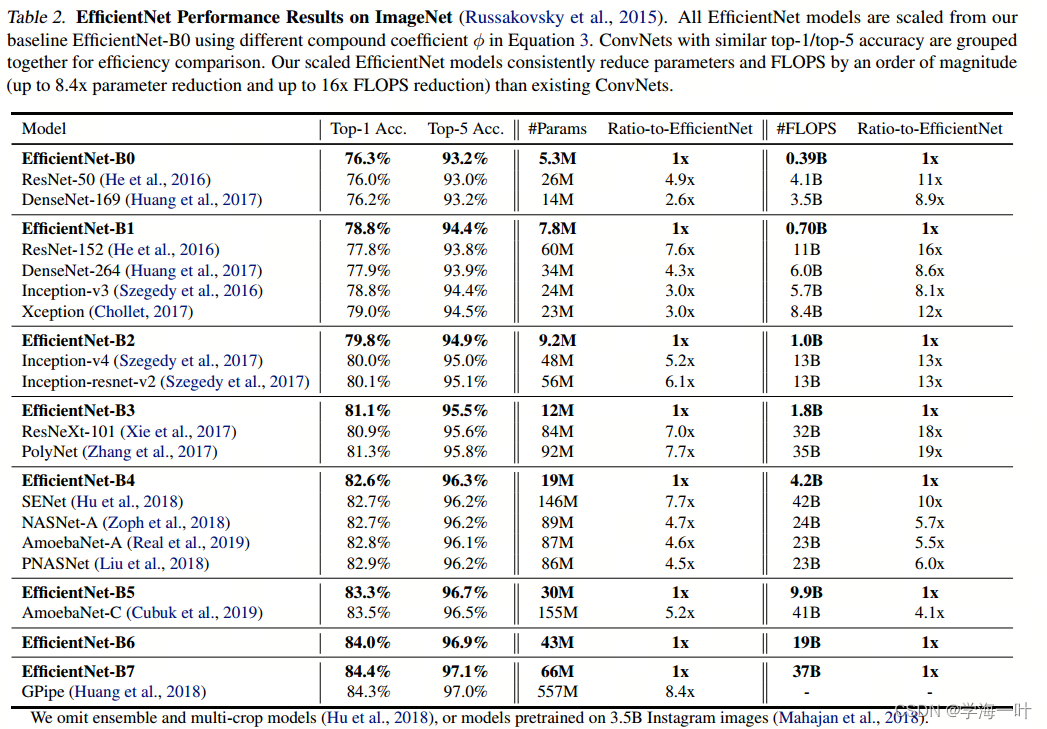
模型精度和速度对比如下:
二、EfficientDet
基于one-stage的检测模型,从骨架网络、特征融合和 class/box 网络的角度,提出两种创新方法:
-
高效的多尺度特征融合----之前的工作都是直接将不同尺度的特征相加,不做任何区分;但是作者发现,不同的尺度的特征对融合后的输出特征有着不同的贡献,因此作者提出了BiFPN,通过学习不同尺度特征的权重来表明不同尺度特征的重要性,同时重复使用自上而下和自下而上两种多尺度特征融合方式。
-
模型缩放----之前的工作为了提升准确率都是选择使用大的骨架网络或者大的输入图像,但是作者发现放大特征融合网络或 box/class 预测网络也很重要。受到EfficientNet的启发,作者提出一种复合缩放方法,同时缩放backbone的分辨率/深度/宽、特征融合网络、box/class 预测网络。
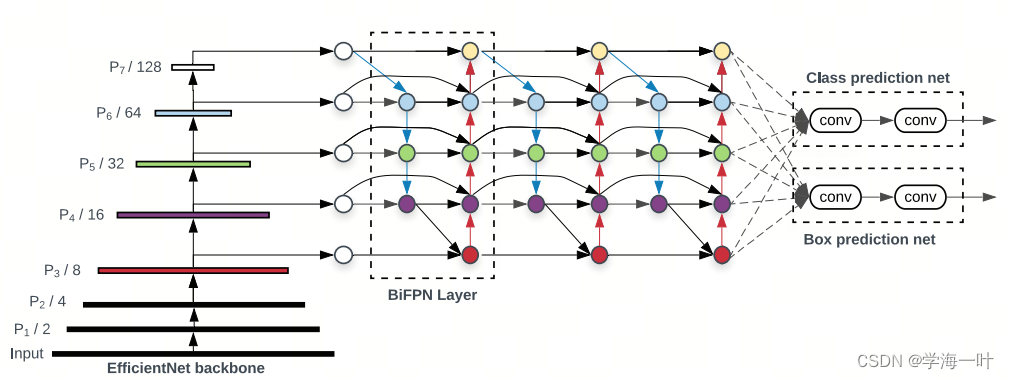
BiFPN
加权双向特征网络BiFPN(Bidirectional Feature network)是EfficientDet的核心, 全称是"Bidirectional Feature Pyramid Network ", 可轻松快速地进行多尺度特征融合
-
关于FPN网络我们已经不陌生,在One Stage(YOLOv3)和Two Stage(Mask RCNN)网络中都有应用,主要用于进行从上自下的进行特征融合,从而解决不同场景图像中对象尺度差异很大的问题。
-
但FPN在实际应用中会面临高层级特征和较低层级特征之间的路径较长的问题,如在大型Backbone 如Resnet-152中,FPN低层信息经过多层网络到高层的时候,由于路径过长导致部分低层级特征丢失,然而低层级的特征对于大型实例的识别其实是很有用的, 此时需要一个能缩短低层级信息到高层级通过路径的方法,因此出现了PANet,在FPN之上添加了一个额外的自下而上的特征融合。
