读算法霸权笔记12_数据科学
news2026/2/11 23:59:34
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1360437.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

常用python代码大全-使用Python的requests模块发送HTTP请求
要使用Python的requests模块发送HTTP请求,你需要首先确保已经安装了这个模块。如果没有安装,可以通过以下命令进行安装:
pip install requests一旦安装完成,你可以按照以下步骤发送HTTP请求:
1.导入requests模块&…
61.网游逆向分析与插件开发-游戏增加自动化助手接口-游戏红字公告功能的逆向分析
内容来源于:易道云信息技术研究院VIP课
上一节内容:游戏公告功能的逆向分析与测试-CSDN博客
码云地址(master分支):https://gitee.com/dye_your_fingers/sro_-ex.git
码云版本号:63e04cc40f649d10ba2f4f…
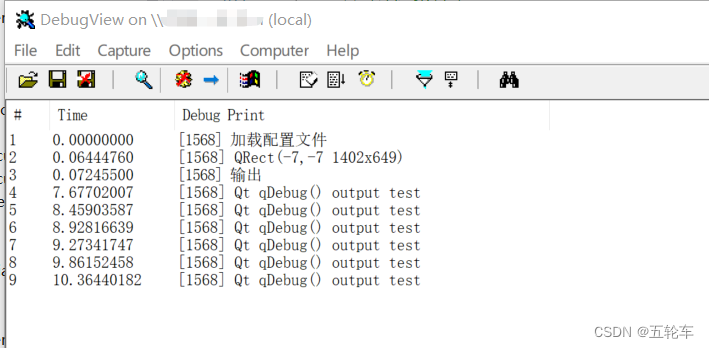
Qt qDebug基本的使用方法详解
目录 qDebug基本用法输出字符串输出变量值1输出变量值2支持流式输出输出十六进制去除双引号和空格调试输出级别 自定义类型输出自定义日志信息的输出格式示例占位符设置环境变量 关闭QDebug输出Qt工程VS工程 在VS工程中如何查看qDebug输出 DebugView下载 qDebug基本用法 qDebug…

初识大数据,一文掌握大数据必备知识文集(12)
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…
一文详解动态 Schema
在数据库中,Schema 常有,而动态 Schema 不常有。 例如,SQL 数据库有预定义的 Schema,但这些 Schema 通常都不能修改,用户只有在创建时才能定义 Schema。Schema 的作用是告诉数据库使用者所希望的表结构,确保…
C++ OpenGL 3D GameTutorial 1:Making the window with win32 API学习笔记
视频地址https://www.youtube.com/watch?vjHcz22MDPeE&listPLv8DnRaQOs5-MR-zbP1QUdq5FL0FWqVzg 一、入口函数 首先看入口函数main代码:
#include<OGL3D/Game/OGame.h>int main()
{OGame game;game.Run();return 0;
} 这里交代个关于C语法的问题&#x…
群晖Docker部署HomeAssistant容器结合内网穿透远程控制家中智能设备
目录
一、下载HomeAssistant镜像
二、内网穿透HomeAssistant,实现异地控制智能家居
三、使用固定域名访问HomeAssistant 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。 点击跳转到网站 Ho…
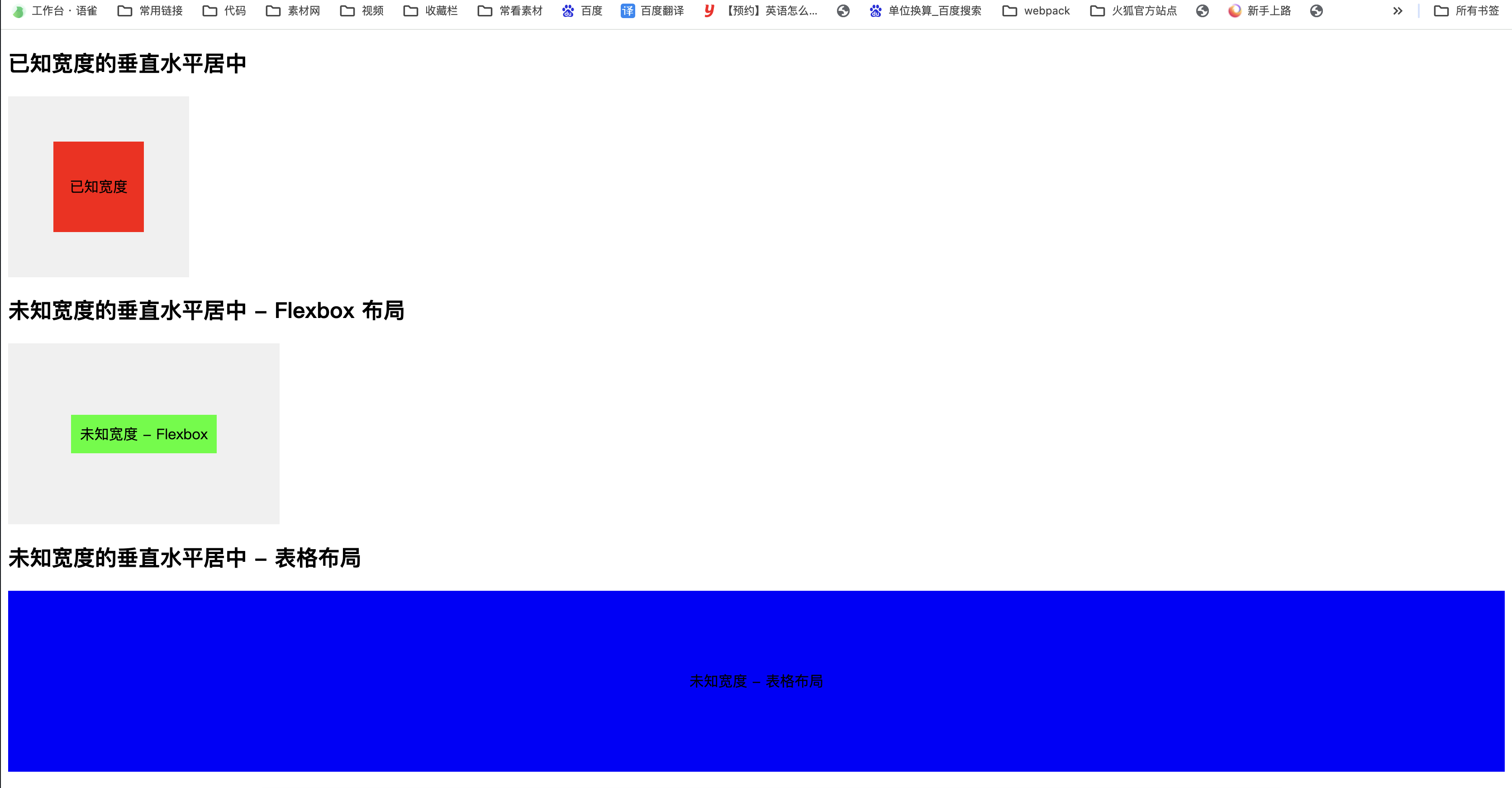
几种常见的CSS三栏布局?介绍下粘性布局(sticky)?自适应布局?左边宽度固定,右边自适应?两种以上方式实现已知或者未知宽度的垂直水平居中?
几种常见的CSS三栏布局
流体布局
效果:
参考代码:
<!DOCTYPE html>
<html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1…

【elfboard linux 开发板】9. 虚拟机扩容和内核编译
1. 虚拟机扩容
需要将虚拟机的快照全都删除,并且将运行的系统关机点击扩展,改为需要的磁盘大小安装gparted工具 sudo apt-get install gparted 如果报错,则按照出错内容修改,一般是出现下载错误,可以使用下列命令&…
【大数据进阶第三阶段之Hive学习笔记】Hive的数据类型与数据操作
【大数据进阶第三阶段之Hive学习笔记】Hive安装-CSDN博客
【大数据进阶第三阶段之Hive学习笔记】Hive常用命令和属性配置-CSDN博客
【大数据进阶第三阶段之Hive学习笔记】Hive基础入门-CSDN博客
【大数据进阶第三阶段之Hive学习笔记】Hive查询、函数、性能优化-CSDN博客
…
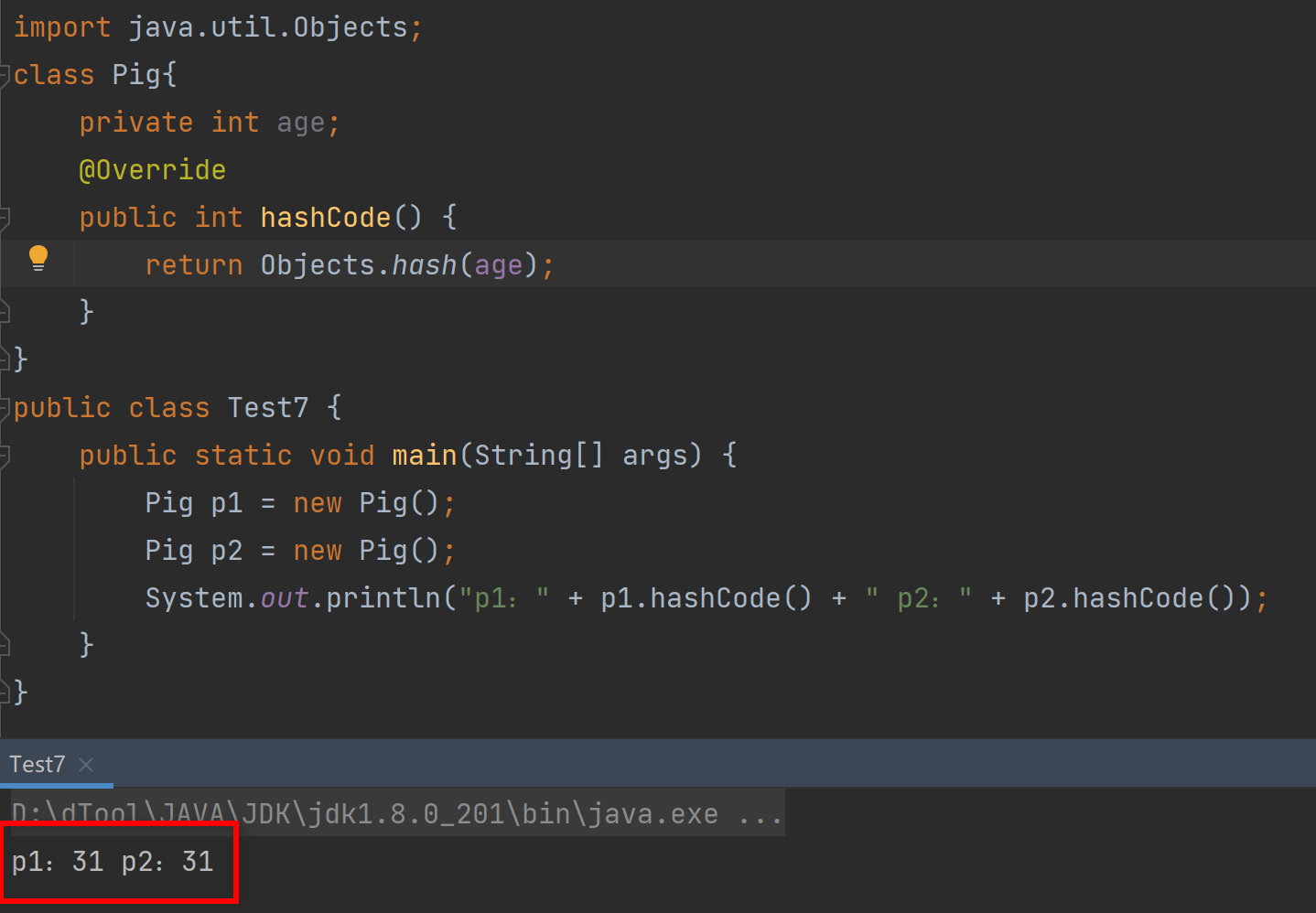
集合-及其各种特征详解