-
同时Google提出了一种类似的神经架构搜索方法 NAS-FPN,用于创建多尺度特征的融合路径,尽管NAS-FPN获得了更好的性能,但它在搜索过程中需要数千个GPU小时,并且由此产生的特征网络是不规则的,因此难以解释和使用。
Efficient的作者在研究中发现:
- 如果一个节点只有一个输入边并且没有特征融合, 那么它对特征网络的融合贡献较小, 这个节点可以删除(Simplified PANet)。
- 如果原始输入与输出节点处于同一级别, 则在它们之间添加一条额外的连接路径, 以便在不增加成本的情况下融合更多功能(BiFPN),这点其实跟skip connection很相似。
- 将每个双向(自上而下&自下而上)路径作为一个特征网络层, 并且重复叠加相同的特征网络层多次, 以实现更高层次的特征融合(BiFPN Layers)。 具体重复几次是速度和精度之间的权衡, 因此会在下面的复合缩放部分介绍。
复合缩放方法
backbone
在EfficientNet中已经给出了backbone的复合缩放方法,EfficientDet使用Image-Net预训练的EfficientNet作为backbone网络
特征融合网络
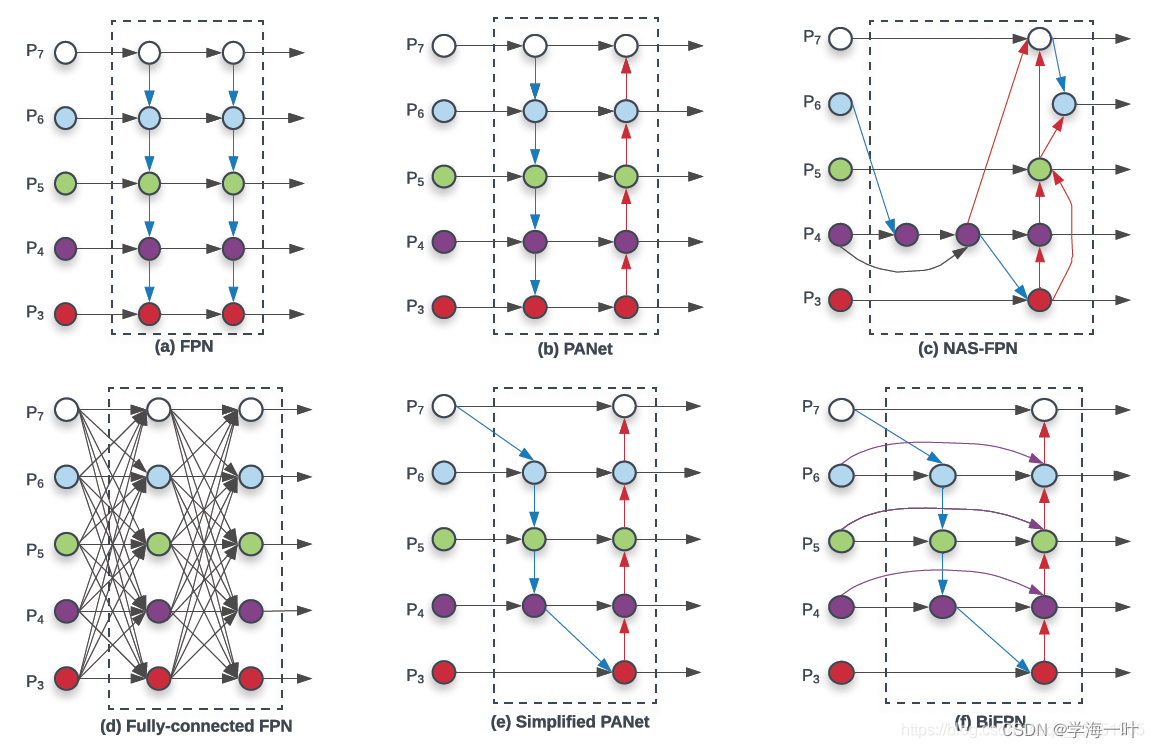
像在EfficientNet中一样以指数方式增长BiFPN宽度(channels), 但是由于深度需要四舍五入为小整数, 因此线性增加了深度(layers),具体而言,对值{1.2、1.25、1.3、1.35、1.4、1.45}的列表执行网格搜索,并选择最佳值1.35作为BiFPN宽度缩放因子。形式上,BiFPN的宽度和深度用以下方程进行缩放:
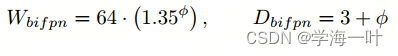
Box/Class 预测网络
宽度保持与BiFPN相同, 但深度(layers)线性增加
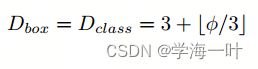
输入图像分辨率
由于BiFPN中使用了特征级别3–7, 因此输入分辨率必须可除以2⁷= 128, 因此我们使用以下公式线性提高分辨率
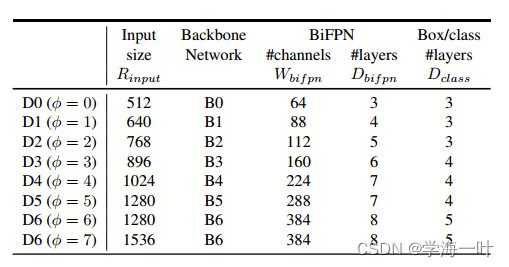
复合缩放的总结图如下所示:
通过改变
ϕ
\phi
ϕ(0-6), 作者得到了以下不同计算量和参数量的8个模型, 由于
ϕ
\phi
ϕ≥7的模型过于庞大, 因此D7相对D6值增加了图像分辨率.
总结
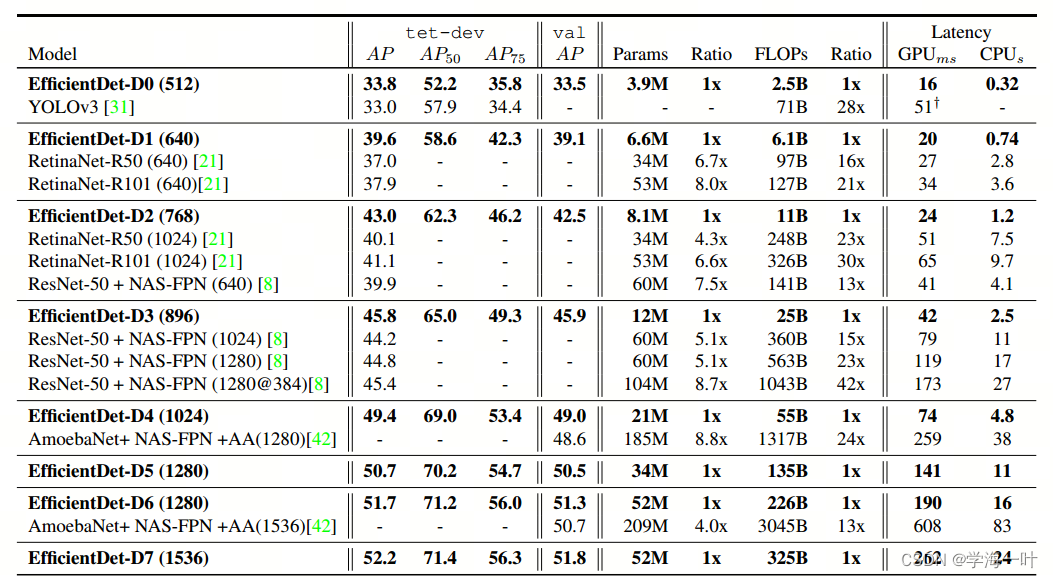
EfficientDet分别包含了从D0~D7总共八个算法,对于不同的设备限制,能给到SOTA的结果,在广泛的资源约束下始终比现有技术获得更好的效率。特别是在单模型和单尺度的情况下,EfficientDet-D7在COCO test-dev上达到了最先进的52.2AP,具有52M参数和325B FLOPs,相比与之前的算法,参数量缩小了4到9倍,FLOPs缩小了13到42倍。
EfficientDet使用神经网络搜索最优架构的优势, 同样使它的不足. 因为EfficientDet的预训练成本是巨大的, EfficientDet的作者使用 32 个V3 TPU 在batch_size为128的数据集上训练, 才达到各项SOTA的成绩. 而普通人拥有的硬件资源是有限的, 从0开始训练完整模型需要的时间和硬件成本过高。如果用时间换成本的方式可以接近但是很难达到相似的精度。