集合 概念:是提供一种存储空间 可变 的存储模型,存储的数据容量可以发生改变。(也就是集合容量不固定) 集合关系图 绿色的代表接口,蓝色的代表接口的实现类 单列集合
Collection(接口) 概述:单列集合的…
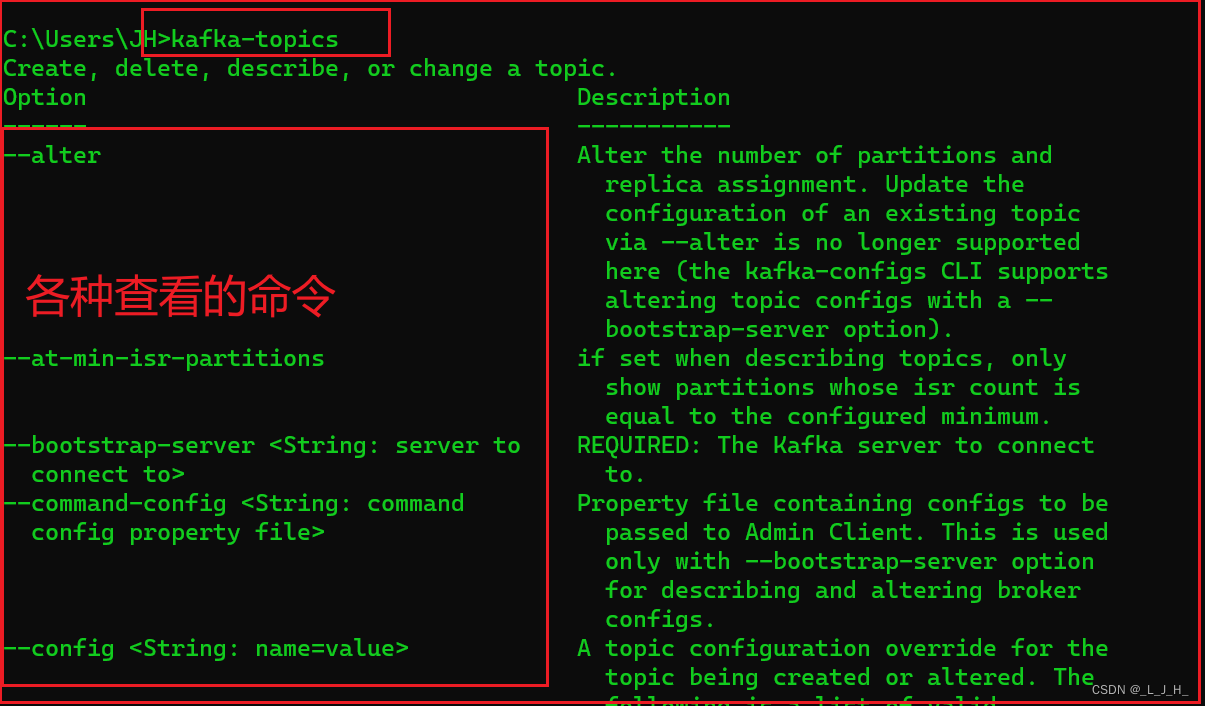
05、Kafka ------ CMAK 各个功能的作用解释(主题和分区 详解,用命令行和图形界面创建主题和查看主题)
目录 CMAK 各个功能的作用解释(主题)★ 主题★ 分区★ 创建主题:★ 列出和查看主题 CMAK 各个功能的作用解释(主题) ★ 主题
Kafka 主题虽然也叫 topic,但它和 Pub-Sub 消息模型中 topic 主题及 AMQP 的 t…
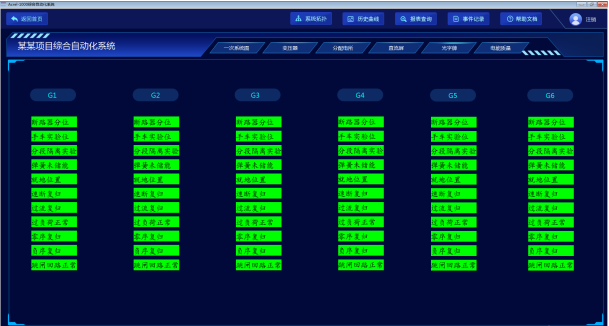
安科瑞变电站综合自动化系统在青岛海洋科技园应用——安科瑞 顾烊宇
摘 要:变电站综合自动化系统是将变电站内的二次设备经过功能的组合和优化设计,利用先进的计算机技术、通信技术、信号处理技术,实现对全变电站的主要设备和输、配电线路的自动监视、测量、控制、保护、并与上级调度通信的综合性自动化功能。 …

深入理解Word Embeddings:Word2Vec技术与应用
目录 前言1 Word2Vec概述2 CBOW模型2.1 CBOW模型简介2.2 基于词袋(bag of word)的假设2.3 One-hot向量编码2.4 分类问题 3 Skip-gram模型3.1 Skip-gram模型简介3.2 目标词预测上下文3.3 词语关联性的捕捉 4 优化Word2Vec模型的方法4.1 负采样和分层softm…
谷歌浏览器启用实时字幕功能
在 Chrome 中使用“实时字幕”功能 - Google Chrome帮助
在 Chrome 中使用“实时字幕”功能
从计算机上的 Chrome 浏览器中,您可以使用“实时字幕”功能自动为视频、播客、游戏、直播、视频通话或其他音频媒体生成字幕。音频和字幕均在本地处理,并会保…
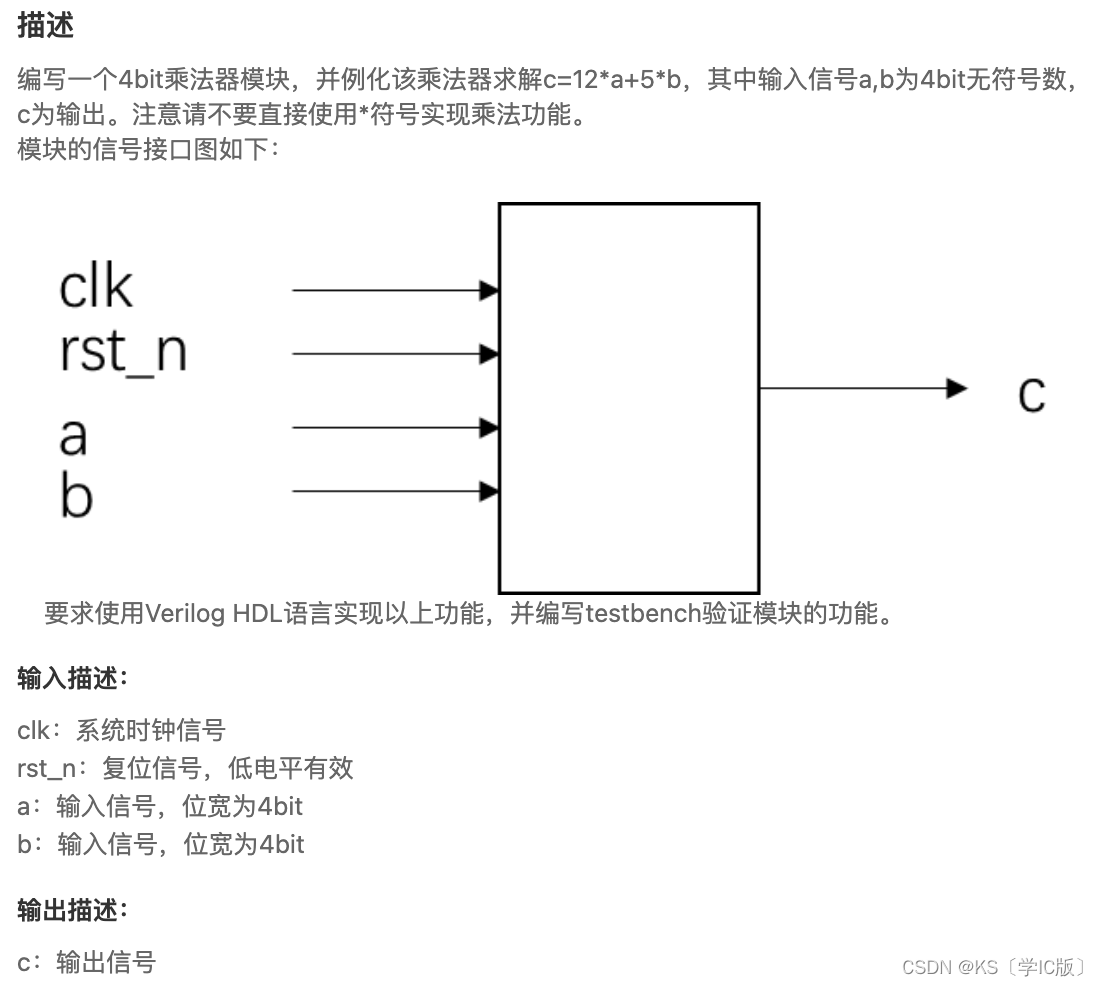
「Verilog学习笔记」编写乘法器求解算法表达式
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 timescale 1ns/1nsmodule calculation(input clk,input rst_n,input [3:0] a,input [3:0] b,output [8:0] c);reg [8:0] data1, data2 ; assign c data2 ; always (posed…

【Filament】自定义Blinn Phong光照模型
1 前言 光照元素主要有环境光(ambient)、漫反射光(diffuse)、镜面反射光(specular),基础的光照模型主要有兰伯特(Lambert)光照模型、冯氏(Phong)光…
【Vue3+React18+TS4】1-1 : 课程介绍与学习指南
本书目录:点击进入
一、为什么做这样一门课程?
二、本门课的亮点有哪些?
2.1、轻松驾驭
2.2、体系系统
2.3、高效快捷
2.4、融合贯通
三、课程内容包括哪些? 四、项目实战 《在线考勤系统》 五、课适合哪些同学? 一、为什么做这样一门课程? 近十年内前端…
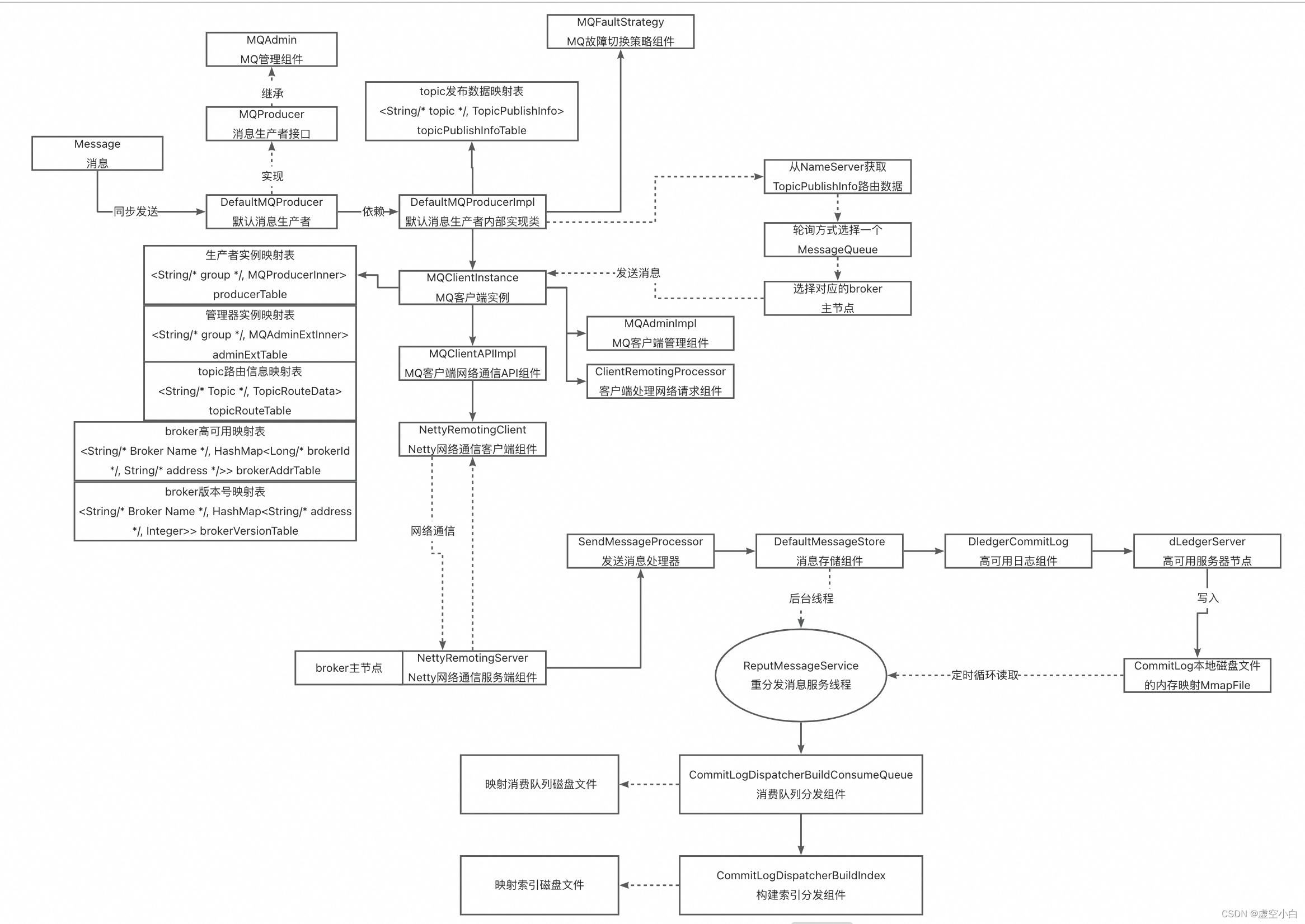
RocketMQ源码 发送消息源码分析
前言
DefaultMQProducer 是默认生产者组件,是生产者客户端中,绝大部分关于生产者和broker、nameSrv进行网络通信的功能入口。其中,包含发送各种形式(同步、异步、事务、顺序)的消息,针对发送消息部分的实现…

Vue页面传值:Props属性与$emit事件的应用介绍
一、vue页面传值
在Vue页面中传值有多种方式,简单介绍以下两种 通过props属性传递值:父组件在子组件上定义props属性,子组件通过props接收父组件传递的值。通过$emit触发事件传递值:子组件通过$emit方法触发一个自定义事件&#…